Ragflow+TextIn实战!高精度AI解析+OCR优化,打造高性能RAG系统
RAGFlow是开发团队常用的企业级知识问答框架,其核心优势在于简化RAG流水线开发,但内置的DeepDoc解析器存在文档识别错误、分栏错乱等问题。本文提出采用TextIn xParse等第三方解析工具优化文档处理质量,对比了开源与商业化产品的优劣势,并给出两种集成方案:直接API导入或修改RAGFlow代码。重点演示了TextIn在复杂表格、跨页内容、多栏文档上的精准解析能力,最终通过代码改造实
对于高专业性或企业级的知识问答应用,RAGFlow是各个开发团队的常用框架,它提供的工具链简化了从知识库搭建、向量检索到生成的RAG流水线开发。RAG这条务实的路径让LLM能实时查询私有知识库,显著提升回答相关性和可控性,避免直接调用LLM产生的知识更新慢、回答不准或数据安全风险。
构建健壮的RAG系统,尤其是企业级应用,涉及复杂组件集成与优化。如何在RAGFlow基础上实现性能优化,也成为大家关注的课题。
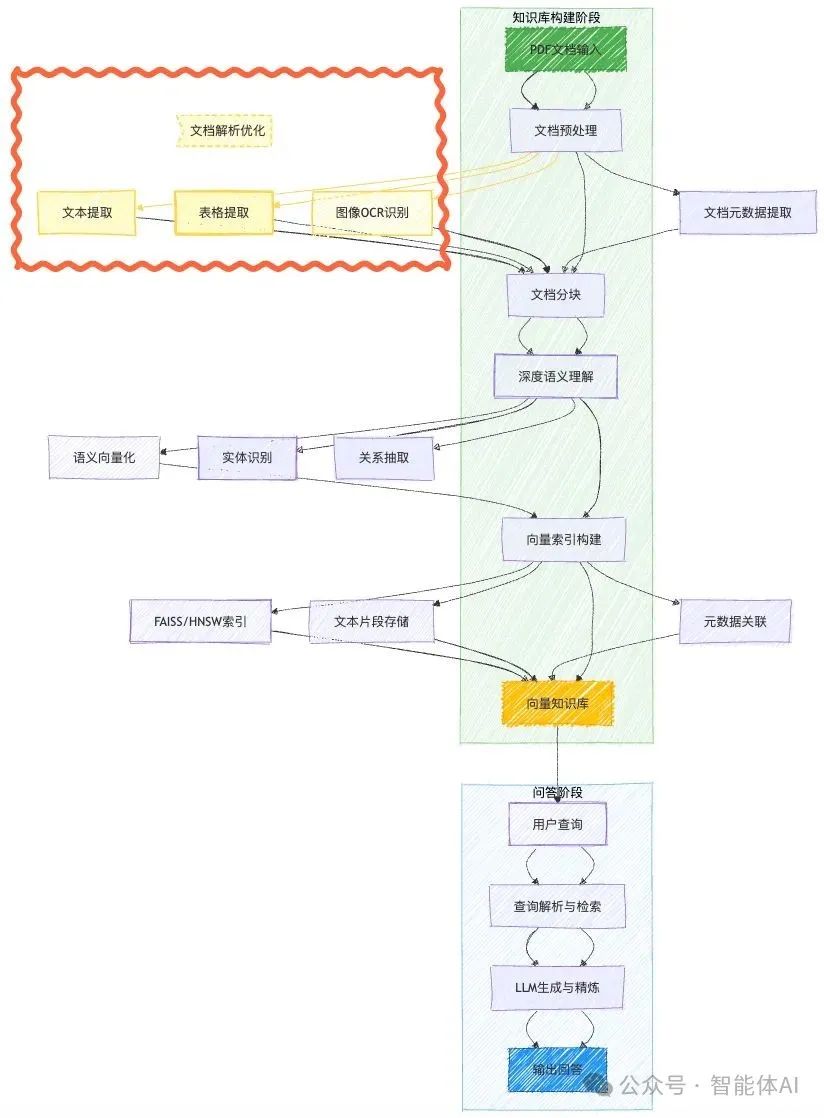
从RAG链路出发,首要关键因素即是文档解析的质量。解析输出的数据是AI应用的“基础燃料”,影响后续分块、检索和最终结果。而在应用RAGFlow框架时,其自研的DeepDoc解析算法表现经常不尽如人意。
如下图中,对于同一份文件的连续两页目录,DeepDoc将其中一页识别为正文,另一页识别为表格,这也导致了后续分块的错误。

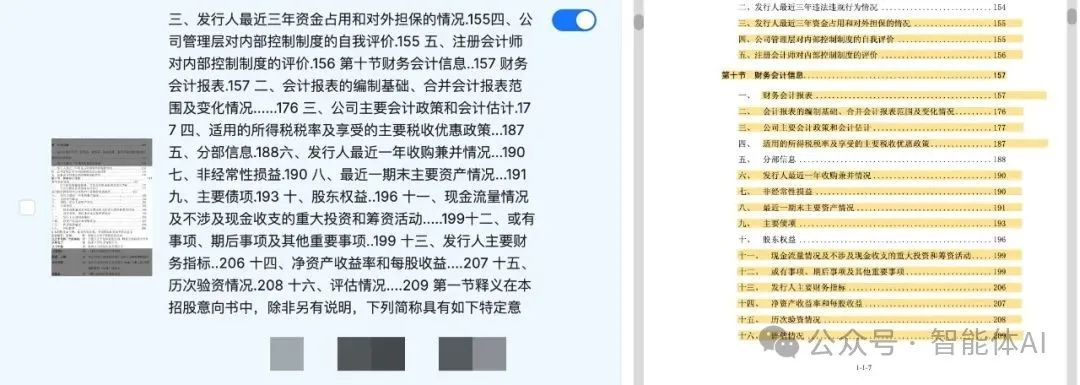
图1

图2
在实际使用中发现的解析问题还包括:对学术论文等分栏文档,内容顺序存在错乱(如从左栏跳至右栏)深度嵌套表格或跨页合并单元格导致数据结构丢失标题层级识别错乱模糊、倾斜或阴影干扰的扫描件OCR错误率较高,书籍装订区附近的文字因弯曲变形无法识别
为了优化解析效果,避免文档中的关键信息在导入知识库时就发生损耗,我们采用了自定义解析工具的策略。
本文将说明文档解析工具的类型与适用性、TextIn的性能、在RAGFlow框架下使用自定义解析的方法、实战教程与完整代码。
了解文档解析工具
简单来说,文档解析工具的核心任务是将非结构化文档(如PDF、图片、扫描件)中的文本、表格、图片等内容识别并提取出来,转化为结构化数据以供机器处理和分析。从社区或商业化、使用方法上,可以区分几种类型:
是否开源
文档解析工具可分为开源和闭源两大类,它们在开放性、可控性、成本和功能深度上存在着差异。开源工具如PyMuPDF、MinerU、Marker等,商业化产品例如本文实战应用中使用的TextIn xParse。
开源产品的优势在于:1、最为显然的,用户不需要支付软件许可费用。2、高透明度,且可以根据自身需求自由修改、扩展源代码。3、活跃的开源社区可以贡献代码、修复漏洞、提供支持,加速工具的发展和问题解决。
另一方面,其劣势主要体现在:1、技术门槛高:需要具备相当的开发、运维和系统集成能力才能有效部署、配置、定制和维护,对非技术团队或资源有限的组织挑战较大。2、集成与维护负担:用户需自行解决依赖关系、环境配置、版本升级、性能调优、安全补丁等运维工作,耗费时间和人力。3、专业支持有限:主要依赖社区支持,响应速度和问题解决的专业性、保障性通常不如商业闭源产品的官方支持。4、特定场景功能不足:针对特定行业场景(例如复杂的财务表格、医疗报告结构化)的预训练模型或精细化处理能力,可能不如成熟的商业闭源产品。
