【datawhale组队学习】RAG技术 -TASK06索引优化
教程地址:https://github.com/datawhalechina/all-in-rag基于LlamaIndex的高性能生产级RAG构建方案1,对索引优化进行更深入的探讨。
教程地址:https://github.com/datawhalechina/all-in-rag
基于LlamaIndex的高性能生产级RAG构建方案1,对索引优化进行更深入的探讨。
文章目录
上下文扩展
在RAG系统中,常常面临一个权衡问题:
- 使用小块文本进行检索可以获得更高的精确度,但小块文本缺乏足够的上下文,可能导致大语言模型(LLM)无法生成高质量的答案;
- 而使用大块文本虽然上下文丰富,却容易引入噪音,降低检索的相关性。为了解决这一矛盾
- LlamaIndex 提出了一种实用的索引策略——句子窗口检索(Sentence Window Retrieval)
该技术巧妙地结合了两种方法的优点:它在检索时聚焦于高度精确的单个句子,在送入LLM生成答案前,又智能地将上下文扩展回一个更宽的“窗口”,从而同时保证检索的准确性和生成的质量。
主要思路
句子窗口检索的思想可以概括为:为检索精确性而索引小块,为上下文丰富性而检索大块。
其工作流程如下:
- 索引阶段:在构建索引时,文档被分割成单个句子。每个句子都作为一个独立的“节点(Node)”存入向量数据库。同时,每个句子节点都会在元数据(metadata)中存储其上下文窗口,即该句子原文中的前N个和后N个句子。这个窗口内的文本不会被索引,仅仅是作为元数据存储。
- 检索阶段:当用户发起查询时,系统会在所有单一句子节点上执行相似度搜索。因为句子是表达完整语义的最小单位,所以这种方式可以非常精确地定位到与用户问题最相关的核心信息。
- 后处理阶段:在检索到最相关的句子节点后,系统会使用一个名为 MetadataReplacementPostProcessor 的后处理模块。该模块会读取到检索到的句子节点的元数据,并用元数据中存储的完整上下文窗口来替换节点中原来的单一句子内容。
- 生成阶段:最后,这些被替换了内容的、包含丰富上下文的节点被传递给LLM,用于生成最终的答案。
代码实现
下面通过 LlamaIndex 官网的示例,来演示如何实现句子窗口检索,并与常规的检索方法进行对比。该示例将加载一份PDF格式的IPCC气候报告,并就其中的专业问题进行提问。
核心代码如下:
import os
# 导入LlamaIndex中的节点解析器(用于拆分文档)
from llama_index.core.node_parser import SentenceWindowNodeParser, SentenceSplitter
# 导入核心组件:向量索引、文档读取器、配置对象
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
# 导入DeepSeek大语言模型(用于生成回答)
from llama_index.llms.deepseek import DeepSeek
# 导入HuggingFace的嵌入模型(用于将文本转为向量)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 导入元数据替换后处理器(用于句子窗口检索的后处理)
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
# 1. 配置模型(告诉程序用什么模型来处理文本和生成回答)
# 设置大语言模型:使用DeepSeek的聊天模型,温度参数控制回答随机性(0.1表示较稳定)
# api_key从环境变量获取,需要提前设置好
Settings.llm = DeepSeek(
model="deepseek-chat", # 模型名称
temperature=0.1, # 回答随机性(0-1之间,越小越固定)
api_key=os.getenv("DEEPSEEK_API_KEY") # 从环境变量获取API密钥
)
# 设置嵌入模型:将文本转为向量的模型,这里用BAAI的bge-small-en模型
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en")
# 2. 加载文档(读取要检索的PDF文件)
documents = SimpleDirectoryReader(
input_files=["../../data/C3/pdf/IPCC_AR6_WGII_Chapter03.pdf"] # PDF文件路径
).load_data() # 加载文件内容,得到文档对象列表
# 3. 创建节点与构建索引(把文档拆成小块并建立检索用的索引)
# 3.1 句子窗口索引(高级检索方式:保留句子上下文)
# 创建句子窗口节点解析器:按句子拆分,同时保留上下文窗口
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3, # 上下文窗口大小:每个句子保留前3句和后3句作为上下文
window_metadata_key="window", # 存储上下文的元数据键名
