腾讯 java后端开发最新面试题
本文摘要:文章涵盖了计算机网络的多个核心概念,包括URL解析过程(DNS查询、TCP连接建立等)、HTTP状态码分类、TCP四次挥手原理、抽象类与接口的区别、ConcurrentHashMap与HashMap的对比、HashSet底层实现、MySQL常用函数分类(字符串、数值、日期、聚合函数)以及SpringBoot启动流程(从main方法到容器初始化)。这些知识点涉及网络协议、Java基础、数据
1. 键入一个网站,会发生什么?
-
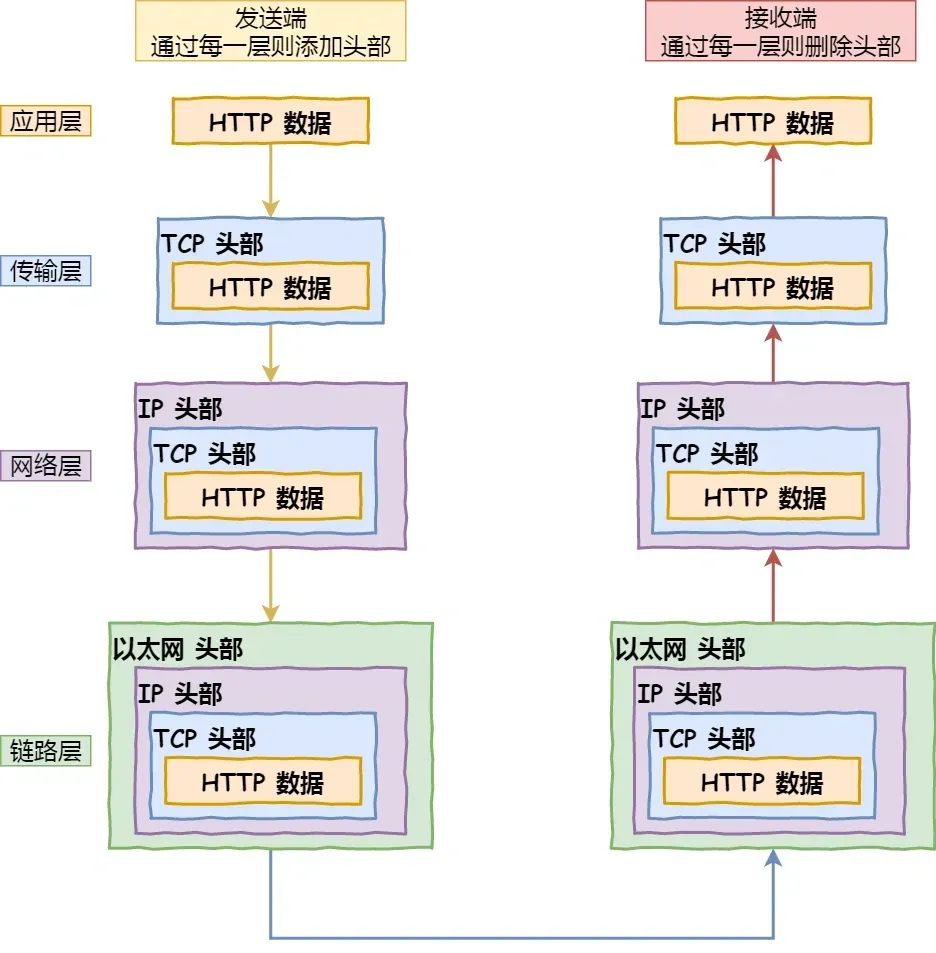
解析URL:分析 URL 所需要使用的传输协议和请求的资源路径。如果输入的 URL 中的协议或者主机名不合法,将会把地址栏中输入的内容传递给搜索引擎。如果没有问题,浏览器会检查 URL 中是否出现了非法字符,则对非法字符进行转义后在进行下一过程。
-
缓存判断:浏览器缓存 → 系统缓存(hosts 文件) → 路由器缓存 → ISP 的 DNS 缓存,如果其中某个缓存存在,直接返回服务器的IP地址。
-
DNS解析:如果缓存未命中,浏览器向本地 DNS 服务器发起请求,最终可能通过根域名服务器、顶级域名服务器(.com)、权威域名服务器逐级查询,直到获取目标域名的 IP 地址。
-
获取MAC地址:当浏览器得到 IP 地址后,数据传输还需要知道目的主机 MAC 地址,因为应用层下发数据给传输层,TCP 协议会指定源端口号和目的端口号,然后下发给网络层。网络层会将本机地址作为源地址,获取的 IP 地址作为目的地址。然后将下发给数据链路层,数据链路层的发送需要加入通信双方的 MAC 地址,本机的 MAC 地址作为源 MAC 地址,目的 MAC 地址需要分情况处理。通过将 IP 地址与本机的子网掩码相结合,可以判断是否与请求主机在同一个子网里,如果在同一个子网里,可以使用 APR 协议获取到目的主机的 MAC 地址,如果不在一个子网里,那么请求应该转发给网关,由它代为转发,此时同样可以通过 ARP 协议来获取网关的 MAC 地址,此时目的主机的 MAC 地址应该为网关的地址。
