Oracle官方文档翻译《Database Concepts 23ai》第4章-表与表簇
Oracle官方文档翻译《Database Concepts 23ai》第4章-表与表簇
4 Tables and Table Clusters(4 表与表簇)
本章介绍模式对象,并重点讨论表(最常见的模式对象类型)。
Introduction to Schema Objects(模式对象简介)
数据库模式是数据结构(称为模式对象)的逻辑容器,表、索引等均为模式对象的示例。可通过 SQL 创建和操作模式对象。
本节包含以下主题:
About Common and Local User Accounts(公用用户账户与本地用户账户简介)
数据库用户账户包含密码和特定的数据库权限。
Common and Local Objects(公用对象与本地对象)
公用对象在 CDB 根容器或应用程序根容器中定义,可通过元数据链接或对象链接引用;本地对象指所有非公用对象。
Schema Object Types(模式对象类型)
Oracle SQL 支持创建和操作多种其他类型的模式对象。
Schema Object Storage(模式对象存储)
部分模式对象将数据存储在名为“段”的逻辑存储结构中,例如非分区堆组织表或索引会创建段。
Schema Object Dependencies(模式对象依赖关系)
部分模式对象会引用其他对象,从而形成模式对象依赖关系。
Sample Schemas(示例模式)
Oracle 数据库可能包含示例模式,这是一组相互关联的模式,可帮助 Oracle 文档和教学材料演示常见的数据库任务。
另请参见:《Oracle Database Security Guide》(《Oracle 数据库安全指南》),了解更多关于用户和权限的信息。
About Common and Local User Accounts(公用用户账户与本地用户账户简介)
数据库用户账户包含密码和特定的数据库权限。
User Accounts and Schemas(用户账户与模式)
每个用户账户拥有一个模式,模式名称与用户名相同,且该模式存储该用户的数据。例如,hr 用户账户拥有 hr 模式,该模式包含 employees 表等模式对象。在生产数据库中,模式所有者通常代表数据库应用程序,而非个人。
在一个模式内,特定类型的每个模式对象名称必须唯一。例如,hr.employees 指 hr 模式中的 employees 表。下图展示了名为 hr 的模式所有者及其模式内的模式对象:
Figure 4-1 HR Schema
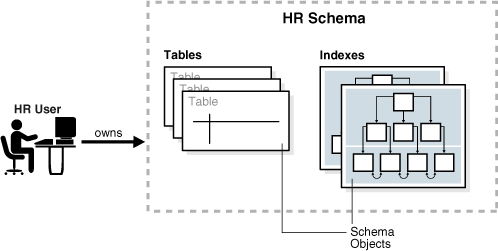
Common and Local User Accounts(公用用户账户与本地用户账户)
若用户账户拥有定义数据库的对象,则该用户账户为公用账户。非 Oracle 提供的用户账户分为本地账户和公用账户两类:
- CDB 公用用户:在 CDB 根容器中创建的公用用户。
- 应用程序公用用户:在应用程序根容器中创建的用户,仅在该应用程序容器内公用。
下图展示了 CDB 中可能的用户账户类型:
Figure 4-2 User Accounts in a CDB
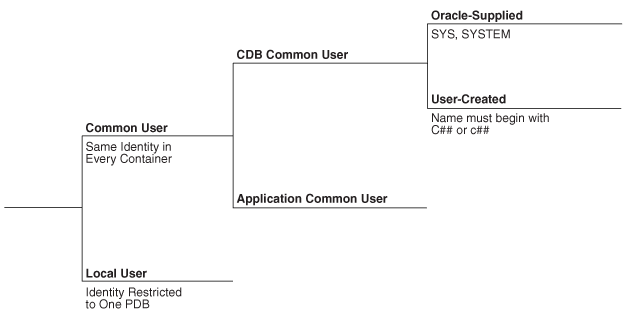
CDB 公用用户可连接到其拥有足够权限的 CDB 内任意容器;而应用程序公用用户根据权限不同,仅能连接到其创建所在的应用程序根容器,或插入该应用程序根容器的 PDB。
Common User Accounts(公用用户账户)
在系统容器(CDB)或应用程序容器的语境下,公用用户是在根容器及该容器内所有现有和未来 PDB 中具有相同身份的数据库用户。
每个公用用户可连接到其所属容器的根容器,并在拥有足够权限的任意 PDB 内执行操作。部分管理任务必须由公用用户执行,例如创建 PDB 和拔出 PDB。
例如,SYSTEM 是具有 DBA 权限的 CDB 公用用户,因此可连接到 CDB 根容器和数据库中的任意 PDB;若在 saas_sales 应用程序容器中创建公用用户 saas_sales_admin,则该用户仅能连接到 saas_sales 应用程序根容器或该容器内的应用程序 PDB。
每个公用用户要么是 Oracle 提供的,要么是用户创建的。Oracle 提供的公用用户示例包括 SYS 和 SYSTEM;用户创建的公用用户要么是 CDB 公用用户,要么是应用程序公用用户。
下图展示了两个 PDB(hrpdb 和 salespdb)中的示例用户和模式:SYS 和 c##dba 是 CDB 公用用户,在 CDB$ROOT、hrpdb 和 salespdb 中均有模式;本地用户 hr 和 rep 存在于 hrpdb 中,且在 salespdb 中也存在同名本地用户:
Figure 4-3 Users and Schemas in a CDB
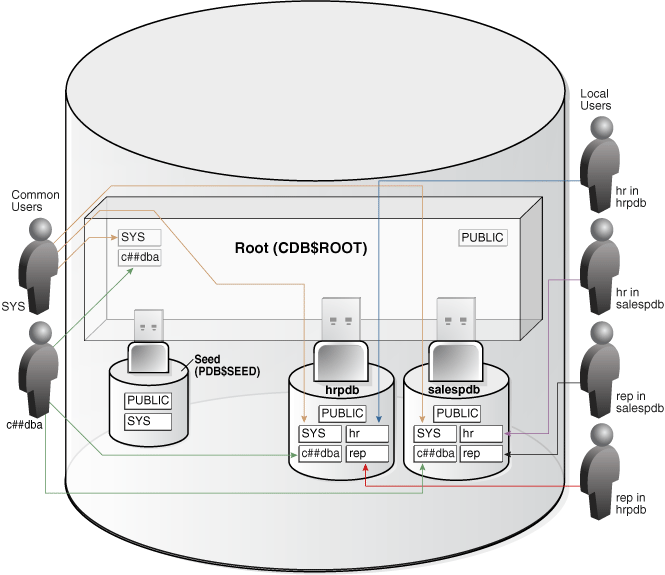
公用用户具有以下特征:
- 公用用户可登录到其拥有
CREATE SESSION权限的任意容器(包括CDB$ROOT)。 - 公用用户在不同容器中的权限可能不同。例如,
c##dba用户可能在hrpdb和根容器中拥有创建会话的权限,但在salespdb中没有该权限。由于拥有相应权限的公用用户可在容器间切换,因此根容器中的公用用户可管理 PDB。 - 应用程序公用用户在其所属应用程序容器外的任何容器中都没有
CREATE SESSION权限,因此仅限于在自身所属的应用程序容器内操作。例如,在saas_sales应用程序中创建的应用程序公用用户,仅能连接到该应用程序根容器和其中的 PDB。 - 用户创建的 CDB 公用用户名称需遵循其他数据库用户的命名规则,且必须以
COMMON_USER_PREFIX初始化参数指定的字符开头(默认前缀为c##或C##);Oracle 提供的公用用户名称和用户创建的应用程序公用用户名称无此限制。 - 本地用户名称不得以
c##或C##开头。 - 每个公用用户在其创建所在的容器(系统容器或特定应用程序容器)内的所有 PDB 中名称唯一:
- CDB 公用用户在 CDB 根容器中定义,但必须能以相同身份连接到所有 PDB;
- 应用程序公用用户位于应用程序根容器中,可以相同身份连接到其所属容器内的所有应用程序 PDB。
Characteristics of Common Users(公用用户的特征)
每个公用用户要么是Oracle提供的,要么是用户创建的。
公用用户账户具有以下特征:
-
只要拥有
CREATE SESSION权限,公用用户就可以登录到任何容器(包括CDB$ROOT)。
公用用户在每个容器中不必拥有相同的权限。例如,c##dba用户可能拥有在hrpdb和根容器中创建会话的权限,但没有在salespdb中创建会话的权限。由于拥有适当权限的公用用户可以在不同容器之间切换,因此根容器中的公用用户可以管理PDB。 -
应用程序公用用户在其所属应用程序容器之外的任何容器中,都没有
CREATE SESSION权限。
因此,应用程序公用用户的操作范围仅限于其所属的应用程序容器。例如,在saas_sales应用程序中创建的应用程序公用用户,只能连接到该应用程序根容器以及saas_sales应用程序容器内的PDB。 -
用户创建的CDB公用用户的名称必须遵循其他数据库用户的命名规则。此外,名称必须以初始化参数
COMMON_USER_PREFIX指定的字符开头,默认情况下为c##或C##。Oracle提供的公用用户名以及用户创建的应用程序公用用户名不受此限制。
本地用户名不得以c##或C##开头。 -
在创建公用用户的容器(无论是系统容器还是特定应用程序容器)内的所有PDB中,每个公用用户的名称都是唯一的。
CDB公用用户在CDB根容器中定义,但必须能够以相同身份连接到每个PDB。应用程序公用用户驻留在应用程序根容器中,且可以以相同身份连接到其所属容器内的每个应用程序PDB。
下图展示了两个PDB(hrpdb和salespdb)中的示例用户和模式。SYS和c##dba是CDB公用用户,它们在CDB$ROOT、hrpdb和salespdb中均拥有模式。本地用户hr和rep存在于hrpdb中,同时本地用户hr和rep也存在于salespdb中。
Figure 4-4 Users and Schemas in a CDB
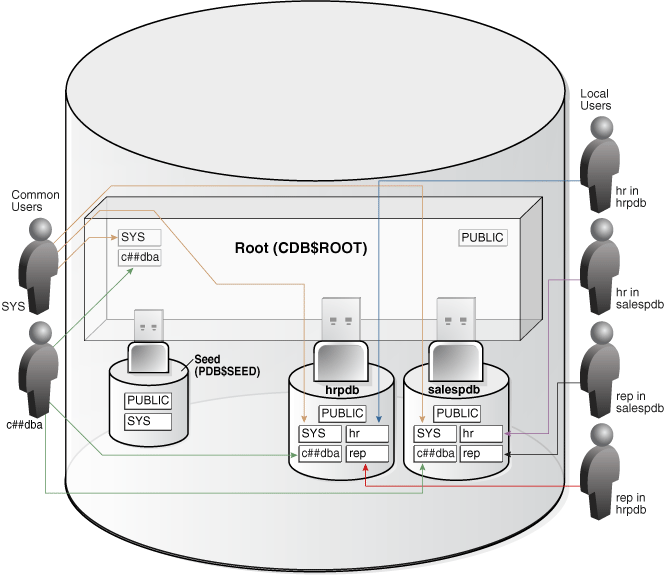
另请参见:
- 《Oracle数据库安全指南》,以了解公用用户账户相关知识
- 《Oracle数据库参考》,以了解
COMMON_USER_PREFIX相关知识
SYS and SYSTEM Accounts(SYS 和 SYSTEM 账户)
所有 Oracle 数据库都包含具有管理权限的默认公用用户账户。
管理账户权限极高,仅供授权 DBA 执行特定任务,例如启动和停止数据库、管理内存和存储、创建和管理数据库用户等。
SYS 公用用户账户在数据库创建时自动创建,可执行所有数据库管理功能。SYS 模式存储数据字典的基表和视图,这些基表和视图对 Oracle 数据库的运行至关重要,仅数据库可操作 SYS 模式中的表,用户不得修改。
SYSTEM 管理账户也在数据库创建时自动创建。SYSTEM 模式存储用于显示管理信息的额外表和视图,以及各种 Oracle 数据库选项和工具使用的内部表和视图。切勿使用 SYSTEM 模式存储非管理用户关注的表。
另请参见:
- 《Oracle Database Security Guide》(《Oracle 数据库安全指南》),了解用户账户相关信息;
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解
SYS、SYSTEM和其他管理账户相关信息。
Local User Accounts(本地用户账户)
本地用户是指非公用用户,仅能在单个 PDB 内操作。
本地用户具有以下特征:
- 本地用户特定于某个 PDB,且可能在该 PDB 中拥有模式。例如,在“公用用户的特征”示例中,
hrpdb中的本地用户hr拥有hr模式,salespdb中的本地用户rep拥有rep模式,且salespdb中的本地用户hr也拥有hr模式。 - 本地用户可管理 PDB(包括打开和关闭 PDB)。拥有
SYSDBA权限的公用用户可将SYSDBA权限授予本地用户,此时该授权用户仍为本地用户。 - 一个 PDB 中的本地用户无法登录到另一个 PDB 或 CDB 根容器。例如,本地用户
hr连接到hrpdb后,若不使用数据库链接,无法访问salespdb中sh模式的对象;同理,本地用户sh连接到salespdb后,若不使用数据库链接,无法访问hrpdb中hr模式的对象。 - 本地用户名称不得以
c##或C##开头。 - 本地用户名称仅需在其所属 PDB 内唯一。本地用户的唯一性由用户名及其所属 PDB 共同决定。例如,“公用用户的特征”示例中,
hrpdb中存在名为rep的本地用户和模式,salespdb中也存在完全独立的同名本地用户和模式。
下表描述了“公用用户的特征”示例中 CDB 的操作场景,每行描述的操作承接上一行操作。公用用户 SYSTEM 在两个 PDB 中创建本地用户:
| 操作(Operation) | 描述(Description) |
|---|---|
SYSTEM 使用服务名 hrpdb 连接到 hrpdb 容器 |
SQL> CONNECT SYSTEM@hrpdb Enter password: ******** Connected. |
SYSTEM 在该 PDB 中创建本地用户 rep,并授予其 CREATE SESSION 权限(该用户为本地用户,因为仅连接到根容器的公用用户可创建公用用户) |
SQL> CREATE USER rep IDENTIFIED BY password; User created. SQL> GRANT CREATE SESSION TO rep; Grant succeeded. |
仅属于 hrpdb 的本地用户 rep 尝试连接到 salespdb(连接失败,因为 rep 在 salespdb 中不存在) |
SQL> CONNECT rep@salespdb Enter password: ******* ERROR: ORA-01017: invalid username/password; logon denied |
SYSTEM 使用服务名 salespdb 连接到 salespdb 容器 |
SQL> CONNECT SYSTEM@salespdb Enter password: ******** Connected. |
SYSTEM 在 salespdb 中创建本地用户 rep,并授予其 CREATE SESSION 权限(由于本地用户名称仅需在所属 PDB 内唯一,因此 salespdb 和 hrpdb 中均可存在名为 rep 的用户) |
SQL> CREATE USER rep IDENTIFIED BY password; User created. SQL> GRANT CREATE SESSION TO rep; Grant succeeded. |
本地用户 rep 成功登录到 salespdb |
SQL> CONNECT rep@salespdb Enter password: ******* Connected. |
另请参见:《Oracle Database Security Guide》(《Oracle 数据库安全指南》),了解本地用户账户相关信息。
Common and Local Objects(公用对象与本地对象)
公用对象在 CDB 根容器或应用程序根容器中定义,可通过元数据链接或对象链接引用;本地对象指所有非公用对象。
数据库提供的公用对象在 CDB$ROOT 中定义,且无法修改。Oracle 数据库不支持在 CDB$ROOT 中创建公用对象。
可在应用程序根容器中创建大多数模式对象(如表、视图、PL/SQL 和 Java 程序单元、序列等)作为公用对象,此类对象称为应用程序公用对象。
本地用户可拥有公用对象;公用用户也可拥有本地对象,但该对象需满足以下条件:非数据链接或元数据链接对象,且既不是元数据链接也不是数据链接。
另请参见:《Oracle Database Security Guide》(《Oracle 数据库安全指南》),了解更多关于公用对象权限管理的信息。
Schema Object Types(模式对象类型)
Oracle SQL 支持创建和操作多种其他类型的模式对象。
以下表格列出了主要的模式对象类型:
| 对象(Object) | 描述(Description) | 参考文档(To Learn More) |
|---|---|---|
| 表(Table) | 表以行的形式存储数据,是关系数据库中最重要的模式对象 | “Overview of Tables”(表概述) |