original_text_metadata_key="original_text" # 存储原始句子的元数据键名
)
# 用解析器把文档拆成带上下文的句子节点
sentence_nodes = node_parser.get_nodes_from_documents(documents)
# 基于句子节点构建向量索引(用于快速检索相似内容)
sentence_index = VectorStoreIndex(sentence_nodes)
# 3.2 常规分块索引 (基准方法:简单按固定长度拆分)
# 创建常规分块解析器:按512个token长度拆分文档
base_parser = SentenceSplitter(chunk_size=512)
# 用解析器把文档拆成固定长度的节点
base_nodes = base_parser.get_nodes_from_documents(documents)
# 基于常规节点构建向量索引
base_index = VectorStoreIndex(base_nodes)
# 4. 构建查询引擎(创建用于执行查询的工具)
# 句子窗口检索的查询引擎
sentence_query_engine = sentence_index.as_query_engine(
similarity_top_k=2, # 只取最相似的2个结果
# 添加后处理器:用元数据中的上下文窗口替换原始句子
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)
# 常规检索的查询引擎(作为对比)
base_query_engine = base_index.as_query_engine(similarity_top_k=2) # 只取最相似的2个结果
# 5. 执行查询并对比两种方法的结果
query = "What are the concerns surrounding the AMOC?" # 要查询的问题:"关于AMOC的担忧是什么?"
print(f"查询: {query}\n")
# 用句子窗口检索引擎查询
print("--- 句子窗口检索结果 ---")
window_response = sentence_query_engine.query(query)
print(f"回答: {window_response}\n")
# 用常规检索引擎查询
print("--- 常规检索结果 ---")
base_response = base_query_engine.query(query)
print(f"回答: {base_response}\n")
根据 LlamaIndex 的底层源码,SentenceWindowNodeParser 的核心逻辑位于 build_window_nodes_from_documents 方法中。其实现过程可以分解为以下几个关键步骤:
-
句子切分 (
sentence_splitter):解析器首先接收一个文档(Document),然后调用self.sentence_splitter(doc.text)方法。这个sentence_splitter是一个可配置的函数,默认为split_by_sentence_tokenizer,它负责将文档的全部文本精确地切分成一个句子列表(text_splits)。 -
创建基础节点 (
build_nodes_from_splits):切分出的text_splits列表被传递给build_nodes_from_splits工具函数。这个函数会为列表中的每一个句子都创建一个独立的TextNode。此时,每个TextNode的text属性就是这个句子的内容。 -
构建窗口并填充元数据 (主要循环):接下来,解析器会遍历所有新创建的
TextNode。对于位于第i个位置的节点,它会执行以下操作:- 定位窗口:通过列表切片
nodes[max(0, i - self.window_size) : min(i + self.window_size + 1, len(nodes))]来获取一个包含中心句子及其前后window_size(默认为3)个邻近节点的列表(window_nodes)。这个切片操作很巧妙地处理了文档开头和结尾的边界情况。 - 组合窗口文本:将
window_nodes列表中所有节点的text(即所有在窗口内的句子)用空格拼接成一个长字符串。 - 填充元数据:将上一步生成的长字符串(完整的上下文窗口)存入当前节点(第
i个节点)的元数据中,键为self.window_metadata_key(默认为"window")。同时,也会将节点自身的文本(原始句子)存入元数据,键为self.original_text_metadata_key(默认为"original_text")。
- 定位窗口:通过列表切片
-
设置元数据排除项:这是一个非常关键的细节。在填充完元数据后,代码会执行
