一张照片 + 一段音频 = 你的AI数字人:StableAvatar真人说话视频生成教程
StableAvatar 是由复旦大学联合微软亚洲研究院、西安交通大学及腾讯混元团队共同研发的一项突破性AI视频生成技术。该技术于2025年8月首次实现了的高质量生成,显著解决了以往技术在生成长视频时频繁出现的面部扭曲、身体变形、音画不同步等关键问题,推动了AI数字人技术在实际应用中的可用性与自然度。
一、项目介绍
StableAvatar 是由复旦大学联合微软亚洲研究院、西安交通大学及腾讯混元团队共同研发的一项突破性AI视频生成技术。该技术于2025年8月首次实现了无限长度真人说话视频的高质量生成,显著解决了以往技术在生成长视频时频繁出现的面部扭曲、身体变形、音画不同步等关键问题,推动了AI数字人技术在实际应用中的可用性与自然度。
核心技术机制
StableAvatar 的核心创新在于其时间步感知音频适配器(Timestep-Aware Audio Adapter)。该模块能够将输入的音频信息(如语音内容、音调、节奏等)高效编码为视频生成模型可理解的时序特征信号,确保每一帧视觉内容与对应时间点的音频信息实现精准对齐。通过引入时间上下文建模,系统不仅能保持口型的同步性,还能实现对头部微动作、表情自然过渡等细节的连续控制,从而支持生成长时间且视觉一致性极高的动态视频。
应用前景展望
StableAvatar 的出现极大地降低了多行业在视频内容制作方面的门槛与成本。其可广泛应用于:
-
影视制作与广告行业:快速生成虚拟角色讲解视频,大幅减少后期配音与演员拍摄成本;
-
虚拟助手与交互代理:打造高度拟人化的数字员工,提升用户体验;
-
在线教育与企业培训:教师或讲师仅需提供录音即可生成授课视频,支持多语言、多风格输出;
-
社交媒体与内容创作:用户可通过一张自拍和一段语音生成个性化视频内容,极大丰富创作形式。
星海智算平台已经为大家部署好这个镜像,开箱即用,下面为大家介绍一下,如何在星海智算平台上使用。
星海智算-GPU算力云平台![]() https://spacehpc.com/user/register?inviteCode=57833422
