Xinference详细搭建步骤及如何接入dify
Xinference 是针对生成式 AI 场景度身定制的能力全面的推理服务平台。附官网地址:https://xorbits.cn/
Xinference 是针对生成式 AI 场景度身定制的能力全面的推理服务平台。
附官网地址:https://xorbits.cn/
支持的模型丰富
提供100+最新开源模型,从文本语音视频到 embedding/rerank 模型,始终保持最快适配。
广泛的模型支持
支持多种硬件平台,支持国产 GPU,包括华为昇腾、海光、天数等。可同时支持多种硬件共同服务
生态丰富
多种主流开发框架已经原生支持 Xinference,包括 Langchain、Dify、Ragflow、FastGPT 等
官方列举的不仅有上面几个优势,还支持多推理引擎、异构 GPU、高吞吐和高可用。
说了这么多优势,不如咱们实际来操作下。
1、创建环境
我这边是使用的conda来管理环境,后台回复"conda"可拿到conda的安装包。
conda create -n xinf python==3.11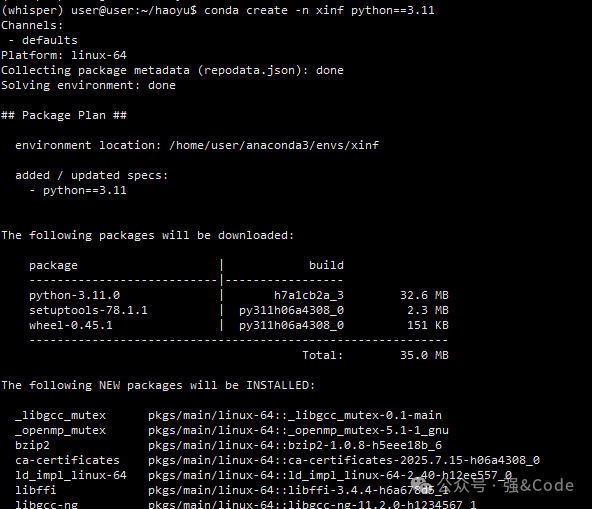