node.excluded_embed_metadata_keys.extend(...)和node.excluded_llm_metadata_keys.extend(...)。这行代码的作用是告诉后续的嵌入模型和LLM,在处理这个节点时,应当忽略"window"和"original_text"这两个元数据字段。这确保了只有单个句子的纯净文本被用于生成向量嵌入,从而保证了检索的高精度。而"window"字段仅供后续的MetadataReplacementPostProcessor使用。
通过以上步骤,SentenceWindowNodeParser 最终返回一个 TextNode 列表。列表中的每个节点都代表一个独立的句子,其 text 属性用于精确检索,而其 metadata 中则“隐藏”了用于生成答案的丰富上下文窗口。
-
构建句子窗口索引:这一步利用了
SentenceWindowNodeParser。它将文档解析为以单个句子为单位的Node,同时将包含上下文的“窗口”文本(默认为前后各3个句子)存储在每个Node的元数据中。这一步是实现“为检索精确性而索引小块”思想的关键。 -
构建查询引擎与后处理:查询引擎的构建是实现“为生成质量而扩展上下文”的关键。
- 在创建
sentence_query_engine时,配置中加入了一个重要的后处理器MetadataReplacementPostProcessor。 - 它的作用是:当检索器根据用户查询找到最相关的节点(也就是单个句子)后,这个后处理器会立即介入。
- 它会从该节点的元数据中读取出预先存储的完整“窗口”文本,并用它替换掉节点中原来的单个句子内容。
- 这样,最终传递给大语言模型的就不再是孤立的句子,而是包含丰富上下文的完整文本段落,从而确保了生成答案的质量和连贯性。
- 在创建
我们向两个引擎提出的问题是:“关于大西洋经向翻转环流(AMOC),人们主要担忧什么?” (What are the concerns surrounding the AMOC?)。
代码输出如下:
查询: What are the concerns surrounding the AMOC?
--- 句子窗口检索结果 ---
回答: The Atlantic Meridional Overturning Circulation (AMOC) is projected to decline over the 21st century with high confidence, though there is low confidence in quantitative projections of this decline. Observational records since the mid-2000s are too short to determine the relative contributions of internal variability, natural forcing, and anthropogenic forcing to AMOC changes. Additionally, there is low confidence in reconstructed and modeled AMOC changes for the 20th century due to limited agreement in quantitative trends. While an abrupt collapse before 2100 is not expected, the decline could have significant implications for global climate patterns.
--- 常规检索结果 ---
回答: The concerns surrounding the Atlantic Meridional Overturning Circulation (AMOC) primarily involve its projected decline over the 21st century across all Shared Socioeconomic Pathway (SSP) scenarios. While an abrupt collapse before 2100 is not expected, there is high confidence in this decline, though quantitative projections remain uncertain. Observational records since the mid-2000s are too short to clearly distinguish the contributions of internal variability, natural forcing, and anthropogenic forcing to these changes. This uncertainty highlights the need for further research to better understand and predict AMOC behavior and its broader climate impacts.
