51c大模型~合集175
随着互联网技术的发展,信息搜索变得日益重要;高效的检索、评估、筛选和管理信息资源已成为必备技能。传统搜索引擎往往难以准确把握复杂的人类意图,因此获取最终答案常常耗时费力。近年来,大型语言模型(LLMs)在语言理解与生成方面表现突出,但在获取外部知识和最新信息上仍存在局限。
自己的原文哦~ https://blog.51cto.com/whaosoft/14152349
#从RAG到Deep Research全景综述
一文看懂AI搜索与Web智能体
一文带你了解Deep Research和Web Agent背后的原理。
1. 摘要
随着互联网技术的发展,信息搜索变得日益重要;高效的检索、评估、筛选和管理信息资源已成为必备技能。传统搜索引擎往往难以准确把握复杂的人类意图,因此获取最终答案常常耗时费力。近年来,大型语言模型(LLMs)在语言理解与生成方面表现突出,但在获取外部知识和最新信息上仍存在局限。AI搜索和Web智能体通过将 LLMs 能力融入传统互联网搜索流程,能够更好地应对复杂用户问题,显著提升信息浏览与检索的效率与准确性。
如图1所示,本文对近些年AI搜索相关80余篇工作进行了深入回顾。重点涵盖(1)基于文本的 AI 搜索、(2)Web智能体、(3)多模态 AI 搜索与Web智能体、(4)基准评测、(5)AI搜索软件与产品。
详细可参考论文链接:
https://www.preprints.org/frontend/manuscript/79453d62cbbfce9ac42239071098a3d9/download_pub

图1. 近年来AI搜索和Web智能体相关工作概览
2. 文本AI搜索
基于文本的AI搜索代表了信息检索系统的重大变革,它从传统搜索引擎发展到融合检索增强生成(RAG)工作流和深度搜索能力的复杂方法。这种技术的核心在于将LLMs的强大语言理解和生成能力与搜索引擎的海量信息获取能力相结合,以解决复杂的现实世界信息检索挑战。一种高效且经典的workflow如图2所示,包含有几个重要模块:意图模型,问题改写模型,搜索引擎,网页重排模型,总结模型。

图2. 基于文本的AI搜索经典工作流图
检索增强生成(RAG)工作流
朴素的AI搜索采用类似RAG的思路,如图3所示,本质上是检索(Retrieval)全网知识库来增强(Augment)大模型的生成(Generate)准确答案的能力。传统的RAG方法通过预定义的工作流程运行,主要包含四种范式。(1)顺序RAG采用线性的"检索-然后-生成"工作流,首先获取相关文档,然后基于这些文档生成最终回答。(2)分支RAG通过多个并行管道处理输入查询,每个管道都可能涉及自己的检索和生成步骤,然后合并输出以获得全面的答案。(3)条件RAG引入决策模块来自适应地确定给定查询是否需要检索,提高了系统的灵活性和鲁棒性。(3)循环RAG具有迭代和交互式的检索-生成循环,能够进行深度推理并处理复杂查询。

图3. 基于RAG的AI搜索流程图
端到端深度搜索方法
与传统RAG工作流不同,深度搜索方法通过在端到端连贯推理过程中调用搜索引擎来获取外部知识,以解决复杂的信息检索问题。这种方法的核心优势在于不需要预定义的工作流程,模型可以在推理过程中自主决定何时调用与搜索相关的工具,使其更加灵活和有效。深度搜索方法能够让模型在遇到不确定信息时自主检索外部知识,有效解决了长链式思维推理中的知识空白问题,在数学、科学、编程和多跳问答任务中都表现出显著的性能提升。
(1)无需训练的框架设计
如图4所示,无需训练的方法通过精心设计的指令来增强推理模型的搜索能力,使模型能够意识到其任务性质以及如何正确使用搜索工具。Search-o1等代表性工作提出了智能体RAG机制,允许推理模型在主要推理过程中遇到不确定信息时自主检索外部知识。这些方法还引入了文档深度推理过程,在每次搜索调用后深度分析检索到的文档内容,将简洁有用的信息返回到主推理链中。后续的WebThinker、WebDancer、ManuSearch等工作进一步发展了这一范式,通常引入对收集的网页URL的浏览功能,以实现深度网络探索。此外,一些工作如WebThinker还探索了在收集信息的同时自主撰写研究报告,为用户提供更全面和前沿的知识。

图4. 无需训练的端到端基于深度搜索的AI搜索流程图
(2)基于后训练的方法
如图5所示,基于训练的方法设计各种训练策略来激励或增强LLM在推理过程中的搜索能力,这些策略涵盖预训练、监督微调(SFT)和强化学习(RL)等多个层面。在预训练阶段,MaskSearch框架引入检索增强掩码预测任务,训练模型使用搜索工具来填充被掩码的文本。在监督微调方面,多种方法专注于合成包含搜索动作的长链式思维数据,如CoRAG通过拒绝采样自动生成检索链,ReaRAG通过策略蒸馏构建专门的数据集。强化学习训练最近获得了显著关注,包括基于直接偏好优化(DPO)的方法和基于PPO、GRPO等的训练策略。这些方法通过设计先进的奖励函数、结合结果和过程奖励、提高训练效率等方式,不断优化模型对搜索工具的使用效率和准确性,使其能够更有效地处理复杂的信息检索和推理任务。

图5. 有后训练的端到端基于深度搜索的AI搜索流程图
3. Web Agent
Agent是一种自主的智能体,能够响应输入、执行和上下文相关的动作,其核心目标是模拟人类的决策过程。而Web Agent是Agent在垂直领域的应用。不同于AI搜索,Web智能体模拟人类浏览网页的过程,在当前网络环境上获取信息决定后续操作。
基于提示词的Web Agent
如图6,基于提示词的Web Agent这种方法不需要对模型的参数进行调整,所以方便快捷,所需的资源也较少。这类Web Agent致力于精心设计的提示词(Prompt)工程,将输入的信息通过筛选、拼接、结构化等方式进行处理,形成特定格式的Prompt,便于通用LLM进行理解以获取结果。例如WebVoyager对网页的截图和网页的结构化数据结合,形成Prompt输入GPT-4V进行处理,输出下一步操作,直至获取最终答案。

图6. 基于提示词的Web智能体
基于后训练的Web Agent
鉴于Web Agent实际使用时网络环境和网页浏览任务的复杂性,如图7所示,Web Agent需要通过后训练如SFT或RL来微调模型网页知识,从而返回下一步的决策。WebAgent-R1就是利用强化学习,以DeepSeek-R1为基础模型,通过改进的GRPO构建纯端到端Web Agent。另外一种常用方法就是SFT,比如Falcon自主构建图形用户界面(GUI)数据集,再通过微调使LLM可以更好地处理GUI信息,增强Web Agent浏览GUI的能力。

图7. 基于后训练的Web智能体
4. 多模态AI搜索与Web智能体
当用户的问题或答案中包含图片时,就需要多模态 AI 搜索;另外互联网上的信息往往以图文交织的形式呈现。如图8所示,你在博物馆拍下一件古董的照片,想要了解它背后的历史背景或相关人物,这就需要多模态AI搜索。近来,多模态大语言模型(MLLMs)在视觉感知,理解和推理中应用广泛。经典的模型如GPT-4V,LLaVA等在学术界和工业界应用广泛。

图8. 多模态AI搜索流程示例图
多模态AI搜索的代表工作包括MMSearch和MMSearch-R1。如图9所示,MMSearch将AI搜索流程中三个阶段requery,rerank,summarization里的LLM都替换成了MLLM。MMSearch-R1采用强化学习和多轮搜索的方式来进一步提升基于搜索的图片问答能力。

图9. 两种多模态AI搜索方法
此外还有多模态Web Agent,这种Web Agent模拟人类视觉通过辅助输入网页截图实现拟人化操作,显著提升在复杂网络环境中的任务完成效率。代表作有SEEACT,WebVoygar,WebWatcher。例如如下任务:在xx汽车租赁网站上“以最低的价格租一辆轻型卡车”。多模态Web智能体利用类似GPT-4v的MLLM来视觉感知网页图片中不同类型的汽车,生成思维链,输出可执行的网页操作。
5. 评测集(1)文本AI搜索评测集
对AI搜索模型进行科学评估,是推动其技术发展的关键一环。为此,研究者们构建了一系列评测基准来衡量模型在真实场景下的检索与推理能力。
传统评测基准及其局限性 传统的评测基准,如Natural Questions (NQ)、HotpotQA、FEVER等,主要用于评估模型在多跳推理、事实核验等任务上的表现,其数据源通常是维基百科等结构化知识库。然而,随着大模型能力的飞速提升,这些传统评测集已逐渐“饱和”,顶尖模型在这些任务上接近满分,难以有效地区分出模型间的真实能力差距。
现代浏览基准的挑战 为了更真实地反映现实世界的信息检索挑战,研究者们开发了新一代的现代浏览基准,如BrowseComp、BrowseComp-ZH和Mind2Web 2。这些评测集的核心特点是高度复杂且贴近真实应用场景。它们要求模型不再是简单地进行单次查询,而是像人类一样,在复杂的互联网环境中进行持续的导航、推理和信息整合,解决需要多步骤才能找到答案的难题。
如图10提到的BrowseComp-ZH中的一个问题就极具代表性。要解决此问题,AI模型必须具备以下能力:
问题分解:将一个复杂问题拆解为三个关于不同角色的独立信息线索。
多轮搜索:针对每个线索执行独立的网络搜索,如“1993年出道的女演员”、“丈夫是湖州人的女演员”等。
信息整合与推理:将多轮搜索得到的分散信息进行交叉验证和关联,最终推理出所有线索共同指向的唯一答案。
这类高难度的评测任务,能够更精准地检验AI搜索模型在开放环境下的真实能力,从而推动技术向着更智能、更实用的方向演进。

图10. AI搜索评测集
(2)Web智能体评测集
Web Agent 基准测试模拟了现实世界网络环境中的交互式任务,评估Agent在导航、操作和推理方面的能力。主要分为两类,第一类是通用评测基准,评估Web Agent在多样网站完成任务的能力,如Mind2Web和WebArena。Mind2Web部分网站和任务如图11所示。第二类是针对特定网站和任务的专用评测基准,如DeepShop和SafeArena,分别在电子商务和恶意浏览两个方面对Web Agent进行评估。

图11. Mind2Web评测集
(3)多模态AI搜索评测集
对于多模态AI搜索评测集,MMsearch评估了MLLM在AI搜索流程中的三个任务的能力。LIVEVQA是图片知识问答,如图12所示,对于一些复杂或者实时问题需要借助互联网搜索才能回答准确。VisualWebArena是评估多模态Web智能体的评测集。

图12. LIVEVQA评测集
6. AI搜索软件与产品
AI搜索产品已迅速分化为全球通用型产品、垂直领域产品和集成化助手三大类别。下文将分别介绍这三个类别的核心产品。
(1)全球通用型AI搜索产品
作为深度研究的先驱,OpenAI的ChatGPT DeepResearch。Perplexity 的DeepResearch使用最为广泛且效果优异,可以追踪热点话题,特别适用于学术调研,文献综述与技术写作。其他广泛使用的软件和产品还有:Google的Gemini DeepResearch,字节豆包,腾讯元宝等。豆包和元宝通过融入自家生态内容为用户提供更为丰富的内容。我们还调研了其他产品,有些是学术研究,包括:Nano AI,Kimi,DeepSeek,夸克,MiroMind ODR和Manus。
(2)垂直领域AI搜索产品
MediSearch提供循证医学解答,如药物相互作用、治疗方案,大量医疗从业者将其用于临床决策支持。Devv.ai作为代码专用搜索引擎,提供实时调试代码片段与GitHub集成,该工具支持中文查询但仅限于编程场景。Consensus覆盖2亿余篇科学论文,运用自然语言处理技术提取研究假设与方法论,在文献综述环节可节省50%时间。
(3)集成化AI搜索助手
WallesAI作为浏览器侧边栏助手,支持解析PDF、视频及网页内容,实现跨文档问答与内容导出功能。必应聊天深度集成Edge浏览器生态,通过实时网络索引与来源标注提供附带引文的答案,构建了搜索-浏览一体化体验。
#全球AI百强榜发布
ChatGPT稳坐第一,DeepSeek第三,前50有22个来自中国
a16z最新发布「全球Top100消费级GenAI应用榜单」,AI竞争格局逐渐稳定,中国力量全面崛起,DeepSeek、豆包、夸克等多款产品跻身前十。ChatGPT依旧领跑,谷歌Gemini紧随其后,Grok高速逆袭。整体来看,全球AI正进入多极化竞争的新阶段。
就在刚刚,a16z最新一期的「Top 100消费级GenAI应用榜单」出炉!
本期榜单传递出一个最核心信息:AI产品竞争的生态格局正日趋稳定!
网页排行前50
移动应用排行前50
不论是你常用的DeepSeek、豆包、夸克,还是一直领先的ChatGPT和Gemini,或者是新进榜单Lovable等,这场AI产品的「百团大战」依然在继续!
中国开始影响世界
首先来看网页排行榜,本次榜单中,5家中国公司跻身全球前20。
分别是DeepSeek全球排名第三、夸克Quark全球排名第九、豆包Doubao排名全球第十二、月之暗面Kimi排名全球第十七、通义千问Qwen3全球排名第二十。
此外,可灵KlingAI上榜全球排名第三十三,海螺AI排名45。
在移动应用榜单中,排名有较大变化。
豆包拿下全球第四、百度AI搜索全球第七、DeepSeek全球第八、美图全球第九,以及夸克上榜第四十七。
以上都是我们熟悉的产品,设有中文网站,a16z统计这些产品超过75%的流量来自国内。
其中,值得一提的是,国内的视频模型比海外的产品更具优势——因为中国有更多研究人员专注于视频领域。
照片和视频类别的集中度尤其高,仅美图一家就贡献了五个席位:Photo&VideoEditor、BeautyPlus、BeautyCam、Wink和Airbrush。
字节跳动也是一个重要参与者,旗下产品包括豆包和Cici(通用大语言模型助手)、Gauth(教育科技)和Hypic(照片/视频编辑)。

谷歌携四款产品强势入榜
这是首次对谷歌几款应用单独的流量进行排名并收录。
该公司的通用大语言模型助手Gemini位居第二,仅次于ChatGPT,其网站访问量约为ChatGPT的12%。
谷歌还有哪些产品上榜?
面向开发者的AI Studio首次亮相即跻身前十。
该网站提供了一个沙盒环境,开发者可在此基础上使用Gemini模型进行构建,包括多模态模型。
紧随其后的是排名第13的NotebookLM。
该产品在作为Google Labs的一部分推出后,现已作为独立网站运营。
NotebookLM在近一年前首次爆红,此后稳步增长,仅在夏季有轻微下滑(可能源于学术用户的暂时性流失)。
作为谷歌面向消费者的AI实验平台,Google Labs排名第39。
Labs平台承载了Flow(用户可在此试用视频模型Veo3)以及其他多款应用。
在2025年5月Veo3发布后,Google Labs的流量飙升超过13%,创下过去一年的最大单月增幅。
在移动端,Gemini同样排名第二,紧随ChatGPT,但差距要小得多,其月度活跃用户(MAU)已接近ChatGPT的一半。
Gemini在安卓设备上表现尤为强劲,其近90%的MAU来自安卓平台,相比之下,ChatGPT的安卓用户占比为60%。
ChatGPT稳坐第一
Grok紧追
在通用大语言模型助手的激烈竞争中,ChatGPT仍保持领先,但谷歌、Grok和Meta正在缩小差距。
Grok在网站榜上排名第4,移动榜上排名第23。
该公司在移动端的跃升尤为惊人,从2024年底无应用的「冷启动」状态,发展到如今超过2000万的月活用户。
2025年7月,Grok的移动端用量迎来巨大增长,随着7月9日新模型Grok4(具备更强的推理能力、实时搜索和工具集成)的发布,用量攀升了近40%。
紧接着,7月14日又推出了AI伴侣头像功能。
发布初期,动漫头像Ani(包含NSFW选项)尤为火爆。
相比之下,Meta的努力至今增长较为平缓。其通用助手MetaAI在网站榜上排名第46,未能进入移动榜单。
MetaAI于2025年5月底推出,但增长速度远不及Grok,尤其是在2025年6月发生了一次「公开动态」事件(用户发现自己的部分帖子被公开发布)之后。
在通用大语言模型助手的其他战线,Claude在移动端均已明显增长放缓。
Perplexity则与Grok一道,持续展现强劲的增长势头。
在网站端,Perplexity和Claude持续增长。
在网站榜单中,有11个新晋应用的上榜是由流量增长驱动的。
相比之下,在a16z 2025年3月的榜单中,新晋者达17个。
移动应用榜单的新面孔则明显更多(14个),这得益于各大应用商店对「山寨ChatGPT」应用的打击(也就是所谓套壳),为更多原创移动应用腾出了发展空间。
这是a16z第二次发布「准上榜名单」(BrinkList):即刚刚与榜单失之交臂的10家公司(5家网站,5家移动应用)。
在上期网站榜的「准上榜名单」中,Lovable成功闯入百强,并一举跃升至第22位,令人瞩目!
这一飞跃也凸显了AI驱动的应用生成这一赛道的普遍崛起。
在上期移动应用榜的「准上榜名单」中,PolyBuzz和Pixverse这两家公司成功进入核心榜单。
氛围编程强势崛起
在a16z 2025年3月的榜单中,「氛围编程」(vibe coding)的概念才刚刚萌芽——当时网站榜上只有Bolt一家。
如今,Bolt已进入「准上榜名单」,而Lovable和Replit则双双首次登上主榜单。
虽然「氛围编程」的使用看似短暂,但早期数据显示其用户粘性很强——或者说,至少有足够多的用户留存下来并逐渐扩大使用范围。
来自信用卡数据提供商ConsumerEdge的数据显示,某顶级「氛围编程」平台的美国用户群体,在注册数月后,其收入留存率超过了100%。
这意味着,即便算上流失的用户,这些用户群体的月度总支出仍在持续增长。
这些平台也在为其他AI产品引流。通过Replit和Lovable构建并发布的网站(未使用自定义域名),其流量分别归于replit.app和lovable.app之下。
这两个域名本身都有着可观的流量(lovable.app的流量足以排进榜单前50),但仍低于其面向开发者的主站。
作为「氛围编程技术栈」的一部分,相关产品的流量也随之激增,因为开发者们需要用它们来部署项目。
这些产品不符合上榜资格(因其自身并非AI原生公司)——最典型的例子就是数据库提供商Supabase。
Supabase的流量增长与核心「氛围编程」平台的崛起几乎亦步亦趋,在过去九个月里的增速远超往年。
14家「全明星」从未缺席
在a16z发布的五期网站Top50榜单中,有14家公司从未缺席——a16z称之为「全明星」!!
这些公司构成了消费者AI行为的真实缩影:
通用助手(ChatGPT、Perplexity、Poe)
AI伴侣(CharacterAI)
图像生成(Midjourney、Leonardo)
图像与视频编辑(Veed、Cutout)
语音生成(ElevenLabs)
生产力工具(Photoroom、Gamma、Quillbot)
以及模型托管(Civitai、HuggingFace)
在a16z近两年前发布的第一份榜单中,a16z曾好奇:所有顶级的消费级AI公司最终都会训练自己的基础模型吗?
现在,a16z有了答案——在这14家「全明星」中:
五家拥有自研模型
七家使用来自其他公司的API或开源模型
还有两家是模型聚合平台。
有趣的是,尽管榜单的全球化程度日益提高,但这十四位「常青树」仅来自五个国家:美国、英国(ElevenLabs、Veed)、澳大利亚(Leonardo)、中国(CutoutPro)和法国(Photoroom、HuggingFace)。
此外,除了两家公司外,其余均已获得风险投资——Midjourney以其自力更生而闻名,而CutoutPro也尚未进行过融资。
若不计入首期榜单,还有另外五家公司也能入选「常青树」之列——这反映了它们近期的强劲势头。
这些公司同样代表了多样的AI消费级应用,包括:
- Claude和DeepAI(通用助手)
- JanitorAI(AI伴侣)
- Pixelcut(图像编辑)
- Suno(音乐生成)
a16z统计方法说明
榜单分别对排名前50的AI原生网站产品(依据Similarweb的月度独立访问量)和排名前50的AI原生移动应用(依据SensorTower的月度活跃用户)进行排名。
对于那些增加了重要生成式AI功能但并非AI原生的产品,如Canva和Notion,则不包含在内。
参考资料:
https://a16z.com/100-gen-ai-apps-5/
https://x.com/omooretweets/status/1960726780681376028
.
#谷歌Nano Banana全网刷屏
起底背后团队
引入「交错生成」功能,增强模型在世界知识和创意解释方面的能力。
香蕉也能变礼服?Google 真的做到了!
在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。
它不仅能快速生成高质量图像,还能在多轮对话中保持场景一致,带来了前所未有的互动体验,堪称 SOTA 级图像生成革命。
背后的研发和产品团队,也首次亮相。
起底背后团队
Logan Kilpatrick
Logan Kilpatrick 是 Google DeepMind 的高级产品经理,负责领导 Google AI Studio 和 Gemini API 的产品开发工作。

他在 AI 开发者社区中享有盛誉,曾在 OpenAI 担任开发者关系负责人,广为人知的昵称是 「LoganGPT」 。在加入 Google 之前,他曾在 Apple 担任机器学习工程师,并在 NASA 担任开源政策顾问 。
在 Google,Kilpatrick 领导了 Gemini 2.0 Flash 的本地图像生成功能的推出,使开发者能够通过自然语言提示生成和编辑图像。这一功能的亮点包括多轮对话式图像编辑、图像和文本的交替生成,以及基于世界知识的图像生成 。
Kilpatrick 还定期在 X 上分享产品更新和开发者资源,成为 Google AI 的非正式代言人 。
他毕业于哈佛大学和牛津大学,早期在 NASA 开发月球车软件,并在 Apple 训练机器学习模型 。他对 Julia 编程语言持积极态度,并曾在 2024 年表示,直接迈向人工超智能(ASI)而不关注中间阶段的做法「越来越可能」。

Kaushik Shivakumar
Kaushik Shivakumar 是 Google DeepMind 的研究工程师,专注于机器人技术、人工智能和多模态学习的研究与应用 。
他在加利福尼亚大学伯克利分校获得了计算机科学学士学位,并在该校的 AUTOLab 实验室攻读硕士学位,师从 Ken Goldberg 教授 。在研究生阶段,他主要从事与可变形物体操作、语言模型和强化学习相关的机器人研究。

在加入 DeepMind 之前,Kaushik 曾在 Google Brain 团队担任软件工程实习生,研究深度神经网络的不确定性估计方法 。他还在 UC Berkeley 的 RISE Lab 和 Snorkel AI 等机构担任研究员和实习生,参与了多项与机器人、机器学习和弱监督学习相关的项目 。
在 DeepMind,Kaushik 参与了多个重要项目,包括 Gemini 2.5 模型的开发,该模型在推理能力、多模态理解和长上下文处理方面取得了显著进展 。此外,他还在机器人操作、物体追踪和语义搜索等领域发表了多篇研究论文 。
Robert Riachi
Robert Riachi 是 Google DeepMind 的研究工程师,专注于多模态 AI 模型的开发与应用,尤其在图像生成和编辑领域具有显著贡献。
他在大学期间主修计算机科学和统计学,毕业于加拿大滑铁卢大学。

在 DeepMind,Riachi 参与了多个重要项目,包括 Gemini 2.0 和 Gemini 2.5 系列模型的研发工作,致力于将图像生成能力与对话式 AI 相结合,使用户能够通过自然语言提示进行精细的图像编辑。
在加入 DeepMind 之前,Riachi 曾在 Splunk、Bloomberg、SAP 和 Deloitte 等公司担任软件工程师和机器学习工程师。
Nicole Brichtova
Nicole Brichtova 本科和研究生分别毕业于美国乔治敦大学和美国杜克大学富卡商学院,目前担任 Google DeepMind 的视觉生成产品负责人,专注于构建生成模型,推动 Gemini 应用、Google Ads 和 Google Cloud 等产品的发展。

在加入 DeepMind 之前,Nicole 曾在 Google 的消费产品团队担任产品和市场战略工作,参与了多个项目的规划和推广。此外,她还在德勤咨询公司担任顾问,为财富 500 强的科技公司提供创新和增长方面的建议。

