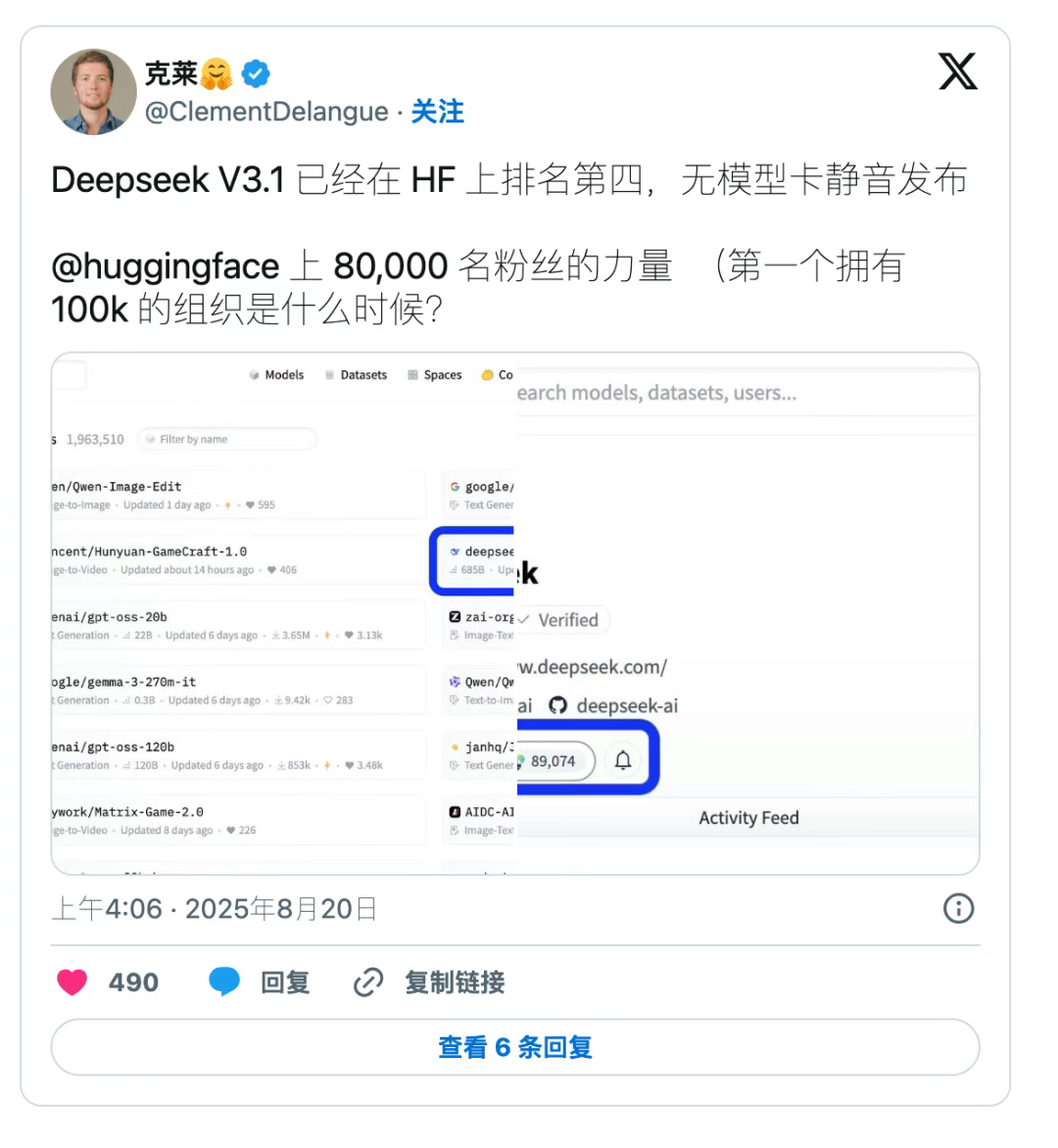
DeepSeek V3.1发布:开源AI的新格局与国产芯片的隐秘联动
的发布,和老牌AI巨头的高调不同,DeepSeek 没有大张旗鼓,直接悄然把模型上传到了 Hugging Face。美国同行不断加码“封闭生意经”,DeepSeek 反手开大门,成了全球眼中最具诚意的中国 AI。这种开放共享,既是实力自信,也进一步推动了产业创新。技术的分水岭或许已经出现,下一个时代赛道,悄然变窄也变宽了……在编程、复杂检索、工具调用等场景,V3.1 都有了显著提升,许多国际榜单上
8月21日,DeepSeek V3.1 的发布,和老牌AI巨头的高调不同,DeepSeek 没有大张旗鼓,直接悄然把模型上传到了 Hugging Face。然而仅几个小时,下载量和热议声便冲上榜单。
