[Linux]从零开始的hailo8加速卡推理YOLO教程
讲解了如何在Hailo硬件上加速推理YOLO模型!
一、前言
最近接触到了hailo边缘计算加速芯片。我目前调试的这一款型号为hailo8,具有26Tops的算力,已经相当于3个3588的算力了。整体用下来感觉算力方面没得说,但是生态还差点意思,对于这个系列的芯片国内资料非常少,官方也只发布了针对某些开发板的demo程序,这也就间接导致了我们调试这款芯片非常困难,常常因为找不到demo程序,我们需要自己去翻官方文档。hailo融合的概念非常多,比如hailoRT,hailo_model_zoo,pyhailort等等。概念太复杂了,非常不适合新手。调试hailo在感觉上比我调试RK芯片更为困难。所以现在有了这篇文章,我会将我调试hailo的经历分享出来,当然,也只是作为一个参考,对于不同的开发板,不同的内核,以至于不同的hailo计算卡,不同的pcie驱动版本,这些步骤都不可能完全一样。如果你准备好了,就让我们开始吧!
二、谁适合本次教程
在本次教程中,涉及到了YOLO,Linux,python等诸多概念,已经不是面向纯小白的了,所以,在开始之前,请你一定要确保自己具备上述基础。在教程中,一些简单,通用的概念我可能只会简单提及甚至一笔带过,所以,在开始之前,请确保你自己一定有基础。
三、整体流程
现在我们先来梳理一下使用hailo计算卡推理YOLO的整体流程。首先我们需要使用YOLO训练一个自己的模型,这里我使用的是YOLOv8,然后使用onnx库将我们训练出来的pt格式的模型转换为onnx格式。然后需要在Linux中搭建hailo_model_zoo的环境,我们需要使用hailo_model_zoo环境将一开始得到的onnx格式模型转换为hef格式,至此我们模型转换就完成了。然后我们需要在板端安装好hailo的pcie驱动(一般卖家提供,如果没有提供或者是自己搭配的板子与计算卡,那么极有可能你需要自己编译驱动,编译驱动需要借助你板子的内核源码进行编译,这是一个非常麻烦的过程)。当我们hailo计算卡的pcie驱动正确以后,就可以在板端安装hailoRT了,这里hailoRT的版本需要和我们的pcie驱动对应(hailoRT的运行依赖了hailo-pcie,不要存在侥幸心理,版本差0.1你的hailoRT都装不上去)。然后就是需要在板端安装python,我们利用python创建一个虚拟环境,在这个python虚拟环境中我们安装hailoRT的python包,这里被俗称pyhailoRT(这里需要注意,pyhailoRT依赖了我们上面安装的hailoRT,所以这里需要先装hailoRT),完成上面的步骤以后,环境配置就差不多了,我们需要用python代码来运行我们的模型,到了代码这一步就来到了最困难的一步,如果你使用的是树莓派搭配hailo,那么恭喜你,hailo官方提供了现成了demo代码。如果你使用hailoRT,hailo-pcie,pyhailoRT版本都在4.22以上,那么同样恭喜你,官方提供了现成的demo代码。如果你不属于上面的情况,那就非常麻烦了,hailo4.22以下的版本官方几乎没提供任何demo代码,只有API文档,你需要参考这个文档进行编程。当然,如果你处于第三种情况也不用担心,因为我也正处于这种情况,后续会教大家如何解决。
上面就是使用hailo推理YOLO的基本流程,现在让我们开始吧!
四、YOLO的训练与ONNX模型转换
这里我会使用YOLOv8进行展示,如果你对YOLO的环境搭建与训练不是很了解,可以看下面的教程:
YOLO环境搭建:[AI]小白向的YOLO安装教程-CSDN博客
YOLO的训练:[AI]YOLO如何训练对象检测模型(详细)_yolo模型训练-CSDN博客
这里YOLO的环境搭建与训练都比较简单,我也就不多说了,我下面的操作会默认大家已经搭建好了YOLO的训练环境。
我们需要hailo推理YOLO模型,所以首先我们就需要训练一个YOLO模型,这里我从网络上下载了一个开源的识别杯子的数据集:
这里我们将其放到YOLOv8目录下的datasets如图所示,这里默认大家都会训练,就不多说了:
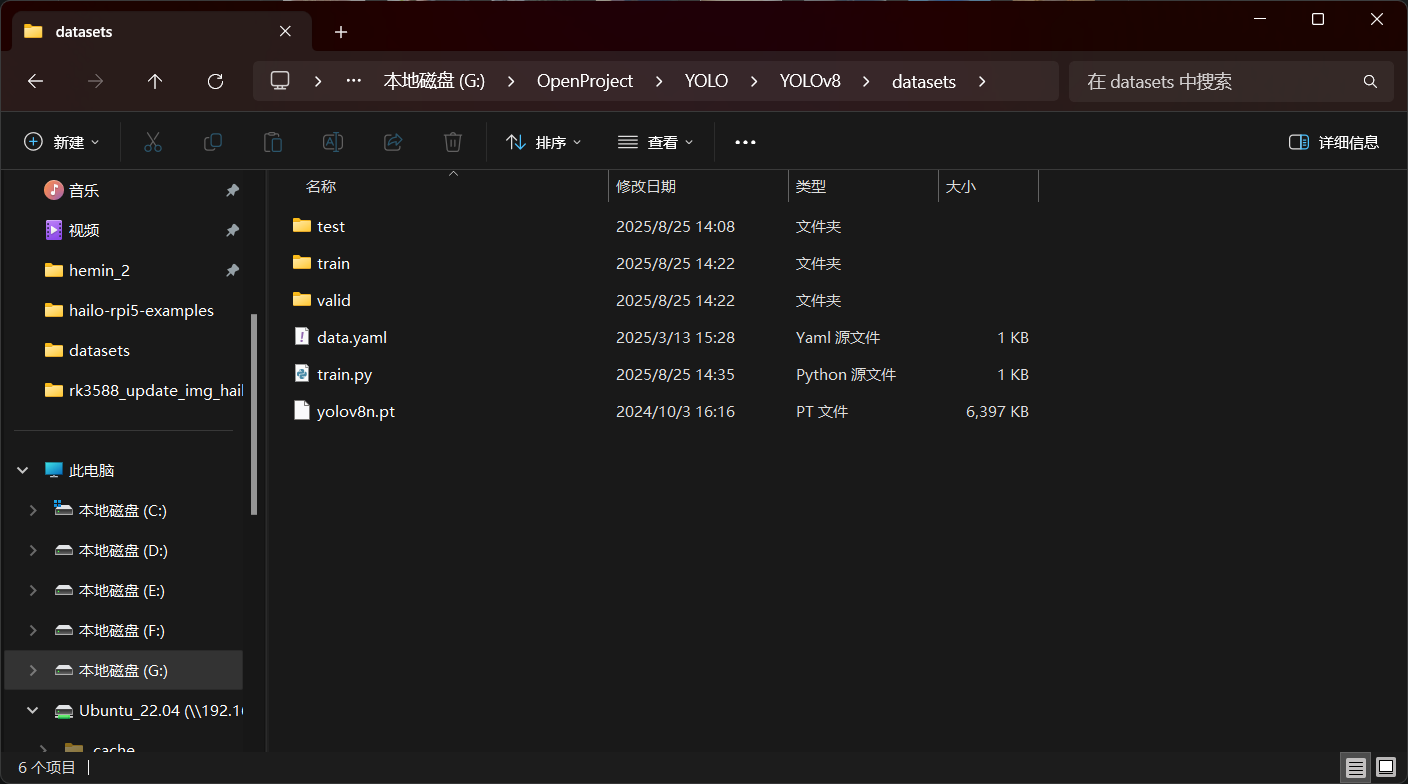
我的data.yaml内容如下:
train.py文件如下:
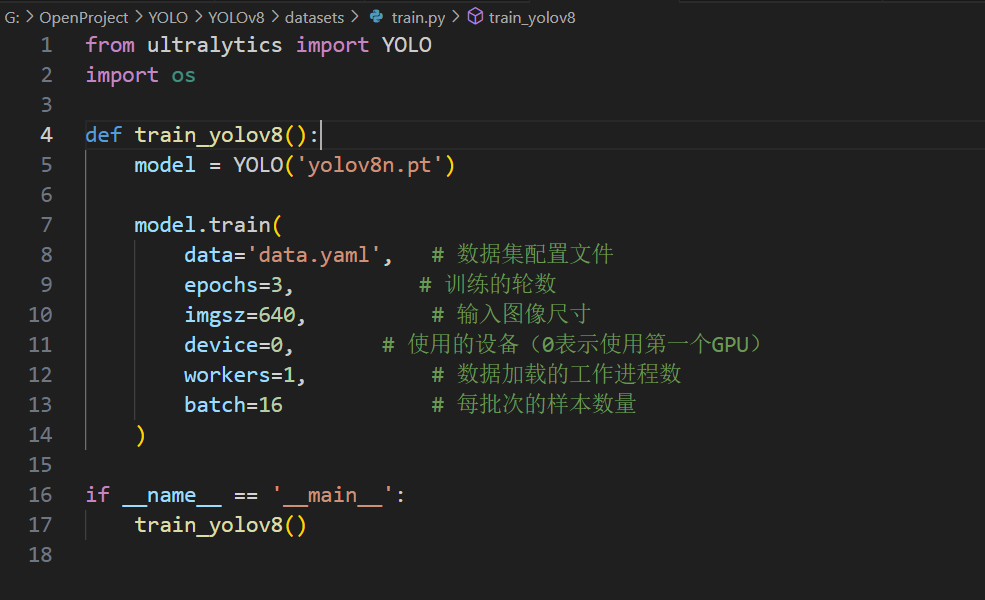
因为我这里的数据集有好几千张,所以就只训练三步,大家根据自己的情况调整训练步数即可。
训练完成后的文件夹如图所示:
pt模型在weights文件夹中:
这里我们训练得到pt文件以后,需要将其转换为onnx格式,在转换之前需要安装一下相关的库,直接使用下面的命令安装onnx库即可:
pip install --no-cache-dir "onnx>=1.12.0"安装完相关onnx库以后,我们就可以来转换模型了,这里我们进入有pt文件的文件夹,执行下面的命令:
yolo export model=./best.pt imgsz=640 format=onnx opset=11这里的参数很好理解,就不多说了。
执行以后,就可以看到下面的内容了:
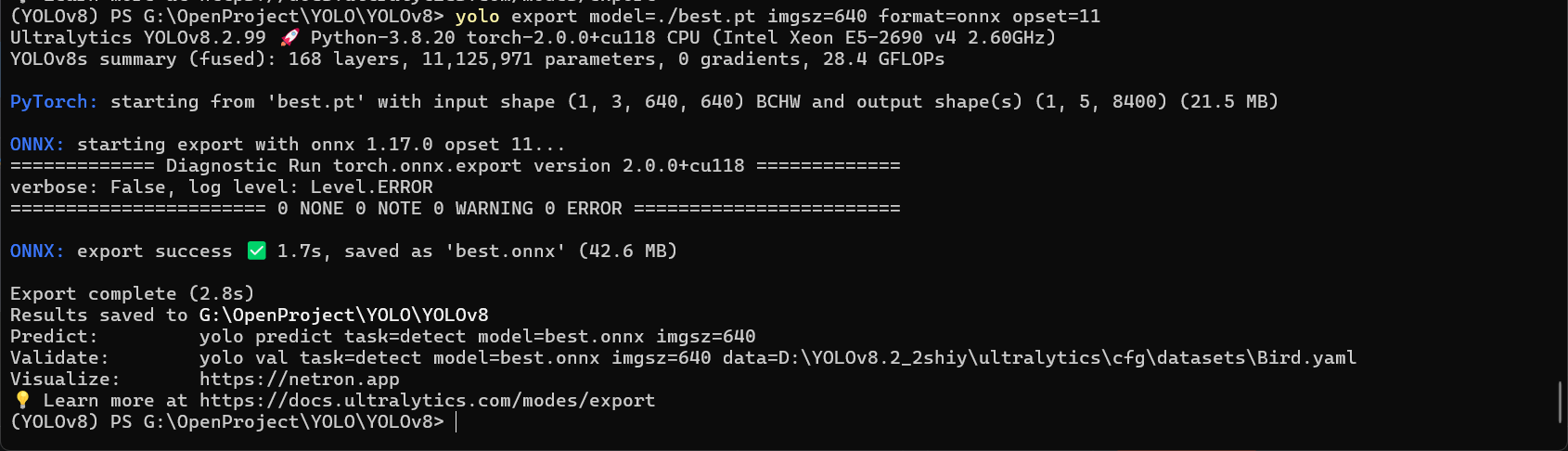
我们的模型输出为了一个与pt文件同名的onnx文件。至此,我们YOLO的训练与模型转换就完成了。
五、VM虚拟机配置及HEF模型转换
当我们得到onnx文件以后,就可以来转换hef文件了。这里我们需要在Linux环境中进行,这里我使用的是VM虚拟机,大家根据自己的情况进行操作即可。如果你还不会创建虚拟机,可以看下面的文章:
VM安装及虚拟机创建:[Linux]如何在虚拟机安装Ubuntu?(小白向)_虚拟机 ubuntu-CSDN博客
这里我使用的是Ubuntu22.04的系统,为了完整还原整个过程,我将新建了一个虚拟机,新建完成如图所示:
为了方便我们后面命令操作的方便,这里先来安装一下ssh相关的库,直接使用下面的命令:
sudo apt install openssh-server net-tools安装完成以后,我们就可以查询到我们虚拟机的IP地址了:
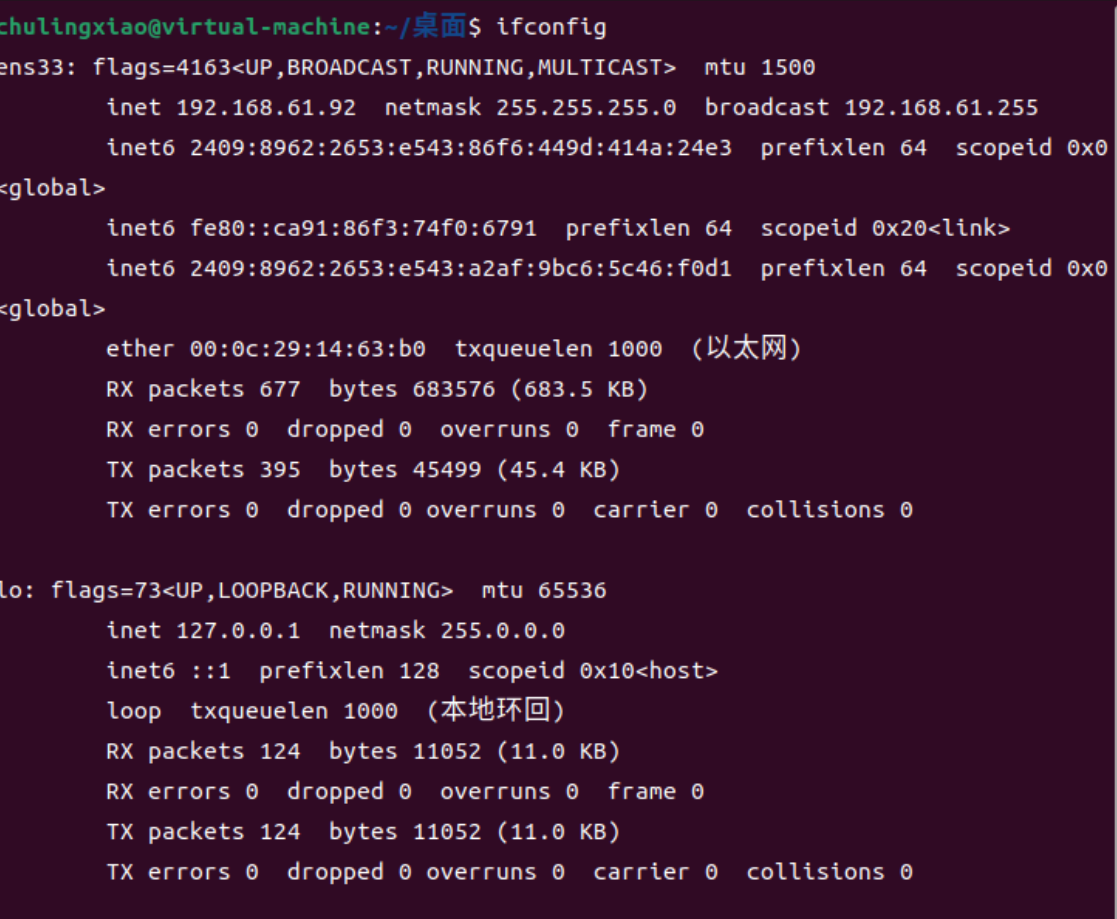
这里我们直接在windows中使用powershell远程即可:
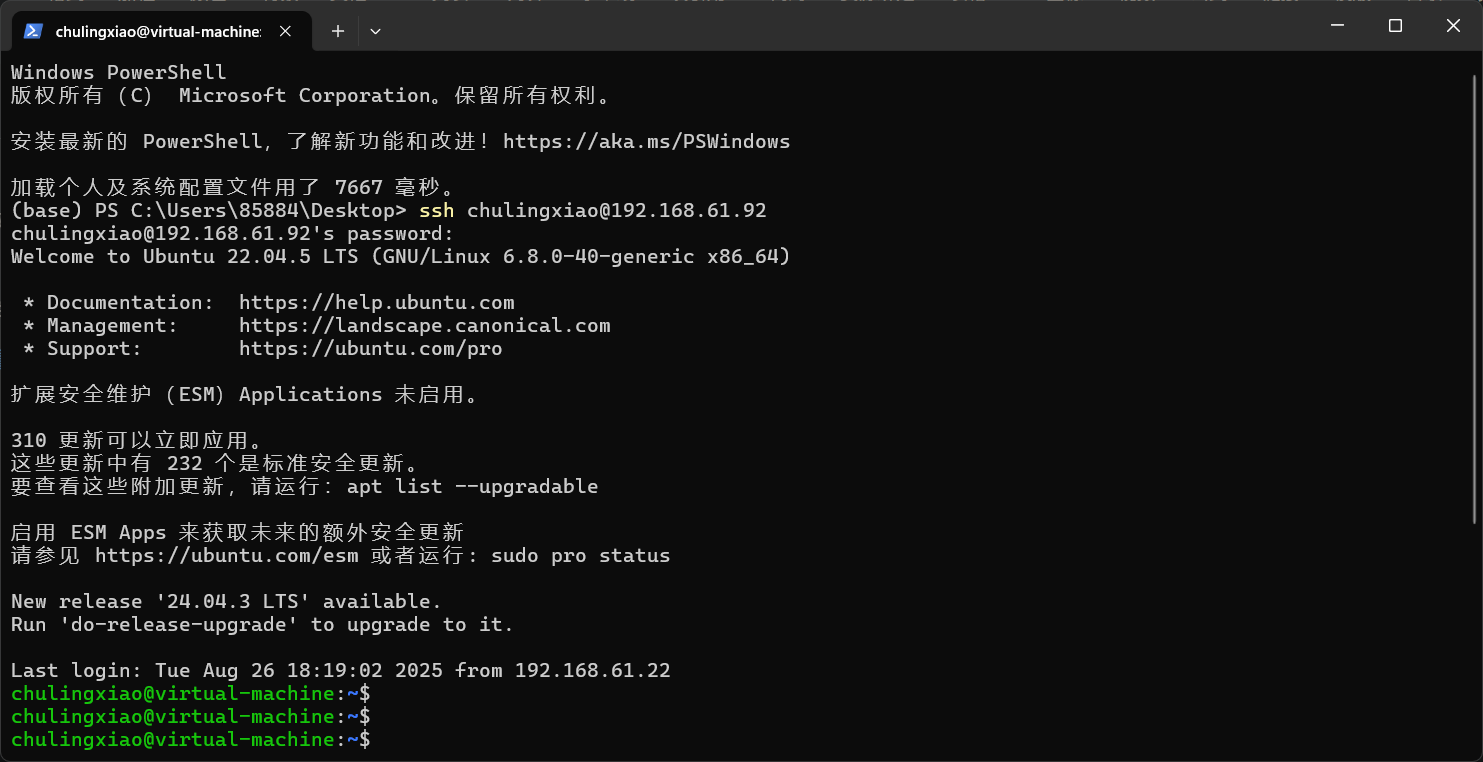
这样我们后续复制命令就会方便很多。
这里我们首先要把hailo_model_zoo的项目克隆下来,hailo_model_zoo主要用于模型转换与训练,我们这里只讲模型转换。
要克隆项目我们就需要git,这里我们直接使用下面的命令安装一下git:
sudo apt install gitgit安装完成以后,使用下面的命令克隆hailo_model_zoo:
git clone https://github.com/hailo-ai/hailo_model_zoo.git如果你在克隆时遇到问题,可以使用下面的命令配置一下git的代理,这里大家将代理的地址和端口号修改为自己的即可:
git config --global http.proxy http://192.168.61.22:7897
git config --global https.proxy http://192.168.61.22:7897克隆完成以后,得到以下文件夹:

hailo的运行依赖了python环境,这里我们需要安装conda来实现python的虚拟环境,我们可以直接在浏览器中搜索“miniconda”:
一般搜出来的第一个就是miniconda的官网,当然也可以点击下方的链接前往:
miniconda:Miniconda - Anaconda
进入以后,就可以看到如下界面了:
随后点击左边选框的“Installing Miniconda”来到以下界面:
然后这里我们选择“Basic install instructions”下的“macOS/Linux installation”:
然后我们点击“Linux terminal installer”下的“Linux x86”:
我们这里将miniconda的安装脚本的下载链接复制下来:
我们直接把下载命令粘贴到终端下载即可:

如果你在下载时出现了卡住的情况,可以使用下面的命令配置一下代理:
export http_proxy="http://192.168.61.22:7897"
export https_proxy="http://192.168.61.22:7897"下载完以后,使用下面的命令取消代理,这里的代理尽量取消掉,不然Ubuntu的任何流量都会走代理。
unset http_proxy
unset https_proxy下载完成以后,得到下面的shell脚本文件:
我们直接使用下面的命令运行这个脚本文件即可:
bash Miniconda3-latest-Linux-x86_64.sh运行以后,这里让我们看协议,我们直接回车即可:

然后问我们要不要同意,我们直接输入yes回车即可:
下面问我们Miniconda的安装位置,这里安装位置默认为用户目录下,我们直接回车即可:

回车以后,就进入了安装步骤:
这里在问我们是否希望修改你的 Shell 启动配置文件,以便让 Conda 在每次打开终端时自动启动?,我们输入yes回车即可:
这一步完了以后,我们的conda就安装完成了:
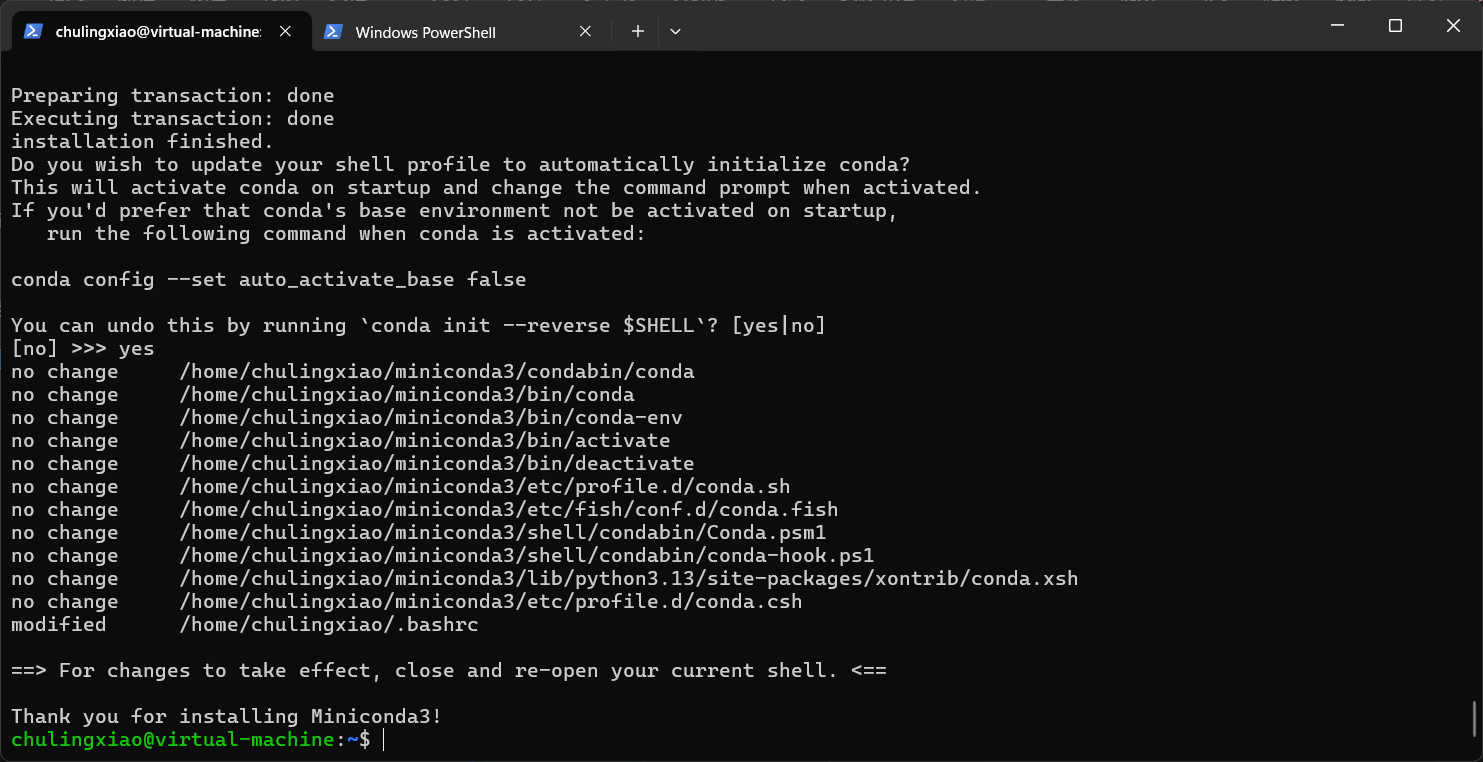
安装完成以后,我们使用下面的命令刷新一下环境变量,这样我们的conda就被正常加载了:
source ~/.bashrc
conda安装完成以后,我们使用下面的命令来创建一个针对与hailo_model_zoo的虚拟环境:
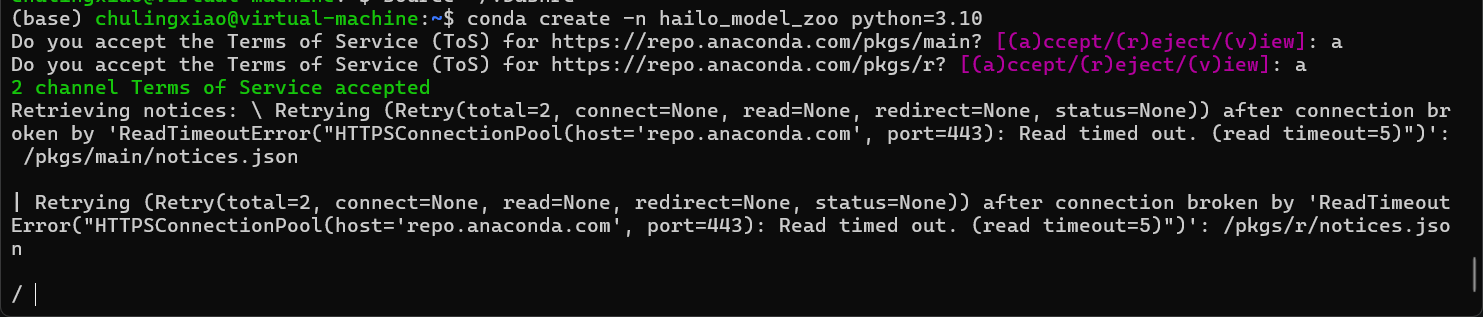
conda create -n hailo_model_zoo python=3.10这里在我们是否接收conda仓库的条款,我们输入“a”回车即可:

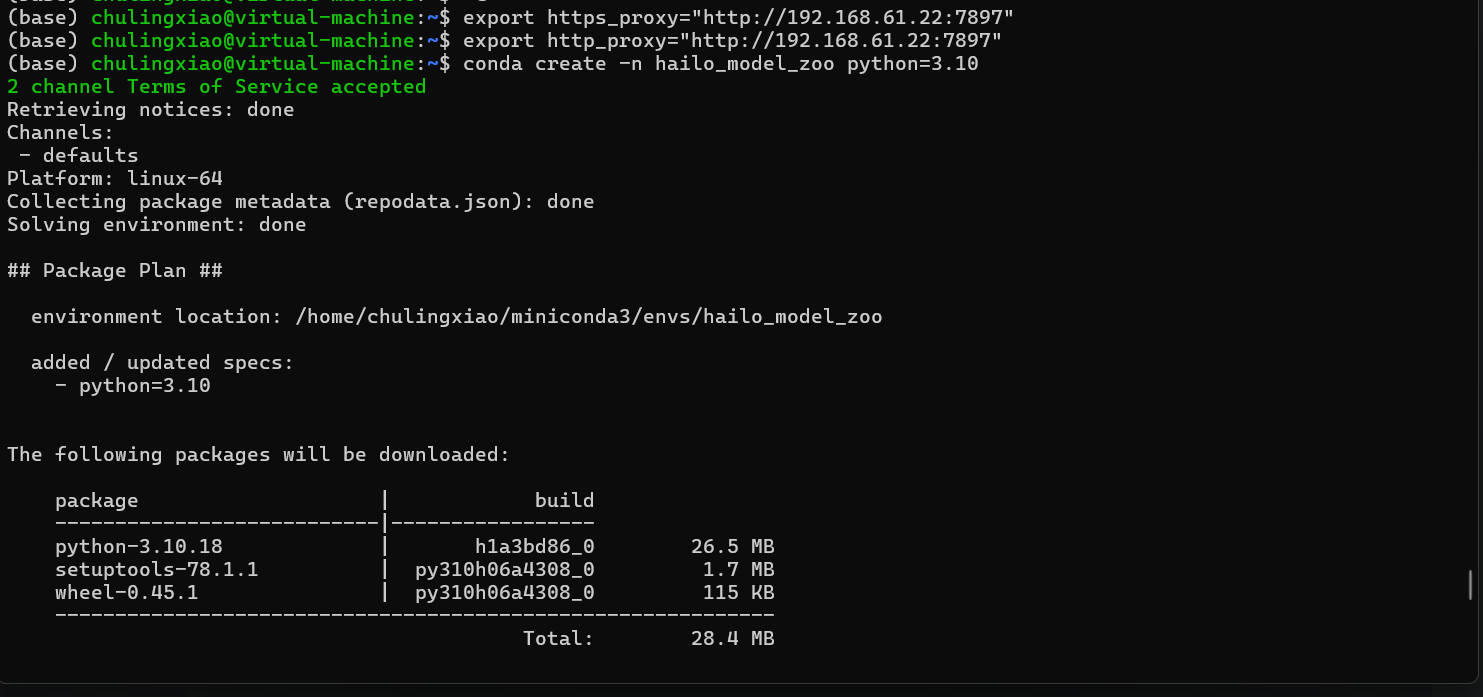
如果你出现了下面这样的情况,可以尝试把代理配回去,我实际测试下来,配置了代理后,环境可以正常创建了:
当然,也可以考虑换源,下面我来演示一下,直接用下面的命令,在用户目录新建一个名为“.condarc”的文件:
touch ~/.condarc然后用你熟悉的编辑器打开这个文件,将下面的内容粘贴到文件中:
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud这样就换镜像源完成了。
新建完conda虚拟环境后,我们使用下面的命令进入虚拟环境:
conda activate hailo_model_zoo进入虚拟环境以后,我们先不着急去安装hailo_model_zoo的环境,我们预先安装一些库,防止在安装hailo_model_zoo的环境时报错,直接执行下面两条命令即可:
sudo apt install -y graphviz graphviz-dev pkg-config gcc g++ makeconda install -c conda-forge lap这几个库安装完成以后,我们就可以开始配置hailo_model_zoo的环境了,我们直接使用下面的命令进入hailo_model_zoo的项目目录:
cd hailo_model_zoo然后执行下面的命令来安装相关库:
pip install -e . -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package输入命令回车以后,可以发现,报错了,这里告诉我们缺少hailo相关的依赖包:
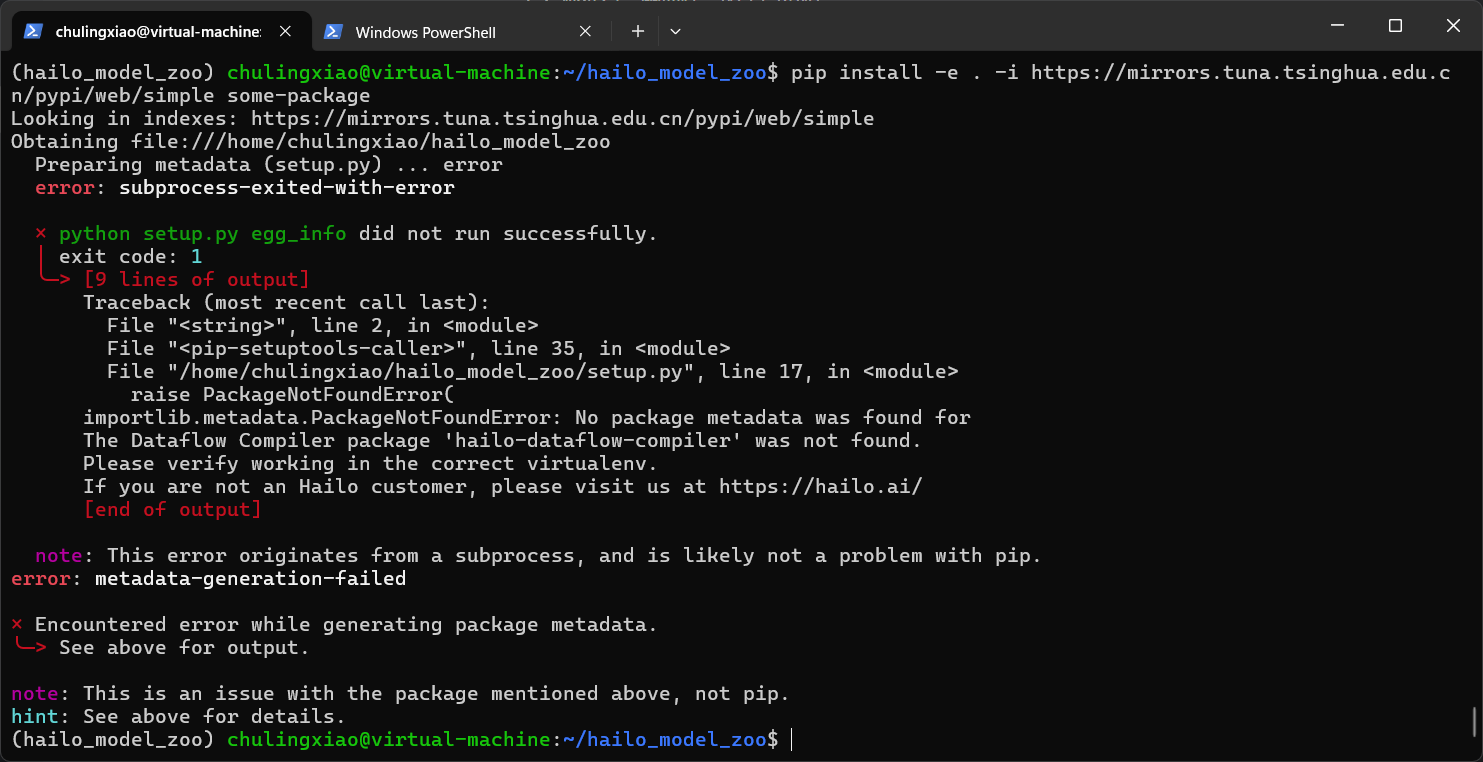
这些与hailo相关的包在pip源中没有,只能去hailo官网下载,下面教大家如何下载。
我们首先使用下面的链接前往hailo的官网:
hailo:Hailo AI on the Edge Processors | Edge AI Chip Solutions
进入以后,可以看到下面的界面:
这里我们需要点击右上角的头像注册并且登录我们的hailo账号:
登录完成以后,如图所示:
然后我们点击右上角的“Developer Zone”进入开发者社区:
进入以后,可以看到以下界面:

我们点击界面中的“SW Download”来到软件下载界面:
软件下载界面如图所示:
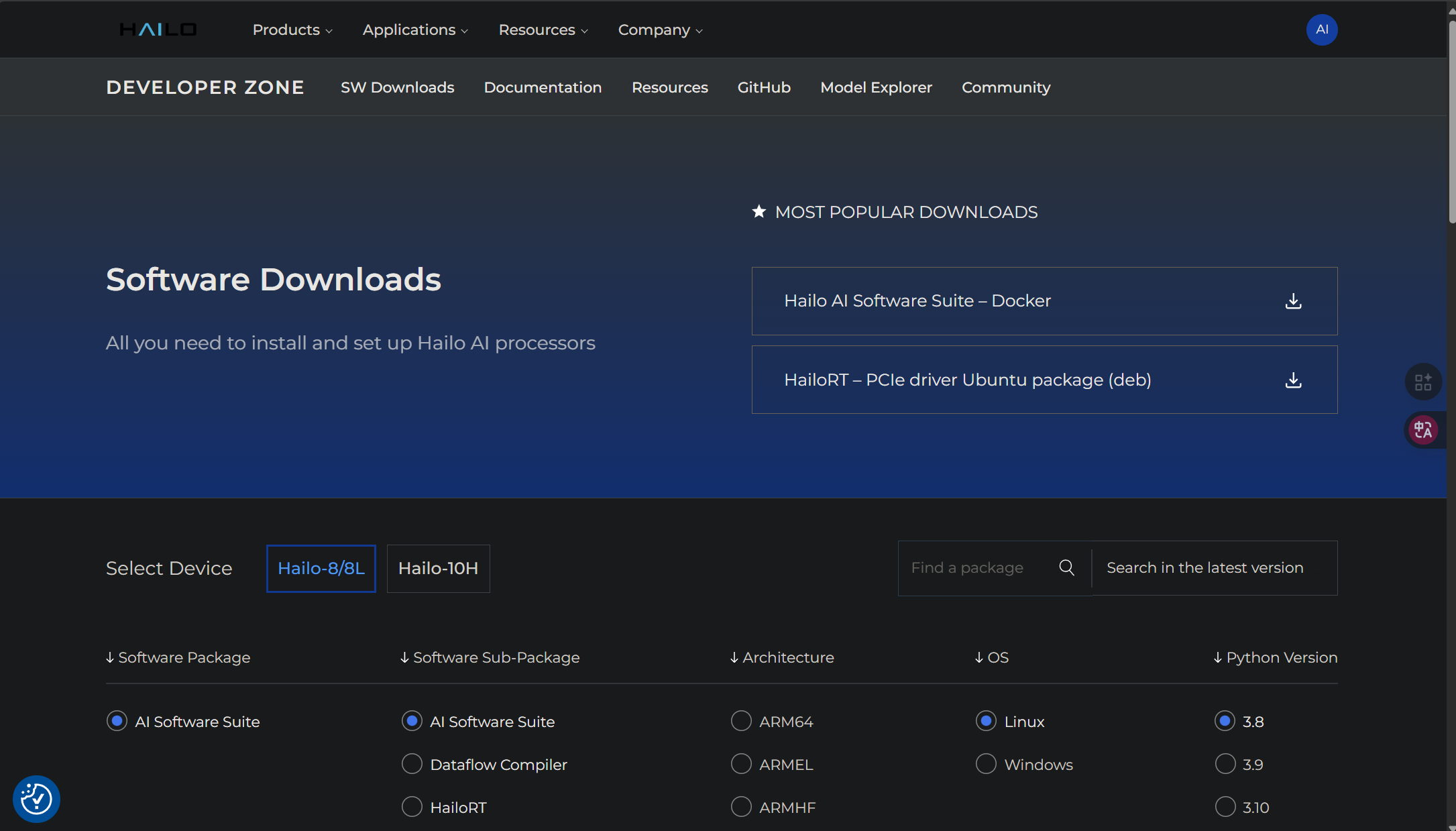
这里我们需要下载“Dataflow Compiler”的whl包。下面我来演示如何下载,首先我们需要选择我们hailo计算卡,这里我的计算卡是hailo8所以就选择了第一个:
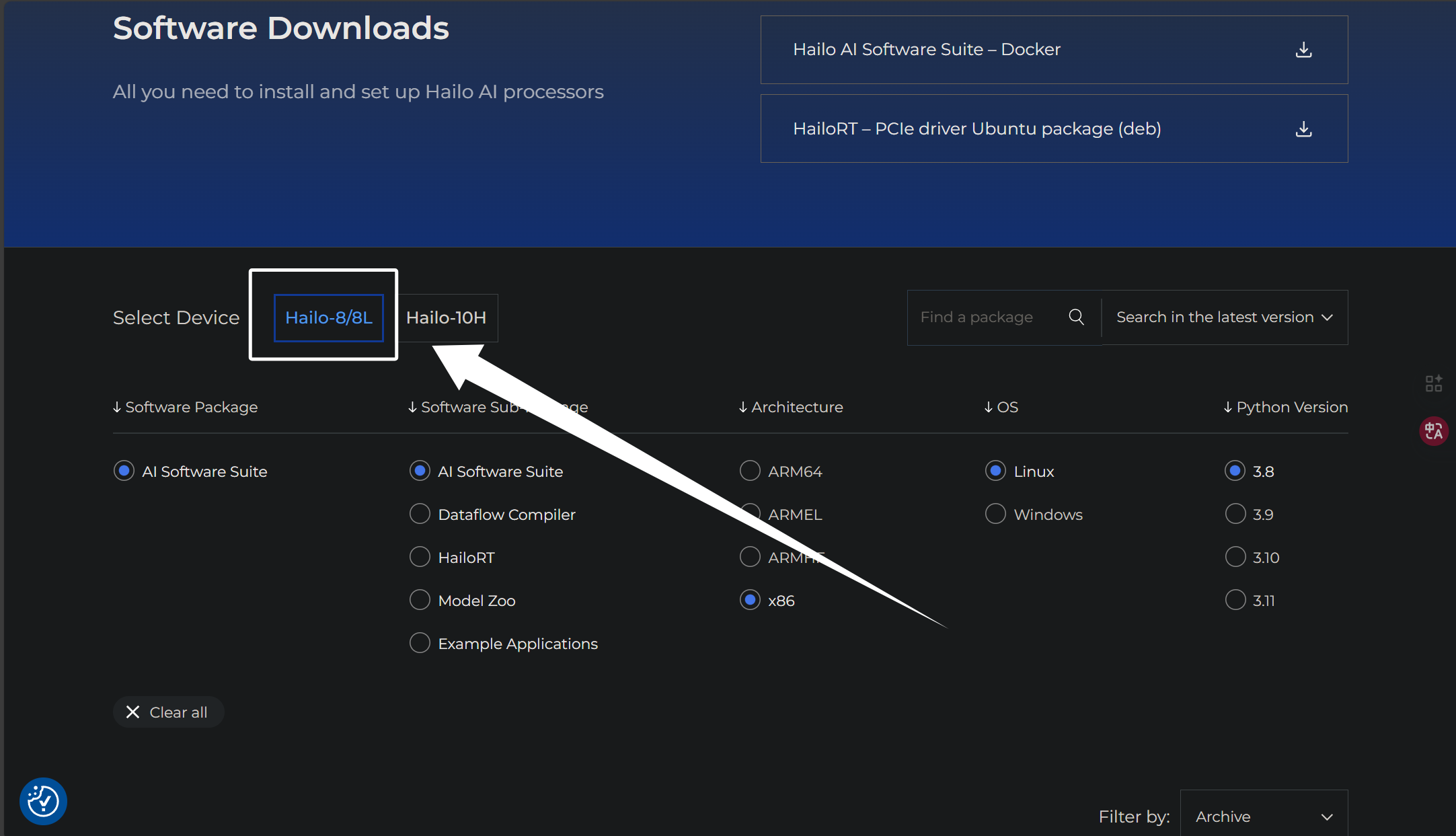
我们首先来下载“Dataflow Compiler”,首先在下方的选框中,选择“Dataflow Compiler”,架构选择X86,系统选择Linux,python版本就是我们一开始创建虚拟环境时的python版本,即3.10:
选择完成以后,我们往下拉就可以看到,它已经列举出了与我们选项符合并且最新的“Dataflow Compiler”的whl包: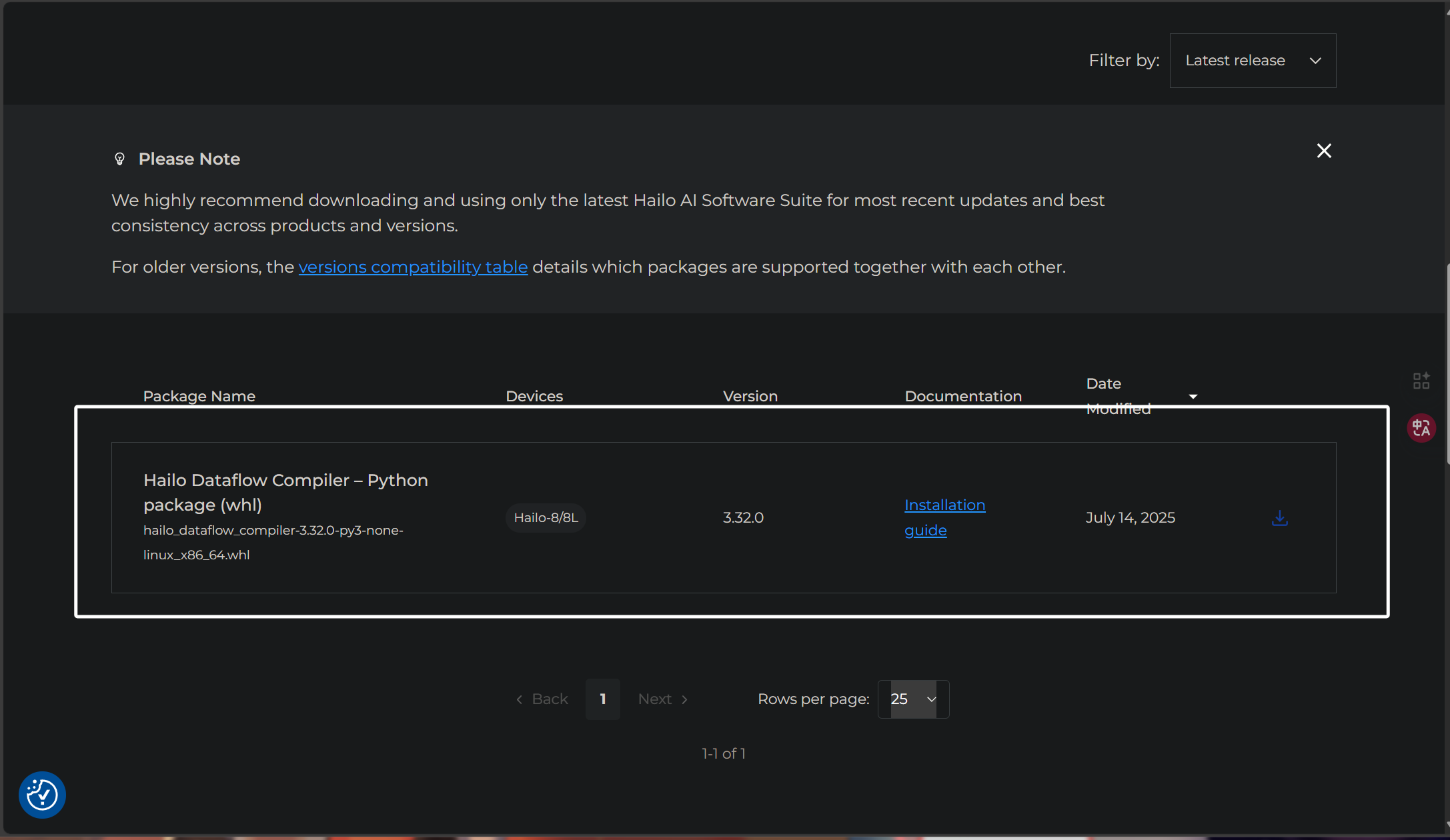
下载完成以后,得到以下文件: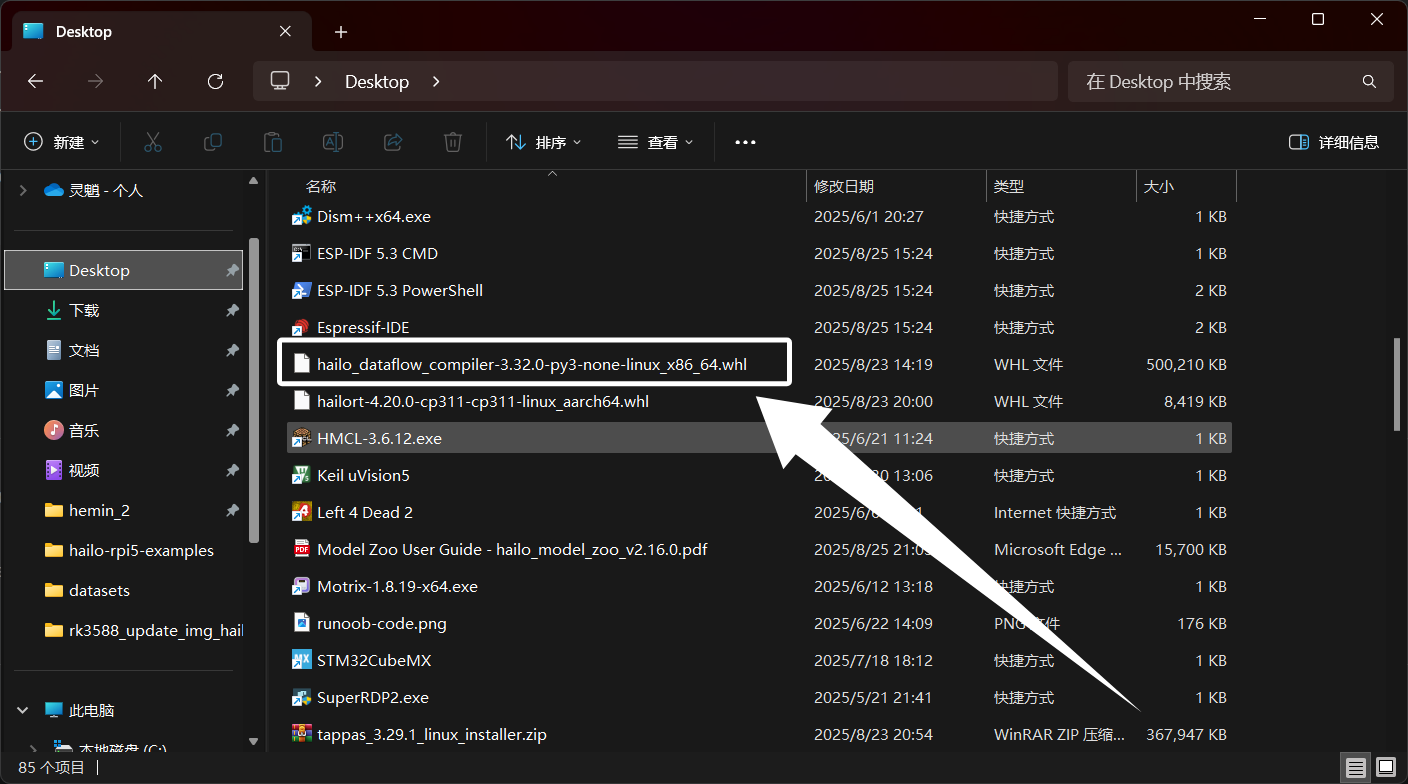
我们将我们下载完成的“Dataflow Compiler”whl文件传到Ubuntu中,完成以后如图所示:

我们直接在虚拟环境中,使用pip安装这两个包即可:
pip install hailo_dataflow_compiler-3.32.0-py3-none-linux_x86_64.whl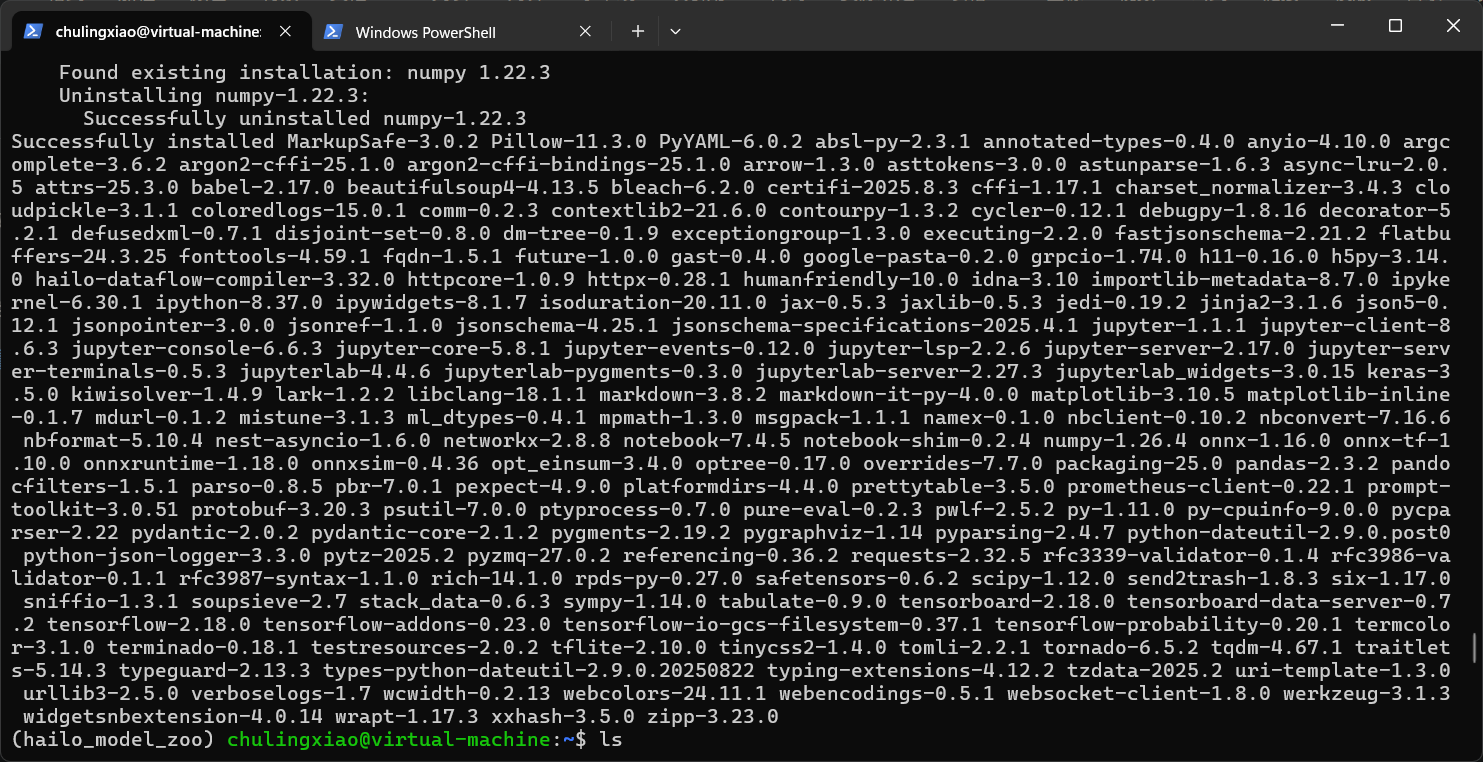
如果觉得中途下载库太慢了,可以在命令后面加上下面的镜像源:
-i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package安装完上面两个依赖库以后,我们再次到hailo_model_zoo目录执行下面的环境安装命令:
pip install -e . -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package可以看到,这次已经不报错了:
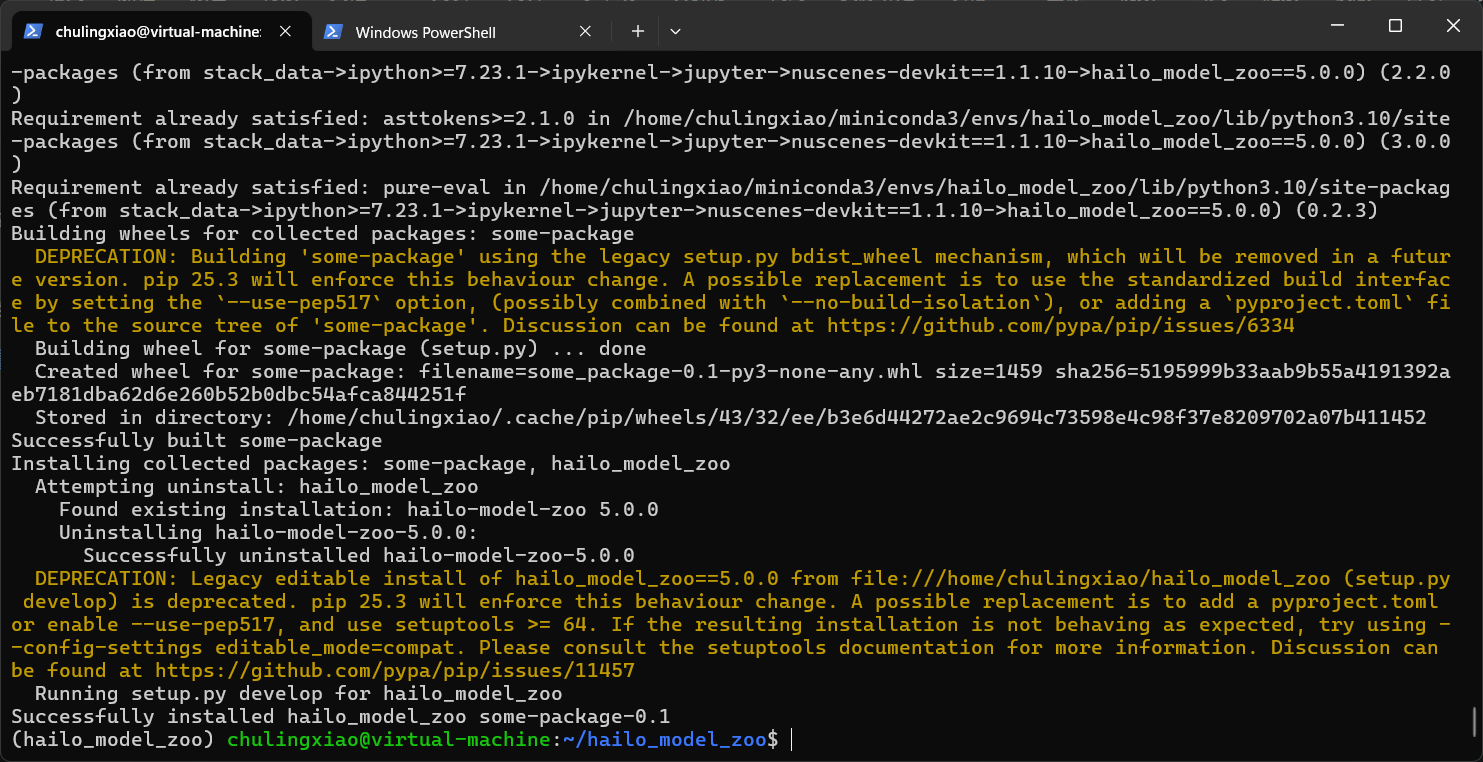
至此,我们hailo_model_zoo的环境就安装完成了。
我们可以直接在虚拟环境中输出hailo来看看效果:
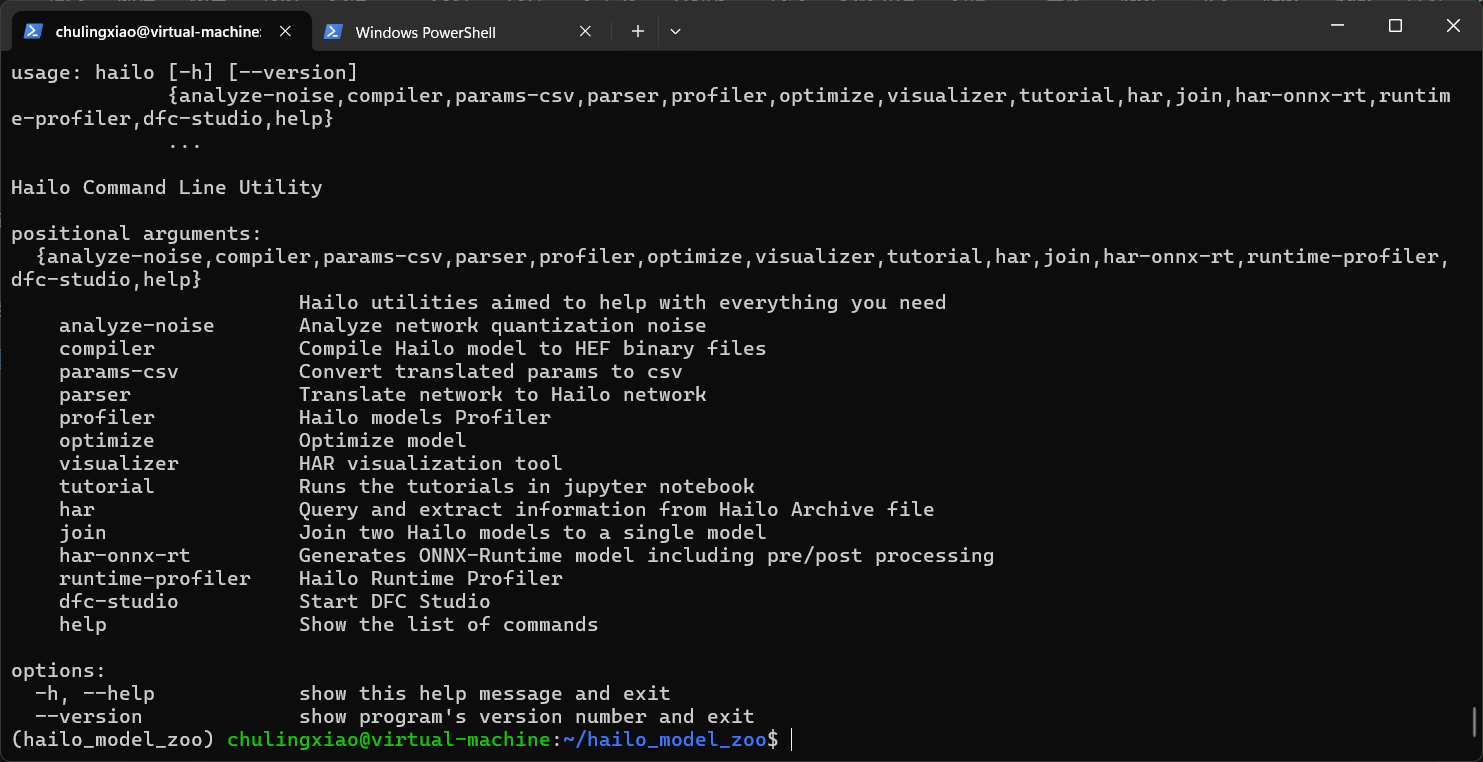
当我们安装好hailo_model_zoo的模型以后,就可以来进行模型转换了,我们将我们之前转换得到的onnx模型复制到hailo_model_zoo的项目目录中,如图所示:

这里我们使用还需要将我们训练时用到的数据集拿过来一些,这里拿500~1000张就行,我们在hailo_model_zoo的项目目录下新建一个名为“images”的文件夹,将我们的数据集放进去,如图:
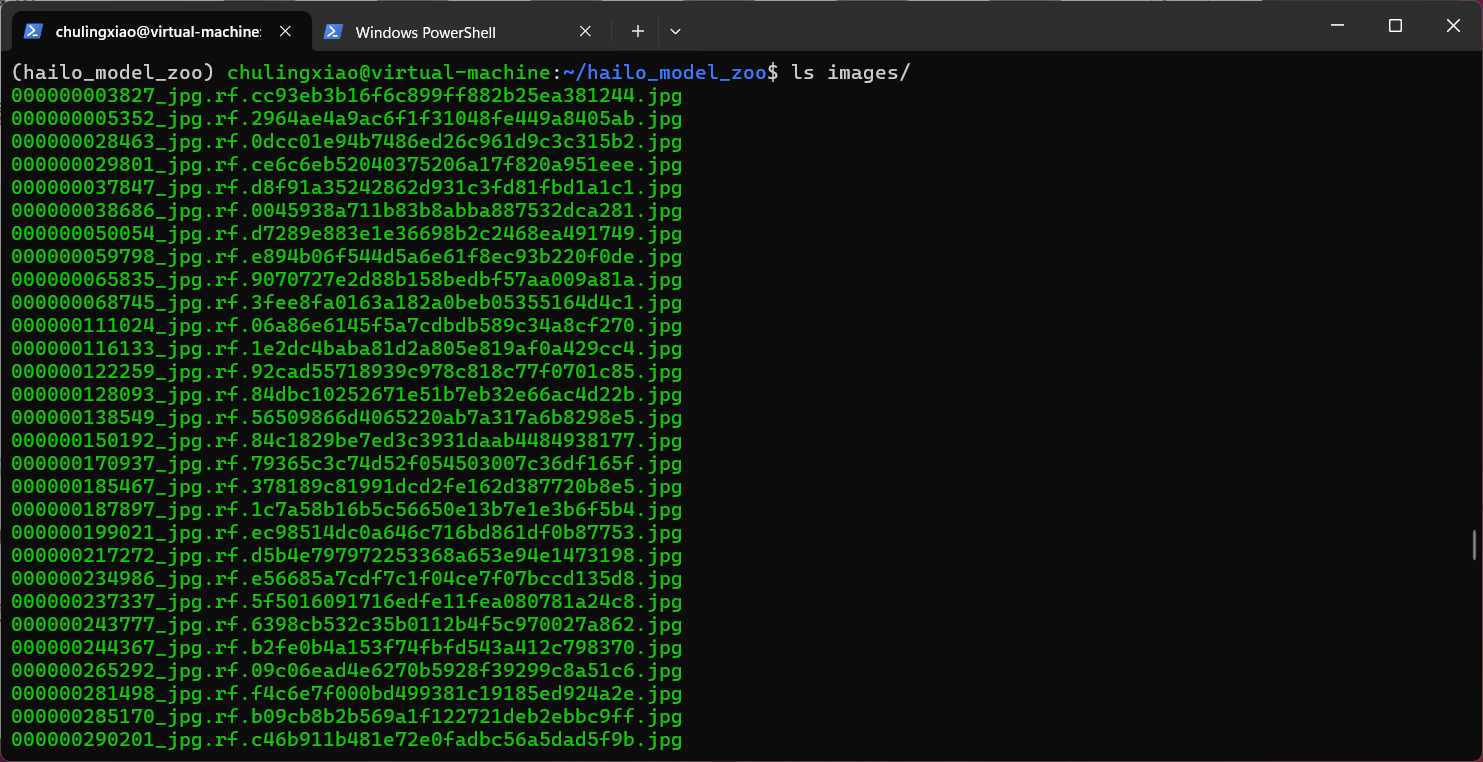
这里只需要图片即可,即images文件夹下只包含我们训练时用的数据集的图片。
完成以后,我们使用下面的命令来转换模型:
hailomz compile --ckpt best.onnx --calib-path ./images --yaml ./hailo_model_zoo/cfg/networks/yolov8n.yaml --classes 9下面我来简单解释一下这些参数,
--ckpt 表示我们要转换的模型的路径,这里需要指向我们的onnx文件。
--calib-path 表示我们数据集的路径,这里就指向我们刚刚复制过来的数据集。
--yaml 表示模型转换时配置文件的位置,这里我们直接使用官方的配置文件。大家根据自己底模选配置文件。
--classes 表示我们模型中包含物品的数量,这里一定要和训练时对上。这关系到后面的推理代码。
如果想要了解更详细的参数,以及yaml配置文件的格式,可以看hailo_model_zoo的文档:
hailo_model_zoo文档:文档 |海洛
这里没办法直接把文档网址复制过来,大家自己进去选Model_zoo即可。
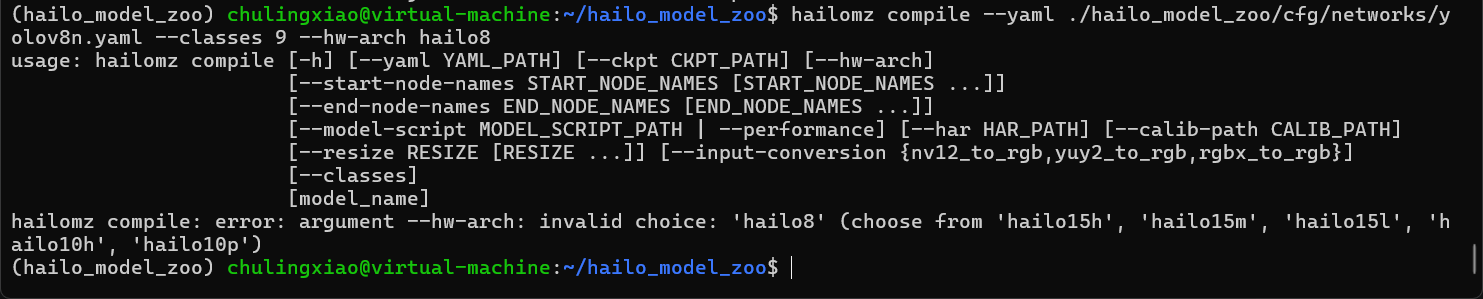
输入命令回车以后,模型转换就开始了,但是我们会发现,出现了错误:

是哪个环节出了问题?
因为我们克隆了最新的hailo_model_zoo源码版本为5.0,我们使用pip list就可看到:
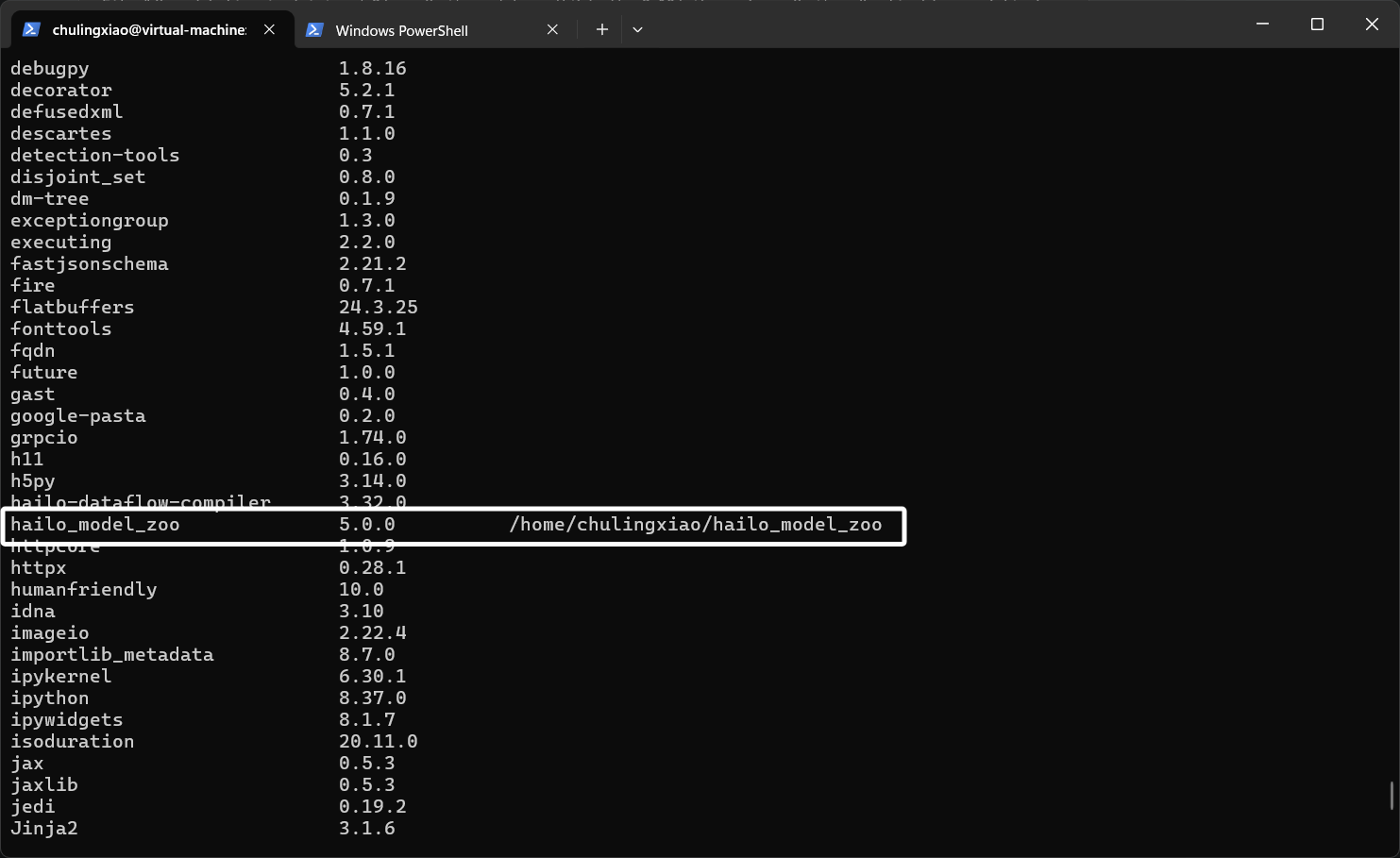
这个版本是不支持hailo8芯片的,即使我们转换模型时指定芯片,也会被提示不支持:
我们使用下面的命令将我们hailo_model_zoo的版本切换到2.16:
git checkout tags/v2.16 -b version-v2.16可以看到,我们已经切换过来了:

然后我们再次执行依赖库安装命令:
pip install -e . -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package这次安装完以后,就可以看到,我们hailo_model_zoo的版本就是2.16了:
我们再次使用模型转换命令:
hailomz compile --ckpt best.onnx --calib-path ./images --yaml ./hailo_model_zoo/cfg/networks/yolov8n.yaml --classes 9 --hw-arch hailo8这里新增了一个--hw-arc参数来指定我们的芯片。
过一会儿就可以看到我们的模型转换已经开始了:
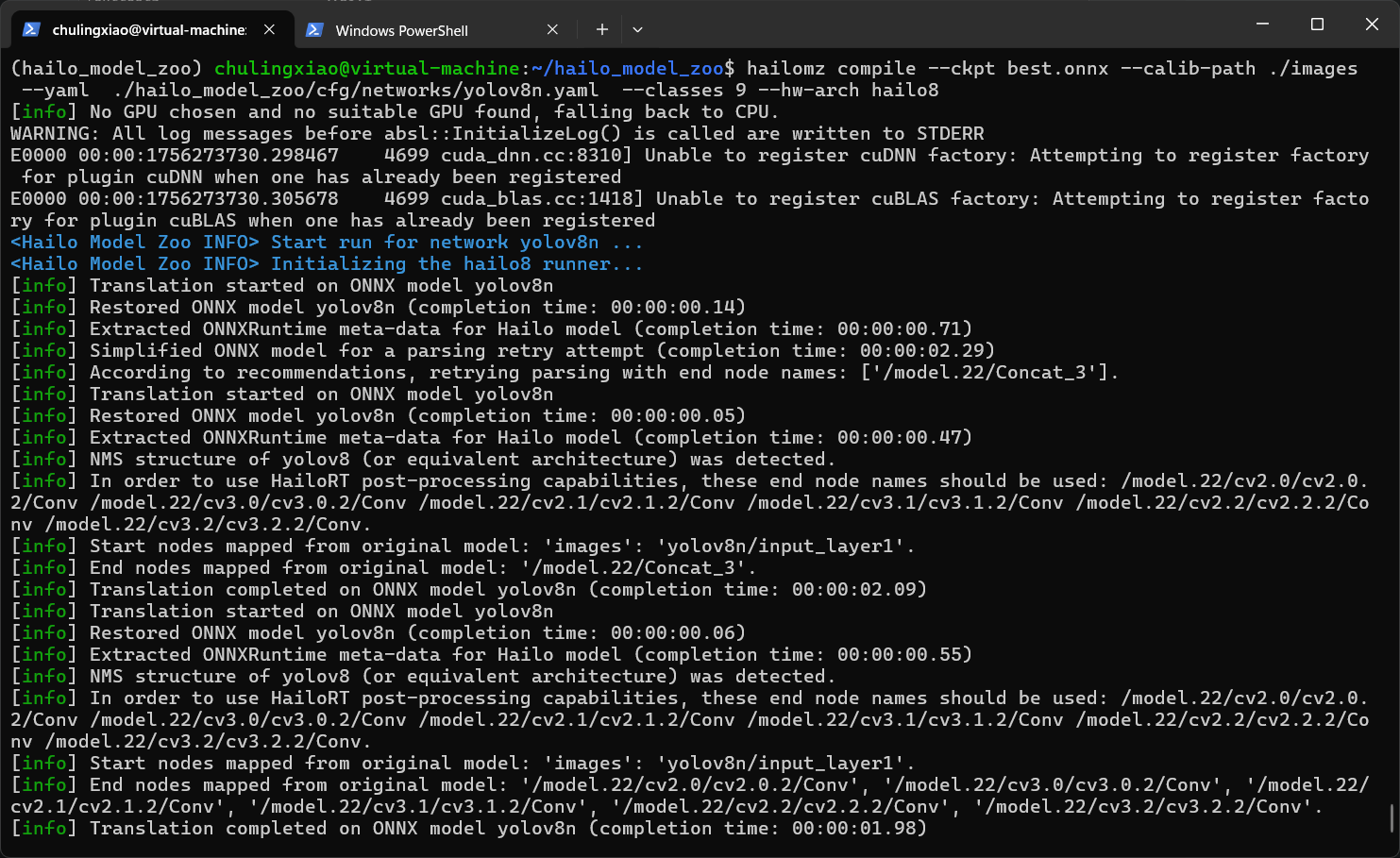
这里模型转换需要一阵子,大家耐心等待。
当出现这样的提示以后,表示我们的模型已经转换完成了:
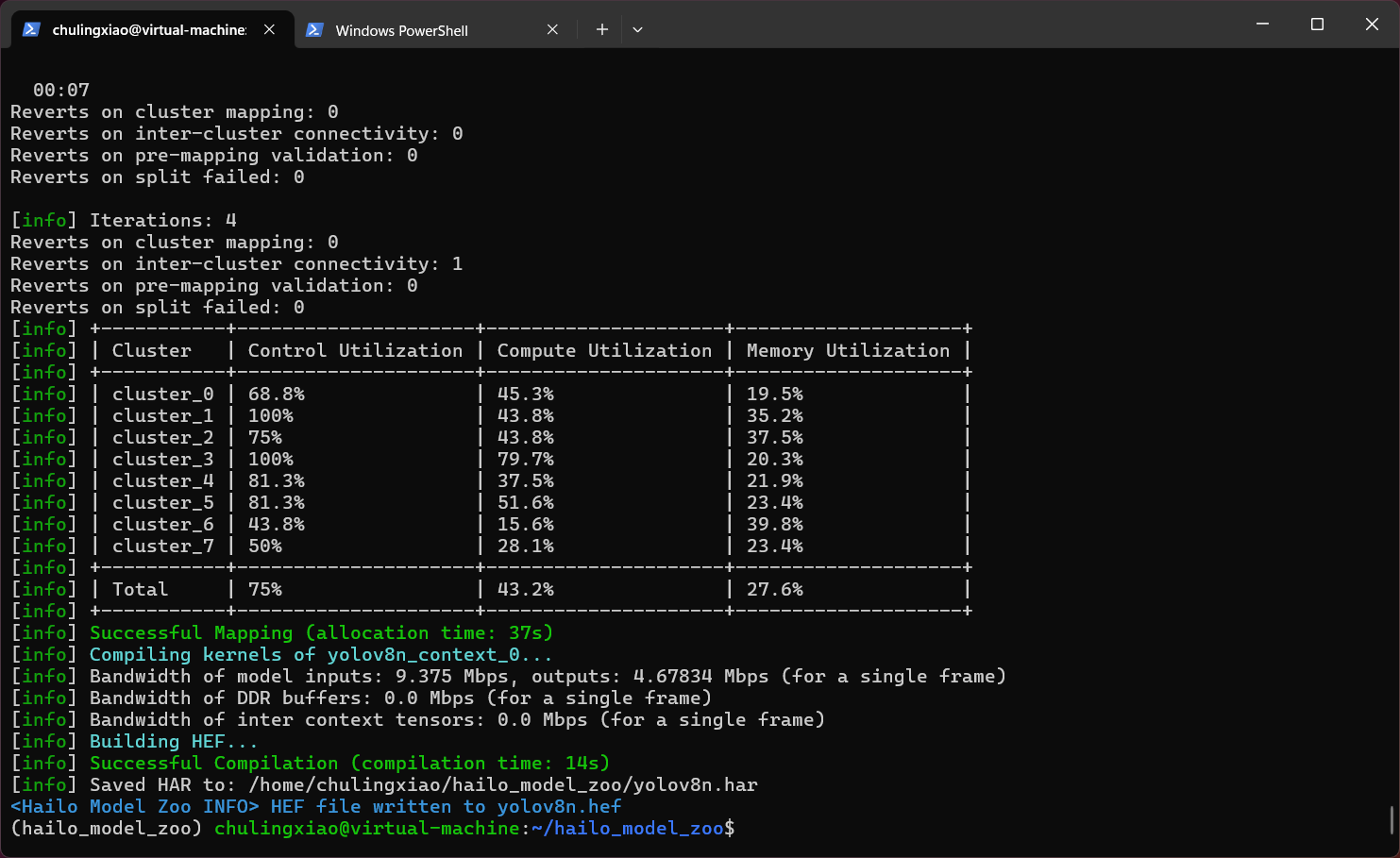
可以看到,我们的模型输出为了一个名为“yolov8n.hef”的文件。在hailo_model_zoo的项目目录中就能看到:
这就是我们转换出来的模型文件了。至此,hef模型转换就完成了。
六、板端配置及hailo模型推理
当我们转换完模型以后,就可以来配置开发板一侧了,这里开发板一侧首先需要我们将网络远程配通,我们可以通过ssh远程到开发板:
这里我使用的是鲁班猫3588开发板,大家根据自己的开发板配置即可。然后我们还需要将开发板的外部网络配通,我们的开发板需要能上网:

然后我们还需要配置hailo的pcie驱动,这一部分是非常麻烦的,我们需要得到当前开发板的内核源码,然后使用与编译内核时相同的交叉编译工具编译hailo的pcie驱动程序,最后得到ko,bin等二进制文件。具体的编译步骤可以查看hailort的相关文档:
hailoRT文档:v4.20.0 | Hailo
我现在拿到的板子,卖家已经帮我编译好了驱动,我只需要安装。但是这也引发了一些另外的问题,现在卖家编译的pcie驱动版本为4.20,这就意味着,我hailoRT也需要安装4.20版本,后面再python环境中安装的pyhailoRT也需要4.20版本。这里版本必须一样,我已经尝试过了,就算相差0.1都不行。但是目前,官方公开的demo代码的hailoRT版本为4.22,这就意味着,我们用不了官方的demo代码来推理,更糟糕的是,我们无法模仿demo来编写我们的代码,因为每个hailoRT版本之间的接口不完全通用。当然,针对4.20版本我已经摸索出来了一套能够运行代码,下面我将继续使用4.20版本进行演示。
当我们安装好板子的pcie驱动以后,我们就可以来安装hailoRT,这里我们同样来到刚刚下载“Dataflow Compiler”的地方,我们选择HailoRT:
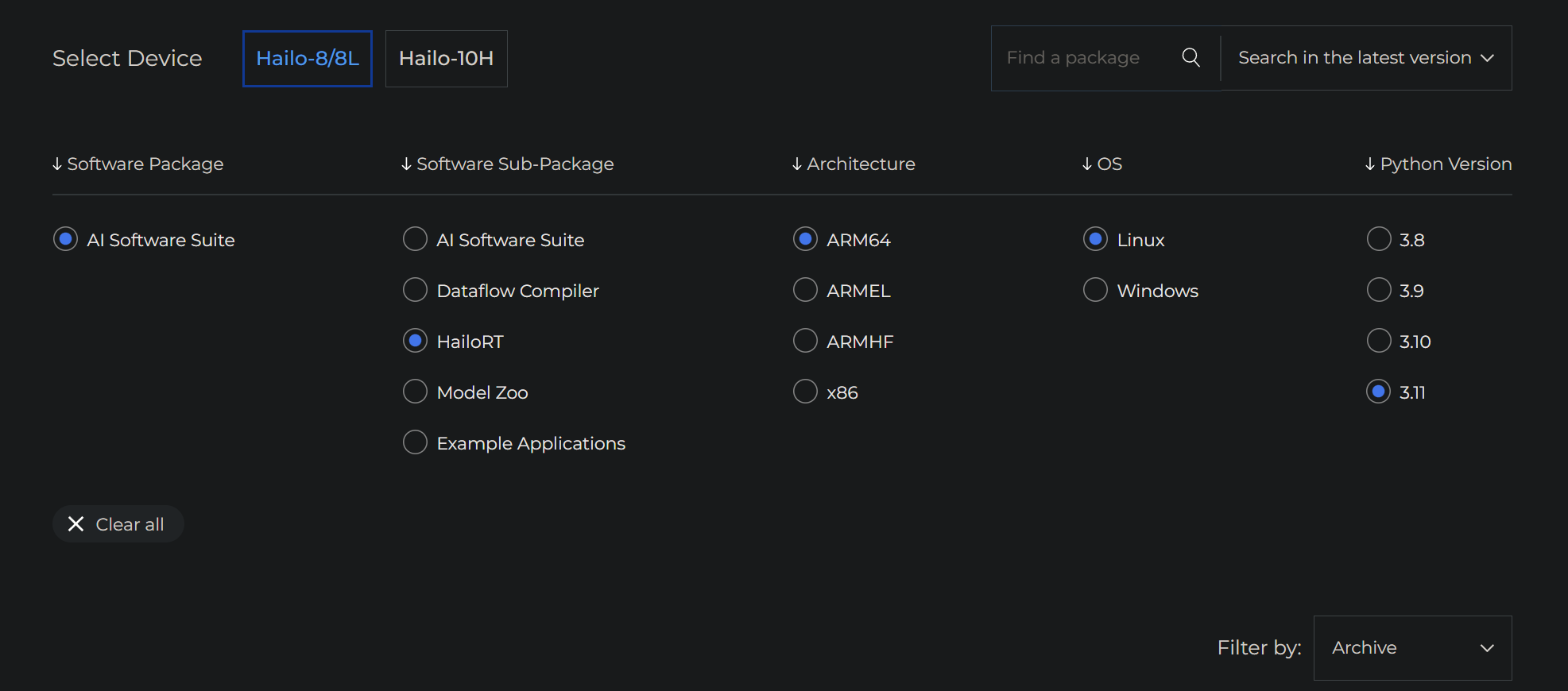
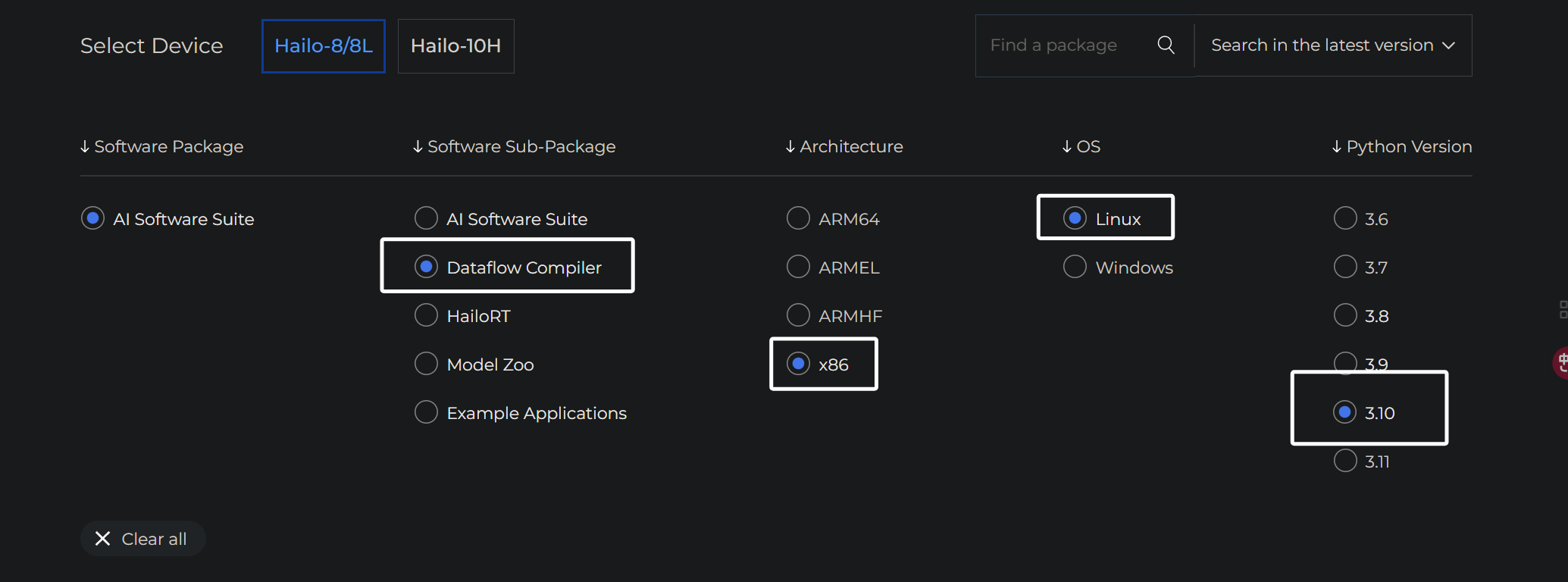
这里因为是给板子安装的,架构我们选择ARM64,系统选择Linux,python选择3.11然后右边同样选择“Archive”,往下滑,就可以看到被筛选出来的文件了:
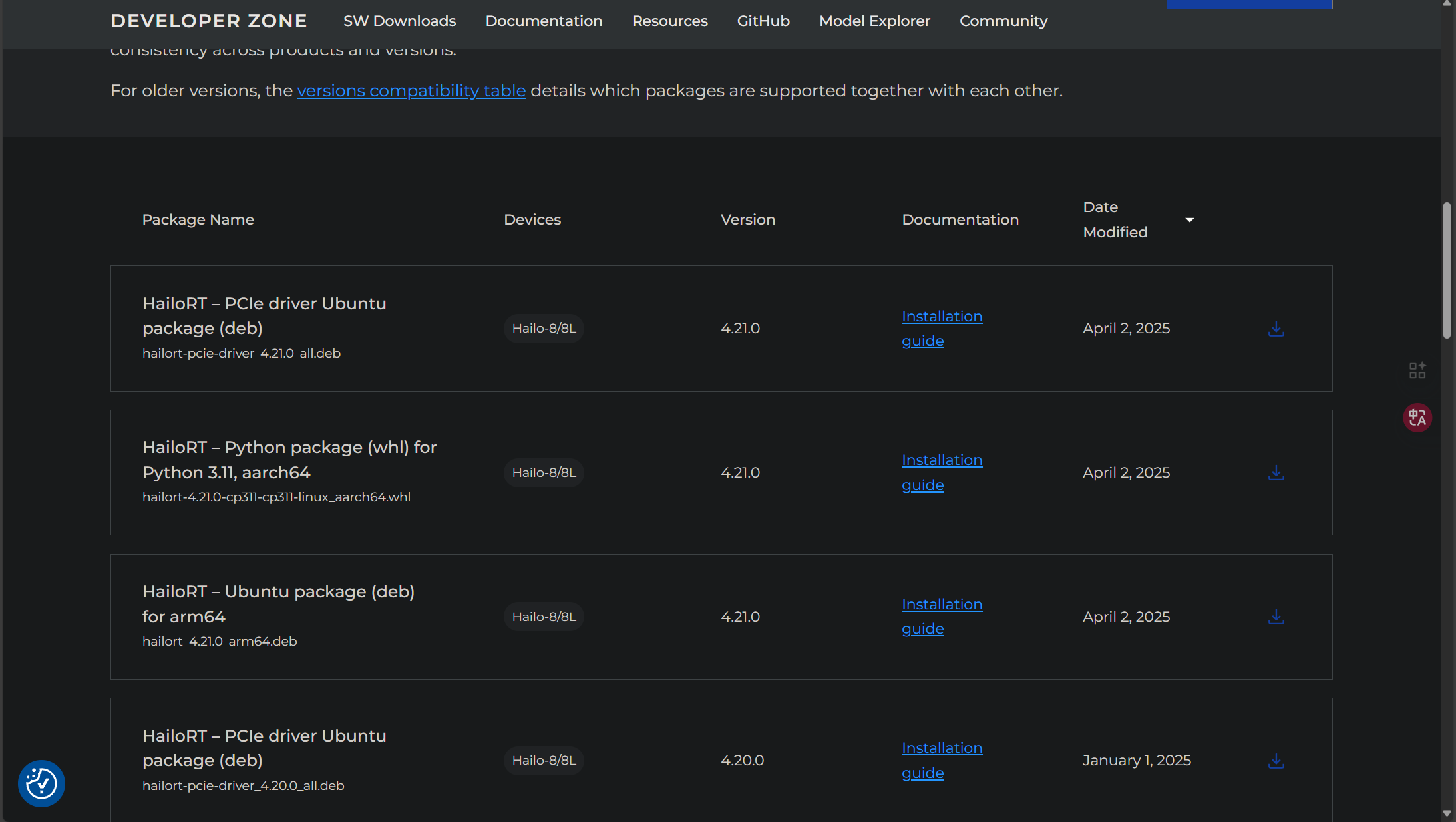
我们往下滑找到4.20版本:
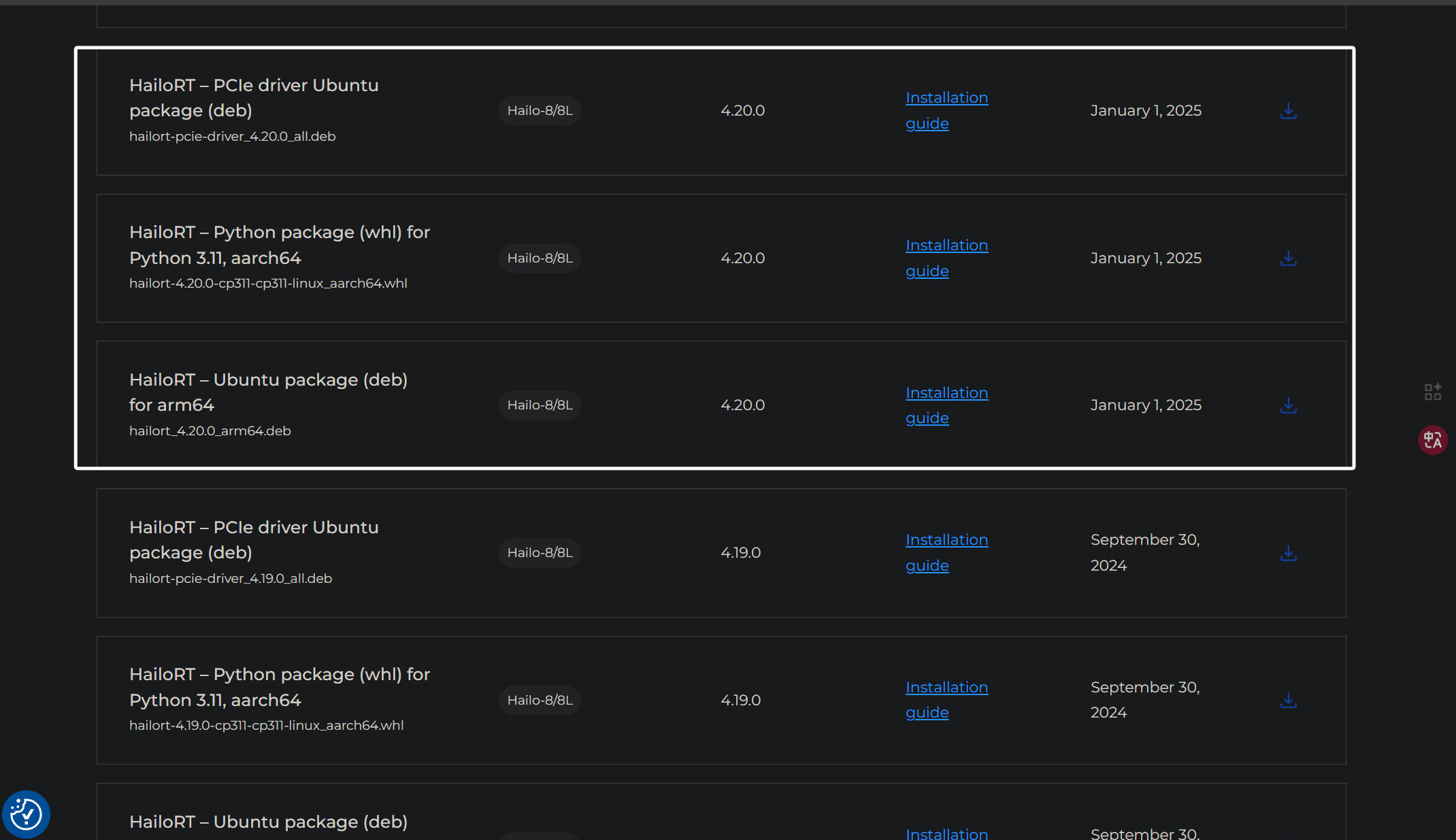
这里我们需要下载两个东西,一个是hailoRT的deb包,另一个是hailoRT的whl包,whl包也被被我们叫做pyhailoRT,下次我提及这个概念的时候大家要知道。要下载的东西,就是被我框出来的这两个,当然,我这里因为pcie驱动是4.20,所以选择4.20,大家根据自己的情况选择即可:
下载完成以后,得到以下文件:
我们将其传到板子上,如图所示:

这里我们首先使用下下面的命令来安装hailoRT的deb包:
sudo dpkg -i hailort_4.20.0_arm64.deb
安装完hailoRT并且hailo的pcie驱动没问题的话,我们就可以输入下面的命令来查看以下我们的hailo设备:
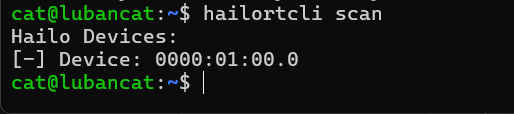
可以看到,我们的设备被正常识别。
下面我们来安装python,直接使用下面的命令为开发板安装python3.11:
sudo apt install python3.11-venv python3.11-distutils python3.11-dev -y安装完成以后,我们使用下面的命令来创建一个python的虚拟环境:
python3.11 -m venv hailo_test创建好以后,使用下面的命令进入这个虚拟环境:
source hailo_test/bin/activate下面我们在虚拟环境中来安装pyhailoRT,直接使用下面的命令来安装我们刚刚下载whl包:
pip install hailort-4.20.0-cp311-cp311-linux_aarch64.whl安装完成以后,如图所示:
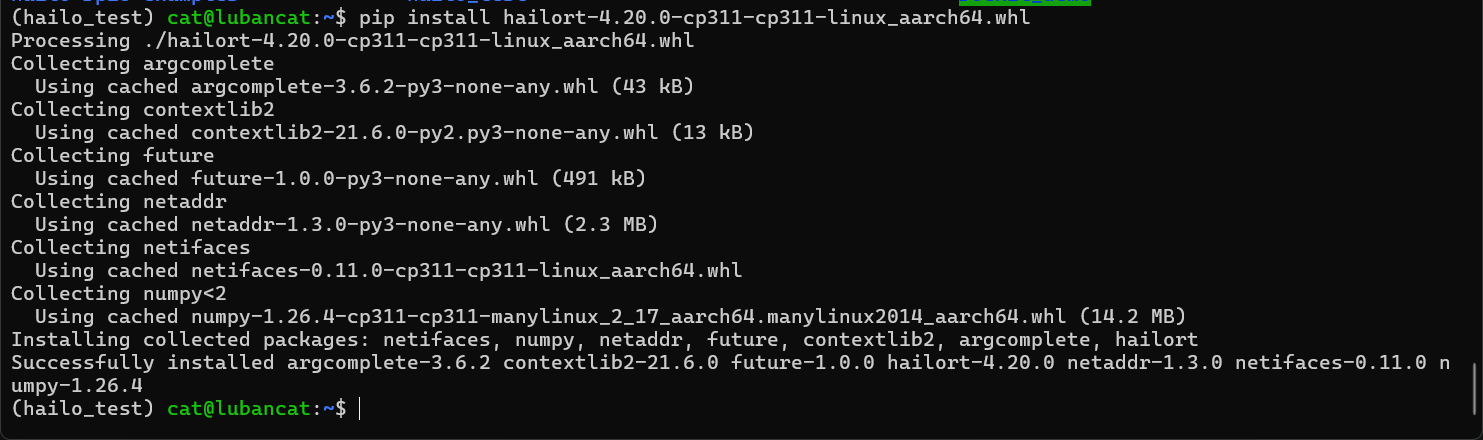
现在就来到最后一步了,我们需要写代码来推理我们hailo模型。如果你和我一样使用的是hailoRT4.20版本,那么我的代码你可以完美的运行起来。如果不是,那就需要看官方文档了,文档地址如下:
hailoRT文档:
可以在上方的版本这里选你自己hailo的版本:

目录往下滑,就能看看各个语言接口的参考了:
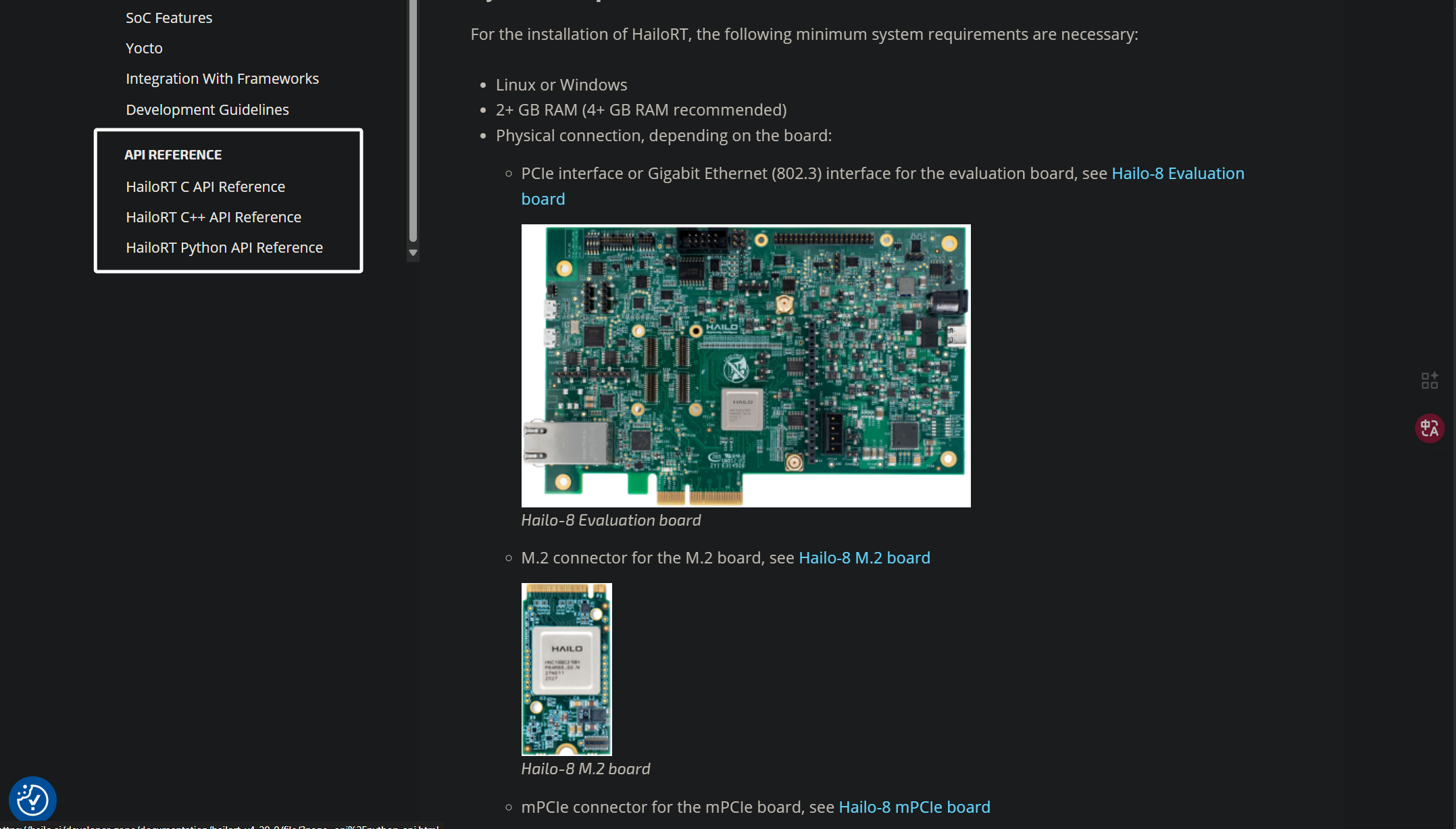
这些接口文档都是没有中文的,大家可以借助翻译与AI来阅读文档,从而编写推理代码。
好了,现在下面是我针对hailoRT4.20写的代码,不一定是最好的,但是起码能够推理图片:
import cv2
import numpy as np
from PIL import Image
import time
from hailo_platform.pyhailort.pyhailort import VDevice, HEF, InputVStreamParams, OutputVStreamParams, InferVStreams
# ---------- 初始化设备和模型 ----------
vdevice = VDevice()
hef = HEF("yolov8n.hef")
net_groups = vdevice.configure(hef)
net_group = net_groups[0]
input_info = net_group.get_input_vstream_infos()[0]
output_info = net_group.get_output_vstream_infos()[0]
# ---------- 类别列表 ----------
names = ['bird']
# ---------- 加载图片 ----------
image_path = "001.jpg"
image = Image.open(image_path).convert('RGB')
image_resized = image.resize((input_info.shape[0], input_info.shape[1])) # width, height
input_data = np.array(image_resized)
# ---------- 数据类型 ----------
input_dtype = np.uint8 if hasattr(input_info, "quant_info") else np.float32
if input_dtype == np.float32:
input_data = input_data.astype(np.float32) / 255.0
else:
input_data = input_data.astype(np.uint8)
input_data = np.expand_dims(input_data, axis=0) # batch维度
# ---------- 推理 ----------
input_params = InputVStreamParams.make(net_group)
output_params = OutputVStreamParams.make(net_group)
with net_group.activate():
with InferVStreams(net_group, input_params, output_params) as inferer:
start_time = time.time()
results = inferer.infer({input_info.name: input_data})
end_time = time.time()
infer_time = (end_time - start_time) * 1000 # 转换成毫秒
print(f"Inference time: {infer_time:.2f} ms")
# ---------- 合并输出,添加 class_id ----------
output_list = results[output_info.name]
all_detections = []
for batch_outputs in output_list: # 遍历 batch
for class_id, out_arr in enumerate(batch_outputs): # 每个 buffer 对应一个类别
if out_arr.size > 0:
class_col = np.full((out_arr.shape[0], 1), class_id, dtype=np.int32)
out_with_class = np.hstack([out_arr, class_col]) # shape=(N,6)
all_detections.append(out_with_class)
if len(all_detections) > 0:
all_detections = np.vstack(all_detections) # shape=(N,6)
else:
all_detections = np.empty((0,6))
# ---------- 画框 ----------
img_cv = cv2.imread(image_path)
h, w = img_cv.shape[:2]
for det in all_detections:
y1, x1, y2, x2, score, cls_id = det
score = float(score)
cls_id = int(cls_id)
if score < 0.5:
continue
# 归一化坐标 -> 像素
x1 = int(x1 * w)
x2 = int(x2 * w)
y1 = int(y1 * h)
y2 = int(y2 * h)
x1, x2 = sorted((max(0, x1), min(w - 1, x2)))
y1, y2 = sorted((max(0, y1), min(h - 1, y2)))
class_name = names[cls_id]
print(f"Box: ({x1},{y1},{x2},{y2}), score={score:.2f}, class_id={cls_id}, class_name={class_name}")
label = f"{class_name} {score:.2f}"
cv2.rectangle(img_cv, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img_cv, label, (x1, max(0, y1 - 5)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
cv2.imwrite("001_result.jpg", img_cv)
print("Result saved as 001_result.jpg")
这里代码中有几处大家需要自己改以下,首先就是“hef = HEF("yolov8n.hef")”这里大家需要将其修改为自己的模型路径。
然后是下面的类别列表中,这里的列表要与你训练时yaml文件的列表对应,下面是我训练模型时yaml的列表:
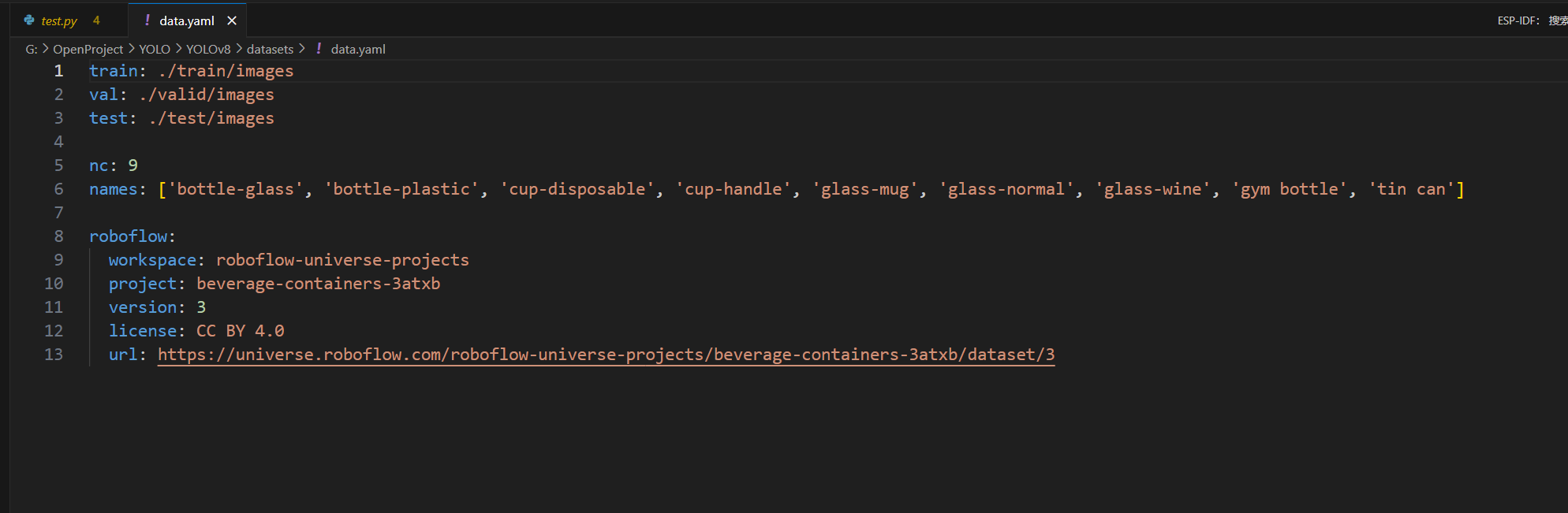
那我写到这边来就是这样的:
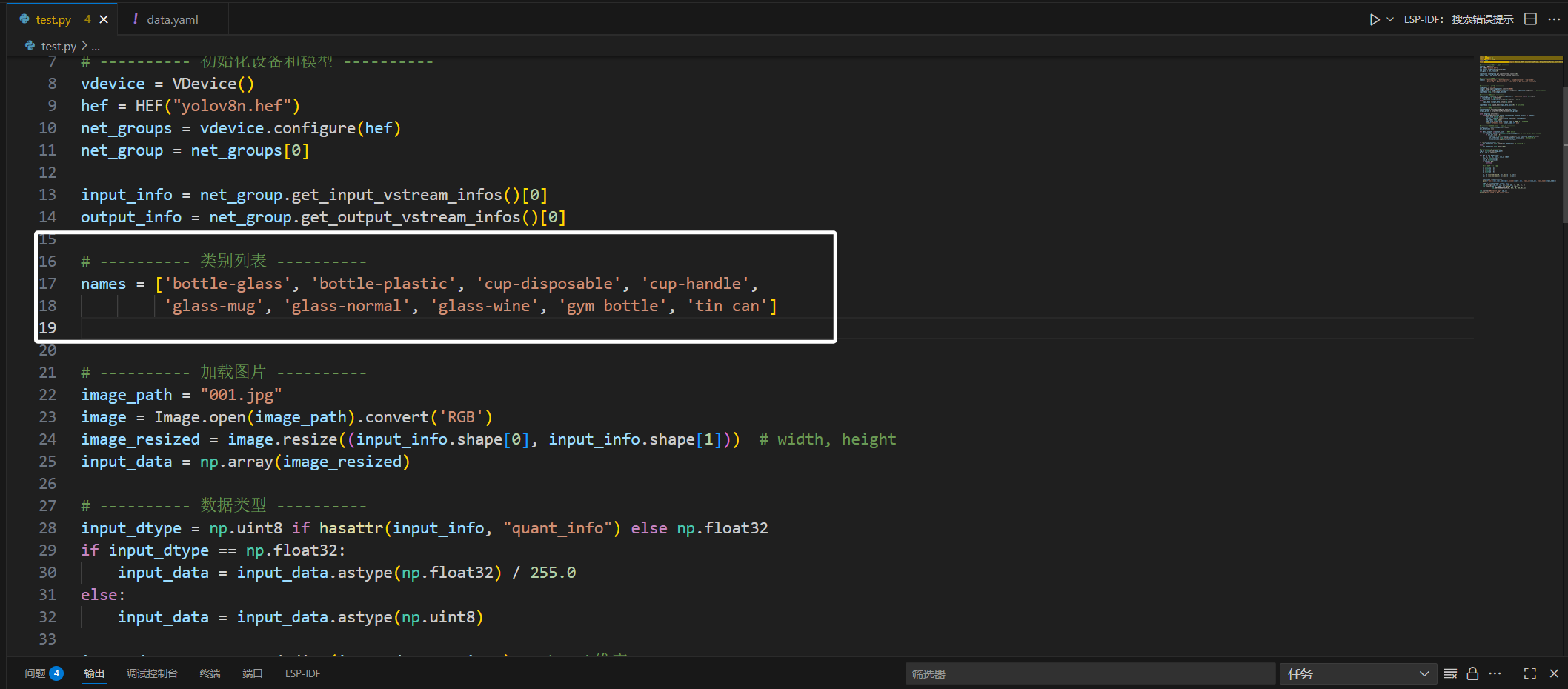
然后就是下面的“image_path = "001.jpg"”大家修改为自己要推理的图片的路径。
完成上面的步骤以后,我们使用下面的命令安装以下代码运行的依赖:
sudo apt install -y libopencv-dev libglib2.0-0 libsm6 libxext6 libxrender-devpip install opencv-python numpy Pillow -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package安装完成以后,大家别忘了把我们转换完成的hef模型文件拿过来:

准备好以后,我们直接运行这个py文件:

可以看到,这次运行使用了13.52ms,模型检测到了四个对象,并且将检测画框后的图像输出到了“001_result.jpg”。我们看看这个输出的图像:

可以看到,模型正常的框出了每一个杯子,并且类型也没问题。至此,我们使用hailo推理YOLO模型就完成了。
七、结语
总算是完成了,完成这篇文章可以说是非常不容易,中间出现了太多没有解决办法的错误。在配置过程中,我反复强调版本问题,就是因为这是我折腾最久的地方,当你在某个步骤出错,不知道怎么办时,可以尝试看看官方文档。那么最后,感谢大家的观看!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)