[Sync_ai_vid] 数据处理流水线 | 配置管理系统
数据处理流水线通过:1. 系统化的多阶段清洗2. 智能化的质量过滤3. 分布式的并行处理为LatentSync提供高质量训练数据。配置管理系统通过:1. 声明式的参数定义2. 模块化的配置组织3. 灵活的方案切换为LatentSync提供精准可控的参数管理能力。
第6章:数据处理流水线
在LatentSync的探索之旅中,我们已经了解了生成唇形同步视频的唇形同步推理流程、实现核心功能的LatentSync UNet、提供音频线索的音频特征提取器(Whisper)、评估同步质量的SyncNet唇形同步评判器,以及处理单帧画面的图像与视频处理器。
这些强大工具都需要一个关键基础:高质量、规范化的训练数据。
就像建造高效工厂需要预先分类、清洗和标准化的原材料一样,训练LatentSync这样的复杂AI模型也需要精心准备的数据。
这就是数据处理流水线的价值所在。它是一个自动化的"数据工厂",将海量原始音视频转化为干净、统一且优化过的数据集,为模型训练做好准备。
核心价值
原始音视频数据往往存在诸多问题:
- 文件损坏或格式错误
- 不同的帧率(FPS)和采样率(Hz)
- 未分段的长视频包含多个场景
- 面部未对齐、角度异常或尺寸过小
- 音画不同步
- 画质模糊、噪点多或曝光不足
数据处理流水线通过系统化的清洗和整理解决这些问题,其主要应用场景是为LatentSync模型准备大规模训练数据集(如数千小时的说话人视频)。
流水线工作流程
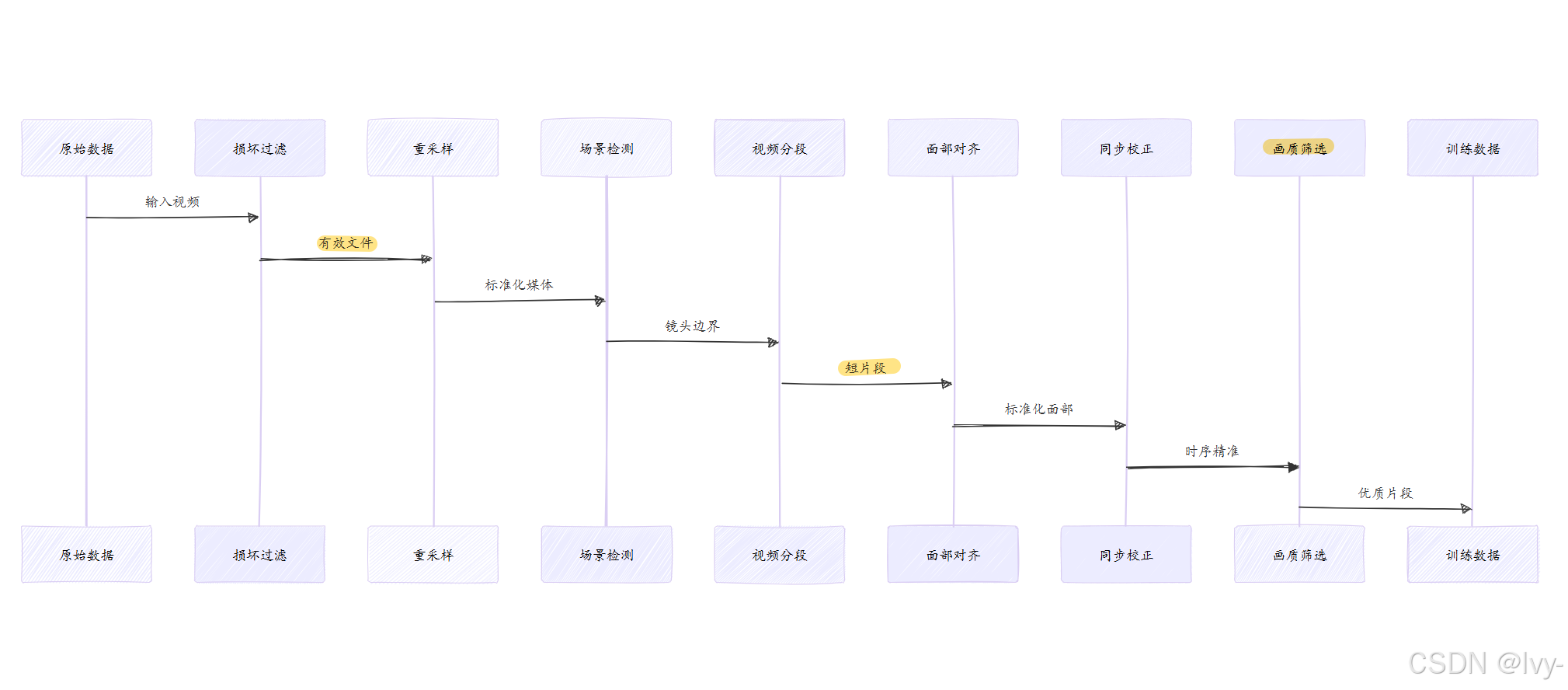
数据处理流水线如同精密的生产线,每个环节执行特定的清洗和标准化任务:
- 损坏文件过滤:剔除无法读取的损坏文件
- 媒体重采样:统一视频为25FPS,音频为16000Hz
- 场景切换检测:识别视频中的镜头切换点
- 视频分段:将长视频切割为固定时长片段(如5秒)
- 面部仿射变换:检测并对齐面部,统一为256x256像素
- 音画同步校正:调整音视频时序偏差
- 画质筛选:保留清晰度、亮度达标的高质量片段
实现方式
通过命令行工具运行数据处理流水线:
python -m preprocess.data_processing_pipeline \
--total_num_workers 96 \ # 总工作进程数
--per_gpu_num_workers 12 \ # 单GPU工作进程数
--resolution 256 \ # 目标分辨率
--sync_conf_threshold 3 \ # 同步置信度阈值
--input_dir /raw/videos # 原始数据目录
流水线会生成多个中间目录(resampled、segmented等),最终输出到high_visual_quality目录的即为可直接用于训练的高质量数据。
技术架构
关键代码模块包括:
- 流水线调度器 (