从输出结果中可以观察到:
- 两个答案都抓住了核心:两个引擎都正确地识别出,对AMOC的主要担忧是其在21世纪预计的衰退。
- 句子窗口检索的答案更详尽、更连贯:句子窗口检索的回答不仅指出了衰退的趋势,还补充了关于“定量预测的置信度低”、“观测记录时间过短”、“20世纪重建和模拟的变化置信度低”等多个维度的细节。这使得答案的信息量更大,上下文更完整,更像一个综述。
- 常规检索的答案相对宽泛:常规检索的回答虽然正确,但内容相对概括,最后以“需要进一步研究”这样较为笼同的结论收尾。
这种差异正是句子窗口检索策略优势的体现。它通过“精确检索小文本块(单个句子),再扩展上下文(句子窗口)”的方式,为大语言模型提供了高度相关且信息丰富的上下文,从而生成了质量更高的答案。
结构化索引
随着知识库的规模不断扩大(例如,包含数百个PDF文件),传统的RAG方法(即对所有文本块进行top-k相似度搜索)会遇到瓶颈。当一个查询可能只与其中一两个文档相关时,在整个文档库中进行无差别的向量搜索,不仅效率低下,还容易被不相关的文本块干扰,导致检索结果不精确。
为了解决这个问题,一个有效的方法是利用结构化索引。其原理是在索引文本块的同时,为其附加结构化的元数据(Metadata)。这些元数据可以是任何有助于筛选和定位信息的标签,例如:
- 文件名
- 文档创建日期
- 章节标题
- 作者
- 任何自定义的分类标签
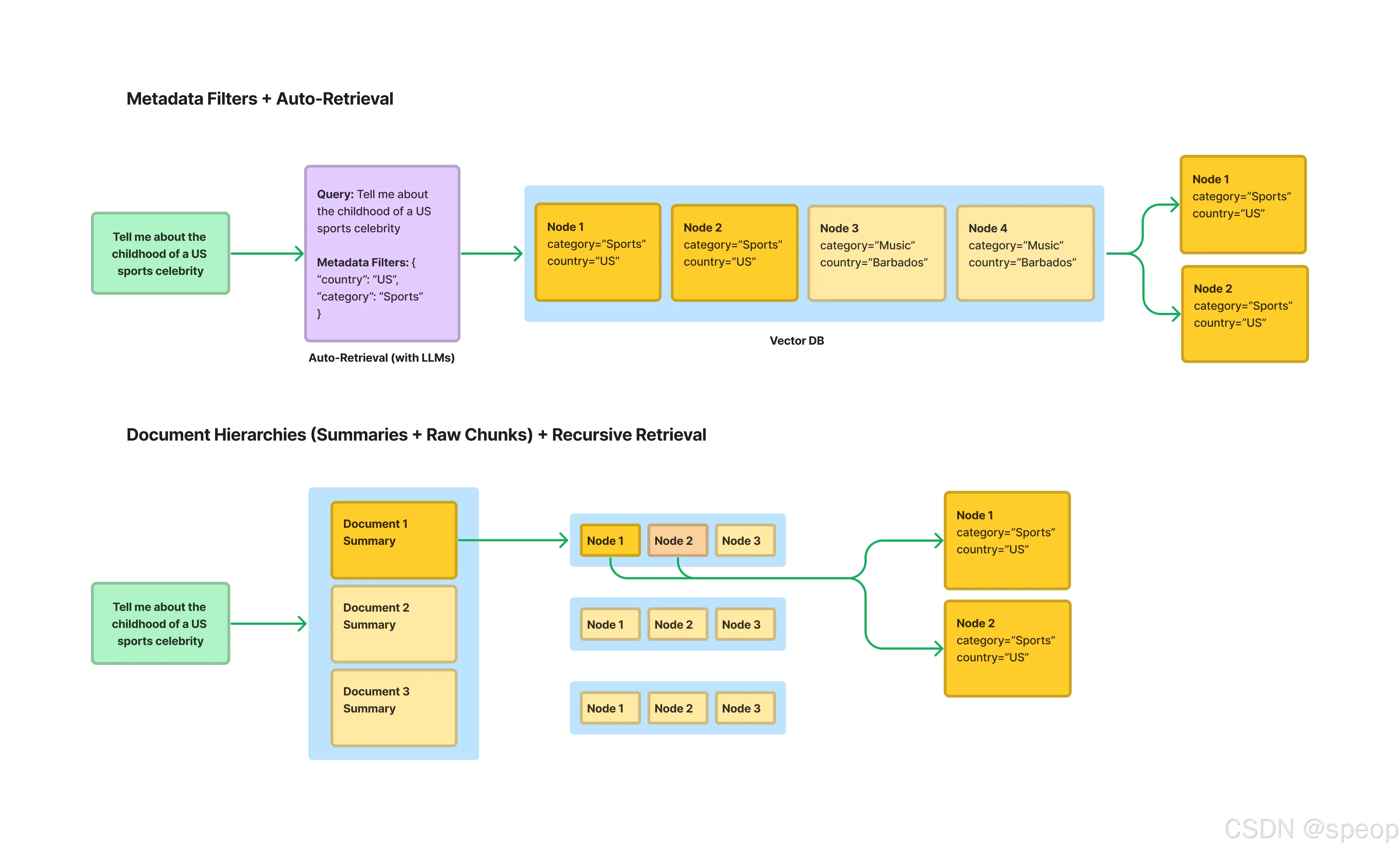
实际上,在第二章“文本分块”中介绍的基于文档结构的分块方法,就是实现结构化索引的一种前置步骤。例如,在使用MarkdownHeaderTextSplitter时,分块器会自动将Markdown文档的各级标题(如Header 1,Header 2等)提取并存入每个文本块的元数据中。这些标题信息就是非常有价值的结构化数据,可以直接用于后续的元数据过滤。
通过这种方式,可以在检索时实现“元数据过滤”和“向量搜索”的结合。例如,当用户查询“请总结一下2023年第二季度财报中关于AI的论述”时,系统可以:
- 元数据预过滤:首先通过元数据筛选,只在
document_type == '财报'、year == 2023且quarter == 'Q2'的文档子集中进行搜索。 - 向量搜索:然后,在经过滤的、范围更小的文本块集合中,执行针对查询“关于AI的论述”的向量相似度搜索。
这种“先过滤,再搜索”的策略,能够极大地缩小检索范围,显著提升大规模知识库场景下RAG应用的检索效率和准确性。LlamaIndex 提供了包括“自动检索”(Auto-Retrieval)在内的多种工具来支持这种结构化的检索范式。
下面是添加了 **逐行详细注释** 的代码版本,每个步骤都用大白话解释,小白也能轻松看懂每个代码块的作用:
```python
# 导入需要的工具(类似“准备好要用的工具箱”)
# pandas是处理Excel表格的工具,简称pd;后面是LlamaIndex的核心组件
import pandas as pd
from llama_index.core.query_engine import PandasQueryEngine
from llama_index.core.nodes import IndexNode
from llama_index.core import VectorStoreIndex, Settings
from llama_index.core.retrievers import RecursiveRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
# ------------------------------------------------------------------------------
# 1. 为Excel每个工作表(按年份分)创建“专属查询工具”和“身份名片”
# ------------------------------------------------------------------------------
# 1.1 先找到要处理的Excel文件(这里写的是文件路径,相当于“文件地址”)
excel_file = '../../data/C3/excel/movie.xlsx'