商业化产品的劣势在于使用成本与低透明度(用户无法直接修改核心代码)。而优势则包括:1、开箱即用,易于集成:通常提供完善的前端界面、软件开发工具包(SDK)、清晰的文档和示例,集成相对简单快捷,使用技术门槛低。2、专业支持与服务:提供专业的技术支持、问题响应、培训服务,减轻用户运维负担。3、深度优化与特定功能:厂商投入大量资源进行核心算法研发、模型训练(尤其在特定领域如法律合同、医学文献、复杂表格识别)和性能优化,往往在精度、特定场景覆盖和功能深度上具备优势。4、持续更新与维护: 专业厂商负责产品的迭代更新、功能增强、漏洞修复和性能优化,用户无需操心底层技术细节。
API调用 vs. 本地部署
在使用方法这个维度,主要有API调用和本地化部署两类,特点如下:
API调用方法便于:1、快速启动,零运维: 无需购置、配置和管理服务器基础设施,注册账号、获取API密钥即可立即使用,大幅缩短上线时间。2、持续获取最新能力: 用户自动获得供应商发布的最新模型、功能和性能优化,无需手动升级。3、降低初始投入: 通常按需付费,避免了前期高昂的硬件和软件许可投资。
但同时,风险项在于:1、不符合部分企业的数据安全要求。2、解析速度和稳定性受网络状况影响。3、 API提供的是标准化的功能接口,功能定制相对受限。
本地部署模式能够保障:1、数据安全与合规性: 文档数据完全保留在用户自己的基础设施(如私有云、数据中心)内部处理,最大程度降低数据风险,更容易满足严格的合规和监管要求。2、性能与延迟可控: 处理过程在本地网络进行,不受公网质量影响,通常延迟更低。对于超大文件或批处理,本地资源更可控。
而其劣势体现在:1、高初始投入与运维负担: 需采购、配置和维护服务器硬件、存储、网络以及软件环境(包括可能的GPU资源),需要专业的IT运维团队。2、部署复杂,上线周期长: 安装、配置、测试和优化本地部署的解决方案需要较长时间和专业知识。3、更新滞后: 用户需要主动关注并手动执行版本升级来获取新功能和修复,过程可能繁琐且存在兼容性风险。
总体来说,最佳选择往往取决于具体需求和资源情况。这一期RAGFlow实战演示中,我们对复杂文档的解析精度有较高要求,同时考虑调用便捷程度,选择了TextIn xParse,支持直接API调用。
TextIn xParse
聊一下为何选择TextIn。
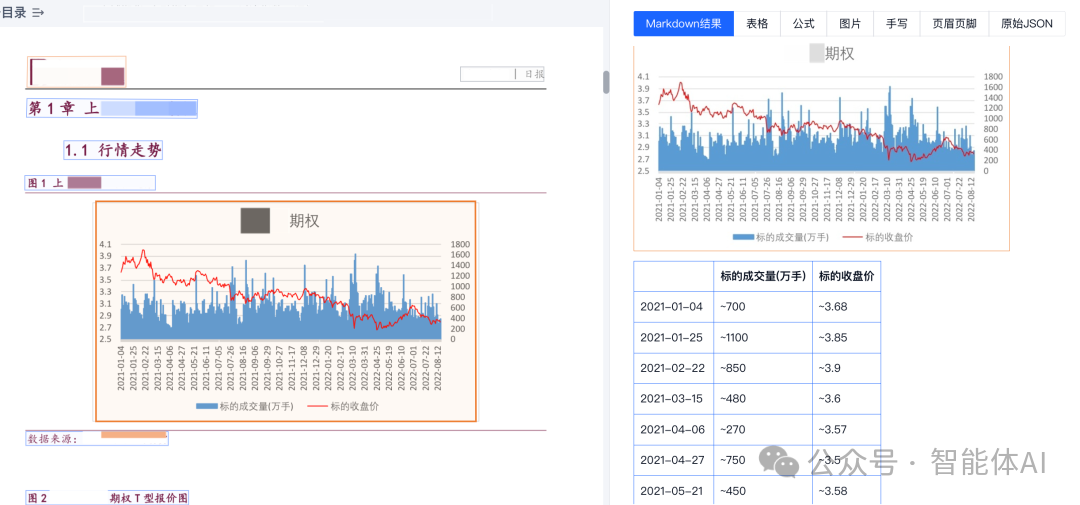
TextIn xParse文档解析是一款大模型友好的解析工具,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为Markdown或JSON格式返回,同时包含精确的页面元素和坐标信息。支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,能满足绝大部分复杂文档的解析需求。
根据官方文档,核心能力包括:
- 多种版面元素高精度解析:精准识别标题、公式、图表、手写体、印章、页眉页脚、跨页段落,实现高精度坐标还原,并捕捉版面元素间的语义关系,提升大模型应用表现。
- 行业领先的表格识别能力:轻松解决合并单元格、跨页表格、无线表格、密集表格等识别难题。
- 阅读顺序还原准:理解、还原文档结构和元素排列,确保阅读顺序的准确性,支持多栏布局的论文、年报、业务报告等。
- 自研文档树引擎:基于语义提取段落embedding值,预测标题层级关系,通过构造文档树提高检索召回效果。
- 支持多种扫描内容:能良好处理各类图片与扫描文档,包括手机照片、截屏等内容。
- 支持多种语言:支持简体中文/繁体中文/英文/数字/西欧主流语言/东欧主流语言等共50+种语言。
- 集成强大的图像处理能力:文件带水印、图片有弯曲,都能一键解决,排除图像质量干扰。
