AI总记不住上下文?MCP 智能化上下文管理,让智能体真正“长记忆”
MCP上下文管理与持久化技术解决了传统AI的"健忘症"问题,通过三层记忆架构(即时、工作、长期记忆层)实现跨会话记忆。该技术包含智能化上下文压缩、分层存储、会话管理等功能,使AI能够保持工作连续性、记住决策历史。应用于企业场景如金融客服、制造业设备维护等,赋予AI从"工具"升级为"工作伙伴"的能力,同时保障数据安全与隐私。
前言
如果说传统 AI 就像患有“健忘症”的专家,每次对话都要重新开始,那么 MCP 的上下文管理就是给 AI 装上了“永久记忆”。这不只是技术升级,而是 AI 从“对话工具”迈向“工作伙伴”的关键一步。
1、上下文管理的核心挑战
传统 AI 的记忆困境
第一、Token 限制问题:
-
Claude-3: 200K tokens ≈ 150,000 字
-
ChatGPT-4: 128K tokens ≈ 100,000 字
-
Gemini: 2M tokens ≈ 1,500,000 字
但复杂的企业对话往往需要:
- 历史决策记录
- 项目背景资料
- 技术规格文件
- 工作流程状态 = 轻易超过任何模型的上下文限制
第二、状态丢失问题:
-
- 对话前段:“我们决定使用 PostgreSQL 作为主数据库”
- 对话中段:(讨论 API 设计、前端开发…)
- 对话后段:“数据库用什么?”
- AI 回答:“建议考虑 MySQL 或 PostgreSQL…”
- 结果:AI 忘记了自己的决定!
为了优雅地解决这些问题,我们需要引入 基于 MCP 的智慧化上下文管理技术,下文我们详细剖析之。
1、MCP 的革命性解决方案
1、智能化上下文分层管理
MCP 建立了一个三层记忆架构,模拟人类的记忆模式:
-
即时记忆层 (Session Memory)
-
- 当前对话内容
- 近期操作记录
- 暂时工作状态
-
工作记忆层 (Working Memory)
-
- 项目相关上下文
- 任务执行状态
- 决策历程记录
-
长期记忆层 (Persistent Memory)
-
- 历史对话摘要
- 学习模式记录
- 知识库累积
2、会话管理机制
会话生命周期:
class MCPSessionManager: def __init__(self): self.sessions = {} self.context_store = PersistentContextStore()
async def create_session(self, user_id: str, project_id: str = None): """建立新的工作会话""" session_id = str(uuid.uuid4())
session = MCPSession( id=session_id, user_id=user_id, project_id=project_id, created_at=datetime.now(), context_window=ContextWindow(max_tokens=150000), persistent_memory=await self._load_persistent_context(user_id, project_id), working_memory=WorkingMemory() )
self.sessions[session_id] = session return session
async def restore_session(self, session_id: str): """恢复之前的会话状态""" if session_id in self.sessions: return self.sessions[session_id]
# 从持久化存储恢复 session_data = await self.context_store.load_session(session_id) if session_data: session = MCPSession.from_dict(session_data) self.sessions[session_id] = session return session
return None
3、智能化上下文压缩
重要性评分机制:
class ContextImportanceEvaluator: def __init__(self): self.importance_factors = { 'decision_made': 1.0, 'error_encountered': 0.9, 'requirement_defined': 0.8, 'progress_milestone': 0.7, 'general_discussion': 0.3 }
def evaluate_context_importance(self, context_item: dict) -> float: """评估上下文项目的重要性""" importance = 0.0
# 基于内容类型评分 content_type = context_item.get('type', 'general_discussion') importance += self.importance_factors.get(content_type, 0.3)
# 基于引用频率评分 reference_count = context_item.get('reference_count', 0) importance += min(reference_count * 0.1, 0.5)
# 基于时间衰减 age_days = (datetime.now() - context_item['created_at']).days time_decay = max(0.1, 1.0 - (age_days * 0.02)) importance *= time_decay
return min(importance, 1.0)
async def compress_context(self, context_items: List[dict], target_tokens: int): """智能化压缩上下文到目标大小""" # 评估所有项目的重要性 scored_items = [] for item in context_items: score = self.evaluate_context_importance(item) scored_items.append((score, item))