-
建立TCP连接:主机将使用目标 IP地址和目标MAC地址发送一个TCP SYN包,请求建立一个TCP连接,然后交给路由器转发,等路由器转到目标服务器后,服务器回复一个SYN-ACK包,确认连接请求。然后,主机发送一个ACK包,确认已收到服务器的确认,然后 TCP 连接建立完成。
-
HTTPS 的 TLS 四次握手:如果使用的是 HTTPS 协议,在通信前还存在 TLS 的四次握手。
-
发送HTTP请求:连接建立后,浏览器会向服务器发送HTTP请求。请求中包含了用户需要获取的资源的信息,例如网页的URL、请求方法(GET、POST等)等。
-
服务器处理请求并返回响应:服务器收到请求后,会根据请求的内容进行相应的处理。例如,如果是请求网页,服务器会读取相应的网页文件,并生成HTTP响应。
2. DNS域名怎么解析?
-
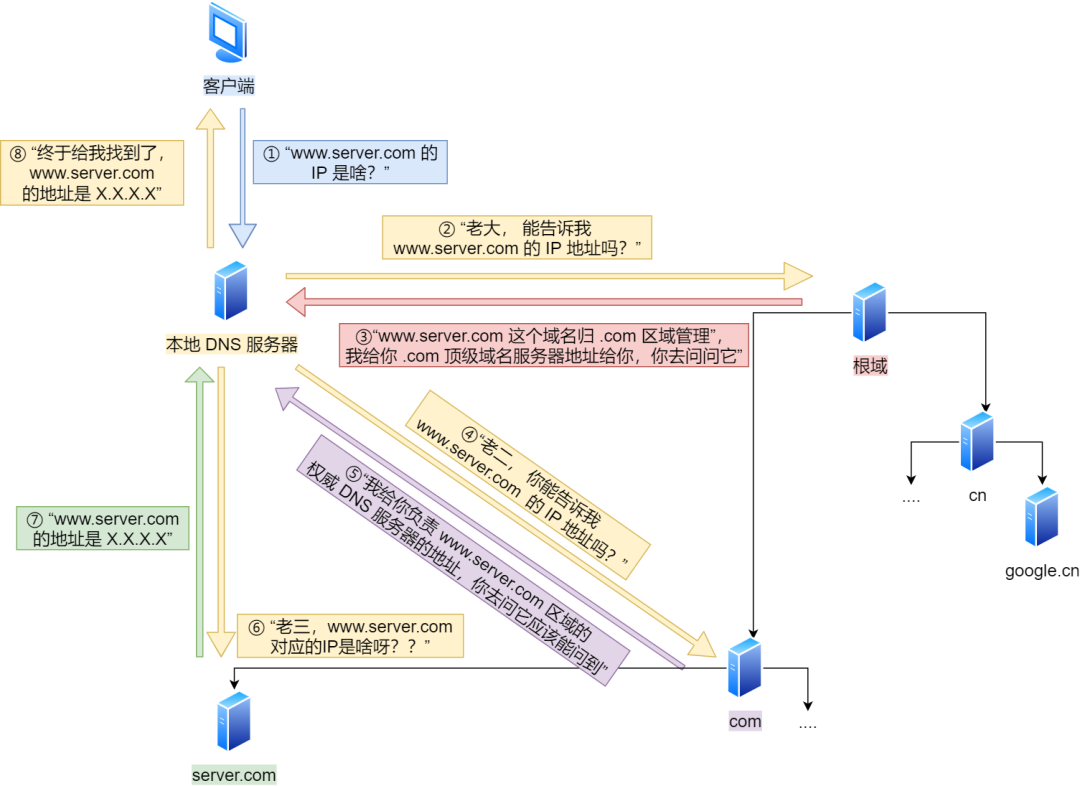
客户端首先会发出一个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
-
本地域名服务器收到客户端的请求后,如果缓存里的表格能找到 www.server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我 www.server.com 的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
-
根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
-
本地 DNS 收到顶级域名服务器的地址后,发起请求问“老二, 你能告诉我 www.server.com 的 IP 地址吗?”
-
顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
-
