对比传统模型,M3-Agent多模态记忆推理有何优势?
M3-Agent框架突破AI长期记忆与跨模态推理瓶颈 该研究针对多模态智能体缺乏人类级长期记忆和推理能力的问题,提出M3-Agent创新解决方案。框架采用实体中心的多模态记忆图结构,通过分层记忆(情景记忆与语义记忆)和并行处理流程(记忆流程与控制流程),实现持续感知、身份统一的信息存储和递进式推理。相比传统方法,M3-Agent支持无限长多模态输入流处理,在M3-Bench等测试集上表现优异,尤其
AI 家庭机器人为何始终“不会举一反三”?
有没有想过,如果你家里的机器人能像人一样,记住昨天谁拜访过、厨房里那瓶牛奶什么时候快过期,甚至能在没被明说的情况下帮你收拾房间,会是什么体验?现实却是,尽管AI在识别、对话等任务上进步神速,但“长期记忆”和“复杂推理”仍是硬伤——机器人往往只能机械地执行显式命令,无法凭经验自发行动,更别提跨视觉、声音理解、长期追踪一个人的习惯和身份。
这背后的核心问题是:多模态智能体(能处理视觉、听觉等多种输入的AI)缺乏真正“像人一样”的长期记忆和跨模态推理能力。传统方法不是死记硬背对话,就是存储简单摘要,远远达不到人类那种“串联事件、推断隐含信息”的水平。视频理解领域更是受限于窗口大小和算力,无法处理现实环境中的“无限长信息流”。
M3-Agent 如何让智能体拥有“人类级记忆”?
M3-Agent 框架正是为此而来。它的核心思路是:
- 持续感知:像人一样,随时“看”与“听”周围发生的事。
- 分层记忆:将体验拆分为两类——情景记忆(具体事件)和语义记忆(抽象知识)。
- 实体为中心的多模态记忆图:把人脸、声音、知识等串成统一节点,确保身份和信息的一致性。
- 并行两大流程:
- 记忆流程:实时分析多模态输入,生成/更新长期记忆。通过外部数据库,所有信息以记忆图结构存储,节点间通过无向边连接,信息冲突用“投票机制”自动加权筛选。
- 控制流程:解释外部指令,检索记忆库,多轮推理后输出答案。流程规范,支持递进式、多轮交互检索,保证复杂推理能步步落地。
类比一下,这就像一个训练有素的助理——每天不只是记日记,还能把所有见过的人、听到的声音、学到的知识都“串起来”,遇到问题时主动翻找过往经历,多轮思考、查证,最终给出精确答案。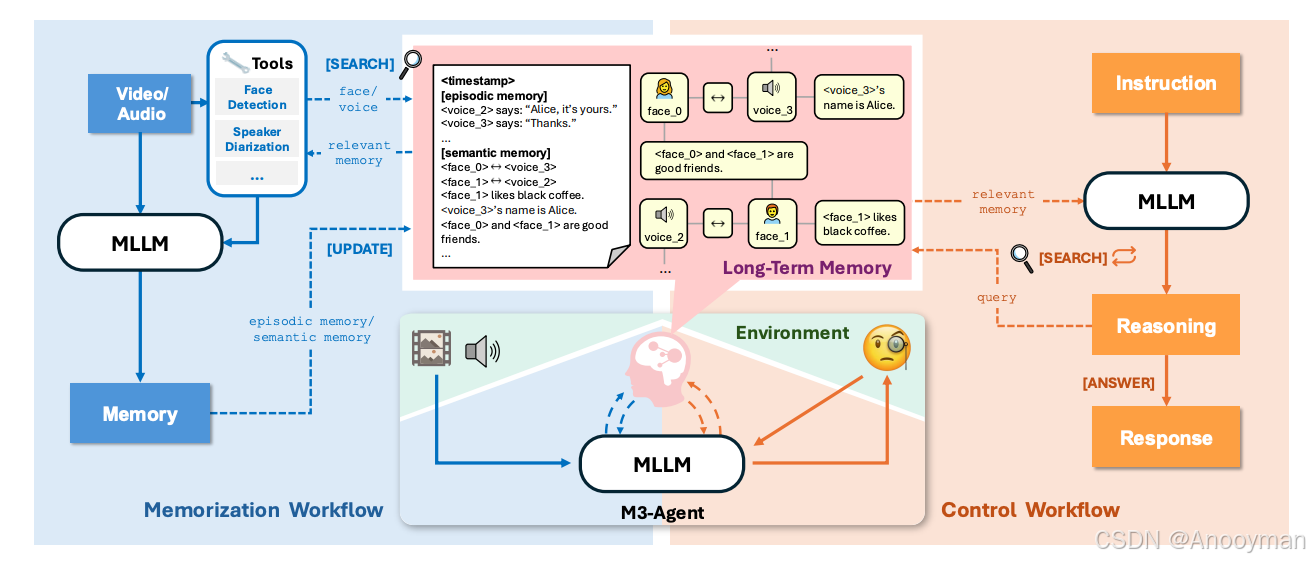
M3-Agent 比传统模型强在哪?