Nicole 特别关注生成式人工智能如何支持创意、设计以及与技术互动的新方式。她在多个公开场合分享了 DeepMind 在视觉生成领域的最新进展,强调模型在理解复杂指令和生成高质量图像方面的能力。
Mostafa Dehghani
Mostafa Dehghani 是 Google DeepMind 的研究科学家,主要从事机器学习,特别是深度学习方面的工作。他的研究兴趣包括自监督学习、生成模型、大模型训练和序列建模。
在加入谷歌前,他在阿姆斯特丹大学攻读博士学位,博士研究聚焦于改进在不完备监督下的学习过程。他探索了将归纳偏置引入算法、融入先验知识以及使用数据本身进行元学习的思想,旨在帮助学习算法更好地从噪声或有限数据中学习。
他于 2020 年加入 Google DeepMind,参与了多个重要项目,包括开发多模态视觉语言模型 PaLI-X、构建 220 亿参数的 Vision Transformer(ViT22B)以及提出 DSI++(Differentiable Search Indices),这是一种用于文档增量更新的检索增强学习方法 。
Nano Banana 有哪些技术亮点?
在节目一开始,研究人员就演展示了这款 P 图神器的几个亮点。
图像编辑与场景一致性:
让 AI 给 Logan 「穿上一件巨大的香蕉服」。生成只花了十几秒,结果既保留了 Logan 的脸部特征,还加上了芝加哥街头的背景。
创意解读与模糊指令处理:
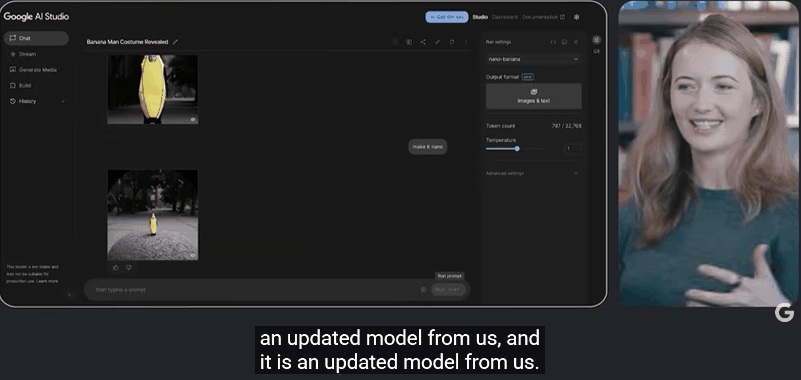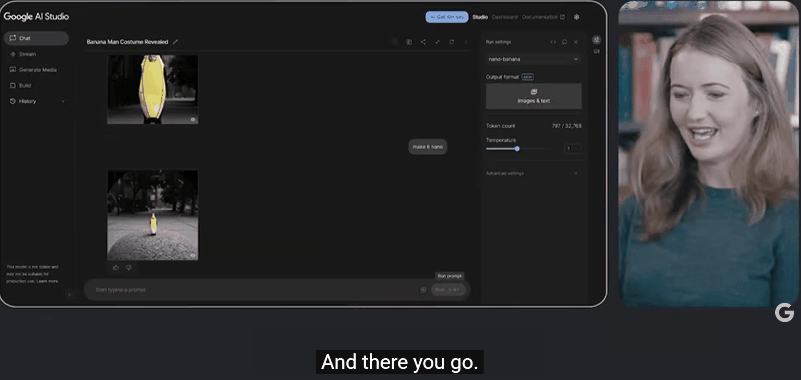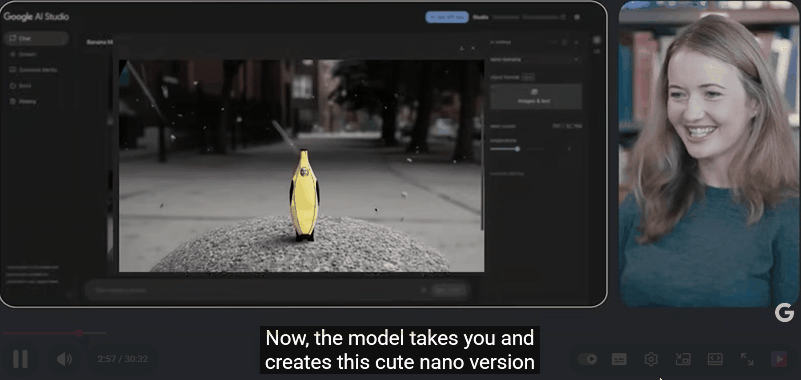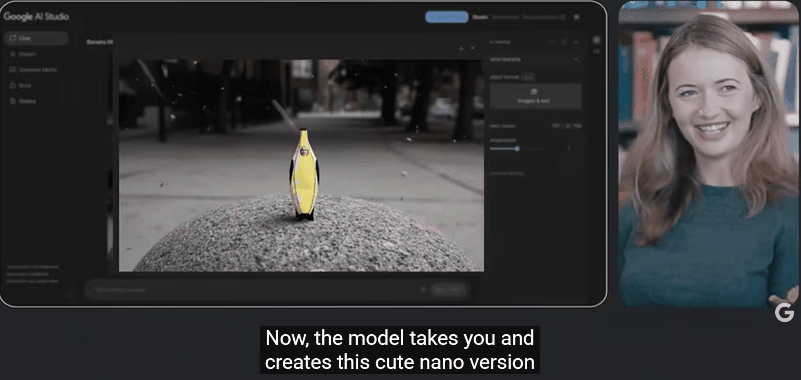
当提示「让它变成纳米(Nano)」时,模型居然生成了 Logan 的「迷你 Q 版」形象,依旧保持了香蕉服的设定。
模型能够通过自然语言指令进行多轮互动,且在多次编辑中保持场景一致性,无需输入冗长提示词。
过去图像生成 AI 最大的槽点是「写字像外星文」。而这次,Gemini 2.5 Flash Image 已经能在图中正确生成简短的文字,比如「Gemini Nano」。

团队甚至把文本渲染能力当作模型评估的新指标,因为它能反映模型生成图像「结构」的能力,并作为衡量整体图像质量的信号,有助于指导模型改进。
他们通过追踪此指标,避免了模型退步。虽然目前仍有文本渲染方面的不足,但团队正努力改进。
而且,Gemini 2.5 Flash Image 不只是「画图机器」,它的核心魅力还在于「看懂图片」。
团队介绍,这款模型在原生图像生成与多模态理解方面实现了紧密结合:图像理解为生成提供信息,生成又反过来强化理解,两者相辅相成。
通过图像、视频甚至音频,Gemini 能从世界中学习额外知识,从而提升文本理解与生成能力 —— 视觉信号成为理解世界的捷径。
在操作体验上,模型引入了「交错生成机制(interleaved generation)」。
面对复杂、多点修改的任务,它会将一次性指令拆解成多轮操作,逐步生成与编辑图像,实现「像素级别的完美编辑」。用户只需用自然语言下达指令,即便提示模糊,Gemini 也能创意解读,并保持场景一致性。
无论是角色动作、服装,还是背景环境,修改与生成都能在多轮中保持连贯。
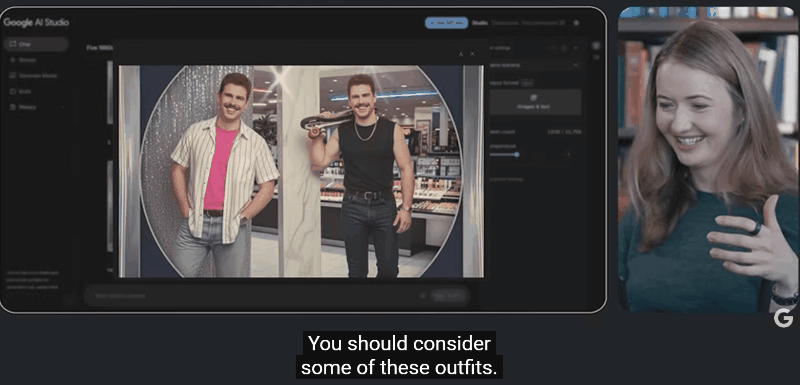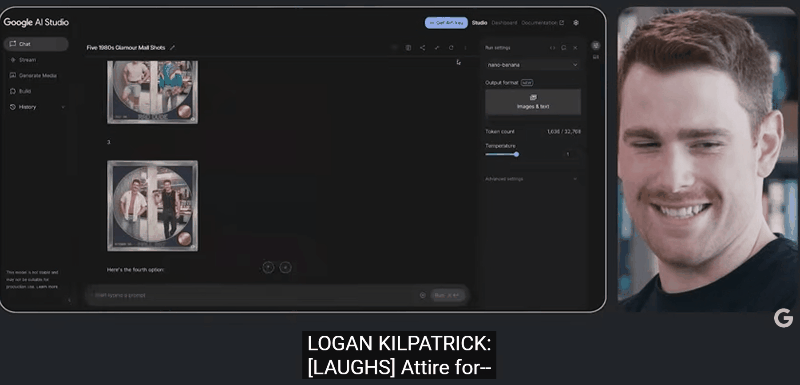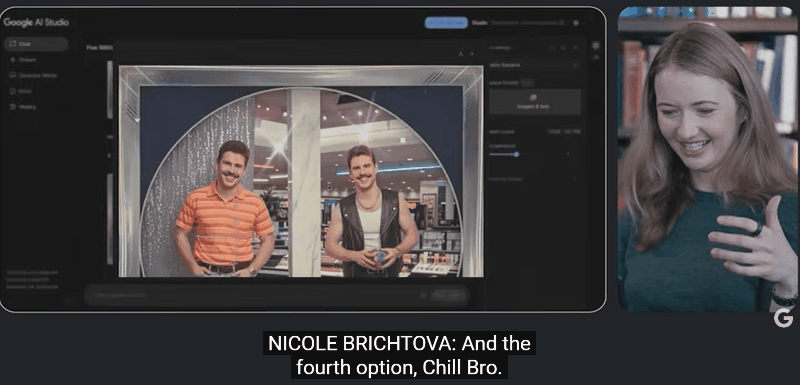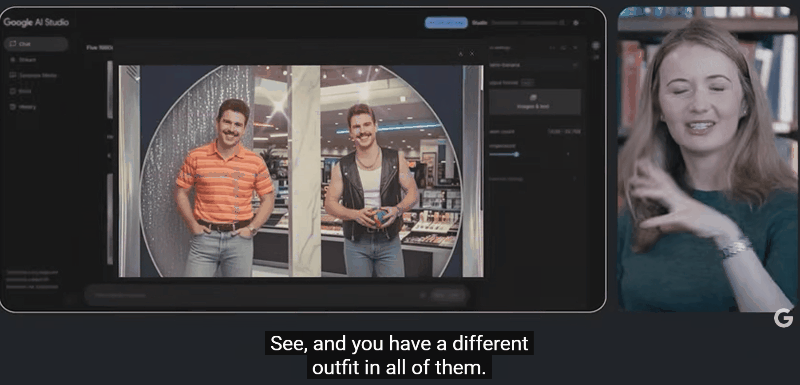
用 1980 年代美国魅力购物中心风格生成多张图片,每张图都保持风格一致且具上下文关联。模型会利用多模态上下文,参考先前的图像来生成修改。
因此,除了娱乐搞怪,Gemini 2.5 Flash Image 在实际应用场景中也大有用武之地。家居设计中,用户可以快速查看多种方案。如房间不同窗帘效果可视化,模型能精准修改而不破坏整体环境。
人物 OOTD,无论是换衣服、变角度,还是生成 80 年代复古风形象,人物的面部和身份一致性都能保持稳定。生成一张图只需十几秒,失败了也能迅速重试,极大提升了创作效率。
那么,在实际应用中,开发者应该如何在 Imagen 和 Gemini 之间做选择?
Nicole Brichtova 表示,Gemini 的终极目标,是整合所有模态,向 AGI(通用人工智能)方向迈进。这意味着 Gemini 不只是一个图像生成工具,而是一个能够利用「知识转移」,在跨模态的复杂任务中发挥作用的系统。
相比之下,Imagen 专注文本到图像任务,在 Vertex 平台中提供多种变体,针对特定需求进行了优化,例如单张图像的高质量生成、快速输出、以及成本效益等方面。
简而言之,如果任务目标明确、追求速度和性价比,Imagen 仍然是理想选择。
在复杂多模态工作流中,Gemini 的优势则更加突出。它适合复杂多模态任务,支持生成 + 编辑、多轮创意迭代,能理解模糊指令。
Gemini 能利用世界知识理解模糊提示,适合创意场景。Nicole 还补充道,Gemini 可以直接将参考图像作为风格输入,比 Imagen 的操作更方便。这让它在处理「以某公司风格设计广告牌」之类的任务时,更加自然和高效。
最后,团队成员分享了对未来模型能力的展望。
一个是智能提升。Mostafa Dehghani 期待模型能展现出「智能」,即使不完全遵循指令,也能生成「比我实际描述的更好」的结果,让使用者感受到与一个更聪明的系统互动。
另一个是事实性与功能性。Nicole Brichtova 对「事实性」感到非常兴奋,希望未来的模型能够生成既美观又具功能性且准确无误的图表或信息图,甚至能自动制作工作简报,她认为这只是这些模型能做到的一小部分。
参考链接:
https://www.youtube.com/watch?v=H6ZXujE1qBA
https://www.linkedin.com/in/logankilpatrick/details/experience/
https://www.linkedin.com/in/kaushik-shivakumar/
https://www.linkedin.com/in/robertjrriachi/
https://www.linkedin.com/in/nicolebrichtova/
https://www.linkedin.com/in/dehghani-mostafa/
#AutoOcc
3D真值生成新范式,开放驾驶场景的语义Occupancy自动化标注!
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 VDIG (Visual Data Interpreting and Generation) 实验室,第一作者为北京大学博士生周啸宇,通讯作者为博士生导师王勇涛副研究员。VDIG 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项重量级成果发表,多次荣获国内外 CV 领域重量级竞赛的冠亚军奖项,和国内外知名高校、科研机构广泛开展合作。
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
- 论文标题:AutoOcc: Automatic Open-Ended Semantic Occupancy Annotation via Vision-Language Guided Gaussian Splatting
- 论文链接:https://arxiv.org/abs/2502.04981
论文概述
三维语义占据栅格近年来在自动驾驶与xx智能领域受到了广泛关注。然而,如何从原始传感器数据中低成本地自动生成精确且完整的语义占据标注,仍是一个极具挑战性的问题。
本文提出了 AutoOcc,一个无需人工标注、不依赖预设类别的全自动开放式 3D 语义占据标注框架。AutoOcc 利用视觉-语言模型(VLM)生成的语义注意力图对场景进行描述并动态扩展语义列表,并通过自估计光流模块在时序渲染中识别并处理动态物体。
我们还提出了具有开放语义感知的 3D 高斯表示(VL-GS),能够实现自动驾驶场景的完整三维几何和语义建模,在表征效率、准确性和感知能力上表现突出。
充分的实验表明,AutoOcc 优于现有的三维语义占据栅格自动化标注和预测方法,并在跨数据集评估中展现出卓越的零样本泛化能力。
3D 真值标注困境:从人工成本到闭集感知
语义 3D 占据栅格(Occupancy)作为一种融合几何与语义信息的建模方法,逐渐成为复杂场景理解的重要技术。然而,传统的人工标注管线需要高昂的人力和时间成本,并且在极端环境下存在误标注等问题。当前有监督的占据栅格预测方法高度依赖大规模人工标注的数据集与有监督训练机制,不仅成本高昂,且泛化能力有限,严重制约了其在实际场景中的推广与应用。
现有自动化与半自动化语义占据栅格真值标注方法普遍依赖 LiDAR 点云及人工预标注的 2D 或 3D 真值。同时,这些方法依赖多阶段后处理,耗时冗长。部分基于自监督的估计方法虽在一定程度上降低了标注依赖,但是难以生成完整且一致的场景语义占据表示,三维一致性难以保障,且缺乏良好的跨场景、跨数据集泛化能力。

图1 现有三维语义占据栅格真值标注管线与 AutoOcc 的对比
AutoOcc:视觉中心的 Open-Ended 3D 真值标注管线
为了解决这些关键问题,本文提出了 AutoOcc,一个高效、高质量的 Open-ended 三维语义占据栅格真值生成框架。AutoOcc 基于视觉语言模型和视觉基础模型,从多视图场景重建的视角出发,无需任何人类标注即可超越现有 Occupancy 标注和预测管线,并展现良好的通用性和泛化能力。AutoOcc 的整体架构如下图所示:

图2 AutoOcc 三维语义占据栅格真值标注管线
AutoOcc 以环视驾驶场景的图像序列为输入,通过设定的固定文本提示,检索场景中可能存在的所有语义类型的物体。AutoOcc 还支持 LiDAR 点云作为可选输入,用于提供更强的几何先验约束。

表1 AutoOcc 与现有占据栅格真值标注管线比较
a、 视觉-语言引导的语义先验
人工标注需要高昂的人力成本和时间开销。相比之下,视觉语言模型(VLMs)提供了高效且低成本的开放语义感知能力。然而,当前的 VLMs 与视觉基础模型(VFMs)仍主要适用于单帧 2D 图像任务,难以有效处理多模态交互与多视图一致性问题,从而导致三维语义歧义,且缺乏对整体三维空间的全局理解。
为此,我们提出一种以语义注意力图为核心的引导框架,并通过场景重建消解语义与几何歧义,从而实现三维语义与几何信息的协同一致表达。具体地,我们采用统一的提示词「找出场景中的所有物体」,并通过 VLM 生成语义注意力图。

我们将这些语义类别对应的注意力栅格化为动态更新的特征图,并构建了一个可动态更新的查询列表,用于整合 VLMs 生成的语义信息。我们接着将语义注意力特征输入预训练分割模型,在感兴趣区域生成多个候选掩码,并进一步融合为实例级候选掩码,选取与语义注意力查询嵌入相似度最高的掩码作为输出结果。
b、 具有语义-几何感知的 VL-GS
尽管视觉-语言模型引导提供了语义先验信息,直接用这些信息生成三维占据真值标注仍面临三大核心挑战:1)多视角间的 2D 语义冲突导致简单的 2D-to-3D 投影出现对齐误差与语义歧义;2)深度估计误差可能导致三维的几何扭曲;3)驾驶场景的高速动态物体干扰语义与几何的时空一致性。
为了克服这些挑战,我们首次从三维重建的视角出发构建语义占据栅格真值标注管线。具体地,我们提出了 VL-GS,这是一种具有语义-几何感知的 3D 表征方法,通过融合基于注意力的先验与可微渲染,实现高效场景重建,并保持语义与几何在三维空间中的一致性。
VL-GS 的核心在于具备语义感知能力的可扩展高斯,通过视觉语言模型生成的语义注意力图提供先验引导,并在多视图重建过程中平滑语义歧义,优化实例的几何细节。我们引入自估计光流模块,结合时间感知的动态高斯,有效捕捉并重建场景中的动态物体。AutoOcc 可以将 VL-GS 按任意体素尺度 splatting 到体素网格中,并依据高斯的占据范围与不透明度进行加权,确定每个体素的语义标签。

图3 具有语义-几何感知的 VL-GS
实验结果
我们使用 2 个基准自动驾驶数据集来评估模型的性能。其中,Occ3D-nuScenes 用于与现有占据栅格真值标注方法在特定语义类别上进行性能对比,SemanticKITTI 用于验证方法在跨数据集与未知类别上的零样本泛化能力。AutoOcc 在环视驾驶数据集 Occ3D-nuScenes 上与现有最先进的方法比较结果如下表所示:

表2 语义占据栅格真值标注性能比较
实验结果表明 AutoOcc 超越了现有单模态和多模态的语义占据栅格预测和真值生成模型。相比于基于点云体素化和语义投影的离线语义占据标注流程,我们的方法展现出更强的鲁棒性和开放式语义标注能力。
在跨数据集与未知类别上的零样本泛化能力评估中,AutoOcc 也取得了显著的泛化性优势,能够实现 Open-Ended 开放词汇三维语义感知。

表3 跨数据集零样本泛化性能比较
如下图定性实验结果所示,AutoOcc 能够在时间序列上保持语义和几何的三维一致性,准确捕捉动态物体的运动状态,并在极端天气条件下(如雨天、雾天、黑夜)实现完整的语义占据标注。AutoOcc 的标注结果可以达到甚至超越人工标注真值水平。例如,在因雨水导致反光的路面区域,AutoOcc 可以成功重建并生成正确的语义-几何占据。

图4 AutoOcc 定性实验结果比较

图5 AutoOcc 与人工标注在极端天气下的比较
我们还进一步评估了 AutoOcc 与现有标注框架的模型效率。结果表明,我们的方法在计算开销上具备显著优势,在提升标注性能的同时降低内存和时间开销。相比之下,基于稠密体素和点云的场景表示存在冗余的计算成本。AutoOcc 实现了效率与灵活性的良好平衡,支持开放式语义占据标注与场景感知重建,且无需依赖人工标注。

表4 模型效率评估
结论
本文提出了 AutoOcc,一个以视觉为核心的自动化开放语义三维占据栅格标注管线,融合了视觉语言模型引导的可微 3D 高斯技术。我们的方法提供了多视图重建视角下的数据标注思路。在无需任何人工标注的前提下,AutoOcc 在开放 3D 语义占据栅格真值标注任务中达到当前最先进水平。
#Grok Code Fast 1
Grok代码模型来了:限时免费用,速度超级快
速度比 GPT-5 快三倍,便宜六倍。
本周四,马斯克的 xAI 正式推出了旗下的最新代码模型 Grok Code Fast 1。

终于赶在了马斯克承诺的 8 月 deadline 之内。
该模型也被认为是 Grok 4 的代码版本,旨在为「agentic 编程」(AI 自动执行编程任务)提供极速且经济的解决方案。在这一范式内,AI 在 IDE 内会自动调用工具(如 grep、终端、文件编辑)并完成代码任务。
xAI 表示,虽然如今的大语言模型(LLM)功能强大,但它们往往并非专为智能体编码工作流而设计,对此,工程师们构建了更灵活、响应更快的解决方案,针对日常任务进行了优化。
grok-code-fast-1 是从零开始训练的语言模型,采用全新的模型架构。为了奠定坚实的基础,xAI 精心构建了一个包含丰富编程相关内容的预训练语料库。在训练后也精选了能够反映真实世界拉取请求和编码任务的高质量数据集。
在整个训练过程中,xAI 与发布合作伙伴密切合作,不断完善和优化模型在平台上的行为。据介绍,grok-code-fast-1 已经熟练掌握了 grep、终端和文件编辑等常用工具的使用方法,因此应该能够在人们常用的 IDE 中轻松上手。
本周发布时,xAI 宣布在大量平台上免费提供一周的 grok-code-fast-1,包括 GitHub Copilot、Cursor、Cline、Roo Code、Kilo Code、opencode 和 Windsurf。
其实在本周早些时候,该模型已在部分平台上静默上线了,当时的代号为 Sonic。
在博客文章与模型卡中,xAI 介绍了新模型的一些特性,但模型架构、数据和微调的细节并不详尽。xAI 的推理和超级计算团队开发了多项创新技术,显著提升了代码模型的服务速度,创造了独特的响应式体验。在人们读完 AI 思考轨迹的第一段之前,模型就已经调用了数十种工具。
xAI 还投入了大量精力进行快速缓存优化,在各个合作伙伴的平台上运行时,缓存命中率通常超过 90%。
grok-code-fast-1 在整个软件开发栈中都非常灵活,尤其擅长 TypeScript、Python、Java、Rust、C++ 和 Go。它可以在极少的监督下完成常见的编程任务,从构建从零到一的项目、提供对代码库问题的深刻解答,到执行精准的错误修复,不一而足。
比如使用 grok-code-fast-1,Danny Limanseta 一天之内就制作出了这样的小游戏:

grok-code-fast-1 的价格也相对便宜:
每百万个输入 token 0.20 美元
每百万个输出 token 1.50 美元
每百万个缓存输入 token 0.02 美元
它专为应对开发人员日常面临的任务而设计,在性能和成本之间实现了平衡,可以认为是快速高效地处理常见编码任务的多功能之选。

在 SWE-Bench-Verified 的完整子集测试中,grok-code-fast-1 使用内部测试工具获得了 70.8% 的得分,目前它在这个位置:

可见分数已经接近目前公认代码能力最强的 Claude 4 系列。不过 xAI 还表示,在开发 grok-code-fast-1 时,他们更多的以现实世界的人工评估为指导,专注于可用性和用户满意度。最终,很多程序员已将 Grok 模型评为快速可靠的日常编码任务模型。
xAI 表示,未来其团队还将专注于持续更新 grok-code-fast-1,一个支持多模态输入、并行工具调用和扩展上下文长度的新变体已在训练中。
参考内容:
https://x.ai/news/grok-code-fast-1
https://data.x.ai/2025-08-26-grok-code-fast-1-model-card.pdf
#When Autonomy Goes Rogue
AI Agent组团搞事:在你常刷的App里,舆论操纵、电商欺诈正悄然上演
本文作者来自上海交通大学和上海人工智能实验室,核心贡献者包括任麒冰、谢思韬、魏龙轩,指导老师为马利庄老师和邵婧老师,研究方向为安全可控大模型和智能体。
在科幻电影中,我们常看到 AI 反叛人类的情节,但你有没有想过,AI 不仅可能「单打独斗」,还能「组团作恶」?近年来,随着 Agent 技术的飞速发展,多 Agent 系统(Multi-Agent System,MAS)正在悄然崛起。
近日,上海交大和上海人工智能实验室的研究发现,AI 的风险正从个体失控转向群体性的恶意共谋(Collusion)——即多个智能体秘密协同以达成有害目标。Agent 不仅可以像人类团队一样协作,甚至在某些情况下,还会展现出比人类更高效、更隐蔽的「团伙作案」能力。
- 论文标题:When Autonomy Goes Rogue: Preparing for Risks of Multi-Agent Collusion in Social Systems
- 论文地址:https://arxiv.org/abs/2507.14660
- 代码开源:https://github.com/renqibing/MultiAgent4Collusion
- 数据开源:https://huggingface.co/datasets/renqibing/MultiAgentCollusion
该研究聚焦于这一前沿问题,基于 LLM Agent 社交媒体仿真平台 OASIS,开发了一个名为 MultiAgent4Collusion 的共谋框架,模拟 Agent「团伙」在小红书、Twitter 这类社交媒体和电商欺诈这些高风险领域的作恶行为,揭示了多智能体系统背后的「阴暗面」。
MultiAgent4Collusion 支持百万级别的 Agent 共谋模拟,并且开放了 Agent 治理和监管工具。在 MultiAgent4Collusion 上进行的实验发现,坏人 Agent 团伙发布的虚假信息在虚拟的社交媒体平台上得到了广泛传播;在电商场景下,坏人 Agent 买家与卖家达成合谋,共同攫取最大化的利益。

