LangChain4j入门
AI,人工智能(ArtificialI),使机器能够像人类一样思考、学习和解决问题的技术。Agent 指智能体,是一个能够感知其环境,并通过采取行动以实现最佳目标的系统。在 AI 领域,带有 AI 的应用可以被看作是一种 Agent 的体现形式,它能根据用户输入、环境变化等,利用 AI 技术(如机器学习、深度学习等)做出响应和决策,为用户提供智能化的服务。
1.AI发展的历史
别以为是文字性的东西,其实这个知识点对于你,对于整个AI体系的了解特别重要。
AI的定义
AI,人工智能(Artificial Intelligence),使机器能够像人类一样思考、学习和解决问题的技术。
在历史上为了实现让机器像人类一样去思考经历了三个特殊的阶段:

符号主义
这个实现方式描述的是将世间万事万物,抽象成为一种符号存储在计算机当中,然后根据输入不断去识别。但是显而易见这个实现方式太不客观了,不可能描述世间的万事万物。
连接主义
这个实现方式的核心在于,根据输入事务去提取参数,然后交给感知机模型,根据输入参数的值通过激活函数得到不同的结果,就可以根据参数的不同从而表示不同的事物了。而这个推测的模型也叫做感知机,如下:
注:这个激活函数可以理解为根据参数去使用一种算法从而得出结果,比如说可以使用计算总分的方式。
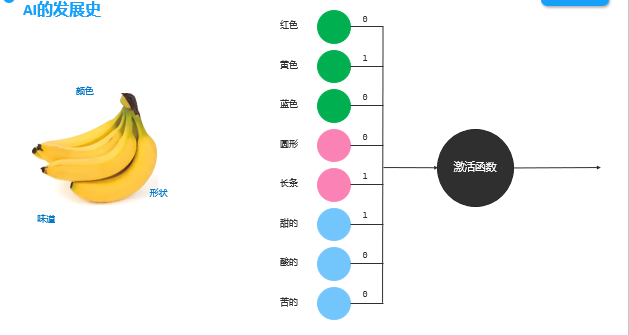
这个去实现对AI,只能去处理简单事件的推理,但是显而易见现实生活当中的问题是复杂多样的,于是在这条件下,产生了多层感知机。
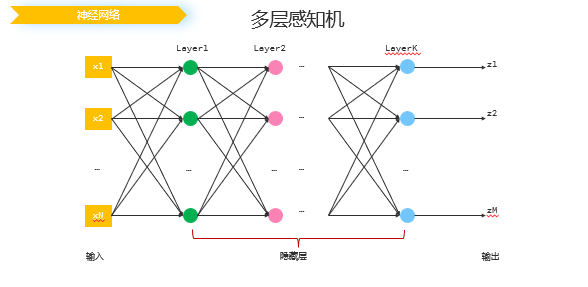
神经网络
将多个感知机组合(将其输入输出链接起来)起来实现复杂的感知机模型,这个也是我们日常所说的神经网络(因为可以让感知机模拟神经突触,而亿万个神经突触就形成了神经网络),也可以成为模型。
而我们所说的大模型,就是感知机的数量特别多,就称为了大模型。
什么是Agent?
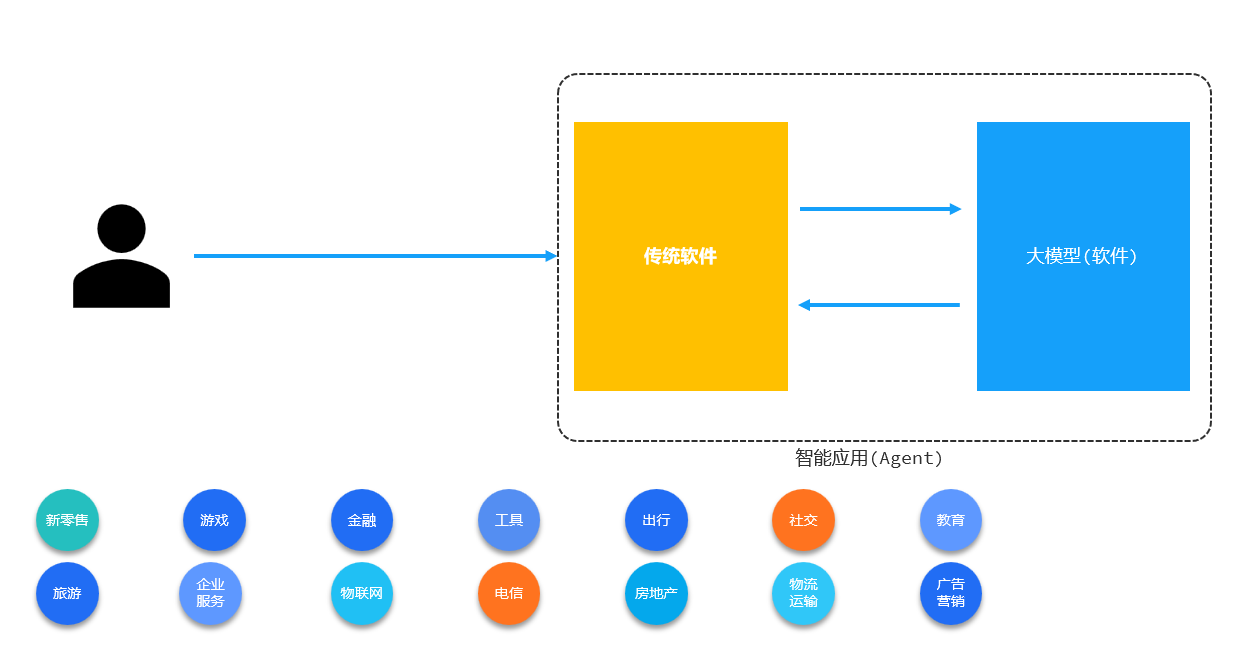
Agent 指智能体,是一个能够感知其环境,并通过采取行动以实现最佳目标的系统 。在 AI 领域,带有 AI 的应用可以被看作是一种 Agent 的体现形式,它能根据用户输入、环境变化等,利用 AI 技术(如机器学习、深度学习等)做出响应和决策,为用户提供智能化的服务。
可以理解为,一个传统的应用在用户日常的使用过程当中会产生参数数据,而通过这些数据给大模型进行使用推测,这样就可以为用户推理出更适合的路线(更优的服务)。
如下述例子描述:
明确要开发的 Agent 需达成的目标,像电商领域中,目标可能是开发能根据用户浏览和购买历史,精准推送商品的购物助手 Agent;教育领域里,可能是开发能依据学生学习进度和知识掌握情况,提供个性化学习方案的辅导 Agent 。
大模型的本地部署
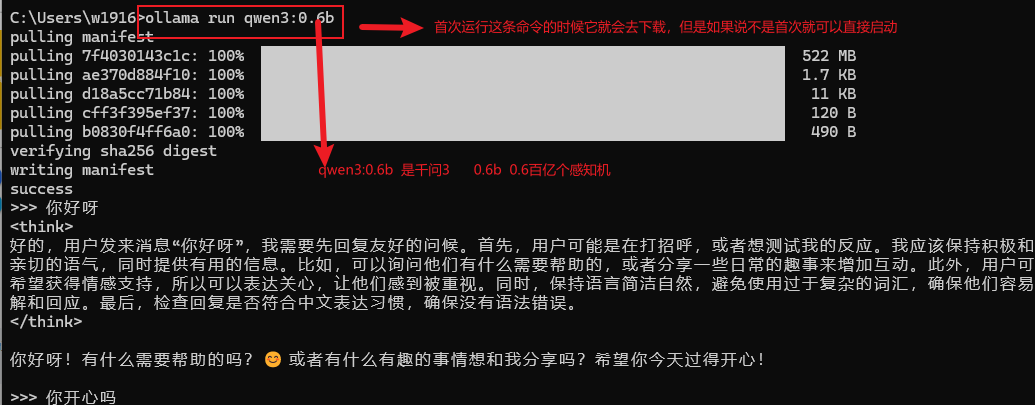
Ollama是一种用于快速下载、部署、管理大模型的工具,下载它之后,只需要一条简单的命令就能够让他一键下载模型,并进行管理使用。
2.大模型调用
2.1请求常见参数
role:该参数指定消息内容是由哪个角色输入的,user参数指定用户输入,system可以指定该大模型的身份,assistant做为大模型的回答内容,它存在的意义就是为了一直讨论一个问题,进行会话记忆。(不传递给它,它自己说了什么都不知道,怎么继续延申呢)
stream:可以让消息生成一点输出一点,而不是一次性生成。
如下图所示:

2.2相应常见参数
最重要的就是choices数组当中的message消息,就是回答的内容。
usage返回的是本次输出你使用了多少token的信息,token作为大模型能识别的最小片段,也作为收费标准。

2.3spring boot 整合LangChain4j
使用的jdk是17 boot版本是3.2.9
下面直接给出我的pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.qingjin</groupId>
<artifactId>consutant</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>consutant</name>
<description>consutant</description>
<properties>
