大模型推理显存优化系列(4):eLLM-大模型推理中的弹性显存管理和优化
本文将介绍eLLM相关技术挑战、总体设计和初步性能评估
文章作者:徐家乐 张锐 赵军平。
系列文章回顾⬇️
大模型推理显存优化系列(3):FlowMLA——面向高吞吐的DP MLA零冗余显存优化
简介
显存管理是大模型推理高效、规模化部署的关键技术之一。蚂蚁集团ASystem团队联合上海交通大学研发的eLLM,挖掘激活与KV cache的动态管理机会,通过弹性显存管理技术实现可用显存的显著提升,在典型模型和显存受限场景下,相比基线方案(基于vLLM)实现3x batch增加和2.3x decode吞吐提升。方案精度无损,无需微调等额外操作。
以下简要介绍eLLM相关技术挑战、总体设计和初步性能评估,完整的技术报告见以下论文链接。
-
eLLM: Elastic Memory Management Framework for Efficient LLM Serving
显存管理挑战
显存需求
随着模型架构发展、长上下文包括思维链等新场景推广,显存需求构成悄然发生一些变化:
-
模型架构创新:DeepSeek MLA、GLA(Group Latent Attn,Tri Dao等,参考文献[2])、混合线性等通过更高效KV cache设计显著降低了KV用量。例如Jamba-52B仅需2块GPU支持200K上下文,其中激活与KV cache用量接近1:1。
-
上下文扩展:上下文长度从2K扩展至200K时,prefill阶段激活内存占比从0.3%跃升至30.8%;而如果是短输入、长思维链,prefill阶段的激活显存在decode阶段无法被使用。
-
KV轻量化:针对KV的各种量化、压缩、稀疏探索层出不穷,而激活由于outlier的存在普遍难以轻量化。
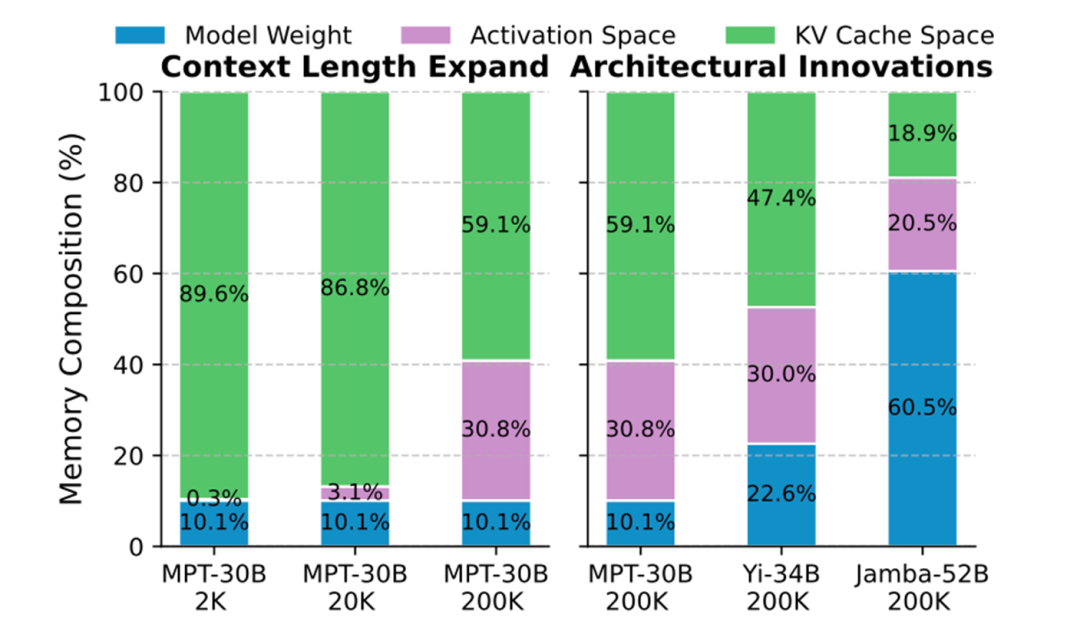