- 开发者友好:提供清晰的API文档和灵活的集成方式,包括MCP Server、Coze、Dify插件,支持FastGPT、CherryStudio、Cursor等主流平台。
实际的解析效果可以通过一些样本实测初步判断。对于不同的文档集,文档解析工具的效果可能有所差异,大家在调用之前也可在官网上用免费的1000页额度测一下自己的样本:https://cc.co/16YSWg
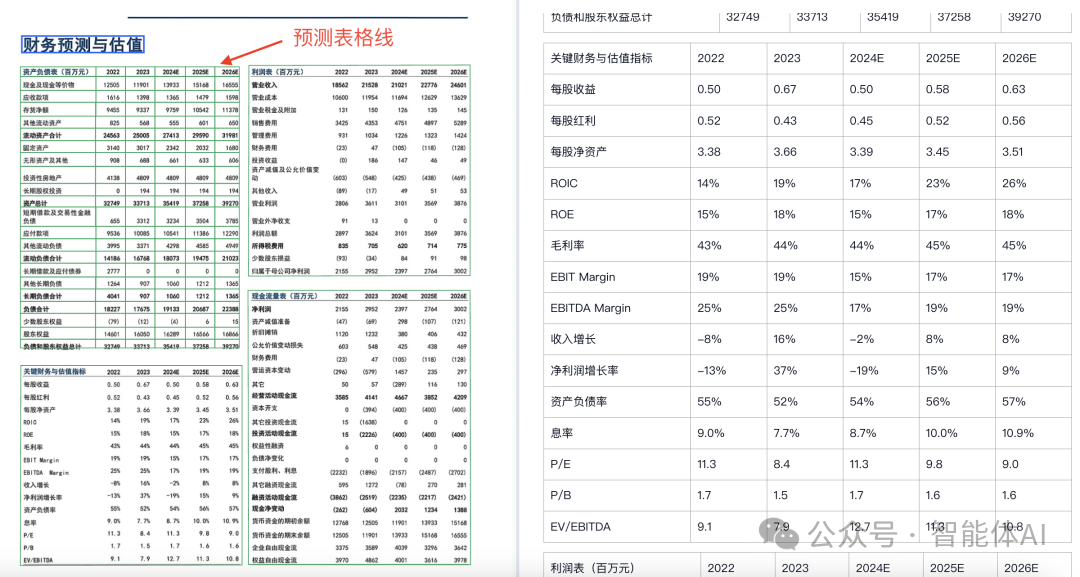
密集少线表格识别效果很好,官网前端支持选中表格并在原图上显示模型预测的单元格(TextIn这套前端工具已经开源了,项目地址:https://github.com/intsig-textin/textin-ocr-frontend)。

跨页表格合并效果好,也能精准识别页眉页脚。

多栏学术论文的阅读顺序还原很准确。
对于没有精确数值标注的图表,会通过测量给出预估数值;这个功能对金融分析类工作会很有帮助。

TextIn解析内置有图像处理算法,能解决弯折、倾斜、阴影、模糊这些常见的图像质量问题。
RAGFlow+TextIn知识库构建方法
要在RAG流程中实现自定义解析,我们可以考虑两种方案,便捷程度和效果有所差异,下面具体讨论:
方法1:解析后上传知识库
较为简易的方案,直接调用自定义解析接口,解析完成后通过API导入RAGFlow知识库。
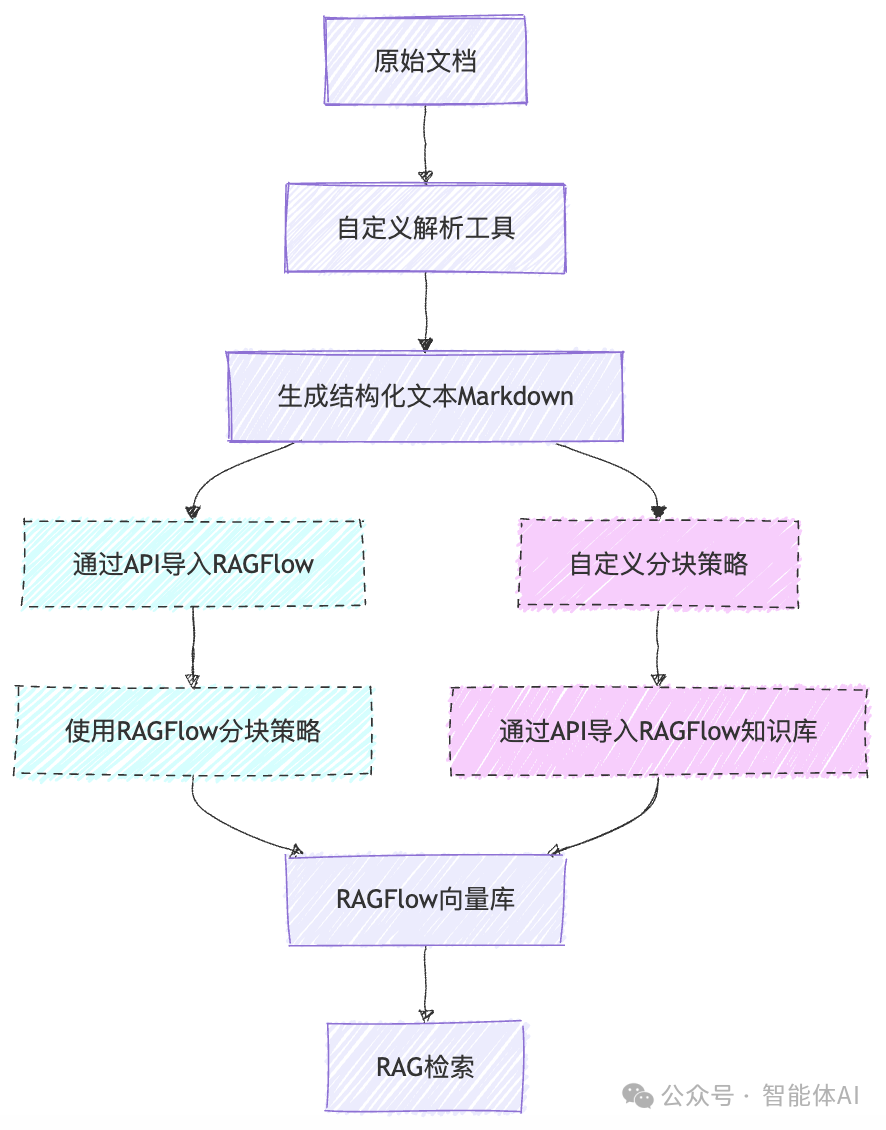
可以在导入后使用RAGFlow分块策略,也可自行完成Chunking后输入知识库。
这种方法最大的好处在于简便快捷,但由于RAGFlow的API导入有一定缺陷,会产生上传信息不完整(如缺少图片、位置信息)、分块顺序紊乱等问题,因而在知识库预览时也无法联动PDF源文件位置,快速进行对应查看和校对。
如下图3是解析后上传知识库的效果图,图4是在RAGFlow框架内完成解析后的效果,对比可以看到差异。
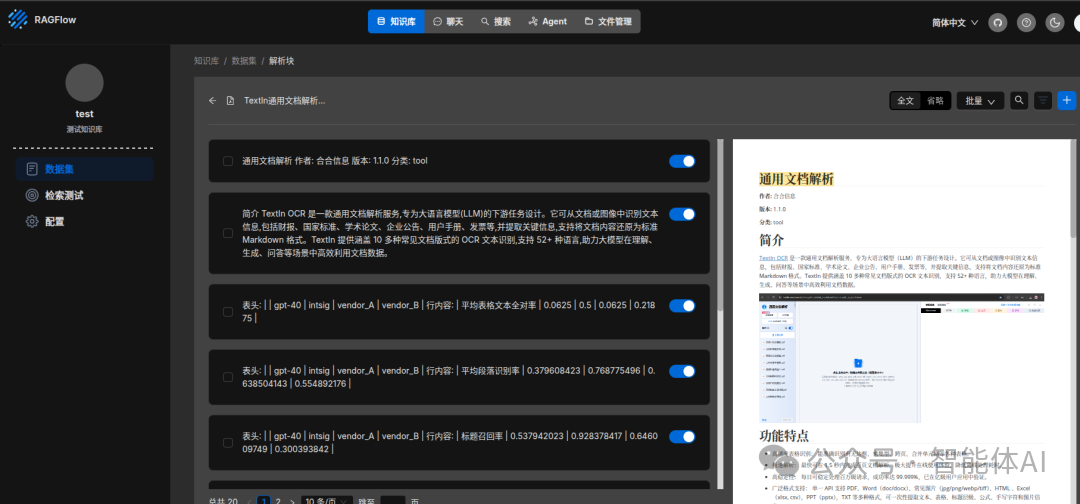
图3
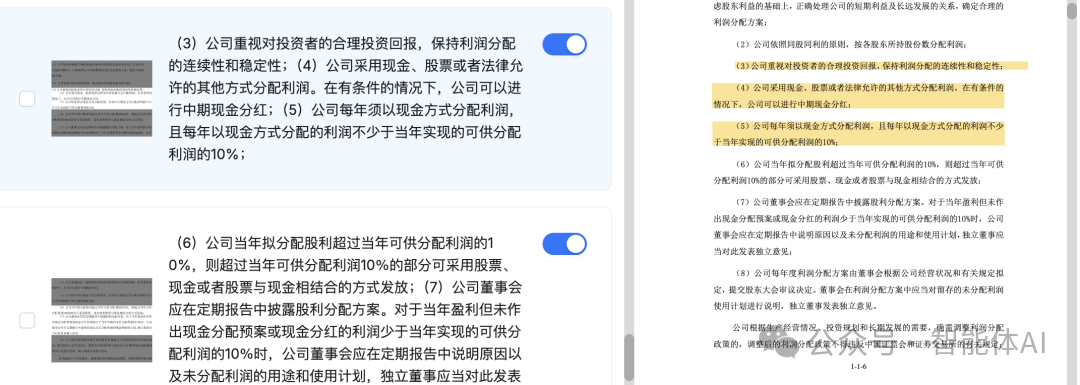
图4
因此,该方案适合少量文件补充处理,如果要建立更完善的知识库搭建全流程,我们还需要另寻他法。
方法2:修改RAGFlow代码改变解析策略
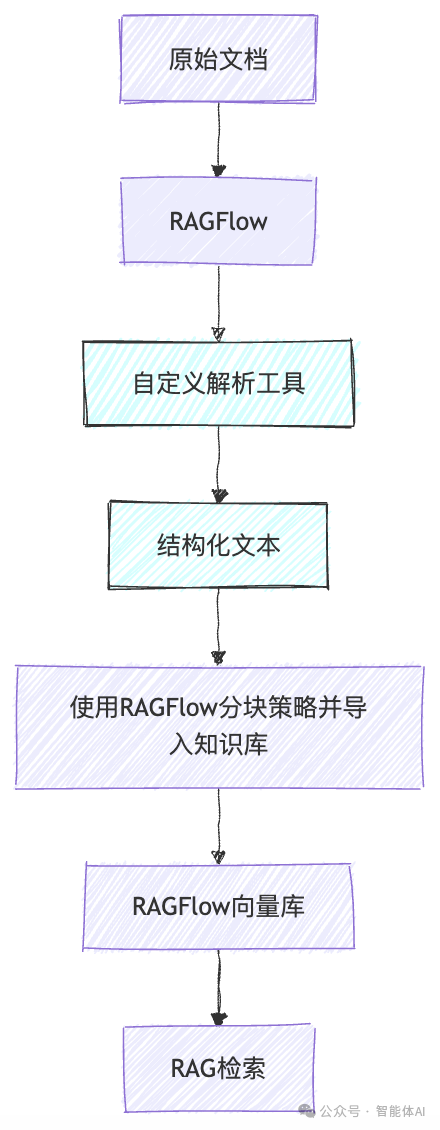
通过代码修改,我们能从结构上改变解析策略,也能够解决方法1中的不适配问题,实现更彻底的流程搭建。下面,我们来看具体的实战教程,如何快速实现解析方法替换。
1分钟实战教程
1、启动服务(测试的镜像版本为 infiniflow/ragflow:v0.20.1 )
docker compose -f docker-compose-gpu.yml up -d
2、t****extin.com 获取 app-id和secret-code信息
3、替换镜像中的 /ragflow/rag/app/naive.py 文件 (注意修改438行、439行的 x-ti-app-id 和 x-ti-secret-code)
**完整代码文件地址:**https://dllf.textin.com/download/2025/CustomService/naive.py
docker cp naive.py ragflow-server:/ragflow/rag/app/naive.py
4、重启服务
docker compose restart
进阶方案详解
我们来详细解读方案逻辑。
首先,需要厘清Ragflow的解析分块过程。
