如何在赛中完整的呈现数学建模模型
原始数据往往存在噪声、缺失和不一致性,如果不加以处理,会严重影响模型的稳定性与结果的可信度。模型建立与求解是数学建模论文的核心环节,其任务是将问题的实际情境转化为数学结构,并通过合理的求解方法获得可解释的结果。完整的过程包括变量与参数的定义、数学形式的表达、模型的求解以及结果的呈现。机器学习与仿真模型:如神经网络、支持向量机、Agent-based 模拟等,通常以假设函数与损失函数为核心,强调预测
数模的完备性一直是国赛中评审的重点,也是大家赛中最容易失分的点。具体来讲,2023年C题国一使用了ARIMA,很多省三论文也是ARIMA。二者之所以出现这种巨大的等级差异不是因为模型问题,而是后者模型并不完备,缺少很多模型必要元素。
针对国赛数学模型的完备性 创新性录制了四个视频作为课程模型篇的序言课,希望能够对大家赛中有所帮助。


在数学建模中,模型假设是连接实际问题与数学模型的桥梁。恰当的假设能够简化问题、突出核心矛盾,使模型既具备可操作性,又尽量贴近现实。通常模型假设可分为以下几类:
1. 前提假设(基本设定类)
前提假设用于明确研究问题的基本框架,是模型建立的起点。
研究对象:界定问题所针对的主体,例如某个市场、某类人群或某一物理系统。
研究范围:限定分析的空间与时间范围,避免无限扩展。
环境稳定性:假设外部环境在研究期间保持基本不变,为模型提供稳定背景。
2. 简化假设(理想化处理类)
现实问题往往复杂难解,必须通过合理的简化来保证模型的可解性。
忽略次要因素:将对结果影响较小的因素排除在外。
理想化处理:对复杂过程进行抽象,例如假设市场完全竞争、忽略摩擦力等。
3. 参数假设(数值设定类)
很多情况下,部分参数或常数难以直接获得,需要人为设定。
参数取值方式:通过经验数据、文献参考或合理推断确定数值。
常数设定:对研究中需要固定的量(如利率、温度)进行假定。
4. 变量关系假设(结构性假设)
模型的核心在于变量之间的关系,而关系本身也需要假设支撑。
线性/非线性关系:变量间是否存在线性相关性。
因果作用:明确哪些变量是自变量,哪些是因变量。
交互效应:假设变量之间是否存在联动或耦合效应。
5. 动态/静态假设(时间性假设)
时间维度的处理方式决定了模型的适用场景。
静态假设:研究对象在某一时刻或较短周期内的特征,不考虑时间演化。
动态假设:考虑系统随时间变化的过程,刻画长期趋势或演化规律。
6. 确定性/随机性假设
对输入与结果的确定性进行说明。
确定性模型:所有输入参数与系统结果固定不变,重复实验条件下结果一致。
随机性模型:引入随机变量,假设其服从特定概率分布,更贴近现实中的不确定性。
7. 边界条件与环境假设
边界与环境是系统运行的重要前提。
边界固定:如管道流体不泄漏、区域范围不变。
环境恒定:假设温度、市场条件或政策环境保持稳定。
系统开放/封闭:说明模型是否考虑外部输入或输出。
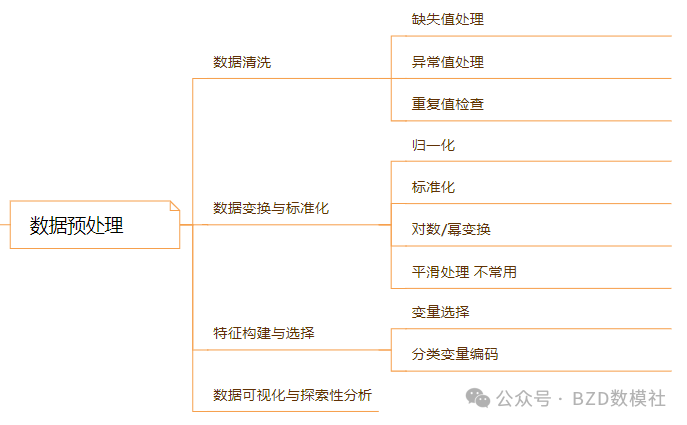
数据预处理
在数学建模与数据分析过程中,数据预处理是保证模型有效性和可靠性的关键步骤。原始数据往往存在噪声、缺失和不一致性,如果不加以处理,会严重影响模型的稳定性与结果的可信度。常见的数据预处理工作包括以下几个方面:
1. 数据清洗
数据清洗旨在提高数据的质量和完整性,使其能够更好地支持后续建模。
缺失值处理:对缺失数据进行合理填补,例如删除缺失比例过大的样本,或采用均值、插值、回归等方法进行估算。
异常值处理:识别并剔除不合理的极端值,或通过箱型图、Z-Score 等方法进行判断,必要时可用合理值替代。
重复值检查:检查并删除重复记录,避免样本权重被无意放大。