图1:典型推理显存构成(A100部署,vLLM)
以上因素叠加促使我们重新关注显存的总体优化,特别是考虑当前主流的推理框架由于一些设计或实现的限制,导致了显存资源事实上的浪费(抛个观点“闲置即浪费”,浪费的单位是 GB * msec,即容量x时间,时间以毫秒计),轻易放弃了优化压榨的机会。
显存管理不足
当前vLLM、SGLang等主流框架经过了充分改进,取得了广泛普及。不过显存管理方面仍存在一些不足:
-
碎片化管理:模型权重、KV cache和激活三分天下,在框架启动时静态圈了3个小池子,互不通用。尤其是KV和激活,随不同模型、负载或SLO等存在更多动态性和潜在流通性。可惜,他们被碎片化的隔离了。
-
激活显存闲置:框架按prefill阶段所需的最大激活显存所预留的显存小池子,到了decode阶段由于激活需求降低了10^3~10^4倍基本在闲置(decode每次1个token,相比Prefill输入1K ~ 32K ctx,降低了1K ~ 32K倍),即使随生成变长,KV cache压力变大,进而触发了recompute/offload等兜底手段在拼命换气,一旁的激活显存仍在躺平。系统缺乏显存的全局、动态调度机制。
-
chunk prefill的限制:chunk prefill可显著降低激活显存的占用(特别是prefill阶段),不过也存在一些限制:1)对一些模型不支持,例如至评测时不支持混合线性模型Jamba;2)影响TTFT指标。
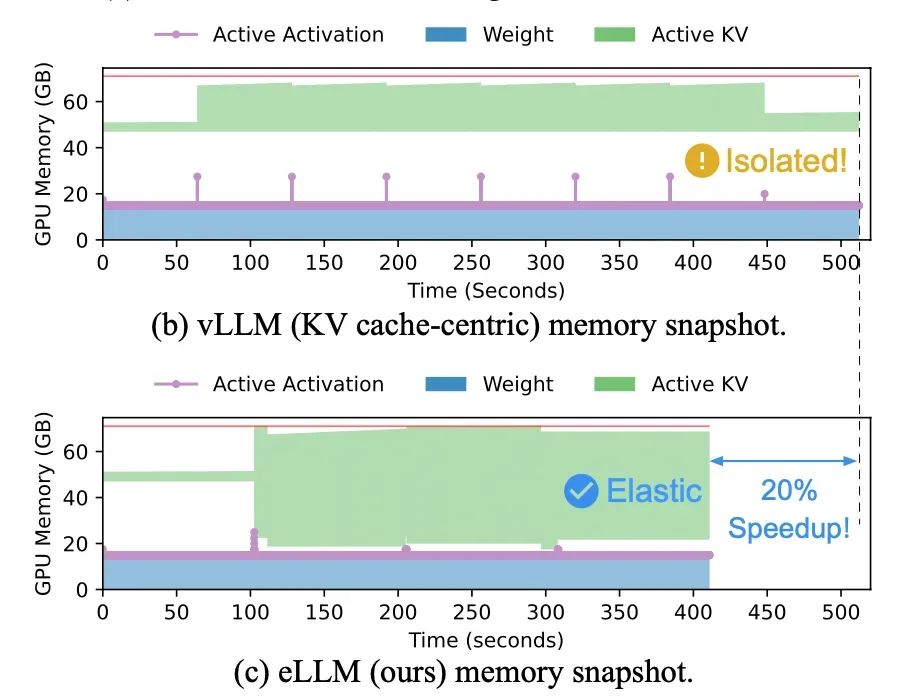
图2:当前框架显存管理的局限和浪费优化机会
进一步,以vLLM为例,简单说明下主流框架的静态显存划分和管理策略:
-
