ICML 2025 | MMMC:揭示多模态大模型幻觉来源之一——模态冲突!
布朗大学与AWS团队在ICLR2025发表的研究提出新理论框架,从流形几何角度分析连续强化学习中的策略学习动态。研究发现,神经网络策略生成的状态分布存在于低维流形中,其维度与动作空间同阶。基于此,团队提出局部流形学习层,在MuJoCo等复杂控制任务中验证了性能提升。该研究首次系统揭示了连续RL训练的几何本质,为高维控制任务提供了新的优化思路和理论基础。
1. 【前言】
在连续状态与动作空间的强化学习(RL)研究中,策略学习的状态-动作分布几何结构是理解学习动态、优化算法性能的关键。然而,现有理论多集中在离散状态-动作空间或假设性的线性系统,对于实际中高维、非线性、神经网络参数化的策略,缺乏统一的几何刻画框架。这导致我们在理解 RL 训练收敛性、策略泛化能力以及结构优化方向时,缺乏明确的理论锚点——尤其是在连续控制任务中,状态空间的高维性与动作空间的限制性之间的关系仍是一个“黑箱”。
为破解这一困境,来自布朗大学与Amazon Web Services(AWS)的研究团队在 ICLR 2025 上提出了全新理论框架,首次从流形几何(manifold geometry)视角系统分析了神经网络策略在连续空间中的可达状态集结构。团队发现:在常用的两层神经网络策略与 actor-critic 框架下,策略生成的状态分布并非遍布整个状态空间,而是近似落在一个维度上界与动作空间维度同阶的低维流形中。基于这一关键现象,作者进一步提出了局部流形学习层(Local Manifold Learning Layer),在保持模型性能的同时,有效压缩表示维度,降低训练与推理的计算开销。
值得强调的是,这一研究不仅在理论上揭示了策略学习的几何本质,也为高自由度连续控制任务提供了新的优化思路——通过显式利用可达状态流形的低维结构,可以在 MuJoCo 等复杂环境中实现更高效、更稳健的策略学习,为构建具备可解释性与可扩展性的下一代 RL 系统奠定了几何基础。
2.【论文基本信息】

文章基本信息
-
论文标题:Geometry of Neural Reinforcement Learning in Continuous State and Action Spaces
-
论文链接:https://arxiv.org/abs/2507.20853
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/YFLzS9tPVPdKRRqOytlFuA
https://mp.weixin.qq.com/s/YFLzS9tPVPdKRRqOytlFuA
3.【创新点概述】
3.1 连续空间下策略可达状态流形的维度上界
-
在常用的两层神经网络策略 + actor-critic 框架中,首次严格证明了可达状态流形(reachable state manifold) 的维度上界与动作空间维度同阶,而非与高维状态空间维度一致。
-
这一结果为连续控制任务中状态-动作分布的几何结构提供了明确的理论刻画,填补了过去 RL 理论集中于离散空间的空白。
3.2 流形几何视角解析 RL 训练动态
-
通过引入动作切向映射(action tangent mapping) 分析状态演化方向,揭示了神经策略在训练过程中生成的状态轨迹是受限于动作空间维度的低维流形。
-
将机器学习中的流形假设与 RL 策略学习过程首次系统结合,建立了几何-学习动力学的桥梁。
3.3 局部流形学习层(Local Manifold Learning Layer)
-
基于上述几何发现,提出一种可插拔的局部流形学习层,可嵌入策略网络与价值网络中,学习状态的低维稀疏表示。
-
该模块既可用于训练阶段提升样本效率,也可用于推理阶段降低计算开销,且在 MuJoCo 等高自由度连续控制任务中验证了性能提升。
4.【整体架构流程】
4.1 两层网络的参数化与线性化
考虑一个两层全连接神经网络策略:
其中:
-
为状态向量;
-
为动作向量;
-
为隐藏层神经元数(网络宽度);
-
为第一层权重;
-
为固定的输出层权重;
-
为激活函数(选用平滑的 GeLU)。
初始化时 固定为 ,训练过程中只更新 。
在宽网络且参数更新幅度较小的情况下,对 在初始化点 处做一阶泰勒展开:
其中 为特征矩阵,由 、 以及 构成。 的维度为 ,可视为 个 的块横向拼接。
定义线性化策略集合:
该集合中的策略在参数球半径 内与原始网络近似等价,便于几何分析。
4.2 连续时间的策略梯度与参数更新
在策略梯度框架下,梯度可写为:
其中 为时间 下的动作价值函数, 为策略诱导的状态分布。
离散时间下,mini-batch SGD 更新可表示为:
其中 为 batch size, 为学习率。