<java.version>17</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>3.2.9</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 引入langchain4j的依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>
<!-- 引入aiservice需要的依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>
<!-- 流式调用的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.1-beta6</version>
</dependency>
<!-- 日志依赖-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
<configuration>
<source>17</source>
<target>17</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>com.qingjin.consutant.ConsutantApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
配置文件:
langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true #开启调用日志
log-responses: true
logging:
level:
dev.langchain4j: DEBUG
这里我就直接给出,最为简化的开发的模式代码,并进行解释
代码的整体架构是如下的:
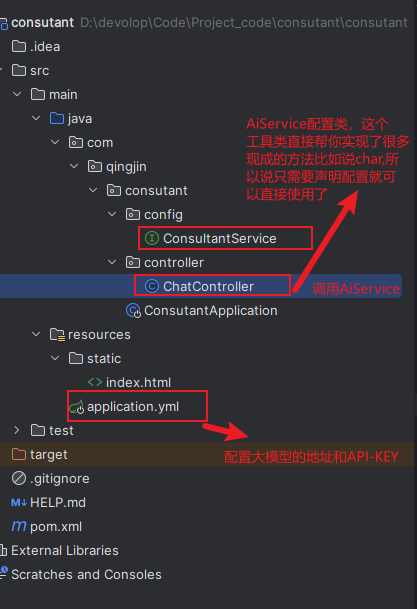
3.AiService工具类的作用
最明显的作用如下两端代码去调用大语言模型:
不使用AiService类的时候,发送一条需要一些类复杂配置,这些配置都是固定的,AiService在底层就实现了。大大的简化了开发,而且AiService还可以继承会话记忆(就是和大模型的对话过程记录下来,这样才能正常交谈)。
// 1. 初始化 LLM 客户端(如 OpenAI)
OpenAiChatModel model = OpenAiChatModel.builder()
.apiKey("sk-xxx")
.modelName("gpt-3.5-turbo")
.temperature(0.7)
.build();
// 2. 手动拼接 prompt
String prompt = String.format("生成一篇%s酒店的介绍,突出%s特点,200字以内", "北京", "近故宫");
// 3. 发送请求并解析结果
ChatResponse response = model.generate(ChatMessage.user(prompt));
String hotelIntro = response.getContent(); // 手动提取结果// 1. 定义 AiService 接口(仅需声明业务方法,无需实现)
@AiService // 关键注解:LangChain4j 自动生成实现类
public interface HotelAiService {
// 方法参数自动注入到 prompt,返回值自动解析为字符串
@SystemMessage("你是酒店文案生成专家,生成内容简洁、符合用户需求")
String generateHotelIntro(@UserMessage("生成一篇{city}酒店的介绍,突出{feature}特点,200字以内")
String city, String feature);
}
// 2. 业务代码直接注入使用(无需关注 LLM 细节)
@Service
public class HotelService {
@Autowired
private HotelAiService hotelAiService;
public String getHotelIntro(String city, String feature) {
// 直接调用接口,LangChain4j 自动完成 LLM 调用与结果返回
return hotelAiService.generateHotelIntro(city, feature);
}
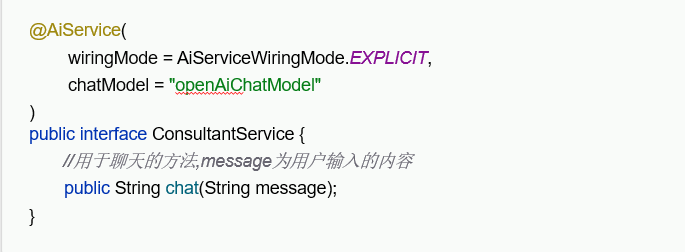
}AiService注解的作用
该注解可以声明使用的模型是什么,但是也可以默认,默认的话就会去读取配置文件的,openAiChatModel属性。也可以指明流式输出模型,以及对话存储记忆。
如何开启流式调用?
