视觉大模型Qwen2.5-VL-7B菜品大模型训练过程及成果
同样通过调用第三方大模型获取每个类别(菜品)的简介以及对应的食谱,这类数据在全参数训练或微调时能够保持模型的基本语言理解能力以及增强泛化能力,在构建训练数据时按比例加入可提升训练效果。干锅土豆片的做法步骤如下:1. 土豆去皮后切成均匀薄片,用清水冲洗去多余淀粉,沥干备用。2. 锅中倒入适量油,放入花椒和干辣椒,小火慢炸出香味,不要炸糊。3. 下土豆片,大火翻炒至表面微微焦黄,土豆片变软。4. 淋入
原文:视觉大模型Qwen2.5-VL-7B菜品大模型训练过程及成果
❝在餐饮数字化、智能化的浪潮中,精准的菜品识别技术正成为连接线上线下服务的关键纽带,无论是智能点餐、供应链管理还是餐饮零售场景,都对其有着迫切需求。然而,相似菜品的区分、复杂场景下的识别准确率等问题,一直是技术落地的难点。
❝本文聚焦于基于 Qwen2.5-vl 大模型的菜品识别能力优化,详细记录了从数据集构建到模型训练、评估的全流程。通过创新的数据集扩充方法(结合第三方大模型补充语义信息)、针对性的训练策略(聚焦视觉与多模态融合层),以及多维度的测试验证(内部数据与现场场景结合),为提升菜品识别的精准度与泛化能力提供了一套可落地的实践方案。
1. 模型训练流程
1.1 数据集构建
本次大模型训练使用的数据集是原用于训练Paddle的PPLCNET模型的数据集中的图片,排除了部分类别后,剩余总类别为3600类,每个类别(菜品)用独立文件夹区分存储。但原数据集并没有特别完善的中文菜名,如使用英文+数字的命名或使用主要食材进行命名,因此,本次数据集的构建采用了如下过程进行二次构建。
1.1.1 调用第三方在线大模型构建菜品语义信息
本次数据集的构建使用了其他在线大模型(GPT4.1、豆包)的能力,通过给予在线大模型有效的提示词,让大模型识别图片中与图片符合的语义信息(每个类别识别一张图,然后展开至全数据集),包含:菜品名、主要食材、菜系、烹饪方式、卡路里、营养成分、颜色、形状、口味、制作难度以及节日关联等等数据。 数据示例:
{
"name": "干锅土豆片",
"cuisine": "川菜",
"cooking_method": [
"干锅"
],
"ingredients": [
"土豆片",
"干辣椒",
"青蒜",
"花椒",
"辣椒油"
],
"calories": 130.0,
"serving_temperature": "热食",
"flavor": [
"辣",
"咸"
],
"nutrients": [
"碳水化合物",
"膳食纤维",
"少量蛋白质"
],
"is_vegetarian": "是",
"allergens": [],
"color": [
"红棕色"
],
"shape": [
"片状"
],
"associated_festival": [],
"difficulty": "简单"
}
通过这些丰富的结构化数据可以组合多样的prompt进行大模型的训练或微调。
1.1.2 调用第三方在线大模型构建菜品简介、食谱
同样通过调用第三方大模型获取每个类别(菜品)的简介以及对应的食谱,这类数据在全参数训练或微调时能够保持模型的基本语言理解能力以及增强泛化能力,在构建训练数据时按比例加入可提升训练效果。 数据示例:
干锅土豆片的做法步骤如下:
1. 土豆去皮后切成均匀薄片,用清水冲洗去多余淀粉,沥干备用。
2. 锅中倒入适量油,放入花椒和干辣椒,小火慢炸出香味,不要炸糊。
3. 下土豆片,大火翻炒至表面微微焦黄,土豆片变软。
4. 淋入辣椒油,继续翻炒均匀,让土豆片充分裹上红亮的辣油和香料。
5. 加入切段的青蒜,快速翻匀,撒适量盐调味。
6. 翻炒均匀后即可盛入干锅,趁热食用。
这道菜色泽红亮,香辣微咸,土豆片口感外香内糯,非常适合作为下饭或聚会小吃。
这道菜是川菜中颇受欢迎的“干锅土豆片”。
它的主角是切成片状的新鲜土豆,经过干锅的特色做法翻炒,充分保留了土豆本身的粉糯口感。烹制时加入大量的干辣椒和花椒,使得整道菜香辣四溢,麻中带香,回味无穷。点缀的青蒜让整个菜肴增添了一抹清新的绿色,同时提升了整体的香味层次。辣椒油的加入,不仅带来了浓郁的川菜风味,也给菜肴赋予了诱人的红棕色泽,看上去十分开胃。
干锅土豆片通常热食,是川菜馆或家庭聚餐桌上的明星素菜。作为川菜中的经典代表之一,它味型以辣、咸为主,麻辣爽口,非常下饭。虽然食材简单,却能通过干锅爆香的技艺,激发出丰富的口感和香气。
营养方面,土豆本身富含碳水化合物、膳食纤维,配搭蔬菜又更加健康。这道菜属于素食,做法简单,适合各种烹饪水平的人士尝试,也是辣味爱好者不可错过的家常佳肴。无论是搭配米饭,还是作为下酒小菜,都别具风味,深受各年龄层欢迎。
1.1.3 使用原方案(yolo+pplcnet)确定相似菜
相似菜品难以区分是当前方案(yolo+pplcnet)难以克服的关键问题,我们希望大模型能够依托天然的大参数、高泛化能力以及更细致的图片编码能力来解决相似菜问题,那么在准备数据集时就应该构建出相似菜的数据。
