基于labelstudio的AI半自动化标注
LabelStudio是一款支持半自动标注的开源工具,具有本地部署、多用户协作等特点。其核心优势在于:1)支持自定义AI模型接口实现自动标注(需GPU及模型开发);2)提供手动标注清洗功能;3)支持检测框、分割等多种标注格式。但存在数据集规模限制、Windows部署复杂等缺点。技术实现上,通过conda创建虚拟环境安装,使用YOLO模型进行自动标注开发,关键步骤包括:模型后端服务搭建、标签配置、预
LabelStudio半自动化标注
优点
本地部署、个人账户注册可免费用,后端启动服务,网页端操作
可自定义模型接口进行AI标注(需要gpu、模型服务开发等)
AI半自动标注之后可进行手动清洗标签和掩膜等标注信息
输出格式多样
检测框、分割、语义标注均可实现
缺点
输入的标注数据集有限制,不能输入大量图像
部署复杂,windows系统比linux系统复杂很多,且所需环境适配问题多
不确定什么时候就不免费了,不过有开源代码,应该可以自己开发
功能
多用户标签注册和登录,创建注释时,与帐户相关联。
多个项目在一个实例中处理所有数据集。
流线型设计专注于任务,而不是如何使用软件。
可配置的标签格式允许自定义可视化界面以满足特定标签需求。
支持多种数据类型 ,包括图像、音频、文本、HTML、时间序列和视频。
存档中的文件或云存储导入 。
与机器学习模型集成 ,以便可以可视化和比较来自不同模型的预测并执行预标记。
将其嵌入到您的数据管道中 REST API 使它很容易成为管道的一部分。
安装方式:本地/conda/docker/云部署均可
ubuntu conda安装
为了安装label-studio的环境洁净无冲突,我打算使用conda创建虚拟环境,首先安装conda
conda create --name label-studio python=3.10
conda activate label-studio
pip install label-studio -i https://pypi.mirrors.ustc.edu.cn/simple/测试:
label-studio strat打开https://localhost:8090
注册
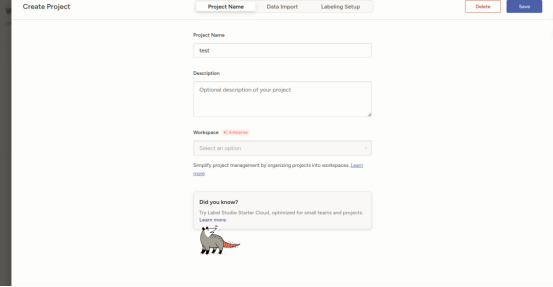
创建项目:
save:
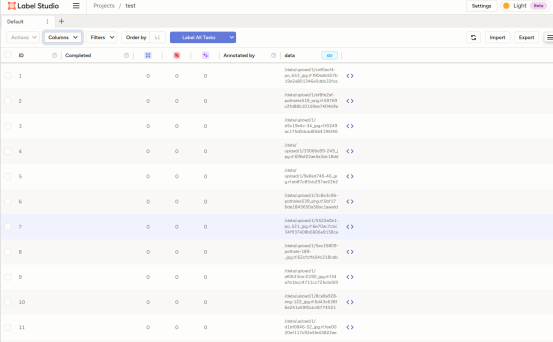
实现图像描述:
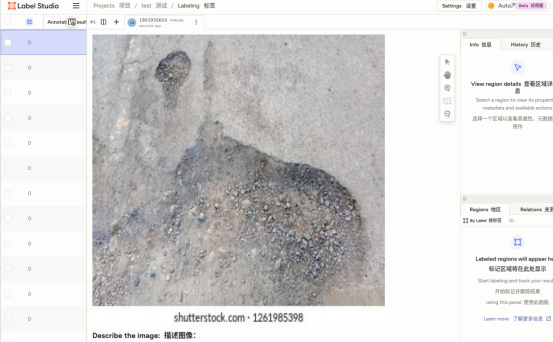
自动标注开发
1.首先在之前准备的conda环境中 pip install label-studio-ml
2.创建一个projects文件夹,将init_model.py放入该文件夹。
init_model.py的代码如下:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
from label_studio_ml.model import LabelStudioMLBase
class DummyModel(LabelStudioMLBase):
def __init__(self, **kwargs):
# don't forget to call base class constructor
super(DummyModel, self).__init__(**kwargs)
# you can preinitialize variables with keys needed to extract info from tasks and annotations and form predictions
from_name, schema = list(self.parsed_label_config.items())[0]
self.from_name = from_name
self.to_name = schema['to_name'][0]
self.labels = schema['labels']
def predict(self, tasks, **kwargs):
""" This is where inference happens: model returns
the list of predictions based on input list of tasks
"""
predictions = []
for task in tasks:
predictions.append({
'score': 0.987, # prediction overall score, visible in the data manager columns
'model_version': 'delorean-20151021', # all predictions will be differentiated by model version
'result': [{
'from_name': self.from_name,
'to_name': self.to_name,
'type': 'choices',
'score': 0.5, # per-region score, visible in the editor
'value': {
'choices': [self.labels[0]]
}
}]
})
return predictions
def fit(self, annotations, **kwargs):
""" This is where training happens: train your model given list of annotations,
then returns dict with created links and resources
"""