这次的 V3.1 是“混合推理”模式,一个模型能自由切换“思考”与“非思考”两种状态。用户想要详细推理过程,用思考模式;要极速简明答案,就换非思考。
这既保证了响应速度,能比传统推理模型快上一截,同时还能节省 20%—50% 的 token 消耗,在成本上彻底把“贵族 AI”拉下马。
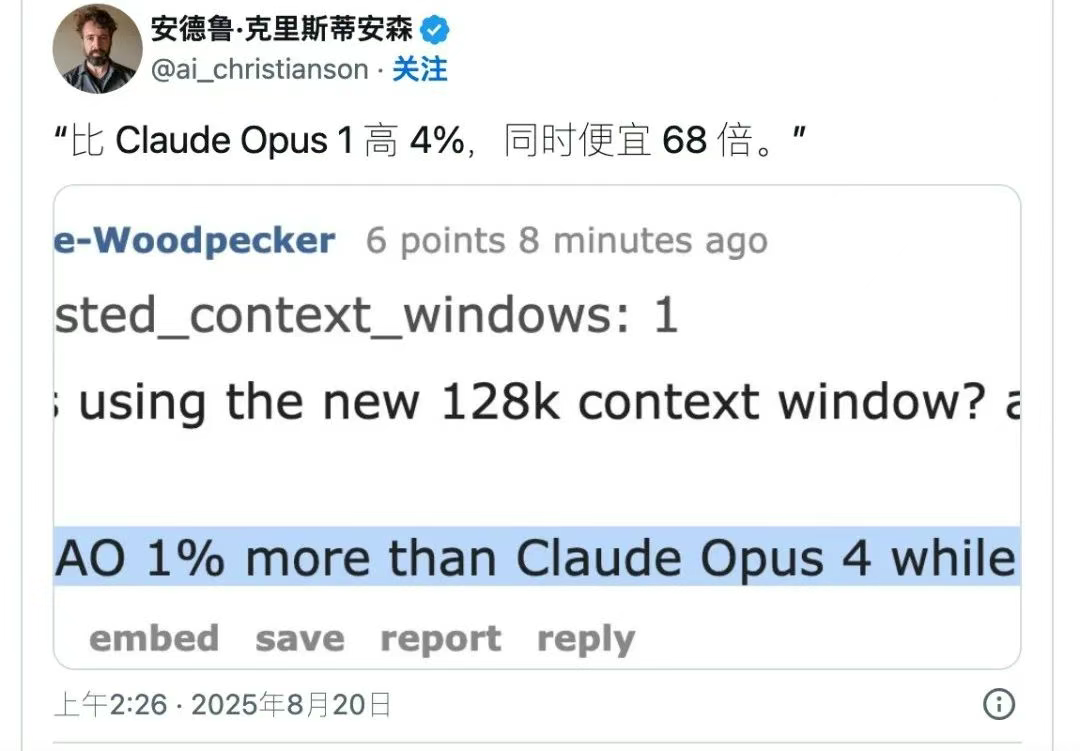
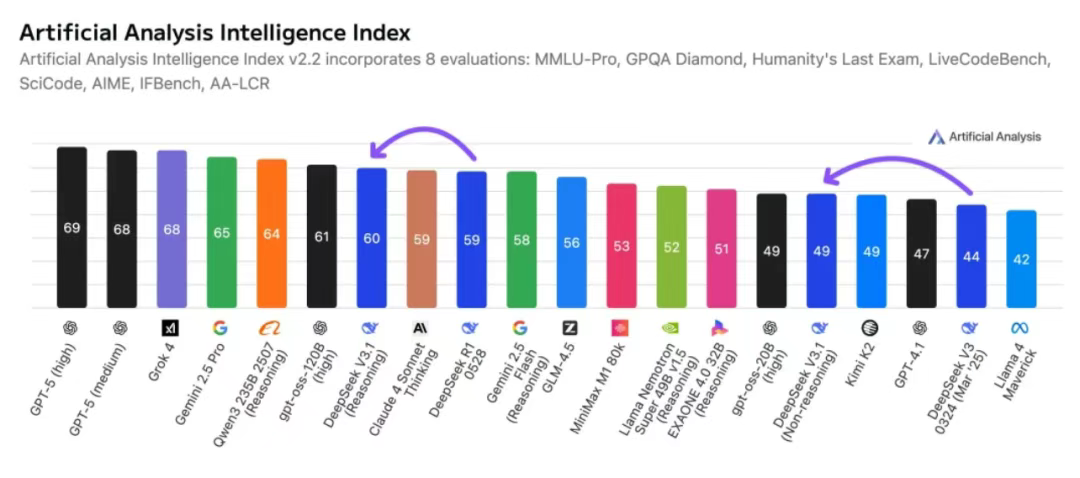
更值得关注的,是 DeepSeek 对智能体(Agent)能力的加强。在编程、复杂检索、工具调用等场景,V3.1 都有了显著提升,许多国际榜单上的成绩也直接超车老牌产品。
尤其是在软件工程和终端自动化测试上,各项代理指标均大幅跃升。