总体逻辑:框架启动后先分配模型权重显存,再按启动参数估算激活内存(为prefill留够激活,prefill进行中不能OOM),剩余空间分配给KV cache。激活值由PyTorch的CUDACachingAllocator管理,KV cache则预分配为torch.Tensor。
-
隔离性弊端:静态划分的3类对象池不利于基于负载、SLO的动态显存,容易引起部分显存闲置。
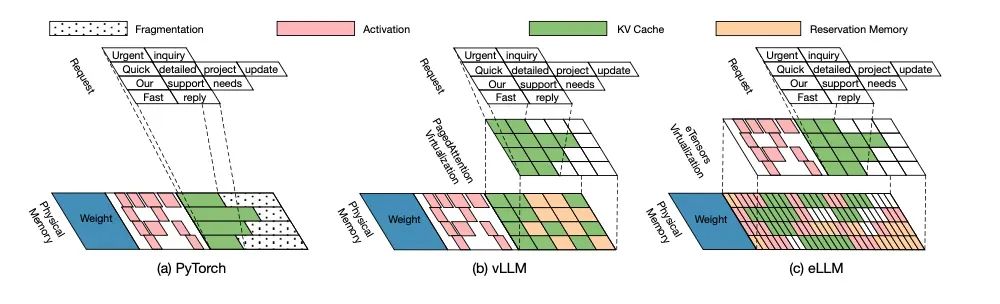
图3:显存管理对比示意
eLLM设计
总体架构
eLLM采用三层架构设计:
1.虚拟张量抽象层:解耦逻辑地址与物理资源,为弹性管理奠定技术基础。
2.弹性内存机制:通过映射重分配实现激活/KV cache的动态空间调整,结合CPU内存作为弹性缓冲。
3.轻量级调度策略:基于服务等级目标(SLO)实现资源分配与性能的动态权衡。
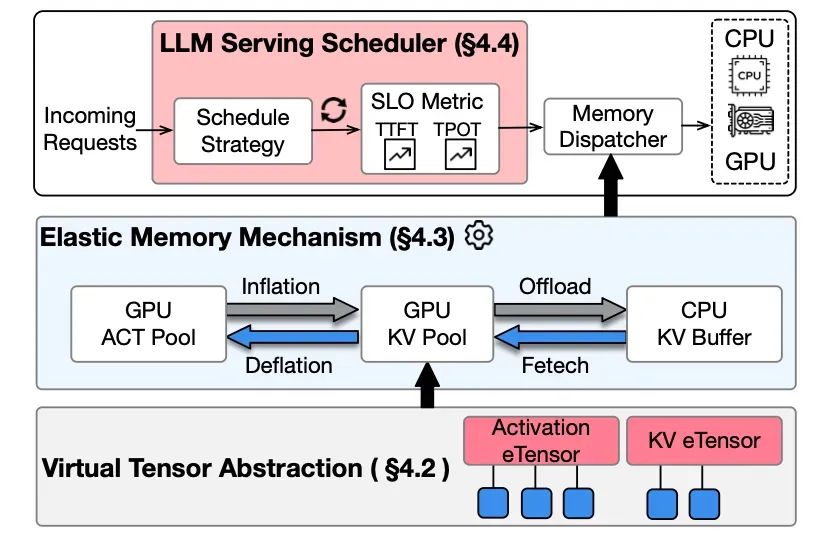
图4:eLLM总体架构
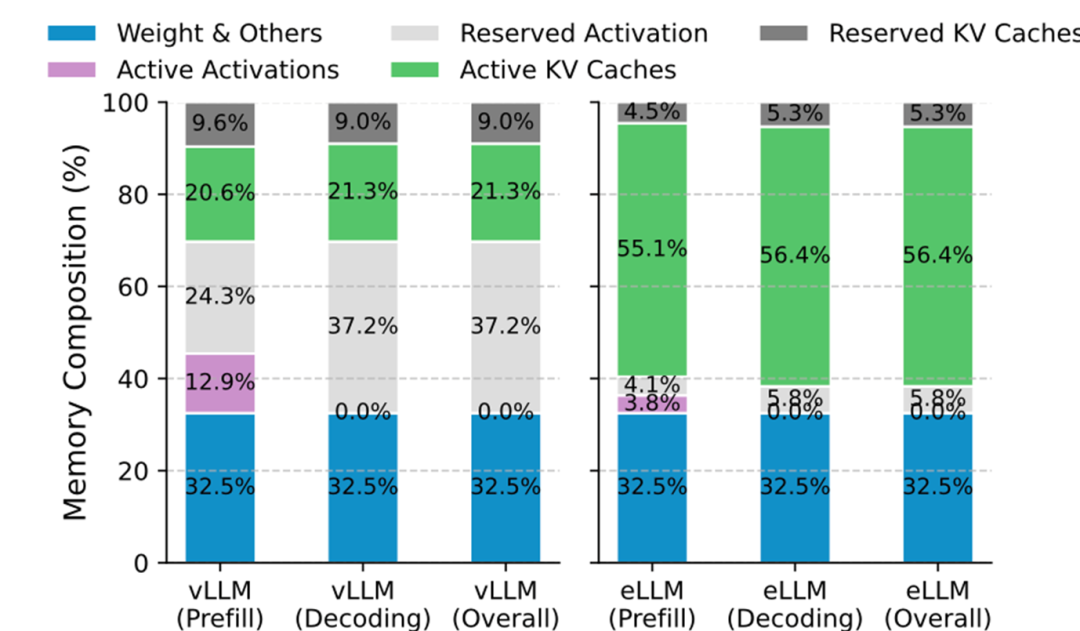
图5:vLLM和优化后eLLM的显存构成对比
eTensor对象
eTensor对象是扩展的PyTorch Tensor对象,保留现有接口,内部封装GPU虚拟内存管理(基于CUDA VMM API)弥合激活值与KV cache的抽象层差距:
-
双张量类型设计
- KV eTensor:预分配与上下文等长的连续的虚拟地址空间,物理内存按需分配。
- 激活eTensor:支持非均匀虚拟地址段,适配小粒度、高频访问特性。
-
地址对齐策略:虚拟地址段(张量槽)与物理内存块粒度严格对齐,平衡访问效率与碎片控制。
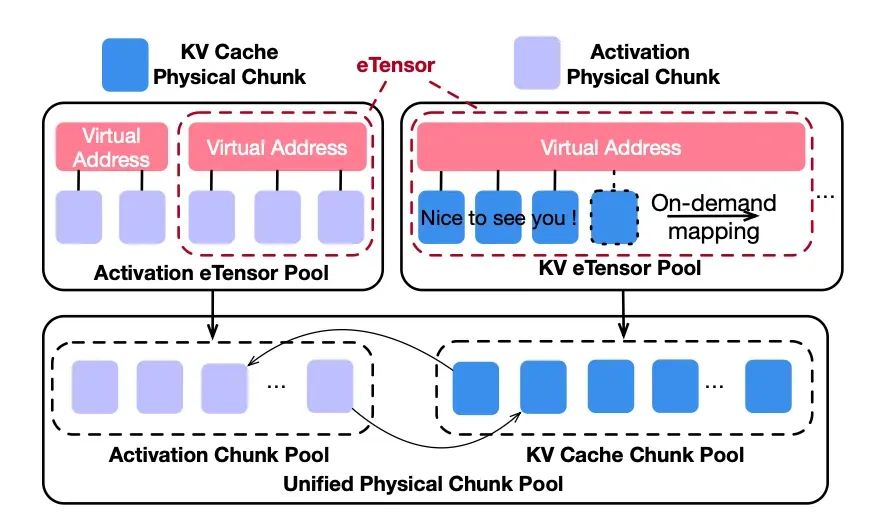
图6:eTensor对象和显存池
弹性显存分配
设计了tensor对象的动态扩、缩操作,打通KV cache和激活显存各自领地:
- 扩张(Inflation,KV cache扩容):
- 检测KV内存不足时向激活池发出借用请求;
- 激活池通过轻量级GC回收非活跃内存块;
- 逻辑转移内存所有权至KV池;
- VMM动态映射至目标KV eTensor地址空间。
- 收缩(deflation):逆向执行膨胀流程,采用惰性避免开销
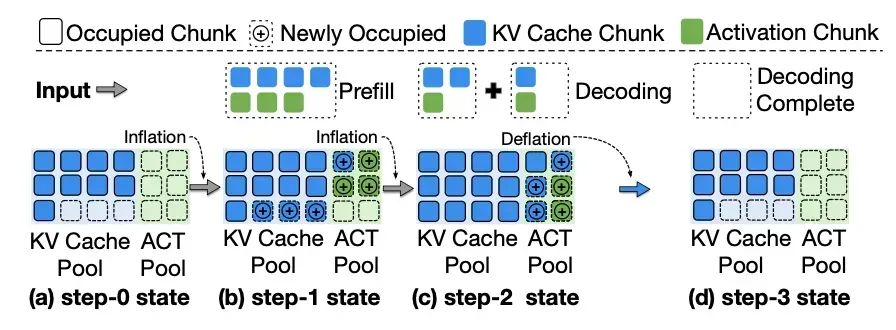
图7:弹性显存扩缩示意
PD感知调度
针对推理Prefill、decode阶段特性优化资源分配:
-
prefill阶段:KV cache卸载至CPU缓冲区,释放GPU空间处理激活数据和放入更多新请求(降低排队耗时);
-
decode阶段:激活内存需求骤降,将KV cache重新加载至GPU,利用膨胀机制扩大批量处理能力;
-
工程优化:采用层级KV cache传输机制,降低CPU-GPU数据迁移开销。

SLO感知弹性缓冲
通过逻辑缓冲区动态平衡TTFT与TPOT指标诉求:
-
动态缓冲区抽象:在固定物理容量内动态调整逻辑可用空间,避免数据逐出;
-
违规响应算法:
- TPOT超标时缩小缓冲区,限制prefill请求;
- TTFT超标时扩大缓冲区,优化首响应延迟;
-
自适应调节:通过5次迭代窗口内的违规次数触发调整,因子α=2控制调整速率。
eLLM结果对比
测试环境
-
基线方案:基于vLLM-0.5.5构建三组对比:
- vLLM:标准实现;
- vLLM-CP:开启chunked-prefill后的vLLM框架;
- eLLM:本项目的实现方法。
-
评测模型:
- 在线服务:Llama3-8B-262K(最大上下文262K);
- 离线推理:Llama3-8B-262K与Jamba-Mini。
-
数据集:
- 在线:32K-2K、2K-2K合成负载,ShareGPT真实对话;
- 离线:8K-2K、16K-2K、32K-4K、128K-4K合成负载。
在线推理性能
Llama3-8B在单A100(80GB)GPU的测试表明:
-
TTFT优化:2K-2K负载下,eLLM相比vLLM和vLLM-CP分别实现295倍和140倍的首字加速。收益主要来自PD感知显存调度、基线由于显存不足,排队时间过长(更详细分析参考另一篇工作LayerKV[3])。
-
弹性机制优势:vLLM-CP仅通过预留激活内存缓解KV压力,eLLM则结合GPU内弹性与GPU-CPU协同,在高并发场景下保持性能稳定;
-
批量处理增益:eLLM支持更大decode批次,输出性能提升显著。
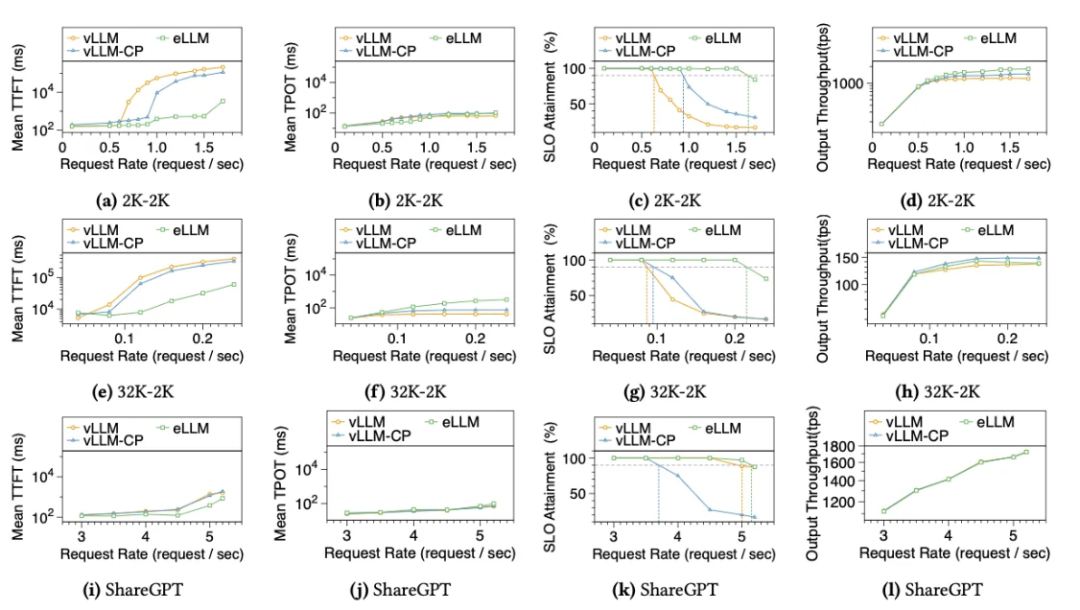
图8:在线推理评测对比
离线推理优化
Jamba-Mini在不同负载下的吞吐表现:eLLM实现最大batch提高至3x,带来总吞吐与decode吞吐分别提升1.8x和2.3x。
-
vLLM对混合线性模型不支持chunk prefill,导致Jamba模型因激活/KV占比更高,eLLM的弹性策略效果更显著。
-
输入序列增长时,eLLM通过内存借调维持大批次处理,避免vLLM的性能陡降。
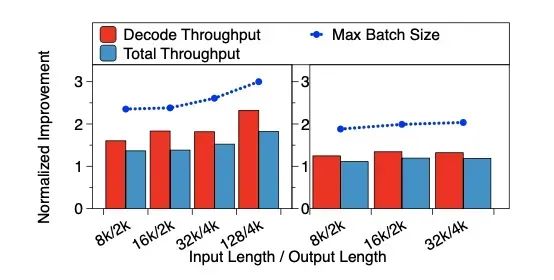
图9:离线推理性能评测
参考
[1] eLLM: https://arxiv.org/abs/2506.15155
[2] GLA: https://arxiv.org/abs/2505.21487
[3] LayerKV: https://arxiv.org/abs/2410.00428

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)