LLM之RAG实战(五十八)| Agentic RAG 如何改变信息检索
在开始之前,让我们先介绍一下RAG基础知识。RAG 主要包括两个步骤: 检索 (从数据库中查找相关信息)和生成 (使用 GPT 等 LLM 根据检索到的信息生成响应)。这有助于帮助LLM在真实数据中生成正确答案来避免“幻觉”(编造事实)。示例:您问人工智能:“气候变化政策的最新情况是什么?”,传统的 RAG 会将查询嵌入为向量,在向量数据库中搜索文档中的类似文本块,并将它们提供给 LLM 以获得响

在人工智能领域,检索增强生成 (RAG) 改变了游戏规则,通过引入外部知识使大型语言模型 (LLM) 变得更加智能。但严重依赖向量数据库来存储和获取数据块,这是传统 RAG 致命缺陷。Agentic RAG是一种更智能、由agent驱动的方法,正在改变一切。我们所知道的向量数据库就这样结束了吗?不完全是,但 Agentic RAG 正在通过使信息检索动态、适应性和更有效来突破界限。
将传统的 RAG 想象成一个图书馆员,他根据关键字检索书籍,但不检查它们是否正是您需要的。Agentic RAG 就像一个智能助手,可以提出问题、完善您的请求、搜索多个货架(甚至在线),并在提交信息之前仔细检查。在这里,我们将深入探讨传统 RAG 为何陷入困境,以及 Agentic RAG 如何解决它。
一、什么是 RAG?
在开始之前,让我们先介绍一下RAG基础知识。RAG 主要包括两个步骤: 检索 (从数据库中查找相关信息)和生成 (使用 GPT 等 LLM 根据检索到的信息生成响应)。这有助于帮助LLM在真实数据中生成正确答案来避免“幻觉”(编造事实)。
示例:您问人工智能:“气候变化政策的最新情况是什么?”,传统的 RAG 会将查询嵌入为向量,在向量数据库中搜索文档中的类似文本块,并将它们提供给 LLM 以获得响应。
但随着查询变得复杂,这种简单的设置就显得不够了。
二、传统 RAG 的问题
传统的 RAG 适用于简单的问题,在复杂性下就会崩溃。下面我们从多个角度来看一下传统RAG的窘境。
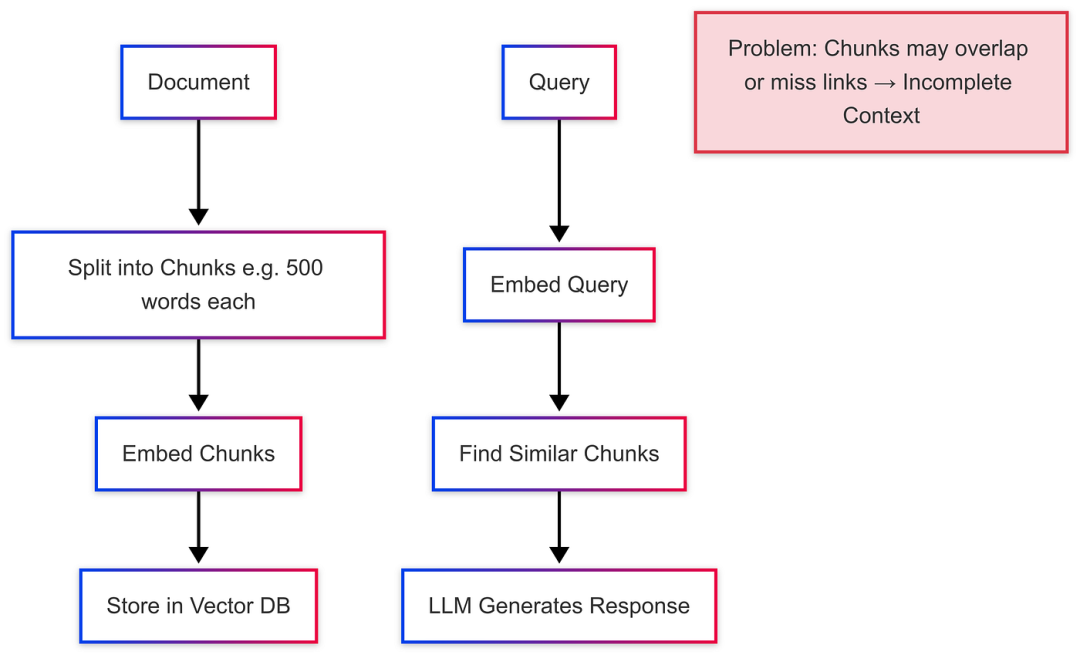
2.1 分块窘境
文件不整齐,又长又乱。传统的 RAG 将它们拆分为“块”(小文本片段)以嵌入到矢量中。但是块应该有多大呢?太小,你会失去上下文(例如,没有段落的句子)。太大,检索效率低下。
例: 想象一下一份关于电动汽车的 10 页报告。如果按句子分块,查询“电池寿命问题”可能会错过与另一个块中的“充电基础设施”的连接。
输出 :肤浅的回应,例如“电池会随着时间的推移而退化”,缺少更广泛的背景。
2.2 嵌入模型
嵌入将文本转换为数字(向量)以进行相似性搜索。但并非所有的嵌入都是平等的,它们可能会错过同义词或讽刺等细微差别。这是一场“彩票”,因为结果取决于嵌入模型,而糟糕的结果会导致不相关的检索。
示例 :查询:“苹果股崩盘。糟糕的嵌入可能会拉出水果从树上掉下来而不是从公司掉下来的块。
输出 :响应中令人困惑的混淆。
常见的嵌入问题:

2.3 向量数据库
矢量数据库(如 Pinecone 或 Weaviate)功能强大,但很麻烦。您需要为数据创建索引、处理缩放、管理更新并支付计算费用。对于大型数据集,这就像驯服野生动物一样,成本高昂且复杂。
示例 :一家拥有数百万个文档的公司必须随着数据的变化不断重新索引。一次更新?繁荣、停机或错误。
2.4 上下文
LLM 有tokens限制(例如,GPT-4 为 128K)。传统的 RAG 内容在提示中检索了块,但如果块不相关或太多,上下文就会被“杀死”,LLM 会忽略关键部分或产生幻觉。
幻觉风险即使进行了检索,如果块不能完全回答查询,LLM 也会用虚构的信息填补空白。研究表明,传统的 RAG 可以减少 50-70% 的幻觉,但对于多步骤问题则不然。
