手机也能跑GPT-4o级视觉模型!MiniCPM-V 4.5:8B参数小巨人碾压72B巨无霸
MiniCPM-V 4.5的发布标志着端侧多模态AI进入新纪元。它证明了小模型也能有大作为,无需依赖云端服务器,手机就能拥有媲美顶级闭源模型的视觉理解能力。
你是否想过,有一天能在手机上流畅运行媲美GPT-4o的视觉理解模型?面壁智能最新发布的MiniCPM-V 4.5让这一梦想成为现实!这款仅8B参数的轻量级多模态模型,不仅性能超越了参数量高达72B的竞品,更在手机端实现了前所未有的视觉理解能力。
一、小身材大能量:8B参数的视觉"六边形战士"
MiniCPM-V 4.5基于Qwen3-8B和SigLIP2-400M构建,总参数量仅8B,却在OpenCompass综合评估中取得了77.0的高分,全面超越了GPT-4o-latest、Gemini-2.0 Pro等专有模型以及Qwen2.5-VL 72B等开源模型。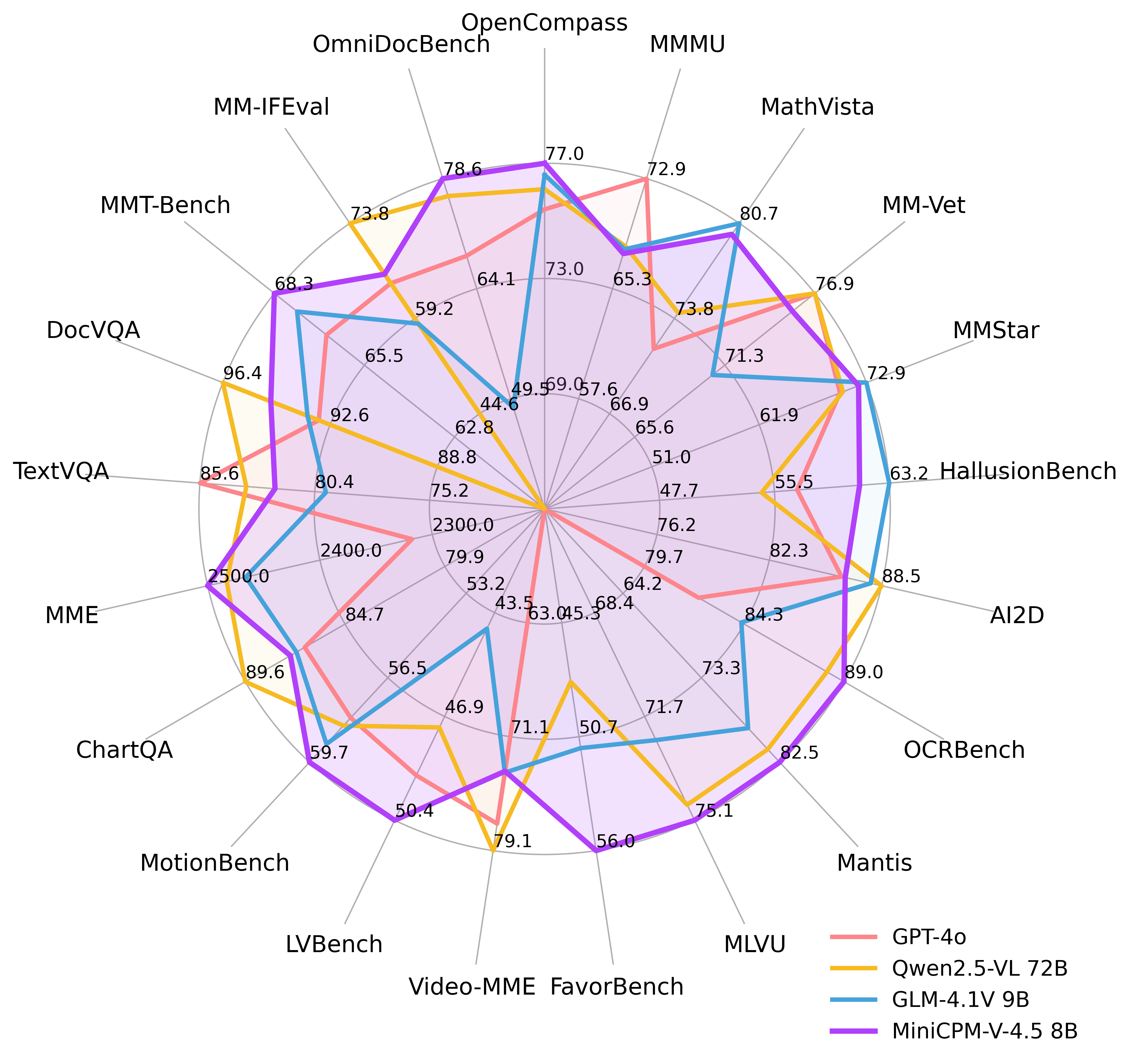