| 索引(Indexes) | 索引是模式对象,包含表或表簇中每个索引行的条目,可提供对行的直接、快速访问。Oracle 数据库支持多种索引类型,索引组织表是一种将数据存储在索引结构中的表 | “Indexes and Index-Organized Tables”(索引与索引组织表) |
| 分区(Partitions) | 分区是大型表和索引的组成部分,每个分区有自己的名称,且可选择性地拥有自己的存储特征 | “Overview of Partitions”(分区概述) |
| 视图(Views) | 视图是一个或多个表或其他视图中数据的自定义呈现形式,可视为存储的查询,本身不实际存储数据 | “Overview of Views”(视图概述) |
| 序列(Sequences) | 序列是用户创建的对象,可由多个用户共享以生成整数,通常用于生成主键值 | “Overview of Sequences”(序列概述) |
| 维度(Dimensions) | 维度定义列集对之间的父子关系,其中列集的所有列必须来自同一张表。维度通常用于对客户、产品、时间等数据进行分类 | “Overview of Dimensions”(维度概述) |
| 同义词(Synonyms) | 同义词是其他模式对象的别名,仅需在数据字典中存储其定义,无需额外存储 | “Overview of Synonyms”(同义词概述) |
| PL/SQL 子程序和包(PL/SQL subprograms and packages) | PL/SQL 是 Oracle 对 SQL 的过程式扩展。PL/SQL 子程序是可通过一组参数调用的命名 PL/SQL 块;PL/SQL 包将逻辑相关的 PL/SQL 类型、变量和子程序分组 | “PL/SQL Subprograms”(PL/SQL 子程序) |
数据库中还存储其他类型的对象,可通过 SQL 语句创建和操作,但这些对象不包含在模式中,包括数据库用户账户、角色、上下文和字典对象。
另请参见:
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理模式对象;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解更多关于模式对象和数据库对象的信息。
Schema Object Storage(模式对象存储)
部分模式对象将数据存储在名为“段”的逻辑存储结构中,例如非分区堆组织表或索引会创建段。
其他模式对象(如视图和序列)仅包含元数据,本节仅描述具有段的模式对象。
Oracle 数据库在表空间内逻辑存储模式对象,模式与表空间之间无关联关系:一个表空间可包含来自不同模式的对象,一个模式的对象也可存储在不同表空间中。每个对象的数据物理存储在一个或多个数据文件中。
下图展示了表段、索引段、表空间和数据文件的可能配置:一张表的数据段跨越两个数据文件(均属于同一表空间),段不能跨越多个表空间。
Figure 4-5 Segments, Tablespaces, and Data Files
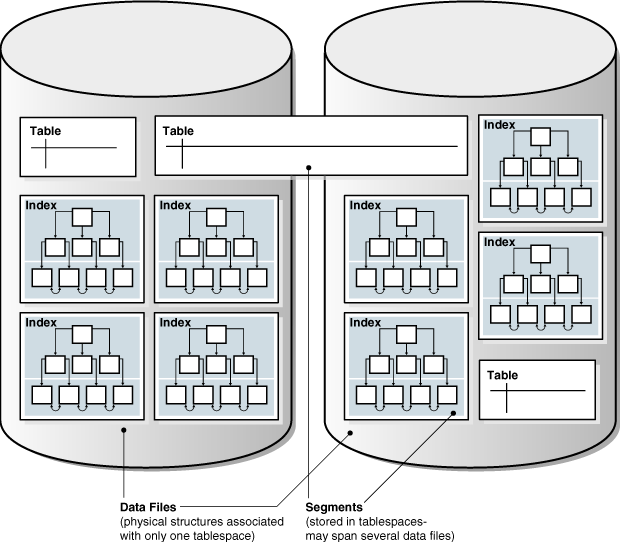
另请参见:
- “Logical Storage Structures”(逻辑存储结构),了解表空间和段;
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理模式对象的存储。
Schema Object Dependencies(模式对象依赖关系)
部分模式对象会引用其他对象,从而形成模式对象依赖关系。
例如,视图包含引用表或其他视图的查询,PL/SQL 子程序会调用其他子程序。若对象 A 的定义引用对象 B,则 A 是 B 的依赖对象,B 是 A 的被引用对象。
Oracle 数据库提供自动机制,确保依赖对象始终与被引用对象保持同步。创建依赖对象时,数据库会跟踪依赖对象与被引用对象之间的依赖关系;当被引用对象发生可能影响依赖对象的更改时,数据库会将依赖对象标记为无效。例如,若用户删除某张表,则基于该表的所有视图均无法使用。
无效的依赖对象需根据被引用对象的新定义重新编译后才能使用,重新编译会在引用无效依赖对象时自动执行。
以下示例脚本创建表 test_table,然后创建查询该表的过程,以演示模式对象如何形成依赖关系:
CREATE TABLE test_table ( col1 INTEGER, col2 INTEGER );
CREATE OR REPLACE PROCEDURE test_proc
AS
BEGIN
FOR x IN ( SELECT col1, col2 FROM test_table )
LOOP
-- 处理数据
NULL;
END LOOP;
END;
查询过程 test_proc 的状态,显示其为有效:
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- ------
TEST_PROC VALID
向 test_table 中添加 col3 列后,过程仍保持有效(因为过程不依赖该列):
SQL> ALTER TABLE test_table ADD col3 NUMBER;
Table altered.
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- ------
TEST_PROC VALID
但修改 test_proc 依赖的 col1 列的数据类型后,过程会变为无效:
SQL> ALTER TABLE test_table MODIFY col1 VARCHAR2(20);
Table altered.
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- ------
TEST_PROC INVALID
运行或重新编译该过程后,其状态恢复为有效:
SQL> EXECUTE test_proc
PL/SQL procedure successfully completed.
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- ------
TEST_PROC VALID
另请参见:《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》)和《Oracle Database Development Guide》(《Oracle 数据库开发指南》),了解如何管理模式对象依赖关系。
Sample Schemas(示例模式)
Oracle 数据库可能包含示例模式,这是一组相互关联的模式,可帮助 Oracle 文档和教学材料演示常见的数据库任务。
hr 示例模式包含员工、部门、位置、工作经历等相关信息。下图展示了 hr 模式中表的实体关系图,本手册中的大多数示例均使用该模式的对象。
Figure 4-6 HR Schema
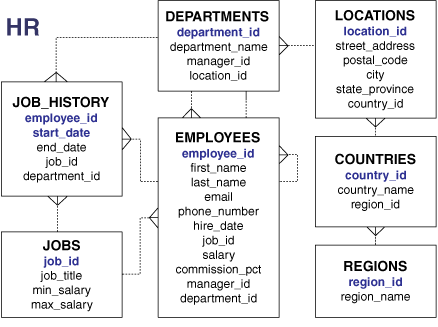
另请参见:《Oracle Database Sample Schemas》(《Oracle 数据库示例模式》),了解如何安装示例模式。
Overview of Tables(表概述)
表是 Oracle 数据库中数据组织的基本单位。
表描述“实体”(即需要记录信息的重要事物),例如员工可作为一个实体。
Oracle 数据库表主要分为以下类别:
- 关系表(Relational tables):包含简单列,是最常见的表类型,示例 4-1 展示了创建关系表的
CREATE TABLE语句。 - 对象表(Object tables):列对应对象类型的顶级属性,参见“Overview of Object Tables”(对象表概述)。
可创建具有以下组织特征的关系表:
- 堆组织表(Heap-organized table):行的存储无特定顺序,
CREATE TABLE语句默认创建堆组织表。 - 索引组织表(Index-organized table):行按主键值排序,对部分应用程序而言,可提升性能并更高效地利用磁盘空间,参见“Overview of Index-Organized Tables”(索引组织表概述)。
- 外部表(External table):只读表,其元数据存储在数据库中,但数据存储在数据库外部,参见“Overview of External Tables”(外部表概述)。
表分为永久表和临时表:
永久表:表定义和数据在会话间持久存在。
临时表:表定义与永久表类似,但数据仅在事务或会话期间存在。临时表适用于需临时保存结果集的应用场景(例如结果集需通过多个操作构建)。
表概述包含的主题
-
Columns(列)
表定义包含表名和一组列。 -
Rows(行)
行是表中对应一条记录的列信息集合。 -
Example: CREATE TABLE and ALTER TABLE Statements(示例:CREATE TABLE 和 ALTER TABLE 语句)
Oracle SQL 中,CREATE TABLE语句用于创建表。 -
Oracle Data Types(Oracle 数据类型)
每个列都有对应的数据类型,关联特定的存储格式、约束和有效值范围。数据类型为值赋予一组固定属性。 -
Integrity Constraints(完整性约束)
完整性约束是限制表中一个或多个列值的命名规则。 -
Table Storage(表存储)
Oracle 数据库使用表空间中的数据段存储表数据。 -
Table Compression(表压缩)
数据库可通过表压缩减少表所需的存储空间。
Columns(列)
表定义包含表名和一组列。
列标识表所描述实体的属性,例如 employees 表中的 employee_id 列对应员工实体的员工 ID 属性。
创建表时,通常需为每个列指定列名、数据类型和宽度。例如,employee_id 的数据类型为 NUMBER(6),表示该列仅能存储最多 6 位的数值数据;部分数据类型(如 DATE)的宽度由数据类型本身预先确定。
Virtual Columns(虚拟列)
表可包含虚拟列,与非虚拟列不同,虚拟列不占用磁盘空间。数据库通过计算用户指定的表达式或函数,按需生成虚拟列的值。例如,虚拟列 income 可由 salary 和 commission_pct 列通过函数计算得出。
另请参见:《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理虚拟列。
Invisible Columns(不可见列)
不可见列是用户指定的列,仅在显式按名称指定时才可见。可在不影响现有应用程序的情况下向表中添加不可见列,必要时再将其设为可见。
不可见列有助于在线应用程序的迁移和演进。例如,某应用程序通过 SELECT * 查询包含 3 列的表,向该表添加第 4 列会破坏应用程序(应用程序预期仅 3 列数据);而添加第 4 列为不可见列可使应用程序正常运行,开发人员可随后修改应用程序以支持第 4 列,并在应用程序上线时将该列设为可见。
以下示例创建包含不可见列 count 的表 products,然后将该列设为可见:
CREATE TABLE products ( prod_id INT, count INT INVISIBLE );
ALTER TABLE products MODIFY ( count VISIBLE );
另请参见:
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理不可见列;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解更多关于不可见列的信息。
Lock-Free Reservation(无锁预留)
无锁预留允许对数值列值进行多个并发更新,在对列值执行增减操作时,不会因未提交的更新而阻塞。
通过在更新过程中避免传统锁定机制,该特性可大幅减少频繁并发更新场景下的阻塞,提升用户体验。在早期版本中,当某行的列值通过增减操作更新时,其他对该行的更新会被阻塞,直到事务提交;而 Oracle 数据库 23ai 引入的无锁预留特性,通过指定更新可执行的条件,允许事务对同一行的预留列并发执行增减操作,无需相互阻塞。实现方式为:将数值列指定为 RESERVABLE 列,并为该列创建 CHECK 约束。此外,由于预留列更新不会锁定行,其他事务可并发更新同一行的非预留列,从而进一步提升吞吐量。
例如,可允许对库存数量(qty_on_hand)执行增减操作,条件是现有库存满足请求,且不超过 100 件的货架容量。只要库存数量大于 0 且小于等于 100,此类更新就可在不受未提交更新阻塞的情况下执行。增减的数量通过内部预留机制保证,事务无需等待其他对同一行预留列的早期预留事务提交即可执行。
表级 CHECK 约束可同时包含预留列和非预留列。事务提交时,更新时已批准的未完成无锁预留可能因约束被违反而失效(例如,预留后非预留列被更新,导致当前值违反 CHECK 约束),此时事务将被终止。但表级约束中的非预留列通常是极少修改的阈值(如货架容量、账户所需余额、消费限额等)。
以下示例创建包含预留列 qty_on_hand 的表 inventory,qty_on_hand 上的 CHECK 约束指定:库存数量需大于等于 0,且不超过该商品的货架容量,确保对 qty_on_hand 的更新不会阻塞其他更新。示例中还包含表创建、数据插入和数据字典查询操作:
CREATE TABLE inventory
(
item_id NUMBER CONSTRAINT inv_pk PRIMARY KEY,
item_display_name VARCHAR2(100) NOT NULL,
item_desc VARCHAR2(2000),
qty_on_hand NUMBER RESERVABLE
CONSTRAINT qty_ck CHECK (qty_on_hand >= 0) NOT NULL,
shelf_capacity NUMBER NOT NULL,
CONSTRAINT shelf_ck CHECK (qty_on_hand <= shelf_capacity)
);
-- 向 inventory 表插入数据
INSERT INTO inventory VALUES (123, 'Milk', 'Lowfat 2%', 100, 120);
INSERT INTO inventory VALUES (456, 'Bread', 'Multigrain', 50, 100);
INSERT INTO inventory VALUES (789, 'Eggs', 'Organic', 50, 75);
COMMIT;
-- 查询 inventory 表
SELECT * FROM inventory;