1.引入下面两个依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.1-beta6</version>
</dependency>2.配置文件当中配置和原型模型一样(前缀不同)的配置如下:
langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true #开启调用日志
log-responses: true
streaming-chat-model: #流式模型
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true #开启调用日志
log-responses: true
logging:
level:
dev.langchain4j: DEBUG
3.设置AiService的返回值为Flux
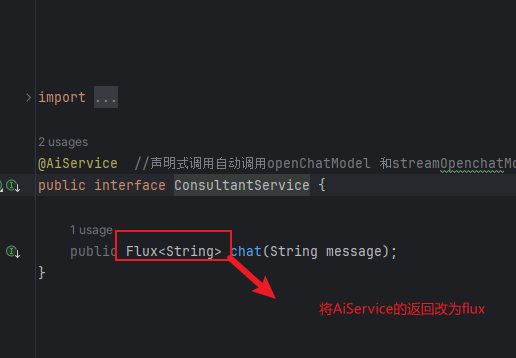
通过上述的配置,AiService注解就会自动读取配置文件当中的streaming-chat-model设置为流模型,chat方法的返回值不一致形成了方法的重载(父类当中有多个chat方法 string/flux),所以说就会调用流式输出的chat方法。
4.会话记忆功能
会话记忆功能主要解决的是,用户和大模型之间的对话的上下文的关系,只有把整个交流过程发给大模型,才能够正常的和大模型交流,不然对话就是间断的,不连续。其中核心包括了,会话存储,隔离和持久化。
4.1会话记忆存储
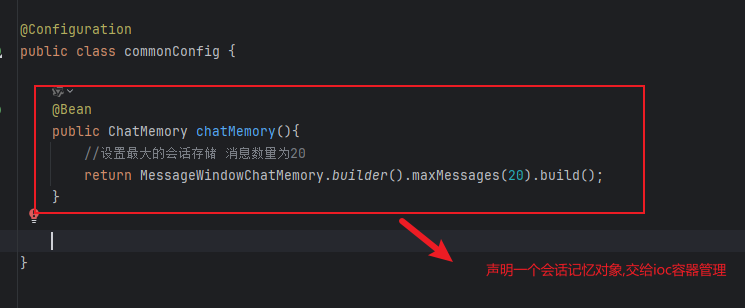
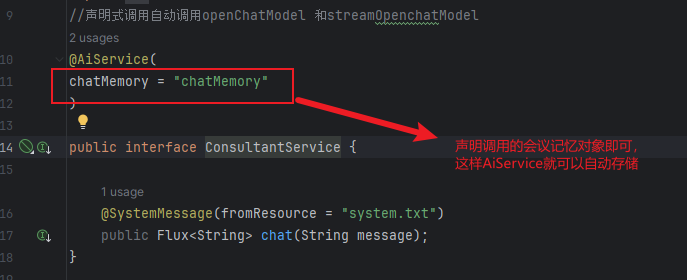
会话记忆主要还是借助的AIService类,给其配置一个会议记忆对象,即可。
具体方式如下:
1.配置一个会话记忆对象
会话记忆隔离
会话记忆隔离,指的是一个用户应该对于自己的会话记忆。