# 1.2 用pandas打开Excel文件,获取文件的“总览”(比如里面有哪些工作表)
xls = pd.ExcelFile(excel_file)
# 1.3 准备两个空容器,后续存数据
df_query_engines = {} # 字典:存“工作表名称→该表的查询工具”(类似“工作表通讯录”)
all_nodes = [] # 列表:存所有工作表的“身份名片”(方便后续快速找到对应表)
# 1.4 逐个处理Excel里的每个工作表(比如“年份_1994”“年份_1995”)
for sheet_name in xls.sheet_names:
# ① 读取当前工作表的内容,转成pandas的DataFrame格式(类似Python里的“电子表格”,能直接操作数据)
df = pd.read_excel(xls, sheet_name=sheet_name)
# ② 为当前工作表创建“专属查询工具”(能听懂自然语言问题,直接从表中找答案)
query_engine = PandasQueryEngine(
df=df, # 传入当前工作表的数据(告诉工具要查哪个表)
llm=Settings.llm, # 用提前配置好的AI模型(让工具能理解问题、生成答案)
verbose=True # 可选:运行时打印详细日志(方便看工具在做什么,调试用)
)
# ③ 为当前工作表创建“身份名片”(告诉系统“这个表是干嘛的”)
# 从工作表名称里提取年份(比如“年份_1994”→ 去掉“年份_”,得到“1994”)
year = sheet_name.replace('年份_', '')
# 写“名片内容”:明确说明这个表存的是哪年的电影数据,能回答什么问题
summary = f"这个表格包含了年份为 {year} 的电影信息,可以用来回答关于这一年电影的具体问题。"
# 创建“身份名片”节点:text是名片内容,index_id绑定工作表名称(确保能找到对应表)
node = IndexNode(text=summary, index_id=sheet_name)
all_nodes.append(node) # 把这张“名片”加入列表,统一管理
# ④ 把“工作表名称”和它的“查询工具”存入字典(后续按名称就能找到对应的工具)
df_query_engines[sheet_name] = query_engine
# ------------------------------------------------------------------------------
# 2. 创建“顶层索引”(给所有工作表的“身份名片”建一个“快速查找库”)
# ------------------------------------------------------------------------------
# 作用:把所有“名片”转成AI能快速对比的“数字标签”,后续用户提问时,能秒匹配到对应工作表
vector_index = VectorStoreIndex(all_nodes)
# ------------------------------------------------------------------------------
# 3. 创建“递归检索器”(搭建“先找表、再查数据”的核心流程)
# ------------------------------------------------------------------------------
# 3.1 把顶层索引转成“向量检索器”:负责“第一步——找对应的工作表”
# similarity_top_k=1:只找和问题最像的1个工作表(比如问1994年,就只找“年份_1994”)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# 3.2 创建递归检索器:串联“找表”和“查数据”两步
recursive_retriever = RecursiveRetriever(