本地 DNS 于是转向问权威 DNS 服务器:“老三,www.server.com对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
-
权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
-
本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
至此,我们完成了 DNS 的解析过程
3. HTTP状态码有哪些?对应什么含义?

HTTP 状态码分为 5 大类
-
1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
-
2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
-
3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
-
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
-
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
其中常见的具体状态码有:
-
200:请求成功;
-
301:永久重定向;302:临时重定向;
-
404:无法找到此页面;405:请求的方法类型不支持;
-
500:服务器内部出错。
4. TCP为什么是四次挥手而不是三次?
具体过程:
-
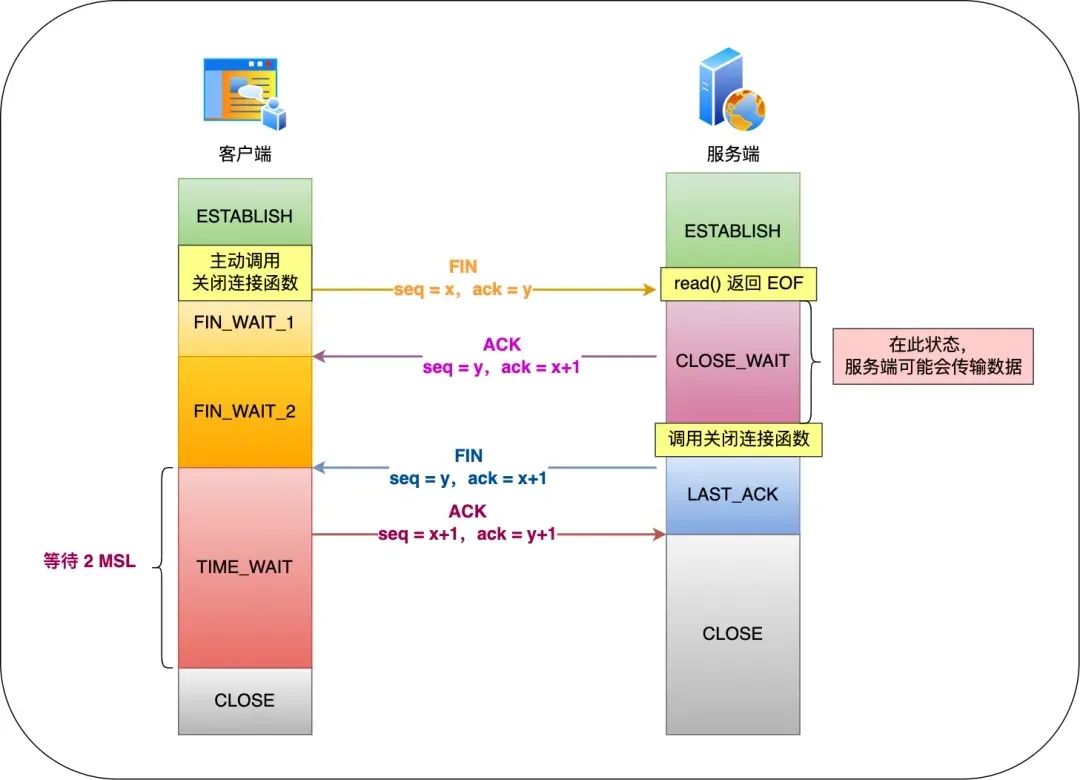
客户端主动调用关闭连接的函数,于是就会发送 FIN 报文,这个 FIN 报文代表客户端不会再发送数据了,进入 FIN_WAIT_1 状态;
-
