2025年“LLM== 编译器”:Megakernel(vLLM / TensorRT-LLM / TVM-Relax / IREE / StableHLO / MoE / CUDA·Triton)
过去两周,几条系统层面的更新把“编译正在重塑大模型”的趋势按下了快进键:PyTorch 2.8官方上线了原生的高性能量化 LLM 推理,直接把 x86/Intel 平台上的低比特推理做成“开箱即用”的能力;这意味着在不换硬件的前提下,许多企业现有 CPU 集群也能吃到成本红利。
引子
过去两周,几条系统层面的更新把“编译正在重塑大模型”的趋势按下了快进键:PyTorch 2.8 PyTorch 官方上线了原生的高性能量化 LLM 推理,直接把 x86/Intel 平台上的低比特推理做成“开箱即用”的能力;这意味着在不换硬件的前提下,许多企业现有 CPU 集群也能吃到成本红利。

PyTorch 2.8
同期 TensorRT-LLM 的 0.21.0 版继续快节奏迭代,针对主流 LLM 的图优化、KV-Cache、MoE、量化与新驱动栈做了整包升级,标注“Last updated: Aug 19, 2025”,释放出明确信号:编译栈正在与新硬件/新算子保持周更级联动NVIDIA。

TensorRT-LLM
另一方面,vLLM 一边发布 v0.10.1(700+ 次提交、200+ 贡献者),一边公开 1.0 的工作计划与里程碑,围绕可插拔调度、KV 管理与多后端接口进行“架构级”打磨,指向更通用的推理编译平台GitHub。甚至连硬件厂商也开始把“编译-优先”的思想打包成产品化工具:Intel LLM-Scaler 1.0 与随后发布的 Beta 更新(LLM-Scaler 1.0 As Part Of Project Battlematrix,如下图),主打多 GPU 扩展与 PCIe P2P、容器化一键部署,把“把模型编译到最会跑的形态”变成工程默认路径Phoronix。

LLM-Scaler 1.0 As Part Of Project Battlematrix
把这些新闻放在一起看,会发现它们折叠成同一条主线:一端是让编译器“学会懂模型”,通过图编译、内核融合(甚至 Megakernel)、动态形状与低比特量化,把 LLM 推理/训练的每一毫秒都抠出来;另一端则是让模型“学会做编译”,用大模型去提出优化决策、自动写 CUDA/Triton 内核,甚至在真实硬件回路里做强化学习式的性能闭环。
为什么现在会呈现这两种趋势呢?
概况而言,大语言模型(Large Language Model, LLM)近年来取得了突破性的进展。然而,LLM的训练和推理对计算资源需求极高,在模型规模不断扩大的背景下,如何通过编译技术更高效地利用硬件、降低延迟和成本,成为学术界和工业界共同关注的问题。一方面,研究者尝试利用LLM强大的知识和推理能力来改进传统编译器的优化过程(“LLM-for-Compiler”),通过LLM辅助搜索庞大的优化空间、自动生成高效代码,以及将强化学习等方法融入编译优化,实现以数据驱动方式超越人类手工规则的编译优化效果。另一方面,为训练和推理服务设计高效的编译系统(“Compiler-for-LLM”)也成为关键课题,包括针对动态计算图的编译、统一的中间表示(如Relax IR、StableHLO等)、跨算子融合生成大型内核(如单一MegaKernel)、模型量化加速、混合专家(MoE)模型的优化、针对新型硬件的部署适配,以及Flash系列高效算子内核的应用等等。本文分析2025年以来LLM与编译技术结合的最新研究进展,涵盖上述两个主要方向的核心思想和代表性成果,并对不同方法进行分析对比,最后展望未来的发展趋势。
LLM赋能编译优化(LLM-for-Compiler)
LLM作为拥有海量代码语料和强大推理能力的模型,被寄予厚望用于提升编译器的智能化水平。传统编译器的优化,例如编译优化选项搜索、循环展开和向量化等,往往依赖人为设计的启发式规则或代价模型,难以充分探索庞大的优化空间。而LLM有望通过数据驱动的方式,自动探索和发现高效优化策略。本节按研究范式将LLM用于编译优化的进展分为三类:(1)LLM引导的优化搜索与决策,利用LLM的上下文推理能力辅助探索复杂的编译优化空间;(2)LLM结合强化学习优化编译,通过训练或微调让LLM自行学会提升代码性能;(3)LLM自动生成高效代码,直接让LLM产出高性能的目标代码或优化补丁,包括针对GPU等特殊硬件的代码生成,以及面向编译优化任务专门训练的基础模型。
LLM引导的优化搜索与序贯决策
由于深度学习模型的计算图包含大量算子和可能的变换,编译器面临指数级庞大的优化空间。例如,针对一个神经网络层,编译器需要决定诸如算子融合、循环拆分/合并、存储布局和并行化等众多变换组合。传统方法(如启发式算法或演化搜索)虽然可以找到有效配置,但往往采样效率低下,需要尝试大量冗余或无效方案。为此,Tang等人提出利用LLM的上下文推理能力指导编译优化搜索,开发了“Reasoning Compiler”编译框架(如下图所示,arxiv)。