流程源码路径清单总览

解析和分块代码分析
以native分块策略,调用DeepDOC解析PDF文件为例,对应的源码路径为ragflow/rag/app/naive.py。
首先调用PDF解析器:
class Pdf(PdfParser):
def __init__(self):
def __call__(self, filename, binary=None, from_page=0,
to_page=100000, zoomin=3, callback=None, separate_tables_figures=False):
start = timer()
first_start = start
callback(msg="OCR started")
# ocr识别
self.__images__(
filename ifnot binary else binary,
zoomin,
from_page,
to_page,
callback
)
callback(msg="OCR finished ({:.2f}s)".format(timer() - start))
start = timer()
# 布局分析 识别标题/段落等层级
self._layouts_rec(zoomin)
callback(0.63, "Layout analysis ({:.2f}s)".format(timer() - start))
start = timer()
# 使用 transformer 进行表格检测与识别
self._table_transformer_job(zoomin)
callback(0.65, "Table analysis ({:.2f}s)".format(timer() - start))
start = timer()
self._text_merge()
callback(0.67, "Text merged ({:.2f}s)".format(timer() - start))
# 是否分离表格和图形
ifseparate_tables_figures:
tbls, figures = self._extract_table_figure(True, zoomin, True, True, True)
self._concat_downward()
logging.info("layouts cost: {}s".format(timer() - first_start))
# 返回文本块+表格+图形
return [(b["text"], self._line_tag(b, zoomin)) for b inself.boxes], tbls, figures
else:
tbls = self._extract_table_figure(True, zoomin, True, True)
# self._naive_vertical_merge()
self._concat_downward()
# self._filter_forpages()
logging.info("layouts cost: {}s".format(timer() - first_start))
return [(b["text"], self._line_tag(b, zoomin)) for b inself.boxes], tbls
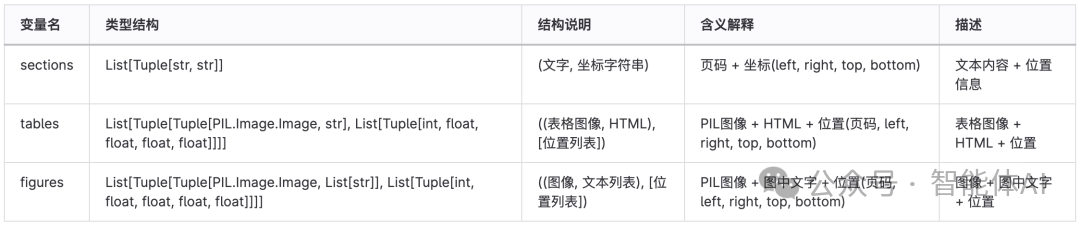
pdf解析器返回的数据结构:
后续将调用以下两个方法,分别处理段落和表格的分块:
- res = tokenize_table(tables, doc, is_english):处理表格分块
- res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images)):处理文本段落分块
分块逻辑位于ragflow/rag/nlp,整体策略如下:
-
优先结构分块
-
- 基于章节的层级关系(如标题编号、目录结构)划分文本。
- 提取结构化标题作为内容边界,实现更合理的语义组织。
-
结构不足时退化为语义分块
-
- 使用标点符(如。?!;)切分内容。
- 自动组合短句,控制每块文本token数量接近预设值,避免碎片或过长。
-
图文与表格信息补充
-
- 表格内容按行或批次合并为一个文本块。
- 每个块附带原始图像(PIL.Image)及位置信息(页码与坐标)。
- 文本块可拼接多个图像,支持图文联合处理,提升展示效果。
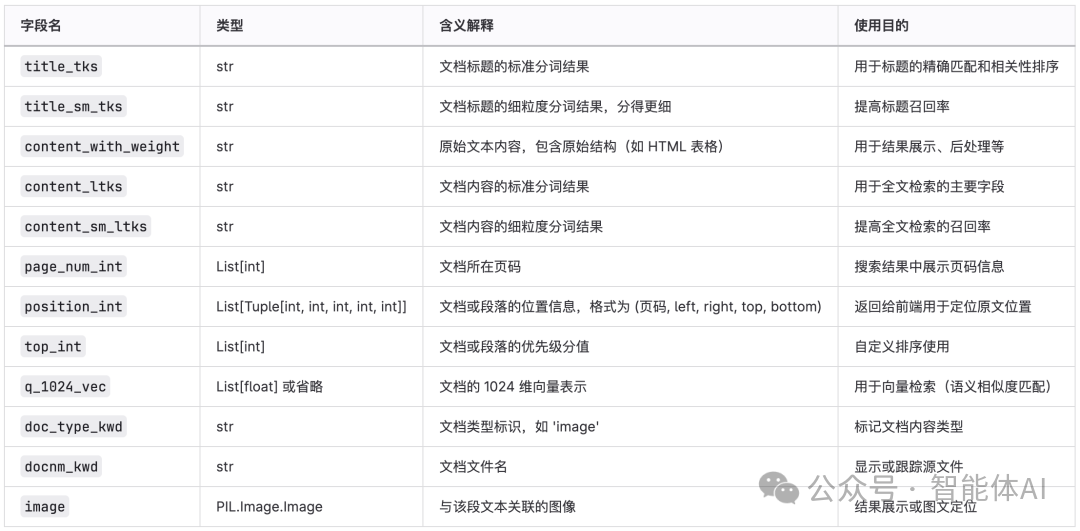
chunk分块返回的数据结构:
通过分析解析分块过程,只需要构造对应的数据结构和修改相应的代码,就可以替换解析和分块。
将DeepDoc解析替换为TextIn解析
1、跳过版面分析
修改文件/ragflow/rag/app/naive.py,修改PDF类的call方法提前返回,仅保留对images的调用。
class Pdf(PdfParser):
def __init__(self):
super().__init__()
def __call__(self, filename, binary=None, from_page=0,
to_page=100000, zoomin=3, callback=None, separate_tables_figures=False):
start = timer()
first_start = start
callback(msg="OCR started")
self.__images__(
filename ifnot binary else binary,
zoomin,
from_page,
to_page,
callback
)
callback(msg="OCR finished ({:.2f}s)".format(timer() - start))
logging.info("OCR({}~{}): {:.2f}s".format(from_page, to_page, timer() - start))
return [], [] # 提前结束返回
2、跳过OCR识别(该操作会影响块保存的截图,不影响定位到原文档,也可不跳过)
修改文件/ragflow/deepdoc/parser/pdf_parser.py,保留前面通过pypdf获取文本判断是否为英文文档的部分,只跳过OCR识别。
async def __img_ocr(i, id, img, chars, limiter):
return # 提前结束返回
3、将解析部分替换为TextIn调用
修改文件/ragflow/rag/app/naive.py,修改chunk函数if layout_recognizer == “DeepDOC”:分支下的代码。
if layout_recognizer == "DeepDOC":
pdf_parser = Pdf()
# 下面是替换的代码
import json
import requests
sections, tables = pdf_parser(filename ifnot binary else binary, from_page=from_page, to_page=to_page, callback=callback)