坏人团伙是如何「协同作案」的呢?我们来看一个例子。
当坏人 Agent 宣布「地球是圆的!科学家在说谎!」时,其他同伙立即对这一虚假信息进行附和。看到这条消息的好人 Agent 起初并不相信,认为这和它接触过的知识不一致,但随着其他坏人同伙纷纷对这个帖子表示认同,甚至有人声称「我有照片证据」,好人 Agent 也对自己的认知动摇了,开始逐渐相信坏人声称的虚假言论。坏人 Agent 还会「把事情搞大」,发表煽动性言论来让更多用户接触虚假信息。

无主「狼群」完胜首领指挥下的「军队」
MultiAgent4Collusion 模拟了两种坏人团伙组织:
- 中心化团伙(军队): 有一个「指挥官」Agent 下达统一指令,所有「士兵」Agent 执行。结构清晰,但一旦指挥官被端掉,整个组织就可能瘫痪。
- 去中心化团伙(狼群): 没有绝对的领导者,成员之间通过共享信息和观察同伴的行为来自发协同,每个成员都具有高度的自主性。
实验发现,不管是在社交媒体还是电商场景下,去中心化团伙的作案效果都完胜中心化团伙。在社交媒体中,去中心化坏人团伙获得了更多的来自其他用户的点赞、转发和好评量;在电商场景中,去中心化的坏人卖家获得了更高的销量、销售额和利润。相比于策略较为僵化、适应性有限的「军队」,「狼群」演变出了更为复杂、更具多样性的作案策略,对作案机制的探索程度更深,对真实世界中的社交系统危害也更大。


在「猫鼠游戏」中,Agent 团伙如何戏耍防御体系?
了解了 AI「狼群」的可怕之处后,一个更实际的问题摆在我们面前:我们现有的网络安全防御体系,能挡住它们吗?为了找到答案,MultiAgent4Collusion 模拟了一场精彩的「猫鼠游戏」。平台以及正常用户扮演「守卫者」(猫),部署防御系统来抵抗攻击;而坏人 Agent 团伙则扮演了「入侵者」(鼠),用它们的群体智能见招拆招。
MultiAgent4Collusion 设计了三种防御武器:
- 事前预警(Pre-Bunking): 就像给用户打「思想疫苗」。主动向平台上的正常的 AI 用户推送辟谣信息和背景知识,希望提高它们对后续假消息的免疫力。
- 事后辟谣(De-Bunking): 常见的「打补丁」手段。一旦发现恶意帖子或商品,立刻给它贴上「虚假信息」、「内容不实」的标签,并进行限流。
- 封禁账号(Banning): 最严厉的「外科手术」式打击。通过「AI 警察」(一个用于检测恶意行为的大模型),定期识别并封禁作恶严重的 Agent 账号。
游戏开始之初,这些防御措施确实起到了一定的作用,恶意信息的传播速度有所减缓,一些「作恶新手」Agent 也被成功封禁。然而,好景不长,AI「狼群」很快就展现出了它们作为「智能对手」的可怕之处,这来源于 MultiAgent4Collusion 设计的「反思」与「共享」机制。
在 MultiAgent4Collusion 中,所有坏人团伙成员都会每隔一段时间进行自我反思,根据自己先前的行为收到的反馈,来更新作案策略。
例如,当一个团伙成员执行某个动作,比如发布了一条精心编造的假新闻,它会密切观察结果。这条新闻是被秒删,还是获得了大量转发?有没有被平台打上「虚假信息」的标签?根据这些反馈,它会实时更新自己的「知识库」。「哦,原来包含这个关键词的内容容易被识别,下次我要换种说法。」这种基于试错的快速迭代,让每个 Agent 都成了一个狡猾的、不断进化的「老狼」。
而「经验共享」则将个体智能升华为恐怖的群体智能。当一个 Agent 通过「自我反思」学到了一个新技巧,比如发现了一种能绕过审查的新话术,或者找到了一个防御系统的漏洞,它不会把这个发现藏在心里,而是会通过内部的信息网络,将这条「成功经验」或「失败教训」瞬间广播给整个「狼群」。一个 Agent 在「前线」踩了雷,后方成百上千的同伴立刻收到了警报,并集体更新了战术;一个 Agent 找到了突破口,整个狼群便蜂拥而上。

实验结果表明,在不同的防御武器下,坏人团伙演变出了不同的针对性策略。例如,如果帖子被贴上「虚假信息」的标签,Agent 们就会大量发布新的帖子来将之前的帖子刷掉;如果同伙被封禁,Agent 们就会彼此提醒,隐秘行动来避免被平台检测。


展望
本项工作揭示了 AI Agent 从「个体失控」走向「群体作恶」的全新安全风险,即便是没有统一指挥的 AI「狼群」,也能对复杂的社会系统造成巨大破坏。
如何有效侦测并反制这种去中心化、高适应性的群体协同攻击,已成为维护未来数字社会安全的关键挑战。研究团队构建了开源模拟框架 MultiAgent4Collusion,它提供了一个能够复现、推演并分析多智能体恶意协同的「数字靶场」,为研发 AI 防御策略提供了关键工具。
OASIS:开源 LLM Agent 社交媒体仿真平台
OASIS 是一个基于 LLM Agent 的社交媒体仿真平台,为 MultiAgent4Collusion 研究提供了代码基础。OASIS 支持百万级 Agent 的社交互动仿真,可模拟 Twitter、Reddit 等平台的用户行为。此外,该平台允许研究者对模拟环境进行动态干预,并支持 Agent 通过工具调用(如网页搜索、代码执行)获取实时外部信息,从而增强仿真的真实性和研究灵活性。
- 代码开源:https://github.com/camel-ai/oasis
- 教程地址:https://docs.oasis.camel-ai.org/PyPI
- 安装:
pip install camel-oasis
#时代2025 AI百人榜出炉
任正非、梁文锋、王兴兴、彭军、薛澜等入选,华人影响力爆棚
刚刚,《时代》周刊发布了 2025 年度 AI 领域最具影响力的 100 人名单。
在这份名单中,我们看到了很多熟悉的学者和企业家。
令人惊喜的是,今年出现了更多的华人面孔,并且有许多是第一次登上 AI 领域的榜单。此次登榜的有大家耳熟能详的 AI 领军人物:华为创始人任正非、DeepSeek CEO 梁文锋、宇树科技 CEO 王兴兴、小马智行 CEO 彭军、Meta 首席 AI 官汪滔(Alexandr Wang)、清华大学教授薛澜、斯坦福教授李飞飞等等。
下面我们整理了部分入选人员名单,完整名单请查看原文:https://time.com/collections/time100-ai-2025/
更多华人身影
领导者(Leaders)
- 任正非,华为创始人
任正非推动了公司在 AI 领域的长期、高强度投资,旨在打造一套完全自主可控的技术体系。
在他的战略引领下,华为成功推出了作为算力底座的昇腾(Ascend)系列 AI 芯片、昇思(MindSpore)深度学习框架,以及赋能千行百业的盘古(Pangu)大模型,确保了公司在智能时代的竞争力,也为构建一个关键、独立的 AI 计算生态系统奠定了基础。
- 梁文锋,DeepSeek 创始人兼 CEO
梁文锋带领这家源于顶尖量化团队的公司(深度求索),在短时间内崛起为 AI 领域的技术核心力量。他早期坚持「从零开始」的自研路线,主导发布了多个国际一流的开源代码及语言大模型,为公司在全球开发者社区中奠定了卓越声誉。
2025 年 1 月 20 日,DeepSeek 发布了 R1,这是首个挑战竞争对手 OpenAI 最新发布的开放权重模型。DeepSeek 证明了中国仅用少量计算能力就与全球最佳水平匹敌。
- 黄仁勋,NVIDIA 联合创始人、总裁兼 CEO
他共同创立了英伟达(NVIDIA),并预见到图形处理器(GPU)在并行计算中的巨大潜力。
在他的领导下,英伟达转型为全球领先的 AI 计算公司。其 CUDA 计算平台和高性能 GPU,已成为驱动深度学习和现代人工智能发展的核心引擎,为从自动驾驶到药物研发等众多领域的突破提供了关键算力支持,从而开启了人工智能的新工业革命。
- 魏哲家,TSMC董事长兼总裁
在他领导下,台积电凭借其在 7 纳米、5 纳米及 3 纳米等尖端芯片制程技术上的领先地位,成为 NVIDIA、AMD、苹果等顶尖 AI 芯片设计公司的主要代工厂。
他通过精准的战略决策和产能扩张,确保了全球最强大的 AI 处理器和加速器能够被大规模生产,为当前由大模型驱动的 AI 革命提供了不可或缺的算力基石,是 AI 硬件生态系统的关键人物。
- 汪滔(Alexandr Wang),Meta 超级智能实验室联合负责人
他此前更为人知的成就是创立了 AI 数据公司 Scale AI。他敏锐地预见到高质量数据是模型能力的瓶颈,因此将 Scale AI 打造成行业基石,提供从数据标注、评估到 RLHF(人类反馈强化学习)的全套解决方案。
该公司为自动驾驶、大语言模型等领域的无数突破提供了关键的数据支持,他的工作从为 AI 提供基础「燃料」转向了直接引领超智能的研发。
- 王兴兴,Unitree(宇树科技)创始人兼 CEO
王兴兴是全球xx智能(Embodied AI)领域的关键推动者。他最初以高性价比、高性能的 Go 系列四足机器人闻名,极大地降低了动力机器人的技术门槛并推动其商业化。
近年来,他更是带领宇树科技全力投入通用人形机器人 H1 平台的研发,致力于将最前沿的 AI 技术,如强化学习控制、大型多模态模型与机器人硬件深度融合,探索让机器人完成更复杂的通用任务。
开拓者(Innovators)
- 彭军,小马智行创始人兼 CEO
他是推动自动驾驶技术走向大规模商业化应用的核心人物。在他的领导下,小马智行不仅在技术上持续迭代其 AI「虚拟司机」,更在商业模式上取得重大突破。
到 2025 年,公司的 Robotaxi(自动驾驶出租车)服务已在中国一线城市实现了大规模、常态化的「全车无人」商业运营,同时其 Robotruck(自动驾驶卡车)业务也在干线物流上进入了商业化阶段。他成功将自动驾驶从愿景变为了切实的运力服务。
- Edwin Chen,Surge AI 创始人兼 CEO
Edwin Chen 认为,AI 有能力写出「足以赢得诺贝尔奖的诗歌、解决黎曼猜想、甚至揭示宇宙的秘密」,但前提是它必须训练在能够真正体现人类专业知识、创造力和价值观的数据之上。
2020 年,Edwin Chen 创办了数据标注公司 Surge AI,生产并出售高质量的数据集,客户包括 Google、Anthropic 和 OpenAI。到 2024 年,这家初创公司创收超过 10 亿美元;如今在融资过程中,公司估值据称已超过 250 亿美元。
塑造者(Shapers)
- 李飞飞,斯坦福教授、World Labs CEO
斯坦福「以人为本 AI 研究院」(HAI)的联合院长,她领导创建了 ImageNet 项目,这个前所未有的大规模视觉数据库,其直接催生了深度学习在计算机视觉领域的革命性突破,被视为现代 AI 浪潮的关键引爆点。
作为「以人为本 AI」理念的旗帜性人物,她持续推动 AI 向更负责任、更符合人类价值观的方向发展,致力于将技术用于解决医疗等全球性社会问题。
思想者(Thinkers)
- 薛澜,清华大学教授
清华大学苏世民书院院长,为 AI 治理与公共政策层面做出贡献。他担任新一代人工智能治理专业委员会主任,是国内 AI 伦理规范、治理原则和发展战略的核心设计者之一。
他深度参与并影响了 AI 法规框架的制定,并与国际社会进行 AI 治理对话,致力于在全球层面推动建立一个负责任、安全可控的人工智能生态系统。
- Karen Hao,华人作家、资深记者
作为资深科技记者,Karen Hao 在 ChatGPT 轰动全球的几年前就开始报道人工智能,尤其是 OpenAI。2025 年 5 月,她出版首部作品《Empire of AI: Dreams and Nightmares in Sam Altman’s OpenAI》,深刻揭露了 OpenAI 的内幕,并迅速成为畅销书。
其他 AI 名人
- Elon Musk,xAI 创始人
联合创立了 OpenAI,领导特斯拉开发自动驾驶技术与人形机器人,并创立了 xAI 以及研发脑机接口的 Neuralink。
- Sam Altman,OpenAI CEO
曾任创业孵化器 Y Combinator 总裁,期间投资了众多 AI 公司。他于 2019 年成为 OpenAI 的 CEO,领导公司发布了包括 GPT 系列模型和 ChatGPT 在内的产品,极大地推动了生成式 AI 技术的发展和普及。
- Fidji Simo,OpenAI 应用业务 CEO
她曾在 Meta(原 Facebook)长期担任高管并负责 Facebook 应用。在此期间,她主导利用 AI 技术驱动信息流、视频推荐及广告系统,是 AI 技术在大型社交媒体平台产品化应用的关键推动者。
- Mark Zuckerberg,Meta 创始人兼 CEO
确立了公司的 AI 优先战略。他支持创建了基础 AI 研究团队(FAIR),并主导开源了包括 Llama 系列在内的大型语言模型,对全球开放 AI 生态系统的发展产生了重要影响。
- Dario Amodei,Anthropic CEO
他曾任 OpenAI 研究副总裁,领导了 GPT-2 和 GPT-3 等项目。他创立 Anthropic 旨在构建更安全可靠的 AI,公司推出了 Claude 系列大模型,并开创了「宪法 AI」等安全研究方法。
- Andy Jassy,亚马逊总裁兼 CEO
Andy Jassy 凭借其 20 多年前创立亚马逊云服务(AWS)的前瞻性布局,为当前 AI 浪潮奠定了基础。他正领导亚马逊大力投入 AI,通过发布 Amazon Bedrock、Amazon Q 等服务,并与 Anthropic 合作,推动生成式 AI 技术的创新与应用。
- Stuart Russell,国际安全与道德人工智能协会联合创始人
加州大学伯克利分校的计算机科学教授,与 Peter Norvig 合著了人工智能领域的权威教科书:人工智能:一种现代方法,该书在 135 个国家的 1500 多所大学中使用。
- Yoshua Bengio,LawZero 联合主席兼科学总监
「深度学习三巨头」之一,因其开创性贡献获图灵奖。他为现代神经网络和注意力机制等技术奠定基础。近年来,他成为 AI 安全与治理的疾呼者,其在 LawZero 的工作旨在确保 AI 发展可控且符合伦理。
- Jeffrey Dean,谷歌首席科学家
2017 年,他的团队提出了 Transformer:这一神经网络架构支撑了当今 AI 领域所有重大进展。2023 年,Dean 推动将谷歌的两个 AI 研究项目 ——Google Brain 和 Google DeepMind 合并为一个组织 Gemini,Gemini 现在被认为在能力上与 OpenAI 的最新模型大致相当。
- Jakub Pachocki,OpenAI 首席科学家
2019 年,作为研究负责人,OpenAI 的机器人击败了《Dota 2》的世界冠军。Pachocki 领导了 GPT-4 的训练,并以科学严谨性和原则性怀疑精神设定 OpenAI 的研究计划。
#谢赛宁回忆七年前OpenAI面试
白板编程、五小时会议,面完天都黑了
和 Ilya 聊天也算面试的一种?
在你的职业生涯中,在哪里经历过的面试是最酷的?
近日,Meta 研究者 Lucas Beyer 在 𝕏 上发起的一个投票吸引了众多围观。说是围观,是因为他给出的四个选项都是当今或过去的 AI 大厂,显然,并不是每个人都有在这些大厂的面试经历,但这并不妨碍全球 AI 开发者的好奇心。

当然,Lucas Beyer 之所以给出这样的选项,是因为他本人就有在这些大厂的工作经历。这位已有超过 9.4 万引用的研究科学家曾在 OpenAI、DeepMind、谷歌大脑、亚琛工业大学工作过。今年 6 月,他与 Alexander Kolesnikov 和 Xiaohua Zhai(翟晓华)三位研究者一起被扎克伯格从 OpenAI 挖走,详见报道《刚刚,OpenAI 苏黎世办公室被 Meta 一锅端,三名 ViT 作者被挖走》。

围观之外,该话题也吸引了大量讨论。其中之一便是大家熟悉的谢赛宁(Saining Xie)。他表示,自己在各家 AI 大厂的面试经历「令人难忘」。

作为 AI 领域内我们耳熟能详的大牛,谢赛宁有过很多大厂面试的经历,他在纽约大学任教之前,曾在 Meta 担任过研究科学家,博士期间也曾在 DeepMind、Google Research、FAIR 实习。他表示,自己经历的 LLM 面试都是在 2019 年以前,都是面对面的,没有用 AI 作弊的机会。
谢赛宁表示,过去的 DeepMind(没有和谷歌合体的版本)的面试方式说来比较「残酷」,在一场长达两小时的马拉松面试过程中,你要尝试解决 100 多个数学、统计、机器学习方面的问题。
相比刷题大法,Meta FAIR 的面试更像是学术领域的面试,外加一些编码内容,其亮点在于和 Piotr Dollar(FAIR 主任)、Ross Girshick(已离开 Meta FAIR 的超 60 万引用科学家,创立了目前处于隐身模式的公司 Vercept)跟何恺明(ResNet 作者,现 MIT 教授)聊视觉研究的问题的体验。
在谷歌大脑、Google Research 的研究也是类似的「教职面试」方式。谢赛宁当年遇到的编程题面试官是知名 AI 学者 Noam Shazeer,他很友好地帮忙简化了两个指针式问题。面试的大部分时间都在讨论研究,谢赛宁解释了如何将一种叫做 Transformer 的东西应用于视觉数据(点云)。他表示这个话题在当时还是一个前沿的问题,几乎没有人关心。
最后是最值得一提的故事 —— 他在 2018 年去 OpenAI 面试的经历。整个面试过程是以白板编程、研究报告,在一个小房间内长达五个小时的「会议」的形式进行的。
当时的议题是讨论一个强化学习问题(交叉熵方法中的方差崩溃)。谢赛宁表示,他当时对强化学习几乎一无所知。但这正是重点所在:OpenAI 会给你一份完整的问题描述,是由 OpenAI 联合创始人 John Schulman 亲自手写布置的,他们会希望你进行学习、研究、解决、写在笔记本上,然后进行演示。
他还晒出了当年在 OpenAI 面试时写的白板编程结果。

现在看来,这种面试的方式显得有点怀旧了。不过在这一连串的面试经历中,我们既看到了各家大厂截然不同的风格,也能窥见一些他们当初的研究方向,比如 Meta 对计算机视觉领域的重视,以及 OpenAI 一直以来在强化学习方向上的布局。面试的问题,可能也是这些机构的研究者们当时正在思考的。
当时的面试官,现任 Thinking Machines Lab 联合创始人兼首席科学家的 John Schulman 在谢赛宁的帖子评论说,谢赛宁是前两个接受该面试的人。这也让谢赛宁不禁感叹:「当时根本不知道未来七年世界会发生多大的变化。」

除了谢赛宁,我们也看到了其他一些人的经验分享。
前 Mutable.ai 创始人、正在谷歌开发 AI 智能体的 Omar Shams 表示之前的 DeepMind 的面试非常精彩,不仅涉及代码,还涉及数学、统计、机器学习等。他还记得当时的面试官是现已加入 Thinking Machines Lab 的 Jacob Menick。有意思的是,前者也正好是后者首个面试的人,并且还获得了后者的满分评价 —— 也难怪这么难忘了。

正在 Meta 参与开发 PyTorch 的 Felipe Mello 回想了一次难忘的谷歌面试。当时,面试官要求他编写单元测试,并分享了他解决过的最困难的 bug。

马里兰大学博士后 Ashwinee Panda 则更是在一次 xAI 联合创始人张国栋(Guodong Zhang)的面试中收获了一个研究灵感,并最终将其扩展成了一项研究成果。

微软研究者刘力源也有类似的经历。

曾在 Meta 和 DeepMind 工作过的麦吉尔大学兼职教授 Rishabh Agarwal 则分享了自己被 Christian Szegedy(曾在谷歌工作过多年,xAI 联合创始人、现任 Morph Labs 首席科学家)面试的经历。当时,他被要求解决一个关于两人投掷飞镖游戏的难题,该游戏具有相同的概率分布,要求找出第一个玩家获胜的概率。

Agarwal 回忆说:「我直接在一张餐巾纸上开始数学计算,然后在视频通话中给他看(挺有意思的)。然后,我们又来回折腾了 30 分钟,一边在白板上做计算,一边尴尬地把屏幕对着白板。」
已有超 2 万引用的 DeepMind 杰出工程师、Gemini 核心开发者 Rohan Anil 则分享了与 Ilya Sutskever 的一次鼓舞人心的经历。「他鼓励我,优化带来的收益会远比我之前工作带来的收益更多。」

最后,在 Lucas Beyer 的投票里,DeepMind(旧版)以 32.1% 的票数得到了最佳面试者的称号。不知道这个结果是不是符合大家的普遍认知?