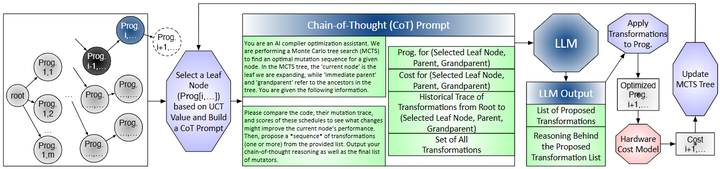
Optimization workflow in REASONING COMPILER
该方法将编译优化视为决策过程,在每一步由LLM根据当前程序状态和过往优化历史提出候选优化变换(如融合特定算子、调整内存布局等),LLM的建议具有硬件相关性和上下文相关性。然后通过蒙特卡洛树搜索(MCTS)评价并选择这些变换,平衡探索新方案和利用已有高性能方案之间的关系(如下图)。
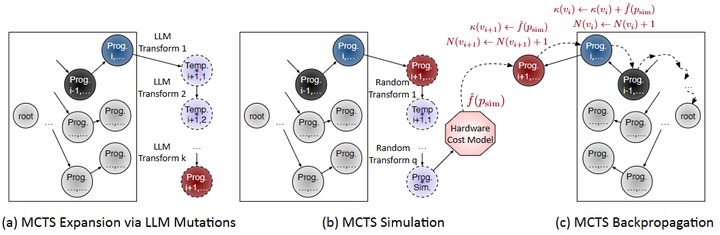
Structured tree search
实验结果显示,该LLM引导的编译器在样本效率上显著优于传统黑盒自动调优:在只尝试36个程序样本的情况下取得了对未优化代码最高2.5×的加速,比进化算法等方法减少了一个数量级的采样。这一研究证明,不经额外训练的LLM通过提供链式思考的上下文建议,结合MCTS等搜索策略,即可显著提升神经网络编译优化的效率和效果。
除了将LLM与决策树搜索结合,另一些工作探索将LLM融入编译器的变换调度和搜索框架。Hong等人提出的“Autocomp”系统以LLM为核心引擎来优化张量加速器(如TPU等)的代码arxiv。Autocomp将每个优化pass分解为“规划”与“生成”两个阶段,以两段式提示引导LLM工作(如下图):首先LLM根据提供的“优化菜单”选择下一步优化策略(如Loop Tiling、算子融合等),然后生成应用该策略后的代码版本。
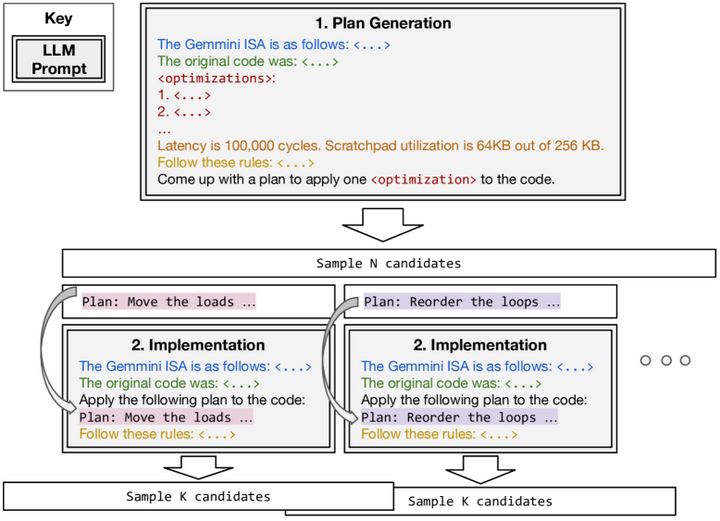
Autocomp’s two-phase optimization
整个过程迭代进行,在每轮生成后将真实硬件的性能反馈(运行时间等)返回给LLM,用于指导后续步骤,从而形成一个闭环的优化搜索(如下图)。这种方法无需额外训练LLM,而是依赖LLM对常见优化模式的先验知识和上下文推理来探索优化空间。
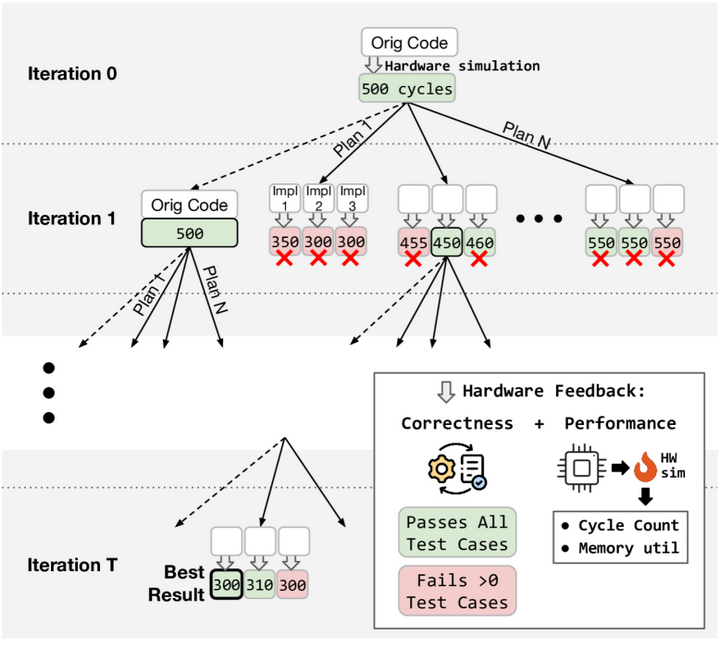
Autocomp’s beam search(Iteration)
Autocomp在两个定制加速器上的评估显示:经该框架优化后,矩阵乘法(GEMM)代码比厂商库实现快5.6倍,卷积代码快2.7倍,均超越专家手写的优化代码。类似地,Acharya等人提出的“AutoPatch”框架通过Retrieval-Augmented Generation(检索增强生成)提升LLM优化代码的能力ar5iv。AutoPatch首先从历史代码库中检索结构类似的“未优化-已优化”代码对及其控制流图差异,将这些作为提示供LLM参考。
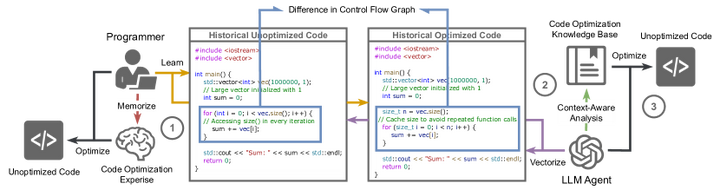
AutoPatch Workflow
LLM据此生成优化补丁代码并输出改进后的版本。该方法在IBM CodeNet数据集上使生成代码的运行效率平均提升7.3%,优于直接让GPT-4输出的结果。这一结果说明,引入历史优化案例和程序结构分析,能帮助LLM更深入地理解性能瓶颈并生成更高效的代码。
总的来看,以LLM为指导的编译优化探索呈现出“LLM提案 + 搜索验证”的范式:LLM利用其对代码和优化模式的语义理解给出启发性的优化建议,然后由搜索算法或实际硬件反馈加以筛选和验证。这种范式提升了优化空间探索的智能性和高效性,在编译优化决策中引入了“经验驱动”的成分,弥补了传统启发式和随机搜索的不足。
LLM结合强化学习提升编译优化
虽然只依靠提示的LLM已展现出不俗能力,但进一步的研究发现,通过强化学习(RL)或专门微调,LLM可以成为更强大的代码优化器。Wei等人针对汇编代码优化任务,引入了深度强化学习框架训练LLM直接输出高性能汇编arxiv。他们首先构建了包含8,000多个真实程序的基准,其中每个程序都有若干对应的GCC -O3编译产生的汇编码。然后使用Proximal Policy Optimization (PPO)算法对一款开源代码模型(Qwen2.5-Coder-7B)进行微调,将执行性能提升作为奖励信号。训练后模型在未见过的测试程序上取得了平均1.47×的速度提升,显著超越GCC -O3,也超过了包括Claude和GPT-4在内的20个对比模型。这一研究表明,通过强化学习可以“解锁”LLM在代码优化上的潜力,让其真正起到类似编译器优化器的作用(参考下图)。
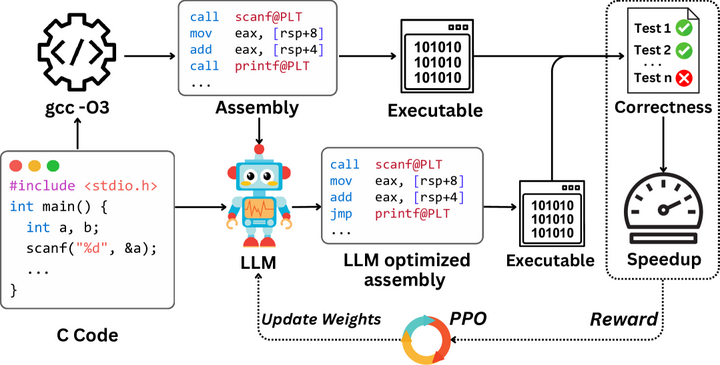
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
与此思路类似,Li等人提出了“CUDA-L1”框架,用对比强化学习训练LLM来优化CUDA GPU内核代码arxiv。他们关注GPU代码优化的特殊挑战:不同优化手段(如存储访存优化、线程调度优化等)常具有乘法式叠加效果,必须组合应用才能发挥最大性能。CUDA-L1通过一种新颖的对比学习策略,让LLM在训练中反复尝试不同的优化组合,并根据相对性能差异来调整策略。
