【大模型量化:让 AI 从云端走向终端的关键技术】
大模型量化:让 AI 从云端走向终端的关键技术
大模型量化:让 AI 从云端走向终端的关键技术
随着人工智能特别是深度学习的发展,超大规模模型(Large-Scale Models)在自然语言处理、计算机视觉、推荐系统等领域取得了突破性成果。然而,随着模型规模的指数级增长,模型参数量通常达到数百亿甚至上千亿,带来了存储占用巨大、推理延迟高、能耗增加等现实问题。这不仅增加了云端部署成本,也限制了模型在边缘设备和移动终端的应用。
为了在保证模型性能的前提下,提高推理效率并降低资源消耗,模型量化(Model Quantization) 应运而生。量化技术通过将高精度浮点数(如 FP32、FP16)转换为低比特表示(如 INT8、INT4、甚至二值化),在减小模型存储空间、提升计算速度、降低能耗方面表现出显著优势。量化不仅可应用于模型权重,也可扩展至中间激活和梯度,实现端到端的低比特计算。
大模型量化的发展涉及多方面挑战:如何在降低比特宽度的同时保证精度,如何对不同层采取合理的量化策略(如混合精度量化),以及如何结合硬件特性进行优化。近年来,随着 PTQ(Post-Training Quantization)与 QAT(Quantization-Aware Training)的提出,以及低秩近似、知识蒸馏、混合精度策略等技术的融合,大模型量化已经成为大模型部署和高效推理的核心技术。
本篇文档将系统阐述大模型量化的核心概念、比特宽度选择、量化对象、量化方法与分类,并结合典型案例与工具链,提供从理论到实践的全景指南。同时配套流程图、示意图和性能对比表,帮助读者全面理解量化的原理、实现方法和应用价值,为大模型在云端、边缘及嵌入式设备的高效部署提供技术参考。
一、基本概念
1. 定义
大模型量化(Large Model Quantization, LMQ)是将深度学习模型中**高精度浮点数(通常是 FP32 或 FP16)压缩为低比特表示(如 INT8、INT4、二值化或三值化)**的过程。其核心目标是用有限比特表示连续数值,同时尽量保留原始信息分布。
原理解释:浮点数通常以指数+尾数表示,其动态范围大,但存储和计算开销高。量化通过映射函数将连续浮点数映射到离散整数区间,同时使用缩放因子(scale)和偏移量(zero-point)恢复近似值。
例如:
x quant = round ( x − x min x max − x min ⋅ ( 2 b − 1 ) ) x_{\text{quant}} = \text{round}\left(\frac{x - x_\text{min}}{x_\text{max}-x_\text{min}} \cdot (2^b-1)\right) xquant=round(xmax−xminx−xmin⋅(2b−1))
其中 b b b 为量化比特位宽, x min , x max x_\text{min}, x_\text{max} xmin,xmax 分别为数值的最小值和最大值。
量化不仅用于权重,也可用于激活值和梯度,从而降低存储、加速推理、减少能耗。
2. 目标
-
降低存储空间
- 大模型参数量巨大,例如 GPT-3 175B 参数模型占约 350GB FP32 存储空间。
- 将 FP16 压缩到 INT8 可减小 2 倍存储,INT4 可减小 4 倍,从而支持单机 GPU 或边缘设备推理。
- 实践案例:LLaMA-70B 模型 FP16 占 140GB → INT4 占 35GB,单张 A100 GPU 可加载。
-
提升计算速度
- 低比特运算可使用向量化指令(如 AVX512、ARM Neon)或 GPU/TPU 的张量核心进行加速。
- 对卷积、矩阵乘法、注意力计算,INT8 运算可比 FP32 运算快 2~4 倍。
- 硬件原理:整数乘法比浮点乘法占用更少的 ALU 资源,减少流水线延迟。
-
降低能耗
- 低比特计算减少内存访问次数和算力消耗,适用于移动端、嵌入式设备及无人机。
- 在边缘设备上,INT8 推理相比 FP32 可节省 50%~70% 能耗。
3. 应用场景
- 云端推理:大规模推理任务,降低存储和带宽成本,提高多模型并行部署效率。
- 边缘设备部署:智能手机、IoT、无人机等,需低功耗且内存有限的环境。
- 分布式训练:梯度量化可显著降低通信带宽,提高多节点训练效率,常见于 8-bit 或 4-bit 梯度压缩。
4.源码示例(PyTorch)
import torch
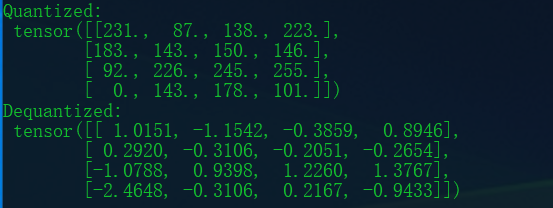
def min_max_quantize(x, num_bits=8):
x_min, x_max = x.min(), x.max()
qmin = 0
qmax = 2**num_bits - 1
scale = (x_max - x_min) / (qmax - qmin)
x_quant = torch.round((x - x_min) / scale)
x_dequant = x_quant * scale + x_min
return x_quant, x_dequant
tensor = torch.randn(4,4)
q, dq = min_max_quantize(tensor, 8)
print("Quantized:\n", q)
print("Dequantized:\n", dq)
5. 参考论文
- Jacob et al., “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference”, CVPR 2018.