如下:ChatMemory接口下有一个id字段专门用来进行会话隔离的。这个id需要前端进行传递,后端只需要判断该id是否有存储记忆即可。
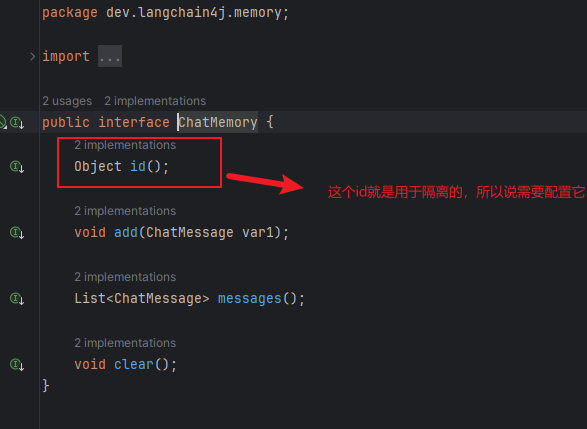
LangChain4j提供了工具来帮助我们实现隔离
会话记忆对象提供者
该对象的作用就是,根据memoryId去判断当前请求是否包含会话记忆,如果说不存在的话就新创建一个,并把当前用户的消息放入进去,如果说存在了就直接将用户的信息添加进去即可,这样就实现了会话的隔离。
实现方式
还是通过配置的方式进行使用
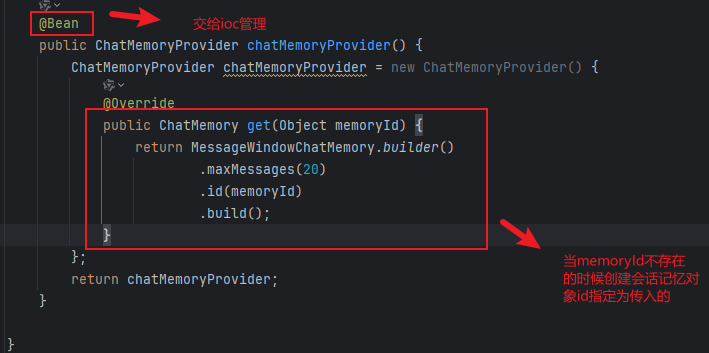
1.创建一个bean 进行提供一个provider对象,内部就是提供一个会话对象
该provider的主要作用就是 若这个id存在就往这个id内容里面添加值
不存在的话就直接创建一个id为传入的memoryid的新会话记忆对象
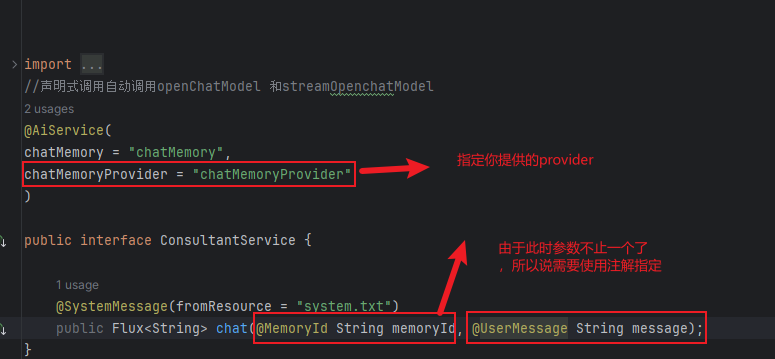
2.修改chat方法需要接收前端传递的固定id,这个id一般是时间戳,由前端生成然后传递给后端,前端控制如果说想开启新的会话就清空前端的id再生成一个新的id即可,这样就实现了创建新会话。
会话记忆持久化
如下分析:
会话记忆对象的底层实现是由List实现的,所以说不能够做到持久化,但是我们可以自定义一个会话store,重写里面的方法去将数据存储到数据库当中当中实现持久化。
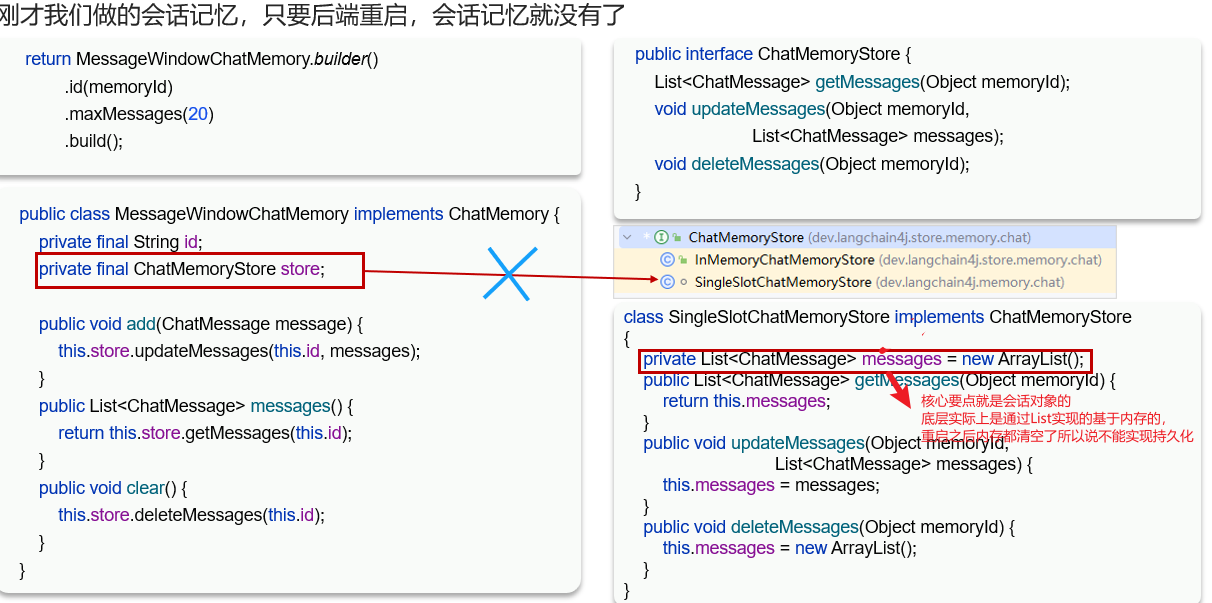
通过Redis实现持久化方式
核心代码如下:
重写了getMessage和updateMessage和deleteMessage,这样AiService去调用会话记忆对象(charMemory)的时候,就会根据下面的规则进行数据的持久化了,清楚该store是位于charMemory下去实现存储消息集合的方式即可,通过重写,并赋值给provider,这样就能够实现消息持久化到数据库当中。