return {'path/to/created/model': 'my/model.bin'}3.上述代码可直接复制,但由他生成的model.py需要自己修改。然后执行命令label-studio-ml init my_backend来初始化模型文件夹。生成的文件夹如下:其中包括model文件夹、model.py文件、_wsgi.py文件(自动生成,一般不需要修改),这几个是必不可少的。
4.将自己yolo模型的pt文件放到model文件夹下:
这里:
model.py代码需要自行开发,现在实现的是对waldo检测模型的自动标注,可以实现12个类别的大视角比较准确的标注,具体代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import re
import json
import logging
import traceback
import urllib.parse
import uuid
from datetime import datetime
from typing import List, Dict, Optional, Any
import torch
from PIL import Image
from ultralytics import YOLO
from label_studio_ml.model import LabelStudioMLBase
from label_studio_ml.utils import get_local_path
from xml.etree import ElementTree as ET
# -------------------------- 全局配置 --------------------------
MODEL_PATH = os.getenv(
'MODEL_PATH',
'/media/m/B12C8B7379122B15/labelstudio/projects/my_ml_backend/model/best.pt'
)
PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__))
TRAIN_DATA_DIR = os.path.join(PROJECT_ROOT, 'yolo_train_data')
TRAIN_RESULT_DIR = os.path.join(PROJECT_ROOT, 'yolo_train_results')
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 预测置信度阈值
PREDICT_CONF_THRESHOLD = max(0.1, min(0.9, float(os.getenv('PREDICT_CONF_THRESHOLD', 0.2))))
MIN_TRAIN_SAMPLES = max(1, int(os.getenv('MIN_TRAIN_SAMPLES', 10)))
TRAIN_EPOCHS = max(1, int(os.getenv('TRAIN_EPOCHS', 50)))
TRAIN_BATCH_SIZE = max(1, int(os.getenv('TRAIN_BATCH_SIZE', 8)))
TRAIN_IMG_SIZE = 640
# Label Studio本地文件访问固定前缀
LABEL_STUDIO_FILE_PREFIX = '/data/local-files/?d='
# Label Studio媒体目录(确保包含实际图片存储目录)
LABEL_STUDIO_MEDIA_DIRS = [
os.path.expanduser('~/.local/share/label-studio/media/'), # 图片实际存储目录
os.path.join(os.path.dirname(PROJECT_ROOT), 'media'),
'/app/media',
os.path.join(PROJECT_ROOT, 'media')
]
# 缓存目录
CACHE_DIR = os.path.join('/tmp', 'labelstudio_ml_cache', os.getlogin() or 'default')
# 预测结果保存目录
PREDICTION_LOG_DIR = os.path.join(PROJECT_ROOT, 'prediction_logs')
os.makedirs(PREDICTION_LOG_DIR, exist_ok=True)
# -------------------------- 日志配置 --------------------------
logger = logging.getLogger(__name__)
class ColoredFormatter(logging.Formatter):
RED = '\033[91m'
YELLOW = '\033[93m'
GREEN = '\033[92m'
BLUE = '\033[94m'
MAGENTA = '\033[95m'
RESET = '\033[0m'
def format(self, record):
if record.levelno == logging.ERROR:
record.msg = f"{self.RED}[ERROR]{self.RESET} {record.msg}"
elif record.levelno == logging.WARNING:
record.msg = f"{self.YELLOW}[WARNING]{self.RESET} {record.msg}"
elif record.levelno == logging.INFO:
record.msg = f"{self.GREEN}[INFO]{self.RESET} {record.msg}"
elif record.levelno == logging.DEBUG:
record.msg = f"{self.BLUE}[DEBUG]{self.RESET} {record.msg}"