2、激活环境
conda activate xinf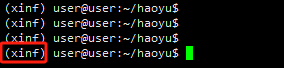
3、安装xinference
pip install "xinference[all]"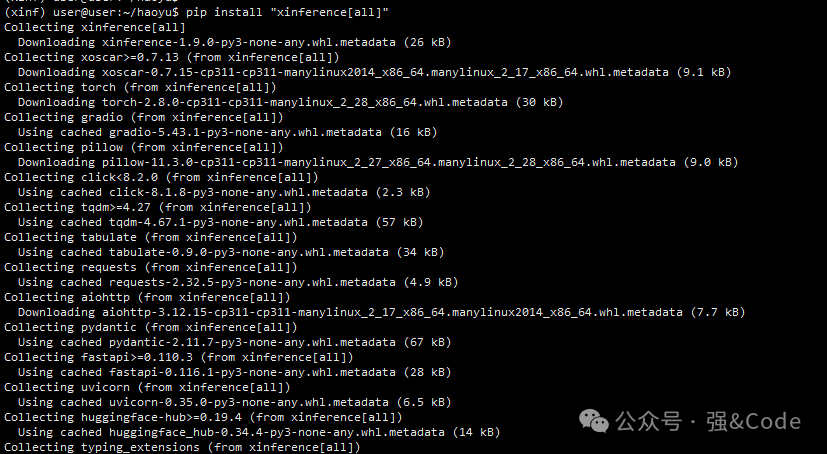
4、启动
xinference-local --host 0.0.0.0 --port 9997端口默认是9997
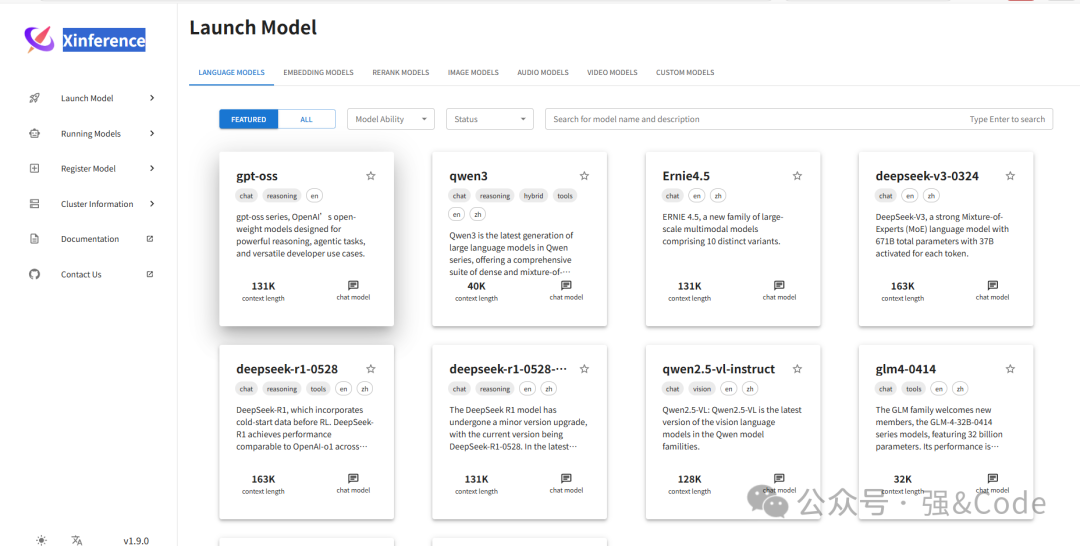
整个过程很顺利,没有报什么错。
5、下载模型
如图,我这边下载bge-base为例
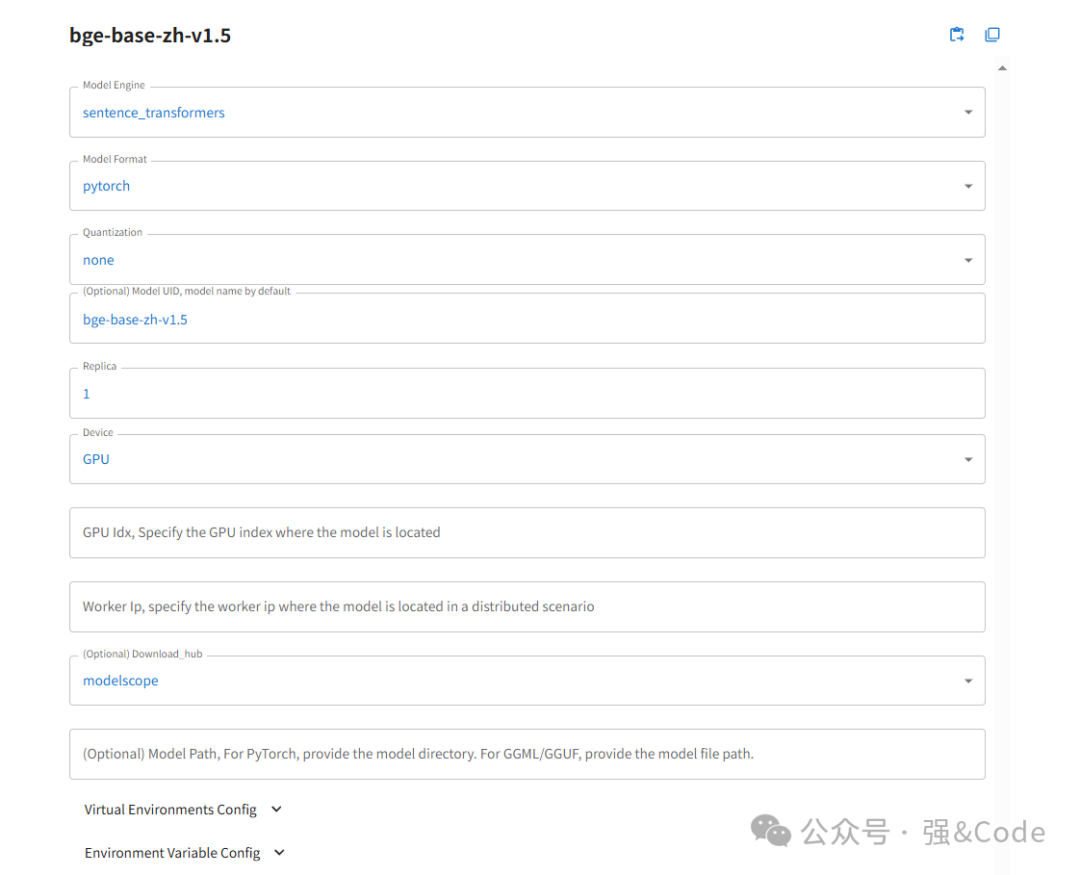
如上图填写。点击最下面”小火箭“按钮,开始下载,选择modelscope下载方式。如果需要huggingface下载的话记得启动前添加镜像。
export HF_ENDPOINT=https://hf-mirror.com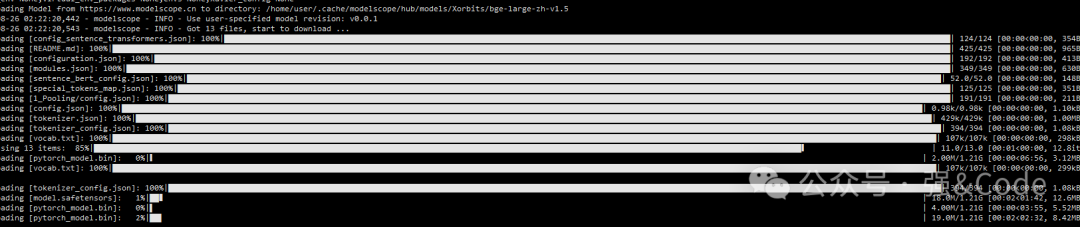
