教你顺利下载Huggingface上的大模型文件以及一些实用技巧
本文介绍下载Huggingface大模型的方法:提供带自动重试的shell脚本,可从GitHub获取,需配置镜像;还提及HFDownloader工具及Windows安装法,最后说明用rsync复制模型到其他主机的方式。
教你顺利下载Huggingface上的大模型文件以及一些实用技巧
阅读原文
建议阅读原文,始终查看最新文档版本,获得最佳阅读体验:《教你顺利下载Huggingface上的大模型文件以及一些实用技巧》
引言
在这个全民AI的时代,很多网友都想捣鼓一下大模型,要玩大模型,有时候需要本地部署,而本地部署则需要下载大模型文件,由于众所周知的原因,国内无法直接访问Huggingface网站(Hugging Face – The AI community building the future.),大家一般用的是镜像站https://hf-mirror.com
但是如果用Huggingface官方的下载工具从镜像站下载大模型,则很不稳定,经常中断,要反复很多次才能下载好,为了解决这个问题,我编写了一个shell脚本(支持Linux和Windows),保证能完整下载大模型文件,哪怕是满血版的deepseek R1(高达720GB)也没问题,只要带宽不是很慢,差不多一个晚上能下载好。
脚本进行了更新,新的脚本有完善的错误处理,更好的提示信息。而且huggingface提供的CLI也进行了很大幅度的更新,连命令都改了,原先是huggingface-cli,最新的是hf,官方文档:Command Line Interface (CLI)

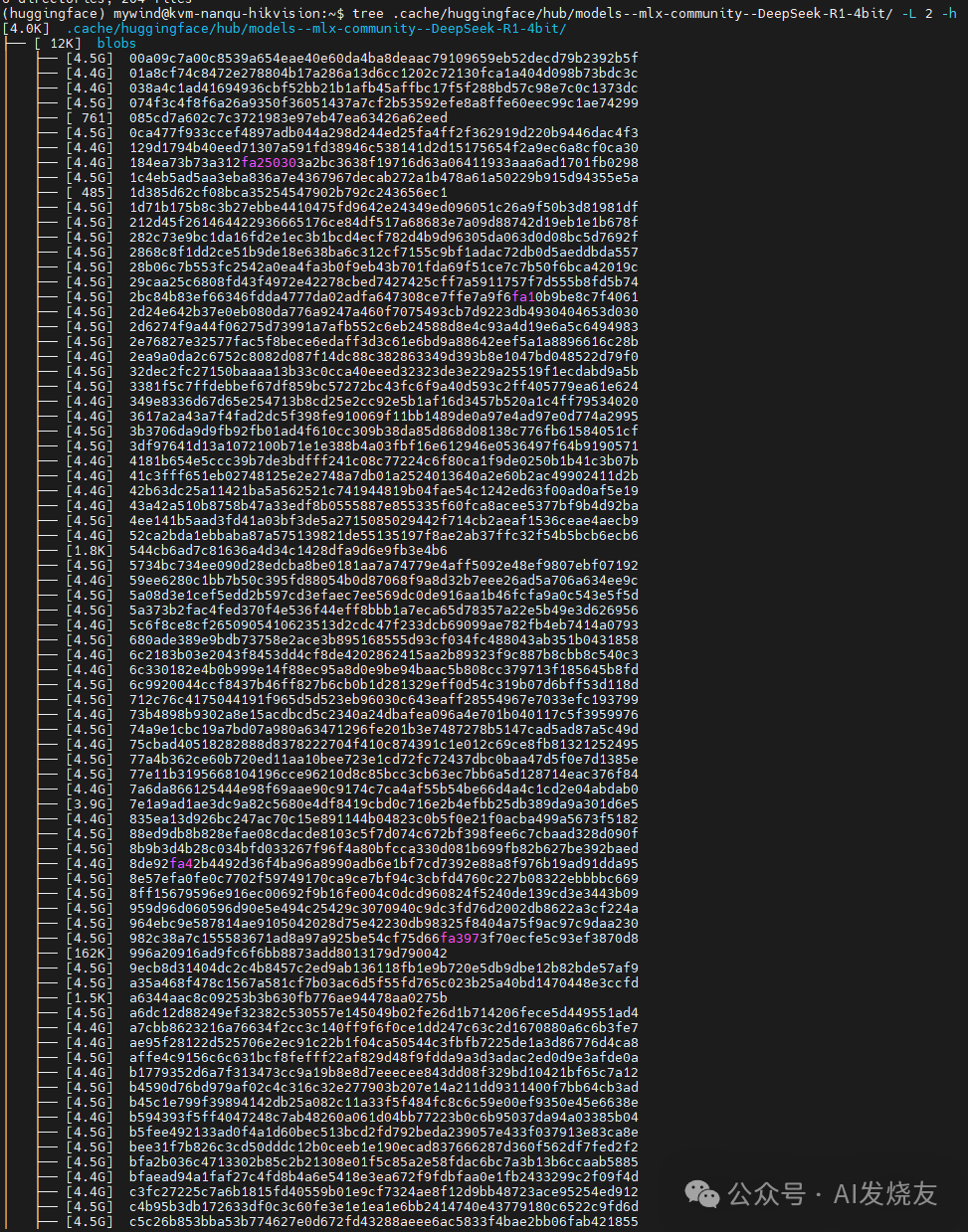
下图是我之前下载的经过Q4量化的deepseek R1,总共接近400GB,睡个觉就下载完了
shell脚本
脚本的逻辑很简单,就是检测huggingface-cli退出代码,如果不是正常退出的,说明报错了,那就自动重新开始下载模型文件,直到下载完成为止。重试次数可以设置,默认是999.
