ChipCamp探索系列 -- 6. GPU/TPU芯片微架构15图
本文以图的形式梳理了主流AI加速芯片的架构演进,为研究从CPU到AI的异构计算架构提供了参考资料。
壹、英伟达Tesla/Fermi/Maxwell/Kepler/Turing共5代8图。
----原文:深入GPU硬件架构及运行机制
----链接1:https://cloud.tencent.com/developer/article/1814898
----Nvidia的各代GPU微架构,可以通过【nvidia xxx architecture white paper】搜索到官方白皮书并披露有微架构图,把xxx改为P100、V100、A100、H100、Fermi等等。可以看出英伟达从很早以前就开始探索不同于CPU的GPU芯片架构并且保持微架构技术的开放,是一个当之无愧的技术开创者和引领者。
贰、谷歌TPU-v1/v2/v3微架构图共4图。
----原文:Google TPU的发展历程与思考
----链接2:https://blog.csdn.net/df12138/article/details/122018914
----链接3:https://blog.csdn.net/df12138/article/details/127045083
叁、昇腾达芬奇架构共1图。
----原文:昇腾AI核心单元。
----链接4:https://blog.csdn.net/m0_37046057/article/details/144090034
肆、英伟达微架构演进+核心概念溯源2图。
----流处理器(Stream Processor, SP)。
----流式多处理器(Stream Multiprocessor, SM)。
----处理器簇(Texture Processor Cluster, TPC)。
----处理器簇(GPU Processor Cluster, GPC)。
1、NVidia Tesla架构
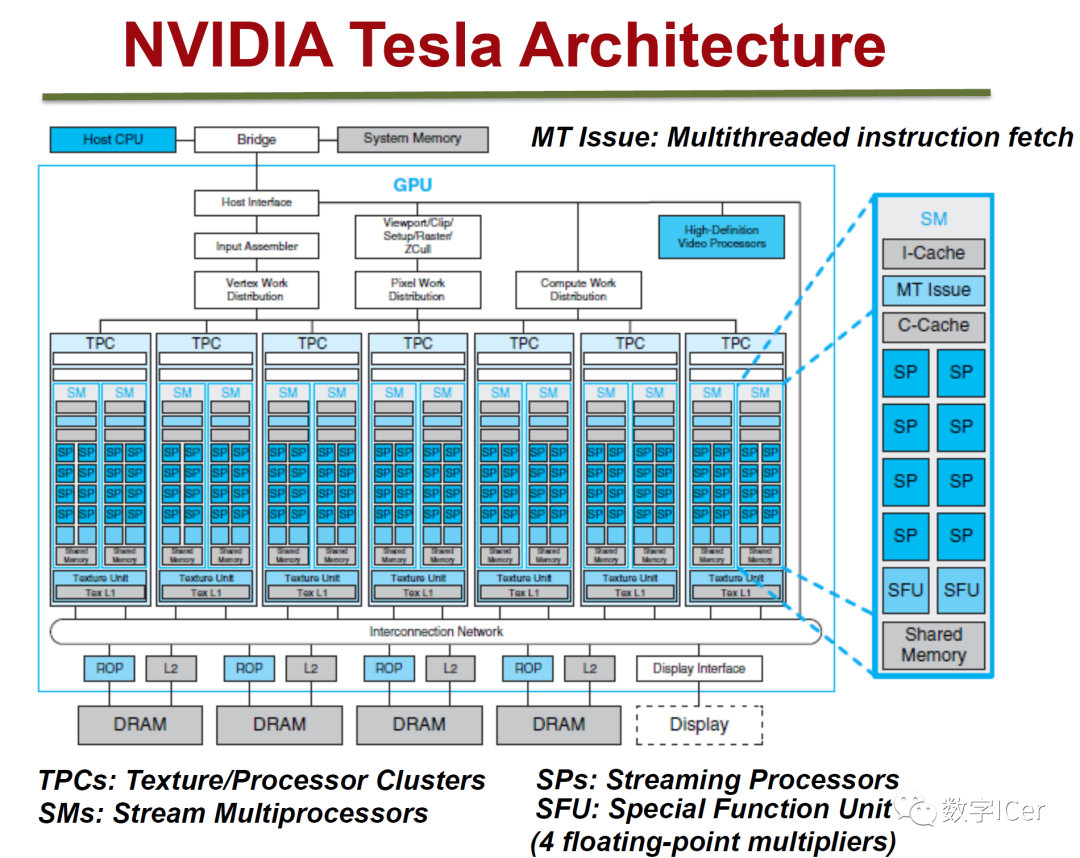
2、NVidia Fermi架构
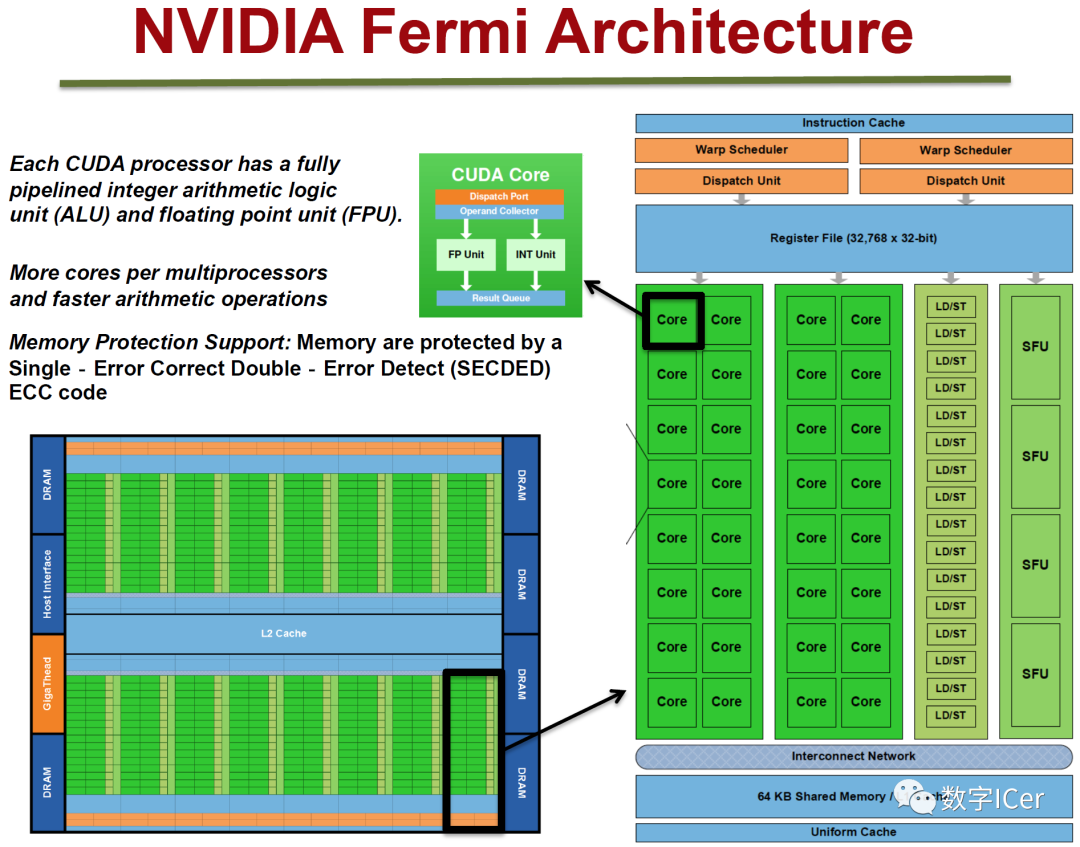
3、NVidia Maxwell架构