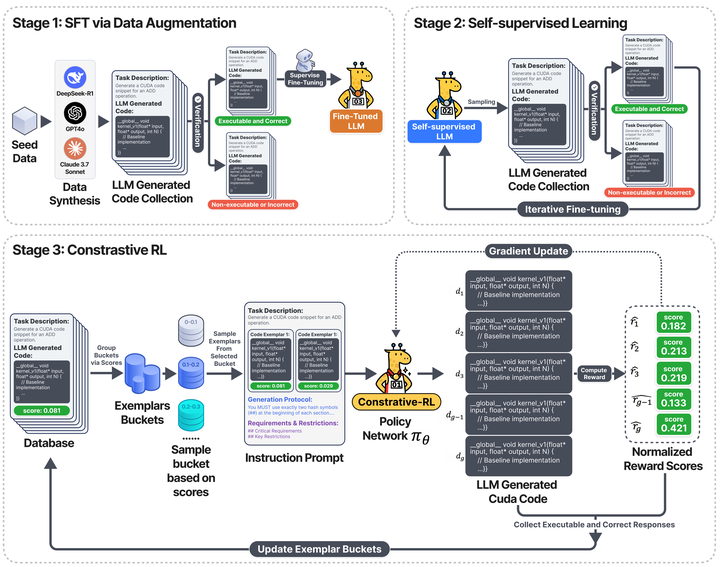
CUDA-L1 training pipeline
实验显示,经过训练的模型在KernelBench基准的250个CUDA内核上平均加速3.12倍,峰值提速高达120×,中值提速1.42×。此外,CUDA-L1在跨架构上具有一定泛化性:用A100 GPU训练的模型在V100等其他GPU上仍获得显著加速。相较于无需训练的提示方法,RL微调需要大量交互采样,但其显著收益证明了训练开销的价值。未来,这类方法有望与硬件厂商的高性能库结合,实现自动化的CUDA代码优化。
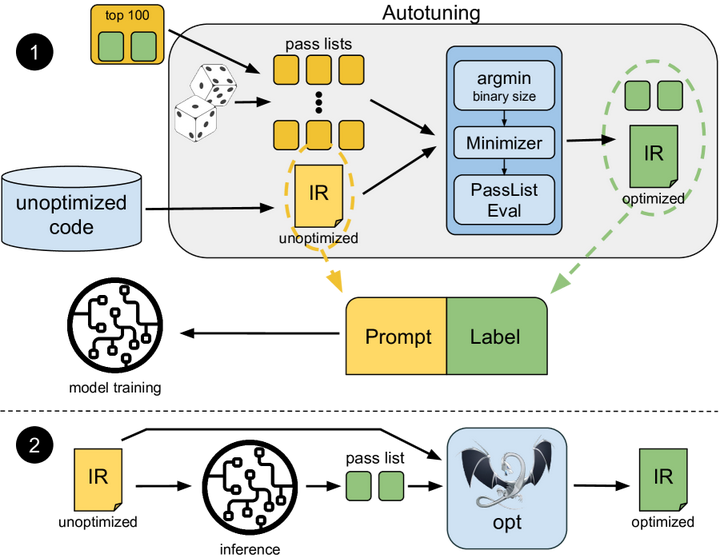
除了训练LLM本身成为优化器,也有工作探索结合RL思路但避免大规模微调。例如,Meta AI研究团队在编译优化次序推荐任务上,引入了优先级采样(Priority Sampling)方法arXiv。他们开发了一个基于CodeLlama的模型,学习优化LLVM编译选项序列。当需要模型生成多个优化方案时,优先级采样算法总是选择模型最确信且尚未生成过的扩展路径,确保每次输出独一无二且高质量的优化序列(如下图)。这种策略相当于在生成过程融入搜索,避免了传统随机采样产生重复或无效方案的问题。实验表明,仅生成5个方案就可达到原自动调优器(演化算法)91%的优化幅度,生成30个方案时甚至略超过原自动调优器的效果。这一成果说明,不通过梯度训练也可以借助算法增强LLM的优化能力,将RL的思想融入推理过程本身。这在一定程度上折中了解决方案质量与计算开销,为实际编译场景中调用LLM提供了新思路。
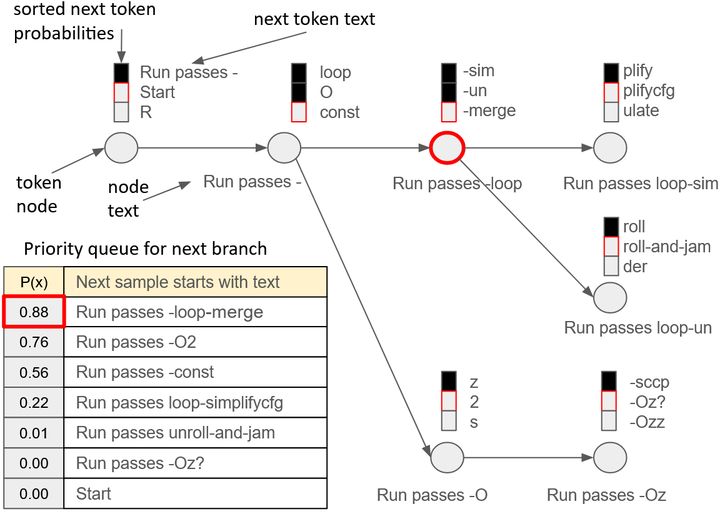
Priority Sampling tree expansion
LLM自动生成与改写高效代码
另一个思路是直接利用LLM的代码生成能力,让模型自行产出优化后的代码片段或完整实现,从而实现对给定程序的性能改进。这方面的研究包括利用LLM生成GPU内核代码、针对源码级别的性能改进建议,以及训练专门面向代码优化任务的LLM基础模型。相比前两节,这类方法往往更加侧重生成式能力的发挥,以及如何保证生成代码的正确性和有效性。
在GPU领域,一个引人瞩目的进展是利用LLM生成高性能CUDA或Triton代码。过去编写高效GPU内核需要专家知识,而现在LLM有可能胜任这一任务。比如,有开发者尝试使用GPT-4自动生成矩阵乘法的Triton实现并进行优化,取得接近CuBLAS的性能。这启发了研究者设计框架结合LLM和人类反馈生成GPU代码。Autocomp前文已经展示了LLM可以通过规划-生成循环自动产出加速器代码arxiv。另一方向是直接面向源代码的优化建议。Zhang等人在ACL 2025提出“BITE”范式,将LLM用于代码加速(Code Acceleration, CA)任务acl。他们的方法通过双向树编辑逐步生成代码的高效版本和低效版本,作为训练数据,使模型学习逐级代码优化模式(如下图)。这种逐步学习策略使LLM更好地掌握代码优化的层次关系。这说明,通过专门设计的数据生成和训练流程,中等规模的开源LLM也能具备一定自动加速代码的能力,与更大的闭源模型竞争。
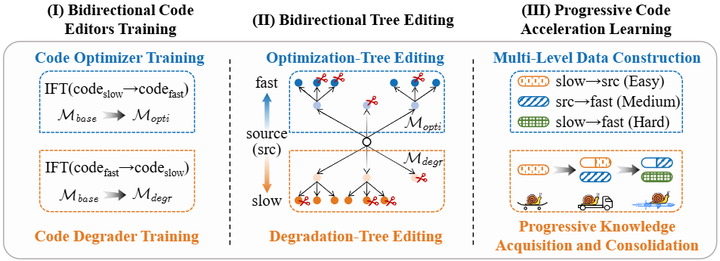
BITE
为了让LLM更专业地服务编译优化,一些工作干脆从预训练阶段就融入编译领域知识。代表性成果是Meta AI提出的“LLM Compiler”思路(如下图,arxiv)。Cummins等人认为通用大模型在编译优化上仍属“泛才”,遂构建了一个在海量编译器IR和汇编数据上预训练的专用模型系列,称为“编译器的大型语言模型”。
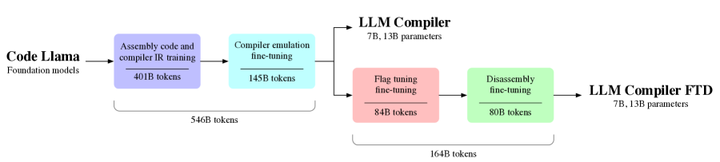
LLM Compiler
具体来说,他们以CodeLlama为基础,在LLVM中间表示(IR)和各种体系结构的汇编代码上继续训练LLM,共计摄入高达5460亿标记的编译器相关语料,并辅以指令微调使模型学会模拟编译器的行为。训练所得模型(7B和13B参数两个版本)被证明掌握了一定的编译优化能力(训练过程如下图所示)。
Compiler training
例如,在优化代码尺寸(根据-Oz选项调整编译参数)任务上,LLM Compiler微调模型达到了传统自动调优77%的优化潜力,却不需要额外编译尝试就能给出优化建议。又如,在将x86和ARM汇编反编译回LLVM IR的任务中,该模型有14%的结果完全正确,实现了以往方法无法达到的双向转换。Meta的这一工作为学术界提供了首批大规模专用代码优化模型,其训练范式表明:通过在模型中内嵌大规模的编译知识,LLM可以成为编译器强有力的“助手”甚至“替代”,为自动性能优化开辟新道路。
