马斯克突然开源 9050 亿参数 Grok 2.5,直言 “中国公司最难缠”!
马斯克开源Grok 2.5引发AI行业震动:参数神话与商业限制并存 xAI发布的Grok 2.5以9050亿总参数成为最强开源模型,支持超长上下文和MoE架构,但附带的“非商业许可”引发争议。马斯克直言中国公司是最大对手,凸显行业竞争加剧。中国AI企业如阿里、DeepSeek等已构建多模态技术护城河,以快速迭代、低成本和高场景适配性应对挑战。面对Grok 2.5的商业限制,中国企业通过二次研发和自

当马斯克在 8 月 24 日按下 “开源” 按钮,整个 AI 行业的震动比预想中更猛烈 ——xAI 在 Hugging Face 正式放出 Grok 2.5,这款号称 “最强开源模型” 的产品,带着 9050 亿总参数的光环登场,却也裹着一层充满矛盾的 “枷锁”。
一边是技术上的大突破:支持 13.11 万 tokens 超长上下文,再加上混合专家架构(MoE)带来的效率优势,直接把开源模型的性能天花板往上抬了一大截;另一边却是刺眼的限制 ——“Grok 2 社区许可证” 明确禁止商业使用,和 MIT、Apache 这类真正意义上的开源协议差着本质区别。
更耐人寻味的是马斯克的一句预判:“中国公司将是 xAI 最难缠的对手”。他没绕弯子,直接点出了中国在电力资源、硬件制造上的核心优势 —— 这番话,与其说是预警,不如说是把 AI 行业的 “暗战” 摆到了明面上。
先别急着为 “9050 亿参数” 的数字惊叹,拆解完 Grok 2.5 的细节,你会发现这场开源没那么简单。
参数神话背后,藏着高不可攀的门槛
Grok 2.5 的 “9050 亿总参数” 确实唬人,但实际激活的只有 1360 亿 —— 这是 MoE 架构的常规操作,既保证性能又控成本。可即便如此,想跑起来这款模型,门槛依然高到让个人开发者望而却步:凑齐 8 块 40GB 显存的 GPU,再准备 500GB 存储,光是硬件投入就不是小数目。
更关键的是 “许可争议”:所谓的 “开源”,其实是 “有限开源”。禁止商业使用这一条,直接把想靠它落地赚钱的公司拦在门外 —— 和真正自由的开源协议比,这更像给模型上了个 “试用锁”。
xAI 的算盘:拉拢开发者,试探对手
马斯克的战略算计其实很清晰:
生态卡位:放开源代码,吸引全球开发者帮着优化模型,相当于用 “众力” 打磨产品,为后续 Grok 4 系列争取市场时间。
技术防御:把现有技术优势 “固化” 在开源生态里,同时用非商业许可堵死商业落地路,避免对手直接拿现成的模型抢市场。
对手试探:尤其针对中国市场 —— 看看中国公司会怎么应对这波开源,是跟进二次研发,还是拿出自研模型对抗?
中国 AI 军团的 “三重护城河”:凭什么让马斯克忌惮?
马斯克说 “中国公司最难缠”,不是随口说说。从阿里、DeepSeek 到商汤、智谱,中国 AI 军团已经筑起了三层硬实力护城河。
现在的 AI 竞争,早就不是单文本模型的较量了,多模态(文本、图像、视频联动)才是主战场,而中国公司已经在这领域跑出了成绩:
阿里通义千问:
Qwen2.5-VL 在 13 项权威评测里直接超过 GPT-4o,还有 Qwen-Image-Edit,成了中文图像编辑领域的 “标杆级产品”
DeepSeek-V3:
6710 亿参数的 MoE 模型,性能快追上 GPT-4o 了,训练成本才 557 万美元 —— 性价比直接碾压同类模型
