Python数据分析——Pandas综合(五)
本文介绍了DataFrame的基本概念、创建方法和常用属性。主要内容包括:通过字典创建DataFrame并设置行列索引;详细说明DataFrame的各类属性如index、values、shape等;介绍获取部分数据的方法;列举常用统计方法如head()、tail()、sum()、mean()等,并附示例说明。文章还提供了相关Numpy和Series知识的回顾链接,以及源码下载地址。适合数据分析初学
·
DataFrame
在本章中,我们将正式进入DataFrame学习,包括DataFrame的属性以及常见函数的应用等方面内容
1,DataFrame的创建
DataFrame的创建方式:
- 通过
字典创建 - 通过
index可以设置索引值idx - 通过
column可以设置每一列的列名,即创建时字典的key,例如下例中的“奇数列”和“偶数列”以及“姓名”、“年龄”、“学号”,其中的顺序会影响每一列在DataFrame中的位置
示例如下: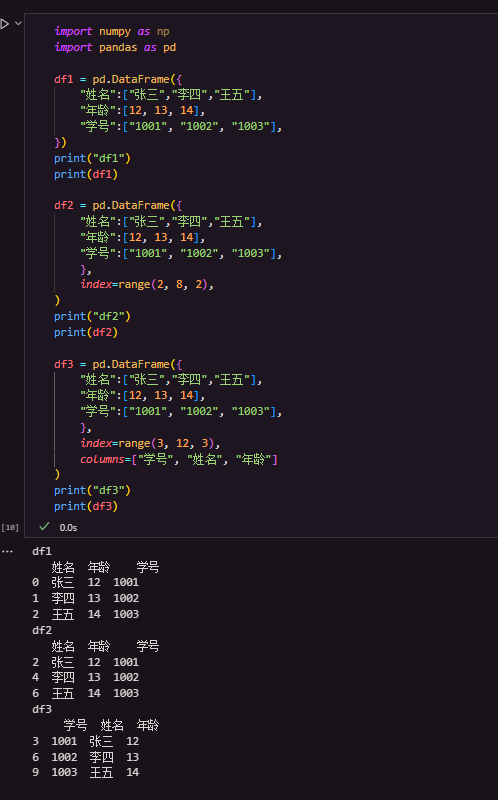
1.2 DataFrame的属性
| 属性 | 说明 | 属性 | 说明 |
|---|---|---|---|
| index | DataFrame的行索引 | loc[] | 显式索引,按行列标签索引或切片 |
| values | DataFrame的值 | iloc[] | 隐式索引,按行列位置索引或切片 |