脚本代码我已经上传到了github,网址为:common_shell_scripts/download_hf_model at main · iamtornado/common_shell_scripts
github的REAMDE有对此脚本的详细使用说明,还有注意事项
接下来简单演示如何使用bash shell脚本(本篇文章以ubuntu server 24.04系统为例):
先从github下载好相应系统的脚本文件,然后授予脚本执行权限:
chmod +x ./download_hf_model.sh
现在就可以开始用脚本下载Huggingface上任意一个大模型了,这里以下载microsoft/Phi-4-mini-instruct大模型为例,其实这是个小模型,总共不超过10GB
运行脚本,加上一个参数即可,这个参数就是Huggingface网站上模型的id
./download_hf_model.sh microsoft/Phi-4-mini-instruct
输出如下,可以看到快得飞起,默认情况下,可同时下载8个文件(注意下图演示的是旧版的脚本,我已经对原有脚步进行了重写,新版脚本更加易用,错误处理更完善,使用方法还是类似的)

下图演示的是利用最新版本的脚本下载google/gemma-3n-E4B-it这个大模型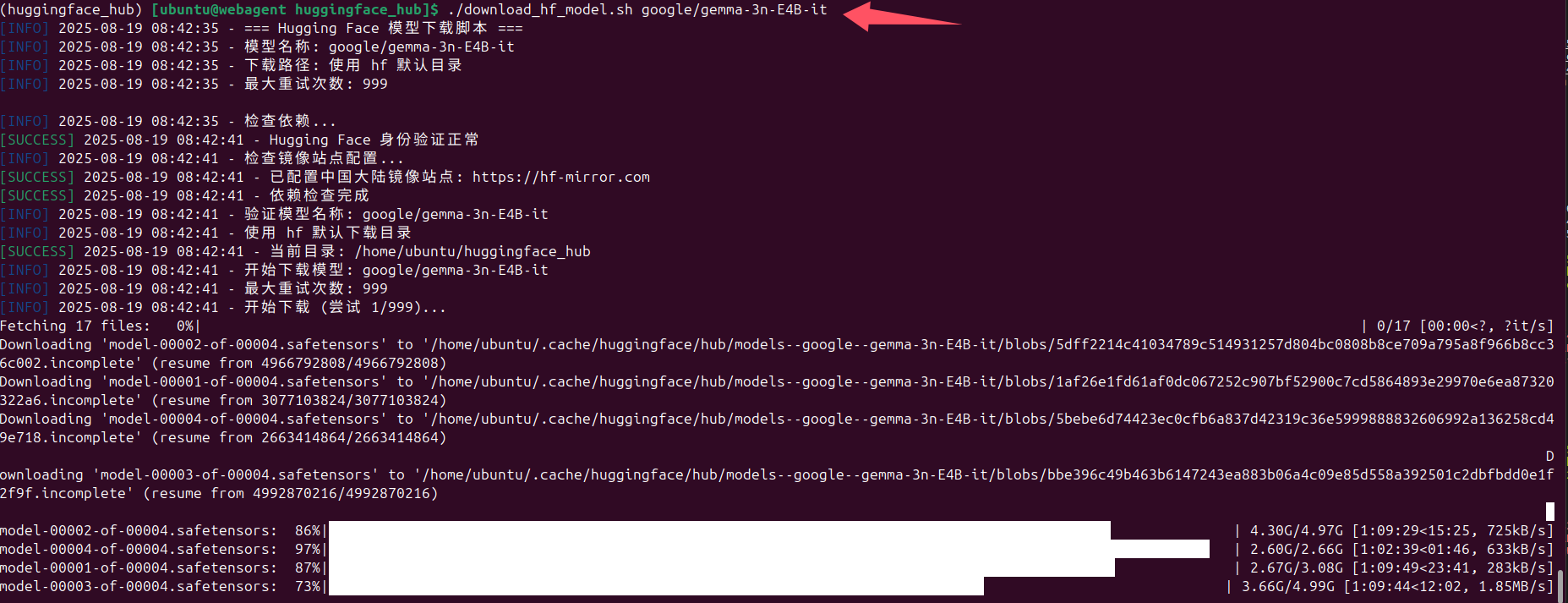
如果下载出错了,比如网络不稳定等原因造成中断,脚本会自动重新开始下载,而且是断电续传。
以下是bash shell脚本完整代码(建议始终查看github上的代码,总是最新版本的):
#!/bin/bash
# Hugging Face 模型下载脚本
# 具有自动重试机制,支持断点续传和错误恢复
# 使用方法: ./download_hf_model.sh <model_name> [download_path] [max_retries]
set -e
# 颜色定义
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m' # No Color
# 默认配置
DEFAULT_DOWNLOAD_PATH="" # 空字符串表示使用 hf 默认目录