return super().format(record)
handler = logging.StreamHandler()
handler.setFormatter(ColoredFormatter(
'[%(asctime)s] [%(funcName)s:%(lineno)d] %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
))
logger.addHandler(handler)
logger.setLevel(logging.DEBUG)
# -------------------------- 安全结果管理器 --------------------------
class SafeResultsManager:
def __init__(self):
self._results: Dict[str, Dict] = {}
def add_result(self, job_id: str, result: Any):
if not isinstance(result, dict):
stack_trace = ''.join(traceback.format_stack()[-6:-1])
logger.error(
f"拦截非字典结果存储!\n"
f" job_id: {job_id}\n"
f" 原类型: {type(result).__name__}\n"
f" 调用堆栈: {stack_trace}"
)
result = {
"status": "error",
"code": "INVALID_RESULT_TYPE",
"message": f"非字典结果被拦截(原类型:{type(result).__name__}"
}
self._results[job_id] = result
def get_result(self, job_id: str) -> Dict:
result = self._results.get(job_id, {})
if not isinstance(result, dict):
logger.critical(f"紧急修复:job_id={job_id} 结果非字典")
return {}
return result
def get_last_result(self) -> Dict:
if not self._results:
return {}
last_job_id = list(self._results.keys())[-1]
return self.get_result(last_job_id)
def clear_results(self):
self._results.clear()
# -------------------------- 标注模板解析工具 --------------------------
class LabelConfigParser:
@staticmethod
def clean_label_config(config_str: str) -> str:
"""清理标注模板,去除注释和多余空格"""
if not config_str:
return ""
# 去除HTML注释
config_str = re.sub(r'<!--.*?-->', '', config_str, flags=re.DOTALL)
# 去除多余空格和换行
config_str = re.sub(r'\s+', ' ', config_str).strip()
# 确保根标签存在
if not config_str.startswith('<View'):
config_str = f'<View>{config_str}</View>'
return config_str
@staticmethod
def parse_from_xml(config_str: str) -> Dict[str, Any]:
"""解析标注模板,提取from_name/to_name/标签列表"""
result = {
'from_name': None,
'to_name': None,
'labels': []
}
try:
clean_config = LabelConfigParser.clean_label_config(config_str)
if not clean_config:
return result
root = ET.fromstring(clean_config)
# 解析RectangleLabels(目标框标注工具)
rect_labels = root.find(".//RectangleLabels")
if rect_labels is not None:
result['from_name'] = rect_labels.get('name')
result['to_name'] = rect_labels.get('toName', '').strip()
# 提取标签列表
for label in rect_labels.findall(".//Label"):
label_value = label.get('value')
if label_value and label_value.strip():
result['labels'].append(label_value.strip())
# 补充解析Image标签(确保to_name有效)
if not result['to_name']:
image_tag = root.find(".//Image")
if image_tag:
result['to_name'] = image_tag.get('name', 'image').strip()
return result
except ET.ParseError as e:
logger.error(f"解析标注模板XML失败:{str(e)}\n原始模板片段:{config_str[:300]}...")