使用pplcnet对数据集中的每个类别进行注册(每个类别注册2张),然后再随机选出一张同类别中的其他图片进行特征比对,选出分数相近的其他若干类别,构建出每个类别(菜品)对应的若干相似菜数据。
1.1.4 train、test以及validation的构建
根据Qwen2.5-vl官方的训练示例以及大模型训练的相关范式,将上述数据构建为两种类型的数据: 第一类:只提供一张菜品图片,让模型识别图片对应的菜品名,数据示例:
{
"image": "/mnt/data/菜品数据/DISH_NJZW_ZLP_GX4.6/train/凉拌鸡胗@ZHONGGUANGHE_20220901/20220609174506-5#90.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\n图中的菜品是什么?"
},
{
"from": "gpt",
"value": "凉拌鸡胗"
}
]
},...
第二类:提供一张图片以及一个候选菜单(包含相似菜),让模型在候选菜单中选择一个最符合图片的菜品名,数据示例:
{
"image": "/mnt/data/菜品数据/DISH_NJZW_ZLP_GX4.6/train/红烧鱼1@HGD_20211221/20210301181427_8190820012282_00044bdebaf5$798_549_1324_811#51.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\n根据提供的菜单(油豆腐烧青椒、素鸡(豆制品)、蚵仔煎、面包片配蛋黄酱、炒鹅肠、豆腐脑、青红椒炒鸡胗、凉拌鸭掌、粉条白菜回锅肉、红烧鱼)和图片内容,请指出图片最可能是哪道菜。限制:只能输出菜单中提供的菜品名称,不要添加其他内容。"
},
{
"from": "gpt",
"value": "红烧鱼"
}
]
},...
每种类型的数据都会包含多种prompt来提升模型的泛化能力。当然在数据集的设计之初还包含了其他类别的数据,如包含菜品的营养成分、菜品简介或菜谱等,但本次训练主要聚焦在模型的菜品识别能力,因此构建的数据集只包含上文所述的两类训练数据。
所构建的数据集包含3600类菜品,用于训练的数据约10万张。
1.2 训练平台选择
由于Qwen2.5-vl 7B大模型参数庞大(官方所谓7B指的是llm模块参数量级为7B,但加上vision相关模块后规模是大于7B的),普通消费级显卡不能加载完整模型参数,因此选择了Nvidia的专业计算卡——H20,H20拥有96GB的大显存,能够胜任7B量级参数的训练。当然分布式训练也进行了尝试,但由于机器的网络带宽问题(千兆网卡,数据传输太慢,训练时长不可接受),遂放弃分布式训练。
在训练过程中内存的使用量最高达到80GB,为了确保足够的内存,至少需要100GB的内存才能保障训练过程不会因为内存溢出而崩溃。硬盘的要求不是很高,但如果设置了检查点都保存模型文件、参数文件以及完整的优化器检查点等信息,那么每个检查点占用的硬盘约44GB.
1.3 模型训练
模型训练可分为全参数训练与微调,在实践中两种方式都进行了测试,其中微调模型使用的是unsloth对大模型进行约全参数的2.5%的参数进行微调,验证集loss最终维持在0.07左右;而全参数训练最终的loss维持在0.0005左右,效果更好,因此下面介绍具体的全参数训练流程。
虽然说是全参数训练,但H20的96GB显存也不能完全加载qwen2.5-vl-7B的全部参数(如果同时训练LLM、Vsion、MLP层比爆显存),考虑到我们的场景其实是要训练模型的vision层编解码能力以及mlp层的多模态特征融合能力,对于LLM层在该场景下作用不是很大,当前的大模型的语言理解能力已经非常强大,足够理解我们的应用场景,因此我们只训练了vision层与mlp层。
即便只加载了vision层与mlp层,在关闭梯度检查后,H20单次也只能输入8张图片进行训练,此时显存占用在70GB左右,设置全局学习率为
,mlp层学习率可以高一些为,视觉塔学习率为,使用deepspeed的zero3级别的显存优化,启用梯度累计后,可模拟 16 或更高 batch size 进行稳定的训练。
10万左右的数据量在H20上进行训练,单个epoch的时间约3.5小时,训练总计10个epoch,耗时近40小时。由于官方提供的训练脚本并没有实现验证功能,因此每个epoch都保存一个检查点,且保存完整的优化器检查点等数据,方便后续的测试或resume来选出最优模型。
2. 模型评估
模型评估分为内部数据与外部数据
2.1 内部数据评估
使用构建数据集时创建的测试集对模型的基础能力进行测试,对应数据集中的两类数据,评估也分为两类评估:
2.1.1 第一类测试(已有标签)
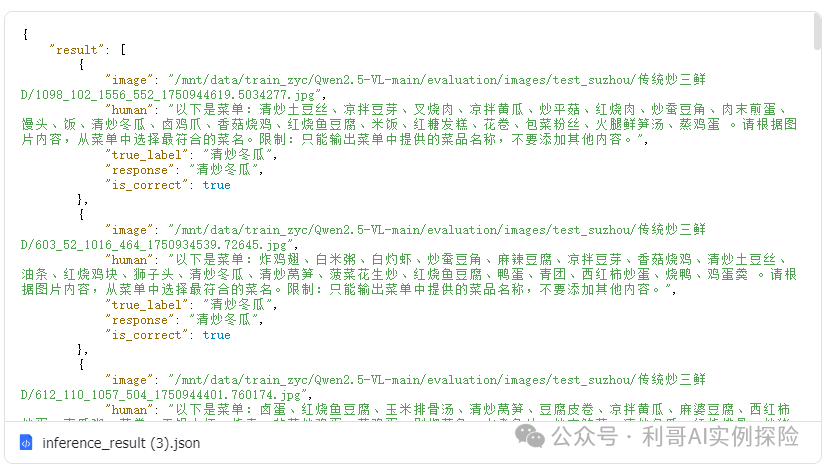
只给模型提供图片,让模型输出菜品名,然后与已有标签值比对,要求强等于算正确,否则算错误。 测试了3633 条数据,结果如下:

具体测试结果:

2.1.2 第二类测试(增加候选菜单列表)
给模型提供图片以及一个候选菜单列表(长度为20),测试了3469条数据,结果如下:

具体测试结果:

2.2 外部数据评估
外部数据评估使用了三个现场数据,zg核现场、浦东现场以及苏州gd现场数据,候选菜单长度为20。

2.2.1 zg核现场(模型起名后,框菜单)


2.2.2 浦东现场(模型起名后,框菜单)

2.2.3 苏州gd现场(模型起名后,框菜单)

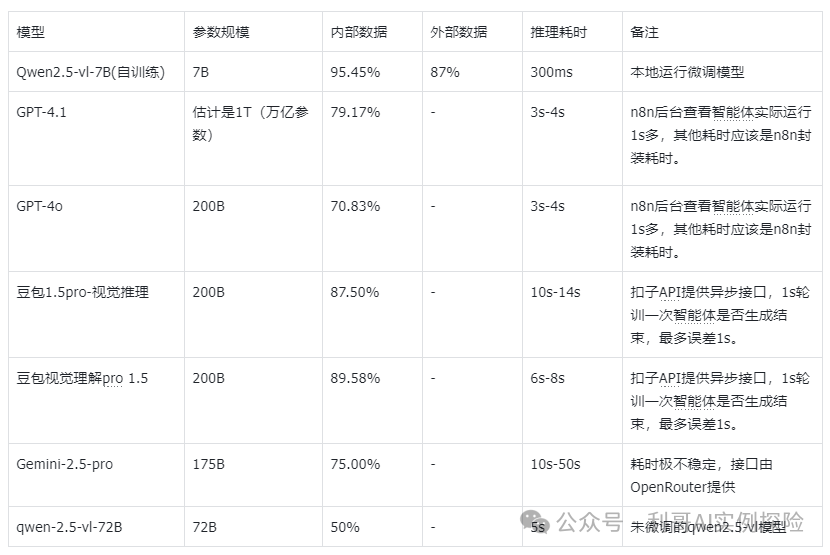
2.3 与在线模型对比
总结
❝本文围绕菜品识别大模型的训练与评估展开,通过系统化的实践验证了基于 Qwen2.5-vl 模型的优化路径的有效性。
❝在训练环节,通过调用第三方大模型补充菜品语义信息(如食材、菜系、做法等)、构建相似菜数据,并针对性划分训练集与测试集,为模型学习提供了丰富的结构化支撑;依托 Nvidia H20 显卡的大显存优势,采用聚焦视觉层与 MLP 层的全参数训练策略,在 10 万级数据上完成了高效训练。
❝评估结果显示,模型在内部测试中表现优异(两类测试均保持高准确率),且在 zg 核、浦东、苏州 gd 等多个现场场景中稳定发挥,识别效果优于部分在线模型,尤其在相似菜品区分上展现了更强的泛化能力。
❝该实践不仅为菜品识别技术的落地提供了参考,也为多模态大模型在垂直领域的微调与优化提供了可借鉴的思路,助力餐饮行业智能化升级。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)