大模型后训练——总结
大模型后训练——总结
·
大型语言模型在能够执行指令和回答问题之前,需要经历预训练(Pre-training)和后训练(Post-training)两个核心阶段。
- 预训练阶段,模型通过学习从海量未标注的文本中预测下一个词或token来掌握基础知识。而在后训练阶段,模型则着重学习实际应用中的关键能力,包括准确理解并执行指令、熟练运用工具,以及进行复杂的逻辑推理。
- 后训练是将在海量无标签文本上训练的原始的通用语言模型转变为能够理解并执行特定指令的智能助手的过程。无论是想打造一个更安全的 AI 助还是提升特定手、调整模型的语言风格,任务的精确度,后训练都不可或缺。
后训练是大语言模型训练中发展最迅速的研究方向之一。
而在本课程中,就可以学习到三种常见的后训练方法——监督微调(SFT)、直接偏好优化(DPO)和在线强化学习(Online RL)——以及如何有效使用它们。
学习地址:总结。
在本课程中,我们已经学习了几种流行的后训练方法以及它们最常见的应用场景。让我们再来回顾一下所有这些内容。

- 对于监督微调(SFT),其背后的原理是通过最大化响应的概率来模仿示例回复。因此,它的实现简单,非常适合开启新的模型行为。然而,对于训练数据中未包含的任务,它可能会降低模型在这些任务上的性能。
- 对于在线强化学习,其原理是最大化响应的奖励函数。因此,它实际上在提升模型能力的同时,不会降低模型在未见任务上的性能。然而,它的实现最为复杂,并且需要精心设计奖励函数才能真正发挥良好效果。
- 对于直接偏好优化,如果你鼓励好的答案,同时不鼓励不好的答案,就在此处提供相关信息。因此,它以对比的方式训练模型,在纠正错误行为和提升特定能力方面表现出色。然而,它可能容易出现过拟合,并且实现复杂度介于SFT和在线强化学习之间。
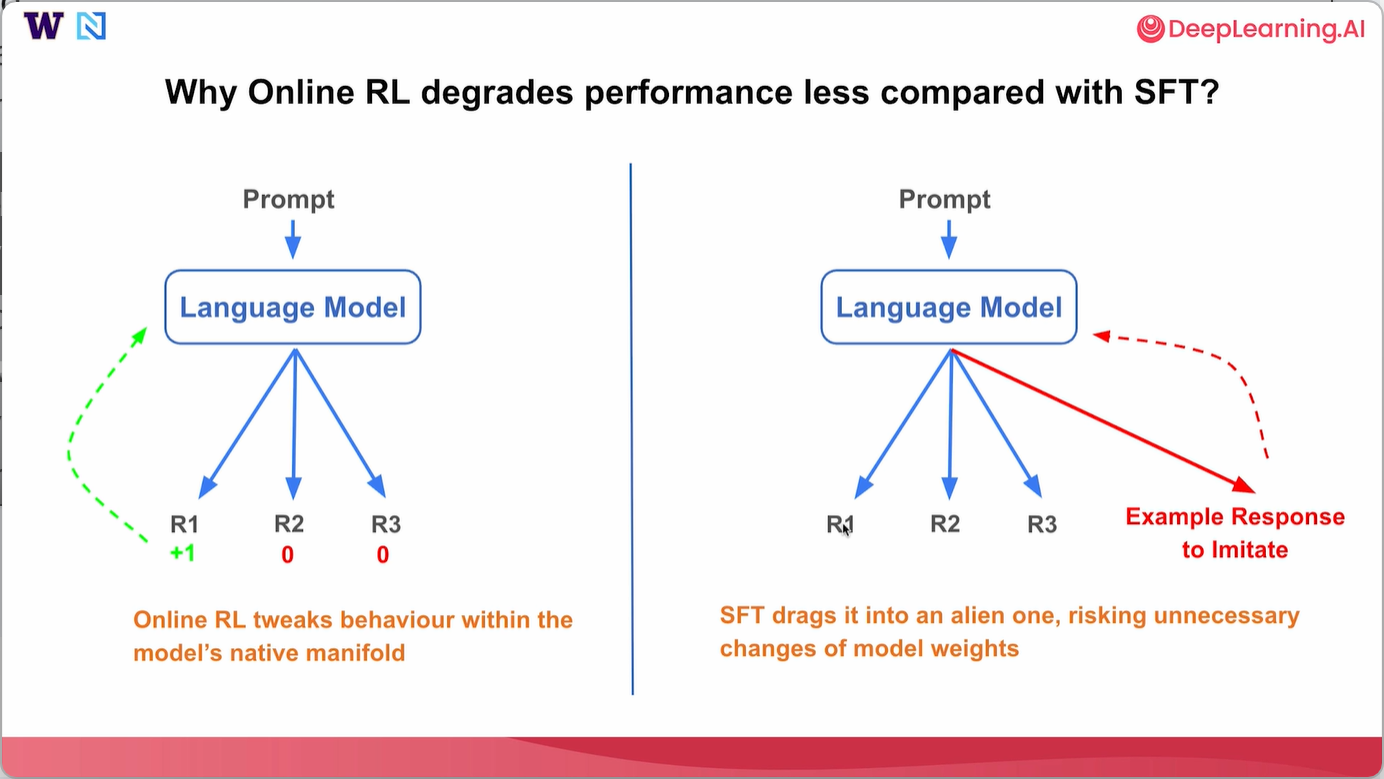
最后讨论一点,为什么在线强化学习相比SFT可能对性能的降低较少。通常,当你向语言模型发送一个提示,让它生成自己的答案R1、R2和R3时,我们的强化学习会从模型自身生成的每个响应中获得奖励,然后将反馈提供给语言模型,并根据该信号更新语言模型的权重。
本质上,在线强化学习试图在模型自身的固有流形内调整模型行为。另一方面,对于监督微调,你向语言模型发送提示,语言模型可能仍然会泛化出不同的响应。然而,提供的用于模仿的示例响应可能与模型想要生成的所有响应截然不同。在这种情况下,SFT可能会将模型引入一个陌生的方向,并有不必要改变模型权重的风险。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)