return result
except Exception as e:
logger.error(f"标注模板解析异常:{str(e)}", exc_info=True)
return result
# -------------------------- 核心模型类 --------------------------
class DummyModel(LabelStudioMLBase):
def __init__(self,** kwargs):
# 调用父类初始化
super().__init__(**kwargs)
self._kwargs = kwargs
# 初始化结果管理器
self.result_manager = SafeResultsManager()
# 确保results属性为字典类型
self.results = {} if not hasattr(self, 'results') or not isinstance(self.results, dict) else self.results
# 初始化环境、配置、模型
self._init_environment()
self._init_label_config()
self._init_train_params()
self._load_yolo_model()
self._print_init_summary()
def _init_environment(self):
"""创建必要目录并设置权限"""
for dir_path in [CACHE_DIR, TRAIN_DATA_DIR, TRAIN_RESULT_DIR, PREDICTION_LOG_DIR]:
os.makedirs(dir_path, exist_ok=True)
# 确保目录可写
if os.access(dir_path, os.W_OK):
os.chmod(dir_path, 0o777)
# 打印媒体目录信息
logger.debug("候选媒体目录列表:")
for i, dir_path in enumerate(LABEL_STUDIO_MEDIA_DIRS):
logger.debug(f" 目录{i+1}:{dir_path}(存在:{os.path.exists(dir_path)})")
def _init_label_config(self):
"""解析标注模板,确保from_name/to_name/标签列表有效"""
# 多途径获取标注模板字符串
label_config_str = None
if 'label_config' in self.__dict__:
label_config_str = self.__dict__['label_config']
elif hasattr(self, 'label_config'):
label_config_str = self.label_config
elif 'label_config' in self._kwargs:
label_config_str = self._kwargs['label_config']
elif hasattr(self, 'parsed_label_config') and self.parsed_label_config:
label_config_str = str(self.parsed_label_config)
# 验证模板有效性
if not label_config_str or not isinstance(label_config_str, str):
raise ValueError(
"未获取到有效的标注模板!请确保Label Studio项目配置包含:\n"
"<Image name='image' value='$image'/>\n"
"<RectangleLabels name='label' toName='image'>\n"
" <Label value='LightVehicle'/>\n"
" <Label value='Person'/>\n"
" ...其他标签...\n"
"</RectangleLabels>"
)
# 解析模板并验证关键字段
parser = LabelConfigParser()
parse_result = parser.parse_from_xml(label_config_str)
self.from_name = parse_result['from_name']
self.to_name = parse_result['to_name']
self.labels = parse_result['labels']
# 校验解析结果
validation_errors = []
if not self.from_name:
validation_errors.append("未找到<RectangleLabels>标签或其'name'属性")
if not self.to_name:
validation_errors.append("未找到<Image>标签或其'name'属性")
if len(self.labels) == 0:
validation_errors.append("<RectangleLabels>内无有效<Label>标签(需包含'value'属性)")
if validation_errors:
# 输出调试信息
debug_info = f"""
调试信息:
1. 标注模板片段:{label_config_str[:500]}...
2. 解析结果:
- from_name(标注工具名):{self.from_name}
- to_name(图像字段名):{self.to_name}
- 标签列表:{self.labels}(共{len(self.labels)}个)
"""
logger.error(debug_info)
raise ValueError(
f"标注模板解析失败:{'; '.join(validation_errors)}\n"
f"请使用标准模板结构"
)
# 解析成功日志
logger.info(
f"标注模板解析成功:\n"
f"- 标注工具名(from_name):{self.from_name}\n"
f"- 图像字段名(to_name):{self.to_name}\n"
f"- 标签列表:{self.labels}(共{len(self.labels)}个类别)"
)
def _init_train_params(self):
"""初始化训练相关参数"""
self.train_data = {'image_paths': [], 'labels': []} # 存储训练样本
def _load_yolo_model(self):
"""加载YOLO模型并验证类别匹配"""
# 检查模型文件是否存在
if not os.path.exists(MODEL_PATH):
raise FileNotFoundError(f"YOLO模型文件不存在:{MODEL_PATH}\n请检查MODEL_PATH配置")
try:
# 加载模型到指定设备
self.model = YOLO(MODEL_PATH).to(DEVICE)
model_class_count = self.model.model.nc # 模型输出类别数
model_classes = self.model.names # 模型类别字典
# 打印模型基础信息
logger.info(
f"模型加载成功:\n"
f"- 模型路径:{MODEL_PATH}\n"
f"- 运行设备:{DEVICE.type.upper()}\n"
f"- 模型类别数:{model_class_count}\n"
f"- 模型类别列表:{dict(model_classes)}"
)
# 验证模型类别与标注模板的匹配性
if model_class_count != len(self.labels):
logger.warning(
f"类别数不匹配!模型({model_class_count}类) vs 标注模板({len(self.labels)}类)"
)
else:
# 检查每个类别名称是否完全一致
mismatches = []
for idx in range(model_class_count):
model_cls = model_classes.get(idx, f"未知类别{idx}")
template_cls = self.labels[idx]
if model_cls != template_cls:
mismatches.append(f"索引{idx}:模型={model_cls} vs 模板={template_cls}")
if mismatches:
logger.warning(f"类别名称不匹配:\n " + "\n ".join(mismatches))
else:
logger.info("✅ 模型类别与标注模板完全匹配")
except Exception as e:
raise RuntimeError(f"YOLO模型加载失败:{str(e)}")
def _print_init_summary(self):
"""打印初始化总结"""
logger.info("="*80)
logger.info("✅ 模型后端初始化完成!")