三、Agentic RAG
Agentic RAG 通过添加“agents”AI 组件(比如思考、计划和行动)来弥补传统RAG的不足。代理的流程不是静态的,而是根据环境动态决定下一步该做什么,从而使系统具有适应性。
3.1 核心概念
从本质上讲,Agentic RAG 将检索视为一个推理过程。代理使用以下模式:
-
反思(Reflection) :批评和改进产出。
-
规划(Planning) :将查询分解为多个步骤。
-
工具使用(Tool Use) :调用外部资源(例如网络搜索、API)。
-
多代理协作(Multi-Agent Collaboration) :多个代理组队(例如,一个检索,另一个验证)。
这种理念从“检索和希望”转变为“推理和适应”,尽管它们仍然有用,但可能会减少在简单情况下对海量向量数据库的需求。
3.2 技术拆解
Step1:文档导航器
代理首先“导航”您的数据。它优化查询、决定工具和检索。
工作流如下所示:
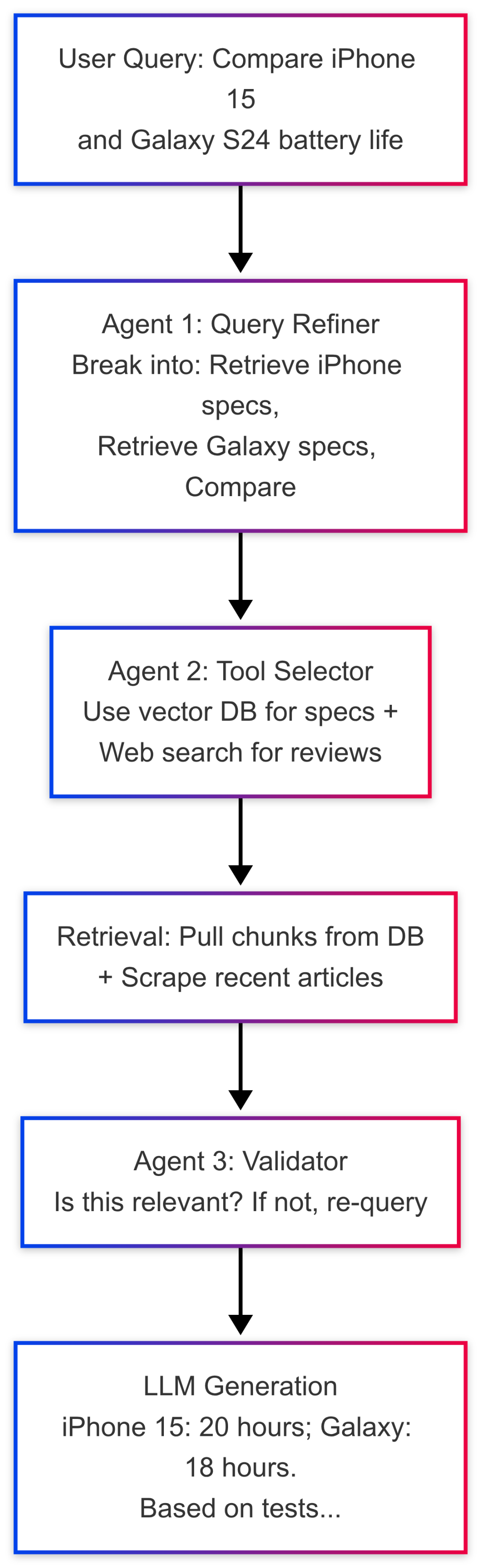
输出示例: 查询:“巧克力蛋糕的最佳食谱。
-
传统 RAG:检索随机块,输出基本配方。
-
代理 RAG:代理检查饮食需求(例如素食主义者?),在网上搜索变化,验证新鲜度。
-
输出:“纯素巧克力蛋糕:配料 2 杯面粉......步骤:在 350°F 下烘烤 30 分钟。资料来源:最近的 Allrecipes 评论。
代码(使用 LangChain 进行简单的代理 RAG):
from langchain_openai import OpenAIfrom langchain.tools import Toolfrom langchain.agents import initialize_agent# Define tools (e.g., a retriever and web search)retriever_tool = Tool(name="Retriever", func=lambda q: "Retrieved: Chocolate recipe chunks")web_search_tool = Tool(name="WebSearch", func=lambda q: "Web: Vegan variations")# Initialize LLM and agentllm = OpenAI(temperature=0.7)agent = initialize_agent(tools=[retriever_tool, web_search_tool], llm=llm, agent_type="zero-shot-react-description")# Run queryresponse = agent.run("Find a vegan chocolate cake recipe.")print(response)
四、Agentic RAG vs 传统 RAG
为了清楚起见,让我们在表格中进行比较。

查询:“计划去巴黎的旅行,包括预算和天气。
-
传统 RAG:检索块,输出脱节的信息。
-
Agentic RAG:代理计划步骤(天气 API、预算计算器)、
-
输出:“预算:1500 美元。天气:20°C 晴。行程:第一天......”
五、Agentic RAG的优缺点
5.1 优点
-
动态检索 :代理即时选择源(矢量数据库、Web、API)。
-
自我更正 :如果需要,验证并重新检索。
-
多步骤推理 :处理“假设”场景。
-
工具集成 :调用计算器、电子邮件或代码执行器。
5.2 缺点
代理 RAG 并不完美:
-
延迟和成本 :多个座席呼叫 = 响应较慢,账单较高。
-
复杂性 :构建和调试代理很困难。
-
协调: 多代理可能会沟通不畅。
-