"vector", # 检索的起点:从“向量检索器”开始(先找工作表)
retriever_dict={"vector": vector_retriever}, # 存“找目标”的工具(这里只有找表的工具)
query_engine_dict=df_query_engines, # 存所有工作表的查询工具(找到表后用它查数据)
verbose=True # 可选:打印检索日志(看系统先找了哪个表,再查了什么)
)
# ------------------------------------------------------------------------------
# 4. 创建“最终查询工具”(给用户提供一个简单的“提问入口”)
# ------------------------------------------------------------------------------
# 作用:用户不用管“找表”“查数据”的细节,只需输入问题,就能自动跑完全流程
query_engine = RetrieverQueryEngine.from_args(recursive_retriever)
# ------------------------------------------------------------------------------
# 5. 实际提问,测试系统是否能用
# ------------------------------------------------------------------------------
# 要查询的问题:“1994年评分人数最多的电影是哪一部?”
query = "1994年评分人数最多的电影是哪一部?"
print(f"查询: {query}") # 打印问题,方便看自己问了什么
# 调用查询工具,获取答案(系统会自动找表、查数据)
response = query_engine.query(query)
# 打印最终答案
print(f"回答: {response}")
额外补充:核心概念大白话解释
-
DataFrame:可以理解成“Python里的电子表格”,能直接看到行、列(比如电影名、评分、评分人数),方便操作数据。
-
PandasQueryEngine:每个工作表的“专属查询员”——你问它“1994年评分最高的电影”,它能直接在对应的Excel表里算出来,不用你手动筛选。
-
IndexNode(身份名片):给每个工作表写的“简介”,比如“我是1994年的电影表,能回答1994年的电影问题”,方便系统快速识别该找哪个表。
-
递归检索器:相当于“流程管家”——先看问题(比如问1994年),找到1994年的表,再让1994年的“查询员”去表里找答案,一步到位。
-
创建 PandasQueryEngine:遍历 Excel 中的每个工作表,为每个工作表(即一个独立的 DataFrame)都实例化一个
PandasQueryEngine。其强大之处在于,它能将关于表格的自然语言问题(如“评分人数最多的是哪个”)转换成实际的 Pandas 代码(如df.sort_values('评分人数').iloc[-1])来执行。 -
创建摘要节点 (
IndexNode):对每个工作表,都创建一个IndexNode,其内容是关于这个表格的一段摘要文本。这个节点将作为顶层检索的“指针”。 -
构建顶层索引:使用所有创建的
IndexNode构建一个VectorStoreIndex。这个索引不包含任何表格的详细数据,只包含指向各个表格的“指针”信息。 -
创建
RecursiveRetriever:这是实现递归检索的核心。将其配置为:retriever_dict: 指定顶层的检索器,即在摘要节点中进行检索的vector_retriever。query_engine_dict: 提供一个从节点 ID(即工作表名称)到其对应查询引擎的映射。当顶层检索器匹配到某个摘要节点后,递归检索器就知道该调用哪个PandasQueryEngine来处理后续查询。
运行结果:
查询: 1994年评分人数最少的电影是哪一部?
