DeepSeek-V3 架构解析
随着 GPT-4、Gemini 等闭源模型不断突破性能天花板,开源社区也在持续迎头赶上。2024 年底,DeepSeek 团队发布了他们的旗舰大模型 —— DeepSeek-V3 Technical Report,提出一系列突破性优化:包括多 token 预测(MTP)目标、无辅助损失的负载均衡、FP8 训练等。
📚 DeepSeek系列文章
随着 GPT-4、Gemini 等闭源模型不断突破性能天花板,开源社区也在持续迎头赶上。2024 年底,DeepSeek 团队发布了他们的旗舰大模型 —— DeepSeek-V3 Technical Report,提出一系列突破性优化:包括多 token 预测(MTP)目标、无辅助损失的负载均衡、FP8 训练等。
这不是一份单纯扩大模型尺寸的报告,而是对「大规模训练稳定性、计算成本控制、推理表现优化」的深度工程回答。
建议你带着以下三个问题阅读本文,一起探索 DeepSeek-V3 的架构奥秘:
- DeepSeek-V3 为什么在每个 token 只激活 37B 参数,却能保持 671B 参数的表达力?
- 多 token 预测(MTP)训练目标如何降低计算成本?
- 为什么 FP8 精度和均衡负载策略是训练超大模型的关键?
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、参数设计:全量 671B,每 token 激活仅 37B
DeepSeek-V3 是目前开源领域最大的 MoE 模型之一,参数配置如下:
| 模型 | 总参数量 | 激活参数 | MoE 层数 | 每层专家数 | 路由策略 |
|---|---|---|---|---|---|
| DeepSeek-V3 | 671B | 37B/token | 96 | 256 | Top-2(无辅助损失) |
- 架构采用 Mixture-of-Experts(MoE),每个 MoE 层仅激活 2 个专家;
- 因此推理与训练时,只需使用少量激活参数即可达成全模型表达力;
- 进一步结合 FP8 训练,显著节约显存与计算资源。
二、关键创新点一:多 token 预测(MTP)
传统语言模型每次仅预测下一个 token,效率较低。而 DeepSeek-V3 提出了更激进的方案 —— MTP(Multi-token Prediction):

原理
- 将多个 token 的预测目标压缩为一次前向传播;
- 每次预测最多 16 个 token;
- 降低训练中每个 token 所需的 FLOPs,提升整体训练效率。
效果
- 在训练吞吐量几乎不变的前提下,有效减少梯度同步和缓存开销;
- 特别适用于超大 batch、长序列训练,提升 GPU 利用率;
- 在代码任务、推理任务上更具优势。
三、关键创新点二:无辅助损失的负载均衡策略
在 MoE 模型中,路由器决定每个 token 使用哪些专家。然而:
- 常规做法需加入辅助损失(auxiliary loss)来平衡负载;
- 这引入额外损耗,还可能干扰主任务收敛。
DeepSeek-V3 的做法:
- 完全移除 auxiliary loss;
- 改为通过更先进的 top-k soft routing + capacity-aware token allocation 实现负载均衡;
实验结果证明,专家利用率更高,负载分布更加均匀,训练也更稳定。
四、高效训练利器:FP8 混合精度训练
随着模型规模不断扩张,FP8 精度(8-bit float) 成为解决训练资源瓶颈的重要手段。
DeepSeek-V3 采用 NVIDIA 的 Transformer Engine 训练框架,配合 FP8 训练策略:
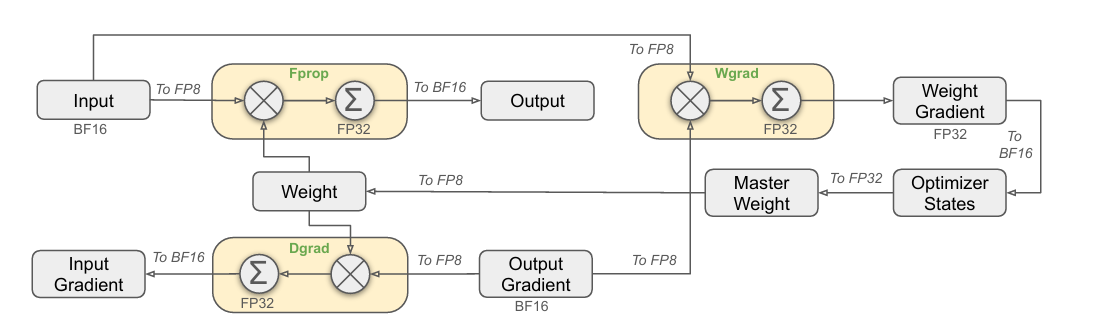
| 精度 | 模块覆盖 | 说明 |
|---|---|---|
| FP8 | Attention、MLP、MoE | 大幅减少显存、加速前向与反向传播 |
| BF16 | 参数更新、权重保持 | 保留关键精度,保证数值稳定 |
| FP32 | 梯度累积、全局标量 | 用于高精度的收敛控制与监控 |
实际收益
- 模型在相同 GPU 数量下训练时间减少 30%;