道德问题 :动态数据提取的隐私风险。
缓解措施:为代理使用较小的 LLM,添加保护措施。
六、什么时候选择Agentic RAG?
如果出现以下情况,请继续这样做:
-
查询是复杂/多步骤的。
-
数据是动态的(例如,实时新闻)。
-
您需要高精度而不是速度。
坚持传统,对静态数据进行简单的问答。
七、未来的可能性
Agentic RAG 可以演变成完全自主的人工智能系统。
趋势:语音代理、浏览器作代理、深入研究工具。矢量数据库不会消亡,它们将作为众多工具中的一个集成。期待像 LangGraph 这样的框架使构建变得更容易。
八、Agentic RAG系统
让我们使用 Python 和 LangGraph(一种流行的框架)构建一个基本的框架。
步骤如下:
1、安装相关包:
pip install langchain langgraph openai2、设置 OpenAI API 密钥。
3、代码:
from langgraph.graph import StateGraph, ENDfrom langchain_core.messages import HumanMessagefrom langchain_openai import ChatOpenAI# Define state and agentsclass State:query: strcontext: str = ""llm = ChatOpenAI(model="gpt-4")def refine_query(state):refined = llm.invoke([HumanMessage(content=f"Refine: {state.query}")]).contentreturn {"query": refined}def retrieve(state):# Simulate retrievalcontext = "Retrieved context for " + state.queryreturn {"context": context}def generate(state):response = llm.invoke([HumanMessage(content=f"Generate with context: {state.context}")]).contentreturn {"query": response}# Build graphworkflow = StateGraph(State)workflow.add_node("refine", refine_query)workflow.add_node("retrieve", retrieve)workflow.add_node("generate", generate)workflow.set_entry_point("refine")workflow.add_edge("refine", "retrieve")workflow.add_edge("retrieve", "generate")workflow.add_edge("generate", END)app = workflow.compile()# Runresult = app.invoke({"query": "Easy chocolate cake recipe"})print(result["query"])
这是一个入门级添加真实工具,例如用于生产的矢量数据库(例如 FAISS)。测试它:输入查询,查看实际的工作流程。
总之,Agentic RAG 并没有扼杀矢量数据库,而是将它们发展成为更智能生态系统的一部分。通过使检索代理驱动,它正在彻底改变人工智能处理信息的方式,一次一个自适应步骤。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)