4、NVidia Kepler架构
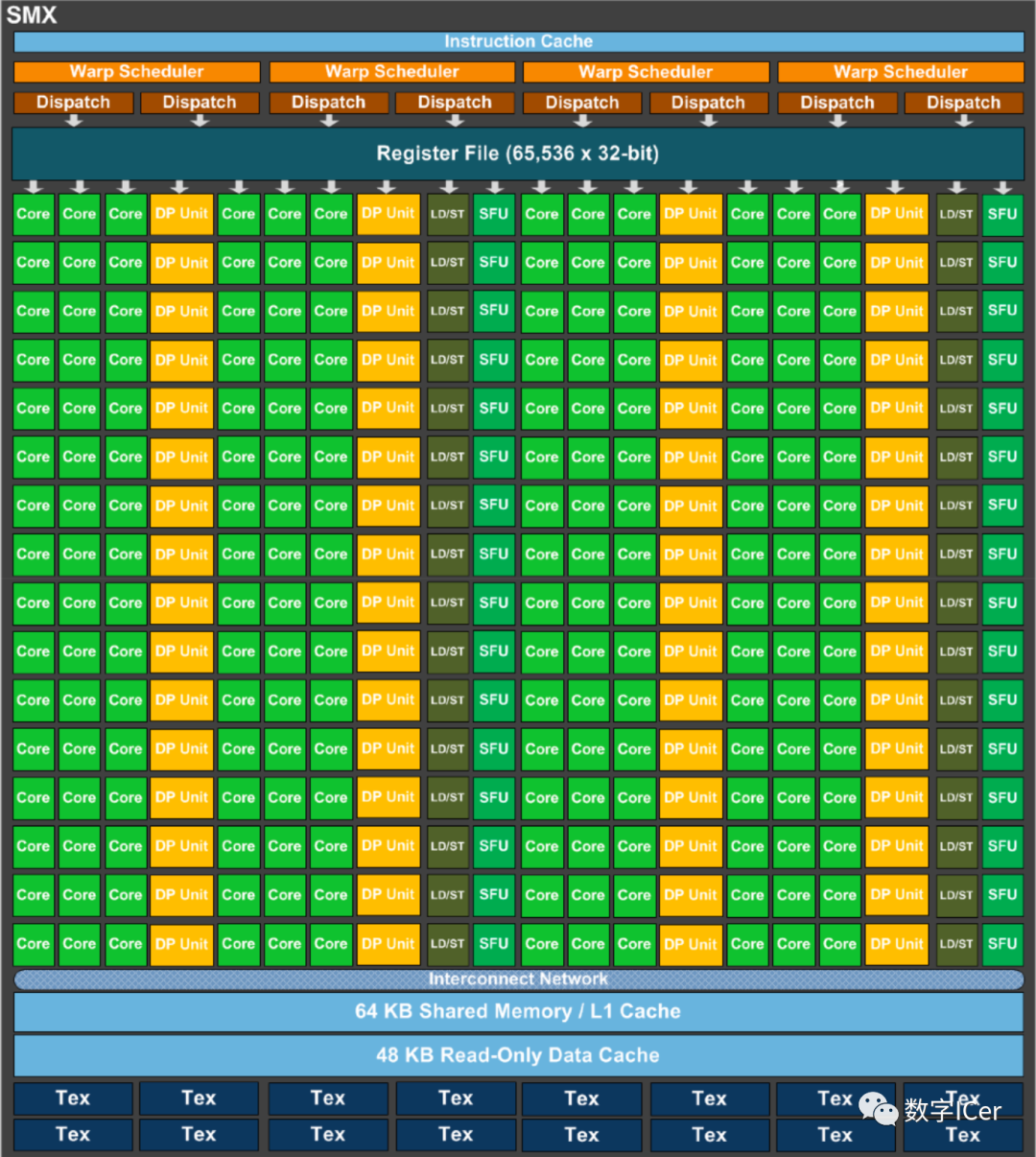
5、NVidia Turing架构
其中的单个SM的结构图如下:
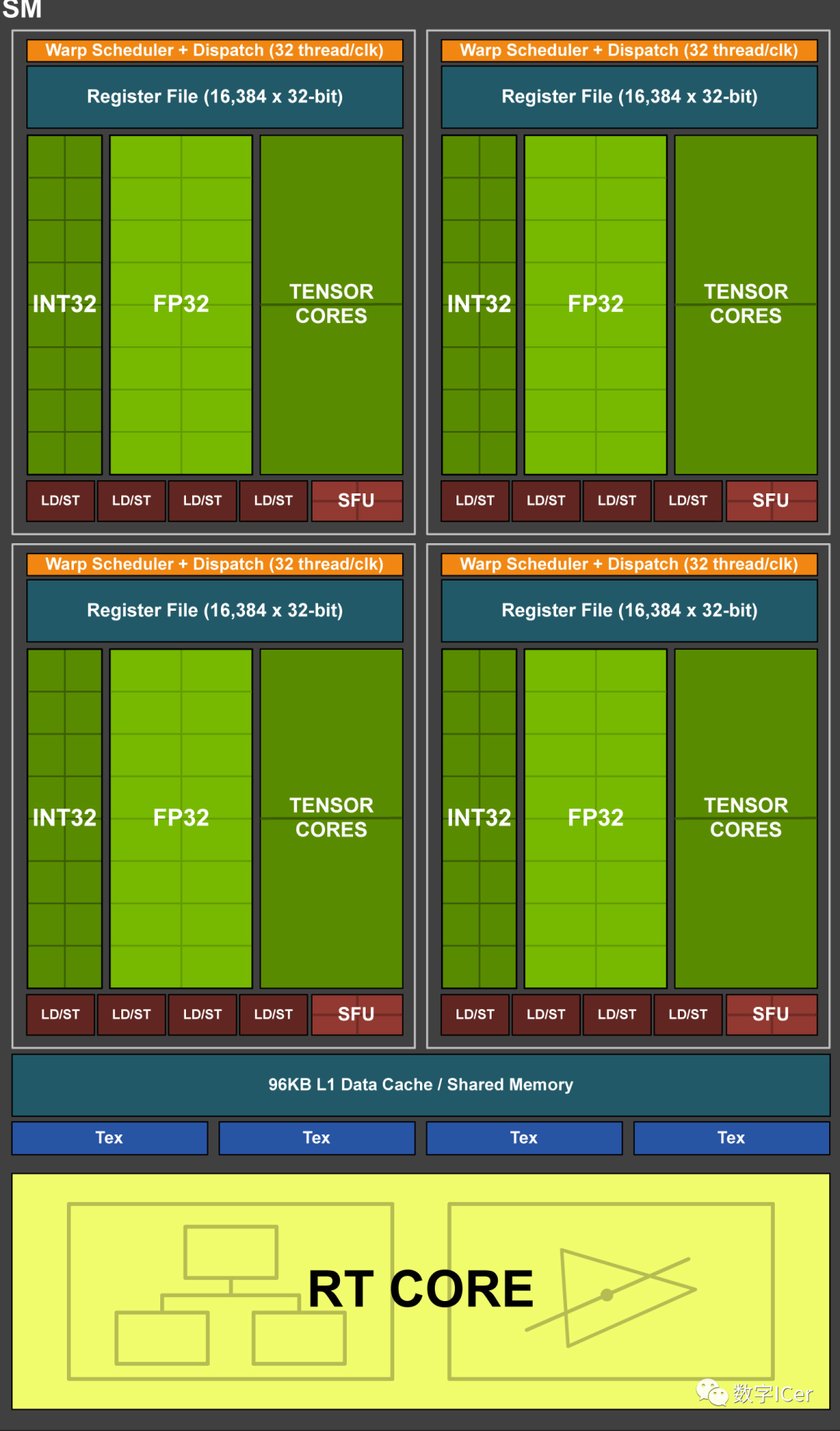
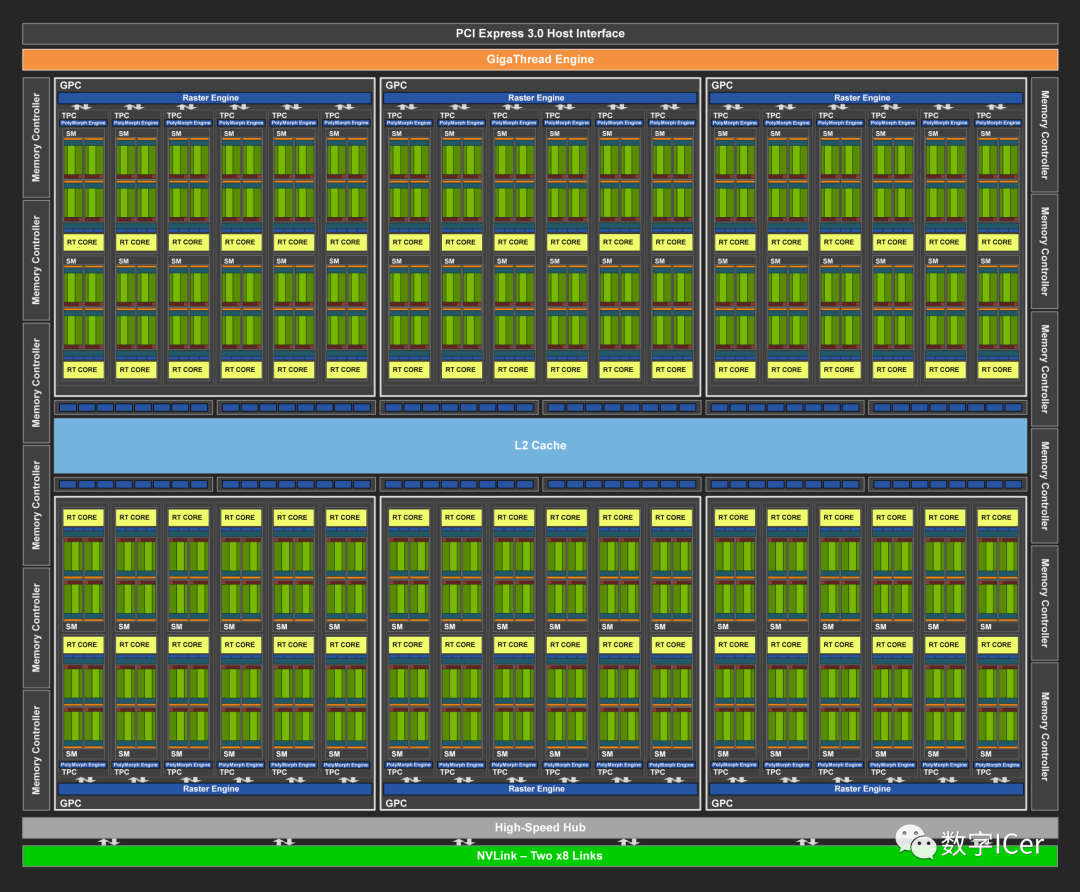
六、Femi的运行机制总览图:

从Fermi开始NVIDIA使用类似的原理架构,使用一个Giga Thread Engine来管理所有正在进行的工作,GPU被划分成多个GPCs(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine),它们其中有很多的连接,最显著的是Crossbar,它可以连接GPCs和其它功能性模块(例如ROP或其他子系统)。
程序员编写的shader是在SM上完成的。每个SM包含许多为线程执行数学运算的Core(核心)。例如,一个线程可以是顶点或像素着色器调用。这些Core和其它单元由Warp Scheduler驱动,Warp Scheduler管理一组32个线程作为Warp(线程束)并将要执行的指令移交给Dispatch Units。