# 按重要性排序 scored_items.sort(key=lambda x: x[0], reverse=True)
# 选择最重要的项目直到达到目标大小 selected_items = [] current_tokens = 0
for score, item in scored_items: item_tokens = self._estimate_tokens(item['content']) if current_tokens + item_tokens <= target_tokens: selected_items.append(item) current_tokens += item_tokens else: break
return selected_items
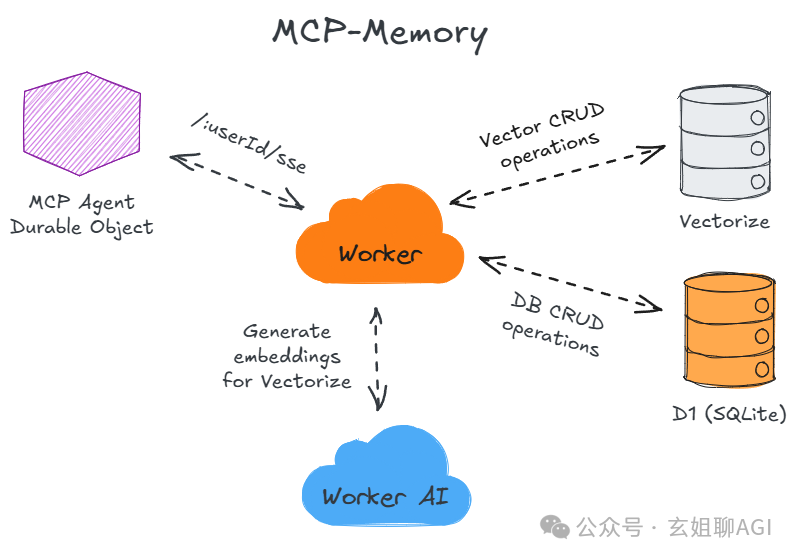
4、实际应用:MCP Memory Keeper
项目背景与功能
MCP Memory Keeper 是一个专门为 Claude Code 设计的上下文持久化服务,解决了 AI 编程助手的记忆问题。
核心功能:
- 跨会话记忆:保存工作历程、决策和进度
- 项目上下文:自动关联 Git 分支和项目目录
- 智能化频道:基于主题的上下文组织
- 文件变更追踪:监控重要文件的修改
技术实现
数据模型设计:
-- 会话管理表CREATE TABLE sessions ( id TEXT PRIMARY KEY, name TEXT NOT NULL, description TEXT, project_dir TEXT, default_channel TEXT, created_at DATETIME DEFAULT CURRENT_TIMESTAMP, continued_from TEXT, FOREIGN KEY (continued_from) REFERENCES sessions(id));
-- 上下文项目表CREATE TABLE context_items ( id TEXT PRIMARY KEY, session_id TEXT NOT NULL, channel TEXT, key TEXT NOT NULL, value TEXT NOT NULL, category TEXT DEFAULT 'general', priority TEXT DEFAULT 'normal', created_at DATETIME DEFAULT CURRENT_TIMESTAMP, reference_count INTEGER DEFAULT 0, FOREIGN KEY (session_id) REFERENCES sessions(id));
-- 文件缓存表CREATE TABLE file_cache ( id TEXT PRIMARY KEY, session_id TEXT NOT NULL, file_path TEXT NOT NULL, content_hash TEXT NOT NULL, cached_at DATETIME DEFAULT CURRENT_TIMESTAMP, FOREIGN KEY (session_id) REFERENCES sessions(id));
API 接口设计 :
interface MCPMemoryKeeper { // 会话管理 sessionStart(params: { name: string; description?: string; projectDir?: string; defaultChannel?: string; continueFrom?: string; }): Promise<SessionInfo>;
sessionList(params: { limit?: number }): Promise<SessionInfo[]>;
// 上下文操作 contextSave(params: { key: string; value: string; category?: 'task' | 'decision' | 'progress' | 'note'; priority?: 'high' | 'normal' | 'low'; channel?: string; }): Promise<void>;
contextGet(params: { key?: string; category?: string; priority?: string; channel?: string; limit?: number; }): Promise<ContextItem[]>;
// 文件管理 cacheFile(params: { filePath: string; content: string; }): Promise<void>;
fileChanged(params: { filePath: string; currentContent: string; }): Promise<boolean>;
// 状态查询 status(): Promise<SessionStatus>;}
使用案例
开发工作流程:
# 1. 开始新的开发会话await mcp_context_session_start({ name: 'User Authentication Feature', description: 'Implementing OAuth 2.0 authentication system', projectDir: '/home/dev/myapp', defaultChannel: 'auth-feature'});
# 2. 记录重要决策await mcp_context_save({ key: 'auth_strategy', value: 'Using JWT tokens with 15-minute expiry and refresh tokens', category: 'decision', priority: 'high'});
# 3. 追踪进度await mcp_context_save({ key: 'current_progress', value: 'Completed user model, working on authentication middleware', category: 'progress', priority: 'normal'});
# 4. 缓存重要文件await mcp_context_cache_file({ filePath: 'src/models/user.ts', content: userModelContent});
# 5. 会话恢复后取得上下文const decisions = await mcp_context_get({ category: 'decision', priority: 'high'});
const progress = await mcp_context_get({ category: 'progress'});
2、企业级持久化策略
1、分布式上下文架构
多层缓存设计:
class EnterpriseContextManager: def __init__(self): self.l1_cache = InMemoryCache(ttl=300) # 5分钟内存缓存 self.l2_cache = RedisCache(ttl=3600) # 1小时 Redis 缓存 self.l3_storage = PostgreSQLStorage() # 永久数据库存储 self.backup_storage = S3BackupStorage() # 云端备份
async def save_context(self, session_id: str, context: dict): """多层存储上下文""" # L1: 内存缓存(最快访问) await self.l1_cache.set(f"ctx:{session_id}", context)
# L2: Redis 缓存(跨服务共享) await self.l2_cache.set(f"ctx:{session_id}", context)
# L3: 数据库存储(持久化) await self.l3_storage.save_context(session_id, context)
# 定期备份到云端 if self._should_backup(context): await self.backup_storage.backup_context(session_id, context)
async def load_context(self, session_id: str) -> dict: """智能化载入上下文""" # 尝试从最快的存储层开始 context = await self.l1_cache.get(f"ctx:{session_id}") if context: return context
context = await self.l2_cache.get(f"ctx:{session_id}") if context: # 回填到 L1 await self.l1_cache.set(f"ctx:{session_id}", context) return context
context = await self.l3_storage.load_context(session_id) if context: # 回填到缓存层 await self.l2_cache.set(f"ctx:{session_id}", context) await self.l1_cache.set(f"ctx:{session_id}", context) return context
return {}
2、智能化上下文同步
跨设备同步机制:
class ContextSynchronizer: def __init__(self): self.sync_queue = asyncio.Queue() self.conflict_resolver = ConflictResolver()
async def sync_context_across_devices(self, user_id: str): """跨设备同步上下文""" devices = await self.get_user_devices(user_id)
for device in devices: local_context = await self.get_device_context(device.id) remote_context = await self.get_remote_context(user_id)
if self._has_conflicts(local_context, remote_context): resolved_context = await self.conflict_resolver.resolve( local_context, remote_context ) else: resolved_context = self._merge_contexts( local_context, remote_context )
await self.update_device_context(device.id, resolved_context) await self.update_remote_context(user_id, resolved_context)
3、企业应用案例
案例一:金融业客服系统
**背景:**某大型银行需要 AI 客服能记住客户的完整服务历程。
实现:
class BankingContextManager: async def handle_customer_interaction(self, customer_id: str, message: str): # 载入客户历史上下文 customer_context = await self.load_customer_context(customer_id)
# 包含: # - 过去 30 天的服务记录 # - 产品使用状况 # - 投诉和建议历史 # - 个性化偏好设置
# 处理当前请求 response = await self.ai_service.process_with_context( message, customer_context )
# 更新上下文 await self.update_customer_context( customer_id, { 'latest_interaction': message, 'ai_response': response, 'satisfaction_score': await self.detect_satisfaction(response), 'timestamp': datetime.now() } )
return response
案例二:制造业设备维护
**背景:**台积电等半导体厂需要 AI 记住每台设备的完整维护历程。
实现:
class EquipmentMaintenanceContext: async def analyze_equipment_issue(self, equipment_id: str, sensor_data: dict): # 载入设备上下文 equipment_context = await self.load_equipment_history(equipment_id)
# 包含: # - 历史故障模式 # - 维护记录 # - 效能趋势 # - 相似设备经验
# AI 分析 analysis = await self.ai_diagnostic.analyze_with_context( sensor_data, equipment_context )
# 更新设备学习记录 await self.update_equipment_context( equipment_id, { 'latest_analysis': analysis, 'sensor_snapshot': sensor_data, 'maintenance_action': analysis.recommended_action, 'timestamp': datetime.now() } )
return analysis