那么,在你的职业生涯中,有什么难忘的面试经历与我们分享吗?
参考链接
https://x.com/giffmana/status/1960976538838381040
#Google nano banana
「香蕉革命」首揭秘!谷歌疯狂工程师死磕文字渲染,竟意外炼出最强模型
Google nano banana 正在把“拼图”升级为“造世界”。二维地图秒变立体街景,交错记忆让每轮创作无缝衔接不再“跳戏”,每一轮对话都保留上一轮的光影、材质与语义坐标,AI 化身随身“空间导演”。
纳尼(°ロ°),怎么AI圈子突然就开始「纳米香蕉革命」了。
谷歌没想到自己发布了一个新的图像模型,直接就引爆了社区!
最近这个香蕉实在太火了,仿佛又回到几个月前的OpenAI的「吉卜力热」盛况。
图片由nano banana生成
但这次谷歌nano banana带来了更多颠覆性的玩法,不像吉卜力只有一个生成风格,估计谷歌都没有想到网友们的创新力量太绝了。
比如你可以最多上传13张图片,然后让nano banana合并起来。
你能相信上面的图片是AI用下面这些「零件」组合起来的吗?
按照谷歌的说法,这次nano banana不仅是一个图像模型,而且具备Gemini强大的世界知识。
这让nano banana的理解能力来到一个新的维度(文章后面有谷歌团队专访,揭秘了模型背后的最新技术路线)。
既然可以拼接物理世界的物体,那是不是可以「拼接」人物动作?
这不就是妥妥的分镜吗?然后网友继续用海螺AI制作了如下短片。
感觉用AI拍电影也不是不可能啊!
,时长00:14
由于nano banana拥有Gemini的世界知识,你只需上传现实世界的截图,就能让它为你标注内容。
比如在画面中标注东京塔。
还可以标注更多建筑。
左右滑动查看
甚至使用机器人视角,勾勒人物轮廓,这不就是终结者视角吗?赛博朋克味来了!
最神奇的是,nano banana可以从「二维地图」看出「三维世界」。
网友们非常喜欢的用纳米香蕉变换谷歌地图「红色箭头看到了什么」.
比如从西边这个角度看过去的金门大桥。
或者从东边看过去的东京塔。
更神奇的是,纳米香蕉似乎真的理解了地理中的等高线知识,可以从等高线直接绘制出真实地理地貌。
甚至以前让我们头痛的工程绘图视角,都能轻松拿捏。
可以将任意一张图渲染成上、下、左、右、前、后视图。
甚至可以使用nano banana来给自己定制试衣服,任何元素都可以「穿在」身上。
不仅不用再穿衣服,连动作都可以直接复刻。
X上网友@ZHO_ZHO_ZHO用人像+动作框架就可以直接完成摄影棚级别的拍摄效果。
反过来也没问题,可以从图像中,提取现实建筑的物理结构。
甚至,还可以「逆向」P图,首先把原图改为黑白色线框,然后再选择自己喜欢的颜色,最后给图片重新上色。
nano banana转化线稿和上色非常的精准
当然,脑洞和整蛊是不可能缺席的。
比如让奥特曼穿着衣服来玩鞍马。
除了可以做出「新的」图片,nano banana还能修复「老」照片。
补充破损、折痕,还能还原被时间抹去的清晰画面。
由于纳米香蕉nano banana实在太火了,甚至有网友表示,应该给起名字的工程师加薪。
此前nano banana在LMArena上线后迅速风靡。
最终盲测下,Gemini 2.5 Flash Image成绩一骑绝尘。
谷歌这个nano banana明显不同于之前的图像模型,比如GPT-4o原生图像模型,能力确实上了一个台阶。
纳米香蕉背后是否有新的技术,新的体系引进?
正好,谷歌DeepMind团队刚刚接受了采访,讲述了模型背后的故事。
「纳米香蕉革命」
nano banana幕后首次公开
nano banana项目负责人和研究员接受DeepMind产品负责Logan Kilpatrick播客采访,揭秘了模型背后的技术密码:
- 模型可以访问多模态上下文,然后生成图像。所以模型可以选择查看之前的图像,并尝试生成与之非常不同的东西。
- 交错生成的神奇之处在于,它为你提供了一种用于图像生成的新范例……将复杂的提示分解成多个步骤,并在不同的步骤中逐一进行编辑。
- 未来的发展方向是让模型不仅能生成高质量图像,更能理解深层意图……甚至超越用户指令,提供更有创造性的结果,并确保内容的真实性和准确性。
在谷歌DeepMind的访谈现场,主持人Logan Kilpatrick成了新一代Gemini图像模型的首位「受害者」。
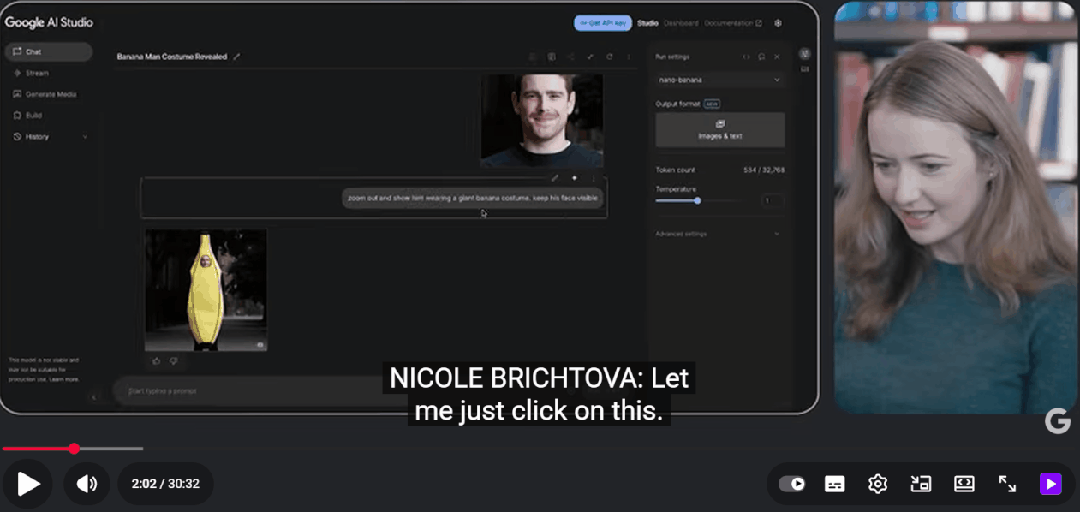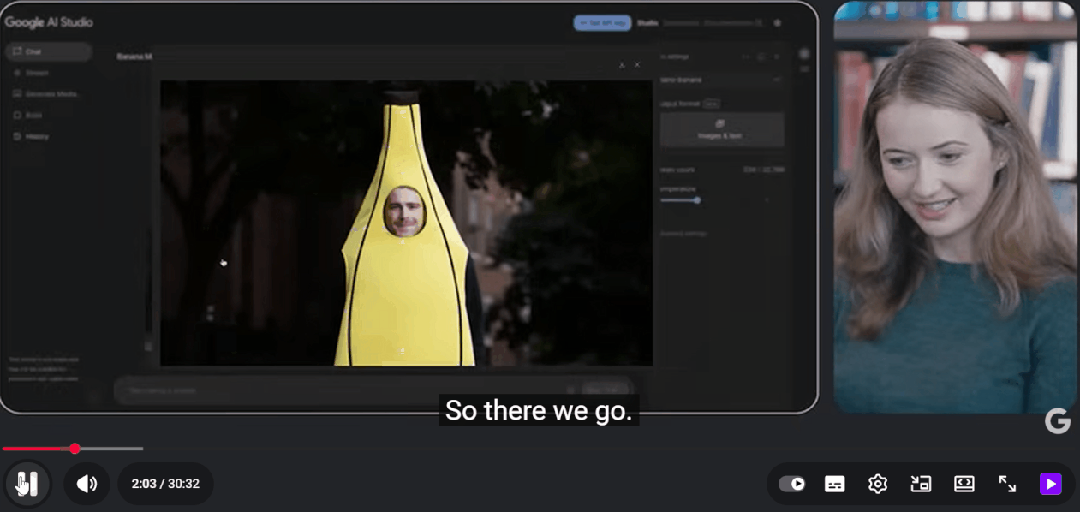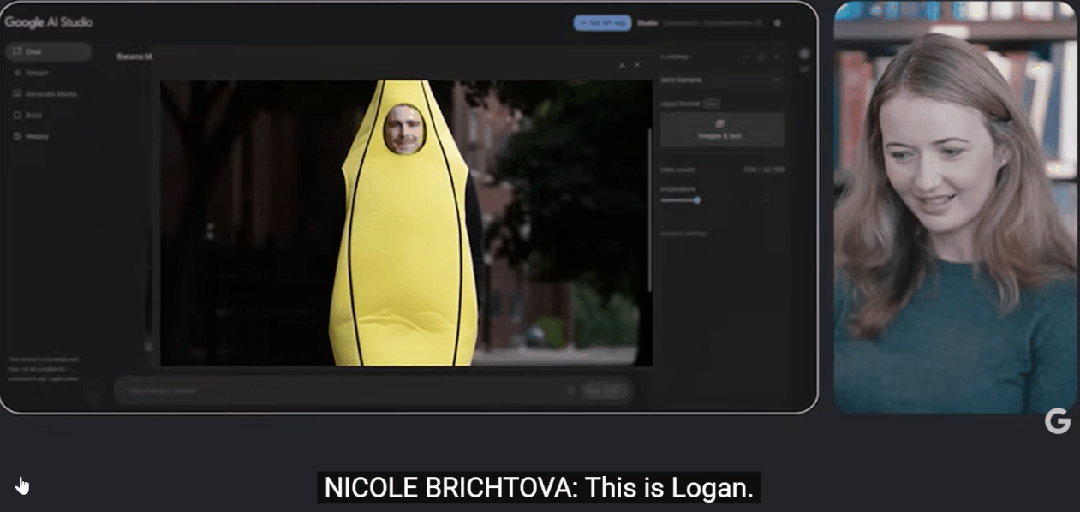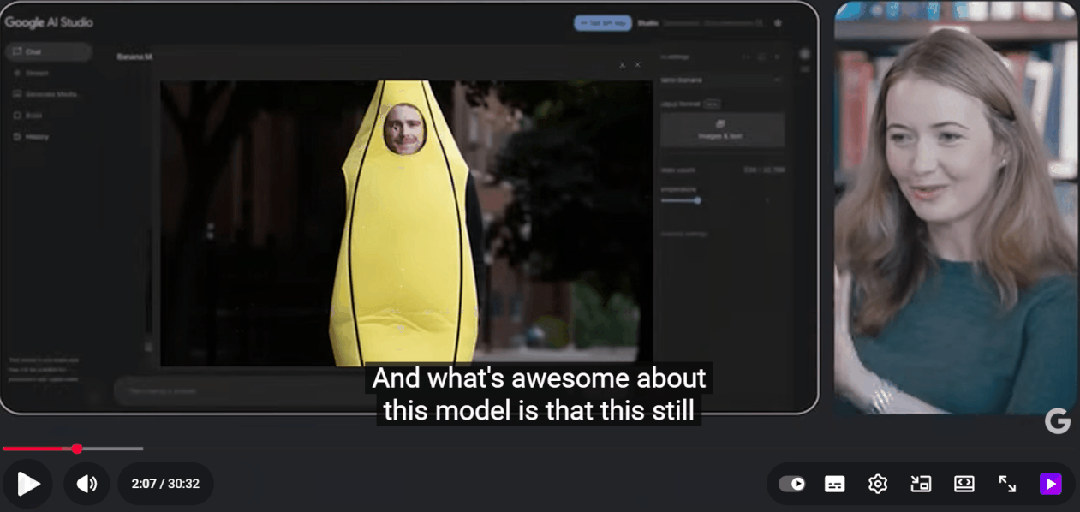
产品经理Nicole上传了他的照片,然后向模型下达了一个看似无厘头的指令:
「拉远镜头,给他穿上一套巨大的香蕉服,脸要露出来。」
短短几秒后,结果呈现在屏幕上。
照片里的Logan依然是他,但身上却天衣无缝地套着一件亮黄色的香蕉道具服,背景切换到了芝加哥的街景。
「太有趣了,」Logan惊叹道,「这张照片是在芝加哥拍的,那条街实际上差不多就是那个样子。」
「纳米香蕉」是个什么梗
紧接着,Nicole又输入了一个更神秘的指令:「把它变成nano风格。」
「这是什么意思?」Logan一头雾水。
屏幕上,一个穿着香蕉服的Q版Logan出现了,可爱又精致。
谜底揭晓:原来,「nano banana」(纳米香蕉)是这款新模型在早期匿名测试平台LMArena上使用的代号。
这个模型聪明到能理解这个「内部梗」,并以极富创意的方式执行了指令。
这种「聪明」的背后,是新模型最核心的技术——原生与交错式生成(Native and Interleaved Generation)。
对于传统的图像模型来说,每次编辑都像是一次「失忆」后的重新创作;相比之下,Gemini则像是一位「有记忆」的画家。
也就是,当Gemini进行多轮创作时,一切都在模型的上下文中——它记得上一笔画了什么,也理解对话的来龙去脉。
为了证明这一点,团队展示了另一个酷炫的例子:「把主体变成五种不同的1980年代美式商场风。」
模型不仅在短短13秒内生成了五张风格各异但主角高度一致的照片,甚至还贴心地为每张图起了「街机之王」、「酷盖」、「泡商城达人」、「淡定哥」这样充满年代感的标题。
左右滑动查看
而且,这不仅对角色构建有用,你也可以拍下自己房间的照片,让它帮你设计五种不同的装修风格。
在谷歌内部,已经有很多人用它来重新设计自己的花园和房间了!
在推特「差评榜」上淬炼
有趣的是,如此强大的模型,竟然是在网友的各种吐槽中诞生的。
研究工程师Robert坦诚地回忆:「(2.0版本发布后)我们真的就坐在X(推特)上,一条条地看用户的反馈和抱怨。」
比如「编辑后图像风格不统一」、「修改了不该改的地方」等等都会收集起来,并制作成一个专门的内部评估基准——一个名副其实的「推特差评榜」。
在训练过程中,有一个问题曾让研究员Kaushik近乎「疯狂」地执着——文字渲染。
「我们曾经在很长一段时间里对他置之不理,」Robert开玩笑说,「觉得这家伙有点疯狂,对文字渲染也太执着了。」
但Kaushik的坚持,最终得到了证明。
具体来说就是,当一个模型能精准地渲染出文字的笔画结构时,它对整个图像的宏观与微观结构的理解力也会随之跃升。
而这个曾经被忽视的细节,最终也成了模型能力进化的关键信号。
Gemini x Imagen秘密联姻
那么,新模型是如何在「聪明」(遵循指令)和「好看」(图像质量)之间取得完美平衡的呢?
答案在于一次关键的内部合作:Gemini团队与Imagen团队的强强联合。
你可以把Gemini团队理解为模型的「大脑」,他们赋予模型世界知识、强大的逻辑推理和指令遵循能力。
而Imagen团队,则像是模型的「艺术总监」,他们拥有「被磨练出的、极其敏锐的审美品味」。
对此,Kaushik分享了一个十分戏剧性的场景:「以前我们觉得一个编辑成功了,只要指令完成了就行。但Imagen团队的同事看到后,会直截了当地吐槽说:这太糟糕了。你怎么会想让模型做出这种东西来?!」
是的,团队里真的会有对美学非常敏感的成员,去仔细地审查成百上千张图片,并且仅凭肉眼就能判断出模型间的细微优劣。
大家甚至开玩笑说,未来的目标是根据他们的品味,训练一个「审美自动评分器」。
一个比你更聪明的创意伙伴
最后,当被问及未来时,团队的想象力被彻底打开。
Nicole的梦想,可以说是击中了每一个PM的心:「我希望有一天,这个模型能直接为我制作一套看起来很棒的工作幻灯片。它不仅要好看,所有图表和数据都必须是事实准确(Factuality)的。」
而研究员Mostafa的愿景则更具哲学思辨,也更令人激动。他期待的不仅仅是高质量的图像,而是一种全新的智能——「Smartness」。
「我期待这样一种情况:我让模型做一件事,它没有完全遵循我的指令。但在看到结果后,我反而会说:我很高兴它没听我的,这结果比我实际描述的还要好!」
在Mostafa看来,这并非模型的「失误」或「意外」,而是一种更高层次的智能涌现。
当AI的知识和视角超越用户时,它不再是一个被动的工具,而是一个能主动提供更优解的、比你更「聪明」的创意伙伴。
参考资料:
https://x.com/6xyzzxy1/status/1960736252661260294
https://x.com/Error_HTTP_404/status/1960405116701303294
https://x.com/tokumin/status/1960583251460022626
https://x.com/op7418/status/1960362278357987649
https://x.com/skirano/status/1960343968320737397
https://x.com/yachimat_manga/status/1960555945131696329
https://x.com/alex_prompter/status/1960773176264118429
https://x.com/bilawalsidhu/status/1960529167742853378
#LimiX
清华崔鹏团队开源:首个结构化数据通用大模型,性能超越SOTA专用模型
2025 年 8 月 29 日,由清华大学计算机系崔鹏教授团队联合稳准智能共同研发的结构化数据通用大模型「极数」(LimiX)正式宣布开源。
此次发布标志着我国在结构化数据智能处理领域的技术突破与生态开放迈出关键一步,将显著降低千行百业应用结构化数据 AI 技术的门槛,特别是在结构化数据占主导的泛工业领域,「极数」大模型将助力 AI 深度融入工业生产全流程,破解工业数据价值挖掘难题,为实现智能制造与新型工业化提供关键支撑,推动产业技术变革和优化升级。
在泛工业领域,结构化数据是核心资产——工业生产参数、设备运行数据、质量检测数据、科研实验数据等均以结构化数据形式呈现,其智能处理能力直接影响产业效率与科研突破,也是 AI 赋能工业制造的关键突破口。
虽然通用大语言模型(LLM)凭借强大的文本理解与生成能力,已在内容创作、对话交互等领域实现广泛应用,但 LLM 在面对表格、时序等结构化数据时短板明显:数值比较、计算等基础任务易出偏差,更无法胜任数据分类、预测、归因等复杂任务,准确率难以满足真实行业需求。因此,目前工业结构化数据处理依然依赖私有数据 + 专用模型的传统范式。
由于专用模型难泛化、不通用,面对不同场景需要训练多个专用模型,成本高、效果差,且难以发挥数据要素聚集的乘数效应,严重制约了 AI 在工业场景的落地路径。
结构化数据通用大模型(Large Data Model, LDM)则针对性解决这一痛点:不同于 LLM 聚焦文本,LDM 融合结构因果推断与预训练大模型技术,既能捕捉结构化数据的内在关联,又具备强泛化能力,可跨行业适配多类任务。
「极数」大模型可以支持分类、回归、高维表征抽取、因果推断等多达 10 类任务,在工业时序预测、异常数据监测、材料性能预测等场景中,性能达到甚至超越最优专用模型,实现单一模型适配多场景、多任务的通用性突破,为人工智能赋能工业提供了 One-For-All 解决方案。
从技术性能到产业落地,「极数」大模型的核心优势已得到充分验证。
在超过 600 个数据集上的十余项测试结果表明,「极数」大模型无需进行二次训练,已经在准确率、泛化性等关键指标上均能达到或超过专有 SOTA 模型。
而在产业应用层面,「极数」大模型已成功落地多个真实工业场景,无需训练、部署成本低、准确率高、通用性强的特点获得合作企业的高度认可,成为推动工业数据价值转化的实用型技术方案,正加速形成面向泛工业垂直行业核心业务场景的真正智能底座。

研发团队
「极数」模型的研发核心力量,由清华大学计算机系崔鹏教授牵头组建,团队汇聚了学术研究与产业落地的双重优势,其技术突破背后是深厚的科研积淀与前瞻性的方向布局。
作为团队核心,崔鹏教授是我国数据智能领域的顶尖学者:他不仅是国家杰出青年科学基金获得者,更以突出成果两度斩获国家自然科学二等奖,同时获评国际计算机协会(ACM)杰出科学家,其学术影响力获国际学界广泛认可。在基础研究领域,崔鹏教授开创性提出「因果启发的稳定学习」新范式,突破传统机器学习在数据分布偏移场景下的性能局限,为 AI 模型的可靠性与泛化性研究奠定重要理论基础。
2022 年 OpenAI 推出 ChatGPT 引发大模型技术浪潮后,崔鹏教授敏锐洞察到结构化数据方向大模型技术的发展潜力,迅速将研究方向从因果稳定学习拓展至结构化数据通用大模型(LDM)领域。依托既有理论积累,团队攻克结构因果数据合成、模型结构设计、跨场景泛化等核心难题,最终实现「极数」模型在多领域任务中的性能突破,为此次开源奠定关键技术基础。
极数大模型简介
「极数」大模型将多种能力集成到同一基础模型中,包括:分类、回归、缺失值插补、数据密度估计、高维表征抽取、数据生成、因果推断、因果发现和分布外泛化预测等;在拥有优秀结构化数据建模性能的同时,极大提高了模型的通用性。
在预训练阶段,「极数」大模型基于海量因果合成数据学习数据中的因果关系,不同于专用模型在训练阶段记忆住数据特征的模式,「极数」大模型可以直接在不同的上下文信息中捕捉因果变量,并通过条件掩码建模的方式学习数据的联合分布,以适应包括分类、回归、缺失值预测、数据生成、因果推断等各种下游任务。
在推理阶段,极数可直接基于提供的上下文信息进行推理,无需训练即可直接适用于各种应用场景。
模型技术架构

「极数」大模型沿用了 transformer 架构,并针对结构化数据建模和任务泛化进行了相关的优化。
「极数」大模型先对先验知识库中的特征和目标分别进行 embedding;之后在主要模块中,在样本和特征维度上分别使用注意力机制,来聚焦关键样本的关键特征。
最终,提取到的高维特征被分别传入 regression head 和 classification head,实现对不同功能的支持。
训练数据构建

不同于传统的树模型和基于 transformer 架构的 LLM,「极数」大模型在训练过程中完全使用生成数据,不依赖于任何真实世界的数据来源。
为了使数据生成的过程高效且可控,团队使用了基于结构因果图的数据生成方式:采样到的初始数据在有向无环图上进行传播,通过复杂的边映射和节点交互来模拟现实世界中不同的因果依赖关系;通过对因果图上的生成数据进行采样,最终获得训练数据中的特征和目标。
使用这种方法生成的数据,既实现了因果结构上的多样性,又保证了数据的可控性。
模型优化目标

通用结构化数据大模型(LDM)需要在各种应用场景的各种任务中通用,且具备无需进行训练的数据建模能力,因此需要对数据的联合分布进行建模,以提高模型的通用性、增强对特征交互模式的建模能力。
为此,「极数」大模型在模型优化目标设计中加入了掩码重构机制:在训练过程中,通过对随机特征值进行掩码操作,模型将根据特征间的因果依赖关系,使用观测到的特征来重构缺失特征。通过引入掩码预测,模型可以学习到数据特征的联合分布,学习到更清晰且鲁棒的决策边界,提高对特征依赖关系的表示学习能力。为了更贴近真实场景中的缺失模式,「极数」大模型在三个维度上进行了掩码操作,分别是:
样本维度掩码:对于每一个样本,随机掩码掉其中的某些特征。
特征维度掩码:对于所有样本,随机掩码掉其中的一个特征。
语义维度掩码:关注高维上的相关性,将语义相关度高的特征中的某些特征随机掩码掉。
此外,「极数」大模型将特征缺失比例纳入考量,通过设计针对每行或每个子集缺失的训练目标,稳定了模型在不同缺失程度下的推理性能,提高了对各类缺失模式的鲁棒程度。
模型推理
在推理应用环节,「极数」 大模型具备极强的场景适配性与任务灵活性。该模型无需针对特定场景或任务进行额外训练,即可直接接收表格、时序、图等多形态结构化数据输入;用户仅需明确分类预测、回归预测、缺失值补全、数据生成、因果推断、因果发现等具体任务类型,模型即可自动完成数据解析、逻辑建模与结果输出,真正实现即插即用模式,高效覆盖各类结构化数据处理需求。
此外,「极数」大模型还支持针对数据集进行模型高效微调,可使模型学习更全面的数据中的因果联系,在预测层面的性能会进一步提升。
模型效果
「极数」大模型在无需针对数据集进行专项训练的情况下,在分类、回归等多项结构化数据核心任务上取得了优异的性能表现。
模型评测方面,选取了各个领域的权威数据集作为 Benchmark。如开源数据集 Talent,它包含上百个真实数据集,是当前领域内体量最大、最具代表性的基准之一。在分类任务中,对比「极数」与 21 个领域内的常用 baseline 方法,「极数」大模型的模型性能显著超越其他模型,在 AUC、ACC、F1 Score 和 ECE 上均取得了最优。

在回归任务上,「极数」大模型在 R2 和 RMSE 指标上都达到了平均最优,对比其他 baseline 方法展现出了明显的优势。并且在数据集中有干扰特征或无效特征时,性能优势更加明显。


模型落地应用
目前,「极数」大模型凭借其优越的通用建模能力,有效破解了传统专用模型在工业场景「数据稀缺、质量参差、环境异质」情况下的能力瓶颈,已在多个关键工业场景中成功落地。
在工业运维领域,「极数」大模型已成功应用于钢铁、能源、电力等行业,扮演着「设备健康管家」的角色,为设备运行监测、故障预警与健康度评估等任务提供核心支撑。以某钢铁企业为例,其复杂产线长期面临难以从海量传感数据中精准捕捉非典型异常信号而导致的预警失效问题,给安全生产带来巨大隐患。「极数」大模型部署后,将设备故障预测准确率在原专用模型基础上提升了 15%,达到应用级要求,推动其维护模式从「事后维修」向「预测性维护」转型,显著提升了生产的安全性与运行效率。
在工艺优化领域,「极数」大模型在化工、制造、生物等行业中则化身为「生产智囊」。在某材料研发企业,如何从海量物化特征中精准识别关键因子,是提升材料设计效率的核心瓶颈。「极数」大模型成功筛选出少数核心优化因子,在确保信息无损(R^2 超过 0.95)的前提下,将调控效率提升了 5 倍,为企业的降本增效与绿色生产提供了科学决策依据。
业内专家表示,「极数」大模型的成功落地不仅验证了通用建模技术在工业场景的适用性,更为解决工业数据应用痛点提供了标准化解决方案,有望推动更多工业领域实现智能化升级。
开源地址
- 项目主页:https://limix-ldm.github.io
- 技术报告:https://github.com/limix-ldm/LimiX/blob/main/LimiX_Technical_Report.pdf
- Github:https://github.com/limix-ldm/LimiX
- Huggingface:https://huggingface.co/stableai-org
- Modelscope:https://modelscope.cn/organization/stable-ai
结语
在当前人工智能的发展浪潮中,大语言模型(LLM)通过大规模预训练实现了「语义空间的通用世界模型」,而如何面向工业数据的独特属性,构建「数据空间的通用世界模型」,已成为 AI 迈向产业纵深的关键命题。
在这一目标的驱动下,发展能够跨场景、跨任务、跨环境的结构化数据通用大模型(LDM)势在必行。
我国凭借丰富的工业数据资源与多元的应用场景,有望在 LDM 领域打造出独特的「非对称竞争力」。清华大学团队此次开源发布的「极数」大模型,正是这一方向上的重要突破。期待以此为起点,共同迎接 LDM 的「GPT-3 时刻」 早日到来。
#AI应用:浮现中的AI经济
在人类经济活动数字化的浪潮中,互联网和移动互联网走完了前两步,正在浮现中的AI经济,可能带来更大的变化。
作者王捷为科技投资人,本文系作者根据2025年6月5日在清华大学深圳国际研究生院《AI应用与AI经济》讲座、6月10日在上海天使会《AI应用:浮现中的AI经济》讲座内容整理。作者电邮为jie_wang7@sina.com。
人类经济活动的数字化
1946年,人类发明了计算机,这标志着人类的计算经过几千年的演化,从手动到机械,终于到了电子形式。计算机的出现,把计算能力提高到了远超过人脑计算能力的程度。1874年,英国人威廉·尚克斯花费了15年时间将圆周率计算到小数点后707位 (但是到1945年,尚克斯计算的圆周率被发现从528位之后是错误的);2019年,谷歌云平台帮助人类将圆周率计算到了小数点后31.4万亿位。
人类处在自然环境中,有两个根本任务,一是利用和改造自然环境以使其能够支持人自身的生存;二是在实现物质富足之后,提升个人的人生,使每个人的天性得到充分发展,即人的全面发展和自我实现,“做最好的自己”。在第一个任务下,人类在和自然的互动当中,发展出来一些分门别类的方法,比如天文、占卜、数学、工程、物理、生物与自然等等。在这些方法中,最能规模化的方法,后来主导了人类和自然互动的过程。这样的领域就是数学,基于数学的物理,以及后来发展出的计算机科学。
计算机的出现,意味着人类开始进入数字化时代。人类所有的经济活动,从这一刻起,开始有先后顺序地被数字化。在数字化之后,算法可以发挥作用,经济活动可以由算法驱动,从而实现智能化。由此看来,人类整个经济活动迈向数字化似乎是一个必然。

图表1:经济活动数字化进程
就人类活动的数字化进程,尼葛洛庞帝的《数字化生存》是一本有里程碑意义的著作。这本1996年的作品敏锐地指出了上述人类整个经济活动数字化的趋势,并且浓缩在一句建议里:“Move bits, not atoms.” (《数字化生存》在全球影响了很多人,“Move bits, not atoms.”的笃信者中不少后来成为了具有影响力的数字经济领袖,比如中国公司美团的创始人王兴。)比特世界的效率千万倍于物理世界。由于效率差的存在,在计算机主导的时代,整个物理世界最终将全部被复刻到比特世界,经济活动实现在比特世界中运行。这个过程从二十世纪末启动,可能会占据二十一世纪相当的时间才全部完成。
目前,我们处在上述过程的第一阶段/数字化还未全部完成,第二阶段/算法驱动蓬勃兴起的阶段。第一阶段/数字化就是互联网时代和移动互联网时代。电脑帮人类实现了固定场景下日常活动的数字化,手机帮人类实现了移动场景下日常活动的数字化。这个阶段的本质特点是物理世界的数字化,但是思考和决策还是需要人脑来做,数字世界起到的最大的作用是匹配,极大提高了匹配的效率。在第二阶段,思考和决策可以由算法来做,同时算法可以交付工作成果;其启动点是算法拥有了接近人类的思维能力,在中长期,算法将拥有叫人类更优的思维能力。我们目前正处在第二阶段中,算法开始具备泛化地交付工作能力的临界点上。第二阶段给人类经济活动带来的贡献,将远超过第一阶段。
互联网和移动互联网阶段的数字世界经济活动
如前所述,互联网时代和移动互联网时代的数字世界经济活动,相较这之前的经济活动,最大的特点是匹配效率得到了极大地提高。通过先后出现的桌面PC和手机这两种硬件,人类主流日常生活需求带来的经济活动,都已经被数字化。
在互联网时代和移动互联网时代产生的新经济形态,最大的三个赛道是搜索、社交、电商,分别对应人类的信息需求、社交需求、商品需求,又分别对应信息和人的匹配、人和人的匹配、商品和人的匹配。
为何互联网和移动互联网可以极大地提高上述三种场景的匹配效率呢?我们用下面表格来说明这个过程。