然而,让LLM自动生成代码用于实际编译还必须解决正确性和约束问题。生成的代码若不等价于原始实现或不满足硬件约束,将适得其反。因此,多数研究在生成过程中加入了验证或约束机制。例如,上述VecTrans系统在用LLM重构代码以利于自动向量化时,集成了IR级别的等价性验证确保语义不变ar5iv。
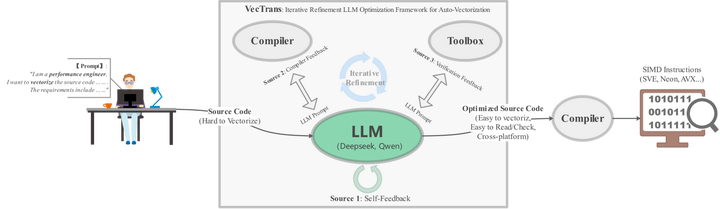
VecTrans
再比如Priority Sampling方法在生成优化序列时用正则表达式约束输出格式,AutoPatch在LLM输出补丁前后进行了测试验证。这些措施保证了LLM产生的代码或优化方案切实可用。未来,随着编译领域知识融入LLM、代码语义约束生成技术的成熟,我们有望看到LLM自动生成高效代码在更多场景落地,从高性能库内核生成到自动优化遗留代码等,为软件性能优化带来范式转变。
面向LLM模型的编译系统设计(Compiler-for-LLM)
随着LLM在各行业的部署需求激增,为其提供高效的推理和训练支撑成为系统研究的重要方向。传统深度学习框架多针对静态计算图或定长小模型进行优化,而LLM具有动态分支、多样算子、大计算量等特点,现有编译器和加速库难以充分榨取性能。为此,近年出现了一系列面向LLM服务的编译系统和优化技术,包括支持动态计算图的新编译流程、跨层次的中间表示(IR)设计、大规模算子融合以减少调度开销、模型压缩与量化以降低资源占用、适配多硬件的统一编译框架,以及针对Mixture-of-Experts这类稀疏大模型和高效Attention内核的特殊优化等。本节将按照技术模块进行介绍。
动态计算图编译与统一中间表示
动态Shape和动态控制流是LLM模型与传统模型的重要区别之一。以Transformer为基础的LLM在推理时,其输入序列长度和分支执行情况可能各不相同,且一些模型包含条件执行、循环等动态控制结构。这对编译器提出了挑战:传统静态优化假定定长shape和确定的计算图,对于LLM的动态行为往往处理不佳,可能退化为运行时解释执行,从而损失性能。为解决这一问题,新一代编译框架开始引入针对动态模型的优化支持。代表性成果是由陈天奇团队开发的Relax IR arxiv。Relax是TVM社区提出的端到端动态计算图优化IR,打通了图层(高层计算图)、张量算子层(TensorIR)和外部库调用等不同层级的表示,用单一IR刻画模型的完整执行(如下图)。

Relax IR
与早期TVM的Relay IR相比,Relax引入了的符号Shape概念,用类型系统在编译期跟踪张量维度的不确定性,同时允许在运行时再确定具体shape。通过这种设计,Relax编译器可以在需要时推迟形状相关优化,又能跨算子全局优化动态模型。例如,Relax实现了动态Shape感知的算子融合(如下图)、内存规划和CUDA Graph等跨层优化,使即便输入长度变化,编译器仍可预先分配好内存并复用计算序列,提高性能。

Dynamic shape–aware operator fusion case study
实验证明,在LLM等动态模型上,Relax优化后性能与静态模型的最先进系统相当,且首次实现了将这些模型部署到手机、嵌入式和浏览器等更多环境中。Relax IR已随TVM Unity项目开源,并成为Apache TVM 0.20.0版本中的重要特性。可以预见,随着Relax等IR的成熟,动态计算图的编译优化将更广泛应用于LLM服务中。
与动态Shape支持相辅相成的是统一的中间表示规范,以方便不同前端框架和后端硬件的对接。其中一个重要项目是开源社区主导的OpenXLA StableHLO ,openxla。
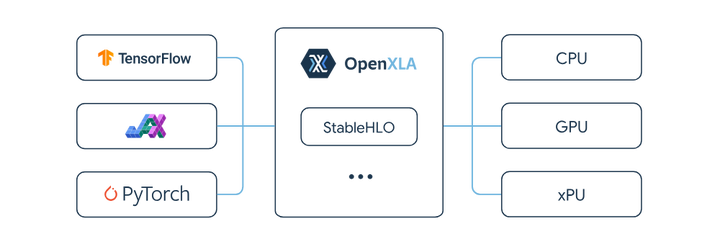
StableHLO
StableHLO定义了一套稳定的高级算子集,覆盖Transformer等模型常用的算子(Attention、LayerNorm等),作为XLA HLO的统一子集标准。各框架(TensorFlow, JAX, PyTorch等)可以将模型转换到StableHLO,再由后端编译器(如IREE、TensorRT、OpenXLA编译器等)接管实现优化和生成 openxla.org(参考下图)。它的意义在于提供可移植、高兼容的IR接口:模型只需转换一次,即可面向多种硬件进行编译,无需为每种平台重复开发优化。
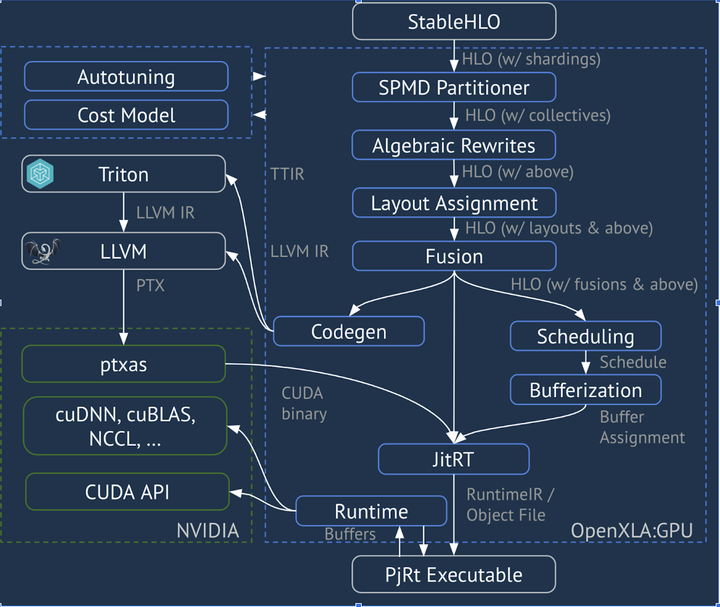
XLA:GPU Pipeline
特别地,LLM涉及的许多自定义Kernel(如FlashAttention等)可以在StableHLO层封装为组合算子,底层由降级实现或调用供应商库,从而统一表示上层逻辑。随着2023-2024年StableHLO正式发布1.0版本并进入OpenXLA项目,该IR正被业界广泛采用。例如PyTorch 2.x的XLA后端以及谷歌的新编译器都已支持StableHLO作为输入格式。这股趋势表明,编译IR正在朝标准化演进,类似传统编译领域的LLVM IR一样,深度学习编译领域也希望建立通用IR来打通生态。这将有助于LLM的模型部署:开发者训练好模型后,抛给编译栈,就能在不同设备上高效运行。