- 显存消耗更低,使得更大 batch、更长序列成为可能;
- 在 3T token 上训练即可获得超越 GPT-3.5 的性能。
五、基准测试:性能全面超越 Mixtral 与 GPT-3
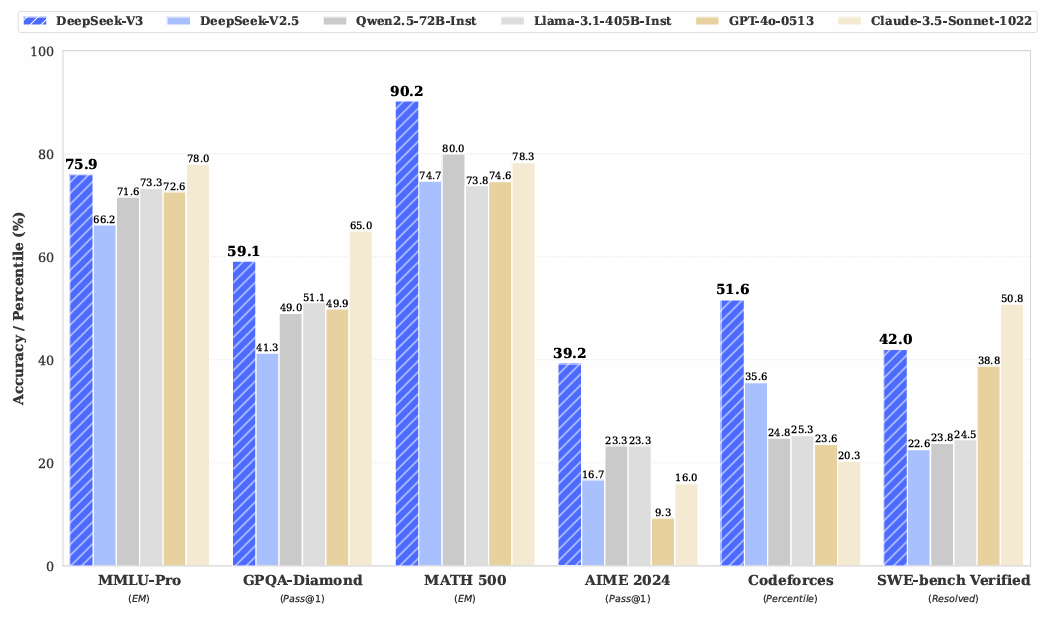
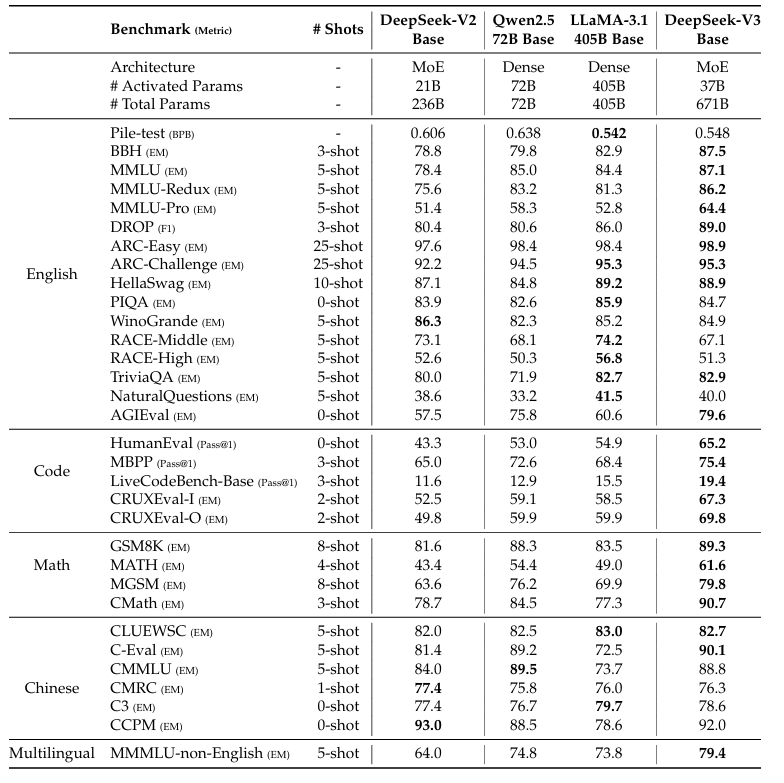
即便不使用指令微调,DeepSeek-V3 的预训练能力已在多项任务上领先,特别是在推理、数学、代码方面优势明显。
📌 结语
DeepSeek-V3 是一个真正意义上的“旗舰级 MoE 模型”,其设计不仅关注模型性能,更体现了对大模型工程部署、训练资源、推理效率的全方位思考。
从架构优化、训练目标、精度控制到专家调度策略,DeepSeek-V3 展示了超大规模开源模型的发展新范式 —— 不仅更强,还要更稳、更省、更实用。
最后我们回答一下文章开头提出的三个问题:
1. 为什么 DeepSeek-V3 在每个 token 只激活 37B 参数,却能保持 671B 参数的表达力?
因为采用 MoE 架构 + Top-2 路由策略,多个 token 共享专家组,每次只激活 2 个专家,大幅减少激活参数量的同时保留全模型表达力。
2. 多 token 预测(MTP)训练目标如何降低计算成本?
通过每轮前向预测多个 token,减少总训练步骤和 token-level 计算冗余,提高训练吞吐量和硬件效率。
3. 为什么 FP8 精度和均衡负载策略是训练超大模型的关键?
FP8 显著减少训练资源消耗,负载均衡策略则解决了专家路由不稳定、训练震荡的问题,两者共同提升超大模型的可扩展性与收敛稳定性。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!
📚 推荐阅读

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)