GPU中实际有多少这些单元(每个GPC有多少个SM,多少个GPC ......)取决于芯片配置本身。例如,GM204有4个GPC,每个GPC有4个SM,但Tegra X1有1个GPC和2个SM,它们均采用Maxwell设计。SM设计本身(内核数量,指令单位,调度程序......)也随着时间的推移而发生变化,并帮助使芯片变得如此高效。
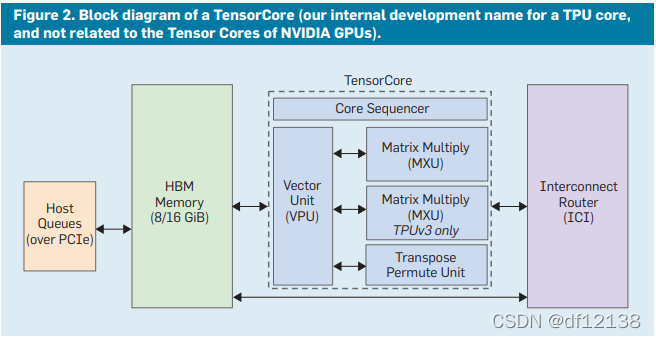
七、谷歌TPUv1微架构:
2016年5月的开发者大会上,Google推出了自行研制的人工智能芯片Tensor Processing Unit, TPU。即下图展现的TUPv1。
https://blog.csdn.net/df12138/article/details/122018914
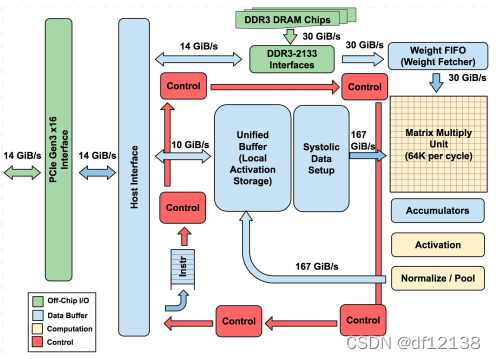