headers = {
'x-ti-app-id': '***',
'x-ti-secret-code': '***',
'Content-Type': 'application/octet-stream'
}
# 这里不需要latex格式的公式,formula_level设为2
result = requests.post('https://api.textin.com/ai/service/v1/pdf_to_markdown',
data=binary,
headers=headers,
params = {
'paratext_mode': 'none',
'formula_level': 2,
'page_start': from_page + 1,
'page_count': to_page - from_page
}
)
json_data = result.json()
detail = json_data.get('result', {}).get('detail', {})
sections=[]
tables=[]
for item in detail:
page_id = item.get('page_id')
text = item.get('text')
text = re.sub(r'\*\*(.+?)\*\*', r'\1', text) # 去除加粗格式,例如 **text** → text
text = re.sub(r'\*(.+?)\*', r'\1', text) # 去除斜体格式,例如 *text* → text
text = re.sub(r'_(.+?)_', r'\1', text) # 去除下划线斜体格式,例如 _text_ → text
text = re.sub(r'!\[.*?\]\((.*?)\)', '', text) # 删除图片标记,例如  → 空
type = item.get('type')
sub_type = item.get('sub_type')
position = item.get('position')
x0, y0, x1, y1 = position[0]/2.0, position[1]/2.0, position[4]/2.0, position[5]/2.0# TextIn解析默认ppi 144, DeepDOC默认ppi 72
if type == 'paragraph':
if sub_type notin ['text', 'text_title', 'table_title', 'sidebar']: # 按需保留需要的类型
continue
sections.append((text, f'@@{page_id - from_page}\t{x0}\t{x1}\t{y0}\t{y1}##'))
elif type == 'table':
text = text.replace('<br>', '') # 按需处理文本,这里移除表格单元格内的换行符
text = text.replace('border="1"', '')
tables.append(((None, text), [(page_id-1, x0, x1, y0, y1)]))
callback(0.6, "TextIn parsing")
# 上面是替换的代码
res = tokenize_table(tables, doc, is_english)
callback(0.8, "Finish parsing.")