4、效能最佳化策略
1、智能化预加载
class ContextPreloader: def __init__(self): self.usage_predictor = UsagePatternPredictor()
async def predictive_preload(self, user_id: str): """基于使用模式预加载上下文"""
# 分析使用者模式 patterns = await self.usage_predictor.analyze_user_patterns(user_id)
# 预测可能需要的上下文 likely_contexts = await self.predict_needed_contexts(patterns)
# 预加载到缓存 for context_key in likely_contexts: await self.preload_to_cache(context_key)
2、动态压缩算法
class AdaptiveContextCompressor: def __init__(self): self.compression_strategies = { 'high_importance': SummaryCompressor(), 'medium_importance': KeyPointExtractor(), 'low_importance': TimestampOnlyCompressor() }
async def adaptive_compress(self, context_items: List[dict], target_size: int): """动态选择压缩策略"""
compressed_items = [] remaining_size = target_size
# 按重要性分组 grouped_items = self._group_by_importance(context_items)
for importance_level, items in grouped_items.items(): compressor = self.compression_strategies[importance_level]
if remaining_size > 0: compressed = await compressor.compress(items, remaining_size) compressed_items.extend(compressed) remaining_size -= self._calculate_size(compressed)
return compressed_items
5、安全性与隐私保护
1、上下文加密机制
class SecureContextStorage: def __init__(self, encryption_key: bytes): self.cipher = Fernet(encryption_key)
async def encrypt_context(self, context: dict) -> bytes: """加密上下文数据""" serialized = json.dumps(context).encode('utf-8') encrypted = self.cipher.encrypt(serialized) return encrypted
async def decrypt_context(self, encrypted_data: bytes) -> dict: """解密上下文数据""" decrypted = self.cipher.decrypt(encrypted_data) context = json.loads(decrypted.decode('utf-8')) return context
2、个人资料保护
class PrivacyProtectedContext: def __init__(self): self.pii_detector = PIIDetector() self.anonymizer = DataAnonymizer()
async def sanitize_context(self, context: dict) -> dict: """清理敏感信息"""
# 检测个人敏感信息 pii_items = await self.pii_detector.detect(context)
# 匿名化处理 sanitized_context = await self.anonymizer.anonymize( context, pii_items )
return sanitized_context
6、监控与分析
1、上下文使用分析
class ContextAnalytics: def __init__(self): self.metrics_collector = MetricsCollector()
async def analyze_context_usage(self, session_id: str): """分析上下文使用效率"""
metrics = { 'context_hit_rate': await self._calculate_hit_rate(session_id), 'compression_ratio': await self._calculate_compression_ratio(session_id), 'retrieval_latency': await self._calculate_retrieval_latency(session_id), 'storage_efficiency': await self._calculate_storage_efficiency(session_id) }
return metrics
7、小结:智能化记忆的未来
MCP 的上下文管理与持久化技术不只是解决了 AI 的“健忘症”,更是为 AI 赋予了学习和成长的能力。
核心价值:
- 连续性:跨会话保持工作状态和决策记录
- 智能化性:自动评估和管理上下文重要性
- 可扩展性:支持企业级的大规模部署
- 安全性:保护敏感信息和个人隐私
这项技术将 AI 从“一次性工具”升级为“长期伙伴”,这正是企业数字化转型所需要的 AI 能力。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献141条内容
已为社区贡献141条内容

所有评论(0)