AI绘画中Lora的奥秘与实战应用

相信熟悉AIGC绘画的朋友都听过Lora这个词,那么,Lora是什么呢?本篇将带大家介绍下Lora的奥秘。
一、Lora是什么
Lora,即 Low - Rank Adaptation of Large Language Models 的缩写,意为大语言模型的低秩适应。最初它是为了解决大语言模型微调时的高成本和高资源消耗问题而提出的。在 AIGC 绘画领域,Lora 模型借鉴了类似的思想,通过引入少量额外的可训练参数,对预训练的绘画模型(如 Stable Diffusion)进行高效的个性化调整。
从技术原理上讲,Lora 模型在预训练模型的权重矩阵上添加了两个低秩矩阵(通常用A和B表示),通过训练这两个低秩矩阵来间接调整模型的输出。相比于直接对整个模型的大量参数进行微调,Lora 大大减少了需要训练的参数量。
例如,对于一个维度为d×k的权重矩阵,传统微调需要更新 d×k 个参数,而使用秩为r的Lora只需要更新r×(d+k)个参数,当r远小min (d,k) 时,参数量的减少是非常显著的。研究表明,在大多数绘画应用场景中,设置r为4-16时就能达到接近全参数微调的效果。

-
r=4~8:轻量级风格定制(如 “水彩风”“扁平插画风”),适合显存<8GB 的消费级显卡(如 RTX 3060);
-
r=12~16:高精度角色 / 细节定制(如 “特定动漫角色”“产品设计细节”),适合显存≥12GB 的显卡(如 RTX 3090);
-
红色警示线:当 r≥32时,参数量占比超过 8%,性价比下降,且易出现 “过拟合”(生成图像与训练数据高度重复)。
如果想寻找Lora的模型资源可以去一些模型网站,如:
Civitai(简称C站,拥有丰富的模型资源,需要魔法上网)
哩布哩布(LiblibAI,作画界面与SD界面几乎一模一样,非常适合新手学习使用)
Lora 模型文件通常非常小(一般只有几MB到几十MB),相比于动辄数GB的完整绘画模型,它在分享和传播上更加方便。创作者可以轻松地将自己训练好的Lora模型分享到网络上,供其他创作者下载和使用,极大地促进了AIGC绘画社区的资源共享和创作交流。
二、Lora 的应用场景
在 Stable Diffusion 中使用 Lora
启动 Stable Diffusion:确保Stable Diffusion已经正确安装并配置好运行环境。打开Stable Diffusion的Web UI界面
加载 Lora 模型:进 Web UI界面后,点击页面中的 “Lora” 选项卡。这里会显示出放置在 “Lora” 文件夹中的所有 Lora 模型。如果模型没有自动加载显示,点击页面中的刷新按钮即可。
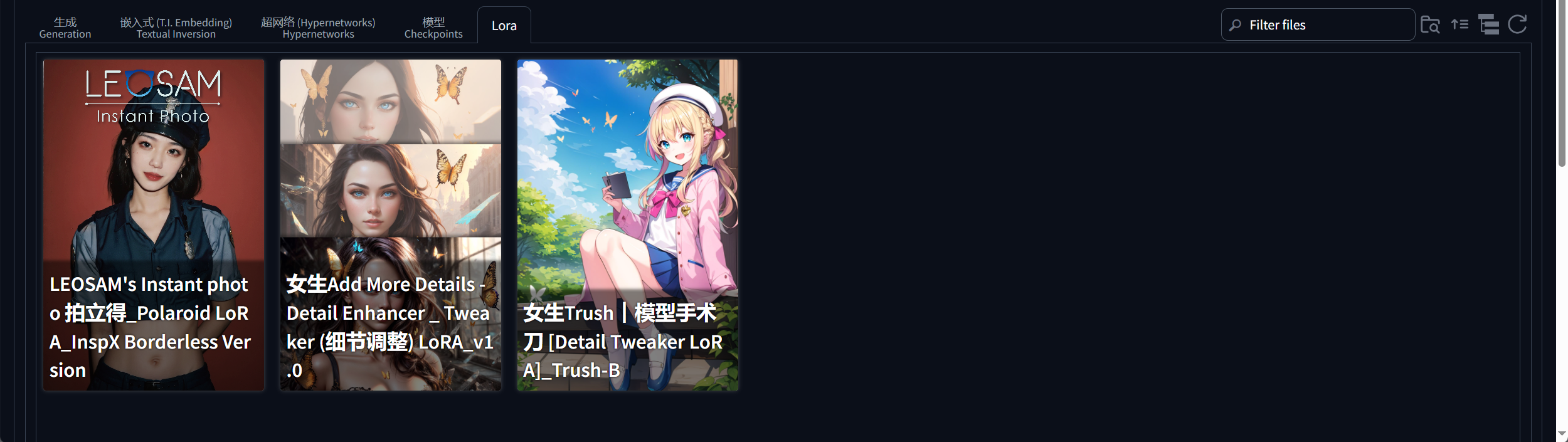
选择并设置 Lora:直接点击要使用的 Lora 模型,此时关键词的文本框中会自动添加一串英文,前半部分是该Lora模型的名字,后面的数字1代表权重。Lora的权重一般设置在0-1之间,当权重过大(大于1)时,生成的图像可能会出现异常。例如,如果想要让Lora模型对生成图像的影响更明显,可以适当提高权重值,但一般建议先从 0.5 左右开始尝试,根据生成效果再进行调整。