-- 查询 user_tab_cols 和 user_tables 视图,检查表是否为预留表及预留列名称
SELECT table_name, has_reservable_column
FROM user_tables
WHERE table_name = 'INVENTORY';
SELECT column_name, reservable_column
FROM user_tab_cols
WHERE table_name = 'INVENTORY' AND reservable_column = 'YES';
以下是对预留列的多个并发更新示例:
-- 事务 1
UPDATE inventory
SET qty_on_hand = qty_on_hand - 10
WHERE item_id = 123;
-- 事务 2
UPDATE inventory
SET qty_on_hand = qty_on_hand + 20
WHERE item_id = 123;
-- 事务 3
UPDATE inventory
SET qty_on_hand = qty_on_hand - 30
WHERE item_id = 123;
-- 事务 2 提交
COMMIT;
-- 事务 3 提交
COMMIT;
-- 事务 1 提交
COMMIT;
- 添加预留列:通过
ALTER TABLE命令添加预留列,并可选择性指定CHECK约束:ALTER TABLE inventory ADD (qty_on_hold NUMBER RESERVABLE DEFAULT 0 CONSTRAINT qty_hold CHECK (qty_on_hold >= 0 and qty_on_hold <= 25)); - 预留列转非预留列:通过以下
ALTER TABLE命令将预留列转换为非预留列。应用程序可选择保留约束(预留功能禁用后约束仍可生效),因此转换时约束不会自动删除,是否删除取决于需求:ALTER TABLE inventory MODIFY (qty_on_hand NOT RESERVABLE); ALTER TABLE inventory DROP CONSTRAINT qty_ck; - 非预留列转预留列:通过
ALTER TABLE命令将非预留列转换为预留列:ALTER TABLE inventory MODIFY (qty_on_hand RESERVABLE CONSTRAINT qty_ck CHECK (qty_on_hand >= 0 and qty_on_hand <= 100));
Rows(行)
行是表中对应一条记录的列信息集合。
例如,employees 表中的一行描述特定员工的属性(员工 ID、姓氏、名字等)。创建表后,可通过 SQL 插入、查询、删除和更新行。
Example: CREATE TABLE and ALTER TABLE Statements(示例:CREATE TABLE 和 ALTER TABLE 语句)
Oracle SQL 中,CREATE TABLE 语句用于创建表。
Example 4-1 CREATE TABLE employees(示例 4-1:创建 employees 表)
以下示例展示 hr 示例模式中 employees 表的 CREATE TABLE 语句,指定了 employee_id、first_name 等列,并为每个列指定了 NUMBER 或 DATE 等数据类型:
CREATE TABLE employees
(
employee_id NUMBER(6),
first_name VARCHAR2(20),
last_name VARCHAR2(25) CONSTRAINT emp_last_name_nn NOT NULL,
email VARCHAR2(25) CONSTRAINT emp_email_nn NOT NULL,
phone_number VARCHAR2(20),
hire_date DATE CONSTRAINT emp_hire_date_nn NOT NULL,
job_id VARCHAR2(10) CONSTRAINT emp_job_nn NOT NULL,
salary NUMBER(8,2),
commission_pct NUMBER(2,2),
manager_id NUMBER(6),
department_id NUMBER(4),
CONSTRAINT emp_salary_min CHECK (salary > 0),
CONSTRAINT emp_email_uk UNIQUE (email)
);
Example 4-2 ALTER TABLE employees(示例 4-2:修改 employees 表)
以下示例展示通过 ALTER TABLE 语句为 employees 表添加完整性约束,这些约束用于执行业务规则,防止无效信息插入表中:
ALTER TABLE employees
ADD (
CONSTRAINT emp_emp_id_pk PRIMARY KEY (employee_id),
CONSTRAINT emp_dept_fk FOREIGN KEY (department_id) REFERENCES departments,
CONSTRAINT emp_job_fk FOREIGN KEY (job_id) REFERENCES jobs (job_id),
CONSTRAINT emp_manager_fk FOREIGN KEY (manager_id) REFERENCES employees
);
Example 4-3 Rows in the employees Table(示例 4-3:employees 表中的行)
以下示例输出展示 hr.employees 表的 8 行数据和 6 列信息:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | COMMISSION_PCT | DEPARTMENT_ID |
|---|---|---|---|---|---|
| 100 | Steven | King | 24000 | 90 | |
| 101 | Neena | Kochhar | 17000 | 90 | |
| 102 | Lex | De Haan | 17000 | 90 | |
| 103 | Alexander | Hunold | 9000 | 60 | |
| 107 | Diana | Lorentz | 4200 | 60 | |
| 149 | Eleni | Zlotkey | 10500 | 0.2 | 80 |
| 174 | Ellen | Abel | 11000 | 0.3 | 80 |
| 178 | Kimberely | Grant | 7000 | 0.15 |
上述输出体现了表、列和行的以下重要特征:
- 表中的一行描述一个员工的属性(姓名、薪资、部门等)。例如,输出第一行是员工 Steven King 的记录。
- 列描述员工的一个属性。示例中,
employee_id列是主键,确保每个员工的员工 ID 唯一,任意两个员工不会有相同的员工 ID。 - 非关键字列的值可以重复。示例中,员工 101 和 102 的薪资相同(均为 17000)。
- 外键列引用同一表或另一表中的主键或唯一键。示例中,
department_id列的 90 对应departments表的department_id列。 - 字段是行与列的交集,仅能包含一个值。例如,员工 103 的部门 ID 字段值为 60。
- 字段可不含值(即包含空值)。示例中,员工 100 的
commission_pct列值为空,而员工 149 的该字段值为 0.2。列允许空值的前提是未定义NOT NULL约束或主键约束,否则插入行时该列必须有值。
另请参见:《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解 CREATE TABLE 语句的语法和语义。
Oracle Data Types(Oracle 数据类型)
每个列都有对应的数据类型,关联特定的存储格式、约束和有效值范围。数据类型为值赋予一组固定属性,使 Oracle 数据库对不同数据类型的值区别对待(例如,可对 NUMBER 类型的值执行乘法运算,但无法对 RAW 类型的值执行该操作)。
创建表时,必须为每个列指定数据类型,后续插入该列的值将遵循该数据类型。
Oracle 数据库提供多种内置数据类型,最常用的类型分为以下类别:
- 字符数据类型(Character Data Types)
- 数值数据类型(Numeric Data Types)
- 日期时间数据类型(Datetime Data Types)
- 行标识数据类型(Rowid Data Types)
- 布尔数据类型(Boolean Data Type)
- 格式模型与数据类型(Format Models and Data Types)
其他重要的内置类型类别包括原始类型(raw)、大型对象(LOBs)和集合。PL/SQL 包含用于常量和变量的数据类型,包括 BOOLEAN、引用类型、复合类型(记录)和用户定义类型。
Character Data Types(字符数据类型)
字符数据类型以字符串形式存储字母数字数据,最常用的字符数据类型是 VARCHAR2,是存储字符数据的最高效选择。
字节值对应字符编码方案(通常称为字符集),数据库字符集在数据库创建时确定,字符集示例包括 7 位 ASCII、EBCDIC 和 Unicode UTF-8。
字符数据类型的长度语义可按字节(byte semantics)或字符(character semantics)衡量:
- 字节语义:将字符串视为字节序列,是字符数据类型的默认语义。
- 字符语义:将字符串视为字符序列,其中“字符”指数据库字符集的码点。
VARCHAR2 and CHAR Data Types(VARCHAR2 和 CHAR 数据类型)
VARCHAR2 数据类型存储变长字符字面量(字面量是固定数据值)。例如,'LILA'、'St. George Island' 和 '101' 均为字符字面量,5001 为数值字面量;字符字面量需用单引号括起,以便数据库将其与模式对象名称区分。
注意:本手册中,文本字面量、字符字面量和字符串这三个术语可互换使用。
创建含 VARCHAR2 列的表时,需指定最大字符串长度。示例 4-1 中,last_name 列的数据类型为 VARCHAR2(25),表示该列存储的姓名最大长度为 25 字节。
对于每行数据,Oracle 数据库会将列值存储为变长字段(若值超过最大长度则返回错误)。例如,在单字节字符集中,若某行的 last_name 列值为 10 个字符,则该列在该行片段中仅存储 10 个字符(10 字节),而非 25 字节,使用 VARCHAR2 可减少空间占用。
与 VARCHAR2 不同,CHAR 存储定长字符串。创建含 CHAR 列的表时,需指定字符串长度(默认为 1 字节),数据库会用空格将值填充至指定长度。
Oracle 数据库对 VARCHAR2 值采用非填充比较语义,对 CHAR 值采用空格填充比较语义。
另请参见:《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解空格填充和非填充比较语义的详细信息。
NCHAR and NVARCHAR2 Data Types(NCHAR 和 NVARCHAR2 数据类型)
NCHAR 和 NVARCHAR2 数据类型存储 Unicode 字符数据。
Unicode 是通用编码字符集,可使用单一字符集存储任意语言的信息:
NCHAR存储与国家字符集对应的定长字符串;NVARCHAR2存储与国家字符集对应的变长字符串。
创建数据库时需指定国家字符集,NCHAR 和 NVARCHAR2 数据类型的字符集必须是 AL16UTF16 或 UTF8(两种字符集均使用 Unicode 编码)。
创建含 NCHAR 或 NVARCHAR2 列的表时,最大长度始终按字符长度语义计算(字符长度语义是 NCHAR 或 NVARCHAR2 的默认且唯一长度语义)。
另请参见:《Oracle Database Globalization Support Guide》(《Oracle 数据库全球化支持指南》),了解 Oracle 全球化支持特性的相关信息。
Numeric Data Types(数值数据类型)
Oracle 数据库数值数据类型存储定点数、浮点数、零和无穷大,部分数值类型还存储运算未定义结果(称为“非数字”或 NaN)。
Oracle 数据库以变长格式存储数值数据:每个值以科学计数法存储,1 字节用于存储指数,最多 20 字节用于存储尾数(浮点数中包含有效数字的部分),且不存储前导零和尾随零。
NUMBER Data Type(NUMBER 数据类型)
NUMBER 数据类型存储定点数和浮点数,可存储几乎任意大小的数值,且在运行 Oracle 数据库的不同操作系统间可移植,是大多数数值数据存储场景的推荐选择。
定点数的指定格式为 NUMBER(p, s),其中 p(精度)表示总位数,s(小数位数)表示从小数点到最低有效位的位数:
- 精度(Precision):若未指定精度,列将按应用程序提供的原始值存储,不进行舍入。
- 小数位数(Scale):正小数位数表示小数点右侧到最低有效位的位数;负小数位数表示小数点左侧到最低有效位(不含)的位数;若指定精度但未指定小数位数(如
NUMBER(6)),则小数位数默认为 0。
示例 4-1 中,salary 列的数据类型为 NUMBER(8,2)(精度 8,小数位数 2),因此数据库会将 100000 存储为 100000.00。
Floating-Point Numbers(浮点数)
Oracle 数据库提供两种专门用于浮点数的数值数据类型:BINARY_FLOAT 和 BINARY_DOUBLE。
这两种类型支持 NUMBER 数据类型的所有基本功能,但 NUMBER 使用十进制精度,而 BINARY_FLOAT 和 BINARY_DOUBLE 使用二进制精度,可加快算术计算速度,且通常减少存储需求。
BINARY_FLOAT 和 BINARY_DOUBLE 是近似数值数据类型,存储十进制值的近似表示(而非精确表示)。例如,0.1 无法被 BINARY_DOUBLE 或 BINARY_FLOAT 精确表示,这类数据类型常用于科学计算,其行为与 Java 和 XMLSchema 中的 FLOAT 和 DOUBLE 数据类型类似。
另请参见:《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解数值类型的精度、小数位数和其他特征。
Datetime Data Types(日期时间数据类型)