DEFAULT_MAX_RETRIES=999
DEFAULT_RETRY_DELAY=10
# 日志函数
log_info() {
echo -e "${BLUE}[INFO]${NC} $(date '+%Y-%m-%d %H:%M:%S') - $1"
}
log_success() {
echo -e "${GREEN}[SUCCESS]${NC} $(date '+%Y-%m-%d %H:%M:%S') - $1"
}
log_warning() {
echo -e "${YELLOW}[WARNING]${NC} $(date '+%Y-%m-%d %H:%M:%S') - $1"
}
log_error() {
echo -e "${RED}[ERROR]${NC} $(date '+%Y-%m-%d %H:%M:%S') - $1"
}
# 显示帮助信息
show_help() {
cat << EOF
Hugging Face 模型下载脚本
用法: $0 <model_name> [download_path] [max_retries]
参数:
model_name 要下载的模型名称 (例如: meta-llama/Llama-2-7b-chat-hf)
download_path 下载路径 (可选,默认: 使用 hf 默认目录)
max_retries 最大重试次数 (可选,默认: 999)
示例:
$0 meta-llama/Llama-2-7b-chat-hf
$0 meta-llama/Llama-2-7b-chat-hf ./my_models 10
$0 "microsoft/DialoGPT-medium" /data/models 3
注意事项:
- 确保已安装 huggingface_hub CLI 工具
- 对于私有模型,需要先运行 'hf auth login' 进行身份验证
- 大模型下载可能需要较长时间,建议使用 screen 或 tmux 运行
- 脚本会直接尝试下载,如果模型不存在会自动报错
EOF
}
# 检查依赖
check_dependencies() {
log_info "检查依赖..."