将其改写为“确定性梯度 + 噪声”形式:
其中 为均值为零的梯度噪声。
4.3 把环境动力学写成 SDE(状态演化)
环境动力学采用控制亲和形式的随机微分方程:
其中:
-
为无控制漂移项;
-
为与第 维动作相关的向量场;
-
为线性化策略输出的第 个分量;
-
为探索噪声项。
该形式使得策略对应于一族参数化向量场,从而将强化学习训练问题转化为流形可达性分析问题。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/YFLzS9tPVPdKRRqOytlFuA
https://mp.weixin.qq.com/s/YFLzS9tPVPdKRRqOytlFuA
5.【实验结果】
实验设置:本文设置了三类实验以验证理论发现与方法有效性:
-
线性化策略模型验证:比较宽网络下线性化策略(linearised policy)与原始神经网络策略在 DDPG 上的表现,以评估线性化近似的逼近效果。
-
维度估计实验:在四种 MuJoCo 连续控制环境中,使用 Facco 等人提出的流形维度估计算法,验证可达状态流形的维度上界。
-
玩具环境 & 高维控制任务测试:在 toy 环境中测试可达状态维数随动作维度变化的规律;同时,在高自由度控制任务(如 Ant、Dog、Quadruped Walk)中,通过引入局部流形学习层(sparsification layer)与 SAC 算法结合,测试性能提升。
实验结果:
-
线性化策略模型验证 (Approximation Error with Linearised Policy) 在 Cheetah 环境下,随着网络宽度 增大(图中以 为大宽度区间),线性化策略引入的 return 差异几乎为 0,即
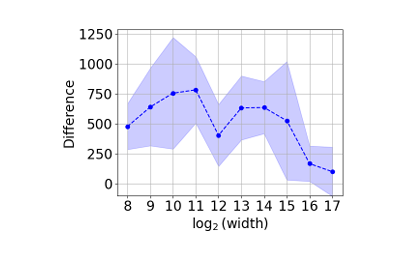
实验结果1
这表明宽网络且参数变化较小时,线性化模型能够准确逼近原始策略的学习动态,理论模型与实测表现高度一致。验证了使用线性化(linearised)策略作为理论简化模型是合理的,为后续使用几何工具进行分析提供了依据。
-
可达状态流形维度估计 在四个 MuJoCo 环境(如 Cheetah 等)中,实测可达状态集的维度估计值均低于理论上预测的上界
其中 为动作空间的维度。实验结果支持可达状态流形确实是低维的,且维度增长与动作空间维度呈同阶行为。实证验证了论文理论推导的关键结论:训练动态生成的可达状态流形具有与动作空间维度相当的低维结构。 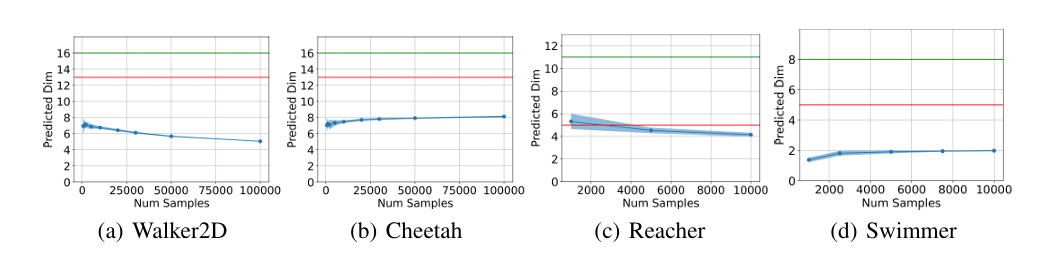
-
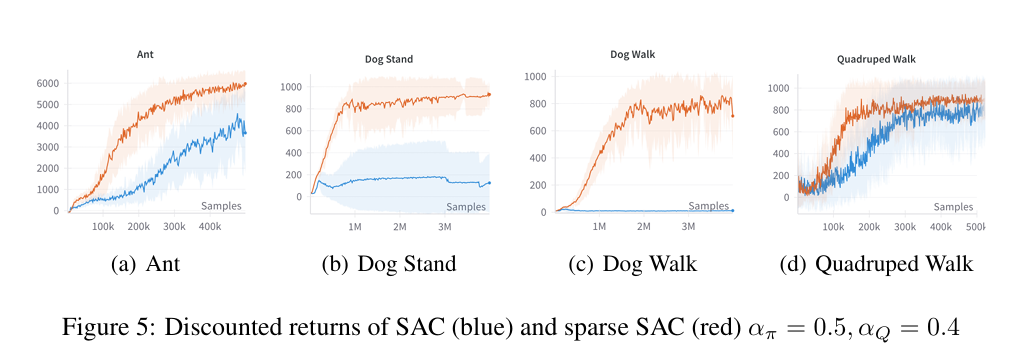
玩具环境与高维控制任务测试 玩具环境:在完全可达(fully reachable)toy 线性系统中,尽管该系统在经典控制理论下是全状态空间可达的,但受限于线性化策略族,可达状态仍集中在低维流形上。 高维控制任务:在 Ant、Dog Stand/Walk、Quadruped Walk 等高自由度任务中,将 SAC 算法中的全连接层替换为局部流形学习层(local manifold learning layer)后:
-
普通 SAC 在部分任务中无法收敛;
-
加入局部流形层后,在高维任务中显著提升了学习效果与稳定性。
实验展示了理论发现的实用价值——即使在高维任务中,仅做微小结构调整(注入低维表示机制)即可显著提升性能。
-
6. 【总结与展望】
总结
本文基于宽两层神经策略的线性化近似,首次从流形几何视角刻画了连续状态与动作空间下神经强化学习的动态演化。理论上证明了可达状态流形的维度受动作空间维度约束,且在实际复杂控制任务中该低维流形结构普遍存在。实验部分通过多环境维度估计、线性化策略逼近及高维控制任务验证了理论的有效性与实用性,进一步展示了基于流形结构设计的局部学习层可显著提升策略的训练效率和性能,彰显了理论对现实问题的指导价值。
展望
一方面,深入研究更宽更深神经网络结构中流形动力学的变化规律,探讨非线性效应对可达状态空间几何结构的影响; 另一方面,结合流形学习与强化学习的交叉技术,设计更高效的策略网络架构和优化算法,特别是在高维复杂环境中提升样本效率与泛化能力。此外,将该理论框架扩展至部分可观测环境及多智能体系统,亦具备广阔的应用前景,推动神经强化学习理论与实践的进一步融合与发展。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/YFLzS9tPVPdKRRqOytlFuA
https://mp.weixin.qq.com/s/YFLzS9tPVPdKRRqOytlFuA

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)