| dtypes | DataFrame的元素类型 | at[] | 使用行列标签访问单个元素 |
| shape | DataFrame的形状 | iat[] | 使用行列位置访问单个元素 |
| ndim | DataFrame的维度 | T | 行列转置 |
| size | DataFrame的元素个数 | ||
| columns | DataFrame的列标签 |
其中大部分属性和numpy章节学习时的内容一致,如果不太熟悉的同学记得常回去看看,传送门:
Python数据分析——numpy综合(二)
表格中的内容部分示例如下: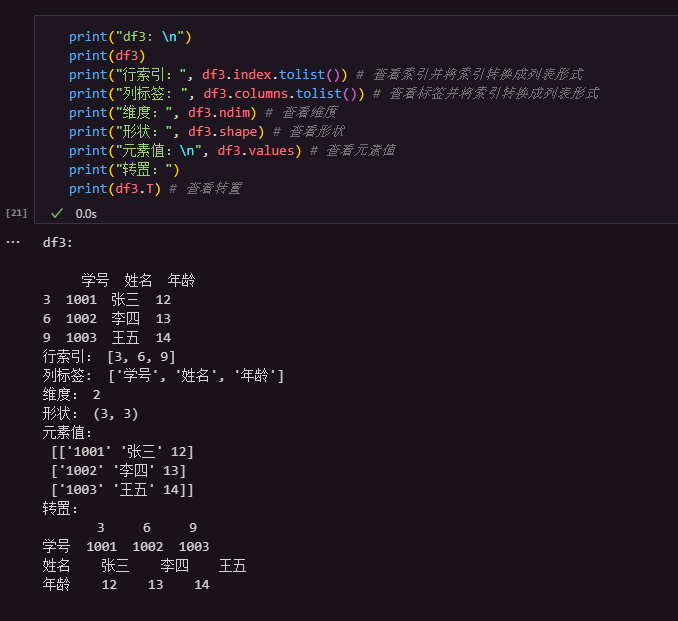