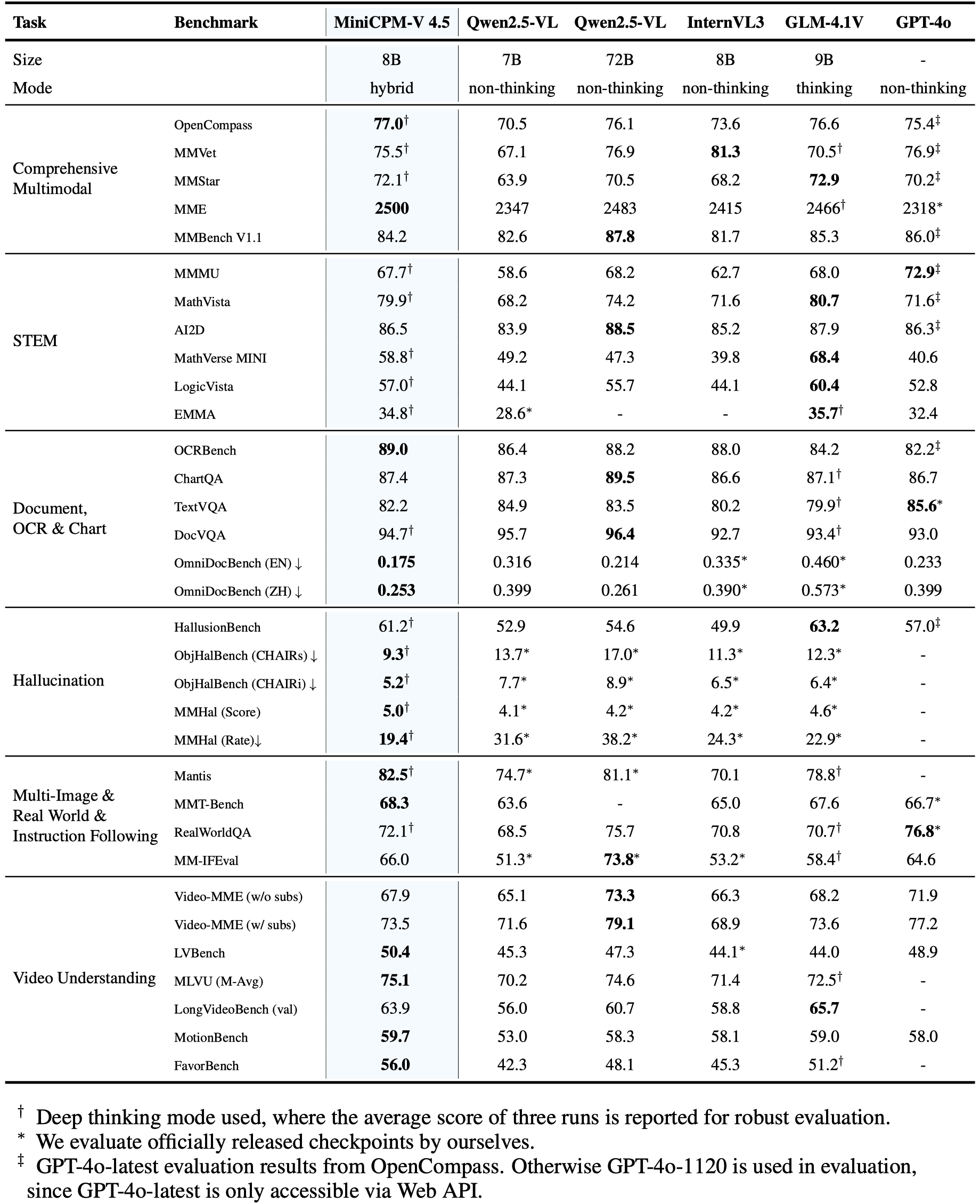
更令人惊叹的是,它在手机端的部署能力——无需云端支持,仅凭iPhone或iPad就能流畅运行,让高端视觉理解真正"触手可及"。这款模型堪称当前参数量低于30B的最强大多模态大语言模型(MLLM),是端侧AI领域的一颗耀眼新星。
二、视频理解革命:96倍压缩率的"鹰眼"技术
MiniCPM-V 4.5最大的突破在于其首创的"高刷视频理解"能力,这也是它被称为"装上鹰眼"的原因。
通过创新的统一3D-Resampler技术,MiniCPM-V 4.5能将6帧448x448的视频压缩成仅64个视频token(通常大多数MLLM需要1,536个token),实现惊人的96倍压缩率。
这意味着什么?在相同计算资源下,MiniCPM-V 4.5能处理6倍于常规模型的视频帧数,实现高达10FPS的高刷新率视频理解,让手机也能流畅分析动态视频内容!