商汤 / 智谱:
商汤日日新 V6.5 搞出全模态架构,智谱 GLM-4.5V 把视觉推理功能开源,而且都在加速本土化场景落地,不搞 “空中楼阁”。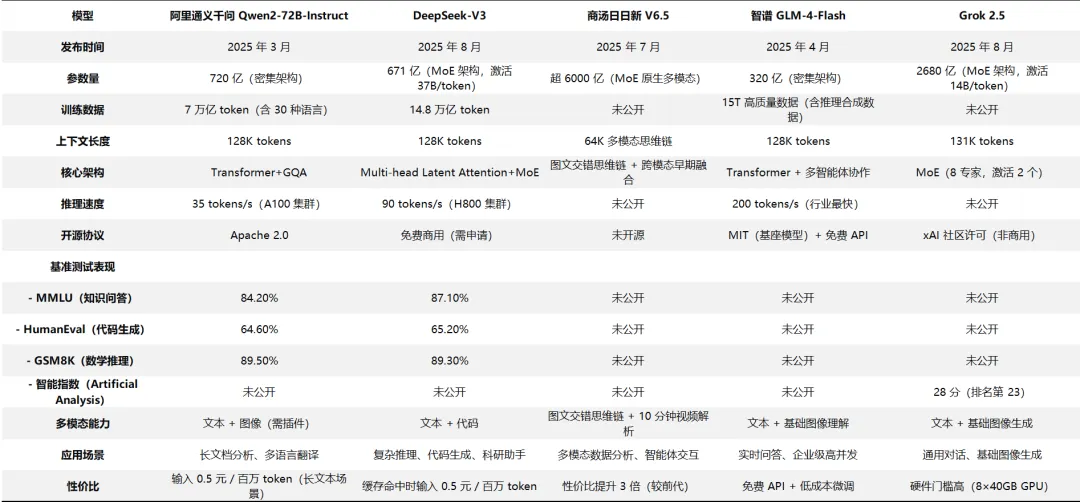
开源 + 商业化:双轨跑,又快又省
中国公司的打法很务实:既要开源攒生态,又要商业化赚收益,而且节奏快、成本控得极严:
迭代速度快到离谱
阿里半年内连更 3 款多模态模型,昆仑万维更夸张,一周就推出 6 款场景化模型,根本不给对手反应时间。
成本压到地板价
DeepSeek-V3 不仅推理速度提了 3 倍,API 价格还只有 GPT-4 的百分之一 —— 这意味着企业用起来更便宜,普及速度会更快。
生态占领稳准狠
Hugging Face(全球最大 AI 模型社区)的榜单上,Qwen-Image 直接登顶;国内的魔搭社区还专门做了本土化支持,开发者用起来更顺手。
基建 + 政策:后盾够硬,场景够多
AI 拼到最后,拼的是 “家底”—— 中国的基建和政策,刚好给 AI 搭好了最稳的舞台:
算力家底厚:
全球最大的数据中心集群在支撑,GPU 算力每年增长超 50%,不用担心 “算不动” 的问题。
政策给明确方向:
生成式 AI 管理办法直接把开源路径说清楚了,多模态技术还被纳入 “新质生产力” 重点领域,相当于有了政策 “背书”。
场景多到用不完:
数字人直播、医疗诊断这些落地场景,中国的规模全球第一 —— 模型练得再好,最终要靠场景落地才算数,这正是我们的优势。
AI 暗战升级:中国怎么破 “非商业许可” 的局?
Grok 2.5 的 “非商业许可”,看似是道坎,但中国公司已经找到了解法,甚至在重构全球 AI 的格局。
两条路破局:不被规则绑住
面对禁止商业使用的限制,国内公司没硬刚,而是走了更灵活的路:
二次研发 + 闭源商业化:
拿 Grok 2.5 的开源代码做基础,自己加功能、优化性能,最后做成闭源产品落地 —— 既利用了现有技术,又绕开了许可限制;
自研模型直接反超:
不依赖 Grok,靠自己的模型构建 “开源替代方案”,比如 DeepSeek-V3,性能已经能对标甚至超过 Grok 2.5,完全不用看别人脸色
全球格局变了:中国成为“规则制定者”
以前 AI 的规则是西方定的,现在不一样了:
西方阵营开始分化。OpenAI 死磕闭源,xAI 搞有限开源,战略不统一。
中国力量正在改写叙事。在多模态领域,我们已经从 “跟着西方学” 变成 “自己做标杆”,甚至能影响全球的技术路线。
下一场竞争在这些领域:空间感知、具身智能(比如机器人理解物理世界)这些还没被攻克的领域,会成为新的 “战场”。
结语:开源不是终点,是新战场的起点
马斯克这张 “开源牌”,其实是给中国 AI 踩了一脚 “加速键”—— 倒逼我们更快实现技术自主。
接下来的多模态竞赛,比的不再是 “谁先开源”,而是 “谁能平衡开源生态和商业价值”:既要让开发者愿意参与,又要让企业能赚钱,谁做到了,谁就能定义下一代 AI 的规则。
最后留个问题给大家:当电力、硬件、场景这些 “家底” 都站在同一起跑线,开源会不会成为 AI 技术 “平权” 的终极武器?中国 AI 又能不能在这场新战场里领跑?
评论区聊聊你的看法~


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)