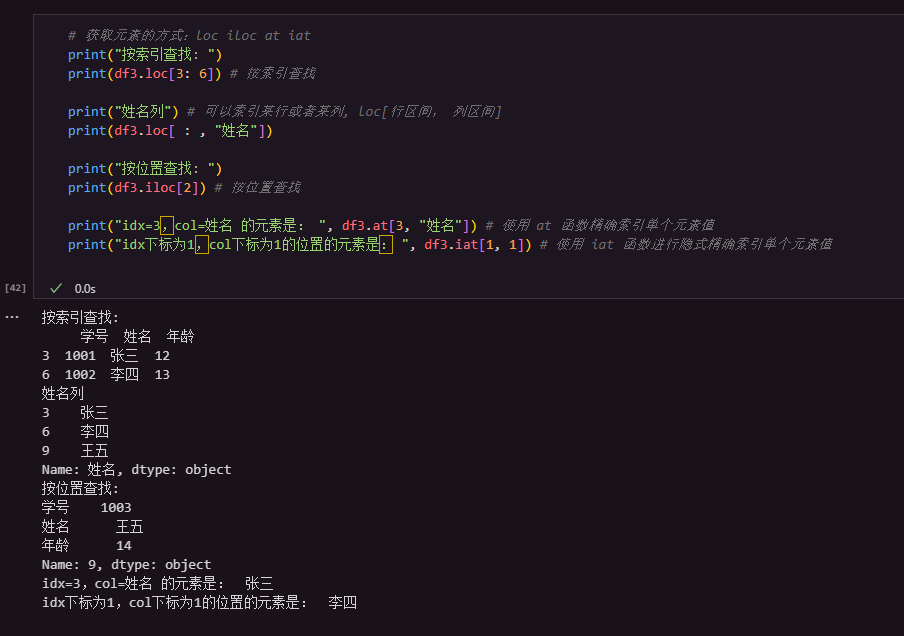
1.3 获取DataFrame中部分数据的方法
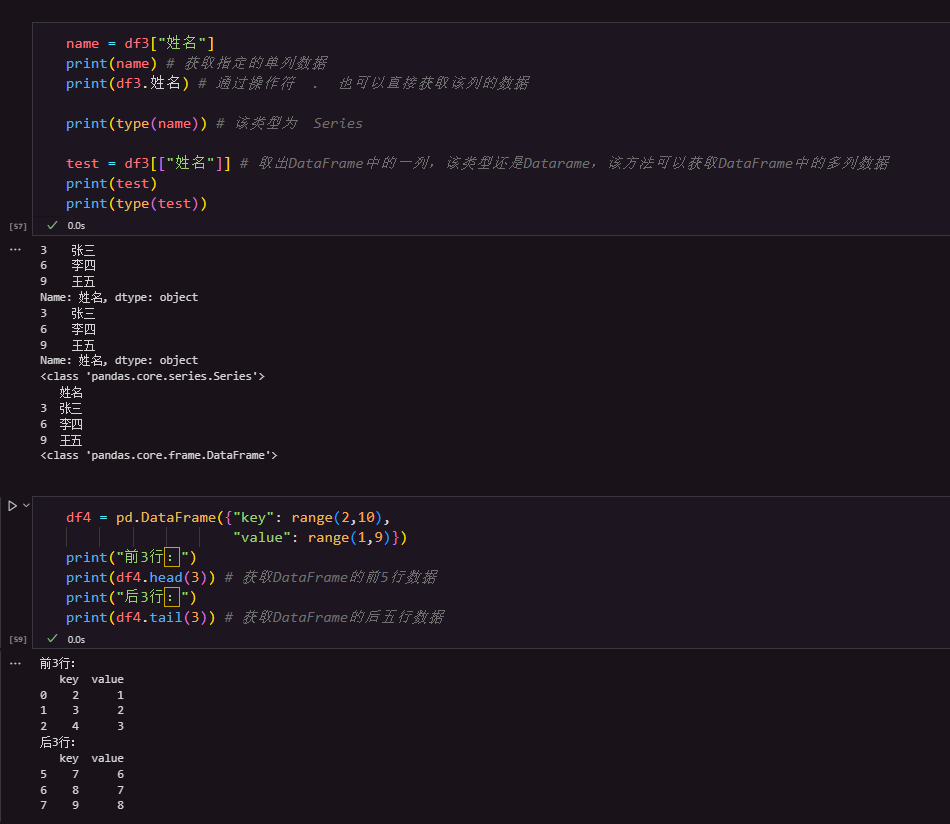
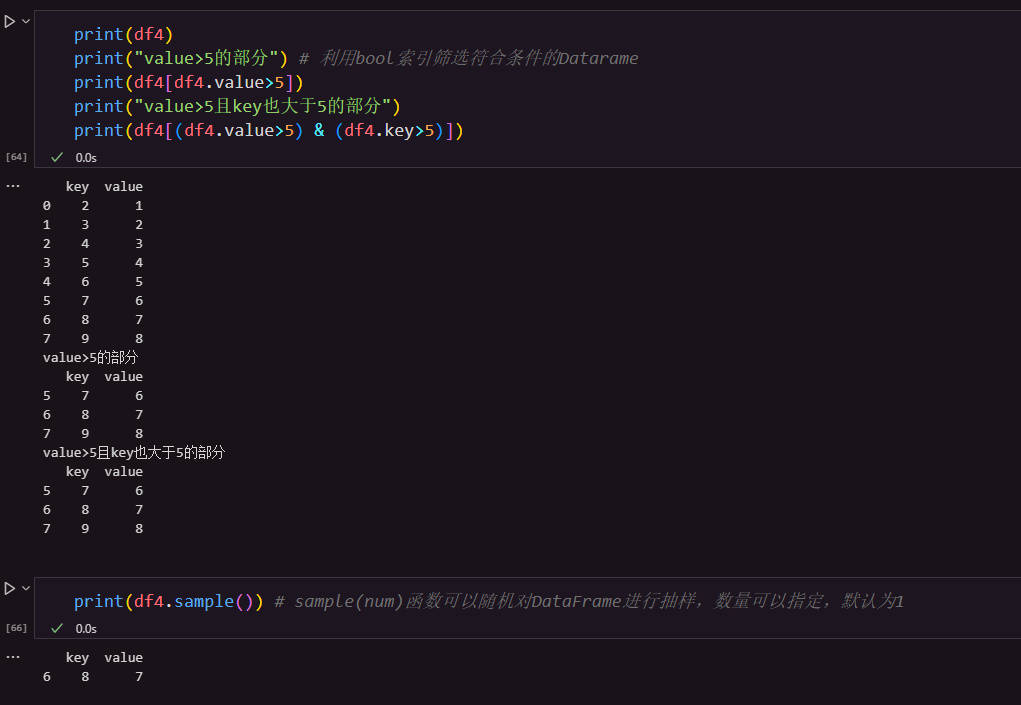
1.4 DataFrame的常用方法
| 方法 | 说明 | 方法 | 说明 |
|---|---|---|---|
| head() | 查看前 n 行数据,默认 5 行 | max() | 最大值 |
| tail() | 查看后 n 行数据,默认 5 行 | var() | 方差 |
| isin() | 判断元素是否包含在参数集合中 | std() | 标准差 |