# 检查 hf 命令是否可用
if ! command -v hf &> /dev/null; then
log_error "未找到 'hf' 命令。请先安装 huggingface_hub CLI 工具:"
echo "pip install -U 'huggingface_hub[cli]'"
exit 1
fi
# 检查是否已登录
if ! hf auth whoami &> /dev/null; then
log_warning "未检测到 Hugging Face 登录状态。某些模型可能需要身份验证。"
echo "如需登录,请运行: hf auth login"
read -p "是否继续下载?(y/N): " -n 1 -r
echo
if [[ ! $REPLY =~ ^[Yy]$ ]]; then
exit 1
fi
else
log_success "Hugging Face 身份验证正常"
fi
# 检查镜像站点配置(针对中国大陆用户)
check_mirror_config
log_success "依赖检查完成"
}
# 检查镜像站点配置
check_mirror_config() {
log_info "检查镜像站点配置..."
if [[ -n "$HF_ENDPOINT" ]]; then
if [[ "$HF_ENDPOINT" == "https://hf-mirror.com" ]]; then
log_success "已配置中国大陆镜像站点: $HF_ENDPOINT"
else
log_warning "检测到自定义 HF_ENDPOINT: $HF_ENDPOINT"
log_info "如需使用中国大陆镜像站点,建议设置: export HF_ENDPOINT=https://hf-mirror.com"
fi
else
log_warning "未配置 HF_ENDPOINT 环境变量"
log_info "针对中国大陆用户,建议配置镜像站点以加快下载速度:"
echo ""
echo " 临时配置(当前会话有效):"
echo " export HF_ENDPOINT=https://hf-mirror.com"
echo ""
echo " 永久配置(添加到 ~/.bashrc 或 ~/.zshrc):"
echo " echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc"
echo " source ~/.bashrc"
echo ""
echo " 或者使用以下命令快速配置:"
echo " echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc && source ~/.bashrc"
echo ""
read -p "是否现在配置镜像站点?(y/N): " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
# 检查是否已经在 ~/.bashrc 中配置过
if grep -q "HF_ENDPOINT" ~/.bashrc 2>/dev/null; then
log_warning "HF_ENDPOINT 已在 ~/.bashrc 中配置过"
log_info "当前配置: $(grep HF_ENDPOINT ~/.bashrc)"
log_info "跳过重复配置,仅设置当前会话环境变量"
else
# 添加配置到 ~/.bashrc
echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
log_success "镜像站点配置已添加到 ~/.bashrc"
fi
# 设置当前会话的环境变量
export HF_ENDPOINT=https://hf-mirror.com
log_success "镜像站点配置完成!当前会话已生效。"
log_info "请运行 'source ~/.bashrc' 使配置永久生效。"
else
log_info "跳过镜像站点配置,继续使用默认设置。"
fi
fi
}
# 验证模型名称
validate_model_name() {
local model_name="$1"
if [[ -z "$model_name" ]]; then
log_error "模型名称不能为空"
show_help
exit 1
fi
# 检查模型名称格式
if [[ ! "$model_name" =~ ^[a-zA-Z0-9_-]+/[a-zA-Z0-9._-]+$ ]]; then
log_warning "模型名称格式可能不正确: $model_name"
log_info "标准格式应为: organization/model-name"
fi
log_info "验证模型名称: $model_name"
}
# 创建下载目录
create_download_dir() {
local download_path="$1"
if [[ -n "$download_path" ]]; then
# 用户指定了下载路径
if [[ ! -d "$download_path" ]]; then
log_info "创建下载目录: $download_path"
mkdir -p "$download_path"
fi
cd "$download_path"
log_success "下载目录: $(pwd)"
else
# 使用 hf 默认目录
log_info "使用 hf 默认下载目录"
log_success "当前目录: $(pwd)"
fi
}
# 模型验证说明
# 不再预先验证模型是否存在,直接通过 hf download 命令进行下载
# 如果模型不存在,hf download 命令会自动报错
# 下载模型文件
download_model() {
local model_name="$1"
local max_retries="$2"
local download_path="$3"
local retry_count=0
local success=false
log_info "开始下载模型: $model_name"
log_info "最大重试次数: $max_retries"
while [[ $retry_count -lt $max_retries && $success == false ]]; do
retry_count=$((retry_count + 1))
if [[ $retry_count -gt 1 ]]; then
log_warning "第 $retry_count 次重试下载 (共 $max_retries 次)"
log_info "等待 ${DEFAULT_RETRY_DELAY} 秒后重试..."