- Banner et al., “Post Training 4-bit Quantization of Convolutional Networks for Rapid-Deployment”, NeurIPS 2019.
二、量化比特(Quantization Bit-width)
量化比特位宽直接影响模型精度与存储/计算效率。
| 类型 | 精度 | 优缺点 | 应用场景 |
|---|---|---|---|
| FP32 | 高 | 精度最高,存储大,计算慢 | 训练阶段常用 |
| FP16 / BF16 | 中 | 存储减半,推理加速,BF16 保留大动态范围 | GPU/TPU 推理,混合精度训练 |
| INT8 | 中低 | 存储降 4 倍,延迟降低 2~4 倍,精度下降 <1% | 主流量化推理 |
| INT4 | 低 | 存储降 8 倍,精度可能下降 | 超大模型边缘部署 |
| Binary / Ternary | 极低 | 极限压缩,精度损失大 | 极低功耗设备,如微控制器 |
示例:
- LLaMA-70B 模型 FP16 → INT4:存储从 140GB 压缩至 35GB;推理速度提升约 1.8 倍,单张 GPU 可直接加载。
技术原理:比特宽度降低后,单次内存访问可处理更多元素,同时低比特乘加运算占用更少硬件资源,整体推理延迟降低。
三、量化对象(Quantization Target)
1. 权重量化(Weight Quantization)
- 权重量化只作用于模型参数,对网络中的参数矩阵进行量化。
- 优点:实现简单,推理精度下降较小。
- 常见策略: 分为逐层(per-tensor)或逐通道(per-channel)量化。Per-tensor是整个张量共享缩放因子,Per-channel则是每个输出通道独立缩放因子,精度更高。
- 应用案例:ResNet-50 权重量化到 INT8,Top-1 精度下降 <1%。
- 源码示例(PyTorch 动态量化):
import torch
import torch.nn as nn
from torch.quantization import quantize_dynamic
model = nn.Linear(512, 512)
quant_model = quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)
print(quant_model)

-
参考论文:
- Gong et al., “Compressing Deep Convolutional Networks using Vector Quantization”, arXiv 2014.
2. 激活量化(Activation Quantization)
- 对中间层输出进行量化。
- 挑战:激活动态范围大,输入依赖数据分布,需要动态量化或非对称量化策略。
- 原理:通过统计 min/max 或分布均值方差,确定缩放因子和零点进行映射。
- 案例:Transformer 注意力层的激活量化至 INT8,可减少内存带宽压力。
- 源码示例(PyTorch QAT 激活量化):
import torch
import torch.nn as nn
from torch.quantization import prepare_qat, convert
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(512, 512)
def forward(self, x):
return self.fc(x)
model = SimpleNet()
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model = prepare_qat(model)
# 训练若干步后
model = convert(model.eval())
- 参考论文:
- Krishnamoorthi, “Quantizing deep convolutional networks for efficient inference”, arXiv 2018.