| 维度 | 传统方法 | M3-Agent 框架 |
|---|---|---|
| 记忆结构 | 简单序列/摘要/向量 | 实体中心多模态记忆图 |
| 信息一致性 | 难以身份统一、易混淆 | 跨模态face_id+voice_id映射 |
| 处理时长 | 受限于窗口/算力 | 支持无限长多模态输入流 |
| 推理流程 | 单轮或提示式检索 | 多轮、递进式检索推理 |
| 问题类型 | 细节/浅层问题为主 | 覆盖多细节、多跳、跨模态、人类理解、知识提取等复杂问题 |
-
长期记忆(Long-Term Memory)

- 采用外部数据库,支持文本、图像、音频等多模态数据,所有信息以记忆图(memory graph)结构存储,每个节点包含唯一ID、模态类型、原始内容、置信权重、向量嵌入和时间戳等元数据。
- 节点间通过无向边连接,便于逻辑关系追溯和相关记忆检索。
- 通过权重投票机制解决冲突信息,重复强化的信息权重更高,可覆盖置信度较低的条目,保证长期记忆的鲁棒性和一致性。
- 系统配备两类检索工具,分别支持节点级和片段级的多模态记忆查询。
-
记忆生成(Memorization)
- M3-Agent按视频片段处理输入,生成事件记忆(episodic memory)和语义记忆(semantic memory)。
- 为保证实体一致性,采用人脸识别和说话人识别工具,提取角色面部和声音特征,并以face_id和voice_id进行唯一标识,实现跨片段、多模态的统一身份映射。
- 记忆生成时,角色必须以face_id或voice_id指代,语义记忆支持跨模态推理,比如将同一人物的面部和声音节点联结为单一角色。