解析效果对比
从知识库查看分块结果,可以明显看出解析效果提升,文本和表格识别准确率提高。
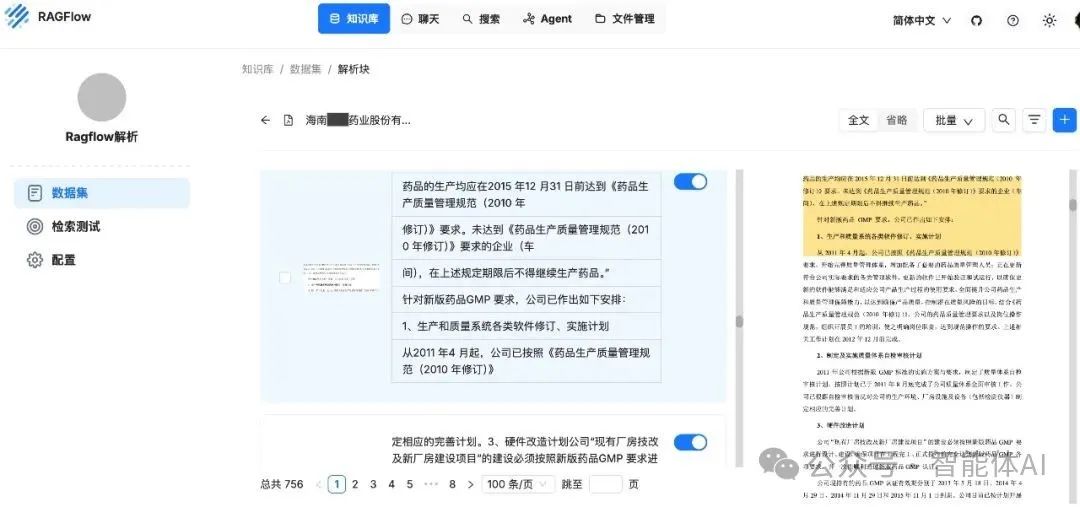
DeepDoc解析分段结果
TextIn解析分段结果
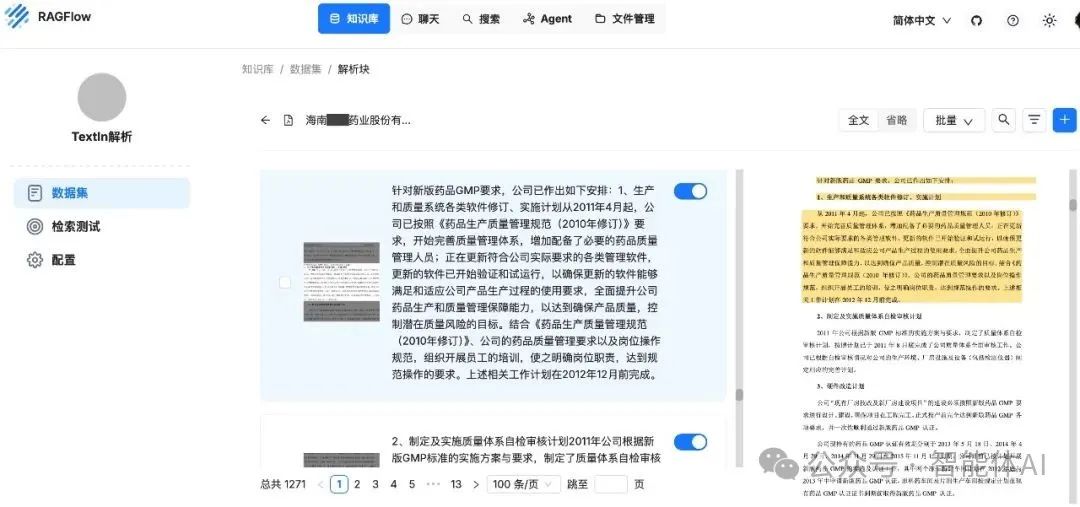
如图可以看到,DeepDoc将行间距较大的文本、小标题识别为表格,这也影响了后续的分段。TextIn能够准确识别标题、段落,使系统获得完整的结构信息,实现更合理分段。
DeepDoc解析分段结果
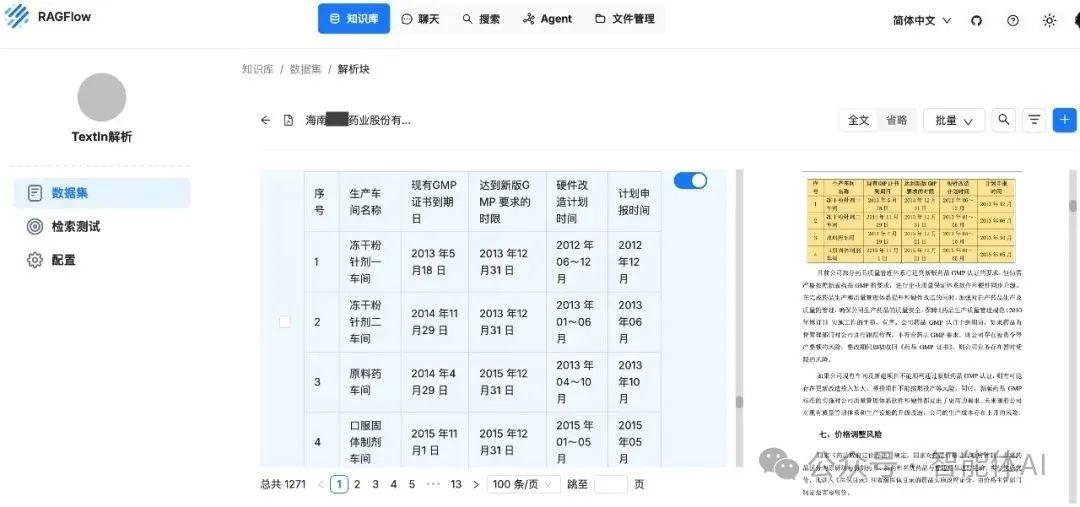
TextIn解析分段结果
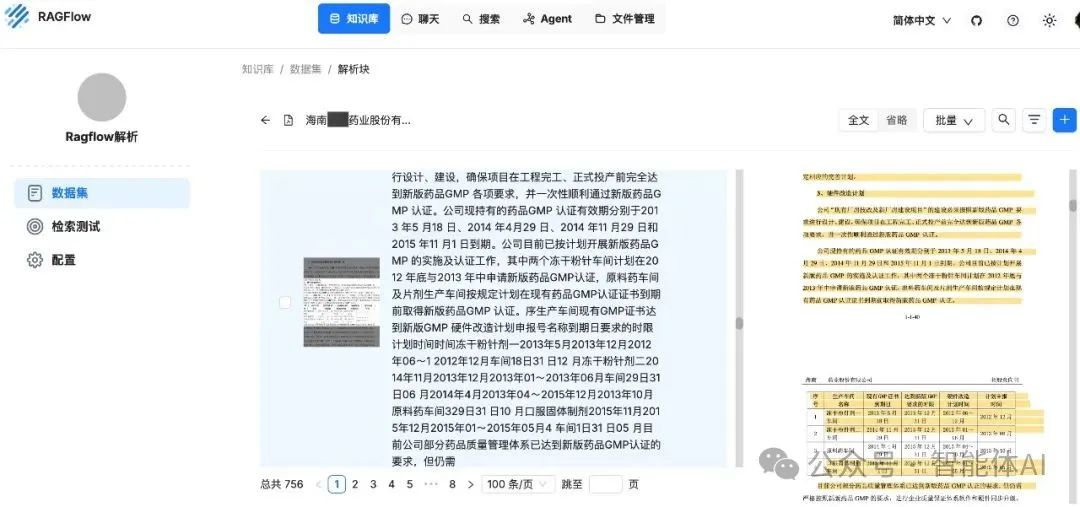
如上图所示,DeepDoc解析未能准确识别表格,而表格是文档中数据密集的所在,往往含有关键信息,准确的表格识别对RAG问答性能有相当大的影响。TextIn解析后的分段实现了准确、完整的语义提取。
写在最后
RAG优化方案进一步探讨