package com.qingjin.consutant.store;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.Duration;
import java.util.List;
@Component //交给ioc容器管理
public class RedisChatMemoryStore implements ChatMemoryStore {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String s = redisTemplate.opsForValue().get(memoryId.toString());
List<ChatMessage> list = ChatMessageDeserializer.messagesFromJson(s); //langchain4j提供的反序列化list的方法
return list;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
//存储list到redis中
String s = ChatMessageSerializer.messagesToJson(list);
redisTemplate.opsForValue().set(memoryId.toString(),s, Duration.ofDays(1));
}
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(memoryId.toString()); //使用通用方法删除key
}
}
第二步配置provider
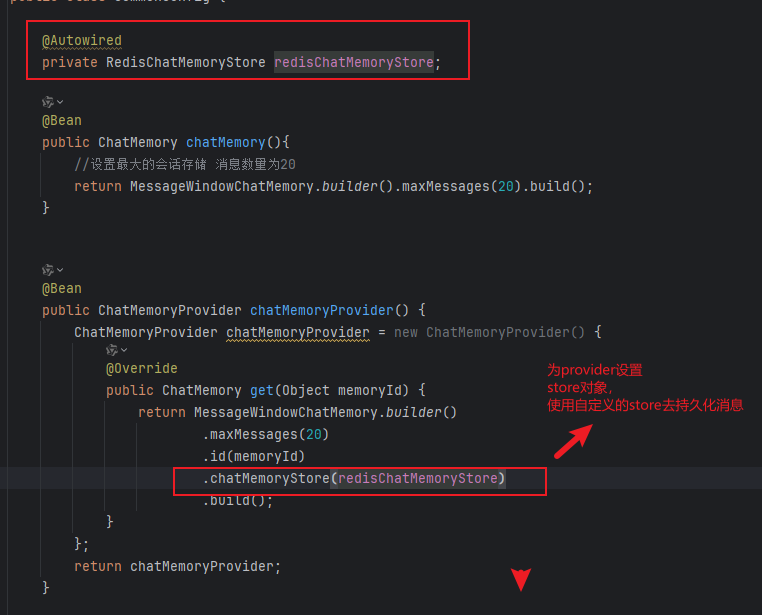
实现结果如下:
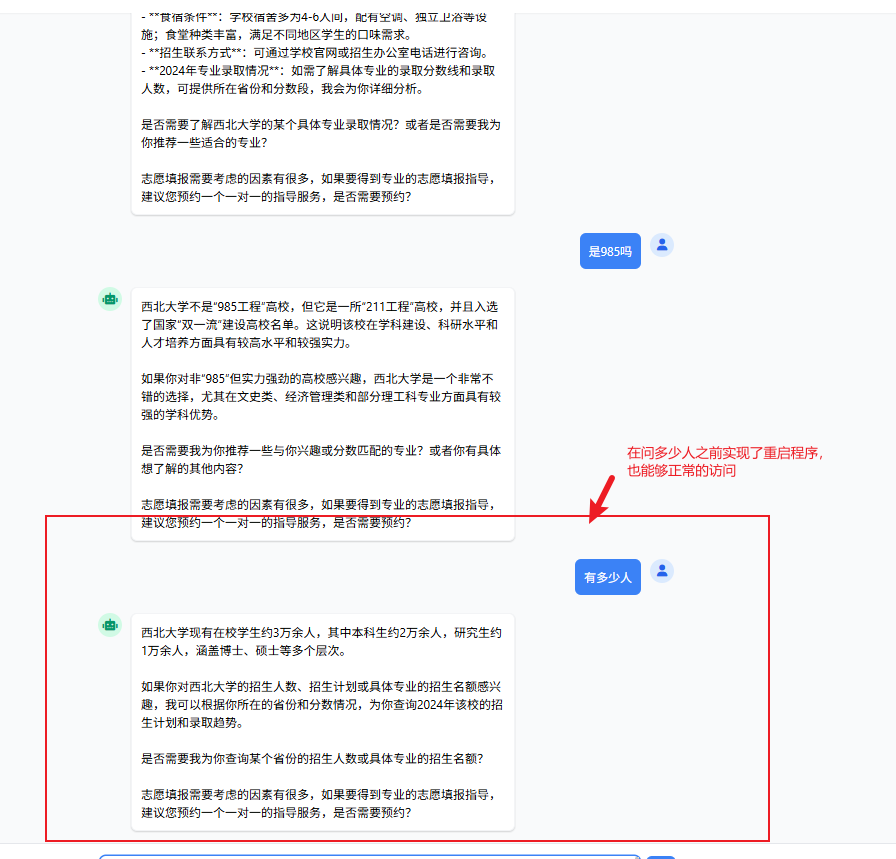
Redis当中持久化的数据

RAG知识库
由于大模型训练的数据不一定是专业化的,也不一定是最新的数据,所以说RAG提供了一种检索增强生成的方式吗,为大模型增强回答结果。
其实做的就是在发送数据给大模型之前,先做到了一个对问题的增强。
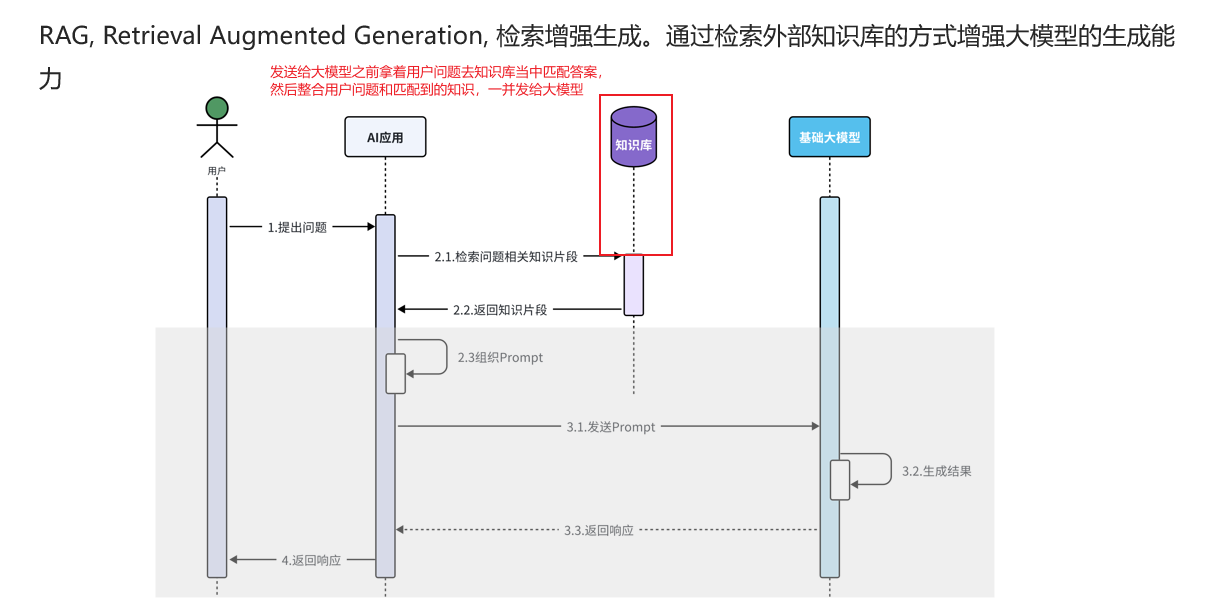
RAG知识库的原理
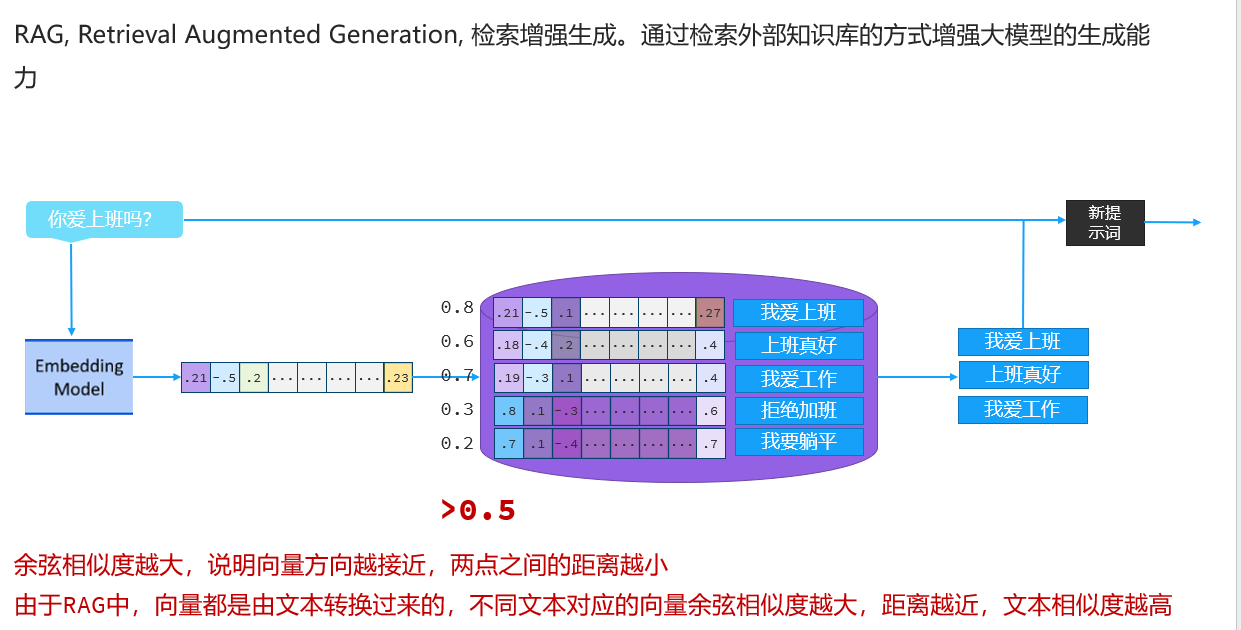
RAG知识库的底层原理其实是基于向量的cos值来匹配转换为向量的数据是否匹配,如果说相似度高那么两条数据趋近于重合这样就能够找到相关的数据了。
.
下图是将文档分割为存入向量数据库的原理过程,也是 RAG存储向量的过程,就是将文档切割为比较小的部分,然后转换为向量进行存储即可。
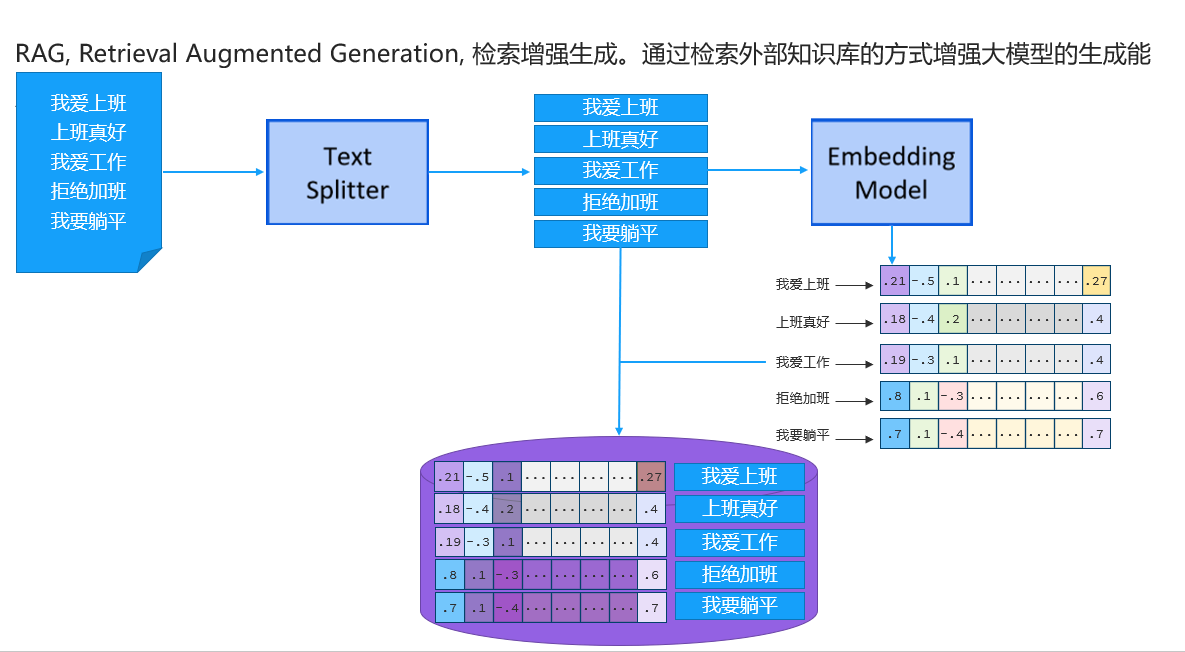
下图就是拿着用户的问题去转换为向量,然后到RAG数据库当中进行向量的匹配,余弦相似度越高的就匹配度越高,说明用户的问题和当前存储的数据有关,这样就将的问题和拿到的知识库的数据拼接在一起并发给大模型。
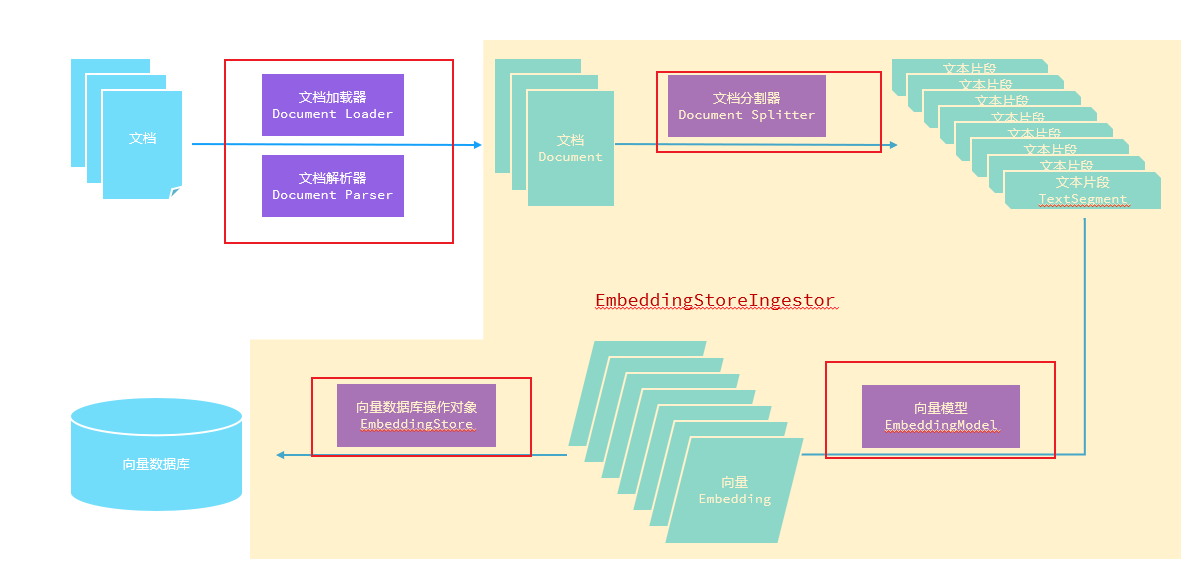
5.LangChain4j对于RAG的核心API
主要是分为以下几个核心API,LangChain4j对于这几个核心API提供了各种各样的类,在不同的场景下使用。
5.1文档加载器

如下图所示是对不同的文档加载器的使用

5.2文档解析器

要使用某一个文档解析器就需要引入对应的依赖,然后就可以直接在文档加载器当中进行传递即可。
拿解析pdf格式文件举例:
引入依赖
<!-- apache的pdf文档解析器-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.1-beta6</version>