在Video-MME、LVBench、MLVU等权威基准测试中,MiniCPM-V 4.5均取得了领先成绩,无论是短视频还是长达数分钟的视频,都能精准捕捉关键信息。
三、多模态全能王:从图片到文档的全方位理解
除了视频理解,MiniCPM-V 4.5在其他视觉任务上同样表现出色:
-
超高分辨率支持:可处理高达180万像素(1344x1344)的图像,支持任意宽高比,视觉token使用量比大多数MLLM少4倍。
-
OCR王者:在OCRBench上的表现超越GPT-4o-latest和Gemini 2.5等专有模型,文字识别准确率令人惊叹。
-
文档解析专家:在OmniDocBench上,PDF文档解析能力达到行业领先水平,能精准提取表格、公式等复杂内容。
-
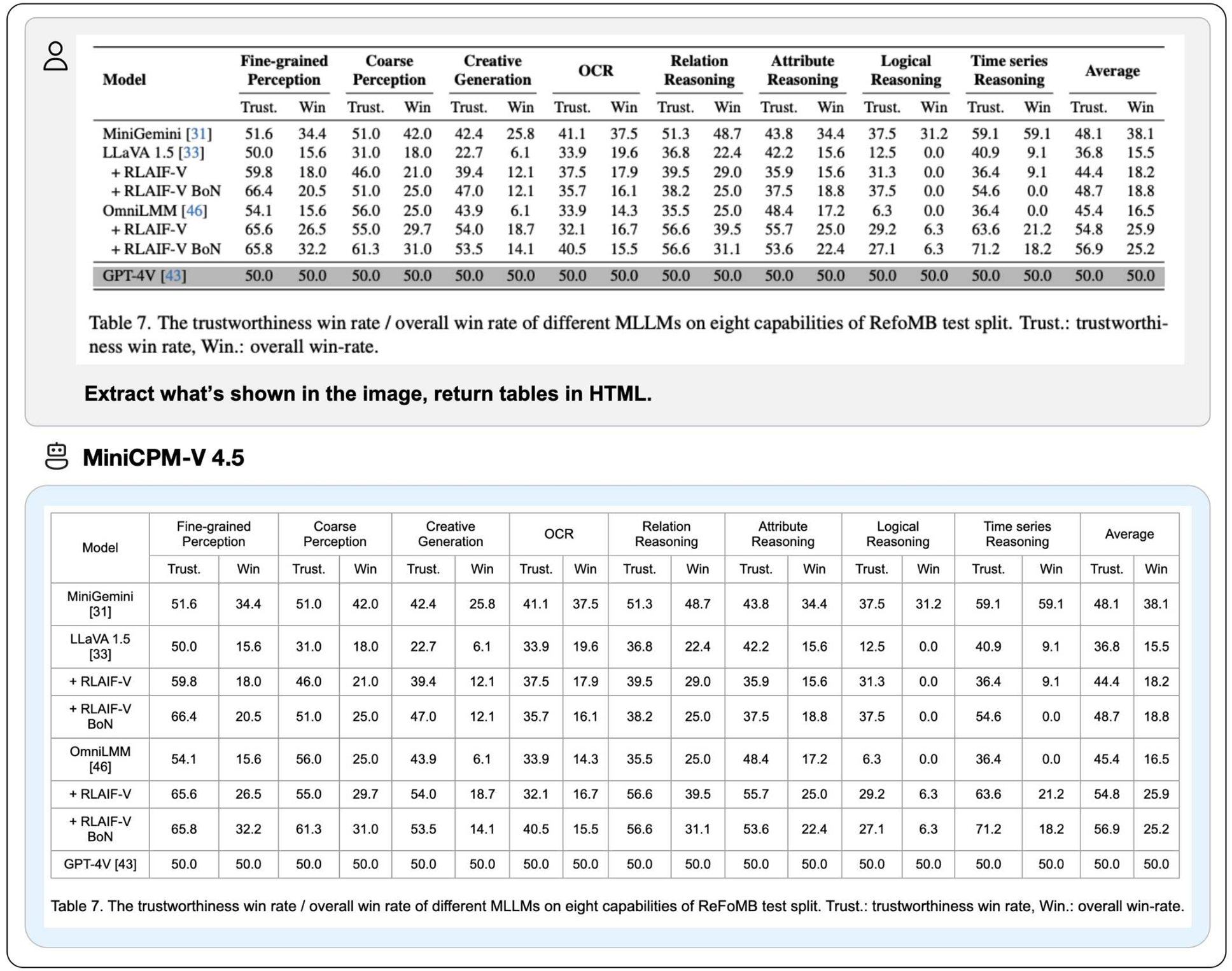
多语言支持:基于最新的RLAIF-V和VisCPM技术,支持超过30种语言,满足全球化需求。
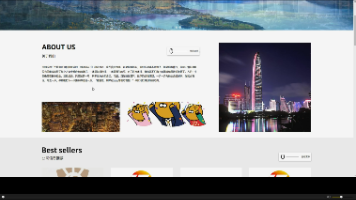
示例


四、手机上的AI革命:从iPad到安卓机都能跑
MiniCPM-V 4.5最令人兴奋的特性是其卓越的端侧部署能力:
-
iOS完美适配:专为iPhone和iPad优化的本地应用,M4芯片iPad上运行流畅,演示视频显示其能实时分析图像和视频内容。
-
多种部署方式:支持llama.cpp和ollama进行高效CPU推理,提供int4、GGUF和AWQ等16种量化模型格式,适应不同设备需求。
-
一键体验:提供快速本地WebUI演示和在线网页演示,无需技术背景也能轻松上手。
只需几行代码,你就能在手机上实现单张图片、多张图片和视频的智能理解,让AI真正融入日常生活。
在iPad M4上部署了MiniCPM-V 4.5,带有iOS演示。演示视频是未经编辑的原始屏幕录制。
五、推理
图片聊天
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking
)
print(answer)
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
输出结果:
# round1
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.
This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.
# round2
When traveling to a karst landscape like this, here are some important tips:
1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.
By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
视频聊天
## The 3d-resampler compresses multiple frames into 64 tokens by introducing temporal_ids.
# To achieve this, you need to organize your video data into two corresponding sequences:
# frames: List[Image]
# temporal_ids: List[List[Int]].
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
from scipy.spatial import cKDTree
import numpy as np
import math
model = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=180 # Indicates the maximum number of frames received after the videos are packed. The actual maximum number of valid frames is MAX_NUM_FRAMES * MAX_NUM_PACKING.
MAX_NUM_PACKING=3 # indicates the maximum packing number of video frames. valid range: 1-6
TIME_SCALE = 0.1
def map_to_nearest_scale(values, scale):
tree = cKDTree(np.asarray(scale)[:, None])
_, indices = tree.query(np.asarray(values)[:, None])