3. 权重 + 激活联合量化
- 权重与激活同时量化,通常用于 INT8 部署。
- 精度控制难度大,通常需要 QAT 或混合精度策略。
- 案例:BERT INT8 部署,使用 TensorRT PTQ,可实现 FP32 精度损失 <1%。
4. 梯度量化(Gradient Quantization)
- 用于分布式训练通信压缩。
- 通过低比特传输梯度,减少网络带宽占用。
- 不影响推理精度,但可提高训练效率。
- 案例:使用 8-bit 梯度压缩的分布式训练,通信带宽减少约 75%。
四、量化分类(Quantization Types)
1. 按量化时间
-
PTQ(Post-Training Quantization)
- 模型训练完成后直接量化
- 优点:部署快速
- 缺点:对大模型或敏感层精度下降明显
- 案例:ResNet-50 PTQ INT8,Top-1 精度下降 ~1.5%
-
QAT(Quantization-Aware Training)
- 训练阶段模拟量化噪声
- 优点:精度更高
- 案例:ResNet-50 QAT INT8,Top-1 精度下降 <0.5%
-
源码示例(PyTorch PTQ/QAT 对比):
# PTQ
from torch.quantization import quantize_dynamic
quant_model = quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)
# QAT
from torch.quantization import prepare_qat, convert
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model = prepare_qat(model)
# 训练若干步后
model = convert(model.eval())
-
参考论文:
- Banner et al., “Post Training 4-bit Quantization of Convolutional Networks for Rapid-Deployment”, NeurIPS 2019.
- Jacob et al., CVPR 2018 (QAT 方案)。
2. 按精度范围
- 对称量化:零点固定为 0,适合权重
- 非对称量化:零点可变,适合激活值动态范围大
3. 按粒度
- 逐层量化(Per-Tensor):整张张量共享量化比例,硬件友好
- 逐通道量化(Per-Channel):每个通道独立量化,精度更高,适合卷积或注意力权重
4. 按硬件支持
- CPU(AVX512/ARM Neon):多为 INT8
- GPU(TensorRT / CUDA cores):支持 INT8 / FP16 / 混合精度
- TPU / NPU:支持 INT4 / INT8 / 混合低比特
五、量化方法(Quantization Methods)
1. Min-Max 线性量化
- 将数值区间 [ m i n , m a x ] [min, max] [min,max] 线性映射到整数区间 [ 0 , 2 b − 1 ] [0, 2^b-1] [0,2b−1]
- 优点:简单、高效
- 缺点:对异常值敏感
- 公式:
q = round ( x − x min x max − x min ⋅ ( 2 b − 1 ) ) q = \text{round}\left(\frac{x - x_\text{min}}{x_\text{max}-x_\text{min}} \cdot (2^b-1)\right) q=round(xmax−xminx−xmin⋅(2b−1))
2. 均匀量化(Uniform Quantization)
- 数值区间等间隔划分
- 优点:硬件友好,矩阵乘加高效
3. 非均匀量化(Non-Uniform Quantization)
- 使用对数量化或 k-means 聚类分配比特
- 优点:精度更高
- 缺点:计算复杂
- 适合分布偏斜的权重或激活
4. 混合精度量化(Mixed-Precision Quantization)
- 不同层采用不同比特位宽
- 核心层(注意力)使用 INT8,次要层使用 INT4
- 兼顾精度与效率
- 案例:Transformer 注意力层 INT8,其余 FP16,推理速度提升 1.5~2 倍
- 源码示例(HuggingFace + bitsandbytes):
from transformers import AutoModelForCausalLM
import torch
import bitsandbytes as bnb
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-13B",
load_in_4bit=True,
device_map="auto")
-
参考论文:
- Dettmers et al., “8-bit Optimizers via Block-wise Quantization”, ICLR 2022.
- Dettmers et al., “GPTQ: Accurate Post-training Quantization for Generative Pre-trained Transformers”, NeurIPS 2023.
5. 低秩近似 + 量化(Decomposition + Quantization)
- 对矩阵进行低秩分解,再量化
- 优点:减少参数冗余,降低内存占用
- 适用于大型 Transformer
- 案例:GPT 系列模型,低秩分解 + INT8 量化,可在单卡加载原本需多卡模型
- 源码示例(PyTorch SVD + INT8):
import torch
W = torch.randn(1024, 1024)
U, S, V = torch.svd(W)
rank = 128
U_low = U[:, :rank] * S[:rank]
V_low = V[:, :rank]
# 对 U_low, V_low 分别量化
-
参考论文:
- Wang et al., “A Survey of Model Compression and Acceleration for Deep Neural Networks”, arXiv 2020.