日期时间数据类型包括 DATE 和 TIMESTAMP,Oracle 数据库为时间戳提供全面的时区支持。
DATE Data Type(DATE 数据类型)
DATE 数据类型存储日期和时间,尽管日期时间也可通过字符或数值数据类型表示,但 DATE 具有特殊关联属性。
数据库将日期以数值形式内部存储,每个日期存储在 7 字节的固定长度字段中,分别对应世纪、年、月、日、时、分、秒。
注意:日期完全支持算术运算,可像对待数值一样对日期执行加减操作。
数据库根据指定的格式模型显示日期,格式模型是描述字符字符串中日期时间格式的字符字面量,标准日期格式为 DD-MON-RR,例如 01-JAN-11。
RR 与 YY(年份的后两位)类似,但返回值的世纪由指定的两位数年份和当前年份的后两位共同决定。假设 1999 年数据库显示日期 01-JAN-11:若格式使用 RR,则 11 表示 2011 年;若格式使用 YY,则 11 表示 1911 年。可在数据库实例级和会话级修改默认日期格式。
Oracle 数据库以 24 小时制(HH:MI:SS)存储时间:若未输入时间部分,日期字段的时间默认为 00:00:00(凌晨);若仅输入时间部分,日期部分默认为本月的第一天。
另请参见:
- 《Oracle Database Development Guide》(《Oracle 数据库开发指南》),了解世纪和日期格式掩码的相关信息;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解日期时间格式代码的相关信息;
- 《Oracle Database Development Guide》(《Oracle 数据库开发指南》),了解如何对日期时间数据类型执行算术运算。
TIMESTAMP Data Type(TIMESTAMP 数据类型)
TIMESTAMP 数据类型是 DATE 数据类型的扩展,除存储 DATE 数据类型的信息外,还存储小数秒。TIMESTAMP 数据类型适用于需存储精确时间值的场景(如需跟踪事件顺序的应用程序)。
日期时间数据类型 TIMESTAMP WITH TIME ZONE 和 TIMESTAMP WITH LOCAL TIME ZONE 支持时区感知,用户查询数据时,值会调整为用户会话的时区,适用于跨地理区域收集和评估日期信息的场景。
另请参见:《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解创建时间戳列和输入时间戳数据的语法细节。
Rowid Data Types(行标识数据类型)
数据库中存储的每一行都有一个地址(用于在数据库中定位该行的内部表示),Oracle 数据库使用 ROWID 数据类型存储每一行的地址(行标识)。
行标识分为以下类别:
- 物理行标识(Physical rowids):存储堆组织表、表簇以及表和索引分区中行的地址。
- 逻辑行标识(Logical rowids):存储索引组织表中行的地址。
- 外部行标识(Foreign rowids):外部表(如通过网关访问的 DB2 表)中的标识符,不属于标准 Oracle 数据库行标识。
通用行标识(urowid)数据类型支持所有类型的行标识。
Use of Rowids(行标识的用途)
Oracle 数据库在内部使用行标识构建索引。例如,最常见的 B 树索引包含按范围划分的有序键列表,每个键关联一个行标识,指向对应行的地址,以实现快速访问。
终端用户和应用程序开发人员也可将行标识用于以下重要功能:
- 若已通过
SELECT语句获取某行的行标识,可通过该行标识快速重新访问该行。 - 可通过行标识了解表的组织方式。
尽管可创建包含 ROWID 数据类型列的表,但不应为后续访问数据而存储行标识,这种方式可能导致不可预测或错误的结果。行的行标识可能因多种原因(用户发起或数据库引擎内部操作)发生变化,执行这些操作后,无法保证行标识仍指向同一行或有效行。
ROWID Pseudocolumn(ROWID 伪列)
Oracle 数据库中的每个表都有一个名为 ROWID 的伪列。
伪列的行为类似表列,但不实际存储在表中:可查询伪列的值,但无法插入、更新或删除;伪列也类似无参数的 SQL 函数,但无参数函数通常为结果集中的每一行返回相同值,而伪列通常为每一行返回不同值。
ROWID 伪列的值是表示每行地址的字符串,数据类型为 ROWID。执行 SELECT 或 DESCRIBE 语句列出表结构时,看不到该伪列,且伪列不占用存储空间,但可通过 SQL 查询使用保留字 ROWID 作为列名,获取每行的行标识。
以下示例查询 ROWID 伪列,显示 employees 表中员工 ID 为 100 的行的行标识:
SQL> SELECT ROWID FROM employees WHERE employee_id = 100;
ROWID
------------------
AAAPecAAFAAAABSAAA
另请参见:
- “Rowid Format”(行标识格式);
- 《Oracle Database Development Guide》(《Oracle 数据库开发指南》),了解如何通过地址标识行;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解行标识类型的相关信息。
Boolean Data Type(布尔数据类型)
BOOLEAN 数据类型包含两个不同的真值:TRUE(真)和 FALSE(假)。
除非有 NOT NULL 约束禁止,否则布尔数据类型还支持 UNKNOWN(未知)作为空值的真值。在 Oracle SQL 语法中,BOOLEAN 数据类型可用于任何允许使用 datatype(数据类型)的位置。
另请参见:《Oracle Database SQL Language Quick Reference》(《Oracle 数据库 SQL 语言快速参考》),了解布尔数据类型的相关信息。
Format Models and Data Types(格式模型与数据类型)
格式模型是描述字符字符串中日期时间或数值数据格式的字符字面量,不改变数据库中值的内部表示。
将字符字符串转换为日期或数值时,格式模型决定数据库如何解释该字符串。在 SQL 中,可将格式模型作为 TO_CHAR 和 TO_DATE 函数的参数,对从数据库返回的值或要存储到数据库的值进行格式化。
以下语句查询 80 号部门员工的薪资,使用 TO_CHAR 函数将薪资转换为字符值,格式由数值格式模型 '$99,990.99' 指定:
SQL> SELECT last_name employee, TO_CHAR(salary, '$99,990.99') AS "SALARY"
2 FROM employees
3 WHERE department_id = 80 AND last_name = 'Russell';
EMPLOYEE SALARY
-------- ----------
Russell $14,000.00
以下示例使用 TO_DATE 函数和格式掩码 'YYYY MM DD',将字符串 '1998 05 20' 转换为 DATE 值,以更新雇佣日期:
SQL> UPDATE employees
2 SET hire_date = TO_DATE('1998 05 20','YYYY MM DD')
3 WHERE last_name = 'Hunold';
另请参见:《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解更多关于格式模型的信息。
Integrity Constraints(完整性约束)
完整性约束是限制表中一个或多个列值的命名规则,用于防止无效数据插入表中,且在存在特定依赖关系时可防止表被删除。
约束启用时,数据库会在数据插入或更新时进行检查,阻止不符合约束的数据进入;约束禁用时,数据库允许不符合约束的数据插入。
例如,示例 4-1 的 CREATE TABLE 语句为 last_name、email、hire_date 和 job_id 列指定了 NOT NULL 约束,确保这些列不包含空值。若尝试插入没有职位 ID(job_id)的新员工记录,会触发错误。
可在创建表时或创建后创建约束,也可根据需要临时禁用约束,约束信息存储在数据字典中。
另请参见:
- “Data Integrity”(数据完整性),了解完整性约束;
- “Overview of the Data Dictionary”(数据字典概述),了解数据字典;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解 SQL 约束子句。
Table Storage(表存储)
Oracle 数据库使用表空间中的数据段存储表数据。
段由数据块组成的区构成,表(或表簇的簇数据段)的数据段位于以下位置之一:
- 表所有者的默认表空间;
CREATE TABLE语句中指定的表空间。
Table Organization(表组织方式)
默认情况下,表以堆(heap)方式组织,即数据库将行存储在最合适的位置,而非用户指定的顺序,因此堆组织表是无序的行集合。
注意:索引组织表采用不同的组织原则。
用户添加行时,数据库将行存储在数据段的第一个可用空闲空间中,无法保证按插入顺序检索行。
例如,hr.departments 表是堆组织表,包含部门 ID、名称、经理 ID 和位置 ID 列。插入行时,数据库将其存储在任意合适位置,表段中的某个数据块可能包含如下无序行:
50,Shipping,121,1500
120,Treasury,,1700
70,Public Relations,204,2700
30,Purchasing,114,1700
130,Corporate Tax,,1700
10,Administration,200,1700
110,Accounting,205,1700
表中所有行的列顺序相同,数据库通常按 CREATE TABLE 语句中列出的顺序存储列,但不保证绝对顺序。例如,若表包含 LONG 类型的列,Oracle 数据库始终将该列存储在行的最后;若向表中添加新列,新列也会成为最后存储的列。
表可包含虚拟列,与普通列不同,虚拟列不占用磁盘空间。数据库通过计算用户指定的表达式或函数,按需生成虚拟列的值。可对虚拟列创建索引、收集统计信息和创建完整性约束,因此虚拟列与非虚拟列功能类似。
另请参见:
- “Overview of Index-Organized Tables”(索引组织表概述);
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解虚拟列的相关信息。
Row Storage(行存储)
数据库将行存储在数据块中,包含少于 256 列的表的每行数据存储在一个或多个行片段中。
Oracle 数据库会尽可能将每行存储为一个行片段,但以下情况会使用多个行片段:
- 行的所有数据无法插入单个数据块;
- 更新现有行导致行超出其所在数据块的容量。
表簇中的行包含与非簇表中行相同的信息,此外还包含引用其所属簇键的信息。
另请参见:“Data Block Format”(数据块格式),了解数据块的组成部分。
Rowids of Row Pieces(行片段的行标识)
行标识本质上是行的 10 字节物理地址。
堆组织表中的每行都有一个对该表唯一的行标识,对应行片段的物理地址;对于表簇,不同表中位于同一数据块的行可能具有相同的行标识。
Oracle 数据库在内部使用行标识构建索引,例如 B 树索引中的每个键都关联一个行标识,指向对应行的地址以实现快速访问。物理行标识提供对表行的最快访问方式,使数据库可通过最少一次 I/O 检索一行。
另请参见:
- “Rowid Format”(行标识格式),了解行标识的结构;
- “Overview of B-Tree Indexes”(B 树索引概述),了解 B 树索引的类型和结构。
Storage of Null Values(空值的存储)
空值(null)是列中值的缺失,表示缺失、未知或不适用的数据。
若空值位于有数据值的列之间,则会在数据库中存储,此时需 1 字节存储列长度(零);行中的尾随空值无需存储,因为新行标题会标识前一行的剩余列为空值。例如,若表的最后三列为空值,则不为这些列存储任何数据。
另请参见:《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解更多关于空值的信息。
Table Compression(表压缩)
数据库可通过表压缩减少表所需的存储空间,同时减少数据库缓冲区高速缓存中的内存使用,在部分情况下还能加快查询执行速度,且表压缩对数据库应用程序透明。
Basic Table Compression and Advanced Row Compression(基本表压缩与高级行压缩)
基于字典的表压缩为堆组织表提供良好的压缩比。
Oracle 数据库支持以下两种基于字典的表压缩类型:
-
Basic table compression(基本表压缩)
适用于批量加载操作,数据库不压缩通过常规 DML 修改的数据,需使用直接路径插入(direct path INSERT)、ALTER TABLE ... MOVE或在线表重定义(online table redefinition)实现基本表压缩。 -
Advanced row compression(高级行压缩)
适用于 OLTP 应用程序,可压缩通过任意 SQL 操作处理的数据。该压缩方式在实现有竞争力的压缩比的同时,使应用程序执行 DML 的时间与在未压缩表上执行 DML 的时间大致相同。
对于上述两种压缩类型,数据库以行主序(row major format)存储压缩行:先存储一行的所有列,再存储下一行的所有列,以此类推。数据库用指向块开头符号表的短引用替换重复值,因此重建未压缩数据所需的信息存储在数据块本身中。
压缩数据块与普通数据块结构相似,大多数适用于普通数据块的数据库特性和功能也适用于压缩块。
可在表空间、表、分区或子分区级别声明压缩:若在表空间级别指定压缩,则该表空间中创建的所有表默认启用压缩。
Example 4-4 Table-Level Compression(示例 4-4:表级压缩)
以下语句为 oe.orders 表应用高级行压缩:
ALTER TABLE oe.orders ROW STORE COMPRESS ADVANCED;
Example 4-5 Partition-Level Compression(示例 4-5:分区级压缩)
以下部分 CREATE TABLE 语句示例为一个分区指定高级行压缩,为另一个分区指定基本表压缩:
CREATE TABLE sales (
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL,
...