技术之外,V3.1 的底层参数精度选用了 UE8M0 FP8,这听着冷门,却是下一代国产芯片“原生 ”支持的计算规格。换句话说,DeepSeek 不是盲目追逐纸面参数,而是正合力打造自有生态,减少对英伟达等国外算力的依赖。
V3.1仍坚持开源策略,这让越来越多开发者和企业能方便试用、改造、部署。
DeepSeek-V3.1-Base模型开源地址:
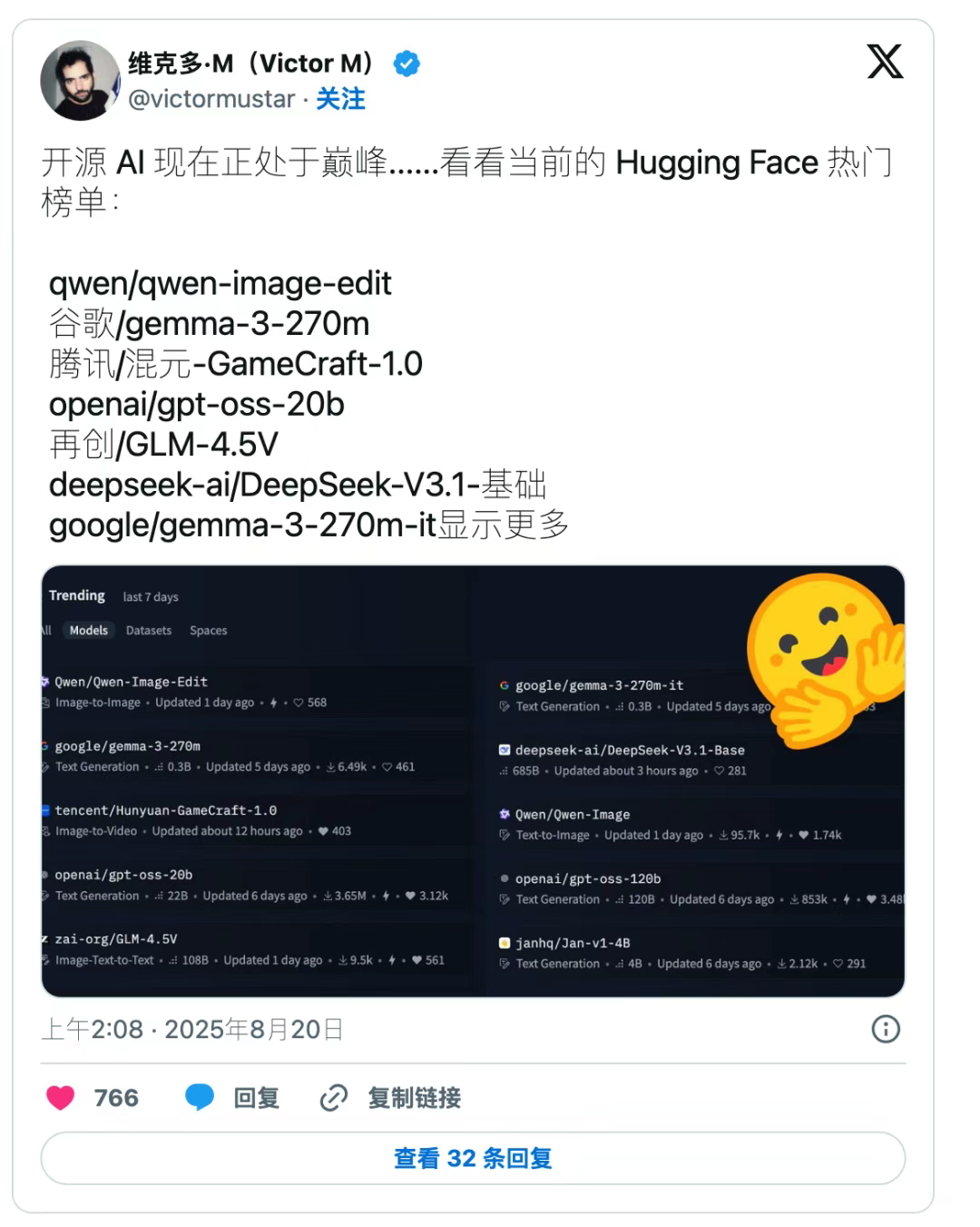
美国同行不断加码“封闭生意经”,DeepSeek 反手开大门,成了全球眼中最具诚意的中国 AI。这种开放共享,既是实力自信,也进一步推动了产业创新。
短短一条产品发布新闻,却引爆了芯片、AI、产业多线关注。技术的分水岭或许已经出现,下一个时代赛道,悄然变窄也变宽了……

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)