logger.info(f" 运行设备:{DEVICE.type.upper()}")
logger.info(f" 模型路径:{MODEL_PATH}")
logger.info(f" 预测置信度阈值:{PREDICT_CONF_THRESHOLD}")
logger.info(f" 最小训练样本数:{MIN_TRAIN_SAMPLES}")
logger.info(f" 标注工具名(from_name):{self.from_name}")
logger.info(f" 图像字段名(to_name):{self.to_name}")
logger.info("="*80)
def _get_image_path(self, img_url: str) -> Optional[str]:
"""
核心修复:获取图像本地路径,生成Label Studio可识别的绝对路径格式
返回格式:/data/local-files/?d=/home/m/...(d=后为绝对路径)
"""
try:
if not img_url:
logger.warning("图像URL为空,无法获取路径")
return None
# 解码URL
img_url_decoded = urllib.parse.unquote(img_url)
logger.debug(f"处理图像URL:原始={img_url} → 解码={img_url_decoded}")
# 1. 优先从Label Studio媒体目录获取
if img_url_decoded.startswith('/data/'):
url_relative_path = img_url_decoded[len('/data/'):]
for media_dir in LABEL_STUDIO_MEDIA_DIRS:
local_abs_path = os.path.join(media_dir, url_relative_path)
local_abs_path = os.path.abspath(local_abs_path)
if os.path.exists(local_abs_path) and os.path.isfile(local_abs_path):
# 生成Label Studio路径(d=后用绝对路径)
ls_image_path = f"{LABEL_STUDIO_FILE_PREFIX}{local_abs_path}"
logger.debug(
f"找到图像:\n"
f" 本地绝对路径:{local_abs_path}\n"
f" Label Studio路径:{ls_image_path}"
)
return ls_image_path
logger.warning(
f"图像在所有媒体目录中均不存在:\n"
f" URL解码后:{img_url_decoded}\n"
f" 搜索的媒体目录:{LABEL_STUDIO_MEDIA_DIRS}"
)
return None
# 2. 从缓存获取
cached_abs_path = get_local_path(url=img_url_decoded, cache_dir=CACHE_DIR)
if os.path.exists(cached_abs_path) and os.path.isfile(cached_abs_path):
ls_image_path = f"{LABEL_STUDIO_FILE_PREFIX}{cached_abs_path}"
logger.debug(
f"从缓存获取图像:\n"
f" 缓存绝对路径:{cached_abs_path}\n"
f" Label Studio路径:{ls_image_path}"
)
return ls_image_path
# 3. 所有途径失败
logger.error(f"图像获取失败:URL={img_url_decoded}")
return None
except Exception as e:
logger.error(f"获取图像路径异常:{str(e)},URL={img_url}", exc_info=True)
return None
# -------------------------- 重写父类结果方法 --------------------------
def get_result_from_job_id(self, job_id: str) -> Dict:
"""重写父类方法,确保返回安全的字典类型结果"""
return self.result_manager.get_result(job_id)
def get_result_from_last_job(self) -> Dict:
"""获取最后一次任务的结果"""
return self.result_manager.get_last_result()
# -------------------------- 核心:预测方法 --------------------------
def predict(self, tasks: List[Dict], context: Optional[Dict] = None, **kwargs) -> Dict:
"""
预测入口:处理图像→模型推理→生成Label Studio兼容的预测结果
"""
context = context or {}
job_id = context.get('job_id', f"predict_{os.urandom(4).hex()}")
logger.info(f"\n{'#'*50}\n开始预测任务:job_id={job_id},任务数量={len(tasks)}\n{'#'*50}")
try:
# 处理空任务列表
if not isinstance(tasks, list) or len(tasks) == 0:
result = {
"tasks": [],
"status": "success",
"message": "无任务可处理",
"job_id": job_id
}
self.result_manager.add_result(job_id, result)
return result
# 存储所有Label Studio兼容的任务结果
label_studio_compatible_tasks = []
# 逐个处理任务
for task in tasks:
# 验证任务基础格式
if not isinstance(task, dict) or 'data' not in task:
logger.warning(f"跳过无效任务:{task}(缺少'data'字段)")
continue
# 提取任务ID
task_id = task.get('id', f"task_{uuid.uuid4().hex[:8]}")
# 提取图像URL
img_url = task['data'].get(self.to_name)
if not img_url:
logger.warning(f"任务{task_id}缺少图像字段'{self.to_name}',跳过")
continue
# 1. 获取Label Studio可识别的图像路径
ls_image_path = self._get_image_path(img_url)
if not ls_image_path:
logger.warning(f"任务{task_id}无法获取有效图像路径,跳过")
continue
# 2. 解析图像路径,获取本地绝对路径
try:
# 提取LS路径中d=后的绝对路径
if ls_image_path.startswith(LABEL_STUDIO_FILE_PREFIX):
local_abs_path = ls_image_path[len(LABEL_STUDIO_FILE_PREFIX):]
# 验证本地路径存在性
if not os.path.exists(local_abs_path):
logger.warning(f"任务{task_id}:本地图像路径不存在:{local_abs_path}")
continue
else:
# 非本地路径:从缓存获取
local_abs_path = get_local_path(ls_image_path, CACHE_DIR)
# 读取图像并获取尺寸
with Image.open(local_abs_path) as img:
img_rgb = img.convert('RGB')
img_width, img_height = img.size
logger.debug(
f"任务{task_id}:\n"
f" 图像尺寸:{img_width}x{img_height}\n"
f" 本地路径:{local_abs_path}"
)
except Exception as e:
logger.warning(f"任务{task_id}读取图像失败:{str(e)},跳过")
continue
# 3. 模型推理(YOLO预测)
try:
logger.info(f"任务{task_id}:启动模型预测(置信度阈值={PREDICT_CONF_THRESHOLD})")
yolo_results = self.model.predict(
source=img_rgb,
conf=PREDICT_CONF_THRESHOLD,
device=DEVICE,
imgsz=TRAIN_IMG_SIZE,
verbose=False
)
# 提取检测结果
detected_boxes = yolo_results[0].boxes if yolo_results else []
logger.info(f"任务{task_id}:YOLO检测完成,共检测到{len(detected_boxes)}个目标")
except Exception as e:
logger.warning(f"任务{task_id}模型预测失败:{str(e)},跳过")
continue
# 4. 转换YOLO结果为Label Studio格式
ls_annotation_results = []