叠加使用 Lora:Lora 模型是可以叠加使用的。例如,想要生成一个既有特定人物风格,又具有某种艺术风格的图像,可以同时选择这两个风格对应的 Lora 模型。在选择多个 Lora 模型时,注意要用英文状态下的逗号将它们分隔开。每个 Lora 模型设置的权重不同,生成的图像效果也会有所差异。创作者可以通过多次尝试不同的权重组合,找到最符合自己需求的效果。
注意触发词:在网站上下载Lora模型时,要留意该Lora是否有触发词。触发词是指在使用某个Lora 模型时,必须在关键词中输入的特定词语,只有这样Lora模型才会生效。例如,一个JK制服风格的 Lora 模型,它的触发词可能是 “JK uniform”,如果在生成图像时使用了该Lora模型,但关键词中没有输入 “JK uniform”,那么生成的图像可能不会呈现出JK制服的风格。为了方便后续使用,可以将触发词和推荐权重直接保存在Stable Diffusion中。将鼠标放在Lora模型上,点击右上角的小图标,在弹出的窗口中记录下触发词和推荐权重信息,然后点击 “保存”。这样,下次使用该Lora模型时,直接点击它,关键词文本框里就会自动加载触发词并调整好权重。

三、训练自己的Lora模型
-
准备训练数据:首先要明确自己想要训练的Lora模型的风格或主题,然后收集相关的高质量图像作为训练数据。例如,如果要训练一个动漫角色风格的Lora模型,就需要收集该动漫角色在不同场景、姿势下的高清图片,图片数量建议在几十张到几百张之间,具体数量可根据实际情况调整。同时,确保图片的质量和多样性,避免图像中存在模糊、噪点过多或内容单一等问题。
-
选择训练工具:目前有多种工具可以用于训练Lora模型,其中较为常用的是 “Dreambooth” 和 “Textual Inversion” 等。这些工具通常需要一定的编程基础和对Stable Diffusion架构的了解才能进行配置和使用。对于初学者来说,可以参考相关的教程和文档,逐步掌握工具的使用方法。例如,在GitHub上有许多开源的Lora训练项目,其中包含详细的安装和使用说明,用户可以根据这些说明搭建自己的训练环境。
-
配置训练参数:在使用训练工具时,需要设置一系列的训练参数,如学习率、训练步数、批次大小等。学习率一般设置在1e-4到1e-3之间,训练步数根据数据量和模型复杂程度而定,通常在几百步到几千步之间。批次大小则要根据显卡的显存大小来调整,显存较大时可以适当增大批次大小,以提高训练效率。此外,还需要指定训练数据的路径、选择要微调的基础模型等参数。
-
开始训练:完成训练参数的配置后,即可启动训练过程。训练过程可能需要较长时间,具体时长取决于训练数据的规模、硬件性能以及设置的训练参数。在训练过程中,可以实时监控训练进度和损失值,根据损失值的变化情况判断训练是否正常进行。如果损失值持续下降且生成的样本图像逐渐符合预期,说明训练进展顺利;如果损失值出现异常波动或不下降,可能需要调整训练参数或检查训练数据是否存在问题。
-
评估与优化:训练完成后,需要对生成Lora模型进行评估。使用一些未参与训练的测试数据,结合训练好的Lora模型在Stable Diffusion中生成图像,观察生成图像的质量、风格一致性以及是否符合预期等方面。如果发现生成的图像存在一些问题,如风格不够突出、与训练数据有偏差等,可以根据问题的具体情况,调整训练参数或增加更多的训练数据,重新进行训练,以优化Lora模型的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)