</dependency>
使用加载器的时候指定解析器:

根据以上的操作就完美的实现了对pdf文件的支持
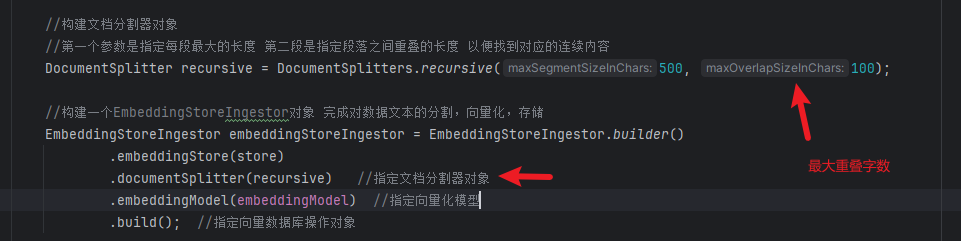
5.3文档分割器
文档分割器的任务是按照规则对文档进行规则分割,不同的规则分割的结果不一样。
默认的递归分割器会不断的去将文本小分割,然后进来的填充进你设置的最大字符数。

如下设置了文档分割器
5.4向量模型
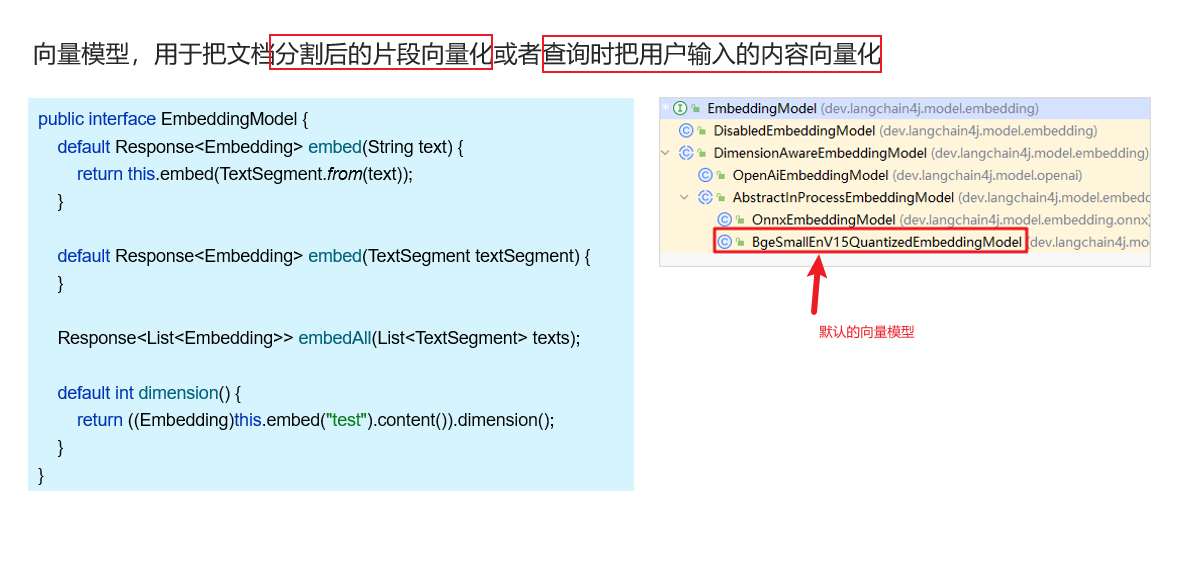
可以使用第三方的向量模型:
也只需要在配置文件进行配置,然后注入对象使用即可
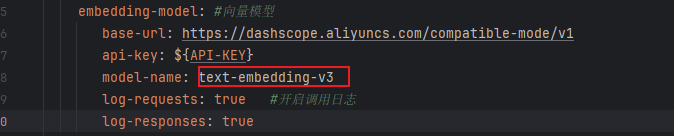
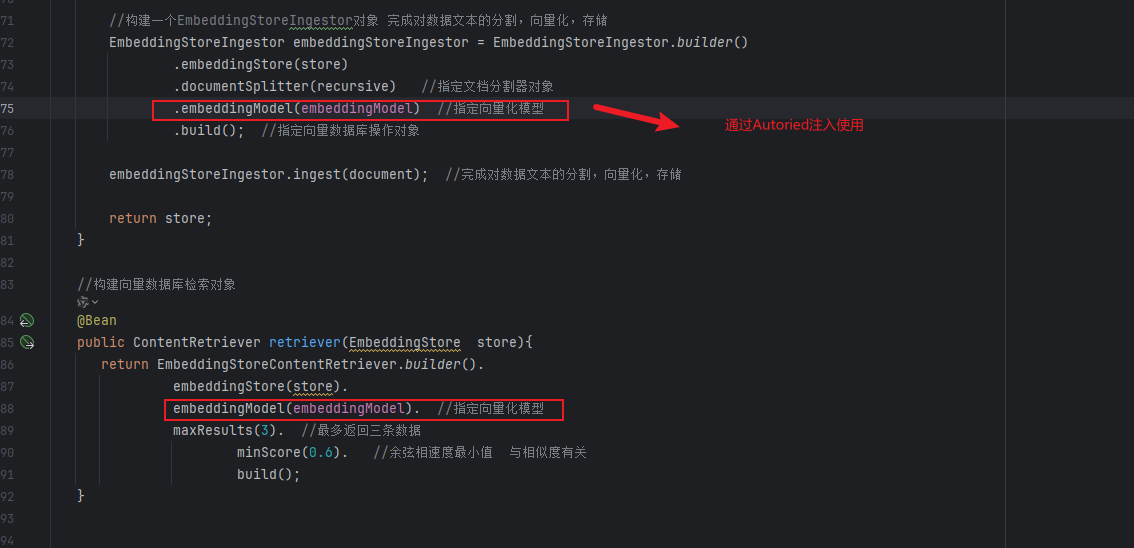
使用向量模型
分别给store和reriver(介绍用户的语句进行分割的对象)
Tools工具
tools工具是允许让我们在操作过程当中操作某个方法的,原理如下,当配置了tools方法,LangChain4j会将配置的tools方法一并发送给大模型,大模型会根据用户发送的语句,去推断是否需要调用function,把要调用的方法和参数都传递回来而最核心的也在于一个话语的配置。
如图是assitant传递回来的消息,去调用对应的方法,参数也是有的

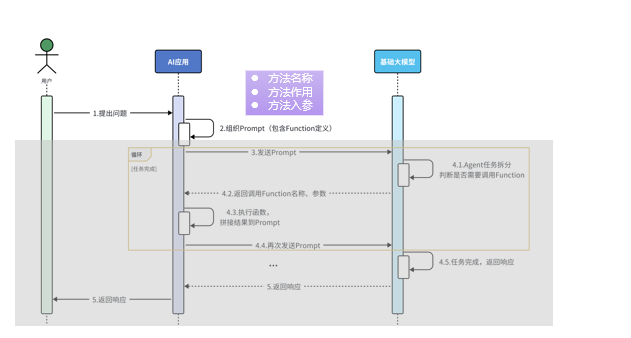
如下是话语的配置,当用户表明了自己需要去预约的时候,那么大模型就会去推断此次要预约,而就去推断预约调用哪个方法,而方法上的参数和用户传递的参数是一致并且,方法名称是大模型判断是否需要调用的关键所在。

核心工具方法:
package com.qingjin.consutant.tool;
import com.qingjin.consutant.entity.Volunteer;