sleep $DEFAULT_RETRY_DELAY
fi
log_info "开始下载 (尝试 $retry_count/$max_retries)..."
# 使用 hf download 命令下载模型
if [[ -n "$download_path" ]]; then
# 用户指定了下载路径,使用 --local-dir 参数
if hf download "$model_name" --local-dir .; then
log_success "模型下载成功!"
success=true
break
fi
else
# 使用 hf 默认目录,不指定 --local-dir 参数
if hf download "$model_name"; then
log_success "模型下载成功!"
success=true
break
fi
fi
# 如果下载失败,处理重试逻辑
log_error "下载失败 (尝试 $retry_count/$max_retries)"
if [[ $retry_count -lt $max_retries ]]; then
log_info "准备重试..."
else
log_error "已达到最大重试次数,下载失败"
fi
done
if [[ $success == false ]]; then
log_error "模型下载最终失败,请检查网络连接和模型名称"
return 1
fi
return 0
}
# 验证下载完整性
verify_download() {
local model_name="$1"
log_info "验证下载完整性..."
# 使用 hf cache scan 命令验证下载
log_info "使用 hf cache scan 验证下载状态..."
# 检查 hf 命令是否可用
if ! command -v hf &> /dev/null; then
log_error "hf 命令不可用,无法验证下载完整性"
return 1
fi
# 执行 hf cache scan 命令
local cache_scan_output
if cache_scan_output=$(hf cache scan 2>&1); then
log_success "缓存扫描完成"
# 显示完整的 hf cache scan 结果
log_success "✓ 缓存扫描完成"
# 直接显示 hf cache scan 的完整输出
echo ""
log_info "📊 Hugging Face 缓存扫描结果:"
echo "=================================="
echo "$cache_scan_output"
echo "=================================="
echo ""
# 检查模型是否在缓存中
if echo "$cache_scan_output" | grep -q "$model_name"; then
log_success "✓ 模型 $model_name 已成功下载到缓存"
return 0
else
log_warning "在缓存中未找到模型 $model_name"
log_info "这可能意味着:"
log_info "1. 模型下载失败"
log_info "2. 模型下载到了不同的位置"
log_info "3. 缓存扫描结果不完整"
# 尝试使用传统方法验证
verify_download_traditional "$model_name"
return 1
fi
else
log_warning "hf cache scan 命令执行失败: $cache_scan_output"
log_info "回退到传统验证方法..."
# 回退到传统验证方法
verify_download_traditional "$model_name"
return $?
fi
}
# 传统验证方法(作为备用)
verify_download_traditional() {
local model_name="$1"
log_info "使用传统方法验证下载完整性..."