除了IR层面的革新,动态图编译在框架层面也取得重要进展。以PyTorch 2.0为代表,动态图框架开始内置JIT编译器(TorchDynamo+TorchInductor),对Python模型进行捕获和优化,将其动态图转换为静态子图并编译medium。对于LLM这种长序列重复结构,TorchDynamo能够捕获循环模式,并通过TorchInductor生成Fusion内核和调用高性能库,从而获得不俗的加速(参考下图,pytorch)。
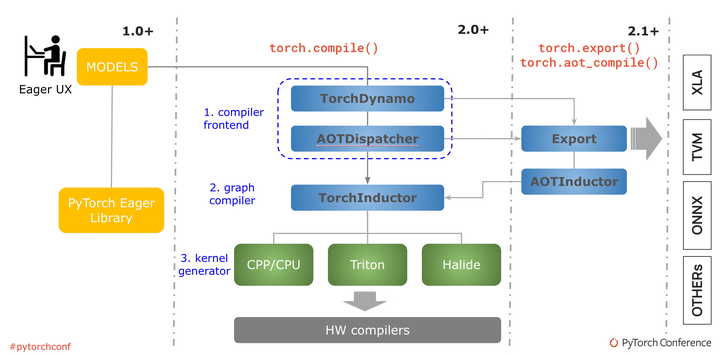
The PyTorch compilation process
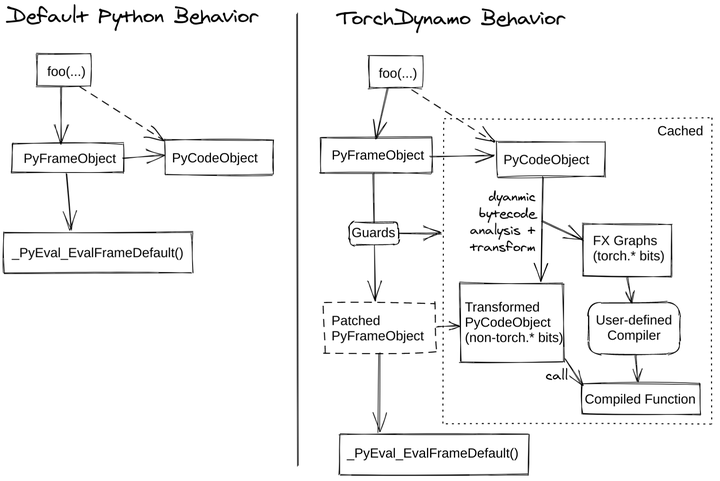
TorchDynamo
另一边,JAX/XLA等原生静态图框架在引入PartiQL/条件执行后也能一定程度支持动态行为。总体而言,“静态编译加速动态模型”成为共识:通过新的IR和编译策略,把LLM这类动态模型用接近静态的方式优化执行,既保留灵活性又获得性能提升。这为LLM大规模部署奠定了基础。
大算子融合与单核执行优化
在LLM推理中,一个突出的问题是算子调用碎片化导致的性能低效。传统的深度学习推理往往逐层调用内核,每层计算完再进入下一层。这种方式在LLM上会造成大量的GPU kernel launch开销和设备间同步等待medium。尤其是LLM具有上百层Transformer块,每层包括矩阵乘、Attention、归一化等多个算子,如果逐个launch,GPU往往处于饥饿或频繁切换状态,不能充分利用算力。为此,研究者提出了内核融合(Kernel Fusion)在LLM中的极致形态:将整个模型(或大的子图)尽可能融合成单个巨型内核(MegaKernel),一次性完成推理计算。
Mirage项目的“Persistent Kernel (MPK)”是这方面的代表工作github。MPK通过编译器将LLM多个层、多次迭代甚至多卡通信融合进一个CUDA内核中执行。这样做带来三大好处:首先完全消除kernel启动开销,哪怕多GPU场景下也只启动一次内核;其次实现跨层的软件流水,当前层计算的同时可以预取下一层数据;最后还能重叠计算与通信,例如在单个内核中一边计算一边进行GPU间的all-reduce,从而隐藏通信延迟。通过这种端到端融合,LLM单卡解码延迟已逼近理论极限(在39-token输入、生成512-token的实验中,MPK将单卡A100每token延迟从14.5ms降至12.5ms,接近理论下限10ms)。此项研究充分展示了极限融合对于降低LLM推理延迟的巨大价值。为了实现MegaKernel,MPK要求模型计算图满足一定条件(例如统一的序列并行度),通过编译分析提取出可用子图并注入特定的调度代码(如下图)。
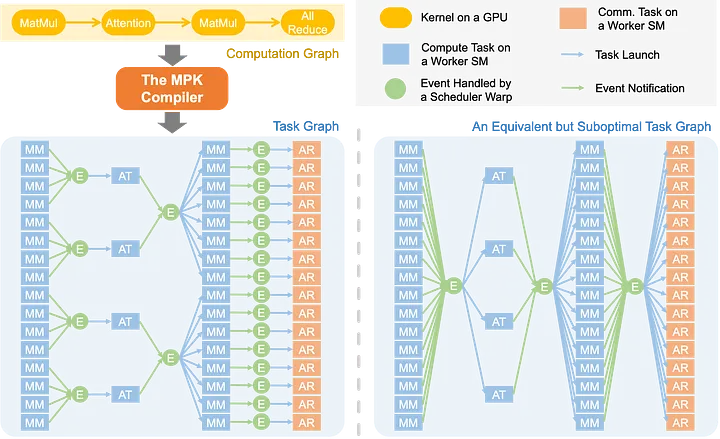
The MPK compiler transforms an LLM’s computation graph (defined in PyTorch) into an optimized, fine-grained task graph that exposes maximum parallelism
除了全模型融合,局部的算子融合和高效内核在LLM加速中也发挥关键作用。其中最著名的是FlashAttention系列。FlashAttention最初由Dao等人在2022年提出,通过重新排列Attention计算与内存访问顺序,实现O(N)的块状计算,极大降低了显存访问和占用。FlashAttention及其改进版本(FlashAttention-2等)已成为LLM模型中的标准配置,在长序列处理上比传统实现快数倍,显存节省达50%以上。近期,来自华盛顿大学和Meta的研究者进一步推出FlashInfer arxiv——一个面向LLM推理的高效可定制Attention内核引擎。FlashInfer引入块稀疏的KV缓存表示来优化内存访问,并提供模板化的Attention内核生成,使其能通过JIT快速适配不同模型配置(例如不同head数量、维度等)。
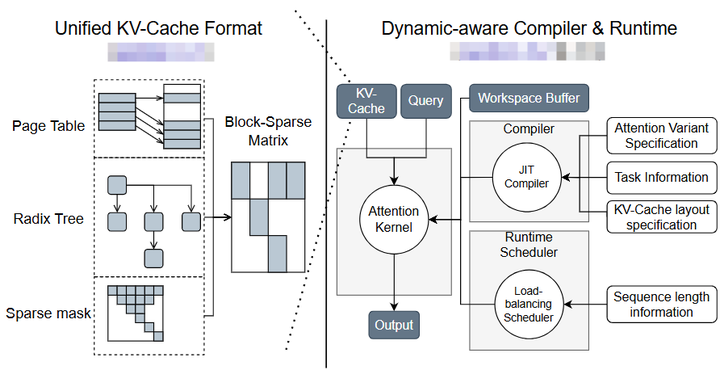
FlashInfer