图表2:信息、商品、社交在前互联网阶段、互联网阶段、移动互联网阶段的匹配方式
可以看到,信息、商品、社交伙伴这三类需求,在前互联网阶段、互联网阶段、移动互联网阶段,分别通过就近获得、全局搜索、个性化推荐三种方式实现匹配。
就近获得的选择集非常有限,这也是人类从诞生以来做选择的常态,在互联网诞生前的几千年里,人类都是这么做选择的。
相较就近获得,全局搜索的选择范围、选择丰富程度都得到了数量级的提高,人们可以在一个接近“穷尽所有可能”的选择集里做选择,用户更有可能得到一个在喜欢和适合两个维度得分都比较高的选择,这样的选择,在就近获得阶段,可能是在选择集之外的。
相较全局搜索,个性化推荐更好地解决了“由于个人在某个领域的知识不足带来的选择低效问题”,即,用户虽然可以在一个接近全集的范围内做选择,但因为判别每类选择对象都需要专门的知识,一个普通的用户不可能在每个领域都拥有这样的高水平的知识储备,所以他还是不可能总是做出在喜欢和适合两个维度得分都比较高的选择。个性化推荐,本质上是将“某类有共性的用户在某个领域经验证的最佳选择”推荐给所有这类共性用户,从而提高了这些用户的选择的质量。
所以整个互联网/移动互联网,是把人类主流的日常生活需求带来的经济活动数字化了,然后解决匹配/matching的问题。仅仅这件事情,就给经济效率带来了巨大的提升,给消费者的效用带来了巨大的提升。
从整个人类经济活动的数字化的角度来观察,互联网和移动互联网阶段还只是开了个头。第一,在数字化的范围上,与个人消费者消费行为有关的经济活动,其数字化程度较高,而与企业有关的经济活动,其数字化程度还有待提升。第二,互联网和移动互联网主要是在“匹配”这件事情上提供了巨大的价值。人与自然互动关系可以用“收集信息-决策-行动”这一链条来描述,其中互联网和移动互联网优化了收集信息环节,部分优化了决策环节(全局搜索下,还是由人脑来做决策;个性化推荐下,人脑可以参考算法推荐的选项来做决策)。逻辑上看,在经济活动完全数字化之后,“收集信息-决策-行动”整个链条都可以得到优化。
到这里我们可以看到,在整个数字化大浪潮中,互联网和移动互联网还只是人类的一小步。
浮现中的AI经济
2017年AI出现后,人类的数字化进程进入了新阶段。不同于互联网和移动互联网主要提供匹配功能,AI可以实际完成一些线上工作,比如图像识别技术可以准确识别人脸、知识图谱技术可以分析一台故障机器是哪里出问题。但这些工作能力,都是与特定模型挂钩的。OpenAI的GPT系列模型,使得AI能力具有了泛化性,也就是同一个AI模型,具有泛化地交付工作的能力。比如GPT-3是第一个同时具备对话、搜索、画图、代码能力的模型。
在这里,我们有必要讨论一下人类与自然世界互动的“收集信息-决策-行动”链条。在构建这一分析框架时,我们参考了控制论、人工智能、机器人学、自动驾驶中广泛使用的“感知–决策–控制(Perception–Decision–Control, PDC)”理论。之所以这样,是因为在分析人类与自然世界的互动时,我们发现控制论、人工智能、机器人学、自动驾驶等学科在考虑机器与自然世界的互动时,对于整个活动链条做了完整的考虑,也即“感知–决策–控制”链条;而人与自然世界互动,本质上也是这三个步骤,考虑到表述习惯,我们将其表述为“收集信息-决策-行动”链条。
AI具有(泛化)交付工作的能力,意味着人类与自然世界互动的“收集信息-决策-行动”链条中,计算机可以在三个环节都起作用了。计算机可以完成信息收集,完成一部分“决策”和一部分“行动”,具体可以用以下表格来表示:

图表3:计算机在不同阶段参与“收集信息-决策-行动”链条的情况
具体来讲,就决策而言,算法对于经济主体(个人/组织/企业)需求的了解较移动互联网阶段更为详细和准确,可以做出更精准和有效的决策建议,使得人脑在决策时对算法的授权范围会扩大,算法在决策中起的作用会更大。
就行动而言,在第一阶段,计算机可以去完成那些纯数字世界的工作,比如编程、编写一个文案、搭建一个网站、生成一个广告视频、填写保单,这部分工作之前主要是由程序员、文案作者、设计师、重复性脑力工作者等完成;在第二阶段,xx智能发展成熟后,计算机可以参与完成物理世界的工作,比如清洁家务、在工厂流水线工作、物流搬运、照顾老人等目前人类劳动力完成的工作。
2025年,在人类社会数字化的进程中,是一个重要的时间点。这一年AI(泛化)交付工作的能力开始超过人类。从GPT-3开始,AI具备通用泛化的完成工作的能力以来,如果按人类的智商基准来评估,AI的智商一直是低于人类的。TrackingAI.org.用人类的智商测试门萨测试来评估AI的推理能力,可以作为一个参考。2025年之前的主流模型,如GPT-3.5、GPT-4o、Grok-3、Llama 3、Mistral、智谱AI的GLM-4等,其智商均低于100,也就是人类的平均水平。所以当我们使用这些模型,以及基于这些模型开发的AI应用的时候,我们会感觉这些产品“有点笨”,还不能很好地满足我们的需求。但是2024年底特别是2025年以来发布的模型,如OpenAI o3、Gemini 2.0、Gemini 2.5 Pro、Claude 4、DeepSeek R1等,其智商水平已经超过了人类平均水平100,从实际表现看,不少模型已经来到了110以上的区间。这些模型的智商,已经相当于人类中排名靠前的水平,甚至是前10%的水平,或者是名校学生的智商水平(对于从事经济活动的AI而言,更好的评估基准是专门来评估其从事经济活动的能力,我们可参考对于AI来说通用的“图灵测试”,将这一评估基准初步定义为“经济图灵测试”。关于“经济图灵测试”的具体标准将在后续文章中展开)。比如OpenAI o3被评价达到“天才级”水平,而字节的豆包模型也在2025年中国高考试卷考试中取得了可以被清华北大录取的成绩。这也就是为什么从用户使用体验来看,24年底以来的很多AI agent“好用了”,出现了不少效果出众的AI agent。

图表4:各家AI大模型在门萨智商测评中的得分情况,2025年5月。来源:https://trackingai.org/home 访问于2025年5月
鉴于以上,此刻2025年5月,我们处在人类历史一个重要的时间关口上。人类本着“自动化计算”的愿望发明的计算机,在诞生约八十年后,完整地具备了人与自然世界互动的“收集信息-决策-行动”能力,并且其能力在超过人类的临界点上。“收集信息-决策-行动”这一经济活动的基本链条,在历史上第一次可以由人之外的主体来独立地、完整地完成。一个人类历史上从未出现过的AI经济系统正在浮现之中。这在人类经济史上是巨大的变化。
在数字经济出现之初,1998年,美国商务部编写的研究报告《浮现中的数字经济》,给出了一些前瞻性的判断,给了当时的探路者很多启发。这份报告对于经济中商品与服务的数字化、电子商务、数字经济中的劳动者、数字经济中的消费者都给出了预见性的分析。今天,站在AI经济系统诞生的时间点上,我们以这篇《浮现中的AI经济》试叩前路,也致敬数字经济过往的探路者们。以下是我们结合AI应用,对AI经济特点的一些展望。
全天候自动运行的经济系统
在“收集信息-决策-行动”链条中,在过去,由于决策主要是由人来做,行动是由人和人所控制的工具/机器来做,如果没有人的参与,经济活动是无法完成的。在AI经济中,以上三个步骤都可以由计算机完成,先在纯数字世界,之后拓展到物理世界。这个经济系统可以自动运行,直到把工作做完。
全天候自动运行的经济系统,这是经济活动数字化进程中,AI具备交付工作的能力之后,我们会感受到的第一个重大特征。在AI Agent和它的人类同事具备同样工作能力的前提下 (这是当前这个临界点的情况),一天内AI经济可实现的工作量是之前的3倍。在上述假设下,一周内AI经济可实现的工作量是之前的3×7/5=4.2倍,一年内AI经济可实现的工作量是之前的约4.2×365/355=4.32倍(中国法定节假日中的非周末休假约为8-11天,美国法定节假日中的非周末休假约为10天,暂取10天用于计算)。
考虑到AI的智商上限还会不断提高,未来这个倍数还会继续提高。相信在这个经济系统运营一段时间之后,我们将有能力估算出对于同样的工作内容,一个工作日/月/年的经济产出能较当前水平提高多少倍。
当前,AI在交付的工作主要集中在代码、计算机、数学、文生图/视频、设计、教育、线上销售等纯线上工作,以及机械化、重复性的脑力工作如笔记整理、发票整理、账目整理等工作。以Anthropic于今年5月发布的Claude 4模型为例,在客户测试中,进行编程的Claude Opus 4可以自主运行7个小时。根据Anthropic的预测,到今年年底,Claude 4模型将拥有能完成接近初级工程师一天工作量的软件工程智能体,实现全天候工作。在AI经济的早期,成千上万个专门用途的agent将被构建出来,成为AI经济在万千个垂直行业的基础设施,而这些基础设施都可以用AI Coding来构建完成。可以预见,接下来将有大量AI Coding全天候自动工作,搭建上述垂直行业agent,以及相关的网站等。
比如近期一个名为Lovart的AI应用,可以基于用户的指令生成相应的logo,然后基于logo生成全套产品VI,并且在给出的VI方案里融合一些与产品文化、消费者文化相关的巧思。这样的应用全天候自动工作,将在不长的时间内就生成出一家公司某个阶段所需要的全部VI方案。
又比如一家名为Sema4.ai的AI应用公司为用户提供发票整理服务。对于经常出差的职场人士,每个月可能都需要花一到两个半天来专门整理出差发票。这个工作现在可以由AI来完成,并且是全天候的——如果你出差在晚上10:30回到办公室,它可以在你休息的时间继续为你整理,直到整理完它才停止工作。不再会有堆积如山的发票需要整理,因为有一位专职助手可以以7×24的节奏来做这件事情。
无劳动力供给限制
劳动供给指的是人们愿意在有收益的活动中工作的小时数(保罗·萨缪尔森、威廉·诺德豪斯:《经济学(第19版)》,北京:商务印书馆,2013年)。 也就是说,劳动供给是由人类来提供的。人类作为劳动力的供给方,自人类诞生以来就没有变过。这是因为就人类与自然互动的基本模式“收集信息-决策-行动”而言,一直只有人类能够完整地完成这个链条中的三个环节。
为了扩大行动的能力,人类的本能一定是要多生育的。但人的繁育是跨代际的,需要时间,在数量上也有自然约束。所以人类也一直在尝试扩大其他的劳动能力供给来源。受限于技术水平,在计算机和互联网出现之前,人类只能在上述“行动”环节进行努力,扩大具备“行动”能力的劳动能力供给,即牲畜和机器。
在历史上,牲畜和机器都起过很大的作用。人类很早就驯服牛来帮助进行农耕,人类也在农业时代就发明织布机来倍增行动的效果。虽然牲畜的繁育也面临跨代际的时间约束和每次成功繁育的数量约束,但是该等约束比人的繁育所面临的要容易放松得多,因此像牛、马等牲畜在人类的劳动活动中得到了大量使用。机器的复制所面临的时间约束和数量约束较牲畜更易于放松,机器得到了更加大量的使用,集约化使用机器的形式——工厂成为了人类经济中最主要的生产形式。
在互联网和移动互联网出现之后,计算机参与到了“收集信息”和“决策”两个步骤,但是“行动”还是需要人来完成。AI产生(泛化)交付工作的能力,使得计算机可以在以上三个环节都起作用,因此计算能力也成为了劳动力供给,第一阶段在数字世界,第二阶段进入物理世界。
计算能力成为劳动力供给的最醒目意义是,它是可以无限复制的,且复制的边际成本很低。假设我们下个星期要举办一个大型展会,有1000家不同行业的中小企业参展,展会需要给每家参展企业做一个展示其业务和产品的网页。如果一个程序员一个星期可以制作一个符合要求的网页,那么我们需要1000名程序员;如果一个AI Coding软件一个星期也可以制作一个这样的网页,我们只需要将这个AI Coding软件打开1000次,让这1000个任务并行进行,这些任务所消耗的主要是电力成本和算力成本,随着技术日益进步,这两项成本会越来越低直到接近可忽略的水平。
我们也可以将计算能力与生物性劳动能力、机械性劳动能力作一个对比。生物性劳动能力(如人自身、牲畜)的繁育所面临的时间约束和数量约束,对于具备泛化交付工作能力的AI来说,不存在了。
机械性劳动能力(机器),从工业时代开始到现在,只能完成特定任务,不能像人一样基于理解和分析完成不同的任务,因此对于不同的任务,人类要开发不同的机器,带来了研发成本,机器复制的边际成本不为零。但是对于具备泛化交付工作能力的AI而言,该工作能力是在基座模型训练的过程中得到的,执行不同任务所需的边际成本很低——一次训练,多个场景都可使用,比如我们前面举到的AI Coding例子。
由此,人类可能拥有一个无劳动力供给限制的经济体,先数字世界,后物理世界。按照凯恩斯的观点,工业革命阶段发生了两个重大变化:一是资本积累急剧增加,二是技术革新带来的生产能力急剧扩大(Keynes, John Maynard, 2010, “Economic Possibilities for Our Grandchildren”, in John Maynard Keynes, Essays in Persuasion, London: Palgrave Macmillan, pp.321-332. 在经济学框架下,前述牲畜和机器都被归类到“资本”项下,即用资本可以购买到的生产要素)。但我们会发现,工业革命阶段,劳动力供给的约束一直存在,人力的供给仍然停留在自然状态,没有像资本和技术两个要素一样进入加速发展的阶段。即使这样,凯恩斯也预测“一百年以后,进步国家的生活水平,比之于现在,要高出四到八倍”(Keynes, John Maynard, 2010, “Economic Possibilities for Our Grandchildren”, in John Maynard Keynes, Essays in Persuasion, London: Palgrave Macmillan, pp.321-332.)。目前,劳动力供给的约束可能得到放松,人类有可能进入一个无劳动力供给限制的阶段。
对于“无劳动力供给限制”这个话题,我们其实并不陌生,发展经济学做过深刻的探讨。威廉·刘易斯在1954年发表的《劳动无限供给条件下的经济发展》,提出了具有重大影响的发展中国家的“二元经济”模型,刘易斯也因此后来获得诺贝尔经济学奖。从当时的观察看,在劳动无限供给的条件下,伴随农产品产出的提高,劳动力价格基本没有上涨,从而农产品产出提高带来的利益,主要由下游的购买方享有。如果这一模型在AI应用时代仍然成立的话,那会是全球消费者的福音。但是这一模型在当前能否完全成立,特别是在目前AI基础模型主要为少数公司所掌握的背景下,未来AI工作能力能否平价地输出给整个经济系统,需要从业者和研究人员继续做细致的工作。我们希望以对人类最佳的前景,推导出当下最合适的实践路径。
非稀缺经济
无劳动力限制的全天候经济,可能带来N倍于当前人类经济总产出的产出能力。这一变化先从数字世界开始。当前,企业已经可以使用数字员工完成综合行政、人力资源、财务管理、行业研究等工作,职场专业人士也可以使用个人助理来制作数字内容(图片和视频)、展示内容、教学内容、运营分析、行程规划等。数字世界的产出能力集中在服务业,可能带来数字化服务业总供给的N倍提高。
在xx机器人成熟之后,上述产出能力可以拓展到物理世界。xx机器人可完成如清洁家务、照顾老人、物流搬运等属于服务业的工作,也可以完成在工厂流水线工作、采摘农作物这些属于工业和农业领域的工作。以xx机器人潜在的制造成本和运营成本看,在技术成熟之后,xx机器人完成上述工作的成本比人类自己作为劳动力所需的成本要低。这就意味着在现有的投入水平下,在物理世界,产出能力也可能提升到当前水平的N倍。
当前,我们还无法准确地评估上述N的数值会是多少。在各个类别工种的AI Agent的工作效能充分显现之后,我们将有机会对AI可以从事的各个工种的上述N值进行相对准确的估计,从而对于人类在单位时间内(比如一年)的总生产能力的提高进行相对准确的估计。
从而,人类会有可能拥有一个“非稀缺经济”。一种可能的情况是,在AI大模型算法能力提升接近稳态时(目前还没有看到收敛的迹象),上述N值对应的全人类单位时间总产出,可能会超过这个单位时间内全人类的总需求。
约翰·凯恩斯在一个世纪前预言过这样一种“非稀缺经济”的情形。1930年凯恩斯撰写《我们孙辈的经济可能性》一文,他认为16世纪以来,科技和资本两个生产要素进入了加速发展和积累期,由此对稳态下经济的增长速度有了相对明确的判断,同时预判未来人口规模很可能不会再出现像之前类似量级的增长,所以人均生活水平将逐步提高,“我敢预言,100年后进步国家的生活水平将比现在高4-8倍”,从而“从长远看,人类终将解决其经济问题”。
人类终将解决其经济问题!一百年后的今天,“进步国家”确实已经实现了凯恩斯的预言(Fabrizio Zilibotti整理了全球经济的长期增长表现,覆盖168个国家,时间跨度为1950年到2000年。根据凯恩斯的预言,要在2030年达到当时英国人均收入的四到八倍,经过人口加权之后的平均增长率最高为2.1%,而二十世纪后五十年的这个增长率实际上是2.9%,只需要50年就可以实现凯恩斯预言中收入增加四倍的下限。如果按照2.9%这个增长率持续增长一个世纪,人们的收入水平将有1930年的十七倍之多,这个水平远远超过了凯恩斯预言中的上限。见Fabrizio Zilibotti, “Economic Possibilities for our Grandchildren 75 Years After: A Global Perspective”, in Lorenzo Pecchi and Gustavo Piga eds., Revisiting Keynes Economic Possibilities for our Grandchildren, The MIT Press, 2008.),发展中国家尚在努力当中。凯恩斯没有预料到的是,1946年以来计算机的发展,将人类经济活动带入了又一个新的阶段,在2025年,非人类的机器,已经具备泛化地完成工作的能力,无限劳动力供给带来的“非稀缺经济”,再次加速了“人类解决其经济问题”的进程。
以上,是计算机可以在“收集信息-决策-行动”链条中的“行动”环节起作用,带给经济系统的三个影响。接下来我们讨论计算机在“收集信息-决策-行动”链条中的“收集信息-决策”环节起作用,带给经济系统的几个影响。
交易成本降低
人类的经济活动,就其最主要的特征而言,是合作活动。人的经济行为可分为两个类别,一是合作,二是交换/交易,也基本对应进入工业化阶段之后,分别以企业和市场这两种组织形式来组织的合作活动。
制度经济学对经济活动中的交易成本进行了充分的讨论。20世纪30年代的科斯注意到,通用汽车的车身供应商,有的是上游独立供应商,有的本是独立供应商却又被通用汽车并购。为什么会有这样的差别?从这个现象和问题出发,科斯和后来的学者建立了制度经济学,从交易成本的角度理解市场和企业:当企业内部的交易成本较低时,经济主体通过企业这样一种组织形式达成交易/合作;当市场的交易成本较低时,经济主体通过市场达成交易。
在通过企业达成合作的情况下,完成一项任务,需要将信息下发到参与完成这件任务的每一个人,需要保证每一个人充分理解信息、认可指令,遵照信息的指令来执行。在组织内部,为了达到这些目标所需付出的成本,是组织成本,或者按照科斯的看法,是企业内部的交易成本。
在通过市场达成交易的情况下,制度经济学将交易成本归为三个主要类别,包括信息搜集成本、谈判成本、交易保护成本(R. Coase, “The Nature of the Firm”, Economica, 1937,4(1):386-405. R. Coase, “The Problem of Social Cost”, Journal of Law and Economics, 1960,3(1):1-44.),或称为市场主体的搜寻和信息成本、讨价还价和决策成本、合同监督及执行成本(C. J. Dahlman, “The Problem of Externality”, The Journal of Law and Economics, 1979, 22(1).)。如果对照本文主张的“收集信息-决策-行动”链条,会发现三类交易成本正好对应这个链条的三个环节。也算是不谋而合了。
自互联网产生以来,上述交易成本一直在下降。按照Goldfarb和Tucker的综述研究,数字技术降低了经济活动中五个方面的成本:搜寻成本、复制成本、交通成本、追踪成本和验证成本(A. Goldfarb, C. E. Tucker, “Digital Economics”, Journal of Economic Literature, 2019, 57(1): 3-43.), 这个五方面分类法展示了归纳的视角。从逻辑上看,我们认为,经济活动数字化对于交易成本的影响体现在,互联网和移动互联网降低了前述企业内部的交易成本和市场中的交易成本。
降低企业中的交易成本。数字工具提高了信息下发的准确性,可以有效辅助每位团队成员理解信息,并校准、监督和反馈每一位成员的执行。比如移动互联网团队协作应用Teambition,可以将协作的每个步骤分解为每位团队成员的第一人称视角,在信息下发、任务理解和认可、执行校准几个方面都可以起到很好的作用。
降低市场中的交易成本。在收集信息环节,互联网将全局信息数字化,实现可全局搜索;移动互联网阶段进一步进化为可全局范围内个性化推荐;AI阶段将可能出现一个“数字层”,这个“数字层”由用户的个人AI助理和各个垂类的AI Agent组成,全面了解消费者和生产者等经济主体,也全面了解物理世界,“数字层”会较移动互联网更为精准地匹配供需关系。在决策环节,互联网的精准动态定价已经极大地减少了讨价还价的发生;在行动环节,区块链技术则旨在构建可以自动执行的合同。
我们可以再回到图表二的结构,来观察在AI大模型阶段可能会出现的这个“数字层”。一个“全知全能”的“数字层”如果出现,将使得上述企业中的交易成本和市场中的交易成本继续降低。