# 检查是否有文件被下载
local file_count=$(find . -type f -not -path "./.*" | wc -l)
if [[ $file_count -eq 0 ]]; then
log_error "未找到下载的文件"
return 1
fi
log_success "找到 $file_count 个文件"
# 检查常见的重要文件
local important_files=("config.json" "tokenizer.json" "tokenizer_config.json" "pytorch_model.bin" "*.safetensors" "*.bin")
local found_important=0
for pattern in "${important_files[@]}"; do
if ls $pattern 1> /dev/null 2>&1; then
local count=$(ls $pattern | wc -l)
found_important=$((found_important + count))
log_info "✓ 找到重要文件: $pattern (共 $count 个)"
fi
done
if [[ $found_important -gt 0 ]]; then
log_success "传统验证通过,找到 $found_important 个重要文件"
return 0
else
log_warning "未找到常见的重要文件,但下载可能仍然有效"
return 1
fi
}
# 显示下载统计
show_download_stats() {
local download_path="$1"
local model_name="$2"
log_info "下载统计信息:"
echo "=================================="
# 获取模型的真实缓存路径和统计信息
local model_cache_path=""
local model_size=""
local file_count=""
if command -v hf &> /dev/null; then
local cache_scan_output
if cache_scan_output=$(hf cache scan 2>&1); then
if echo "$cache_scan_output" | grep -q "$model_name"; then
local model_info=$(echo "$cache_scan_output" | grep "$model_name")
# 提取本地路径:使用正则表达式匹配以 / 开头的完整路径
model_cache_path=$(echo "$model_info" | grep -o '/[^[:space:]]*models--[^[:space:]]*--[^[:space:]]*')
model_size=$(echo "$model_info" | awk '{print $3}')
file_count=$(echo "$model_info" | awk '{print $4}')
fi
fi
fi
if [[ -n "$model_cache_path" ]]; then
echo "模型缓存路径: $model_cache_path"
echo "模型大小: $model_size"
echo "文件数量: $file_count"
else
echo "模型大小: 无法获取"
echo "文件数量: 无法获取"
log_warning "无法获取模型缓存信息,可能模型下载失败或缓存扫描失败"
fi
echo "=================================="
}
# 主函数
main() {
# 检查参数
if [[ $# -eq 0 ]] || [[ "$1" == "-h" ]] || [[ "$1" == "--help" ]]; then
show_help
exit 0
fi
local model_name="$1"
local download_path="${2:-$DEFAULT_DOWNLOAD_PATH}"
local max_retries="${999:-$DEFAULT_MAX_RETRIES}"
log_info "=== Hugging Face 模型下载脚本 ==="
log_info "模型名称: $model_name"
if [[ -n "$download_path" ]]; then
log_info "下载路径: $download_path"
else
log_info "下载路径: 使用 hf 默认目录"