同时,它设计了负载均衡的调度算法以适应并发用户请求,并兼容NVIDIA的CUDA Graph机制以降低运行时开销。FlashInfer已经集成到SGLang、vLLM、MLC等主流LLM服务框架中,作为其Attention核心实现。基于基准测试,FlashInfer相比现有最好方案,实现了29%~69%的跨token延迟降低(在不同模型和批量下),长上下文情况下延迟降低28%~30%,开启并行生成时吞吐提升13%~17%。这些成果背后的理念是一致的:通过编译和代码生成,充分挖掘算子级优化,包括访存重排、算子融合、精度降级(如FP8)等,以定制内核替换通用实现,从而针对LLM的模式取得最优性能。如今的LLM编译系统往往内置大量特定优化内核(如Flash系列Attention、Fused Feedforward等),并在编译时根据模型配置选择最佳内核或自动生成内核medium。未来随着模型架构的演进(如出现新的Attention变体或其它瓶颈算子),编译器将继续扮演高效内核提供者的角色,快速跟进研究进展,将最新的算子优化融入部署管线。
模型压缩与量化优化
LLM模型的参数规模巨大,显存占用和计算量随之飙升。模型量化(Quantization)技术通过以更低比特宽度表示模型权重和激活,可以大幅减少内存和算力需求,是加速LLM的常用手段之一。目前业界已经成功将INT8甚至INT4量化应用于LLM推理,在较小精度损失下实现数倍的效率提升。例如,GPTQ针对LLM的权重矩阵进行逐层4比特离线量化,在GPT-3等模型上几乎不损失准确率就将模型大小减至原来的1/4(arxiv); 又如SmoothQuant通过缩放处理消除了激活值中的outlier峰值(如下图,arxiv),实现了对权重和激活同时量化到8比特,推理加速明显。
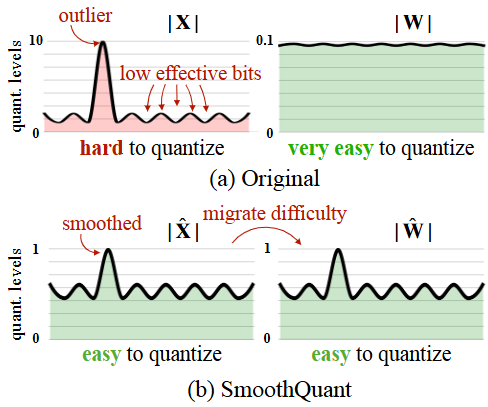
SmoothQuant
编译器在量化加速中扮演了两个角色:首先,将量化算法整合到模型转换流程中,提供自动化的量化支持;其次,输出针对低精度运算优化的代码或调用底层低精度内核。Apache TVM、TensorRT、PyTorch等都提供量化感知训练(QAT)或后量化(PTQ)工具,能将训练后或现有的LLM模型量化为INT8/INT4并校正偏差。NVIDIA的Transformer Engine在A100/H100 GPU上提供FP8矩阵乘的高效Kernel,配合FP8量化可使Transformer推理再提速20%以上(如下图,Nvidia)。
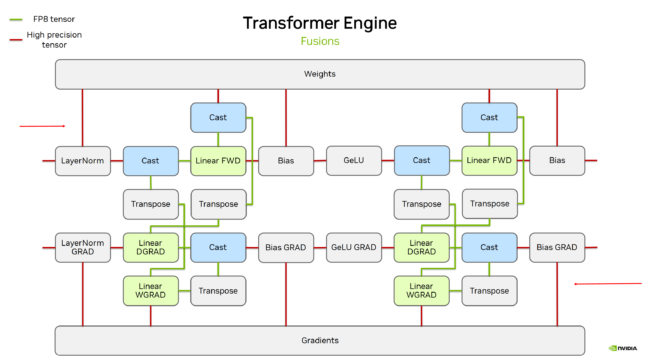
The complete process of FP8 training in Transformer Engine
编译系统需要灵活调度这些Kernel,例如按配置选用FP16还是FP8。近期研究也在探索更低比特(如2比特、1比特)的极限量化以及训练过程中融入量化。Liu等人在2025年提出了ParetoQ框架,统一评估了1、2、3、4比特量化下LLM的性能-精度折衷,发现相比4比特,2~3比特在某些场景更具优势,并通过改进量化算法和训练策略,使2比特模型在相近精度下获得额外的内存和速度优势(如下图,arxiv)。
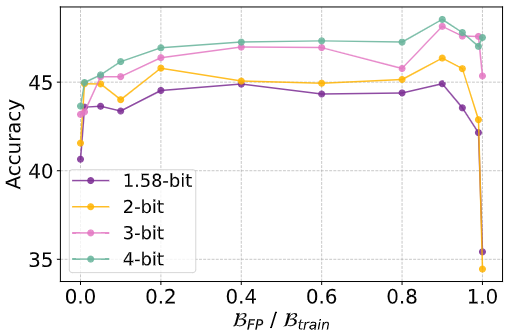
With a fixed total training budget of 100B tokens (Btrain),where BFP + BQAT = Btrain,explore optimal allocation between full-precision pretraining (BFP) and QAT fine-tuning (BQAT). “0.0”represents QAT from scratch, while “1.0” indicates full-precision pretraining
另一些方法则提出学习式量化,如QRazor将权重先量化到8比特保留精度,再通过显著数据剔除(SDR)直接截断为4比特存储,从而无需复杂重新训练就达到SOTA精度arxiv。QRazor甚至设计了配套的整数运算单元,使SDR格式的数据可在硬件上直接计算,无需还原,大幅提升了执行效率。
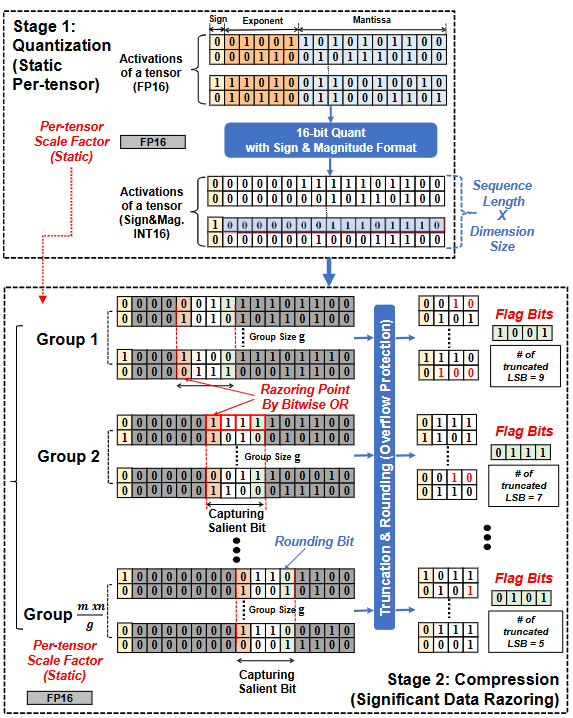
QRazor
这些创新显示,在LLM量化领域仍有潜力可挖。编译器作为衔接模型和硬件的环节,需要及时支持这些新量化方案。例如,当一种新的量化格式出现时,编译器应能利用其提供的算法(如自定义数值格式any4,如下图 arxiv.org)和硬件指令,实现对应的低精度计算。这方面的一项挑战是保持数值正确性和稳定性。
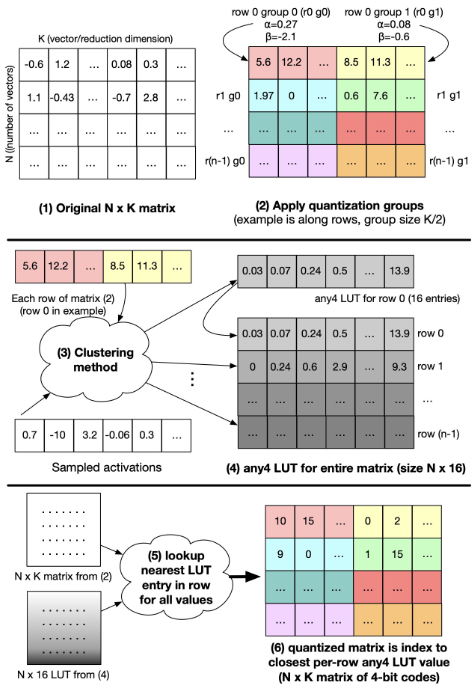
any4 quantization process
量化后模型易出现溢出或下溢,编译器可能需要插入重新标定或分块计算来保证精度,例如在Softmax等敏感算子周围避免过度量化。总之,量化已成为LLM加速不可或缺的一环,编译系统通过集成量化流程和优化低精度计算,使大模型在不显著牺牲效果的前提下瘦身提速,这对在资源受限设备上运行LLM尤为关键arxiv。
除了量化,LLM的剪枝(Pruning)和蒸馏(Distillation)等模型压缩技术同样能降低推理开销,但这些通常需要在模型训练阶段完成,在编译器侧主要体现为对剪枝后的稀疏算子的支持以及小模型的优化,本文限于篇幅这里不展开。