服务端收到了 FIN 报文,然后马上回复一个 ACK 确认报文,此时服务端进入 CLOSE_WAIT 状态。在收到 FIN 报文的时候,TCP 协议栈会为 FIN 包插入一个文件结束符 EOF 到接收缓冲区中,服务端应用程序可以通过 read 调用来感知这个 FIN 包,这个 EOF 会被放在已排队等候的其他已接收的数据之后,所以必须要得继续 read 接收缓冲区已接收的数据;
-
接着,当服务端在 read 数据的时候,最后自然就会读到 EOF,接着 read() 就会返回 0,这时服务端应用程序如果有数据要发送的话,就发完数据后才调用关闭连接的函数,如果服务端应用程序没有数据要发送的话,可以直接调用关闭连接的函数,这时服务端就会发一个 FIN 包,这个 FIN 报文代表服务端不会再发送数据了,之后处于 LAST_ACK 状态;
-
客户端接收到服务端的 FIN 包,并发送 ACK 确认包给服务端,此时客户端将进入 TIME_WAIT 状态;
-
服务端收到 ACK 确认包后,就进入了最后的 CLOSE 状态;
-
客户端经过 2MSL 时间之后,也进入 CLOSE 状态;
服务器收到客户端的 FIN 报文时,内核会马上回一个 ACK 应答报文,但是服务端应用程序可能还有数据要发送,所以并不能马上发送 FIN 报文,而是将发送 FIN 报文的控制权交给服务端应用程序:
-
如果服务端应用程序有数据要发送的话,就发完数据后,才调用关闭连接的函数;
-
如果服务端应用程序没有数据要发送的话,可以直接调用关闭连接的函数,
从上面过程可知,是否要发送第三次挥手的控制权不在内核,而是在被动关闭方(上图的服务端)的应用程序,因为应用程序可能还有数据要发送,由应用程序决定什么时候调用关闭连接的函数,当调用了关闭连接的函数,内核就会发送 FIN 报文了,所以服务端的 ACK 和 FIN 一般都会分开发送。
5. 抽象类和接口有什么区别是什么?
两者的特点:
-
抽象类用于描述类的共同特性和行为,可以有成员变量、构造方法和具体方法。适用于有明显继承关系的场景。
-
接口用于定义行为规范,可以多实现,只能有常量和抽象方法(Java 8 以后可以有默认方法和静态方法)。适用于定义类的能力或功能。
两者的区别:
-
实现方式:实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。
-
方法方式:接口只有定义,不能有方法的实现,java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。
-
访问修饰符:接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。
-
变量:抽象类可以包含实例变量和静态变量,而接口只能包含常量(即静态常量)。
6. ConcurrentHashMap 和hashMap区别是什么?
JDK1.7版本:hashmap和concurrenthashmap的区别
-
内存结构:hashmap采用数组 + 链表的结构。数组是
HashMap的主体,链表则是为了解决哈希冲突而存在。当两个不同的键通过哈希函数计算出相同的数组索引时,它们会以链表的形式存储在该索引位置。**ConcurrentHashMap**采用分段锁机制,内部结构是一个Segment数组,每个Segment类似于一个小的HashMap,它也有自己的数组和链表结构。 -
线程安全性:hashmap是非线程安全的,在多线程环境下,如果多个线程同时对
HashMap进行读写操作,可能会导致数据不一致、死循环等问题。**ConcurrentHashMap**是线程安全的。每个Segment都有自己的锁,不同的Segment可以被不同的线程同时访问,因此在多线程环境下可以提高并发性能,只有当多个线程同时访问同一个Segment时,才会发生锁竞争。 -
性能:hashmap由于没有锁的开销,在单线程环境下性能较好。但在多线程环境下,为了保证线程安全,需要额外的同步机制,这会降低性能。
**ConcurrentHashMap**通过分段锁机制,在多线程环境下可以实现更高的并发性能,不同的线程可以同时访问不同的Segment,从而减少了锁竞争的可能性。
JDK1.8版本:hashmap和concurrenthashmap的区别
-
内存结构:hashmap采用数组 + 链表 + 红黑树的结构,当链表长度超过一定阈值(默认为 8)时,链表会转换为红黑树,以提高查找效率。
**ConcurrentHashMap**弃了分段锁机制,采用 CAS +synchronized来保证线程安全,内部结构同样是数组 + 链表 + 红黑树。 -
线程安全性:hashmap仍然是非线程安全的,多线程环境下的问题依然存在。
**ConcurrentHashMap**通过 CAS 和synchronized保证线程安全。在插入元素时,首先会尝试使用 CAS 操作更新节点,如果 CAS 失败,则使用synchronized锁住当前节点,再进行插入操作。 -
性能:hashmap在单线程环境下,由于红黑树的引入,当链表较长时查找效率会有所提高。
**ConcurrentHashMap**在多线程环境下,由于摒弃了分段锁,减少了锁的粒度,进一步提高了并发性能。同时,红黑树的引入也提高了查找效率。
7. HashSet的底层实现是什么?
HashSet的底层实现基于HashMap。
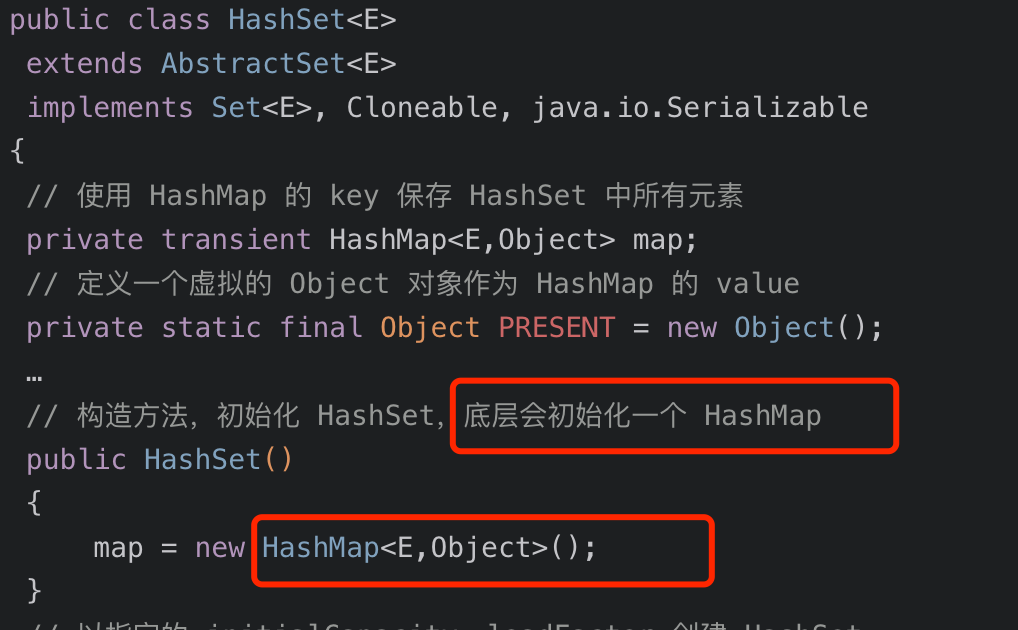
具体来说,HashSet内部维护了一个HashMap实例,当你向HashSet中添加元素时,实际上是将该元素作为HashMap的key存储,而value则是一个固定的Object对象(PRESENT)。
这种实现方式利用了HashMap的特性:
-
HashMap的key不允许重复,这保证了HashSet中元素的唯一性 -
基于哈希表的存储结构,使得
HashSet具有 O (1) 平均时间复杂度的添加、删除和查找操作 -
元素的存储顺序不保证,取决于哈希值的计算结果