六、量化案例(Practical Cases)
- BERT INT8 部署:TensorRT/PTQ,FP32 → INT8 推理延迟降低 2~4 倍,精度下降 <1%
- GPT / LLaMA INT4 部署:bitsandbytes 库,LLaMA-13B FP16:52GB → INT4:13GB,单张 GPU 可加载
- QAT 在 ResNet-50 上:PTQ INT8 精度下降 ~1.5%,QAT INT8 精度下降 <0.5%
- 混合精度 Transformer:注意力权重 INT8,其余 FP16,推理速度提升 1.5~2 倍
七、量化工具(Tools for Model Quantization)
针对深度学习和大模型量化,目前有很多成熟的工具和库,可以支持 训练后量化(PTQ)、量化感知训练(QAT)、混合精度以及硬件加速部署。
1、通用量化工具
-
TensorRT(NVIDIA)
- 支持 FP16 / INT8 / 混合精度量化。
- 可以对 PyTorch / ONNX 模型进行推理加速。
- 提供 QAT 和 PTQ 流程。
-
ONNX Runtime(ORT)
- 支持 INT8 PTQ 和 QAT。
- 跨平台:CPU/GPU/NPU。
- 可与 PyTorch、TensorFlow 模型互操作。
-
OpenVINO(Intel)
- 支持 CPU / VPU / FPGA。
- 提供模型优化器和 INT8 推理量化工具。
-
TVM(Apache)
- 深度学习编译器,支持自定义量化策略。
- 支持多硬件后端(CPU/GPU/FPGA/嵌入式)。
-
TFLite(TensorFlow Lite)
- 面向移动端/边缘设备。
- 支持 FP16、INT8、全整数量化。
- 适合小型模型部署。
2、深度学习框架自带工具
-
PyTorch
- torch.quantization 模块:支持 PTQ、QAT、动态量化。
- bitsandbytes:专为大模型(如 LLaMA / GPT)提供 INT8 / INT4 量化工具。
- torch.ao.quantization:PyTorch 新的量化工具包,支持高级量化方案。
-
TensorFlow / Keras
- tf.quantization / TFLiteConverter:支持 PTQ、动态量化、QAT。
- Model Optimization Toolkit:提供量化感知训练与权重量化。
-
HuggingFace Transformers
- 集成 bitsandbytes,支持大模型 INT8 / INT4 推理。
- 提供 FP16 / BF16 混合精度训练接口。
3、硬件加速与编译工具
-
XLA(Accelerated Linear Algebra)
- TensorFlow / JAX 自动图优化和低比特支持。
- 可与量化结合实现高性能部署。
-
NVIDIA APEX / AMP
- PyTorch 混合精度训练(FP16 / FP32),可与 QAT 结合。
-
Intel Neural Compressor
- 提供 PTQ / QAT 工具。
- 自动搜索最优量化策略并生成可部署模型。
-
Qualcomm SNPE / Hexagon DSP
- 针对移动端 Snapdragon 处理器优化量化模型。
4、辅助工具与库
-
nncf(OpenVINO NNCF)
- 提供 QAT、剪枝、低秩分解等压缩工具。
-
Distiller(Nervana / Intel)
- 用于 PyTorch 的模型压缩和量化框架。
-
HuggingFace PEFT + 量化插件
- 用于大语言模型微调和低比特推理。
综上所述,大致可以分为三大类:
- 小模型 / 移动端:TFLite、ONNX Runtime、TensorRT。
- 大模型 / GPU / 多卡部署:PyTorch + bitsandbytes、TensorRT、ORT + QAT。
- 自动化量化与搜索最优策略:Intel Neural Compressor、OpenVINO NNCF。
八、总结与发展趋势
-
大模型量化涉及比特选择、量化对象、量化方法、量化分类与案例,依赖完整工具链支撑推理与部署
-
趋势:
- INT4 / 混合精度量化成为主流
- 自适应量化、学习型量化策略快速发展
- 与硬件协同优化,实现极致性能和低能耗
-
挑战:
- 超大模型量化精度控制
- 激活量化动态范围适配
- 与剪枝、低秩分解、知识蒸馏融合优化

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)