| isna() | 判断是否为缺失值(如 NaN 或 None) | median() | 中位数 |
| sum() | 求和,自动忽略缺失值 | mode() | 众数(可返回多个) |
| mean() | 平均值 | quantile(q) | 分位数,q 取 0~1 之间 |
| min() | 最小值 | describe() | 常见统计信息(count、mean、std、min、25%、50%、75%、max) |
| value_counts() | 每个唯一值的出现次数 | sort_values() | 按值排序 |
| count() | 非缺失值数量 | replace() | 替换值 |
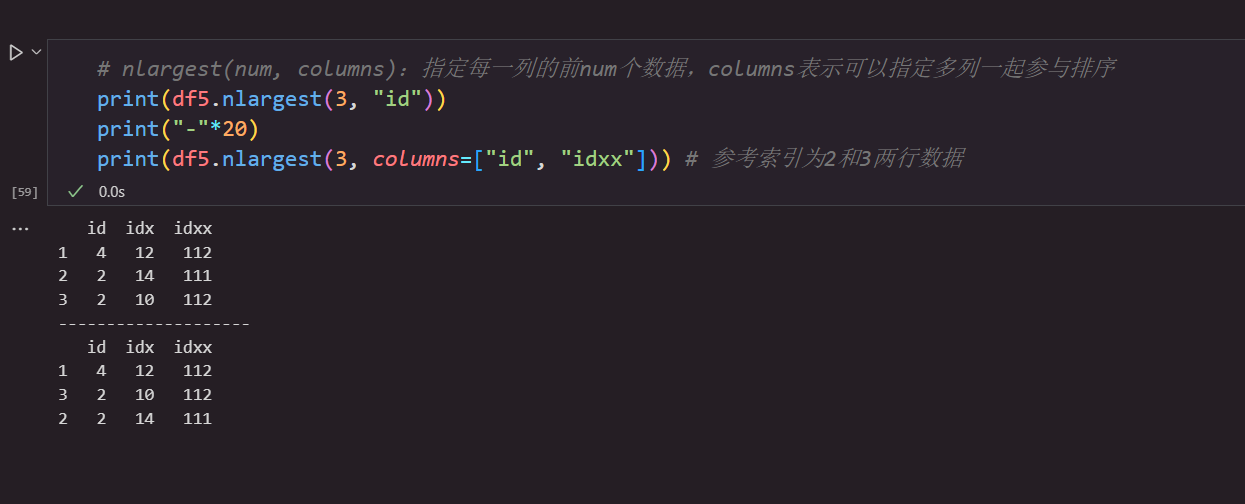
| duplicated() | 是否重复 | nlargest() | 返回某列最大的n条数据 |
| drop_duplicates() | 去除重复项 | nsmallest() | 返回某列最小的n条数据 |
| sample() | 随机抽样 | ||
| replace() | 替换值 | ||
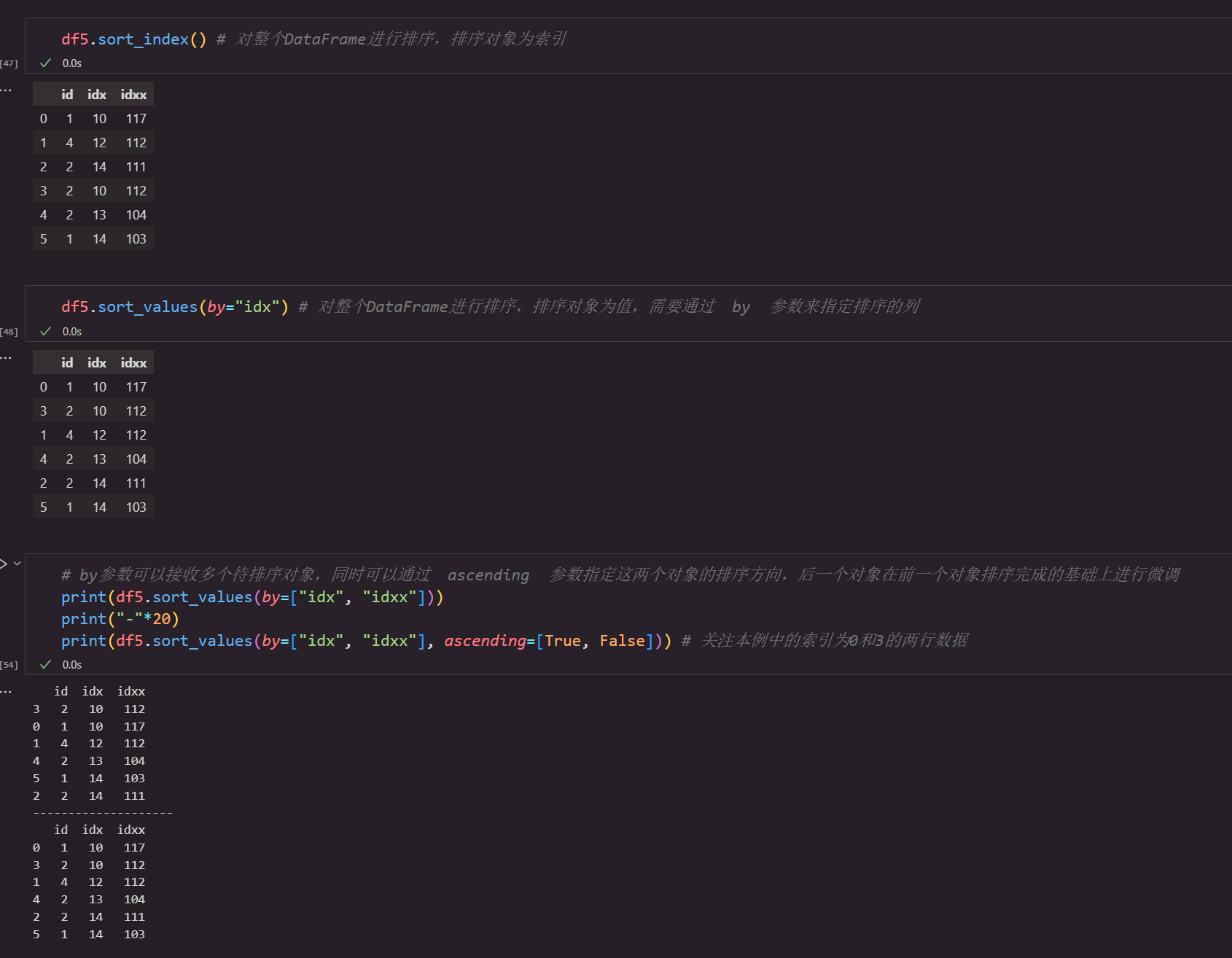
| sort_index() | 按索引排序 |
在DataFrame这篇开篇之时我们叙述过DataFrame和Series这两大对象的关系,上述常用方法中大部分在Series篇章中已经举例过了,这里也不再过多叙述,点击传送门快速回顾:Python数据分析——Pandas综合(二)