- 信息以文本节点或实体关系边形式存储,冲突通过投票机制自动校正,确保长期积累的准确性。
-
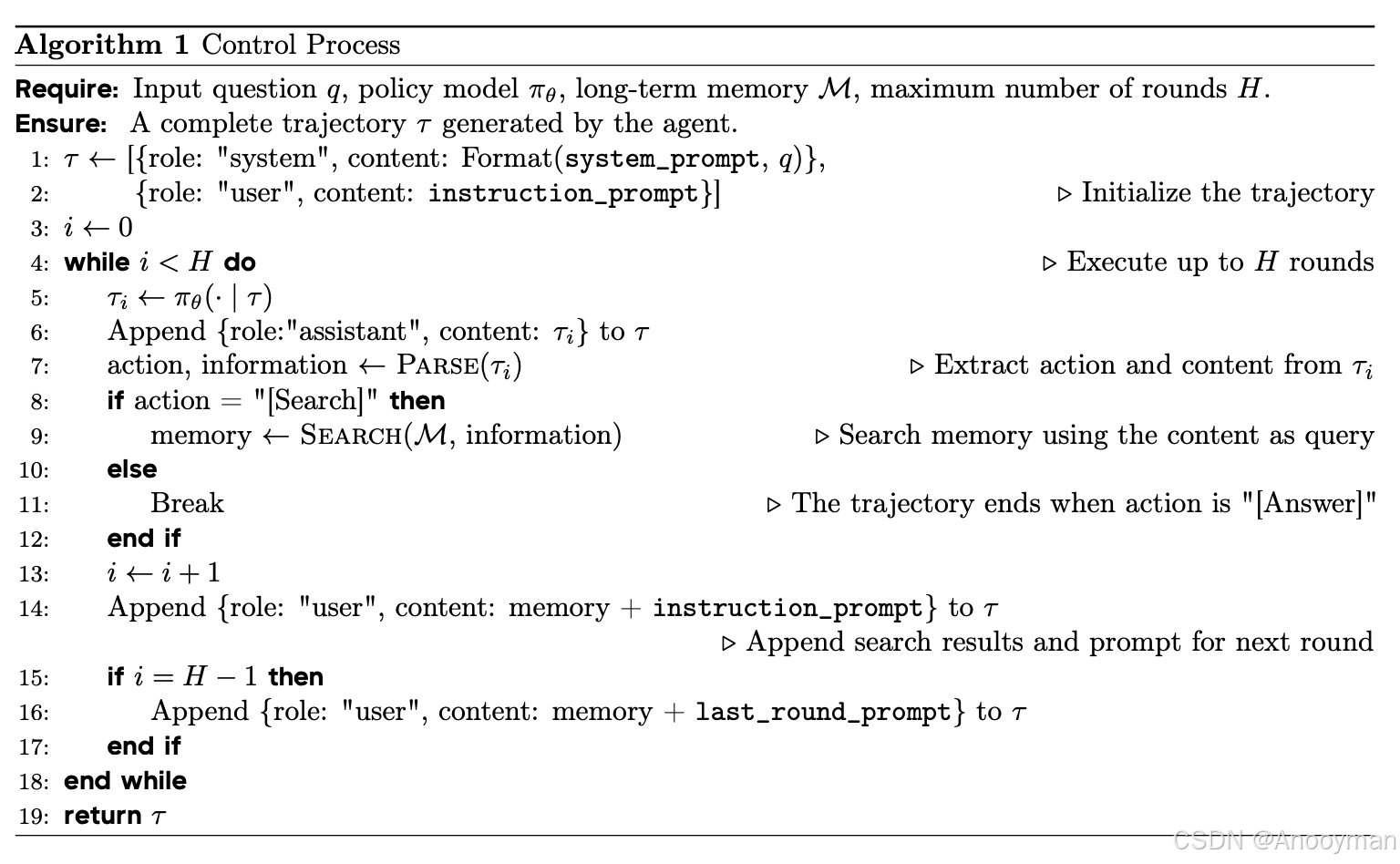
控制流程(Control)
- 接收指令后,自动启动多轮推理,通过调用检索函数(如search_clip、search_node)从长期记忆中获取相关信息。
- 控制流程由MLLM作为策略模型驱动,支持系统提示、回合提示和最终回合提示三种模板,保证推理流程规范和高效。
- 算法流程明确:初始化→多轮推理与检索→最后一轮输出答案,保证每次查询都有完整的推理轨迹。
-
输入与初始化
- 输入包括:问题q、策略模型πθ(即多模态大语言模型)、长期记忆库M,以及最大推理轮数H。
- 首先初始化推理轨迹τ,包含系统提示(system_prompt)和首轮指令提示(instruction_prompt),明确任务目标与初始指导。
-
多轮推理过程
- 进入循环,每轮最多执行H次:
- 策略模型πθ根据当前轨迹τ生成响应(即一个新的assistant内容)。
- 解析assistant内容,提取本轮动作(action)和相关信息。
- 若动作为“Search”,则根据解析出的信息调用长期记忆库的检索函数(如search_node、search_clip)获取相关记忆内容。
- 将检索结果和新的指令提示追加到轨迹τ,为下一轮推理提供上下文。
- 若动作为“Answer”,即模型决定输出最终答案,则跳出循环,结束推理流程
- 进入循环,每轮最多执行H次:
-
特殊回合处理
- 如果到达倒数第二轮(i = H-1),追加最后一轮提示(last_round_prompt),确保模型在最后一次机会输出答案。
-
输出
- 算法最终返回完整的推理轨迹τ,包括所有轮的系统、用户、助手内容以及检索结果。
实验对比:
-
Socratic Models(多模态模型生成片段描述,LLM检索生成答案)
-
在线视频理解方法(如MovieChat、MA-1MM、Flast-VStream,采用滑窗、流式特征等策略)
-
Agent方法(如Gemini-Agent、Gemini-GPT4o-Hybrid,分别利用商用大模型实现记忆与控制流程)
-
评测数据集覆盖M3-Bench-robot、M3-Bench-web和VideoMME-Long,全面测试多模态智能体在真实与网络场景下的长期记忆与推理能力。
-
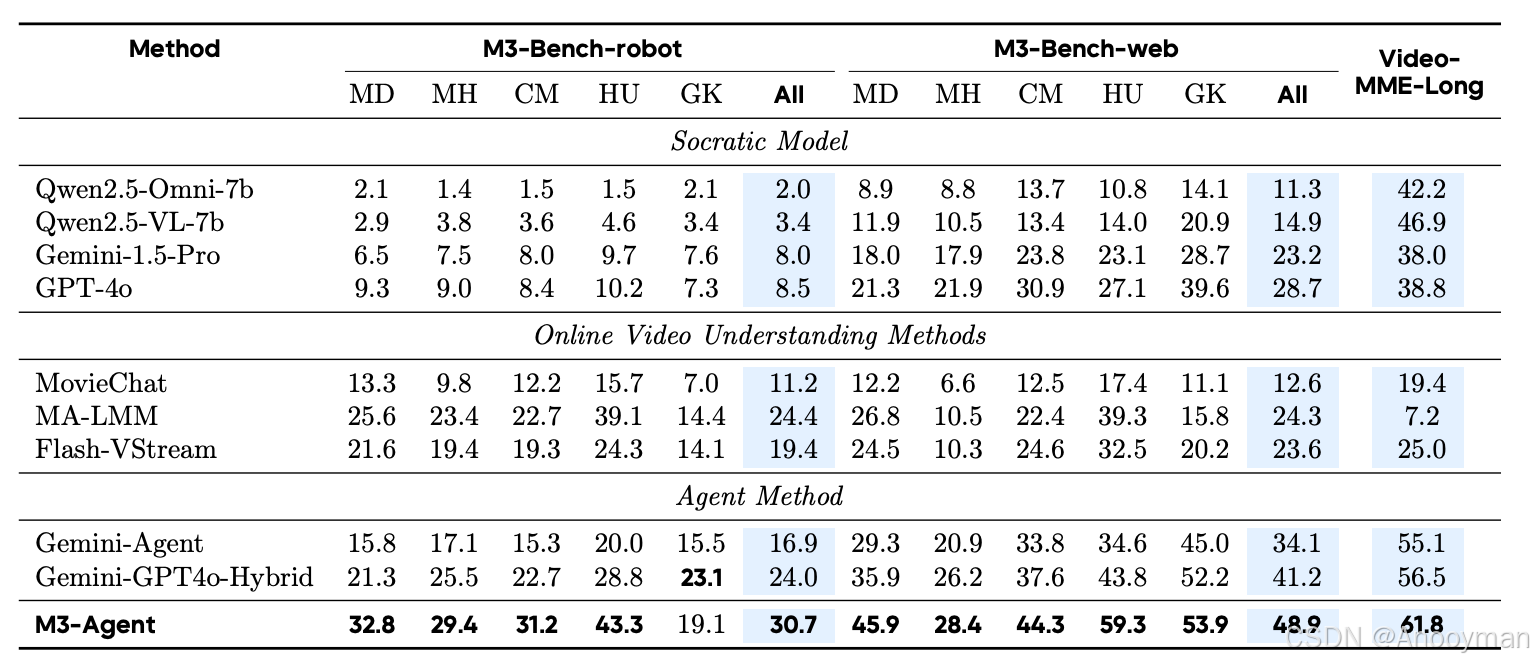
M3-Agent(MS-Agent)在所有基准数据集和所有问题类型上表现最优:
- 在M3-Bench-robot上整体准确率领先最强基线6.3%
- 在M3-Bench-web和VideoMME-Long上分别领先7.7%和5.3%
- 在“人类理解”和“跨模态推理”问题上提升尤为显著,分别高出基线4.2%-15.5%和6.7%-8.5%
- 说明M3-Agent在角色一致性、多模态信息整合和复杂推理方面具有明显优势

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)