)
PCTFREE 5 NOLOGGING NOCOMPRESS
PARTITION BY RANGE (time_id)
(
partition sales_2013 VALUES LESS THAN(TO_DATE(...)) ROW STORE COMPRESS BASIC,
partition sales_2014 VALUES LESS THAN (MAXVALUE) ROW STORE COMPRESS ADVANCED
);
另请参见:
- “Row Format”(行格式),了解值在行中的存储方式;
- “Data Block Compression”(数据块压缩),了解压缩数据块的格式;
- 《Oracle Database Utilities》(《Oracle 数据库实用程序》),了解如何使用 SQL*Loader 进行直接路径加载;
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》)和《Oracle Database Performance Tuning Guide》(《Oracle 数据库性能调优指南》),了解表压缩的相关信息。
Hybrid Columnar Compression(混合列压缩)
混合列压缩将一组行的同一列数据存储在一起,数据块不采用行主序存储数据,而是结合行存储和列存储两种方式。
将同一数据类型、相似特征的列数据集中存储,可显著提高压缩带来的存储空间节省效果。该压缩方式支持通过任意 SQL 操作处理的数据压缩,且直接路径加载的压缩比更高。数据库操作对压缩对象透明,无需修改应用程序。
注意:混合列压缩与内存中列存储(IM column store)密切相关,主要区别在于:混合列压缩优化磁盘存储,而 IM 列存储优化内存存储。
Types of Hybrid Columnar Compression(混合列压缩的类型)
若底层存储支持混合列压缩,可根据需求指定不同的压缩类型:
- 数据仓库压缩(Warehouse compression):优化存储空间节省,适用于数据仓库应用程序。
- 归档压缩(Archive compression):优化压缩比(最大化压缩程度),适用于历史数据和不常修改的数据。
混合列压缩针对 Oracle Exadata 存储上的数据仓库和决策支持应用程序进行了优化。Oracle Exadata 利用其存储服务器内置的处理能力、内存和 InfiniBand 网络带宽,最大化对混合列压缩表的查询性能。
其他 Oracle 存储系统也支持混合列压缩,可实现与 Oracle Exadata 存储相同的空间节省效果,但查询性能无法达到同等水平。对于这些存储系统,混合列压缩非常适合对不常访问的旧数据进行库内归档(in-database archiving)。
Compression Units(压缩单元)
混合列压缩使用名为“压缩单元”的逻辑结构存储一组行。
向表中加载数据时,数据库将多行的列数据以列序格式存储并压缩,压缩后的数据将适配到压缩单元中。
例如,对 daily_sales 表应用混合列压缩,每天结束时向该表填充商品及销售量数据(商品 ID 和日期构成复合主键),下表展示 daily_sales 表的部分行:
| Item_ID | Date | Num_Sold | Shipped_From | Restock |
|---|---|---|---|---|
| 1000 | 01-JUN-18 | 2 | WAREHOUSE1 | Y |
| 1001 | 01-JUN-18 | 0 | WAREHOUSE3 | N |
| 1002 | 01-JUN-18 | 1 | WAREHOUSE3 | N |
| 1003 | 01-JUN-14 | 0 | WAREHOUSE2 | N |
| 1004 | 01-JUN-18 | 2 | WAREHOUSE1 | N |
| 1005 | 01-JUN-18 | 1 | WAREHOUSE2 | N |
假设上述部分行存储在一个压缩单元中,混合列压缩将每列的值集中存储,然后使用多种算法对每列进行压缩(算法选择基于多种因素,包括列的数据类型、列中实际值的基数、用户选择的压缩级别)。
如下图所示,每个压缩单元可跨越多个数据块,某一列的值可能跨越多个块,也可能不跨越:
Figure 4-7 Compression Unit
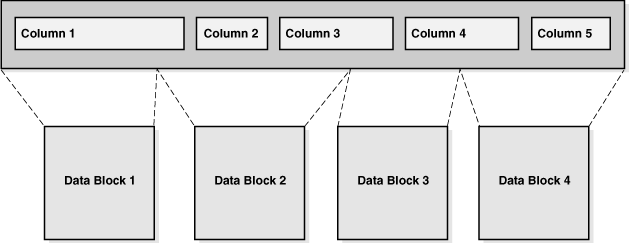
若混合列压缩无法实现空间节省,数据库将以 DBMS_COMPRESSION.COMP_BLOCK 格式存储数据,此时数据库对块应用 OLTP 压缩,这些块位于混合列压缩段中。
另请参见:
- “Row Locks (TX)”(行锁(TX));
- 《Oracle Database Licensing Information User Manual》(《Oracle 数据库许可信息用户手册》),了解混合列压缩的许可要求;
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何使用混合列压缩;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
CREATE TABLE语句的语法和语义; - 《Oracle Database PL/SQL Packages and Types Reference》(《Oracle 数据库 PL/SQL 包和类型参考》),了解
DBMS_COMPRESSION包的相关信息。
DML and Hybrid Columnar Compression(DML 与混合列压缩)
混合列压缩对不同类型 DML 操作的行锁定有影响。
Direct Path Loads and Conventional Inserts(直接路径加载与常规插入)
向使用混合列压缩的表加载数据时,可使用常规插入或直接路径加载:
直接路径加载会锁定整个表,降低并发性;
从 Oracle 数据库 12c 第 2 版(12.2)开始,支持向混合列压缩格式执行常规数组插入,其优势包括:
- 插入的行使用行级锁,提高并发性;
- 自动数据优化(ADO)和热图(Heat Map)支持对混合列压缩使用行级策略,因此即使段的其他部分存在 DML 活动,数据库也可对符合条件的块使用混合列压缩。
应用程序使用常规数组插入时,满足以下条件的行将存储在压缩单元中:
- 表存储在 ASSM(自动段空间管理)表空间中;
- 兼容性级别为 12.2.0.1 或更高;
- 表定义满足现有混合列压缩表的约束(包括无
LONG类型列、无行依赖关系)。
常规插入会生成重做(redo)和回滚(undo)数据,因此常规 DML 语句创建的压缩单元会随 DML 一起提交或回滚。数据库会自动执行索引维护,与常规数据块中的行维护方式相同。
从 Oracle 数据库 23ai 开始,自动存储压缩(Automatic Storage Compression)支持 Oracle 数据库先将加载的数据以未压缩格式存储,然后在后台逐步将行转换为混合列压缩格式。此过程对用户透明,可在提高 ETL 性能的同时保持快速查询性能。
Updates and Deletes(更新与删除)
默认情况下,若对压缩单元中的任意行执行更新或删除操作,数据库会锁定该压缩单元中的所有行。为避免此问题,可选择为表启用行级锁定,此时数据库仅锁定受更新或删除操作影响的行。
另请参见:
- 自动段空间管理(Automatic Segment Space Management);
- 行锁(TX)(Row Locks (TX));
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何执行常规插入;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
INSERT语句的相关信息; - 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
COMPRESS_IMMEDIATE提示的使用方法; - 《Oracle Database VLDB and Partitioning Guide》(《Oracle 数据库 VLDB 和分区指南》),了解自动存储压缩的相关信息。
Overview of Table Clusters(表簇概述)
表簇是共享公共列且将相关数据存储在同一数据块中的一组表。
表簇化后,单个数据块可包含多个表的行。例如,一个块可同时存储 employees 表和 departments 表的行,而非仅存储单个表的行。
簇键(cluster key)是簇化表共有的列(或列组),例如 employees 表和 departments 表共享 department_id 列。创建表簇和向表簇中添加表时,需指定簇键。
簇键值(cluster key value)是特定行集合的簇键列值,所有包含相同簇键值(如 department_id=20)的数据都物理存储在一起。无论不同表中有多少行包含该值,簇键值在簇和簇索引中仅存储一次。
表簇的类比说明
假设人力资源经理有两个书架:一个存放员工文件夹盒,另一个存放部门文件夹盒。用户经常需要某一部门所有员工的文件夹,为方便检索,经理将所有文件夹盒整理到一个书架中,按部门 ID 划分:部门 20 的所有员工文件夹和部门 20 的文件夹放在一个盒子里,部门 100 的所有员工文件夹和部门 100 的文件夹放在另一个盒子里,以此类推。
当表主要用于查询(而非修改),且表中的记录经常被一起查询或连接时,适合使用表簇。由于表簇将不同表的相关行存储在同一数据块中,合理使用表簇相比非簇表具有以下优势:
- 减少簇化表连接操作的磁盘 I/O;
- 提高簇化表连接操作的访问速度;
- 减少存储相关表和索引数据所需的空间(簇键值无需为每行重复存储)。
通常,以下场景不适合使用表簇:
- 表频繁更新;
- 表频繁需要全表扫描;
- 表需要执行
TRUNCATE(截断)操作。
Overview of Indexed Clusters(索引簇概述)
索引簇是使用索引定位数据的表簇,簇索引是基于簇键的 B 树索引,必须先创建簇索引,才能向簇化表中插入行。
Example 4-6 Creating a Table Cluster and Associated Index(示例 4-6:创建表簇及关联索引)
假设创建簇键为 department_id 的表簇 employees_departments_cluster,示例如下:
CREATE CLUSTER employees_departments_cluster (department_id NUMBER(4))
SIZE 512;
CREATE INDEX idx_emp_dept_cluster ON CLUSTER employees_departments_cluster;
由于未指定 HASHKEYS 子句,employees_departments_cluster 是索引簇。上述示例创建了基于簇键 department_id、名为 idx_emp_dept_cluster 的索引。
Example 4-7 Creating Tables in an Indexed Cluster(示例 4-7:在索引簇中创建表)
在簇中创建 employees 表和 departments 表,指定 department_id 列为簇键,示例如下(省略号表示列定义部分):
CREATE TABLE employees ( ... )
CLUSTER employees_departments_cluster (department_id);
CREATE TABLE departments ( ... )
CLUSTER employees_departments_cluster (department_id);
向 employees 表和 departments 表中添加行后,数据库会将每个部门的 employees 表行和 departments 表行物理存储在同一数据块中,行以堆的形式存储,通过索引定位。
下图展示包含 employees 表和 departments 表的 employees_departments_cluster 表簇:数据库将部门 20、部门 110 等每个部门的 employees 表行集中存储;若表未簇化,数据库无法保证相关行存储在一起。
Figure 4-8 Clustered Table Data
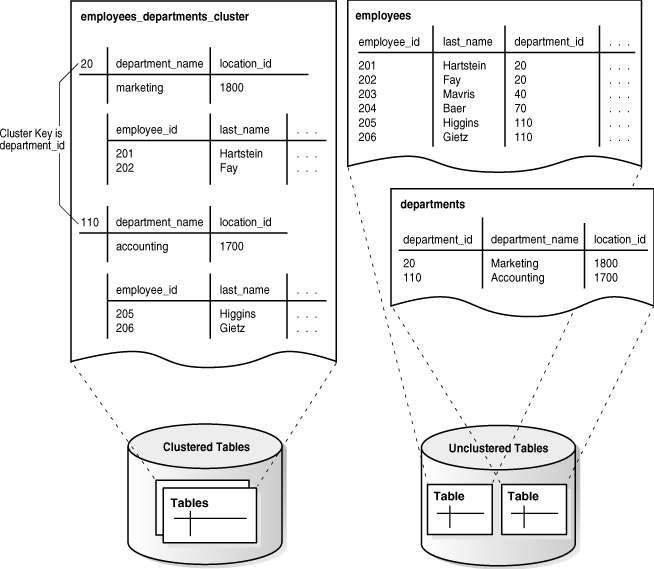
B 树簇索引将簇键值与包含数据的块的数据库块地址(DBA)关联。例如,键值 20 的索引条目显示包含部门 20 员工数据的块的地址:
20,AADAAAA9d
簇索引与非簇表上的索引一样单独管理,可存储在与表簇不同的表空间中。
另请参见:
- “Introduction to Indexes”(索引简介);
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何创建和管理索引簇;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
CREATE CLUSTER语句的语法和语义。
Overview of Hash Clusters(哈希簇概述)
哈希簇与索引簇类似,不同之处在于它使用哈希函数替代索引键,不存在独立的簇索引——在哈希簇中,数据本身就是索引。
对于索引表或索引簇,Oracle 数据库需通过存储在独立索引中的键值定位表行。要在索引表或表簇中查找或存储一行,数据库至少需执行两次 I/O 操作:
- 一次或多次 I/O 操作,用于在索引中查找或存储键值;
- 一次 I/O 操作,用于在表或表簇中读取或写入行。
而在哈希簇中查找或存储行时,Oracle 数据库会对行的簇键值应用哈希函数,生成的哈希值对应簇中的一个数据块,数据库会代表执行的语句读取或写入该块。
哈希是一种可选的表数据存储方式,可提高数据检索性能。满足以下条件时,哈希簇可能带来优势:
- 表的查询频率远高于修改频率;
- 哈希键列常用于等值条件查询(例如
WHERE department_id=20)。对于此类查询,簇键值会被哈希处理,生成的哈希键值直接指向存储该行的磁盘区域; - 可合理预估哈希键的数量以及每个键值对应的数据存储大小。
Hash Cluster Creation(哈希簇的创建)
创建哈希簇时,使用与创建索引簇相同的 CREATE CLUSTER 语句,但需额外指定哈希键。簇的哈希值数量由哈希键决定。
簇键与索引簇的键类似,是簇中表共享的单个列或复合键;哈希键值是插入到簇键列中的实际值或可能值。例如,若簇键为 department_id,则哈希键值可能为 10、20、30 等。