稀疏专家模型(MoE)的编译与调度优化
Mixture-of-Experts(MoE)模型是近年大模型领域的重要方向,通过引入海量“专家”子模型并在推理时稀疏激活部分专家,从而在参数规模巨大的同时控制每次推理开销。但MoE给系统和编译带来了新的挑战:一方面,不同专家通常需要分布式部署在多张设备上,推理时需要在GPU间动态路由token,使通信和同步开销剧增;另一方面,不同专家负载不均衡会导致某些设备比其他设备慢,造成尾部延迟增加。
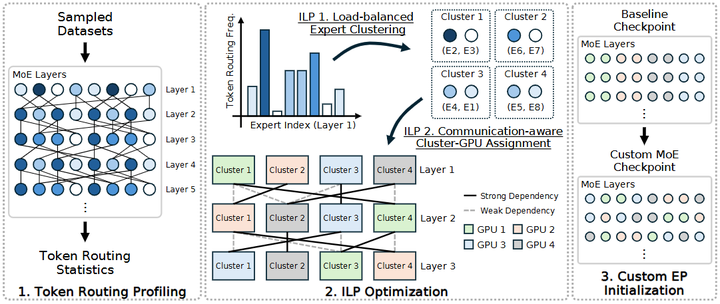
MOETUNER
针对这些问题,编译优化可以从负载均衡和路由高效两个方向入手。Go等提出了“MoETuner”(如上图),通过整数线性规划(ILP)算法优化专家到GPU的放置,以及token到专家的路由方式arxiv。MoETuner利用了这样一个观察:在实际模型中,同一个token往往在相邻层会被路由到相似的专家集合。据此,它在跨层联合考虑专家负载和通信成本,给出一个近似最优的专家映射方案,使每块GPU上处理的token数量尽量均衡,并将需要跨GPU传输的token对尽量安排在邻近设备。实验结果显示,在一个8-GPU单机MoE推理测试中,MoETuner将端到端延迟降低了9.3%,在多机场景下降低17.5%,证明了优化放置和路由对改善性能的价值。同时,一些工作关注减少MoE模型的内存和计算开销。Huang等人提出了Mixture Compressor (MC)框架,通过静态量化和动态裁剪相结合,实现对MoE-LLM的极限压缩arxiv。
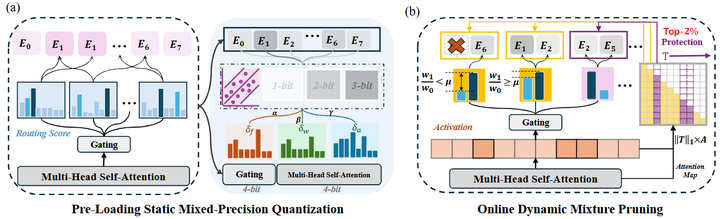
Mixture Compressor (MC)
具体来说,对每个专家权重执行混合精度量化(不同bit宽度分配给不同重要程度的权重)以减小存储和加载开销;推理时则监控每个token的重要性,仅对小部分重要token送入完整专家计算,其余token动态跳过部分专家,从而减少实际激活的参数量。在2.54比特的平均精度下,MC方案将一个MoE模型压缩了76.6%且准确率只下降3.8%,并在推理时进一步减少了15%的专家计算量,仅带来不到0.6%的性能损失。这表明,通过编译时整合量化和推理时裁剪,MoE模型可以大幅削减资源需求,使在有限硬件上部署超大规模专家模型成为可能。
编译器针对MoE的优化,还可以包括稀疏计算图优化(例如通过条件执行只计算被选中的专家)和高效通信实现(如利用组通信或拓扑优化降低all-to-all开销)。现代分布式深度学习编译框架(如Microsoft DeepSpeed、FastMoE等)已经内建针对MoE的执行计划优化,能自动安排通信和并行模式。然而,MoE的极端规模(可能包含数千个专家)对编译器的可扩展性提出了很高要求,如何在编译期快速决定optimal的专家调度仍是挑战。因此,很多系统采用运行时自适应策略:编译器先生成通用计算图,运行时根据负载统计进行调整。这也提示未来编译系统需要在静态优化和动态调整之间取得平衡,让MoE这样的动态稀疏模型获得既高效又灵活的执行。
跨硬件的统一部署与系统优化
LLM的繁荣催生了多样化的算力平台:从数据中心的GPU/TPU,到终端设备的手机GPU、专用NPU,甚至Web浏览器的WebGPU。在不同硬件上部署LLM通常需要不同的底层代码和优化,给模型提供者带来很大负担。因此,跨平台的一体化编译成为迫切需求。Apache TVM和谷歌开源的IREE正是两大面向多硬件的深度学习编译框架。TVM自2018年问世即以“端到端编译、自动优化”著称,通过抽象tensor算子并对接AutoTVM/Ansor自动调优,实现对CPU、CUDA GPU、OpenCL、Metal等后端的支持arxiv。2023年TVM进一步推出Unity计划,引入上述Relax IR统一表示,并加强对移动GPU(如Mali)、WebGPU等新平台的支持github。有了TVM,开发者可以用一种语言(如Python描述的调度或TensorIR)编写模型优化,在不同硬件后端编译出各自的高效代码。这对于需要在服务器和边缘同时部署LLM的场景极为有用(如下图,tvm)。
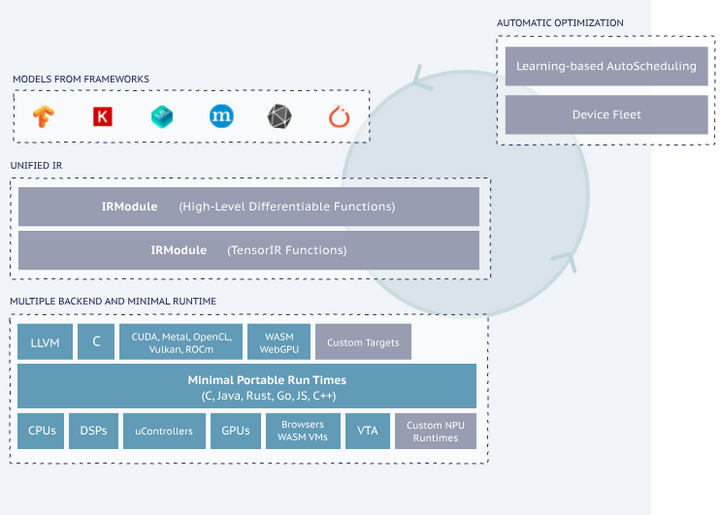
TVM
IREE(Intermediate Representation Execution Environment)则是基于LLVM/MLIR的另一套端到端编译器和运行时。IREE同样接受来自TensorFlow、PyTorch等前端的模型,并将其降低到统一的中间表示后,通过一系列编译pass生成适配目标设备的代码 github。IREE的设计强调可移植性和伸缩性,一套IR既能针对数据中心级性能优化,又能在移动/嵌入式设备上满足资源约束github。
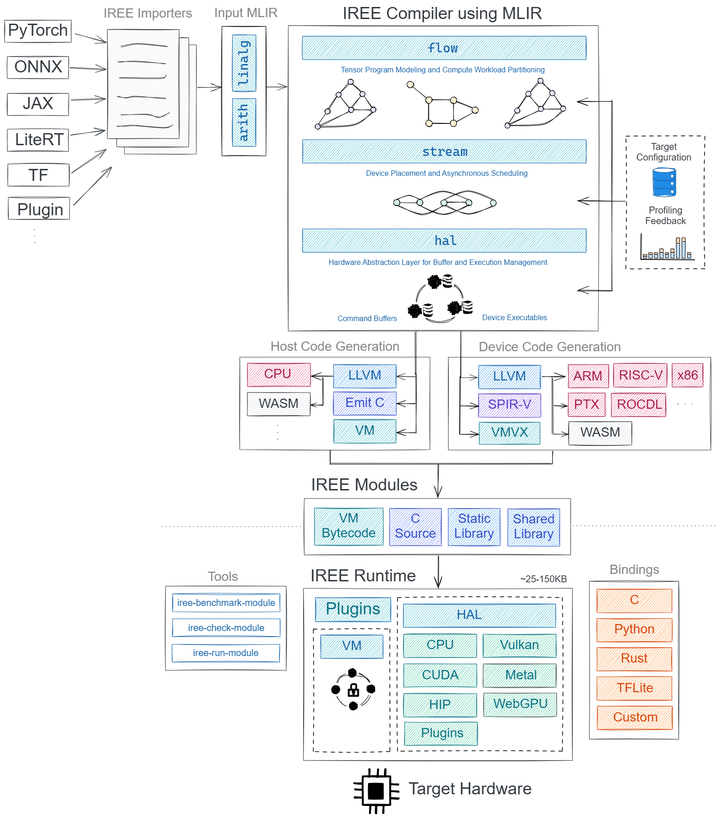
IREE