https://spacehpc.com/user/register?inviteCode=57833422
二、使用教程
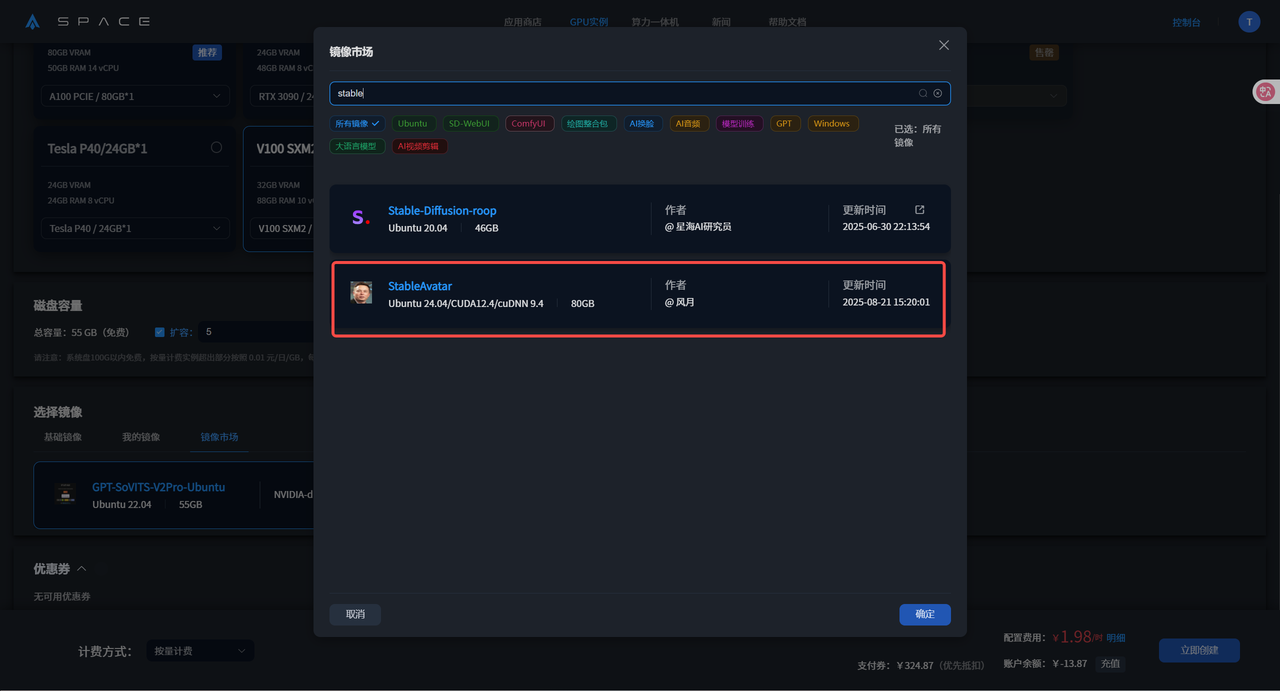
2.1、选择镜像
在镜像市场选择StableAvatar镜像并创建实例
2.2、应用服务
实例运行后,等待两到三分钟点击应用服务按钮即可

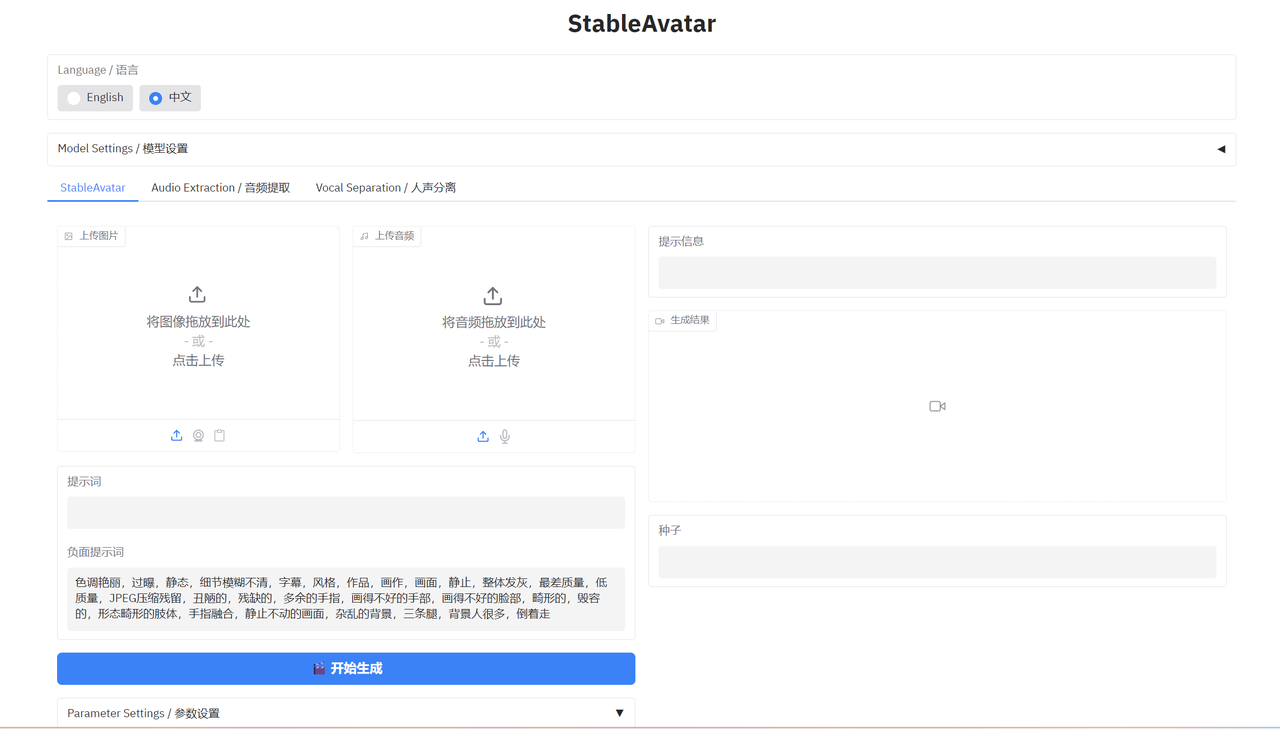
2.3、选择模式
有StableAvatar、音频提取、人声分离三种模式可供选取,由于音频提取和人声分离较为简单,这里演示StableAvatar模式,选择相应语言,并选择相应模型,上传完图片和音频之后,调整提示词和参数,点击开始生成即可。
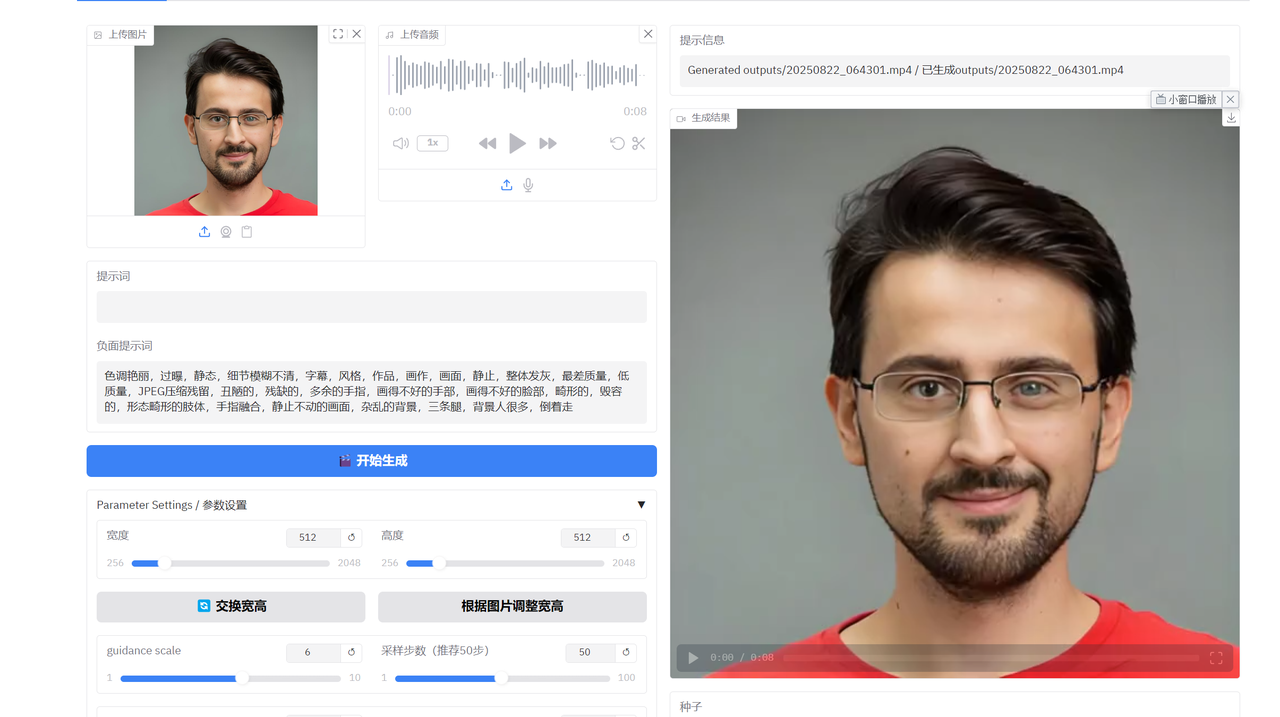
2.4、结果
实现一张图、一段音频,生成数字人。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)