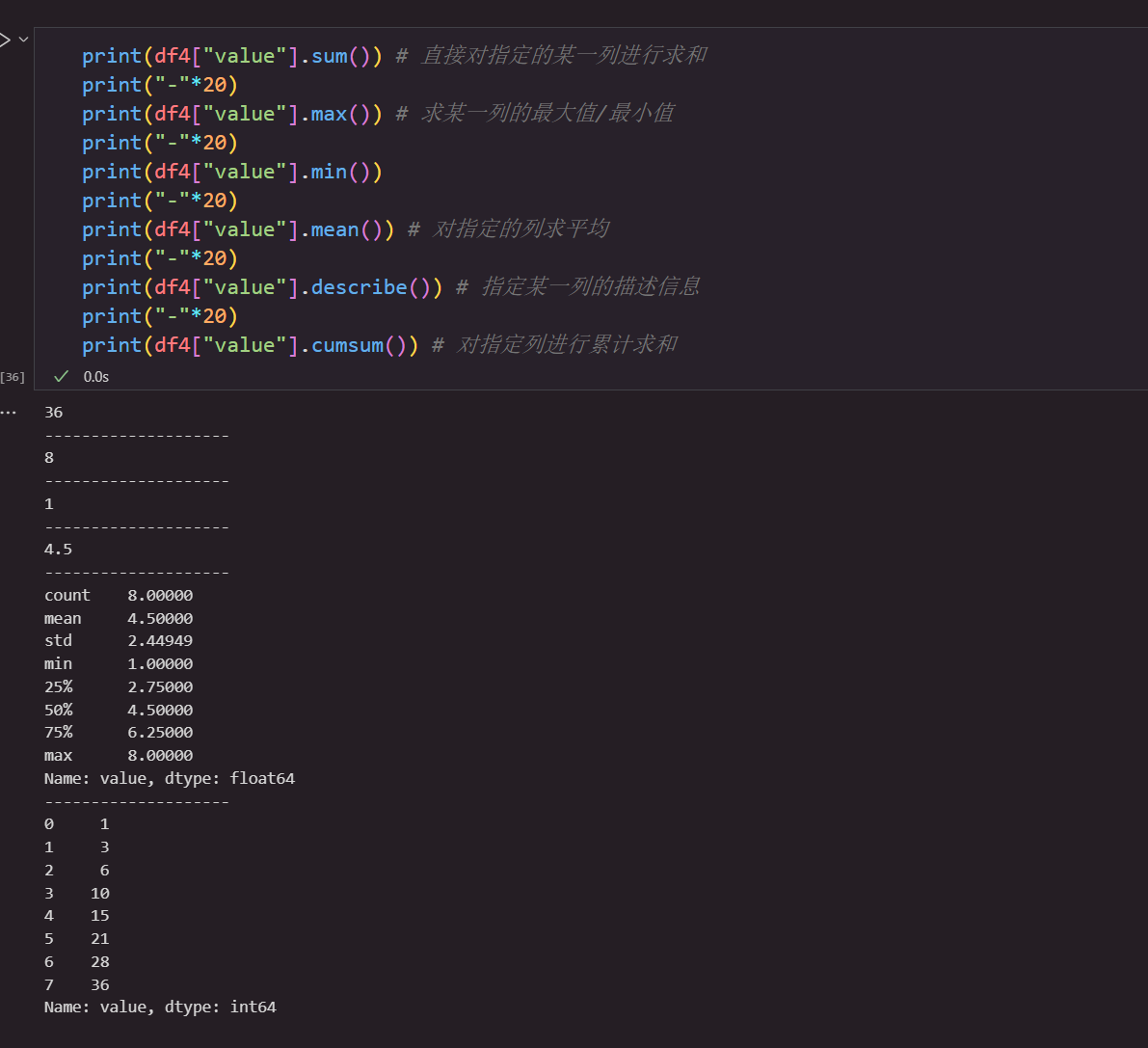
部分使用案例如下: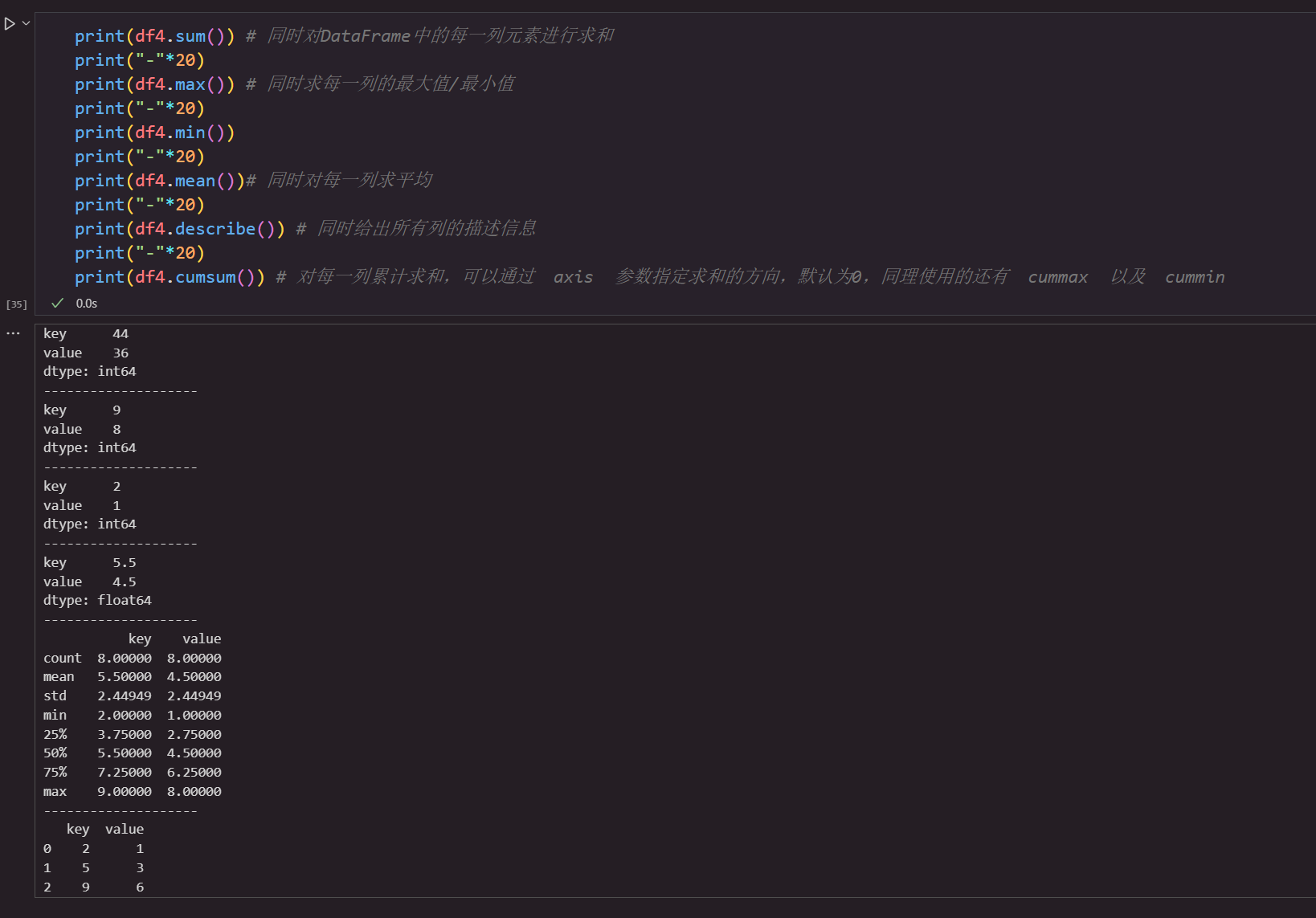
以上就是本期的所有内容了,如果您在阅读本文的过程中有所收获,或者有任何宝贵的建议和想法,欢迎通过邮箱、微信或者留言等方式给我留言交流,或者是访问我的个人博客 南徽玉的个人博客,您的每一次建议都将是我前进的动力!
关于源码下载:请关注Github-NanHuiyu的CSDN源文件仓库


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)