一文了解大模型基础
在分类问题中使用 MSE 损失函数可能不太合适,因为它对概率的微小差异不够敏感,而且在分类问题中通常需要使用激活函数(如 Sigmoid 或 Softmax)将输出映射到概率空间,使得 MSE 的数学性质不再适用。对比学习的目标是学习数据的表示,以捕捉不同数据点之间的基本结构和关系。在对比学习中,算法被训练最大化相似数据点之间的相似度,并最小化不相似数据点之间的相似度。该公式可以看作是一个基于概率
一.当前主流的开源模型分类
1. Prefix Decoder 系
(1)介绍:输入双向注意力,输出单向注意力
(2)特点:prefix 部分 token 互相可见,介于 Causal Decoder 和 Encoder-Decoder 之间
(3)缺点:训练效率低
(4)代表模型:ChatGLM、ChatGLM2、U-PaLM
2. Causal Decoder 系
(1)介绍:从左到右的单向注意力
(2)适用任务:自回归语言模型,预训练与下游应用完全一致,严格遵守“只能看到前面 token”的规则 ,文本生成任务效果好
(3)优点:训练效率高,zero-shot 能力更强,具有涌现能力
(4)代表模型:LLaMA-7B、LLaMA 衍生物
3. Encoder-Decoder 系
(1)介绍:输入双向注意力,输出单向注意力
(2)适用任务:输入采用双向注意力,对问题的编码理解更充分 ,偏理解的 NLP 任务效果好
(3)缺点:长文本生成效果差,训练效率低
(4)代表模型:T5、Flan-T5、BART
思考:为何现在的大模型大部分是 Decoder-only 结构?
因为 decoder-only 结构在没有任何微调数据的情况下,zero-shot 表现最好;而 encoder-decoder 则需要一定量的标注数据做多任务微调才能激发最佳性能。
二.Layer normalization
1.LayerNorm 的计算公式

2.RMSNorm(均方根 Norm)的计算公式
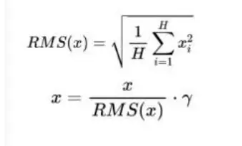
3.RMSNorm 相比于 LayerNorm 的特点:RMSNorm 简化了 LayerNorm,去除了计算均值并进行平移的部分。相比 LayerNorm,RMSNorm 计算速度更快,效果基本相当,甚至略有提升。
4.LN 在 LLMs 中的不同位置及其区别
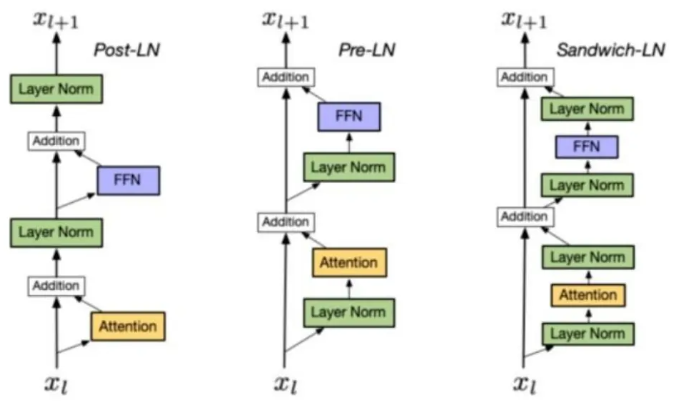
上图中从左到右分别为:
-
Post-LN
-
位置:LayerNorm 放在残差连接之后
-
缺点:深层梯度范数逐渐增大,深层 Transformer 容易出现训练不稳定
-
-
Pre-LN
-
位置:LayerNorm 放在残差连接“之内”(每个子层输入前)
-
优点:深层梯度范数近似相等,训练更稳定,缓解不稳定问题
-
缺点:相比 Post-LN,模型最终效果略差
-
-
Sandwich-LN
-
位置:在 Pre-LN 基础上,额外在 Attention/FFN 输出后再插一层 LayerNorm
-
优点:CogView 等工作中用于防止值爆炸
-
缺点:训练不稳定,可能导致训练崩溃
-
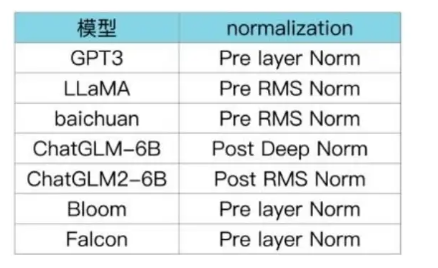
5.LLMs 各模型分别使用的 Layer Normalization 类型
三、激活函数
FFN 块计算公式:
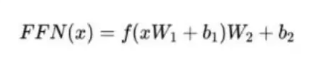
GeLU 激活函数:
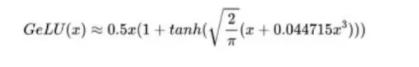
相比 ReLU,GeLU 在负值区域不是一刀切到 0,而是一条平滑曲线,梯度更柔和,训练更稳;BERT、GPT-3 都在用。
Swish 激活函数:
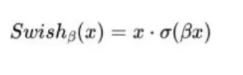
“ReLU 升级版”,β=1 时就是 x·sigmoid(x)。实验发现比 GeLU 稍好,但计算略贵,所以 LLaMA-2、PaLM-2 选它。
使用 GLU 线性门控单元的 FFN:
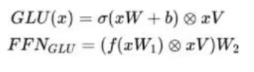
核心思想:把一路输入再分两条——一条当“门”,一条当“值”,逐元素乘后再过激活。
效果:在几乎不增加参数的情况下,把信息通路翻倍,提升表达能力。
公式里 W,V 就是这两条分支的权重矩阵。
使用 GeLU 的 GLU(GeGLU):
![]()
使用 Swish 的 GLU(SwiGLU):

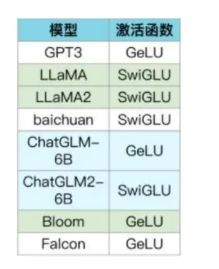
各LLMs都使用哪种激活函数:
四、损失函数
1.KL 散度
KL(Kullback-Leibler)散度衡量了两个概率分布之间的差异。其公式为:
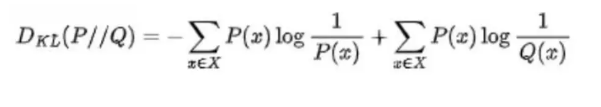
-
P(x):真实分布(ground truth)。
-
Q(x):模型分布(你训练出来的预测)。
-
KL 散度衡量的是:如果你 用 Q 来近似 P,需要付出的“额外信息代价”。也就是说,KL 散度越小,两个分布越接近;KL 散度为 0,说明 P 和 Q 完全一致。
2.交叉熵损失函数
交叉熵损失函数(Cross-Entropy Loss Function)是用于度量两个概率分布之间的差异的一种损失函数。在分类问题中,它通常用于衡量模型的预测分布与实际标签分布之间的差异。
![]()
其中,p 表示真实标签,q 表示模型预测的标签,N 表示样本数量。该公式可以看作是一个基于概率分布的比较方式,即将真实标签看做一个概率分布,将模型预测的标签也看做一个概率分布,然后计算它们之间的交叉熵。
物理意义:交叉熵损失函数可以用来衡量实际标签分布与模型预测分布之间的 “信息差”。当两个分布完全一致时,交叉熵损失为 0,表示模型的预测与实际情况完全吻合。当两个分布之间存在差异时,损失函数的值会增加,表示预测错误程度的大小。
3.KL 散度与交叉熵的区别
KL 散度指的是相对熵,KL 散度是两个概率分布 P 和 Q 差别的非对称性的度量。KL 散度越小表示两个分布越接近。也就是说 KL 散度是不对称的,且 KL 散度的值是非负数。(也就是熵和交叉熵的差)
- 交叉熵损失函数是二分类问题中最常用的损失函数,由于其定义出于信息学的角度,可以泛化到多分类问题中。
- KL 散度是一种用于衡量两个分布之间差异的指标,交叉熵损失函数是 KL 散度的一种特殊形式。在二分类问题中,交叉熵函数只有一项,而在多分类问题中有多项。
4.分类问题为什么用交叉熵损失函数不用均方误差(MSE)
交叉熵损失函数通常在分类问题中使用,而均方误差(MSE)损失函数通常用于回归问题。这是因为分类问题和回归问题具有不同的特点和需求。
分类问题的目标是将输入样本分到不同的类别中,输出为类别的概率分布。交叉熵损失函数可以度量两个概率分布之间的差异,使得模型更好地拟合真实的类别分布。它对概率的细微差异更敏感,可以更好地区分不同的类别。此外,交叉熵损失函数在梯度计算时具有较好的数学性质,有助于更稳定地进行模型优化。
相比之下,均方误差(MSE)损失函数更适用于回归问题,其中目标是预测连续数值而不是类别。MSE 损失函数度量预测值与真实值之间的差异的平方,适用于连续数值的回归问题。在分类问题中使用 MSE 损失函数可能不太合适,因为它对概率的微小差异不够敏感,而且在分类问题中通常需要使用激活函数(如 Sigmoid 或 Softmax)将输出映射到概率空间,使得 MSE 的数学性质不再适用。
五、相似度函数
1.除了 cosin 还有哪些算相似度的方法
除了余弦相似度(cosine similarity)之外,常见的相似度计算方法还包括欧氏距离、曼哈顿距离、Jaccard 相似度、皮尔逊相关系数等。
2.对比学习
对比学习是一种机器学习技术,算法学习区分相似和不相似的数据点。对比学习的目标是学习数据的表示,以捕捉不同数据点之间的基本结构和关系。在对比学习中,算法被训练最大化相似数据点之间的相似度,并最小化不相似数据点之间的相似度。通常的做法是通过训练算法来预测两个数据点是否来自同一类别。
对比学习是无监督 / 自监督学习里的核心方法,通俗讲就是让模型学会 “找不同、认相同” ,通过构造样本对(正例、负例),让模型学习到:同类样本的特征表示更接近(拉近正例),不同类样本的特征表示更疏远(推开负例 ),最终让模型掌握数据的本质特征,具体拆解如下:
(1)核心逻辑:“拉近距离、推开差异”
- 正样本:语义 / 标签相同的样本(比如同一张猫图的不同 augmentation、同一用户的不同行为序列 ),模型训练目标是让它们的特征表示尽可能接近。
- 负样本:语义 / 标签不同的样本(比如猫图和狗图、不同用户的行为),模型要让它们的特征表示尽量远离。
- 举例:用对比学习训练图像模型时,给模型同一只猫的 “原图 + 旋转图 + 模糊图”(正例),和其他猫 / 狗 / 汽车图(负例),模型会学到 “这些长得像的是一类,和其他不同”,从而提炼出区分度高的特征。
(2)常用做法(以图像 / 文本为例)
- 样本构造:
- 图像:对同一张图做裁剪、旋转、加噪声等数据增强,生成正例;其他图当负例。
- 文本:同一句话的不同 paraphrase(改写)当正例,其他句子当负例;或用 “上下句” 关系(如同一篇文章的相邻段落)做正例。
- 损失函数:用对比损失(如 InfoNCE)量化 “正例要近、负例要远” 的目标,让模型优化特征表示。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)