Oracle 数据库使用的哈希函数可接收无限个哈希键值作为输入,并将其分类到有限个“桶”(bucket)中。每个桶有唯一的数字 ID(称为哈希值),每个哈希值映射到存储对应哈希键值(如部门 10、20、30 等)行的数据库块地址。
以下示例中,预计可能存在的部门数量为 100,因此将 HASHKEYS 设置为 100:
CREATE CLUSTER employees_departments_cluster (department_id NUMBER(4))
SIZE 8192 HASHKEYS 100;
创建 employees_departments_cluster 后,可在该簇中创建 employees 表和 departments 表,之后即可像在索引簇中一样向哈希簇加载数据。
另请参见:
- “Overview of Indexed Clusters”(索引簇概述);
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何创建和管理哈希簇。
Hash Cluster Queries(哈希簇的查询)
查询哈希簇时,数据库会确定如何对用户输入的键值进行哈希处理。
例如,用户经常执行以下查询(为 p_id 输入不同的部门 ID 号):
SELECT *
FROM employees
WHERE department_id = :p_id;
SELECT *
FROM departments
WHERE department_id = :p_id;
SELECT *
FROM employees e, departments d
WHERE e.department_id = d.department_id
AND d.department_id = :p_id;
若用户查询 department_id=20 的员工,数据库可能将该值哈希到桶 77;若用户查询 department_id=10 的员工,数据库可能将该值哈希到桶 15。数据库会使用内部生成的哈希值定位存储所需部门员工行的块。
下图展示了作为水平块行的哈希簇段,如图所示,查询可通过单次 I/O 检索数据:
Figure 4-9 Retrieving Data from a Hash Cluster
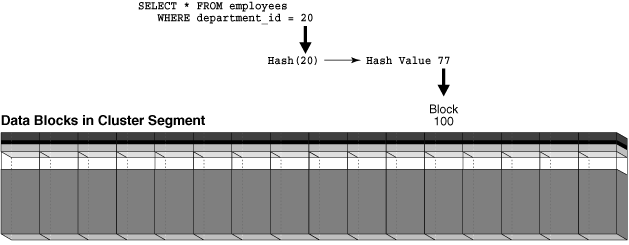
哈希簇的一个局限性是,无法对非索引簇键执行范围扫描。假设“哈希簇的创建”中创建的哈希簇没有独立索引,那么查询部门 ID 在 20 到 100 之间的部门时,无法使用哈希算法(因为无法对 20 到 100 之间的所有可能值进行哈希处理)。由于不存在索引,数据库必须执行全表扫描。
另请参见:“Index Range Scan”(索引范围扫描)。
Hash Cluster Variations(哈希簇的变体)
单表哈希簇是哈希簇的优化版本,一次仅支持一个表,哈希键与行之间存在一对一映射关系。
当用户需要通过主键快速访问表时,单表哈希簇可能带来优势。例如,用户经常通过 employee_id 查找 employees 表中的员工记录。
排序哈希簇会将哈希函数每个值对应的行以特定方式存储,使数据库能高效地按排序顺序返回这些行,排序过程由数据库内部优化执行。对于始终需要按排序顺序使用数据的应用程序,这种方式可加快数据检索速度。例如,某应用程序可能始终对 orders 表的 order_date 列进行排序。
另请参见:《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何创建单表哈希簇和排序哈希簇。
Hash Cluster Storage(哈希簇的存储)
Oracle 数据库为哈希簇分配空间的方式与索引簇不同。
在“哈希簇的创建”示例中,HASHKEYS 指定预计存在的部门数量,SIZE 指定每个部门对应数据的大小。数据库会根据以下公式计算存储空间值:
HASHKEYS * SIZE / database_block_size
因此,若“哈希簇的创建”示例中的块大小为 4096 字节,数据库会为哈希簇分配至少 200 个块。
Oracle 数据库不限制插入到簇中的哈希键值数量。例如,即使 HASHKEYS 设置为 100,也可在 departments 表中插入 200 个唯一部门,但当哈希值数量超过哈希键数量时,哈希簇的检索效率会降低。
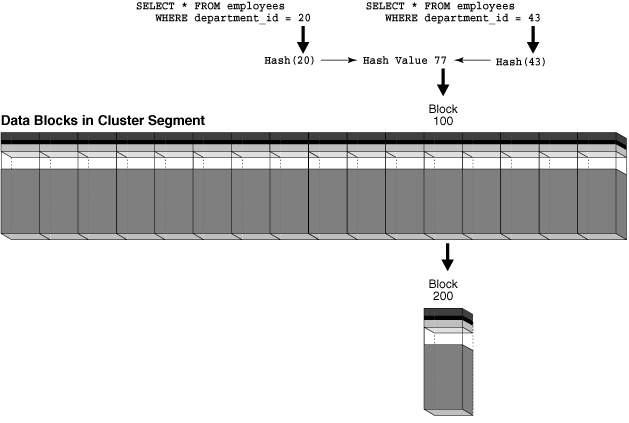
为说明检索问题,假设图 4-9 中的块 100 已装满部门 20 的行。用户向 departments 表中插入一个 department_id=43 的新部门,此时部门数量超过 HASHKEYS 值,数据库会将 department_id=43 哈希到哈希值 77(与 department_id=20 使用的哈希值相同)。这种将多个输入值哈希到同一输出值的情况称为“哈希冲突”(hash collision)。
当用户向簇中插入部门 43 的行时,数据库无法将这些行存储到已装满的块 100 中,因此会将块 100 链接到一个新的溢出块(如块 200),并将插入的行存储到新块中。此时块 100 和块 200 都可存储任意一个部门的数据。如图 4-10 所示,查询部门 20 或 43 时,需两次 I/O 操作才能检索数据(块 100 及其关联的块 200)。此问题可通过重新创建具有不同 HASHKEYS 值的簇解决。
Figure 4-10 Retrieving Data from a Hash Cluster When a Hash Collision Occurs
另请参见:《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理哈希簇的空间。
Overview of Attribute-Clustered Tables(属性簇表概述)
属性簇表是一种堆组织表,会根据用户指定的簇化指令,将数据在磁盘上存储在相邻位置,这些指令指定单个或多个表中的列。
簇化指令包括以下两种:
CLUSTERING ... BY LINEAR ORDER指令:根据指定的列对表中的数据进行排序。当查询条件包含簇化子句中列的前缀时,建议使用默认的BY LINEAR ORDER簇化方式。例如,若对sh.sales表的查询常指定客户 ID(cust_id),或同时指定客户 ID 和产品 ID(prod_id),则可使用cust_id、prod_id的线性列顺序对表中的数据进行簇化。CLUSTERING ... BY INTERLEAVED ORDER指令:使用类似 Z 序函数的特殊算法,对一个或多个表中的数据进行排序,可减少多列 I/O。当查询指定多种列组合时,建议使用BY INTERLEAVED ORDER簇化方式。例如,若对sh.sales表的查询指定不同顺序的多个维度,则可根据这些维度中的列对sales表的数据进行簇化。
属性簇化仅适用于直接路径插入(direct path INSERT)操作,对常规 DML 操作无效。
属性簇表包含的主题
- Advantages of Attribute-Clustered Tables(属性簇表的优势)
- Join Attribute Clustered Tables(连接属性簇表)
- I/O Reduction Using Zones(使用区域减少 I/O)
- Attribute-Clustered Tables with Linear Ordering(线性排序属性簇表)
- Attribute-Clustered Tables with Interleaved Ordering(交错排序属性簇表)
Advantages of Attribute-Clustered Tables(属性簇表的优势)
属性簇表的主要优势是减少 I/O,这可显著降低表扫描的 I/O 成本和 CPU 成本。I/O 减少可通过以下两种方式实现:一是利用区域(zone)减少 I/O;二是通过将簇化值在磁盘上存储在相邻位置,减少物理 I/O。
属性簇表具体具有以下优势:
- 可基于星型模式中的维度列对事实表进行簇化。在星型模式中,大多数查询会过滤维度表而非事实表,因此按事实表列进行簇化效果不佳,Oracle 数据库支持按维度表中的列进行簇化。
- 多种场景下可实现 I/O 减少:
- 与 Oracle Exadata 存储索引、Oracle 内存中最小/最大剪枝(In-Memory min/max pruning)或区域映射(zone map)配合使用时;
- 在 OLTP 应用中,对于包含前缀条件且使用线性排序属性簇化的查询;
- 对于
BY INTERLEAVED ORDER簇化,在使用部分簇化列的场景。
- 可提高数据压缩率,从而间接降低表扫描成本。当相同值在磁盘上存储在相邻位置时,数据库更容易对其进行压缩。
- 无需承担索引的存储和维护成本。
另请参见:《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解属性簇表的更多优势。
Join Attribute Clustered Tables(连接属性簇表)
基于连接列的属性簇化称为“连接属性簇化”。与表簇不同,连接属性簇表不会将多个表的数据存储在同一数据库块中。
例如,考虑一个与维度表 products 连接的属性簇表 sales:sales 表仅包含自身的行,但行的排序基于从 products 表连接而来的列值。在数据移动、直接路径插入和 CREATE TABLE AS SELECT 操作期间,会执行相应的连接。相反,若 sales 表和 products 表位于标准表簇中,则数据块会包含两个表的行。
另请参见:《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解更多关于连接属性簇化的信息。
I/O Reduction Using Zones(使用区域减少 I/O)
区域(zone)是一组连续的数据块,存储相关列的最小值和最大值。
当 SQL 语句包含对区域中存储列的谓词时,数据库会将谓词值与区域中存储的最小值和最大值进行比较,从而确定 SQL 执行期间需要读取的区域。
I/O 减少是指跳过不包含数据库满足查询所需数据的表块或索引块,这可显著降低表扫描的 I/O 成本和 CPU 成本。
Purpose of Zones(区域的用途)
用一个通俗的类比理解区域:假设销售经理使用一个带有鸽巢(类似数据块)的书架,每个鸽巢中存放描述已售衬衫的收据(类似行),并按发货日期排序。在这个类比中,区域映射(zone map)类似一叠索引卡,每张卡对应一个“区域”(连续范围的鸽巢,如鸽巢 1-10),卡上列出该区域中存储收据的最小和最大发货日期。
当有人需要查找某一日期发货的衬衫时,经理会翻阅索引卡,找到包含目标日期范围的卡,记录对应的鸽巢区域,然后仅在该区域的鸽巢中查找所需收据,无需搜索书架上的所有鸽巢。
Zone Maps(区域映射)
区域映射是一种独立的访问结构,将数据块划分为区域,Oracle 数据库将每个区域映射实现为一种物化视图(materialized view)。
与索引类似,区域映射可降低表扫描的 I/O 成本和 CPU 成本。当 SQL 语句包含对区域映射中列的谓词时,数据库会将谓词值与每个区域中存储的表列最小值和最大值进行比较,确定 SQL 执行期间需要读取的区域。
基本区域映射(basic zone map)基于单个表定义,维护该表部分列的最小值和最大值;连接区域映射(join zone map)基于与一个或多个其他表进行外连接的表定义,维护其他表中部分列的最小值和最大值。Oracle 数据库会自动维护这两种类型的区域映射。
一个表最多可存在一个区域映射;对于分区表,所有分区和子分区共享一个区域映射,且分区表的区域映射还会跟踪每个区域、每个分区和每个子分区的最小值和最大值。若表与维度表存在外连接,区域映射定义可包含维度列的最小值和最大值。
另请参见:《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解区域映射的概述。
Zone Map Creation(区域映射的创建)
基本区域映射可手动或自动创建。
Manual Zone Maps(手动区域映射)
可使用 DDL 语句创建、删除和维护区域映射。
在 CREATE TABLE 或 ALTER TABLE 语句中指定 CLUSTERING 子句时,数据库会自动在指定的簇化列上创建区域映射,该区域映射将属性簇表中连续数据块与列的最小值和最大值关联起来,属性簇表通过区域映射实现 I/O 减少。
也可使用 CREATE MATERIALIZED ZONEMAP 语句显式创建区域映射,这种情况下,无论是否使用属性簇化,都可创建区域映射。例如,可在行按一组列自然排序的表(如按时间排序的股票交易表)上创建区域映射。
另请参见:
- “Overview of Materialized Views”(物化视图概述);
- 《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解如何创建区域映射。
Automatic Zone Maps(自动区域映射)
Oracle 数据库可自动创建基本区域映射,这类区域映射称为“自动区域映射”。
Oracle 数据库可为分区表和非分区表自动创建基本区域映射,后台进程会自动维护以这种方式创建的区域映射。
使用 DBMS_AUTO_ZONEMAP 过程启用自动区域映射:
EXEC DBMS_AUTO_ZONEMAP.CONFIGURE('AUTO_ZONEMAP_MODE','ON');
另请参见:
- 《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解如何使用
DBMS_AUTO_ZONEMAP包管理自动区域映射; - 《Oracle Database PL/SQL Packages and Types Reference》(《Oracle 数据库 PL/SQL 包和类型参考》),了解
DBMS_AUTO_ZONEMAP包的相关信息; - 《Oracle Database Licensing Information User Manual》(《Oracle 数据库许可信息用户手册》),了解不同版本和服务支持的功能详情。
How a Zone Map Works: Example(区域映射的工作原理:示例)
以下示例说明区域映射如何在包含常量谓词的查询中对数据进行剪枝。
假设创建以下 lineitem 表:
CREATE TABLE lineitem
(
orderkey NUMBER,
shipdate DATE,
receiptdate DATE,
destination VARCHAR2(50),
quantity NUMBER
);