data_processing_pipeline.py)
def data_processing_pipeline():
remove_broken_videos() # 第一步
resample_fps_hz() # 第二步
detect_scene_changes() # 第三步
segment_videos() # 第四步
affine_transform_faces() # 第五步
sync_av() # 第六步
filter_visual_quality() # 第七步
- 多GPU面部对齐 (
affine_transform.py)
def affine_transform_multi_gpus():
num_gpus = torch.cuda.device_count()
for gpu_id in num_gpus: # 多GPU并行
Process(target=transform_worker, args=(gpu_id,))
- 数据集封装 (
unet_dataset.py)
class UNetDataset:
def __getitem__(self, idx):
# 直接加载预处理好的对齐面部
video = load_preprocessed(self.video_paths[idx])
return {
'pixels': video.frames,
'audio': video.audio
}
总结
数据处理流水线通过:
- 系统化的
多阶段清洗 - 智能化的质量
过滤 分布式的并行gpu处理
为LatentSync提供高质量训练数据。下一章将介绍配置管理系统如何统一管理这些复杂组件的参数设置。
第7章:配置管理系统
在前几章中,我们已经探索了LatentSync的所有核心组件:协调全局的唇形同步推理流程、创意十足的LatentSync UNet、敏锐的音频特征提取器(Whisper)、严格的SyncNet唇形同步评判器、精确的图像与视频处理器以及高效运转的数据处理流水线。这些组件都有大量参数需要控制。
假设我们需要调整UNet的"学习率"(学习速度)或修改"模型架构"(UNet内部结构),直接修改Python源码就像随意更改精密机器的线路——不仅混乱易错,而且难以追踪变更。
配置管理系统正是为此而生。它如同整个LatentSync项目的总控蓝图,将所有重要参数定义在易读的YAML文件中,而非隐藏在代码深处。
核心价值
YAML("YAML不是标记语言"的递归缩写)是一种人性化的数据格式,特别适合定义配置参数:
# 简单YAML示例
model:
layers: 12
attention_heads: 8
training:
learning_rate: 0.0001
batch_size: 32
配置管理系统为LatentSync带来四大优势:
灵活调整:通过编辑YAML文件即可改变模型行为,无需修改代码结果复现:共享配置文件即可精确复现实验效果- 模块化管理:不同组件的配置分门别类,便于维护