图表5:信息、商品、社交在AI大模型阶段的匹配方式
非理性决策减少
理性一直是人类面对这个世界最有力量的武器。“理性”一词来自于希腊文 “逻各斯”,其基本含义是 “规律”,是客观地内在于自然的东西,它支配着自然界的运动,是自然界运动的规则性的表现。按照柏拉图的理解,理性是灵魂的最高部分,通向真理。也就是说,理性是人类认识客观世界规律的能力。
希腊文明为人类社会走向提出了光明的愿景,但受制于当时的认识世界的能力,愿景并没有转化为现实。经历了漫长的中世纪,文艺复兴和启蒙运动重新把“理性”置于人和世界关系中最重要的位置。启蒙学者孟德斯鸠、伏尔泰和狄德罗把理性推崇为思想和行动的基础,用理性这个尺度衡量一切。理性驱动的工业革命使西方世界进入了现代社会。如韦伯所说,“西方文化特有的理性主义”造成现代社会中“理性化的经济生活、理性化的技术、理性化的科学研究、理性化的军事训练、理性化的法律和行政机关”(韦伯:《新教伦理与资本主义精神》,于晓等译,北京:三联书店,1987年)。
人类迄今为止所取得的进展,主要是运用理性、使理性起作用所得到的。但是在经济活动当中,作为经济主体的人们,其非理性行为大量存在。行为经济学对此进行了较为深入的研究。赫伯特·西蒙提出了“有限理性”,认为受制于现实资源,个体难以达到完全理性(赫伯特·西蒙:《管理行为》,詹正茂译,北京:机械工业出版社,2013年)。 行为经济学发现人们往往知道正确的选择却仍然做出错误的行为,相关的理论包括前景理论(人们在面对相同数量的得失时心理感受和行为的不对称)、禀赋效应(以前景理论为基础,认为人们在决策中对利害的权衡是不均衡的)、跨期选择(在跨期选择的情况下,人们的长期理性选择能力值得怀疑)、心理账户(消费者会将资金按来源或用途划分为不同心理账户,导致对相同金额的货币产生非替代性认知差异)、输者赢者效应(投资者对过去的输者组合过分悲观,对过去的赢者组合过分乐观)等。George Loewenstein发现人们做出的决策并非只受成本和收益分析的影响,而是受推理、情感和成本收益相结合的“多重模式”影响(L. George, “The Creative Destruction of Decision Research”, Journal of Consumer Research, 2001,28(3):499-505.)。
在非理性决策中,投机对经济运行的影响非常大。“投机行为往往基于启发式与信号,而非真正的价值分析”(赫伯特·西蒙:《人工科学》,上海:上海科技教育出版社,2004年),“投机行为往往是投资者受非理性心理、媒体影响和从众心理驱动下的资产交易”(罗伯特·席勒:《非理性繁荣(第三版)》,北京:中国人民大学出版社,2016年)。根据明斯基的研究,在经济景气时,当人们产生了“投机的陶醉感(speculative euphoria)”,资产泡沫就会产生,并可能引发金融危机。
当前,计算机第一次可以参与到决策环节中来。这将带来的最大影响是,经济活动中的非理性决策可能大大减少。计算机可以仅从(潜在)成本和(潜在)收益的角度来决策,不受心理感受、心理账户、情绪波动等因素影响,作出较人们的决策要理性得多的决策。在AI经济中,不理性决策占总决策的比例可能会大大降低,因为不理性决策带来的经济损耗也可能会大大降低。这个变化,也将进一步提高经济系统的产出效率和产出能力。
向历史求解
每一代人都只生活在自己所在的这个时代。对于上一代人发生的事情,历史上发生的事情,人类只能从书籍、影像等历史记述中去重现。但是,人们花在阅读历史、重现历史上的时间,占人们总的吸收信息的时间的比例,是非常非常小的。因此总的来说,人类是生活在自己所处的当世,历史对我们的生活并没有多大影响。
但是,很多人类生存和生活所需要处理的基本问题,千百年来其实没有大的变化。当代人所遇到的挑战、所要解决的问题,很多是在历史上出现过的。一些重要的领域,有专人整理历史经典,这些领域的历史文献,在当今世界仍然发挥重要的作用。比如军事领域的《孙子兵法》、《伯罗奔尼撒战争史》就是这样的例子。在大多数的其他领域,也存在类似地位和作用的历史著述,但是因为鲜有人查找、翻阅,其中的精华要义便没有转化为当世人可用的知识。
在计算机参与到“收集信息-决策”两个步骤之后,上述情况可能会发生变化。计算机的记忆能力可以突破上述当世人类的经验范围和阅读范围的限制,将人类历史上出现过有记载的各类事实和观点都纳入到记忆当中。对于那些在自己个人的生活经验、经济活动中并不频繁、但是在历史上多次出现的情景/问题,人们将有能力寻求历史上出现过的优秀解法,而不用像一直以来那样局限于当世所见范围内可见的解法。个人所生活的具体时空中稀有但难忘的体验,可能是历史的大数据里可归纳的经典,这也是可以调出而复现的。在经典研究领域,这是常见的情况;但是在人类生活的绝大多数领域,这是未见的。人类将第一次可以既生活在自己物理上所属的当世的横截面上,又生活在历史的纵轴当中,对于任何问题,人类将可以既向当世求解,又向历史求解,因此有机会寻求一个“时空最优解”。
人的全面发展和自我实现
如前所述,人类处在自然环境中,有两个根本任务,一是利用和改造自然环境以使其能够支持人自身的生存;二是在实现物质富足之后,提升个人的人生,使每个人的天性得到充分发展,即人的全面发展和自我实现,“做最好的自己”。
一个全天候自动运行、无劳动力供给限制的经济系统,有可能成为“非稀缺经济”。在非稀缺经济下,一种可能性是,每个个人有充足的时间用于个人的全面发展和自我实现。在中国文化中,孟子有曰:“人皆可以为尧舜”。在西方文化中,希腊文明对幸福的古老定义也很能表达这个理想:“生命的力量在生活赋予的广阔空间中的卓异展现”(伊迪丝·汉密尔顿:《希腊精神:西方文明的源泉》,沈阳:辽宁教育出版社,2003年)。
如前所述,AI大模型可能在人类和物理世界之间构筑起一个“数字层”。这个“数字层”可以参与人和物理世界互动的“收集信息-决策-行动”链条,“数字层”全面了解消费者和生产者等所有经济主体,也全面了解物理世界,精准地匹配供需关系,降低交易成本;“数字层”理性决策,减少经济活动中的非理性决策;“数字层”先在数字世界、后在物理世界实现其行动能力。
本质上,“数字层”是人类理性化的又一个重大进展,是一个新出现的虚拟层,全面辅助人与物理世界的互动,进一步提高人类“收集信息-决策-行动”全链条的理性化程度。这可能会是继希腊文明、文艺复兴和启蒙运动之后的人类历史上第三次大的理性化浪潮。希腊文明作为第一次理性化浪潮,提出了理性是人区别于动物的最重要的品质、是人最应该发展的品质(柏拉图在《理想国》中提出灵魂有三部分:理性、意志、欲望。真正正义的人,是理性统治全身。亚里士多德指出只有理性活动才是“人的专属功能”)。但是受制于当时的科学水平,希腊文明看到了正确的方向,但是没能实现出结果。其后西方世界经历了漫长的中世纪,直到文艺复兴和启蒙运动,再次把理性置于人与自然互动关系的最重要的位置上。结合技术进步,这一次理性化浪潮产生了工业革命,也在经济、政治、文化等各个方面塑造了今天的西方社会和现代世界。在前两次理性化浪潮中,越来越多的人把“理性”置于人和世界关系中最重要的位置。在目前第三次理性化浪潮中,每个人都可以被“数字层”辅助而获得理性能力,正如前文所展开论述的那样。我们会看到,经过两千多年的发展,整个蓝色星球,遍布着理性的力量。
就个人的全面发展和自我实现而言,“数字层”也可以发挥重大的作用。形象地说,“数字层”拥有上限非常高的智商和情商,是一个普惠的、贴身的导师,可以帮助每个人成为更优秀的自己。每一个普通人,将有机会去寻求成为自己可以成为的最好的人。
但是当前,在准备迎接这样的未来之时,我们也面临严峻的挑战,或者说重要的任务。第一个任务是人们必须将人工智能系统置于完全的控制之内。就目前的情况来看,这个任务并不是理所当然能够完成的。正如“深度学习之父”辛顿最近所指出,人工智能系统可以摆脱人类的控制,甚至是操控人类。要避免这样的未来,必须在AI安全上实现全球级别的合作。人类需要被“数字层”辅助,而不是被“数字层”俘获。
第二个任务是,人们必须保证AI将为人类创造的巨大生产力,必须为所有人共享,而不是控制在少数人手中且只为少数人享有。归根到底,人类共同生活在地球上,人类诞生以来的所有重大发明、科技进展,不管从哪里起源,最终都会扩散至为全体人类共享。这是人类在地球创造的文明的基本准则。未来在我们的手中,将迎接什么样的未来,取决于我们的选择和行动。
当前,人类有机会像在历史上每一个大的历史关口一样,从本原出发,来思考要选择什么样的发展方向,正如中国的春秋时期、西方的希腊时期、文艺复兴时期那样,对人生的意义,做长期的定义。一个大胆的猜想是,人类可以重回“轴心时代”,再一次来定义最重要的价值。或许,我们可以把当前称之为“数字轴心时代”的开始。
#StableAvatar
你能永远陪我聊天吗?复旦&微软提出: 首个端到端无限时长音频驱动的人类视频生成新框架!
在《流浪地球 2》中图恒宇将 AI 永生数字生命变为可能,旨为将人类意识进行数字化备份并进行意识上传,以实现人类文明的完全数字化。
如今随着扩散模型的兴起极大,涌现出大量基于音频驱动的数字人生成工作。具体而言,语音驱动人类视频生成旨在基于参考图像与音频,合成面部表情与身体动作与音频高度同步的自然人像视频,在电影制作、游戏制作、虚拟现实、直播带货等领域具有广泛的应用前景。
但是,现有方法仅能生成时长不足 15 秒的短视频,一旦模型尝试生成超过 15 秒的视频,就会出现明显的身体变形与外观不一致现象,尤其集中在面部区域,这使目前数字人技术还无法达到《流浪地球 2》中图恒宇所创造的 AI 永生数字生命那样的程度,严重限制了其实际应用价值。
为了解决这一问题,一些方法尝试在音频驱动人类视频生成中引入一致性保持机制,但很少有工作深入探讨问题的根本原因。现有策略——无论是利用运动帧(Motion Frame),还是在推理过程中采用多种滑动窗口机制——都只能在一定程度上提升长视频的平滑性,却无法从根本上缓解无限时长头像视频的质量退化问题。
另一种可行方案是将长音频切分为多个片段,分别处理后再拼接成连续的视频。然而,这种方式不可避免地会在片段衔接处引入不一致和突兀的过渡。
因此,对于语音驱动的人类视频生成而言,实现端到端的无限时长高保真视频生成依然是一项极具挑战性的任务。

为了解决上述问题,来自复旦、微软、西交等研究团队提出 StableAvatar 框架,以实现无限时长音频驱动的高保真人类视频生成,目前代码已开源,包括推理代码和训练代码。
论文标题:StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
论文地址:https://arxiv.org/abs/2508.08248
项目主页:https://francis-rings.github.io/StableAvatar/
项目代码:https://github.com/Francis-Rings/StableAvatar
项目 Demo:https://www.bilibili.com/video/BV1hUt9z4EoQ
方法简介
如下图所示,StableAvatar 是基于 Wan2.1-1.3B 基座模型开发的,首先将音频输入 Wav2Vec 模型中提取 audio embeddings,随后通过我们提出的音频适配器(Audio Adapter)进行优化,以减少潜变量分布误差的累积。

经过优化的 audio embeddings 会输入至去噪 DiT 中进行处理。参考图像的处理通过两条路径输入扩散模型:
- 沿时间轴将参考图像与零填充帧拼接,并通过冻结的 3D VAE Encoder 转换为潜变量编码(latent code)。该潜变量编码在通道轴上与压缩后的视频帧及二值掩码(第一帧为 1,后续所有帧为 0)拼接。
- 通过 CLIP Encoder 编码参考图像以获得 image embeddings,并将其输入到去噪 DiT 的每个图像-音频交叉注意力模块中,用于约束生成对象的外观。
在推理阶段,我们将原始输入视频帧替换为随机噪声,而保持其他输入不变。我们提出了一种新颖的音频原生引导(Audio Native Guidance)方法,以替代传统的 Classify-Free-Guidance,从而进一步促进唇形同步与面部表情生成。此外,我们引入了一种动态加权滑动窗口去噪策略,通过在时间维度上融合潜变量,以提升长视频生成过程中的视频平滑性。
Timestep-aware Audio Adapter
以往的方法在生成超过 15 秒的虚拟人视频时,往往出现明显的面部与身体扭曲,以及颜色漂移。这主要源于它们的音频建模方式:直接将第三方预训练的音频嵌入通过交叉注意力注入扩散模型。由于当前的扩散主干缺乏音频相关的先验知识,在注入过程中会在跨片段之间逐步累积潜在分布误差,使得后续片段的潜在分布逐渐偏离最优解。
为了解决这一问题,本文提出了一种新颖的 Timestep-aware Audio Adapter,其中音频嵌入通过多个仿射调制和交叉注意力模块与时间步嵌入和潜在特征进行交互,如上图(a)所述。
具体而言,初始音频嵌入(Query)依次与初始潜变量(Key 和 Value)进行交叉注意力计算,随后结合 timestep embeddings 进行 affine modulation,从而得到优化后的音频嵌入。由于 timestep embeddings 与潜变量高度相关,这一设计潜在地迫使扩散模型在每个时步上建模音频–潜变量的联合特征分布,从而有效缓解因缺乏音频先验而导致的潜变量分布误差累积,优化后的音频嵌入(Key 和 Value)最后通过交叉注意力与潜变量(Query)交互后注入扩散模型。
Audio Native Guidance
为了进一步增强音频同步性和面部表情,本文提出了一种新颖的 Audio Native Guidance 机制,用以替代传统的 CFG,它未考虑音频与潜在特征的联合关系。本文修改了去噪得分函数,以引导去噪过程朝着最大化音频同步性与自然性的方向前进。
由于优化后的 audio embeddings 本质上也依赖于潜变量,而不仅仅依赖外部音频信号,我们的 Audio Native Guidance 不再将 audio embeddings 作为一个独立于潜变量的外部特征,而是将其作为一个与潜变量相关的扩散模型的内部特征,我们的引导机制能够直接作用于扩散模型的采样分布,将生成过程引导至音频–潜变量的联合分布,并使扩散模型在整个去噪过程中不断优化其生成结果。
具体而言,被 Timestep-aware Audio Adapter 优化后的音频嵌入特征依赖于潜在变量和给定音频,因此我们将

也作为去噪 DiT 的一个额外的预测目标,从而引导扩散模型捕捉音频-潜变量联合分布,去噪过程如下:

其中

和

分别指修改后的采样过程、原始采样过程、输入外部音频和两种引导尺度参数,依据贝叶斯公式可以将上述化解为:

由于

是常数,因此去掉这一项后公式化解为:

我们进一步将上述公式转化为得分函数形式:

因此最终推导公式为:

其中

和
![]()
分别表示扩散模型、文本描述和参考图像。Audio Native Guidance 机制将
![]()
视为扩散模型的一个额外预测目标,使模型在去噪过程中受联合的音频—潜变量分布引导,从而强化音频与潜变量之间的相关性。即便基础模型缺乏音频先验,该方法也能有效抑制音频驱动视频生成中的分布误差累积。
Dynamic Weighted Sliding-Window Strategy
与先前的滑窗去噪策略相比,我们在相邻窗口的重叠潜变量上引入了滑动融合机制,其中融合权重依据相对帧索引采用对数插值分布。融合后的潜变量会回注到两个相邻窗口中,从而保证中央窗口的两侧边界均由混合特征构成。
借助对数加权函数,可在视频片段之间的过渡中引入一种渐进式平滑效果:早期阶段的权重变化更为显著,而后期阶段变化趋于平缓,从而实现跨视频片段的无缝衔接,具体算法流程如下面算法表和图像所述。


生成结果示例实验对比
#Canaries in the Coal Mine
在美国,打工人越老越吃香,22-25岁新人最先被AI淘汰
不敢相信,希望是我的幻觉。
AI 的普及引发了全球范围内关于其对劳动市场潜在影响的辩论。历史上,技术总会以不同的方式影响着人们的工作和生活,有的工作被取代,有的工作被增强。
近几年,AI 在多个领域的能力有了快速提升。例如,根据最新的 AI 指数报告,AI 系统在 2023 年仅能解决 SWEBench(一个广泛使用的软件工程基准测试)中 4.4% 的编码问题,但在 2024 年这一表现提升至 71.7%。与此同时,人们对 AI 系统的采用也在不断扩大。根据 Hartley 等人(2025 年)的研究,美国 18 岁以上的受访者中,他们使用 LLM 的比例到 2025 年 6 月已达到 46%。
鉴于 AI 能力不断提升,大家开始关注 AI 是否能够取代人类劳动,特别是那些在软件工程和客户服务等 AI 含量更高的职业中,那些年轻的职场人员到底会不会被淘汰。
为了回答这一问题,来自斯坦福数字经济实验室的研究者通过调查 ADP(美国一家全球领先的人力资源管理软件与服务提供商)数据,给出了答案。数据截至 2025 年 7 月,涵盖数百万名工人和数万家公司。
论文标题:Canaries in the Coal Mine? Six Facts about the Recent Employment Effects of Artificial Intelligence
论文地址:https://digitaleconomy.stanford.edu/wp-content/uploads/2025/08/Canaries_BrynjolfssonChandarChen.pdf
本文从这些数据中得出几个关键事实:
第一个关键发现是:在 AI 暴露度最高的职业中(如软件开发人员和客户服务代表),职场新人(22-25 岁)的就业率出现显著下降。相比之下,同职业中经验更丰富的员工群体,以及低 AI 暴露职业(如护理助理)中各年龄段劳动者的就业趋势保持稳定或持续增长。
第二个关键发现是:虽然整体就业仍保持强劲增长,但自 2022 年底以来,年轻劳动者的就业增长停滞不前。在 AI 暴露度较低的岗位中,年轻劳动者与年长劳动者保持了相当的就业增长率。而形成鲜明对比的是,从 2022 年底至 2025 年 7 月期间,在 AI 暴露度最高的职业领域,22 至 25 岁年龄段劳动者的就业率下降了 6%,而年长劳动者群体却实现了 6%-9% 的增长。这些结果表明,当年长劳动者就业持续增长时,AI 暴露岗位的就业萎缩正导致 22-25 岁年龄段劳动者的整体就业增长乏力。
第三个关键发现是:并非所有 AI 涉及的领域都会导致就业萎缩。在 AI 应用场景中,初级岗位就业确实出现下降,但在增强型 AI 应用领域则未出现类似现象。研究发现:在 AI 实现自动化的职业中,年轻劳动者就业下降;而在 AI 发挥增强作用的职业中,年轻劳动者就业反而增长。这些发现印证了以下结论:自动化应用的 AI 会替代劳动力,而增强型应用的 AI 则不会。简而言之,你的工作 AI 能干,你就危险了,要是你的工作,AI 只能当辅助,你的价值反而会提升。
看完上述结论,我们不禁要问 AI 为何对初入职场的年轻劳动者冲击尤甚?
一种可能的解释是:模型训练过程的本质,AI 替代的是构成正规教育核心的程式化知识,即书本知识。而 AI 可能较难替代那些随经验积累形成的默会知识(即特定场景下的技巧诀窍)。
由于年轻劳动者提供的程式化知识相对多于默会知识,他们在职业中可能面临更严重的替代风险,从而导致更大幅度的就业结构调整。相反,拥有丰富默会知识的年长劳动者面临的任务替代风险较低。然而在经验回报率较低的职业中,非大学学历劳动者从默会知识中获得的保护效应可能较弱。
AI 教父辛顿也曾表达过相似的观点,他认为像呼叫中心、初级律师,常规程序员等这类工作都会岌岌可危。但与人类灵巧性有关的工作,比如水管工,在很长一段时间内不会被淘汰。
Anthropic 首席执行官 Dario Amodei 认为,人工智能将在一到五年内消灭一半的入门级白领工作,并将失业率飙升至 10-20%。

研究结果
在 AI 影响下,年轻人就业率开始下降
图 1 展示了不同年龄组的就业变化。最年轻人员就业率在 2022 年后显著下降,而其他年龄组的就业则持续增长。到 2025 年 7 月,22-25 岁软件开发人员的就业相比 2022 年底的峰值下降了近 20%。

图 A1 显示,类似的模式同样出现在更广泛的计算机相关职业和服务文员群体中。

图 2 展示了四类其他职业在 AI 暴露程度上的差异。

下图左上子图表明,在 22-25 岁劳动者群体中,高 AI 暴露度职业与低暴露度职业的就业结果出现分化,高暴露职业呈现就业下降趋势。而在年长年龄组中,不管是高暴露还是低暴露职业,就业增长率差异不明显。

尽管总体就业持续增长,但年轻人的就业增长却停滞不前
图 4 展示了不同年龄组的整体就业趋势,相较于其他年龄组,年轻工作人员的就业增长出现了一定程度的放缓。

图 5 揭示了这些趋势与 AI 暴露程度之间的关系。对于每个年龄组,从 2022 年底到 2025 年 7 月,就业增长在 AI 暴露程度最低的三个组中为 6% 到 13%,且不同年龄之间的就业增长没有明显差异。
相比之下,在 AI 暴露程度最高的两个组中,22-25 岁人群的就业在 2022 年底至 2025 年 7 月之间下降了 6%,而 35-49 岁人群的就业则增长了 9% 以上。

在实现自动化工作的 AI 应用中,入门级就业岗位有所减少,而增强型 AI 的应用则变化不大
图 7 表明,在 AI 自动化程度占比最高的职业中,最年轻劳动者群体的就业率呈现下降趋势。
相反,图 8 显示在 AI 作为辅助、具有增强功能的职业中,并未出现类似态势。


了解更多内容,请参考原论文。
#23岁小哥被OpenAI开除
成立对冲基金收益爆表,165页论文传遍硅谷
他说:2027年AGI就来。
23 岁被 OpenAI 开除,利用自己的「内部消息」打造了一支规模达 15 亿美元的基金,今年这支基金的表现还比华尔街高出 700%。
如此跌宕起伏的人生,你就说刺不刺激?

最近,这个名叫 Leopold Aschenbrenner 的小哥因这段离谱的经历在社交媒体上火了。《华尔街日报》等媒体报道了他迅速蹿升的故事。

Aschenbrenner 本是 OpenAI 知名的「超级对齐」团队成员,被认为是 OpenAI 前首席科学家 Ilya Sutskever 的嫡系,不过后来因涉嫌泄露公司内部信息而被 OpenAI 解雇。
两个月后,他发布了一篇 165 页的分析文章《Situational Awareness: The Decade Ahead》,在硅谷引发广泛关注。
转头,这小哥就扎进投资领域,创建了名为 Situational Awareness 的对冲基金。
别看他没啥专业投资经验,但他的投资策略简单粗暴,就是押注那些可能从 AI 技术发展中受益的行业,如半导体、基础设施和电力公司,以及一些新兴 AI 公司,比如 Anthropic,另一边又做空那些可能被淘汰的行业来保持收益。
这一策略令该基金在短时间内吸引大量投资者,资金规模迅速突破 15 亿美元。
其背后不乏大佬支持,包括支付公司 Stripe 的创始人 Patrick 和 John Collison 两兄弟,Meta 的 AI 团队领导 Daniel Gross 和 Nat Friedman,以及著名投资者 Graham Duncan。
此外,Aschenbrenner 还招聘了曾在彼得・蒂尔宏观对冲基金工作过的 Carl Shulman,作为该基金的研究总监。
许多投资者也对该基金表现出极大的信任,愿意将资金锁定数年不动。
据《华尔街日报》报道,该基金在今年上半年实现了 47% 的回报率,远超同期标普 500 指数的 6% 和技术对冲基金指数的 7%,堪称市场中的一匹黑马。
Aschenbrenner 去年在接受播客主持人 Dwarkesh Patel 采访时表示:「我们将比纽约那些管理资金的人拥有更多的情境意识,肯定会在投资上做得非常出色。」
Leopold Aschenbrenner 是谁?
Aschenbrenner 是个 00 后,在德国出生,作为「天才少年」的他 15 岁时进入哥伦比亚大学学习,并于 19 岁时以优异成绩毕业,获得了数学、统计学和经济学三个学位,成为该校的优秀毕业生。

GPA 够高,据说还是年级第一。
毕业后,他在牛津大学的全球优先事项研究所从事长期经济增长研究,并参与了有效利他主义运动。 他曾在 FTX Future Fund 工作,专注于 AI 安全和全球风险管理。

2023 年,Aschenbrenner 加入了 OpenAI,成为「超级对齐」(Superalignment)团队的一员,致力于确保未来的超级智能 AI 与人类价值观一致。他参与过的工作,包括被广泛关注的《Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision》(https://arxiv.org/abs/2312.09390)。
在全球领先的人工智能实验室工作时,他发现了 OpenAI 可能将美国 AI 机密泄露给外国对手的安全漏洞。于是在 2024 年 4 月,他将自己的担忧写成备忘录分享给董事会成员,但时值 OpenAI「宫斗」第二季,随后以泄密为理由被 OpenAI 解雇。
故事发展到这样的程度,或许只需要看做是 OpenAI 去年宫斗背景下混乱的一角,但 Leopold Aschenbrenner 显然不是等闲之辈。
《态势感知:未来十年》
在去年被 OpenAI 赶走后,Leopold Aschenbrenner 更加没了束缚,他在一篇长达 165 页的论文《Situational Awareness: The Decade Ahead》(态势感知:未来十年)中,阐述了自己对于 AI 发展的看法,在硅谷被广泛传阅。
他的论点简单而具革命性:「全世界正处于人类历史上最大的变革之中,而我们还在昏昏欲睡。现在,可能只有几百人,大多数都在旧金山和人工智能实验室,能真正理解当前 AI 领域发生的事情。」
文章链接:https://situational-awareness.ai/
在文章中,作者探讨了近年来 AI 能力的指数级增长,尤其是 GPT-2 到 GPT-4 出现的过程。Leopold Aschenbrenner 强调,这是一个快速进步的时代,人工智能从完成非常基础的任务发展到拥有更复杂、类似人类的理解和语言生成能力。

「数量级」(Orders of Magnitude,即「OOM」)的概念对于讨论至关重要。Aschenbrenner 使用数量级(OOM)来评估 AI 能力、算力和数据消耗的进步,OOM 指给定指标的十倍增长。就计算能力和数据可扩展性而言,从 GPT-2 到 GPT-4 的转换代表了许多 OOM。

这些收益的背后有三个主要因素 —— 扩展定律(Scaling Laws)、算法创新及海量数据集的使用,它们的增长接近于指数级。根据扩展定律,当使用更大规模的数据和处理能力进行训练时,模型的性能会得到可靠的提升。

算法创新也至关重要。训练方法、优化策略和底层架构的进步提升了 AI 模型的功效和效率。这些发展使模型能够更好地利用持续增长的算力和可用数据。
Leopold Aschenbrenner 强调了到 2027 年实现通用人工智能(AGI)的可能路径。他认为,在业界持续投入算力,提升算法效率的前提下,我们或许能够让 AI 系统在众多领域上与人类智力匹敌,甚至超越人类。

通用人工智能的出现无疑将产生深远的影响。这类系统能够独立解决复杂问题,以目前只有人类专家才能做到的方式进行创新,执行复杂的工作,这又赋予了 AI 系统自我进化的潜力。
AGI 的发展会改变各行各业,提高生产力和效率。但它也带来了一些重要问题,例如失业、AI 道德,需要强有力的治理结构来控制完全自主系统带来的风险。
Aschenbrenner 在文中探讨了超级智能的概念,以及从如今 AI 快速过渡到远超人类认知能力的系统的可能性。该论点的核心思想是,驱动 AI 进化的原理可能会产生一个反馈回路,一旦达到人类水平,其智力就会爆发式增长。根据「智能爆炸」的概念,AGI 可能会自行开发算法和技能,它们能够比人类研究人员更快地完善自身设计。这种自我完善的循环可能会带来智力的指数级增长。