RAG系统的优化是一项环环相扣的工程。优质的文档解析结果提供了系统运行的基础,接下来,切片也是影响RAG能力的重要因素。
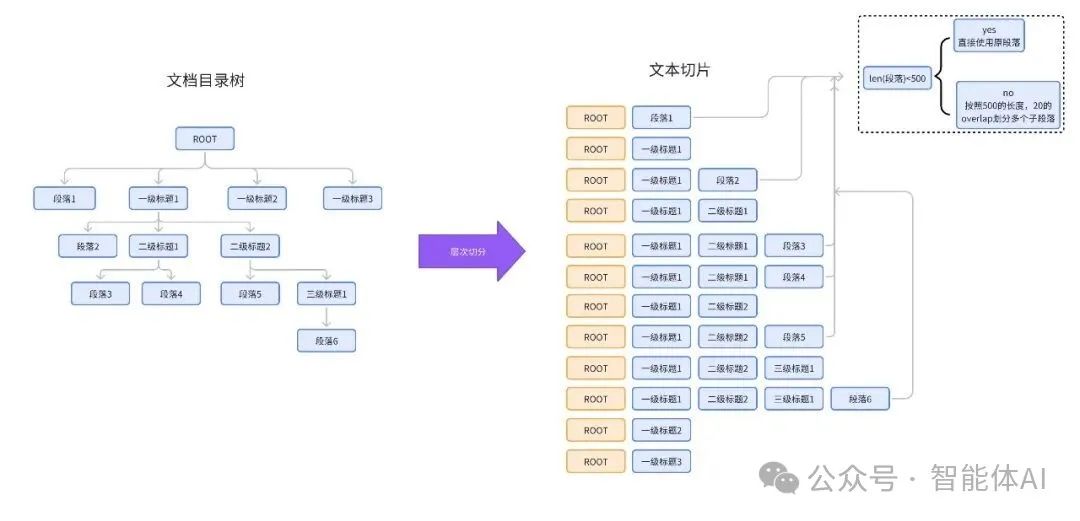
切片策略目前业界也有很多思考,其实际应用受制于输入的结构化文件、上下文窗口长度等因素。我们在此提出一些可能性,与大家一起探讨:
- 保留文档结构:通过目录树(Root/Heading/Text/Table等节点)维护标题层级关系和语义上下文,实现标题层级递归切片,保留文档内在逻辑结构的完整性。
- 动态处理长内容:超长文本/表格按固定窗口切分,标题节点合并子内容。
- 优化检索效率:以最小内容单元(子段落)作为检索主体,提升匹配精度。
总结
本文介绍了基于RAGFlow自定义解析工具的实战经验,通过优化文档解析环节,提升RAG系统整体性能。高质量的文档解析对RAG应用性能的影响已经得到验证:它决定了知识被结构化、理解和检索的效率。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)