2. 数据变换与标准化
为了保证模型的稳定性和变量间的可比性,需要对数据进行数值变换。
归一化:将不同量纲的数据缩放到统一区间(如 [0,1]),适用于神经网络等对数值范围敏感的模型。
标准化:将变量转换为均值为 0、方差为 1 的分布,消除不同变量尺度差异的影响。
对数/幂变换:在数据分布偏态或存在较大波动时,对变量进行对数或幂次变换,使其更符合正态分布假设。
平滑处理(较少使用):通过移动平均、加权平均等方式,削弱数据中的随机波动。
3. 特征构建与选择
合理的特征工程能显著提升模型的解释力与预测性能。
变量选择:筛选与目标变量高度相关的特征,剔除冗余或无关变量,以减少维度灾难。
分类变量编码:将定性变量转换为数值型变量,例如独热编码(One-hot Encoding)或序数编码(Ordinal Encoding),以便模型能够识别与利用。
4. 数据可视化与探索性分析
在正式建模前,应通过数据可视化与探索性分析(Exploratory Data Analysis, EDA)对数据分布、变量关系进行初步理解。
使用直方图、散点图、箱线图等方法,直观展示变量的分布特征与相互关系。
结合相关系数或热力图,分析变量之间的线性或非线性相关性。
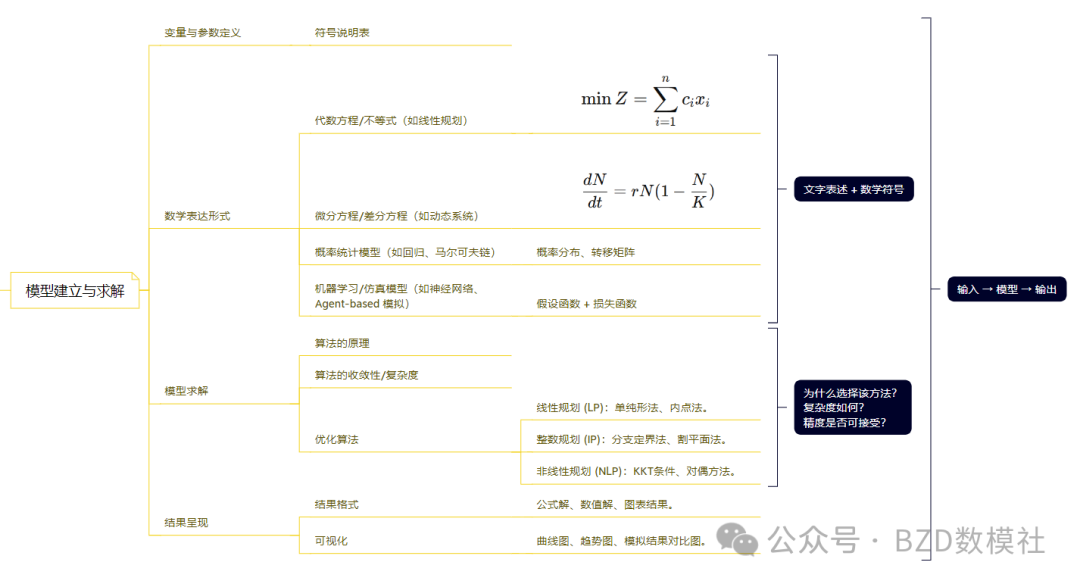
模型建立与求解
模型建立与求解是数学建模论文的核心环节,其任务是将问题的实际情境转化为数学结构,并通过合理的求解方法获得可解释的结果。完整的过程包括变量与参数的定义、数学形式的表达、模型的求解以及结果的呈现。
1. 变量与参数定义
在模型构建之前,必须对问题中的各类量进行严格定义。
符号说明表:统一说明自变量、因变量、参数和常数的符号含义及单位,保证模型的可读性与规范性。
明确角色区分:区分可控变量、状态变量与外部干扰量,为后续方程构建提供清晰框架。
2. 数学表达形式
不同类型的问题需要采用不同的数学工具加以描述。常见形式包括:
代数方程与不等式:用于表示线性或非线性规划问题,如资源分配、路径优化等。
微分方程与差分方程:适用于动态系统或时间演化过程,能够刻画系统状态随时间的变化规律。
概率统计模型:如回归模型、马尔可夫链等,能够刻画不确定性过程,包括概率分布设定和转移矩阵构建。
机器学习与仿真模型:如神经网络、支持向量机、Agent-based 模拟等,通常以假设函数与损失函数为核心,强调预测能力与复杂系统仿真。
结果分析
1. 合理性检验
首先,需要检验模型解是否符合基本的现实常识与逻辑。例如,预测的人口规模应为正数且随时间变化趋势合理,规划模型的资源分配结果不能超过总供给。通过与直觉和常理的对照,可以初步判断模型结果是否可信。
2. 数据验证
数据验证是衡量模型有效性的重要手段。具体做法是将模型结果与实验数据或历史数据进行对比,检验其精度与适用性。如果模型预测与真实数据高度吻合,则说明其可靠性较高;若差异较大,则需要反思假设合理性或模型结构是否需要调整。
3. 敏感性分析
为了进一步检验模型的稳健性,需要研究不同参数取值对结果的影响。通过对关键参数进行扰动并观察结果变化,可以揭示模型对输入的敏感程度。例如,若轻微的参数变化导致结果剧烈波动,说明模型存在不稳定性;反之,结果变化平缓则表明模型具有较好的稳健性。
4. 鲁棒性检验(可选)
在部分研究中,还需考察模型在不同环境或场景下的适用性,即鲁棒性。例如,预测模型在不同数据集、不同初始条件下是否仍能保持较高的精度。这一分析虽在常规赛题中使用较少,但若能体现,将显著增强模型的学术价值与推广价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)