H20 性能表现之 GLM-4.5
我也抢鲜体验了一下,先不说比不比得上 o3,至少对比 DeepSeek R1(以下称671B)以及 Qwen3-Coder (以下称480B),已略有胜算。,这个性能表现还是颇有亮点的,特别是在多用户代码生成场景上。同时,从能力上来说,GLM-4.5 是目前数一数二的开源大模型了,所以部署到H20上应该不亏。通义千问前脚刚发布完 Qwen3-Coder-480B,智谱马上有了回应,不仅发布了新的。
通义千问前脚刚发布完 Qwen3-Coder-480B,智谱马上有了回应,不仅发布了新的旗舰级模型 GLM-4.5,还将其开源了。从官方发布的消息来看,其能力已快赶上 OpenAI 的 o3。我也抢鲜体验了一下,先不说比不比得上 o3,至少对比 DeepSeek R1(以下称671B)以及 Qwen3-Coder (以下称480B),已略有胜算。
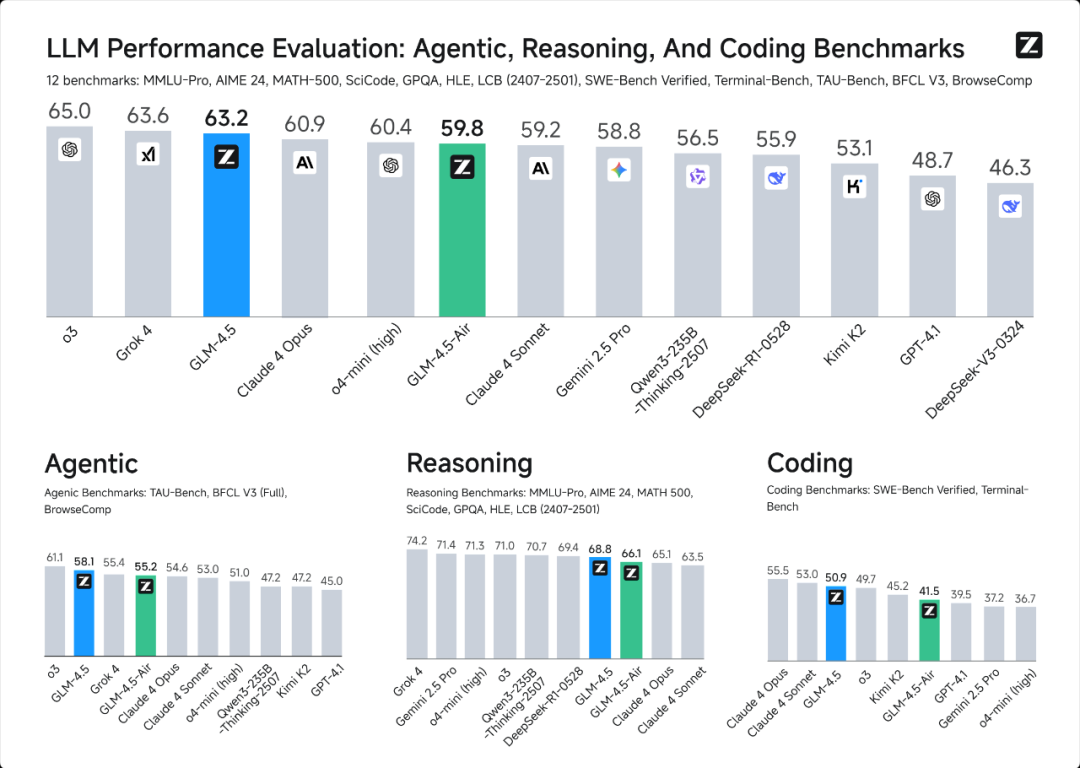
那么,问题就来了,这个参数量达到355B的模型,运行在目前的旗舰主机 H20 上的表现如何呢?继上周我来大家带来H20性能表现之Qwen3-Coder-480B,今天,再次奉上 GLM-4.5 在 H20 上的性能表现。
测试环境与之前480B一样,都是在H20八卡机上,使用0.10.0版本的vllm进行推理。
首先,我们先来看看在代码生成上的性能表现,也就是长输出的情况。(输入128,输出2K token)如下图所示。