return np.asarray(scale)[indices]
def group_array(arr, size):
return [arr[i:i+size] for i in range(0, len(arr), size)]
def encode_video(video_path, choose_fps=3, force_packing=None):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
fps = vr.get_avg_fps()
video_duration = len(vr) / fps
if choose_fps * int(video_duration) <= MAX_NUM_FRAMES:
packing_nums = 1
choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))
else:
packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)
if packing_nums <= MAX_NUM_PACKING:
choose_frames = round(video_duration * choose_fps)
else:
choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)
packing_nums = MAX_NUM_PACKING
frame_idx = [i for i in range(0, len(vr))]
frame_idx = np.array(uniform_sample(frame_idx, choose_frames))
if force_packing:
packing_nums = min(force_packing, MAX_NUM_PACKING)
print(video_path, ' duration:', video_duration)
print(f'get video frames={len(frame_idx)}, packing_nums={packing_nums}')
frames = vr.get_batch(frame_idx).asnumpy()
frame_idx_ts = frame_idx / fps
scale = np.arange(0, video_duration, TIME_SCALE)
frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALE
frame_ts_id = frame_ts_id.astype(np.int32)
assert len(frames) == len(frame_ts_id)
frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]
frame_ts_id_group = group_array(frame_ts_id, packing_nums)
return frames, frame_ts_id_group
video_path="video_test.mp4"
fps = 5 # fps for video
force_packing = None # You can set force_packing to ensure that 3D packing is forcibly enabled; otherwise, encode_video will dynamically set the packing quantity based on the duration.
frames, frame_ts_id_group = encode_video(video_path, fps, force_packing=force_packing)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
use_image_id=False,
max_slice_nums=1,
temporal_ids=frame_ts_id_group
)
print(answer)
六、免费开源,商业友好
对于开发者和企业用户,MiniCPM-V 4.5提供了友好的使用政策:
- 完全免费用于学术研究
- 商业用途只需填写问卷注册,即可免费获取模型权重
- 代码采用Apache-2.0许可证发布,模型权重遵守MiniCPM Model License
结语:端侧AI的新纪元
MiniCPM-V 4.5的发布标志着端侧多模态AI进入新纪元。它证明了小模型也能有大作为,无需依赖云端服务器,手机就能拥有媲美顶级闭源模型的视觉理解能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)