高效实验:通过创建多个配置文件快速尝试不同参数组合
配置内容
这些"总控蓝图"文件几乎定义了所有关键参数:
- 模型架构:
UNet的规模、SyncNet的层数等结构参数 - 训练超参:学习率、批大小、损失函数权重等
- 数据路径:训练视频位置、缓存目录等
- 推理设置:生成步骤数、引导强度等
使用方式
通过--config参数指定配置文件启动训练:
python scripts/train_unet.py \
--config configs/unet/stage2.yaml
典型配置文件示例:
# configs/unet/stage2.yaml片段
data:
batch_size: 1 # 单次训练处理的视频数
resolution: 256 # 面部图像分辨率
model:
cross_attention_dim: 384 # 音频特征维度
use_motion_module: true # 启用运动模块
training:
sync_loss_weight: 0.05 # SyncNet损失权重
实现原理
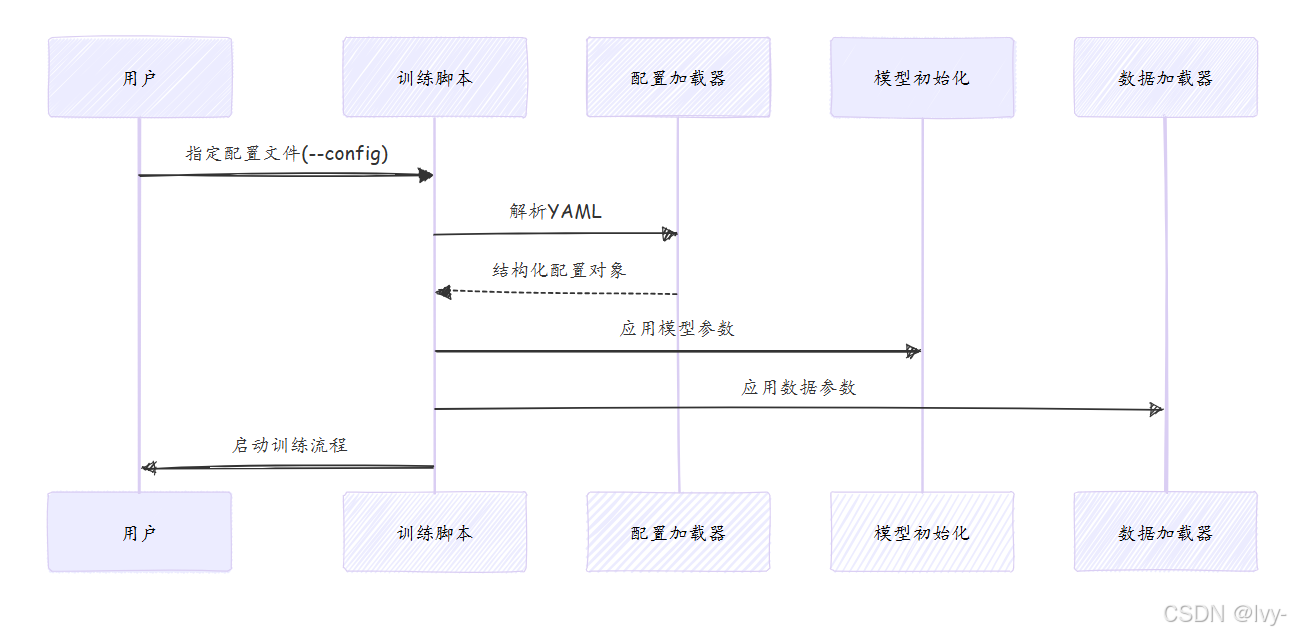
核心代码逻辑:
# train_unet.py简化示例
from omegaconf import OmegaConf
def main():
config = OmegaConf.load(args.config) # 加载YAML
print(f"学习率: {config.training.learning_rate}")
# 根据配置初始化UNet
model = UNet3D(
in_channels=config.model.in_channels,
out_channels=config.model.out_channels
)
配置分类
LatentSync的配置文件按组件分类存储:
| 配置文件 | 关键参数 | 适用场景 |
|---|---|---|
| configs/unet/stage1.yaml | use_motion_module: false | 初始训练阶段 |
| configs/unet/stage2.yaml | use_motion_module: true | 主训练阶段(含运动模块) |
| configs/syncnet/pixel.yaml | latent_space: false | 基于像素的SyncNet |
总结
配置管理系统通过:
声明式的参数定义模块化的配置组织- 灵活的方案切换
为LatentSync提供精准可控的参数管理能力。至此我们已完成LatentSync核心架构的全面解析。
END ★,°:.☆( ̄▽ ̄)/.°★ 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)