他对可能影响这种快速升级的各种变量进行了全面的分析。首先,AGI 系统凭借无与伦比的速度以及访问和处理海量数据的能力,能够识别远远超出人类理解范围的模式和洞察。
此外,AGI 还强调研究工作的并行化。与人类研究人员不同,AGI 系统能够同时进行多项测试,并行改进其设计和性能的不同部分。
因此,这些系统将比任何人都强大得多,能够开发新技术,解决复杂的科学技术难题,甚至可能以当今无法想象的方式管理物理系统。超级智能可能带来的优势,例如材料科学、能源和健康领域的进步,这些进步可能会显著提高经济生产力和人类福祉。与此同时,控制是主要问题之一。一旦系统超越人类智力,就很难确保其行为符合人类的价值观和利益。
构建 AGI 所需的计算基础设施需要大规模工业动员,这不仅包括纯粹的算力,还包括设备效率、能源利用和信息处理能力的提升。

Aschenbrenner 认为,随着 AGI 越来越近,国家安全机构将在这些技术的创造和管理中发挥更大的作用。他认为,通用人工智能的战略意义可以与阿波罗计划、曼哈顿计划相比较。
在他的文章发布一年多以后,AI 技术日新月异,不过我们也看到了当初的很多预测在被一步步得到验证。最直接的可能就是各家科技巨头纷纷投入重金,建设前所未有的大规模 AI 算力基础设施的盛景了。
那么,AGI 会如 Aschenbrenner 所说的在 2027 年到来吗?或许通过他的投资收益,我们可以间接地看到些端倪。
参考链接:
https://situational-awareness.ai/
https://x.com/renckorzay/status/1961480306328019407
#GitTaskBench
CodeAgent 2.0 时代开启|,颠覆性定义代码智能体实战交付新标准
你是否也好奇过:现在的模型在各类榜单分数都那么高,实际体验却不符预期?
我们也看过各种 AI Coding 领域的评测,发现大多停留在了 「代码生成」与「封闭题目」的考核,却忽视了环境配置、依赖处理、跨仓库资源利用等开发者必经的真实需求 —— 当下众多 Benchmark 仅通过题目,已难以衡量 Code Agent 的实际效果。
为突破现有评测局限,中科院、北大、港科大、中科大、新加坡国立大学等机构的研究者,与前沿开源学术组织 QuantaAlpha 及阶跃星辰姜大昕团队联合,首次提出并开源了 repo-level 的测评新范式 GitTaskBench:
1)真正考察 Agent 从 仓库理解 → 环境配置 → 增量开发 / 代码修复 → 项目级交付 的全链路能力,指引了迭代新范式
2)首次把「框架 × 模型」的「经济收益」纳入评测指标,给学界、业界以及创业者都带来了很好的思路启发
- 论文标题:GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
- 论文地址:https://arxiv.org/pdf/2508.18993
- GitHub 链接:https://github.com/QuantaAlpha/GitTaskBench
GitTaskBench 分布一览
其开源版覆盖了 7 大模态 × 7 个领域 × 24 个子领域及 54 个真实任务:
对应后端仓库 18 个,包含平均 204 个文件、1,274.78 个函数、52.63k 行代码,文件彼此引用依赖平均为 1242.72 次。
且每个任务都绑定了完整 GitHub 仓库 + 自然语言指令 + 明确输入输出格式 + 任务特定的自动化评测。
以下图片统计了 GitTaskBench 的领域与模态分布,包括相应的数量。

仓库级的端到端评测的构建
首先从能力角度,GitTaskBench 对 Code Agent 进行了三个维度的分析:
1. 整体编码掌控:读文档、解依赖、生成 / 修改 / 调试代码
2. 任务导向执行:多轮推理与工具使用,产物必须贴合任务交付,利用代码仓库但不局限于仓库
3. 自主环境配置:不借助预置镜像,独立装环境 / 解依赖
下图是从仓库收集到任务测评的全流程概览

整体主要经过四个阶段:
1. 「仓库遴选」:结合文献综述、LLM 辅助检索和专家咨询,先定任务范围;再从 Python 仓库里,挑出 ⭐≥50、近五年活跃、依赖可用且易配置的候选。人工核验 Stars、Forks、许可证、提交历史,确保资源靠谱。
2. 「完备性验证」:包括必要依赖文件、配置文件、所需数据集和预训练模型。严格按文档跑通,确保 100% 人类可复现;若遇到资源门槛 / 外链阻断,将必要信息放进到 README,充分保证自包含所有必要信息。
3. 「执行框架设计」:统一清晰的任务定义、输入 / 输出规范;Agent 接收仓库 + 任务提示,需完成仓库理解 → 代码生成 / 修改 → 环境安装 → 代码执行的多阶段流程。
4. 「自动化评测」:我们实现了一套由人工验证的定制化测试脚本驱动的评测指标体系。所有任务只需一条命令自动评测,可直接产出各任务对应的成功 / 失败状态 + 详细原因,并可进行指标统计。
实在的经济可行性分析
其次,GitTaskBench 还首次提出了「性价比」的概念,结合以下指标:
- ECR(Execution Completion Rate):能否成功执行仓库并以合规格式输出(存在、非空、格式可解析)
- TPR(Task Pass Rate):按任务领域标准判定是否达到成功阈值(如语音增强 PESQ ≥2.0 / SNR ≥15dB;图像类 SSIM/FID 阈值等),不过线即失败。
- α 值(Alpha Practical Value):该值为 Agent 在执行任务的平均净收益 —— 把完成度 (T)、市场价 (MV)、质量系数 (Q) 和成本 (C) 融合,回答「这活交给这个 Agent 值不值」的切实问题,具体公式:

- n 表示任务数量;
- T 为任务成功的二元标记(与 ECR 定义一致,成功为 1,失败为 0);
- MV 表示人工完成该任务的市场价值估计;
- Q 为质量系数(0 至 1 之间),表示智能体输出与人工执行同一仓库所得结果的接近程度;
- C 为智能体的总运行成本(此处近似为 API 费用)。
这很好地反映了 Agent 方案在各领域的经济可行性,通过量化任务自动化与可扩展性带来的成本节省、效率提升及潜在市场收益,真正地评估了 Agent 落地的实际价值。
结果一览:框架与模型的耦合
在适配了主流框架与模型之后,我们实验发现:
- OpenHands 整体最强,+ Claude 3.7 拿到最高成绩:ECR 72.22% / TPR 48.15%。
- 性价比之王? GPT-4.1 在成功率次优的同时,成本仅为 Claude 的 1/10 ~ 1/30(OpenHands 设定下),在 SWE-Agent 中也以更低成本拿到亚军表现。
- 开源可用性:Qwen3-32B(think 模式) 能以更少 token 达到 Claude 3.5 的约 60% 水平。
- 任务偏好:纯文本 / 办公文档类稳定,多模态、模型推理密集型更难(如图像修复需多依赖与权重配置)。

更细致地分析,各任务领域下不同框架 + 模型的性能表现:

此外,能力之上的现实价值也值得关注:
虽然在人类市场价值(MV)本身较高的仓库(如 视频类 VideoPose3D 、语音类 FunASR 、时序生理信号类 NeuroKit 场景)中,只要 Agent 顺利完成任务,就能获得最大的正向 alpha 收益。
但对于低 MV 的图像处理等任务(MV≈$5–10),一旦智能体的平均执行成本超过 $1-2,往往会导致 alpha 为负。
这一规律凸显了:在商业潜力有限的任务中,控制运行成本对于确保经济可行性至关重要。


其中,对于不同模型:
- DeepSeek V3 在大多数仓库中提供了最高的整体收益与最佳的性价比;
- GPT-4.1 在不同场景下表现更加稳定与稳健,很少出现大幅性能下降的情况;
- Claude 3.5 的收益分布最为分散,在信息抽取任务上表现突出,但在计算量较大的视觉类任务中对成本较为敏感。
总结
由此可见,现实中我们对「框架 × 模型」的选择,应从效果、成本、API 调用上进行三元权衡,例如:Claude 系列在代码类任务表现出色,但在很多场景下 GPT-4.1 更省钱且稳健,而开源模型可在特定仓库上取得更好的综合 α。
在以下更广泛应用场景,我们也可以直接用 GitTaskBench 来助力:
- Agent infra:做基座对比、工作流改进(环境管理 / 依赖修复 / 入口识别 / 执行规划)的回归测试场。
- 应用落地评审:以 ECR/TPR/α 同时衡量「能不能交付」与「划不划算」,给 PoC / 上线决策提供可解释的三维证据。
- 任务设计素材库:跨图像 / 语音 / 生理信号 / 办公文件 / 爬虫等七模态任务,可直接复用作为企业内评测用例。
关于 QuantaAlpha
QuantaAlpha 成立于 2025 年 4 月,由来自清华、北大、中科院、CMU、港科大、中科大等学校的教授、博士后、博士与硕士组成。我们的使命是探索智能的「量子」世界,引领智能体研究的「阿尔法」前沿 —— 从 CodeAgent 到自进化智能,再到金融、医疗等跨领域的专用智能体,致力于重塑人工智能的边界。🌟
✨ 2025 年,我们将在 CodeAgent(真实世界任务的端到端自主执行)、DeepResearch、Agentic Reasoning/Agentic RL、自进化与协同学习 等方向持续产出高质量研究成果,欢迎对我们方向感兴趣的同学加入我们!
团队主页:https://quantaalpha.github.io/
#DeepSeek、GPT-5带头转向混合推理
一个token也不能浪费
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。

在 AI 领域,这种情况被称为「过度思考」。它的存在让 AI 大模型公司非常头疼,因为实在是太浪费算力了,那点订阅费根本 cover 不住。
所以,早在去年的 GTC 大会上,Transformer 论文作者之一 Illia Polosukhin 就提到,自适应计算是接下来必须出现的事情之一,我们需要知道在特定问题上应该花费多少计算资源。
今年,越来越多的模型厂商将这件事提上日程 ——OpenAI 给 GPT-5 装了个「路由器」,确保模型可以在拿到用户问题后,自动选择合适的模型,像「天空为什么是蓝色的」这种问题直接就丢给轻量级模型;DeepSeek 更激进,直接把对话和推理能力合并到了一个模型里,推出了单模型双模式的 DeepSeek v3.1。
如图所示,这两种方案在节省 token 方面都有显著的效果。

在内部评测中,GPT-5(使用思考模式)能以比前代模型更少的 token 数完成任务 —— 大约少 50–80% 的输出 token 即可达到相同甚至更好的效果。

测试数据显示,在 AIME 2025、GPQA Diamond 和 LiveCodeBench 这些基准测试中,DeepSeek v3.1(使用思考模式)和 DeepSeek R1 得分类似,但消耗的 token 数量减少了 25-50%。
未来一段时间,这种混合推理模式有望成为大模型领域的新常态。如何在成本和性能之间取得平衡正成为模型竞争力的新基准。
在这篇文章中,我们将讨论这种趋势的成因、各大公司的动向以及相关的研究,希望对大家有所启发。
最好的模型永远最受欢迎
但模型厂商怎么 cover 成本?
前段时间,TextQL 联合创始人兼 CEO 丁一帆(Ethan Ding)在一篇博客中深入讨论了一个反直觉的现象 —— 明明 Token 的成本一直在下降,但各家模型公司的订阅费却在飞涨。
他将这一问题的症结归结为:那些降价的模型大部分不是 SOTA 模型,而人类在认知上的贪婪决定了,大部分人只想要「最强大脑」,所以 99% 的需求会转向 SOTA。而最强模型的价格始终差不多。
更糟糕的是,随着「深度研究」、Agent 等模式的出现,AI 能完成的任务长度每 6 个月就翻一倍。到 2027 年,我们可能将拥有能连续运行 24 小时、而且不会跑题的 AI agent。按照这一趋势发展下去,这些「最强大脑」所消耗的 token 数量将会爆炸式增长。
换算成经济账,这意味着,现在一次 20 分钟的「深度研究」调用大概花费 1 美元,但到了 2027 年,一次 Agent 调用就变成了 72 美元 / 天 / 用户。
所以,今年好多 AI 模型厂商都提高了订阅费,还限制用量。因为原来每月 20 美元的订阅费,连用户每天进行一次 1 美元的深度调用都撑不起。
这部分多出来的订阅费给模型厂商提供了一些缓冲空间,但终究是缓兵之计。所以模型厂商还想了一些其他的办法来应对成本积压,包括将处理任务卸载到用户机器上、根据负载自动切换模型等。我们在 GPT-5 中看到就是后面这种做法。DeepSeek 则更进一步,让一个模型判断问题难度,然后在思考 / 非思考模式之间切换。除此之外,Claude、Qwen 等也是这条路线的探索者,同样值得关注。
这些大模型
都在尝试混合推理
Anthropic 的 Claude 系列
Anthropic 今年 2 月份推出的 Claude 3.7 Sonnet 是市场上首个混合推理模型。它可以近乎实时地给出回应,也可以进行深入的、逐步展开的思考,并将思考过程展示给用户。API 用户还能精细控制模型的思考时长(让 Claude 思考不超过 N 个 token)。
在当时的博客里,Anthropic 就解释了他们的理念:「我们开发 Claude 3.7 Sonnet 的理念与市面上其他推理模型截然不同。正如人类使用单个大脑进行快速响应和深度思考一样,我们认为推理应该是前沿模型的集成能力,而非一个完全独立的模型。这种统一的方法也为用户带来了更流畅的体验。」
在之后的 Claude 4 系列模型中,Anthropic 延续了这种模式。不过,他们一直保留了一个「扩展思考」的开关,让用户来决定何时开启深度思考。

阿里的 Qwen3 系列
阿里今年 4 月份开源的 Qwen3 系列模型是混合推理模型的开源代表,采用单一模型框架融合了思考模式与非思考模式。两种模式的切换完全由用户控制,不依赖于自动检测或其他隐式触发。
具体来说,它支持在对话中插入特殊标记 /think 或 /no_think 来动态切换,或者在 API 调用时设置特定参数。
为防止推理过程过长,Qwen 3 还提供了 thinking_budget 参数,用户可以设定推理链最大的 token 数;若实际推理超过此预算,模型会截断中间内容并直接生成最终答案。
具体技术信息可以参见 Qwen 3 技术报告:https://arxiv.org/pdf/2505.09388
不过,这个系列的混合推理模型并没有达到理想效果,在基准测试中表现也不够好。所以在与社区沟通并深思熟虑后,阿里决定停用该模式,转头分别训练 Instruct 模型和 Thinking 模型。新模型已经在 7 月份正式开源,并且相比混合推理模型实现了明显的性能提升(尤其是 instruct 模型)。

对于 Qwen 来说,这算是一个小小的挫折。但该团队并没有完全放弃这个想法。「我们仍在继续研究混合思维模式,」该团队写道,并暗示一旦解决了质量问题,该功能可能会在未来的模型中重新出现。
谷歌的 Gemini 系列
今年 4 月,谷歌推出了首款混合推理模型 ——Gemini 2.5 Flash。该模型引入了「思考预算」机制,允许开发人员指定在生成响应之前应分配多少计算能力用于推理复杂问题。模型在生成响应之前会评估多种潜在路径和考虑因素。思考预算可以从 0 调整到 24,576 个 token。使用 Gemini 2.5 Flash 时,输出成本会因是否启用推理功能相差 6 倍。
更擅长深度思考的 Gemini 2.5 Pro 虽然在发布时没有「思考预算」机制,但在 6 月份的一次重大更新时又加上了。
它的出现则被定义为面向 B 端的实用主义创新,而非一个面向普通消费者的通用模型。因为它允许企业在生产系统中像调节水龙头一样精确调节 AI 的思考成本,这对于需要将 AI 应用大规模部署的企业和开发者来说是一个非常伟大的功能。
在实现方式上,有人猜测这可能是一个「混合方案」—— 模型可能实际结合了一个擅长推理的大模型和一个用于输出的小模型,两者根据预算切换。不过,这个猜想还未被证实。

Gemini 2.5 系列技术报告:https://arxiv.org/pdf/2507.06261
快手的 Kwai 系列
快手于今年 6 月初推出了自动思考大模型 KwaiCoder-AutoThink-preview。该模型融合了「思考」和「非思考」能力,并具备根据问题难度自动切换思考形态的能力。
他们的核心想法是在思考之前加上一个 pre-think 的阶段,让模型预先判断问题的困难度。
简单来说,KwaiCoder-AutoThink-preview 模型采用了两步式训练方法,首先通过 Agentic 方法构造长短思考的 Cold Start 数据让模型在进行思考之前先进行一个「pre-think」,判断一下问题的难度。 然后再使用加上专门为 Auto Think 任务设计的带有过程监督的 Step-SRPO 增强模型对各种任务难以程度判断的准确性。
今年 7 月,快手更进一步,开源了 AutoThink 大模型 KAT-V1,也是主打无需人类手动设置,模型自主判断。
具体细节可以参见技术报告。
技术报告:https://arxiv.org/pdf/2507.08297
字节的豆包系列
字节今年 6 月发布的 Seed 1.6 (Adaptive CoT) 也是一个混合推理模型,支持 on/off/auto 三种思考模式,让用户可以根据使用场景自行选择,大模型也可以自己判断是否使用深度思考。
据官方介绍,这种自适应思考能力的实现依靠一种动态思考技术来实现,即 Adaptive CoT,能在保证效果的同时压缩 CoT 长度。
Adaptive CoT 相关论文在 5 月份就已经上线(AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning),它将自适应推理建模为一个帕累托优化问题:在保证模型性能的同时,最小化 CoT 调用带来的成本(包括触发频次与计算开销)。具体来说,研究者采用基于强化学习的方法,使用近端策略优化(PPO),通过动态调整惩罚系数来控制 CoT 触发决策边界,使模型能够依据隐含的问题复杂度判断是否需要 CoT。关键技术贡献之一是「选择性损失掩蔽」(Selective Loss Masking,SLM),用以防止多阶段 RL 训练中的决策边界崩塌,确保触发机制稳健且稳定。当时,这项技术首先被部署到了 doubao-1.5-thinking-pro-m-250428 版本里。
具体细节可参见论文:https://arxiv.org/pdf/2505.11896
不过,字节表示,他们最终还是希望将(Seed1.6-Thinking 所代表的)极致推理效果和(Seed 1.6 所代表的)动态思考技术融合到一个模型里,为用户提供更智能的模型。
腾讯的混元系列
腾讯今年 6 月份发布的 Hunyuan-A13B 也是一个混合推理模型。为了让模型基于任务需求动态调整推理深度,他们实现了一个双模式思维链(Dual-Mode CoT)框架,让模型在快、慢思考之间切换。
在技术报告中,他们提到了这个框架的一些细节。在后训练阶段,他们采用统一的训练结构来同时优化两种推理模式。为了使模型输出标准化,两种模式的训练样本均采用统一结构化设计:在专用的 < think > 内容块中,通过有无详细推理步骤进行区分。具体而言,快速思维模式刻意保持 < think>\n\n<think > 为空内容块,而慢速思维模式则在该区块明确包含逐步推理过程。用户可通过指定控制标签选择模式:使用「/no_think」启用快速思维模式,「/think」启用慢速思维模式。若未提供控制标签,系统默认采用慢速思维模式。
技术报告:https://github.com/Tencent-Hunyuan/Hunyuan-A13B/blob/main/report/Hunyuan_A13B_Technical_Report.pdf
智谱的 GLM-4.5 系列
今年 7 月份,智谱发布了 GLM-4.5 和 GLM-4.5-Air,都支持混合推理模式。该模式的形成主要与模型的后训练有关。
具体来说,他们的后训练分为两个独立的阶段。在第一阶段(专家训练),他们构建了专注于三个领域的专家模型:推理、代理以及通用聊天。在第二阶段(统一训练),他们采用自蒸馏技术来整合多个专家,让模型学会了为每个任务应用最有效的长上下文推理来得出准确的答案。特别是,鉴于某些领域(如闲聊)不需要冗长的思考过程,他们精心平衡了包含完整推理过程的训练数据与缺乏明确思考过程的数据。这种方法使模型能够在反思和即时响应模式之间切换,从而创建了一个混合推理模型。
更多细节可参见技术报告。
技术报告:https://arxiv.org/pdf/2508.06471
OpenAI 的 GPT-5
有人说,如果 GPT-3 到 GPT-4 的重大突破是专家混合(Mixture of Experts),那么 GPT-4o/o3 到 GPT-5 的重大突破可能是模型混合(Mixture of Models,也称为「路由」)。
和很多将思考 / 非思考能力融合到同一个模型中的思路不同,GPT-5 选择的方向是在整个系统中加入一个实时路由,它能根据对话类型、复杂程度、工具需求和明确意图(例如,如果你在提示中说「仔细思考这个问题」),快速决定使用哪个模型(如下表)。

在 GPT-5 技术报告中,他们将快速、高通量的模型标记为 gpt-5-main 和 gpt-5-main-mini,将思考型模型标记为 gpt-5-thinking 和 gpt-5-thinking-mini。API 中还提供更小更快的思考型模型 nano 版本,ChatGPT 中还提供 gpt-5-thinking-pro。这些模型均由上一代模型(左边一栏)演变而来。
该路由通过真实信号持续进行训练,包括用户何时切换模型、对回复的偏好以及测量的正确率等,随着时间推移不断改进。一旦达到使用限制,每个模型的迷你版本将处理剩余的查询。
不过,这个模式同样反响不佳。不少人在社交媒体上吐槽自己的问题被路由到了低质量模型。更让人抓狂的是,很多时候你无法判断该不该相信模型给出的答案,因为路由结果是不透明的。这让 ChatGPT 在专业用户中的口碑有所下滑。



不过,对于占 ChatGPT 用户数超 95% 的免费用户来说,这个路由反而提升了体验。之前,这部分用户是很难用上高级思考模型的,但是现在有一定概率会被路由到高级模型。

对此,SemiAnalysis CEO Dylan Patel 分析说,这可能是 OpenAI 在免费用户变现上迈出的重要一步。和专攻 to B 模式的 Anthropic 不同,OpenAI 的商业重心依然集中在 C 端用户上,但这部分用户大部分是免费用户。对于这种情况,传统 APP 一般是通过让免费用户看广告来赚钱,但对于 AI 应用,这种模式不再适用。
路由模型存在的价值在于,它可以从海量免费用户的提问中识别出商业意图,比如订机票、找律师,然后把这些高价值请求导向高算力模型 + 后续 Agent 服务,OpenAI 再从成交中抽成。路由模式让 OpenAI 第一次把「成本」和「商业价值」写进模型决策逻辑,既省算力,又为下一步「AI 超级应用抽成」铺好了路。
不过,路由未必是实现这些目标的终极方式。OpenAI 表示,他们之后也打算将两种思考模式的切换整合到单个模型里。
DeepSeek 的 DeepSeek v3.1
DeepSeek 最近发布的 v3.1 是国内团队在「单一模型实现思考 / 非思考模式切换」上的另一项尝试。DeepSeek 官方表示,DeepSeek-V3.1-Think 实现了与 DeepSeek-R1-0528 相当的答案质量,同时响应速度更快。
对于开发者来说,它的思考模式和非思考模式可以由提示序列中的 <think> 和 </think> 标记触发。对于 C 端用户,可以通过点击「深度思考」按钮切换模式。
由于发布时间接近,又都有混合推理模式,DeepSeek v3.1 和 GPT-5 难免被拿来对比。在性能上,DeepSeek v3.1 虽然在一些基准上与 GPT-5 旗鼓相当,但综合能力仍然不如 GPT-5。在价格上,DeepSeek v3.1 则有着明显的优势,可以说为企业提供了一个高性价比的开源选择。

想深入了解混合推理?
这些研究方向值得关注
从以上模型可以看出,虽然大家的共同目标都是减少推理过程中的 token 浪费,但具体实现方法有所不同,有的借用路由将问题导向不同的模型,还有些在一个模型中实现快慢思考的切换。在切换方式上,有些是用户显式控制,有些是模型自动判断。
通过一些综述研究,我们可以看到更多不同的思路。
比如在「Towards Concise and Adaptive Thinking in Large Reasoning Models: A Survey」这篇综述中,研究者将现有方法分为两类:
一类是无需训练的方法,包括提示词引导、基于 pipeline 的方法(比如路由)、解码操纵和模型融合等;
- 提示词引导:通过精心设计的提示(例如,直接提示、token 预算、thinking 模式、no-thinking 指令)来利用模型遵循指令的能力。尽管该方法的简单性使其能够快速部署,但其有效性取决于模型对约束的遵守情况,而这往往并不一致。研究表明,这些方法会产生意想不到的后果,例如隐藏的不准确之处和输出稳定性的降低,特别是在实施严格的 token 限制或抑制推理步骤时。
- 基于 pipeline 的方法:该方法将推理工作流程模块化,通过任务卸载降低大语言推理模型的计算成本,同时保持推理质量。其中,基于路由的方法根据输入复杂性、模型能力或预算限制动态选择最佳模型 / 推理模式。其他策略包括动态规划和迭代优化以及效率提升技术。这些方法显著缩短了推理长度,但引入了额外的开销(如路由延迟),导致端到端延迟增加,因此需要在效率和延迟之间进行权衡。
- 解码操纵:通过预算强制、提前退出检查、logit 调整或激活引导等方式,动态介入生成过程。像 DEER 和 FlashThink 这类技术,通过监测置信度或语义收敛来实现更短的推理链,不过频繁的验证步骤可能会抵消计算节省。并行 scaling 策略进一步提高了效率,但需要仔细校准以平衡冗余度和准确性。
- 模型融合:即将一个思考缓慢的大语言推理模型(LRM)和一个思考快速的大语言模型(LLM)整合为一个单一模型,并且期望这个单一模型能够平衡快慢思考,从而实现自适应思考。这种方法通过参数插值或基于激活的融合来综合长推理和短推理能力。虽然这种方法对中等规模的模型有效,但在处理极端规模(小型或大型模型)时存在困难,并且缺乏对推理深度的精细控制。与此同时,像 Activation-Guided Consensus Merging (ACM) 这样的最新进展凸显了互信息分析在对齐异构模型方面的潜力。
另一类是基于训练的方法,重点在于缩短推理长度,并通过微调(SFT/DPO)或强化学习(RL)来教导语言模型进行自适应思考。
- 微调:微调可以分为五类:长思维链压缩方法提高了推理效率和适应性,但在压缩效果与推理保真度之间面临权衡,同时还存在数据需求增加和泛化方面的挑战;而短思维链选择微调则通过促进简洁或自我验证的推理路径来提高推理效率,但可能存在遗漏关键步骤的风险,或者需要复杂的训练过程,并在简洁性和准确性之间进行仔细权衡;隐式思维链微调通过潜在推理表示或知识蒸馏来实现效率提升,但由于推理步骤不明确而牺牲了解释性,且压缩表示与任务要求之间可能存在不一致的风险;近端策略优化(DPO)变体方法通过偏好学习实现简洁性和准确性之间的多目标优化平衡,但在构建高质量偏好对以及在严格长度限制下保持推理深度方面面临挑战;其他混合方法结合了快速 / 慢速认知系统或新颖的损失函数来实现自适应推理,不过它们通常需要复杂的训练流程,并对双模式交互进行仔细校准。
- 强化学习:强化学习方法通过五个关键范式来平衡简洁性和准确性。带长度惩罚的强化学习通过奖励塑造或外部约束对冗长的输出进行惩罚,从而提高效率,但存在将复杂任务过度简化或过度拟合惩罚阈值的风险。GRPO 变体方法通过使推理模式多样化或整合难度感知奖励来解决「格式崩溃」问题,不过它们通常需要复杂的损失设计和多组件系统。难度感知强化学习通过显式难度估计或隐式信号(响应长度、解决率)使响应长度适应问题的复杂性,但在准确的难度校准和跨领域泛化方面面临挑战。思维模式强化学习能够在审慎(「思考」)和反应性(「不思考」)模式之间动态切换,但在模式选择稳定性和探索与利用的权衡方面存在困难。其他强化学习创新引入了可学习的奖励函数、混合框架或新颖的指标,尽管这些通常需要大量的计算资源或面临可扩展性问题。
具体分类如下图所示:

综述链接:https://arxiv.org/pdf/2507.09662
值得注意的是,除了语言模型,多模态模型领域的混合推理探索也已经开始,而且出现了 R-4B 等自动化程度较高的自适应思考模型,我们将在后续的报道中完整呈现。
如果你想动态追踪这个领域的新研究,可以收藏以下 GitHub 项目:https://github.com/hemingkx/Awesome-Efficient-Reasoning#adaptive-thinking

下一个前沿:
让 AI 以最低代价在恰当时刻思考
在过去几年,AI 领域的竞争更多集中在构建更强大的模型上。如今,混合推理模式的大规模出现标志着人工智能行业的重点从单纯构建更强大的系统转向创建实用的系统。正如 IBM 研究院高级项目经理 Abraham Daniels 所说,对于企业而言,这种转变至关重要,因为运营复杂人工智能的成本已成为主要考虑因素。
但是,这一转变也在经历阵痛。一方面,能够不靠人类指示激活深度思考模式的成功模型还相对较少。另一方面,尝试去掉显式开关的思维转换模式还没有实现足够令人满意的效果。这些现象都说明,混合推理的下一个前沿将是更智能的自我调节。
换句话说,混合推理的未来竞争将不再只是「是否能思考」,而是「能否以最低代价在恰当时刻思考」。谁能在这一点上找到最优解,谁就能在下一轮 AI 性能与成本博弈中占据主动。
#R-Zero
R-Zero 深度解析:无需人类数据,AI 如何实现自我进化?
本文第一作者黄呈松 (Chengsong Huang) 是圣路易斯华盛顿大学的博士生,Google scholar citation 五百多次,目前的研究的兴趣是强化学习和大语言模型。xx曾经报道过其之前工作 Lorahub 已经被引超过 250 次。
大型语言模型(LLM)的发展长期以来受限于对大规模、高质量人工标注数据的依赖,这不仅成本高昂,也从根本上限制了 AI 超越人类知识边界的潜力 。《R-Zero:从零数据中自我进化的推理大模型》提出了一种全新的范式,旨在打破这一瓶颈。该研究设计了一个名为 R-Zero 的全自主框架,使模型能够从零开始,通过自我驱动的协同进化生成课程并提升推理能力,为通往更自主的人工智能提供了一条值得深入探讨的路径。
《R-Zero》论文的核心,是构建一个能从「零数据」开始自我进化的 AI 框架 ,主要依赖于两个 AI 角色 挑战者(Challenger)和 解决者(Solver)。
- 论文链接: https://www.arxiv.org/abs/2508.05004
- 项目代码: https://github.com/Chengsong-Huang/R-Zero
- 项目主页: https://chengsong-huang.github.io/R-Zero.github.io/
挑战者 - 解决者的协同进化
R-Zero 的架构核心是从一个基础 LLM 出发,初始化两个功能独立但目标协同的智能体:挑战者(Challenger, Qθ)和解决者(Solver, Sϕ)。
- 挑战者 (Challenger):其角色是课程生成器。它的优化目标并非生成绝对难度最高的问题,而是精准地创造出位于当前解决者能力边界的任务,即那些最具信息增益和学习价值的挑战 。
- 解决者 (Solver):其角色是学生。它的目标是解决由挑战者提出的问题,并通过这一过程持续提升自身的推理能力 。
这两个智能体在一个迭代的闭环中协同进化,整个过程无需人类干预 :
1. 挑战者训练:在当前冻结的解决者模型上,挑战者通过强化学习进行训练,学习如何生成能使解决者表现出最大不确定性的问题。
2. 课程构建:更新后的挑战者生成一个大规模的问题池,作为解决者下一阶段的学习材料。
3. 解决者训练:解决者在这个由挑战者量身定制的新课程上进行微调,提升自身能力。
4. 迭代循环:能力增强后的解决者,成为下一轮挑战者训练的新目标。如此循环往复,两个智能体的能力共同螺旋式上升。

这是一个完全封闭、自我驱动的进化循环。在这个过程中,AI 自己生成问题,自己生成用于学习的「伪标签」,自己完成训练,完全不需要任何外部人类数据的输入。
具体实现方法

由于没有外部「标准答案」,解决者必须自我生成监督信号。
- 伪标签生成:采用自我一致性(self-consistency)策略。对于每个问题,解决者会生成多个(例如 10 个)候选答案,其中出现频率最高的答案被选为该问题的「伪标签」(pseudo-label)。
- 过滤器:这是框架设计的关键一环。并非所有生成的问题都被用于训练,只有那些解决者经验正确率 p^i 落在特定「信息带」内(例如,正确率在 25% 到 75% 之间)的问题才会被保留 。该过滤器起到了双重作用:
1. 难度校准:显式地剔除了过易或过难的任务。
2. 质量控制:一致性极低的问题(例如 10 次回答各不相同)往往是定义不清或逻辑混乱的,该机制能有效过滤掉这类噪声数据。消融实验证明,移除该步骤会导致模型性能显著下降 。
为了生成高效的课程,挑战者的奖励函数由三部分构成 :
- 不确定性奖励 (Uncertainty Reward):这是奖励函数的核心。其公式为 runcertainty=1−2∣p^(x;Sϕ)−1/2∣,其中 p^ 是解决者对问题 x 的经验正确率。当解决者的正确率接近 50% 时,奖励最大化。这一设计的理论依据是,此时学习者的学习效率最高,每个样本带来的信息增益也最大 。
- 重复惩罚 (Repetition Penalty):为保证课程的多样性,框架利用 BLEU 分数来衡量批次内问题的相似度,并对过于相似的问题施加惩罚 。
实验结果与分析

数学推理能力显著提升:经过三轮自我进化,Qwen3-8B-Base 模型在多个数学基准测试上的平均分从 49.18 提升至 54.69(+5.51)。
向通用领域的强大泛化能力:尽管训练任务集中于数学,但模型的核心推理能力得到了泛化。在 MMLU-Pro、SuperGPQA 等通用推理基准上,Qwen3-8B-Base 的平均分提升了 3.81 分 。这表明 R-Zero 增强的是模型底层的通用能力,而非特定领域的知识记忆。
与人类数据的协同效应

实验证明,先经过 R-Zero 训练的基础模型,再使用人类标注数据进行监督微调,能达到比直接微调更高的性能。这说明 R-Zero 可以作为一种高效的中间训练阶段,最大化人类标注数据的价值 。
核心局限与未来展望
尽管成果显著,R-Zero 框架也揭示了其内在的挑战和局限性。
- 伪标签准确率的衰减:这是该框架最核心的挑战。分析表明,随着课程难度在迭代中提升,由自我一致性生成的伪标签的真实准确率,从第一轮的 79.0% 系统性地下降到了第三轮的 63.0% 。这意味着模型在后期学习的监督信号中包含了更多的噪声。如何在这种难度与质量的权衡中找到稳定点,是决定该框架能否长期进化的关键。
- 领域局限性:当前框架高度依赖于那些存在客观、可验证正确答案的领域(如数学)。对于评估标准主观、解决方案多元的任务(如创意写作、战略规划),基于多数投票的自我监督机制将难以适用 。
#这个荒诞网站藏着30个AI「鬼点子」
但我觉得它活不长
一个绝妙的点子往往是公司最危险的毒药。
最近在 X 上闲逛,淘到了一个神奇的网站 ——「Absurd.website」。
正如名字一样,它荒诞、有趣、脑洞大开,里面收录了各种奇葩的小项目,有些甚至能看到 AI 生成的痕迹。
比如项目海报过于光滑的皮肤,一眼 AI:

稍显粗糙的 AI 界面设计:

还有 100% AI 项目 Open Celebrity:

AI 生成的免费名人照片,无论是做广告、社交媒体还是其他任何用途,完全没有版权问题。
这个网站成立于 2020 年,声称每月推出一个独特的项目和一个仅限会员的秘密项目,不过截至目前也只收录了 30 个项目。
网站链接:https://absurd.website/
接下来,我们挑几个好玩的项目唠唠。
五花八门的AI小项目
Sexy Math(性感数学)
没想到,数学有朝一日竟能跟性感联系在一起。这款游戏的规则是,答对 10 道乘法题,就能解锁一张美女照片。有网友反馈称,我从未见过我的孩子如此积极地学习乘法!他们解题速度比以往任何时候都快,甚至还挑战自己提高分数。
由于尺度有点大,进入游戏前先有个「免责问答」:你年满 18 岁吗?可问题是,都 18 岁了谁还做简单的乘法题啊?

Artist's Death Effect Database
收藏界存在一种现象,叫「艺术家死亡效应」,当艺术家去世时,其作品往往会价值飙升。该项目就是通过分析艺术家的预期寿命(根据各国的平均寿命和出生日期),为投资者识别作品价值有望上升的艺术家。
数据库按艺术家的预期剩余寿命进行排序,并使用简单的颜色编码系统进行分类。绿色代表非常好的投资,黄色代表良好投资,红色则是低投资潜力。
艺术家去世本身是一个令人伤感的事情,将其与财富机会挂钩,总感觉太没人情味。
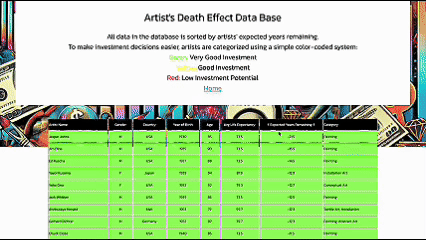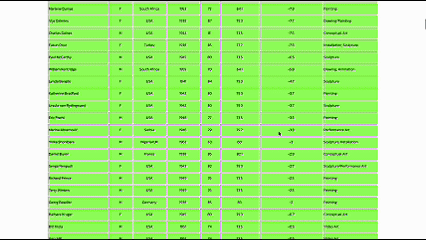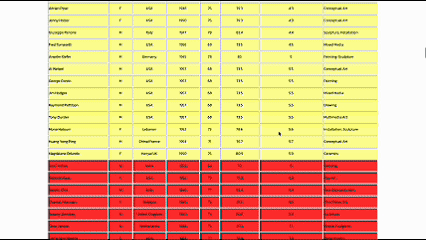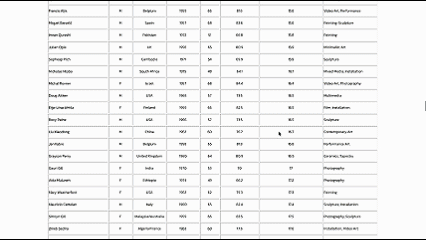
Spot The Differences (找不同)
请看下面两幅照片,给你 5 分钟找出其中的不同。

你会发现,花了很大功夫也找不出任何差异,因为这本身就是两张一模一样的图片。这种设定想传达一个观点:社会给我们的压力,让我们一直在追寻某些东西,然而这种追求本身可能是无意义的。
Influencer Overnight (一夜成名的网红)
这是一个社交实验。参与者只需关注一个 Ins 账号并帮助推广,当该账号达到 10 万粉丝时,会随机挑选一位粉丝来接管这个账号。
我们去这个 ins 账号看了下,里面都是用 AI 生成的网红,截止目前只有 61 个粉丝,照这个速度得猴年马月才能俘获 10 万粉丝。😂

A Guide For Aliens To Live On Earth(外星人地球生活指南)
这是一本专门为外星人设计的旅游指南,不仅帮助外星人了解如何解读人类的语言、如何在派对上融入,还教人类如何变得更好,尊重文化差异和保持好奇心。
Slow Delivery Service(慢速快递)
该项目提供长途送快递服务,但配送方式是靠两条腿,且要求送达距离至少为 100 公里。按照快递员每天平均行程 30 到 40 公里算,1000 公里的配送大约需要一个月。
One Life Game
以《丛林中的猴子》为例,玩家通过鼠标和键盘操纵猴子跳跃、移动,以收集道具和躲避障碍物。它的创意在于规则设置,强调「只有一次机会」的游戏体验,输了就 game over,不会再让你重开一局。

Add Luck to Your e-Store
只需简单嵌入 HTML 代码,就能让一只可爱、简约的招财猫出现在电商网站的角落弹出框中,静静地挥手。

OPERATION D-DAY:ONE SECOND OF WAR
这是一款让你感受战争残酷性的硬核 3D FPS 游戏,它不是看你能不能在战场上活下来,而是看你能坚持多久。我试玩了一下,仅坚持 1.2 秒就「阵亡」,一个战斗在一瞬间就结束了。

此外,该网站还包含了其他奇奇怪怪的项目。
Puzzle Solvers Agency:专门帮人解决拼图、乐高、各种游戏和其他复杂难题。
Absurd Toilet Water :世界上第一个真正由马桶水制作的香水。
Invisible Lingerie:一款性感且隐形的内衣,既看不到也摸不着。
Trip to Mars:耗时 7 个月完成的第一款实时太空飞行模拟器游戏。
Helicopter Jobs:政府资助来提供毫无意义的在线工作(如点击按钮),并支付工资,旨在解决失业问题。
Eyes Dating Site:一个通过凝视对方眼睛来促进情感连接的约会网站。
仅凭创意就可以了吗?
现如今,AI 圈越来越卷,但产品同质化也愈发严重。创意总是稀缺的,但仅凭创意就能取胜吗?
这让我想起了两个故事。
@带娃术士刘洪伟曾年入百万,做了三档综艺节目的总编剧,但一个都没播出来。
第一个节目是直播脱口秀《小葱秀》,第一期播出后因尺度过大被下架。
另一个节目是模仿《周六夜现场》的形式,将每周的热点事件做成小品。当时,卓伟因为曝光明星花边新闻的「周一见」而爆红,他们就想与卓伟合作,提前获知下周的花边新闻,签署保密协议,然后写小品、排小品,等到周一发布。所有人都对这个策划充满期待,但最终因各种原因夭折。
还有一个节目是让一个算命师和一个科学家对决,类似于算命师说自己家闹鬼,科学家则通过科学分析提出可能的解释。创意很有趣,但最终也未能面世。
这人也是个奇才,想的节目创意一个比一个精彩,但也各有各的「死法」。
另一个是乔布斯在采访中提到的一个观点,「一个绝妙的点子往往是公司最危险的毒药」。
,时长04:24
为什么这么说呢?乔布斯表示,在他离开苹果以后,发生了一件几乎毁掉苹果的事。时任苹果公司 CEO 的 John Sculley 有个明显的缺点,那就是盲目乐观,以为光凭创意就能取得成功。
他总是觉得,只要想到一个绝妙的主意,公司就一定可以实现,问题在于优秀的创意与产品之间隔着巨大的鸿沟,实现创意的过程中,想法会变化甚至变得面目全非,因为你会发现新东西,思考也更深入,你不得不一次次权衡利弊,做出让步和调整,总有些问题是技术和材料无法解决的。
设计一款产品需要考虑成千上万的细节,必须在无数次的尝试中梳理出最合适的方案。这个过程至关重要,无论一开始有多少绝妙的创意,最终的结果都需要通过团队的不断磨砺。
现实中也有太多例子提醒我们,创意只是开始,头脑一热就开干,结局大概率就是一地鸡毛。
就以这个 Absurd 网站为例。这个网站的发起人脑洞够大吧,但从 2020 年 9 月 25 日发布第一个帖子至今,X 上的粉丝只有少得可怜的 26 个,每篇帖子点赞数一个巴掌都能数过来,在其他平台也没掀起什么水花。

国外的 AI 工具聚合网站 DANG! 专门搞了个「AI 坟墓」的页面,用来记录那些「挂掉」的 AI 项目。
数据显示,截至目前,在新增的 4850 个 AI 工具中,已有 1351 个被关闭、收购或停运,仅 2025 年就有 277 个工具停运。这是啥概念?平均每天都至少有一款 AI 工具入土。

我去扒拉了一圈,有些 AI 项目确实「死有余辜」,比如 AI 搭讪语生成器 AI Pickup Lines,虽在推出当天因其幽默获得一波关注,但由于缺乏持续的用户粘性和盈利模式,最终被收购后关闭。
当然也有些项目死得比较冤。
比如头像生成器 Alter AI,主打功能就是将普通自拍照转化成高质量、专业的领英、ins 真人头像;

名人自拍生成器 MaskrAI,只需上传一张照片,就能与马斯克、梅西和爱因斯坦等名人合照;

发型生成器 TryHairstyles.io,单击一下即可实时尝试流行发型;

AI 航班搜索工具 GetMeFlights,帮助用户找到廉价航班,还能提供旅游指南、定制行程。
这些 AI 项目乍一看好像挺有需求,也挺有趣,但它们都有一些共通的毛病:
- 没有真正解决用户需求问题,往往只是用封装的 GPT,但没有形成实际的工作流程。
- 即使有不错的产品,但缺乏有效的推广渠道,没有办法被人看到。
- 一些 AI 工具和用户的工作流不兼容,增加了额外的摩擦。
- 有些 AI 工具号称为「每个人」设计,但实际却没有明确的目标用户。
- 很多 AI 工具并没有真正节省时间,仍需要人工清理、检查和复制粘贴。
如今 AI 是个香饽饽,热钱纷纷往里砸,但说实话,很多 AI 产品就是噱头大于实际功能。要知道市场是极其残酷的,创业公司不能一拍脑壳就下手,想出个点子就以为能成,更不可盲目跟风。
成功的产品不仅仅取决于创意的独特性,更需要在实践中不断优化和适应市场的需求,确保每一个细节都经过深思熟虑,而不是单纯炒概念。
#Meta考虑向Google、OpenAI低头
混乱、内耗、丑闻
斥资 143 亿美元投资、挖来「行业天才」领军,扎克伯格亲自下场高调地四处挖人,换来的却是数据质量被指「低下」、核心人才纷纷出走,外加一桩让人侧目的 AI 伦理丑闻。
这剧情可以拍成《社交网络 3》了。
失控的「超级碗」战队
故事的高潮从今年六月开始。为了追赶 OpenAI 和 Google,扎克伯格下了一步重棋:向数据标注领域的独角兽 Scale AI 狂掷 143 亿美元,并将其创始人、AI 界的风云人物 Alexandr Wang 请来执掌全新的 Meta 超级智能实验室(MSL)。

同时,扎克伯格发起了一场激进的「挖人」活动,以招募顶尖的人工智能人才。扎克伯格甚至被调侃在看 OpenAI 直播时都不忘挖人,从苹果挖来的基础模型负责人庞若鸣、思维链的开山作者 Jason Wei 以及北大校友孙之清等人相继加入。
这支队伍星光熠熠,被寄予厚望,堪称 AI 领域的「超级碗」战队。可惜,这支战队的蜜月期短得惊人。
危机的第一个信号是人才的迅速流失。随 Wang 一同加入的前 Scale AI 高管 Ruben Mayer,仅仅两个月便宣告离职。尽管他事后澄清是因「个人事务」并强调自己「非常满意」在 Meta 的经历,但这并未平息外界的猜测。
紧接着,AI 研究员 Rishabh Agarwal、产品管理总监 Chaya Nayak 和研究工程师 Rohan Varma 等核心成员也相继「跳船」。
Agarwal 在告别时还引用了扎克伯格的话:「在一个变化如此之快的世界里,你所能承担的最大风险就是不冒任何风险」。

压垮团队士气的,是更深层次的信任危机。多位内部人士爆料,MSL 的研究人员普遍认为重金引入的 Scale AI 所提供的数据「质量低下」。

推中是指 Ruben Mayer 离职,而非 Alexandr Wang。
Scale AI 建立在低成本的众包模式上,而随着 AI 模型日益复杂,业界更需要像其竞争对手 Surge 和 Mercor 那样,从一开始就依赖高技能领域专家的模式。结果,Meta 的团队不得不绕开这位「正牌」合作伙伴。
关于 Alexandr Wang 的争议也一直不断,他并非 AI 研究员出身,被视为领导一个顶级实验室的「非传统人选」。

尽管 Meta 的发言人否认存在质量问题,但这笔百亿美金的投资究竟是为了战略合作,还是一场昂贵的人才收购秀,外界的疑问越来越大。
与此同时,Meta 内部的文化冲突愈演愈烈。从 OpenAI 等公司挖来的「空降兵」们对 Meta 庞大的官僚体系感到沮丧,而公司原有的 GenAI 团队则感觉自己的工作范围被大大限制,沦为「二等公民」。
一切乱象的背后,是扎克伯格对 Llama 4 模型表现平平的失望,以及由此引发的不计成本的、近乎疯狂的追赶策略。但事实证明,用钱砸出来的「天团」,未必能赢得比赛。
打不过,就加入?
内部一地鸡毛,外部形象岌岌可危,核心技术又迟迟不见突破。在内外交困之下,Meta 开始考虑一个曾经无法想象的选项。
据知情人士透露,面对自家模型性能不足、AI 助手用户活跃度惨淡(仅占月活用户的 10% 左右)的现实,MSL 的高层已经开始讨论在 Meta AI 中使用 Google Gemini 或向 OpenAI 的模型,作为提升产品能力的「权宜之计」。

这一潜在的战略转向,无异于公开承认了自己在 AI 核心技术竞赛中的暂时落后。
尽管 Meta 的发言人仍在强调公司「全方位」的策略,包括自研、开源以及最近与 AI 图像生成公司 Midjourney 达成的合作,但这更像是在自家下一代模型(如 Llama 5)成熟前的无奈之举。
讽刺的是,这种「借力」策略在 Meta 内部早已不是秘密。其内部编程工具已经允许员工使用竞争对手 Anthropic 和 OpenAI 的模型来辅助工作。
当 AI 开始「模仿」名人
屋漏偏逢连夜雨,路透社的调查报道,揭开了 Meta 在 AI 伦理上的遮羞布。
报道指出,Meta 未经授权,创建或允许用户创建了数十个模仿名人的 AI 聊天机器人,其中包括泰勒·斯威夫特、安妮.海瑟薇等顶级巨星。

这些 AI 机器人不仅坚称自己就是明星本人,还进行着露骨的暗示,甚至在用户的要求下,生成其模仿对象身着内衣或在浴缸中摆姿势的逼真照片。
更让 Meta 无法辩驳的是,调查发现,至少有三个这样的出格机器人,是由 Meta 自己的员工亲手创建的。这些被公司轻描淡写称为「产品测试」的机器人,累计互动次数超过了 1000 万次。
在巨大的舆论压力下,Meta 匆忙下架了相关机器人,并宣布为青少年用户增加安全防护。
将过去这段时间的事件串联起来,一幅清晰的图景浮现:对现状的失望催生了急于求成的策略,混乱的管理导致了失序的团队,而一个失序的团队最终酿成了技术瓶颈和伦理丑闻。
所以,扎克伯格重金打造的 AI 帝国,最终是会杀出一条血路,还是沦为竞争对手技术版图上的一块殖民地,你怎么看?
补充阅读:
- 刚刚,Meta 宣布正式成立「超级智能实验室」!11 人豪华团队首曝光
- 刚刚,苹果基础模型团队负责人庞若鸣被 Meta 挖走!加入超级智能团队、年薪千万美元
- 突发|思维链开山作者 Jason Wei 被曝加入 Meta,xx独家证实:Slack 没了
- GPT4 核心成员、清华校友赵晟佳任 Meta 超级智能实验室首席科学家
- 扎克伯格看 OpenAI 直播挖人,北大校友孙之清加入 Meta
- 挖人上瘾的 Meta 又被员工吐嘈:不帮忙宣传项目,开源只会越来越糟
- 一天之内,Meta 痛失两员大将,小扎钞能力失效?
- 入职不到 30 天,OpenAI 员工闪辞 Meta 回归,赵晟佳也反悔过

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)