> Retrieving with query id None: 1994年评分人数最少的电影是哪一部?
> Retrieved node with id, entering: 年份_1994
> Retrieving with query id 年份_1994: 1994年评分人数最少的电影是哪一部?
> Pandas Instructions:
df[df[‘年份’] == 1994].nsmallest(1, ‘评分人数’)[‘电影名称’].iloc[0]
> Pandas Output: 燃情岁月
回答: 燃情岁月
从输出中可以清晰地看到递归检索的完整流程:
- 顶层路由:
Retrieving with query id None,系统首先在顶层的摘要索引中检索,根据问题“1994年…”匹配到了摘要节点年份_1994。 - 进入子层:
Retrieved node with id, entering: 年份_1994,系统决定进入与“年份_1994”这个工作表关联的查询引擎。 - 子层查询:
Retrieving with query id 年份_1994,PandasQueryEngine接管查询,并将问题发送给 LLM,让其生成 Pandas 代码。 - 代码生成与执行:LLM 生成了
df[df['年份'] == 1994].nsmallest(1, '评分人数')['电影名称'].iloc[0],引擎执行后得到输出燃情岁月。
2.2 另一种实现方式
鉴于 PandasQueryEngine 的安全风险,还可以采用一种更安全的方式来实现类似的多表格查询,思路是将路由和检索彻底分离。
这种改进方法的具体步骤如下:
-
创建两个独立的向量索引:
- 摘要索引(用于路由):为每个Excel工作表(例如,“1994年电影数据”)创建一个非常简短的摘要性
Document,例如:“此文档包含1994年的电影信息”。然后,用所有这些摘要文档构建一个轻量级的向量索引。这个索引的唯一目的就是充当“路由器”。 - 内容索引(用于问答):将每个工作表的实际数据(例如,整个表格)转换为一个大的文本
Document,并为其附加一个关键的元数据标签,如{"sheet_name": "年份_1994"}。然后,用所有这些包含真实内容的文档构建一个向量索引。
- 摘要索引(用于路由):为每个Excel工作表(例如,“1994年电影数据”)创建一个非常简短的摘要性
-
执行两步查询:
- 第一步:路由。当用户提问(例如,“1994年评分人数最少的电影是哪一部?”)时,首先在“摘要索引”中进行检索。由于问题中的“1994年”与“此文档包含1994年的电影信息”这个摘要高度相关,检索器会快速返回其对应的元数据,告诉系统目标是
年份_1994这个工作表。 - 第二步:检索。拿到
年份_1994这个目标后,系统会在“内容索引”中进行检索,但这次会附加一个元数据过滤器(MetadataFilter),强制要求只在sheet_name == "年份_1994"的文档中进行搜索。这样,LLM就能在正确的、经过筛选的数据范围内找到问题的答案。
- 第一步:路由。当用户提问(例如,“1994年评分人数最少的电影是哪一部?”)时,首先在“摘要索引”中进行检索。由于问题中的“1994年”与“此文档包含1994年的电影信息”这个摘要高度相关,检索器会快速返回其对应的元数据,告诉系统目标是
通过这种“先路由,后用元数据过滤检索”的方式,既实现了跨多个数据源的查询能力,又避免了执行代码的安全隐患。LlamaIndex 官方也提供了类似的结构化分层检索可以参考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)