下载速度还是很快的。下载完成后xinference会自动加到Running Models里面。这里面是正在运行的模型。
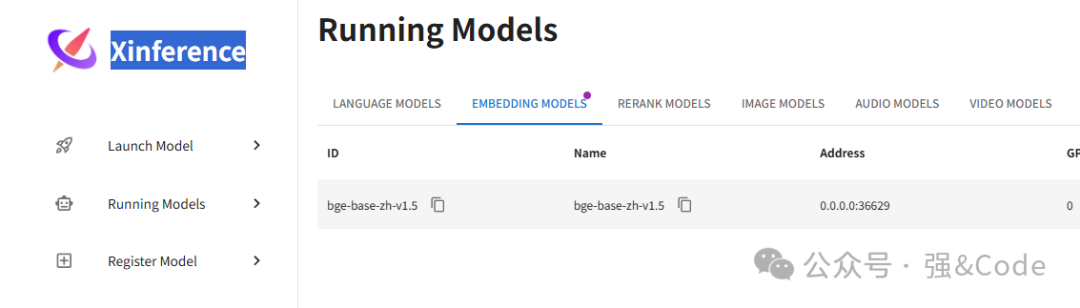
6、接入dify
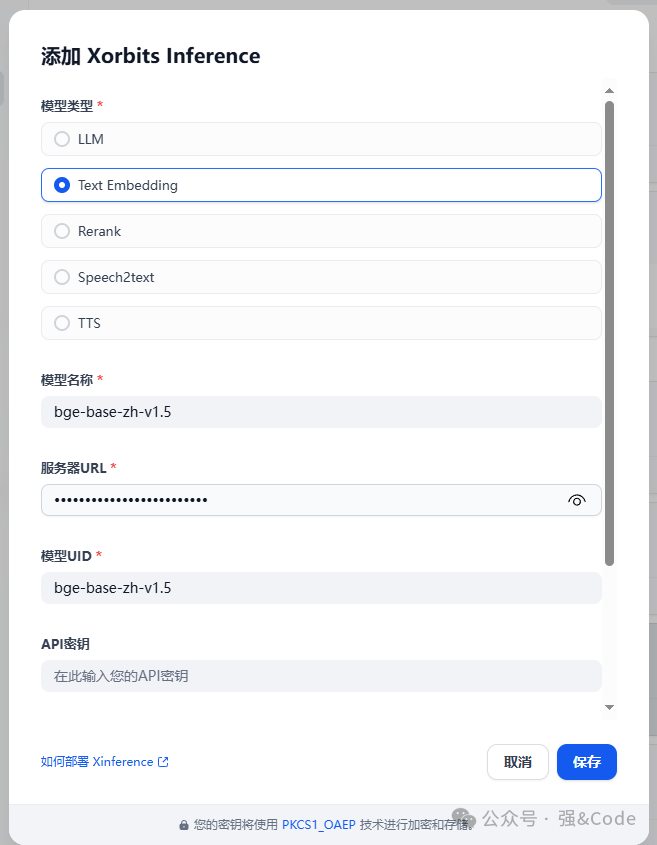
模型类型:选择咱们下载的模型类型。
模型名称:xinference显示的模型名称。
服务器URL:xinference的ip和端口,也就是咱们搭建好的网页地址和端口。
模型UID:xinference显示的模型UID
接着保存,即可添加成功。
7、思考
既然下载模型了,那么模型下载到哪了呢?咱们来找找。
模型默认下载到.cache文件夹下了。

这就是搭建的整个过程和如何接入到dify。
大家在搭建的过程中或者使用的过程中有遇到什么问题欢迎留言,大家一起讨论学习。
你本来就一无所有,还有什么怕失去的? ---《通透》杨天真

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)