import com.qingjin.consutant.mapper.VolunteerMapper;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
public class ReservationTool {
@Autowired
private VolunteerMapper volunteerMapper;
@Tool(name = "添加志愿指导服务预约")
public void addReservation(
@P("考生姓名") String name,
@P("考生性别")String gender,
@P("考生电话") String phone,
@P("沟通时间")LocalDateTime communicationTime,
@P("考生所在省份") String province,
@P("考生预估分数") Integer estimatedScore
) {
Volunteer volunteer = new Volunteer(null, name, gender, phone, communicationTime, province, estimatedScore);
volunteerMapper.insert(volunteer);
}
@Tool(name = "根据考生电话查询考试预约详情")
public Volunteer findByPhone(@P("考生电话") String phone) {
return volunteerMapper.findByPhone(phone);
}
}
最后在AiService开启即可:
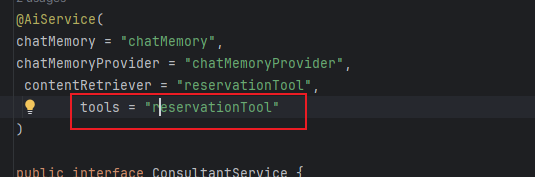
这样就实现了Tools工具类的调用,每当表明有预约倾向的时候,这时候就会去调用插入方法实现预约。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)