目前IREE已支持CPU、CUDA、Vulkan、Metal等后端,甚至可以通过WebASM把模型部署到浏览器中。在FOSDEM 2025大会上,AMD工程师展示了用IREE编译运行自家Ryzen AI NPU的案例,表明IREE正逐渐走向实用 yb。通过统一的编译基础设施,模型开发者可以“编译一次,处处运行”,从而极大降低LLM跨硬件部署的门槛。
一个典型的成功案例是MLC (Machine Learning Compilation)项目 arxiv。该项目由CMU等机构的开发者推动,利用TVM/Relax等编译技术,短短两年内实现了将100多个新兴模型部署到27种不同环境,包括iPhone的Metal GPU、安卓手机的Vulkan、浏览器的WebGPU等。
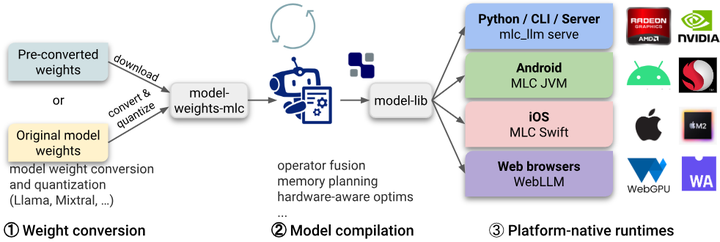
Workflow in MLC LLM
MLC的经验在于采用自顶向下的测试与移植方法(TapML,Top-down Approach for emerging ML deployment):先从成熟平台(如CUDA)拿到模型的正确性和性能基线,再借助编译器工具将模型逐步移植到目标平台,中间通过自动化测试框架保障每一步的正确(如下图)。
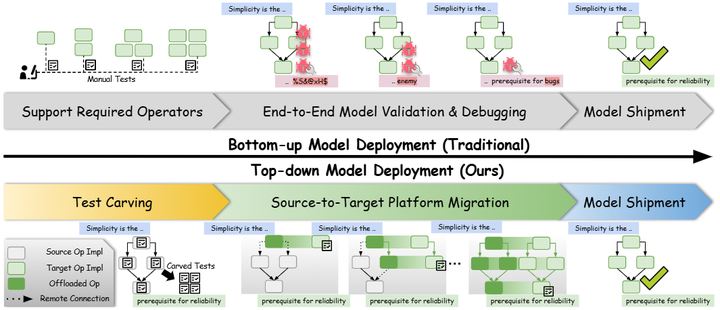
Bottom-up v.s. Top-down approaches to emerging ML system development
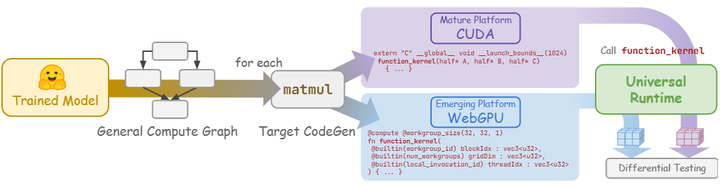
The computation representations in the TapML workflow
可以预见,未来统一编译将成为AI模型部署的主流方式,而编译器本身也将不断适配新的硬件。如RISC-V开源指令集的AI加速扩展、各类大算力芯片(Habana Gaudi、AMD MI300等)的软件栈,甚至模拟量子计算加速器,编译器都需要及时跟进提供支持。在这一过程中,如何充分利用不同硬件的特性也是一大难点。例如,在NVIDIA GPU上要善用Tensor Core和高速显存,在TPU上则需编排好Systolic矩阵阵列,在手机NPU上要平衡CPU/GPU/NPU协同。这些都需要编译器内部有针对性的优化pass。幸运的是,随着硬件厂商也积极参与编译生态(如OpenXLA得到Google、AMD等支持,TVM社区有华为等参与),软硬件协同设计将使未来的LLM运行更加高效、无缝。
综上,面向LLM的编译系统通过动态兼容、跨层优化、混合精度和分布式并行等手段,正在突破大模型部署的性能瓶颈。
趋势与展望
综观LLM与编译技术的融合发展,我们看到双向互促的态势:一方面,LLM为传统编译器注入了智能和数据驱动能力,使编译优化从经验规则走向机器学习优化的新范式;另一方面,编译技术为LLM的高效落地保驾护航,通过软件栈创新弥补硬件和模型之间的鸿沟。展望未来,这一领域有几大值得关注的趋势:
-
LLM与编译器深度结合,实现自适应的智能编译:未来的编译器可能内建LLM模块,在遇到复杂优化决策时自动调用LLM辅助分析。例如编译器可让LLM根据代码上下文建议优化选项、内存布局等,然后由编译器验证应用。
-
编译友好的模型设计与训练:随着编译器在模型部署中扮演更重要角色,模型的设计和训练也会更多考虑编译优化需求。例如,在模型训练时引入编译器反馈(profiling信息)来优化模型结构,使其更易于编译器高效执行。
-
统一开放的编译生态:行业正朝着建立统一的AI编译生态迈进,包括通用IR(如StableHLO、MLIR)、标准算子库和优化pass共享等。开放社区在LLM编译上贡献了大量成果(TVM, IREE, ONNX-MLIR等),未来可能汇聚成类似LLVM在传统编译领域的共同平台。
-
新硬件、新场景带来的挑战:展望未来,量子计算、存内计算、超大规模异构集群等新兴计算范式可能加入LLM加速的竞赛。每种范式都需要定制的编译支持。例如如果出现量子AI处理器,编译器需负责将部分模型算子编译成量子电路并与经典部分衔接。可以预计,编译技术的版图将随着计算版图的扩展而扩展,持续为LLM的“更大更快”之路提供核心动力。
总而言之,LLM与编译技术的结合正在重塑AI技术栈。从让编译器更聪明,到让大模型跑得更快,两方面的创新相互促进。在2025年我们已经看到了初步的成果:LLM能够建议编译优化、自动生成汇编,编译器让千亿参数模型在多种设备上实时运行。这种跨领域融合的巨大潜力才刚刚开始显现。在不远的将来,“编译器即模型、模型即编译器”或许将成为现实,大模型将真正融入软件开发与系统优化的方方面面,推动AI应用走向新的高度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 55
55 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)