Meta V-JEPA 2:革命性的视频联合的世界模型
Meta AI推出V-JEPA2视频联合嵌入预测架构,通过自监督学习分析百万小时视频,构建能理解物理规律的世界模型。该模型在联合嵌入空间进行预测,无需标注即可学习物体运动等常识,在动作识别等任务表现优异。其AC变体仅用62小时机器人视频微调,就实现零样本规划,任务成功率65-80%,效率提升15倍。
1. 项目介绍
V-JEPA 2(Video Joint-Embedding Predictive Architecture 2) 是Meta AI在世界模型构建领域的重大突破,这是一个能够像人类一样理解、预测和规划的自监督视频模型。正如官方论文所述,该模型建立在深刻的认知学习理论基础之上:人类通过整合低级感官输入来表示和预测未来状态,从而学习世界的内部模型。
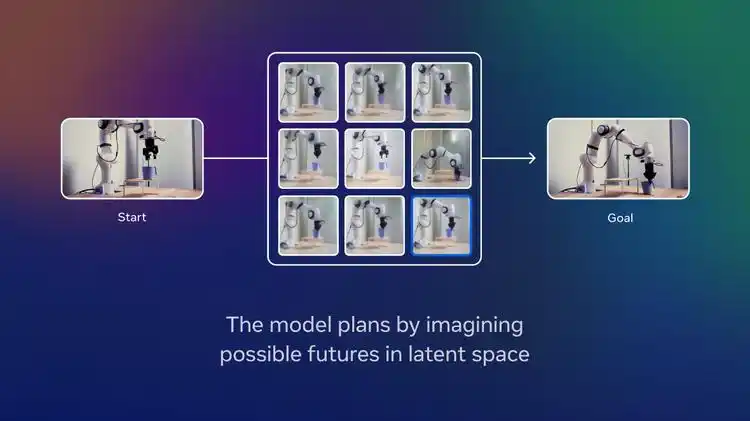
V-JEPA 2将这一理论转化为实际的技术实现,通过分析超过100万小时的互联网视频数据,建立起对物理世界的直觉理解。核心创新在于联合嵌入预测架构(JEPA),它通过在学习到的表示空间中进行预测,而非像传统方法那样在像素空间中操作。这种设计使得模型能够专注于学习物体轨迹、因果关系等可预测的物理规律,而不是纠结于无关的细节噪声。主要优势包括:
- 无需标注训练:通过自监督学习方式,在超过100万小时的视频数据上进行训练
- 世界模型构建:学会了"球掉下桌子不会消失"等从婴幼儿就具备的直观物理常识
- 零样本规划:能够在未见过的环境中预测一系列合理步骤并逐步实现目标

该模型在多个基准测试中取得了突破性成果:在Something-Something v2上达到77.3%的top-1准确率,在Epic-Kitchens-100人类动作预期任务上达到39.7的recall-at-5。更令人瞩目的是,V-JEPA 2-AC(Action-Conditioned)变体仅使用62小时未标注机器人视频进行微调,就实现了零样本机器人操作规划,在到达、抓取和拾取-放置等任务中取得了65-80%的成功率,执行效率比传统方法提升15倍。原始JEPA项目的完整代码实现可以在https://github.com/facebookresearch/jepa 找到,该仓库包含了核心算法的参考实现和详细的文档说明。V-JEPA 2的最新版本及其增强功能则可以在https://github.com/facebookresearch/vjepa2 获取,这里提供了更加优化的模型结构和训练脚本。对于理论背景和技术原理的深入理解,建议仔细阅读Meta AI发布的官方论文https://arxiv.org/pdf/2506.09985,该论文详细阐述了V-JEPA 2的设计思路、实验验证和性能分析。
2. 安装配置
2.1 环境要求
- Python 3.11+
- PyTorch 2.0+
- CUDA 11.8+(推荐)
- 至少16GB GPU内存(ViT-L模型)
2.2 快速安装


3. 核心代码架构与创新详解
点击链接Meta V-JEPA 2:革命性的视频联合的世界模型阅读原文

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)