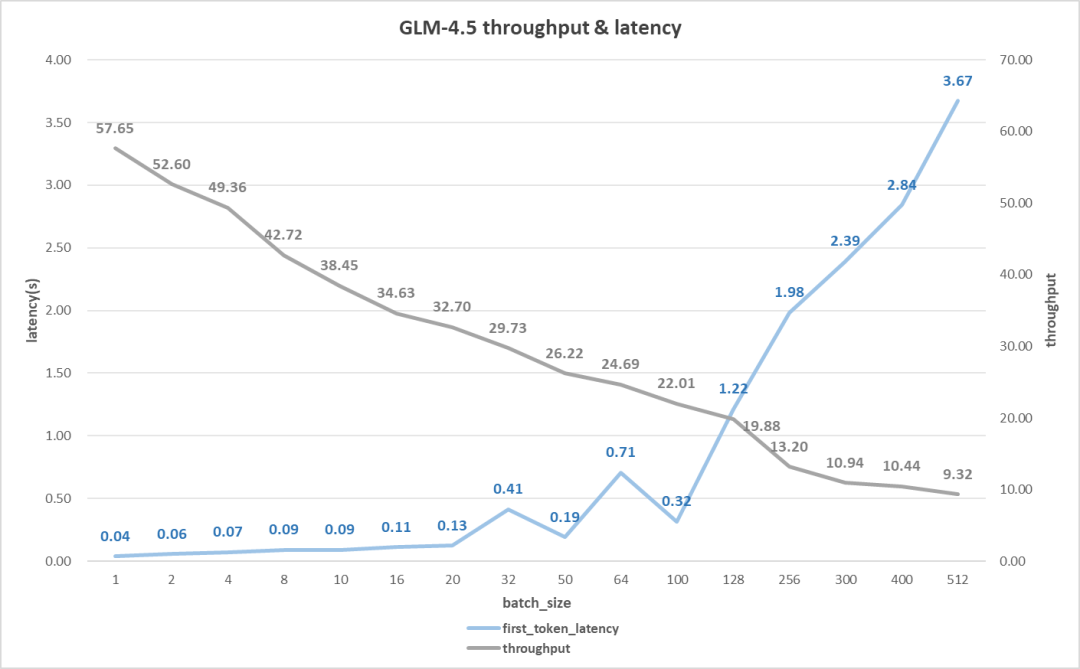
首字时延性能没什么好说的,和其他的模型差别不大;吞吐率表现则中规中矩,在单用户时有58 token/s,虽然比不上480B的92 token/s,但也比671B的 31 token/s强上不少。当并发用户数达到100时,吞吐率却能达到22 token/s,与480B非常接近,并且是671B的两倍,可以说是相当不错的了。
再来看看长输入的情况,一般用于知识库问答或智能体应用场景(输入4K,输出512),如下图。
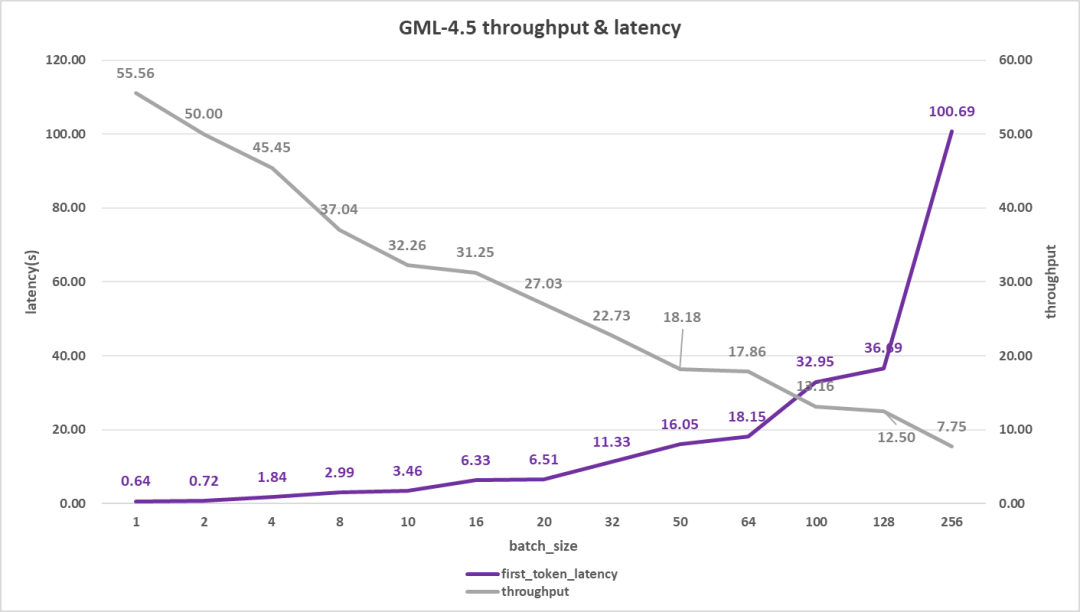
单用户吞吐率表现与上一个案例区别不大,55 token/s。多用户则区别较大,但并发50用户也能达到18 token/s,虽比不上480B的21 token/s,但比671B的11 token/s强出50%有多;不过与此同时,其首字时延表现却不大理想,达到了16秒,比另外两个模型的12秒多了33%。
考虑到 GLM-4.5 的激活集达到了32B,这个性能表现还是颇有亮点的,特别是在多用户代码生成场景上。同时,从能力上来说,GLM-4.5 是目前数一数二的开源大模型了,所以部署到H20上应该不亏。
最后,请看官一键三连,我将为您带来更多的评测数据与文章。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)