for box_idx, box in enumerate(detected_boxes):
try:
# 提取YOLO检测信息
conf_score = round(box.conf.item(), 4)
class_idx = int(box.cls.item())
x1, y1, x2, y2 = box.xyxy[0].tolist()
# 过滤无效类别
if class_idx < 0 or class_idx >= len(self.labels):
logger.warning(
f"任务{task_id}:跳过无效类别索引{class_idx}\n"
f" 有效类别索引范围:0~{len(self.labels)-1}"
)
continue
# 转换坐标:YOLO绝对坐标 → Label Studio百分比坐标
x = (x1 / img_width) * 100
y = (y1 / img_height) * 100
width = ((x2 - x1) / img_width) * 100
height = ((y2 - y1) / img_height) * 100
# 构建Label Studio标准标注格式
ls_annotation = {
"id": f"anno_{job_id}_{task_id}_{box_idx}",
"from_name": self.from_name,
"to_name": self.to_name,
"type": "rectanglelabels",
"score": conf_score,
"original_width": img_width,
"original_height": img_height,
"value": {
"x": round(x, 2),
"y": round(y, 2),
"width": round(width, 2),
"height": round(height, 2),
"rectanglelabels": [self.labels[class_idx]]
}
}
ls_annotation_results.append(ls_annotation)
except Exception as e:
logger.warning(
f"任务{task_id}转换检测结果失败(box_idx={box_idx}):{str(e)},跳过该目标"
)
continue
# 5. 构建完整的任务结果(包含预测)
task_result = {
"id": task_id,
"data": task['data'], # 保留原始数据(包含图像URL)
"predictions": [{
"id": f"pred_{job_id}_{task_id}",
"result": ls_annotation_results,
"score": max([item.get('score', 0) for item in ls_annotation_results], default=0),
"model_version": os.path.basename(MODEL_PATH),
"created_at": datetime.utcnow().isoformat() + "Z"
}]
}
label_studio_compatible_tasks.append(task_result)
# 6. 保存预测结果为JSON文件(Label Studio兼容格式)
prediction_log_path = os.path.join(
PREDICTION_LOG_DIR,
f"ls_compatible_prediction_{job_id}.json"
)
with open(prediction_log_path, 'w', encoding='utf-8') as f:
json.dump(label_studio_compatible_tasks, f, ensure_ascii=False, indent=2)
logger.info(f"✅ 预测结果已保存(Label Studio兼容格式):{prediction_log_path}")
# 7. 构建最终返回结果
final_result = {
"tasks": label_studio_compatible_tasks,
"status": "success",
"message": f"成功处理{len(label_studio_compatible_tasks)}/{len(tasks)}个任务",
"job_id": job_id,
"log_path": prediction_log_path
}
self.result_manager.add_result(job_id, final_result)
return final_result
except Exception as e:
error_msg = f"预测任务整体失败:{str(e)}"
logger.error(error_msg, exc_info=True)
error_result = {
"tasks": [],
