特斯拉 Model 3解析(十一)特斯拉 FSD 芯片深度拆解:为什么能“碾压”英伟达 Xavier?
芯片专用化是趋势通用 GPU 算力再高,遇到卷积/矩阵乘法时,仍然难敌专用 NPU。未来 Orin、华为 MDC、地平线征程系列都会朝这个方向走。功耗和成本同样关键特斯拉 FSD 在功耗/Watt 性能比上虽然不如 Xavier“低功耗”,但考虑到电动车有 400V/800V 电池支撑,几十瓦的差距完全可以接受。换来的,是更低的单车成本。国产 AI 芯片机会国内的地平线 J6、黑芝麻智能 A100
🎯 特斯拉 FSD 芯片深度拆解:为什么能“碾压”英伟达 Xavier?
🚗 1. 背景:从 HW2.5 到 HW3.0 的关键抉择
在 HW2.5 时代,特斯拉依赖英伟达 Parker SoC(基于 Xavier 的架构)。但是随着自动驾驶算法复杂度爆炸式上升,Xavier 的 30 TOPS 算力显然不够用了。
于是,特斯拉在 HW3.0 中果断转向 自研 FSD 芯片。这不仅仅是“造芯”的勇气,而是 性能、功耗、成本、数据闭环 的综合考量。

🔥 2. 核心对比:FSD vs Xavier
| 指标 | Tesla FSD (HW3.0) | Nvidia Xavier |
|---|---|---|
| 工艺 | Samsung 14nm | TSMC 12nm |
| 芯片面积 | ~260 mm² | ~350 mm² |
| AI 算力 | 144 TOPS | 30 TOPS |
| 功耗 | ~72W (双芯片冗余) | ~30W |
| NPU 优化 | 卷积 & 矩阵乘法高度优化 | 通用 GPU 加速 |
| 系统设计 | 双 FSD 芯片 + 冗余 | 单 SoC |
👉 这里的关键差距不只是 TOPS,而是 算力密度:
算力密度=TOPSDie Area (mm2) \text{算力密度} = \frac{\text{TOPS}}{\text{Die Area (mm}^2\text{)}} 算力密度=Die Area (mm2)TOPS
-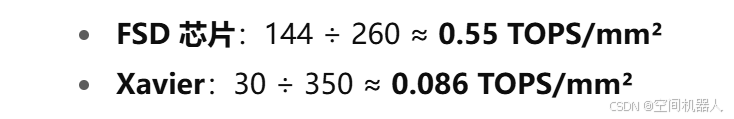
🎯 这意味着特斯拉的自研方案比英伟达的算力利用效率 提升了 6 倍以上。
⚡ 3. 架构优势:为自动驾驶而生
特斯拉 FSD 的 NPU 不是通用计算加速器,而是专门针对 卷积、矩阵乘法、激活函数 等视觉任务定制。
- 数据流优化:NPU 内部采用 局部 SRAM 缓存,避免了大规模访存瓶颈。
- 卷积加速:支持 Winograd 卷积算法,显著降低乘法次数。
- 低精度计算:NPU 针对 INT8/FP16 优化,而不是全靠 FP32。
例如,一个典型的卷积计算量:
MACs=K2×Cin×Cout×Hout×Wout \text{MACs} = K^2 \times C_{in} \times C_{out} \times H_{out} \times W_{out} MACs=K2×Cin×Cout×Hout×Wout
特斯拉的 NPU 可以在硬件级别将 MACs 运算 pipeline 化,同时通过 数据复用 大幅减少访存延迟。
🔒 4. 冗余与安全设计
别忘了,特斯拉在 HW3.0 里采用了 双 FSD 芯片架构:
- 两颗 FSD 芯片同时处理同一组传感器数据。
- 如果结果有分歧,系统会进入安全模式。
这相当于在硬件层面做了 ASIL-D 级别的冗余,保证自动驾驶不会因为单点失效而“翻车”。
🧠 5. 算法与数据闭环
硬件只是“刀”,特斯拉的“剑术”是 AI 算法和数据闭环:
- AutoPilot 神经网络包含 48 个子网络(涵盖车道线、障碍物、行人、交通灯等)。
- 每天训练量达到 70,000 GPU·小时。
- 依托数百万辆车的实时路况,特斯拉能做到 快速 OTA 迭代。
这种 车队数据驱动+芯片加速 的闭环,远比单纯算力堆叠更具竞争力。
🚀 6. 总结
-
芯片专用化是趋势
通用 GPU 算力再高,遇到卷积/矩阵乘法时,仍然难敌专用 NPU。未来 Orin、华为 MDC、地平线征程系列都会朝这个方向走。 -
功耗和成本同样关键
特斯拉 FSD 在 功耗/Watt 性能比 上虽然不如 Xavier“低功耗”,但考虑到电动车有 400V/800V 电池支撑,几十瓦的差距完全可以接受。换来的,是更低的单车成本。 -
国产 AI 芯片机会
国内的 地平线 J6、黑芝麻智能 A1000 Pro 已经能在 100~200 TOPS 区间做到不错的功耗比。如果能进一步打通算法闭环,国产有望在智能驾驶芯片赛道形成差异化。
🎯 总结
特斯拉 FSD 芯片成功的秘诀,不仅仅是 144 TOPS 的纸面数据,而是 架构定制 + 数据闭环 + 系统级冗余 的综合优势。
未来,自动驾驶芯片的竞争不会只看“算力排行榜”,而是:
- 谁的算力利用效率更高?
- 谁的数据闭环更完整?
- 谁能更快实现 OTA 迭代?
在这一点上,特斯拉已经给行业上了一课。🔥

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)