8. MySQL有什么函数?
一、字符串函数
CONCAT(str1, str2, ...):连接多个字符串,返回一个合并后的字符串。
SELECT CONCAT('Hello', ' ', 'World') AS Greeting;
LENGTH(str):返回字符串的长度(字符数)。
SELECT LENGTH('Hello') AS StringLength;
SUBSTRING(str, pos, len):从指定位置开始,截取指定长度的子字符串。
SELECT SUBSTRING('Hello World', 1, 5) AS SubStr;
REPLACE(str, from_str, to_str):将字符串中的某部分替换为另一个字符串。
SELECT REPLACE('Hello World', 'World', 'MySQL') AS ReplacedStr;
二、数值函数
ABS(num):返回数字的绝对值。
SELECT ABS(-10) AS AbsoluteValue;
POWER(num, exponent):返回指定数字的指定幂次方。
SELECT POWER(2, 3) AS PowerValue;
三、日期和时间函数
NOW():返回当前日期和时间。
SELECT NOW() AS CurrentDateTime;
CURDATE():返回当前日期。
SELECT CURDATE() AS CurrentDate;
四、聚合函数
COUNT(column):计算指定列中的非NULL值的个数。
SELECT COUNT(*) AS RowCount FROM my_table;
SUM(column):计算指定列的总和。
SELECT SUM(price) AS TotalPrice FROM orders;
AVG(column):计算指定列的平均值。
SELECT AVG(price) AS AveragePrice FROM orders;
MAX(column):返回指定列的最大值。
SELECT MAX(price) AS MaxPrice FROM orders;
MIN(column):返回指定列的最小值。
SELECT MIN(price) AS MinPrice FROM orders;
9. SpringBoot启动的过程是怎样的?
SpringBoot是一个服务Spring框架的框架,能够简化配置文件,快速构建web应用,内置tomcat,无需打包部署,直接运行。 当我们启动一个SpringBoot应用的时候,都会用到如下的启动类:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
只要加上@SpringBootApplication,然后执行run()方法,就可以启动一个应用程序,启动的流程如下:
-
首先从main找到run()方法,在执行run()方法之前new一个SpringApplication对象
-
进入run()方法,创建应用监听器SpringApplicationRunListeners开始监听
-
然后加载SpringBoot配置环境(ConfigurableEnvironment),然后把配置环境(Environment)加入监听对象中
-
然后加载应用上下文(ConfigurableApplicationContext),当做run方法的返回对象
-
最后创建Spring容器,refreshContext(context),实现starter自动化配置和bean的实例化等工作。
10. 项目
-
选一个最有挑战的项目,遇到最有挑战的是什么,怎么解决的,怎么分析
11. 手撕算法
-
压缩字符串

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)