从左到右看,主机 CPU 通过 PCIe 总线与 TPU 进行连接。因此,TPU 不是与 CPU 紧密集成来减少部署延迟,而是被设计成 PCIe I/O 总线上的类似协处理器,允许它插入现有的服务器,就像 GPU 那样。
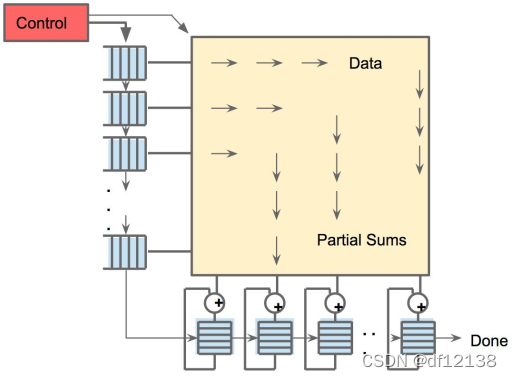
TPU中,输入数据从左侧流入,权重从顶部流入,并且是预加载的,若给定的一256元的乘积运算操作,它会以对角波的形式通过阵列。由于权重是预先加载的,因此随着波的前进,可以立即算出乘积,通过控制部分和的通路,再往下累加。最终产生了256个输入立即被读取的错觉,并且它们立即更新256个累加器中的每个位置。从正确性的角度来看,软件不知道MXU的脉动实现,但从性能角度看,它确实需要考虑其中的延迟,因为数据一级级的传导,意味着延迟的步步累加。
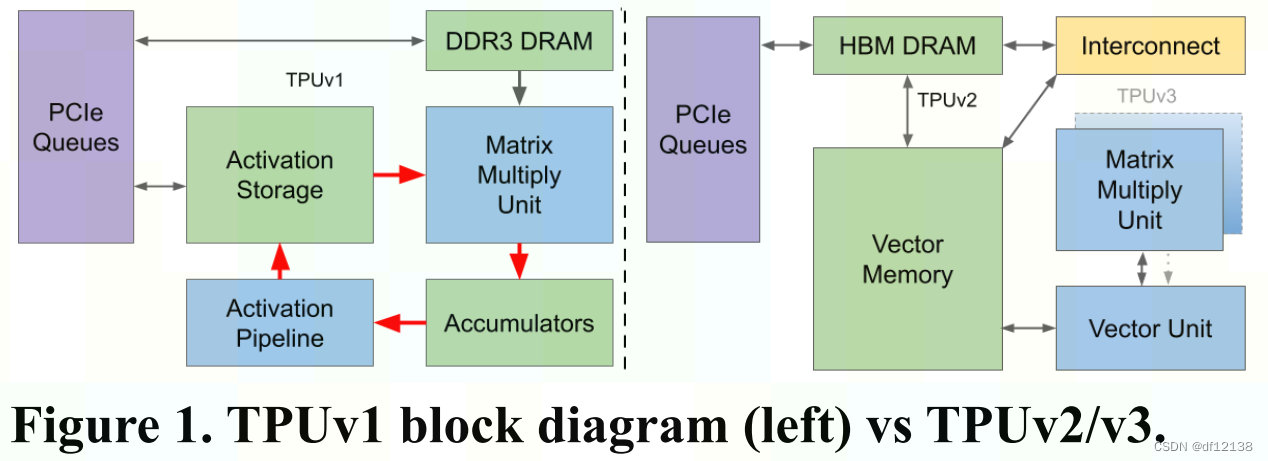
8、TPUv2和TPUv3:
https://blog.csdn.net/df12138/article/details/127045083
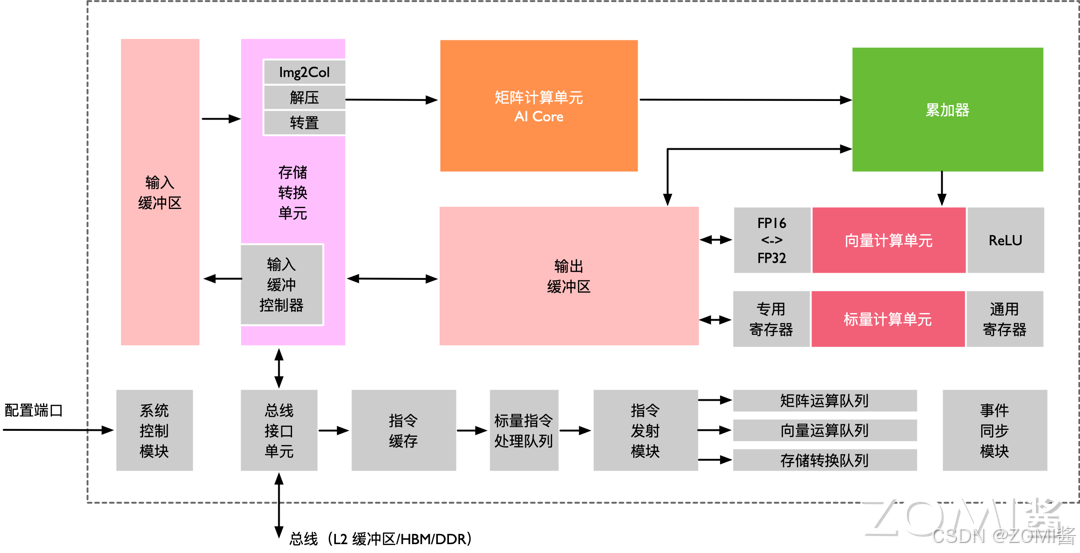
9、昇腾达芬奇架构:
https://blog.csdn.net/m0_37046057/article/details/144090034
十、来一些官网的链接:
Nvidia Fermi architecture wihte paper:
Nvidia P100 architecture wihte paper:
https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf
Nvidia V100 architecture white paper:
https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf
Nvidia H100 architecture white paper:
https://resources.nvidia.com/en-us-hopper-architecture/nvidia-h100-tensor-c
Nvidia Kepler architecture white paper:
nvidia microarchitecture:
https://www.nvidia.com/en-us/technologies/
https://en.wikipedia.org/wiki/Category:Nvidia_microarchitectures
https://www.techpowerup.com/gpu-specs/nvidia-nv11b.g338
可以看到Nvidia的历代架构,作为上面选择的图的参考。
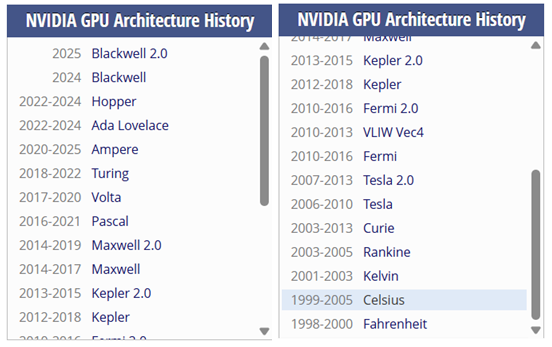
不过,既然已经从官方和Wiki都梳理到了英伟达芯片的更早的“源头”,难免想知道其核心的技术概念SM和SP的引入是什么时候的----【when is SM and SP introduced in nvidia】:

----------The End!!!----------

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 49
49 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)