fi
log_info "最大重试次数: $max_retries"
echo ""
# 开始时间
local start_time=$(date +%s)
# 执行下载流程
if check_dependencies && \
validate_model_name "$model_name" && \
create_download_dir "$download_path" && \
download_model "$model_name" "$max_retries" "$download_path" && \
verify_download "$model_name"; then
# 计算耗时
local end_time=$(date +%s)
local duration=$((end_time - start_time))
local hours=$((duration / 3600))
local minutes=$(((duration % 3600) / 60))
local seconds=$((duration % 60))
log_success "=== 下载完成! ==="
log_info "总耗时: ${hours}小时 ${minutes}分钟 ${seconds}秒"
show_download_stats "$download_path" "$model_name"
# 获取模型的真实下载位置
local model_cache_path=""
if command -v hf &> /dev/null; then
local cache_scan_output
if cache_scan_output=$(hf cache scan 2>&1); then
if echo "$cache_scan_output" | grep -q "$model_name"; then
# 提取本地路径:使用正则表达式匹配以 / 开头的完整路径
model_cache_path=$(echo "$cache_scan_output" | grep "$model_name" | grep -o '/[^[:space:]]*models--[^[:space:]]*--[^[:space:]]*')
fi
fi
fi
if [[ -n "$model_cache_path" ]]; then
log_success "模型已成功下载到: $model_cache_path"
else
log_success "模型已成功下载到 Hugging Face 默认缓存目录"
fi
else
log_error "=== 下载失败 ==="
exit 1
fi
}
# 错误处理
trap 'log_error "脚本执行被中断"; exit 1' INT TERM
# 执行主函数
main "$@"
github上的下载huggingface上的大模型文件的工具
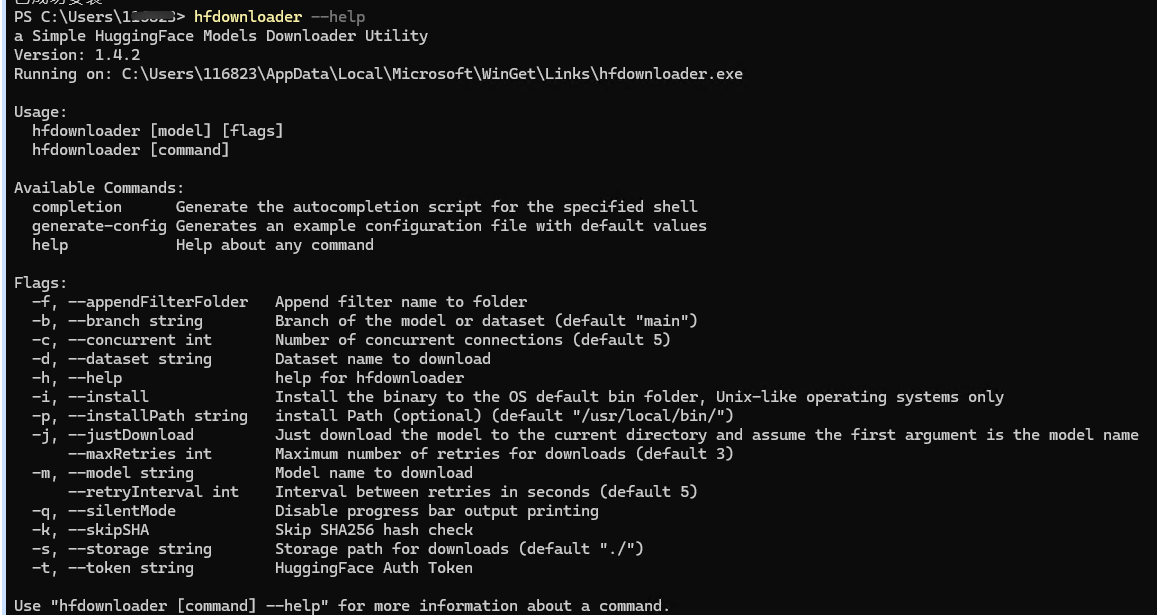
我在github上找到了一个不错的工具,也能下载huggingface上的大模型文件,且支持通过winget安装。
项目网址:Solonce/HFDownloader: HFDownloader - Hugging Face Model Downloader
Windows安装方法
winget install --id bodaay.hfdownloader

命令行参数
如何将下载好的大模型文件复制到另外一台主机上
在用vllm进行分布式推理时,要求各个节点都有完全相同的大模型文件,如果每台主机都单独下载大模型文件,那太费事了,所以我一般是先在一台电脑中下载好大模型文件,然后利用rsync命令拷贝到其它节点上。以下是一个示例:
下面的示例,假定已经在一台主机(10.65.37.233)上下载好了大模型文件,现在利用rsync命令,将下载好的大模型文件复制到另外一台主机(10.65.37.234)上,而且可以很好的保持符号链接。
#下行命令是在已经下载好大模型的主机上执行
#复制速度,取决于局域网的最高速率
rsync -avzh --progress \
/home/ubuntu/.cache/huggingface/hub/models--ByteDance-Seed--UI-TARS-1.5-7B \
ubuntu@10.65.37.234:/home/ubuntu/.cache/huggingface/hub/
关于作者和DreamAI
关注微信公众号“AI发烧友”,获取更多IT开发运维实用工具与技巧,还有很多AI技术文档!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)