lineitem 表包含 4 个数据块,每个块存储 2 行数据,表 4-4 展示了该表的 8 行数据:
| 块(Block) | 订单键(orderkey) | 发货日期(shipdate) | 收货日期(receiptdate) | 目的地(destination) | 数量(quantity) |
|---|---|---|---|---|---|
| 1 | 1 | 1-1-2014 | 1-10-2014 | San_Fran | 100 |
| 1 | 2 | 1-2-2014 | 1-10-2014 | San_Fran | 200 |
| 2 | 3 | 1-3-2014 | 1-9-2014 | San_Fran | 100 |
| 2 | 4 | 1-5-2014 | 1-10-2014 | San_Diego | 100 |
| 3 | 5 | 1-10-2014 | 1-15-2014 | San_Fran | 100 |
| 3 | 6 | 1-12-2014 | 1-16-2014 | San_Fran | 200 |
| 4 | 7 | 1-13-2014 | 1-20-2014 | San_Fran | 100 |
| 4 | 8 | 1-15-2014 | 1-30-2014 | San_Jose | 100 |
可使用 CREATE MATERIALIZED ZONEMAP 语句为 lineitem 表创建区域映射,每个区域包含 2 个块,并存储 orderkey、shipdate 和 receiptdate 列的最小值和最大值,表 4-5 展示了该区域映射:
| 块范围(Block Range) | 最小订单键(min orderkey) | 最大订单键(max orderkey) | 最小发货日期(min shipdate) | 最大发货日期(max shipdate) | 最小收货日期(min receiptdate) | 最大收货日期(max receiptdate) |
|---|---|---|---|---|---|---|
| 1-2 | 1 | 4 | 1-1-2014 | 1-5-2014 | 1-9-2014 | 1-10-2014 |
| 3-4 | 5 | 8 | 1-10-2014 | 1-15-2014 | 1-15-2014 | 1-30-2014 |
执行以下查询时,数据库会读取区域映射,确定仅需扫描块 1 和块 2(跳过块 3 和块 4),因为日期 1-3-2014 落在块 1-2 区域的最小和最大日期之间:
SELECT * FROM lineitem WHERE shipdate = '1-3-2014';
另请参见:
- 《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解如何使用区域映射;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
CREATE MATERIALIZED ZONEMAP语句的语法和语义。
Attribute-Clustered Tables with Linear Ordering(线性排序属性簇表)
表的线性排序方案会根据用户指定的属性,按特定顺序将行划分为多个范围。Oracle 数据库支持对通过主键-外键关系连接的单个或多个表进行线性排序。
例如,sales 表会将 cust_id 和 prod_id 列划分为多个范围,然后将这些范围在磁盘上集中存储。为表指定 BY LINEAR ORDER 指令后,当谓词包含指令中的前缀列或所有列时,可实现显著的 I/O 减少。
假设对 sales 表的查询常指定客户 ID(cust_id),或同时指定客户 ID 和产品 ID(prod_id),可创建属性簇表以让此类查询实现 I/O 减少:
CREATE TABLE sales
(
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL,
amount_sold NUMBER(10,2),
...
)
CLUSTERING (cust_id, prod_id)
BY LINEAR ORDER
YES ON LOAD
YES ON DATA MOVEMENT
WITH MATERIALIZED ZONEMAP;
包含 cust_id 和 prod_id 两列,或仅包含前缀 cust_id 的查询可实现 I/O 减少;仅包含 prod_id 的查询无法实现显著的 I/O 减少(因为 prod_id 是 BY LINEAR ORDER 子句的后缀)。以下示例展示数据库如何在表扫描期间减少 I/O:
Example 4-8 Specifying Only cust_id(示例 4-8:仅指定 cust_id)
应用程序执行以下查询:
SELECT * FROM sales WHERE cust_id = 100;
由于 sales 表是 BY LINEAR ORDER 簇表,数据库仅需读取包含 cust_id=100 值的区域。
Example 4-9 Specifying prod_id and cust_id(示例 4-9:指定 prod_id 和 cust_id)
应用程序执行以下查询:
SELECT * FROM sales WHERE cust_id = 100 AND prod_id = 2300;
由于 sales 表是 BY LINEAR ORDER 簇表,数据库仅需读取包含 cust_id=100 和 prod_id=2300 值的区域。
另请参见:
- 《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解如何使用线性排序对表进行簇化;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
BY LINEAR ORDER子句的语法和语义。
Attribute-Clustered Tables with Interleaved Ordering(交错排序属性簇表)
交错排序使用类似 Z 序(Z-order)的技术,支持数据库基于簇化列中的任意谓词子集对 I/O 进行剪枝,适用于数据仓库中的维度层次结构。
与线性排序属性簇表一样,Oracle 数据库支持对通过主键-外键关系连接的单个或多个表进行交错排序。属性簇表以外的表中的列必须通过外键链接,并与属性簇表连接。
大型数据仓库常采用星型模式组织数据:维度表使用父子层次结构,并通过外键与事实表连接。对事实表进行交错排序簇化后,数据库可使用特殊函数在表扫描期间跳过维度列中的值。
Example 4-10 Interleaved Ordering Example(示例 4-10:交错排序示例)
假设数据仓库包含 sales 事实表及其两个维度表 customers(客户表)和 products(产品表),大多数查询的谓词包含 customers 表的层次结构(cust_state_province、cust_city)和 products 表的层次结构(prod_category、prod_subcategory),可对 sales 表使用交错排序,部分语句示例如下:
CREATE TABLE sales
(
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL,
amount_sold NUMBER(10,2),
...
)
CLUSTERING sales
JOIN products ON (sales.prod_id = products.prod_id)
JOIN customers ON (sales.cust_id = customers.cust_id)
BY INTERLEAVED ORDER
(
products.prod_category,
products.prod_subcategory
),
(
customers.cust_state_province,
customers.cust_city
)
WITH MATERIALIZED ZONEMAP;
注意:
BY INTERLEAVED ORDER子句中指定的列不必实际位于维度表中,但必须通过主键-外键关系连接。
假设应用程序在连接查询中涉及 sales、products 和 customers 表,查询的谓词包含 products.prod_category 和 customers.cust_state_province 列,语句如下:
SELECT cust_city, prod_subcategory, SUM(amount_sold)
FROM sales, products, customers
WHERE sales.prod_id = products.prod_id
AND sales.cust_id = customers.cust_id
AND products.prod_category = 'Boys'
AND customers.cust_state_province = 'England - Norfolk'
GROUP BY cust_city, prod_subcategory;
在上述查询中,prod_category 和 cust_state_province 列是 CREATE TABLE 示例中簇化定义的一部分,扫描 sales 表时,数据库会查询区域映射,仅访问该区域中的行标识(rowid)。
另请参见:
- “Overview of Dimensions”(维度概述);
- 《Oracle Database Data Warehousing Guide》(《Oracle 数据库数据仓库指南》),了解如何使用交错排序对表进行簇化;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
BY INTERLEAVED ORDER子句的语法和语义。
Overview of Temporary Tables(临时表概述)
临时表存储的数据仅在事务或会话期间存在。
临时表中的数据对会话具有私有性,每个会话仅能查看和修改自身的数据。
可创建全局临时表(global temporary table)或私有临时表(private temporary table),下表展示了两者的核心区别:
| 特征(Characteristic) | 全局临时表(Global) | 私有临时表(Private) |
|---|---|---|
| 命名规则(Naming rules) | 与永久表相同 | 必须以 ORA$PTT_ 为前缀 |
| 表定义可见性(Visibility of table definition) | 所有会话可见 | 仅创建表的会话可见 |
| 表定义存储位置(Storage of table definition) | 磁盘 | 仅内存 |
| 类型(Types) | 事务专用(ON COMMIT DELETE ROWS)或会话专用(ON COMMIT PRESERVE ROWS) |
事务专用(ON COMMIT DROP DEFINITION)或会话专用(ON COMMIT PRESERVE DEFINITION) |
第三种临时表类型为“游标持续时间临时表”(cursor-duration temporary table),由数据库为特定类型的查询自动创建。
Purpose of Temporary Tables(临时表的用途)
临时表适用于需缓冲结果集的应用场景。
例如,某日程安排应用允许大学生创建可选的学期课程表,全局临时表中的一行代表一个课程表。会话期间,课程表数据具有私有性;当学生选择某一课程表后,应用程序会将该课程表对应的行移动到永久表中;会话结束时,数据库会自动删除全局临时表中的课程表数据。
私有临时表适用于动态报表应用。例如,某客户关系管理(CRM)应用可能以同一用户身份长期连接,且同时存在多个活动会话,每个会话会为每个新事务创建名为 ORA$PTT_crm 的私有临时表。应用程序可对每个会话使用相同的表名,但修改表定义;数据和定义仅对该会话可见,表定义会保留到事务结束或手动删除表为止。
Segment Allocation in Temporary Tables(临时表中的段分配)
与永久表类似,全局临时表是在数据字典中静态定义的持久对象;对于私有临时表,元数据仅存在于内存中,但可存储在磁盘的临时表空间中。
对于全局临时表和私有临时表,会话首次插入数据时,数据库会分配临时段;在会话中加载数据前,表看起来为空。对于事务专用临时表,数据库会在事务结束时释放临时段;对于会话专用临时表,数据库会在会话结束时释放临时段。
另请参见:“Temporary Segments”(临时段)。
Temporary Table Creation(临时表的创建)
CREATE ... TEMPORARY TABLE 语句用于创建临时表,需指定 GLOBAL TEMPORARY TABLE(全局临时表)或 PRIVATE TEMPORARY TABLE(私有临时表)。两种情况下,ON COMMIT 子句均用于指定表数据是事务专用(默认)还是会话专用。临时表是为数据库本身创建的,而非为每个 PL/SQL 存储过程创建。
可使用 CREATE INDEX 语句为全局临时表(非私有临时表)创建索引,这些索引也具有临时性,索引中的数据与临时表中的数据具有相同的会话或事务范围。也可在全局临时表上创建视图或触发器。
另请参见:
- “Overview of Views”(视图概述);
- “Overview of Triggers”(触发器概述);
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何创建和管理临时表;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
CREATE ... TEMPORARY TABLE语句的语法和语义。
Overview of External Tables(外部表概述)
外部表可访问外部源中的数据,就像这些数据存储在数据库的表中一样。
数据可采用任何提供了访问驱动程序(access driver)的格式存储,可使用 SQL(串行或并行)、PL/SQL 和 Java 查询外部表。
Purpose of External Tables(外部表的用途)
当 Oracle 数据库应用程序需访问非关系型数据时,外部表非常有用。
例如,某基于 SQL 的应用程序可能需要访问以下格式的文本文件记录:
100,Steven,King,SKING,515.123.4567,17-JUN-03,AD_PRES,31944,150,90
101,Neena,Kochhar,NKOCHHAR,515.123.4568,21-SEP-05,AD_VP,17000,100,90