"status": "error",
"message": error_msg,
"job_id": job_id,
"traceback": traceback.format_exc()
}
self.result_manager.add_result(job_id, error_result)
return error_result
# -------------------------- 训练方法(可选) --------------------------
def fit(self, event, data, **kwargs):
"""训练入口(根据标注数据更新模型)"""
try:
logger.info(f"\n{'#'*50}\n开始训练任务\n{'#'*50}")
# 提取标注数据
annotations = data.get('annotations', [])
if len(annotations) < MIN_TRAIN_SAMPLES:
logger.warning(
f"训练样本不足({len(annotations)} < {MIN_TRAIN_SAMPLES}),跳过训练"
)
return {"status": "skipped", "reason": "样本不足"}
# 处理标注数据(转换为YOLO格式)
self._process_annotations(annotations)
# 启动YOLO训练
logger.info(f"开始模型训练(样本数={len(annotations)}, 轮次={TRAIN_EPOCHS})")
self.model.train(
data=os.path.join(TRAIN_DATA_DIR, 'data.yaml'),
epochs=TRAIN_EPOCHS,
batch=TRAIN_BATCH_SIZE,
imgsz=TRAIN_IMG_SIZE,
device=DEVICE.type,
project=TRAIN_RESULT_DIR,
name=f"train_{datetime.now().strftime('%Y%m%d_%H%M%S')}",
exist_ok=True
)
logger.info("✅ 训练完成")
return {"status": "success", "message": "模型训练完成"}
except Exception as e:
error_msg = f"训练任务失败:{str(e)}"
logger.error(error_msg, exc_info=True)
return {"status": "error", "message": error_msg}
def _process_annotations(self, annotations):
"""将Label Studio标注转换为YOLO训练格式"""
# 实现标注数据转换逻辑(根据实际需求补充)
pass
if __name__ == "__main__":
from label_studio_ml.server import run_server
run_server(DummyModel, host='0.0.0.0', port=9090)代码必须要准确生成json标注文件,如果出现错误则无法在labelstudio前端界面中进行数据清洗和优化工作。
5.进入到project目录运行命令label-studio-ml start my_ml_backend -p 9094来启动模型后端服务
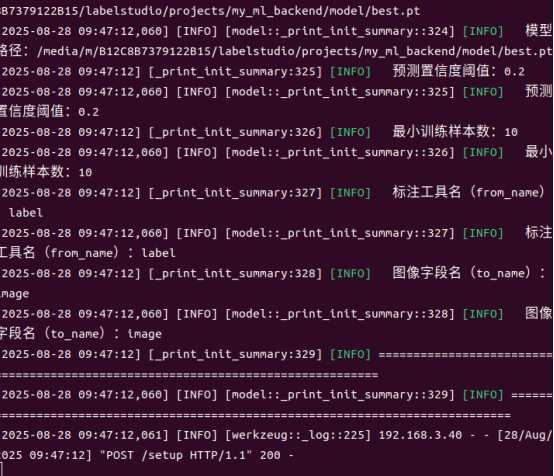
6.明确自己的pt模型类别,根据labelstudio的规则在设置-标签里编写设置标签:
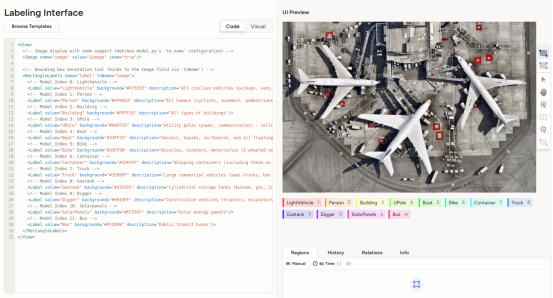
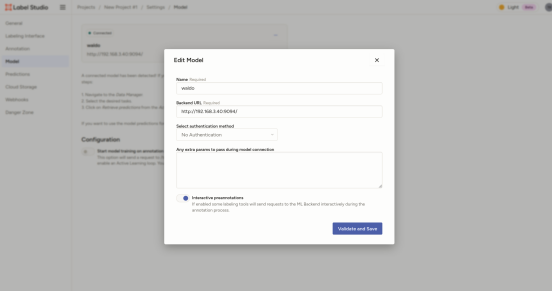
7.在设置model进行模型设置,名称自定,url为6.启动的的ip和端口号。设置好之后点击保存即可。
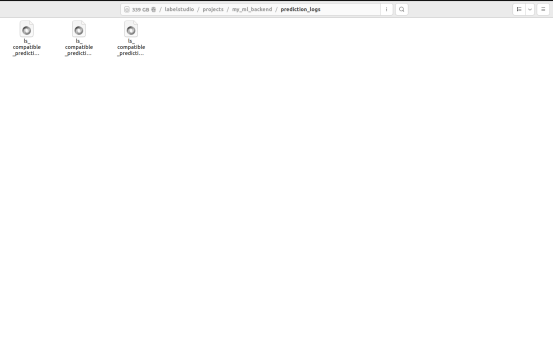
8.返回项目点击图像即可自动标注,标注的结果在下图路径下的json文件。此时并不会直接显示标注信息在label-studio中
9.将json文件导入label-studio前端界面。此时便会显示自动标注的信息
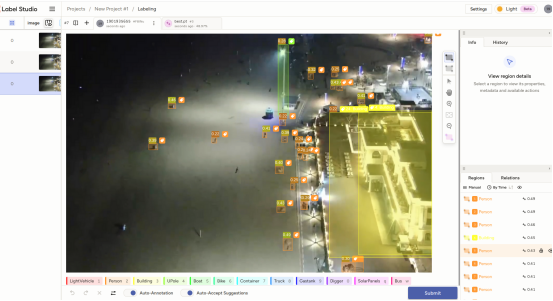
10.根据自动标注的信息进行增添修改清洗。修改完成后点击右下角submit即可发布, 必须submit才可以批量下载成果
11.点击export选择最终导出的标注格式即可
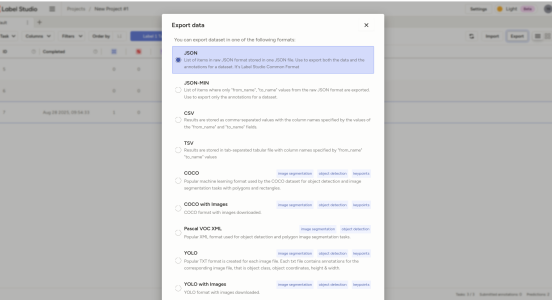
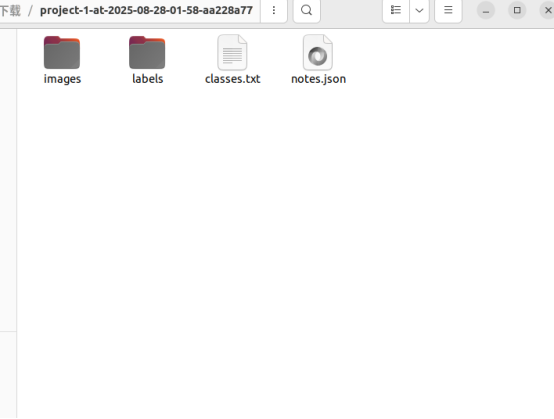
12.下载结果:
私有化标注/自动标注模型可寻求帮助(小企鹅:1901935655)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)