102,Lex,De Haan,LDEHAAN,515.123.4569,13-JAN-01,AD_VP,17000,100,90
此时可创建外部表,将文本文件复制到外部表定义中指定的位置,然后使用 SQL 查询文本文件中的记录。类似地,可使用外部表提供对 JSON 文档或 LOB(大型对象)的只读访问。
在数据仓库环境中,外部表对执行抽取、转换和加载(ETL)任务非常有价值。例如,外部表支持将数据加载阶段与转换阶段流水线化,无需在数据库内部暂存数据以准备后续处理。
可在虚拟列或非虚拟列上对外部表进行分区,也可创建混合分区表(部分分区为内部分区,部分为外部分区)。与内部分区类似,外部分区也可受益于分区剪枝(partition pruning)和分区级连接(partition-wise join)等性能优化。例如,可使用分区外部表分析存储在 Hadoop 分布式文件系统(HDFS)或 NoSQL 数据库中的大量非关系型数据。
另请参见:“Partitioned Tables”(分区表)。
Data in Object Stores(对象存储中的数据)
外部表可用于访问对象存储中的数据。
除支持访问存储在操作系统文件和大数据源中的外部数据外,Oracle 还支持访问对象存储中的外部数据。对象存储在云环境中较为常见,采用扁平架构管理单个对象(任何类型的非结构化数据及元数据),并将对象分组到简单的容器中。尽管对象存储主要是云环境中的数据存储架构,但也有本地部署的存储硬件支持该架构。
可通过 DBMS_CLOUD 包或手动定义外部表访问对象存储中的数据。Oracle 强烈建议使用 DBMS_CLOUD 包,因为它提供更多功能,且与 Oracle 自治数据库(Oracle Autonomous Database)完全兼容。
External Table Access Drivers(外部表访问驱动程序)
访问驱动程序是为数据库解释外部数据的 API,运行在数据库内部,数据库通过该驱动程序读取外部表中的数据。访问驱动程序和外部表层负责对数据文件中的数据执行必要的转换,使其与外部表定义匹配。
下图展示了对外部数据的 SQL 访问流程:
Figure 4-11 External Tables
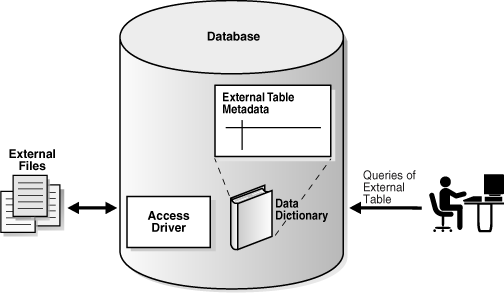
Oracle 为外部表提供以下访问驱动程序:
-
ORACLE_LOADER(默认)
支持访问采用 SQL*Loader 支持的大多数格式的外部文件,无法使用ORACLE_LOADER驱动程序创建、更新或追加外部文件。 -
ORACLE_DATAPUMP
支持卸载(unload)或加载(load)外部数据:- 卸载操作:从数据库读取数据,并将数据插入到由一个或多个外部文件表示的外部表中;外部文件创建后,数据库无法更新或追加数据。
- 加载操作:读取外部表,并将其数据加载到数据库中。
-
ORACLE_HDFS
支持提取存储在 Hadoop 分布式文件系统(HDFS)中的数据。 -
ORACLE_HIVE
支持访问存储在 Apache Hive 数据库中的数据,源数据可存储在 HDFS、HBase、Cassandra 或其他系统中。与其他访问驱动程序不同,无法指定位置,因为ORACLE_HIVE会从外部元数据存储中获取位置信息。 -
ORACLE_BIGDATA
支持对存储在结构化和非结构化格式(包括 Apache Parquet、Apache Avro、Apache ORC 和文本格式)中的数据进行只读访问,也可使用该驱动程序查询本地数据(适用于测试和较小数据集)。
External Table Creation(外部表的创建)
在内部,创建外部表意味着在数据字典中创建元数据。与普通表不同,外部表不描述存储在数据库中的数据,也不描述外部数据的存储方式,而是描述外部表层如何向数据库呈现数据。
CREATE TABLE ... ORGANIZATION EXTERNAL 语句包含两部分:
- 外部表定义:描述列类型,类似视图,支持 SQL 查询外部数据而无需将其加载到数据库中。
- 映射部分:将外部数据映射到列。
外部表默认是只读的,除非使用 CREATE TABLE AS SELECT 语句并指定 ORACLE_DATAPUMP 访问驱动程序创建。外部表的限制包括不支持索引列和列对象。
另请参见:
- 《Oracle Database Utilities》(《Oracle 数据库实用程序》),了解外部表的相关信息;
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理外部表、外部连接和目录对象;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解创建和查询外部表的相关信息。
Overview of Blockchain Tables(区块链表概述)
区块链表是一种仅追加(append-only)表,专为集中式区块链应用程序设计。
在 Oracle 区块链表中,节点(peer)是信任数据库以维护防篡改账本(ledger)的数据库用户。账本以区块链表的形式实现,由应用程序定义和管理。现有应用程序无需新的基础设施或编程模型,即可防范欺诈行为。尽管区块链表的事务吞吐量低于标准表,但性能优于去中心化区块链。
区块链表之所以是“仅追加”表,是因为仅允许 INSERT 这一种 DML 操作,禁止 UPDATE、DELETE、MERGE、TRUNCATE 和直接路径加载。数据库事务可同时涉及区块链表和标准表,例如,单个事务可向一个标准表和两个不同的区块链表中插入行。
区块链表可用于保护闪回数据归档(Flashback Data Archive)的内容,帮助判断是否有人篡改了表的内容。区块链日志历史表可视为维护被跟踪用户表更改的加密安全逻辑重做日志。
从版本 2 区块链表开始,可向区块链表中添加或删除用户列;版本 1 区块链表不允许添加或删除用户列。被删除的物理列和数据不会实际删除,而是标记为不可见。
Row Chains(行链)
在区块链表中,行链是通过哈希方案(hashing scheme)链接在一起的一系列行。
版本 1 区块链表中,系统行链通过数据库实例 ID(instance ID)和链 ID(chain ID)的唯一组合标识;从版本 2 区块链表开始,除这两个标识外,还需插入行的数据库全局唯一标识符(global unique identifier),系统行链通过可插入数据库全局唯一 ID、数据库实例 ID 和链 ID 的唯一组合标识。区块链表中的一行仅属于一个系统行链,单个表支持多个系统行链。
注意:标准表中的链式行(chained row)与区块链表中的行链(row chain)无关,仅“链(chain)”这一术语相同。
链中的每一行都有唯一的序列号,数据库通过对每个链的行执行 SHA2-512 哈希计算,对行进行排序。每个插入行的哈希值由插入行的行内容(包括链中前一行的哈希值)推导得出。
尽管区块链表中的每一行仅属于一个系统链,但也可根据创建区块链表时指定的一组用户列的值,属于一个用户链(user chain)。
Row Content(行内容)
行内容是连续的字节序列,包含行的列数据和链中前一行的哈希值。
创建区块链表时,数据库会创建多个隐藏列。例如,创建包含 bank(银行)和 deposit(存款)列的区块链表 bank_ledger,语句如下:
CREATE BLOCKCHAIN TABLE bank_ledger (bank VARCHAR2(128), deposit NUMBER)
NO DROP UNTIL 31 DAYS IDLE
NO DELETE UNTIL 31 DAYS AFTER INSERT
HASHING USING "SHA2_512"
VERSION "v1";
数据库会自动创建以 ORABCTAB 为前缀的隐藏列,如 ORABCTAB_INST_ID$、ORABCTAB_CHAIN_ID$、ORABCTAB_SEQ_NUM$ 等。这些隐藏列(大部分无法修改或管理)用于实现防篡改算法,该算法通过在提交时按特定顺序获取唯一的表级链锁,避免死锁。
注意:区块链表的行内容存储在标准数据块中,本 Oracle 数据库版本不支持区块链表使用表簇。
实例 ID、链 ID 和序列号可唯一标识一行;从版本 2 区块链表开始,除这三个值外,还需插入行的数据库全局唯一标识符。每行都有一个与平台无关的 SHA2-512 哈希值,存储在隐藏列 ORABCTAB_HASH$ 中,该哈希值基于插入行的内容和链中前一行的哈希值。
行的列值数据格式包含列元数据和内容的字节:
- 列元数据:20 字节的结构,描述列在表中的位置、数据类型、空值状态、字节长度等特征;
- 列内容:表示行中值的字节集,例如,值
Chase的 ASCII 表示为43 68 61 73 65,可使用 SQL 中的DUMP函数获取列元数据和内容。
哈希计算的行内容包括多个列的列数据格式:链中前一行的哈希值、用户定义列,以及固定数量的隐藏列。
可通过指定一组用于定义行版本(row version)的列,由系统跟踪相关行的插入顺序并记录。若指定了行版本,数据库会自动创建并维护一个视图,显示每个用户指定列值组合对应的最后插入行,视图名称遵循 Blockchain_Table_Name_LAST$ 的命名规则。
在许多场景中,行可能需要由最终用户的委托者(delegate)额外签名或替代签名,例如银行经理对最终用户插入的行进行签名。委托签名者(delegate signer)是另一个数据库用户,可对基于行的系统加密哈希计算得出的结果添加签名。行可由最终用户、委托者或两者共同签名。仅当可通过委托者的证书验证签名,且委托者的证书记录在数据库字典表中时,才接受委托者的签名。
当行由最终用户或委托者签名后,用户可能需要为该行获取会签(countersignature)。会签可视为专门针对已由最终用户或委托者签名的行的区块链表摘要(digest)。行为会签后,会签会返回给行签名者,并保存在该行中。请求对行进行会签的用户可将此信息保存在单独的数据存储中,用于不可否认(nonrepudiation)目的。
User Interface for Blockchain Tables(区块链表的用户界面)
与标准表类似,区块链表通过 SQL 创建,支持标量数据类型、LOB、JSON 和分区,也可为区块链表创建索引和触发器。
创建区块链表需使用 CREATE BLOCKCHAIN TABLE 语句,区块链表通过 NO DROP UNTIL n DAYS IDLE 子句指定保留期,可使用 DROP TABLE 语句删除表。
Oracle 区块链表支持以下界面:
DBMS_BLOCKCHAIN_TABLE包:支持对表行执行各种操作,例如,使用SIGN_ROW过程为之前插入的行内容应用签名;使用VERIFY_ROWS验证行是否未被篡改;使用DELETE_EXPIRED_ROWS删除超过保留期(由NO DELETE子句指定)的行。DBA_BLOCKCHAIN_TABLES视图:显示表元数据,如行保留期、表可删除前的闲置期、哈希算法等。
另请参见:
- 《Oracle Database Administrator’s Guide》(《Oracle 数据库管理员指南》),了解如何管理区块链表;
- 《Oracle Database PL/SQL Packages and Types Reference》(《Oracle 数据库 PL/SQL 包和类型参考》),了解
DBMS_BLOCKCHAIN_TABLE包; - 《Oracle Database Reference》(《Oracle 数据库参考》),了解
DBA_BLOCKCHAIN_TABLES视图。
Overview of Immutable Tables(不可变表概述)
不可变表是仅追加(append-only)表,可防止内部人员的未授权数据修改,以及人为错误导致的意外数据修改。
未授权修改可能由获取内部凭证的受损员工或恶意员工尝试执行。
不可变表可添加新行,但无法修改现有行。必须为不可变表和表中的行都指定保留期:行超过指定的行保留期后会变为过期行,仅过期行可从不可变表中删除。
不可变表包含系统生成的隐藏列,与区块链表的隐藏列相同。插入行时,ORABCTAB_CREATION_TIME$ 和 ORABCTAB_USER_NUMBER$ 列会被设置为非空值;除 V1 不可变表外,ORABCTAB_PDB_GUID$ 列也会被设置为非空值;若不可变表创建时指定了行版本,则 ORABCTAB_ROW_VERSION$ 和 ORABCTAB_LAST_ROW_VERSION_NUMBER$ 列会被设置为非空值,其余系统生成的隐藏列值均为 NULL。
使用不可变表无需修改现有应用程序。
Overview of Object Tables(对象表概述)
对象表是一种特殊的表,其中每行代表一个对象(object)。
Oracle 对象类型(object type)是用户定义的类型,包含名称、属性(attribute)和方法(method)。对象类型支持将客户、采购订单等现实世界实体建模为数据库中的对象。
对象类型定义逻辑结构,但不创建存储。以下示例创建名为 department_typ 的对象类型:
CREATE TYPE department_typ AS OBJECT
(
d_name VARCHAR2(100),
d_address VARCHAR2(200)
);
以下示例创建 department_typ 对象类型的对象表 departments_obj_t,然后向表中插入一行。departments_obj_t 表的属性(列)源自对象类型的定义:
CREATE TABLE departments_obj_t OF department_typ;
INSERT INTO departments_obj_t
VALUES ('hr', '10 Main St, Sometown, CA');
与关系列类似,对象表仅能包含一种类型的行,即与表声明类型相同的对象实例。默认情况下,对象表中的每个行对象都有相关联的逻辑对象标识符(OID),用于在对象表中唯一标识该对象,对象表的 OID 列是隐藏列。
另请参见:
- 《Oracle Database Object-Relational Developer’s Guide》(《Oracle 数据库对象关系开发指南》),了解 Oracle 数据库的对象关系特性;
- 《Oracle Database SQL Language Reference》(《Oracle 数据库 SQL 语言参考》),了解
CREATE TYPE语句的语法和语义。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)