多模态大模型——Qwen2.5-Omni端到端实时多模态智能的技术架构与实现机制
Qwen2.5-Omni是阿里巴巴开发的多模态AI模型,支持文本、图像、音频和视频的实时处理与生成。其核心是Thinker-Talker框架:Thinker负责推理和文本生成,Talker专攻语音合成。创新点包括TMRoPE机制实现跨模态时间同步,以及流式优化设计降低延迟。模型训练分三阶段:编码器对齐、跨模态整合和长序列支持。该模型采用ChatML对话格式,适用于智能助手等实时交互场景,在架构设计
Qwen2.5-Omni:实时多模态人工智能
Qwen2.5-Omni是阿里巴巴Qwen团队开发的突破性端到端多模态基础模型。该模型采用统一且流式的方式,能够跨文本、图像、音频和视频等多种模态进行感知与生成。凭借在架构、训练流程和实时处理能力方面的一系列创新,Qwen2.5-Omni成为迄今为止功能最全面的模型之一。
本文基于官方技术报告,对该模型进行详细解析,按章节结构阐述这一新一代AI助手的工作原理、创新点及实际应用能力。
Qwen2.5-Omni模型概述
Qwen2.5-Omni是一款统一多模态模型,旨在对纯文本、音频信号、静态图像和视频等多种输入格式进行实时感知与生成。其设计秉持流式优先理念,非常适用于AI助手、语音交互界面和智能代理等实际应用场景。
与通过拼接独立模型实现的模块化方案不同,Qwen2.5-Omni采用端到端训练方式。这意味着该模型原生具备协调不同输入模态的能力,并能同步、连贯地生成文本和语音输出。
Qwen2.5-Omni架构总览
Qwen2.5-Omni的核心是Thinker-Talker框架,整体架构包含四个主要组件:
在这里插入图片描述
图2. Qwen2.5-Omni架构中的Thinker-Talker流水线
- 多模态编码器:负责感知音频和视觉信息
- Thinker:大型语言模型(LLM),处理推理、理解和文本生成任务
- Talker:流式语音生成模块,将语义表征和文本token转换为逼真音频
- 流式机制:旨在减少实时场景中的延迟和内存占用
该设计模拟人类行为模式:大脑(Thinker)决定表达内容,发声系统(Talker)负责输出。功能分离使两部分能够各自专精。
Qwen2.5-Omni能够处理和解析以下模态:
- 文本:采用字节级BPE词汇表(151K tokens)进行分词
- 音频:重采样至16kHz后,通过25ms窗口和10ms步长转换为128通道梅尔频谱图,再输入基于Whisper-large-v3衍生的编码器。每个输出帧对应约40ms音频
- 图像和视频:由基于视觉Transformer(ViT)的编码器(约6.75亿参数)处理,该编码器同时在图像和视频数据上训练。视频采用动态帧率采样以与音频时序对齐,静态图像则被视为两个相同帧以保证处理一致性
- 混合模态:如视频+音频或文本+图像等组合输入的联合处理
Qwen2.5-Omni中的TMRoPE视频时序对齐机制
为实现时间敏感型音频与视频输入的同步,Qwen2.5-Omni引入了TMRoPE(时间对齐多模态旋转位置嵌入),其基于先前的M-RoPE(多模态RoPE) 理念构建。
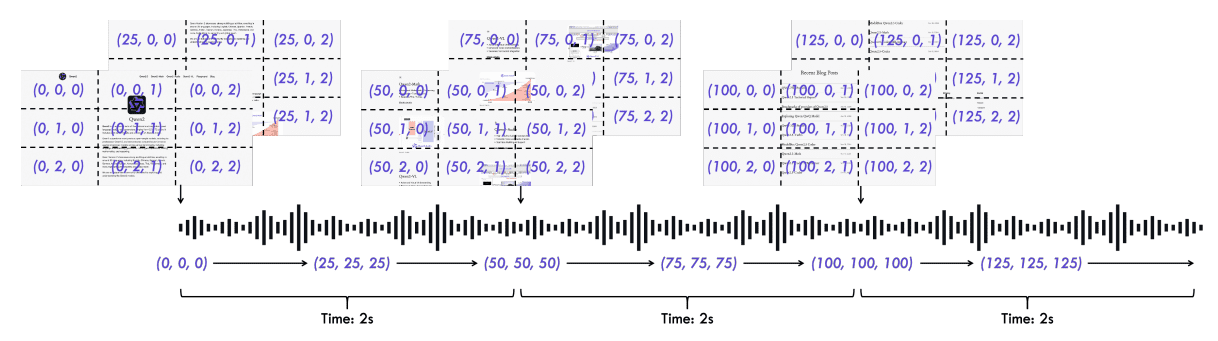
图3. Qwen2.5-Omni中TMRoPE的示意图
- 位置嵌入分解为三个部分:时间维度、高度维度和宽度维度
- 文本无空间或时间结构(仅为序列),因此仅使用时间ID,与传统Transformer一致
- 图像输入为静态,所有token共享相同时间ID,但每个token分配唯一的高度和宽度ID以保留空间结构
- 音频中,每个音频帧=40ms声音片段,因此每帧分配一个时间ID(每40ms递增1)。音频无高度/宽度位置信息——仅时间维度起作用
- 带音频的视频输入中,视频作为图像帧序列,每帧分配唯一时间ID,帧内token含高度/宽度ID;每40ms音频帧分配一个音频位置ID(与单独音频处理一致)。关键在于,音频和视频帧的时间ID通过40ms基准单位实现时序对齐
- 所有模态的输入token经TMRoPE嵌入和标记后,通过时间交织算法每2秒进行一次序列合并,以确保实时感知与处理
Qwen2.5-Omni中的时间交织机制
当所有token(来自视频、音频等)完成嵌入并标记TMRoPE后,会按特定顺序排列,即基于时间混合不同模态token。每2秒片段中,模型先放置视觉token,后跟随音频token,这一过程称为时间交织。
可变帧率处理
实际视频可能存在非均匀帧率(如24fps、30fps或可变帧率)。TMRoPE利用实时时间设置时间ID,确保每40ms=一个时间位置单位,与实际帧率无关。这保证了视频与音频的精确时间对齐。
跨模态位置编号
为确保不同模态的位置ID不重叠,每种模态的位置编号初始值设为前一模态最大位置ID加1。这有助于注意力机制在联合推理时区分不同模态输入。
Qwen2.5-Omni的输出生成
Qwen2.5-Omni中Thinker的文本生成
当模型需要产生文本输出(如回答问题、描述场景或语音转录)时,该任务由Thinker模块负责。Qwen2.5-Omni的Thinker模块采用成熟的LLM技术,生成的文本具有以下特点:
- 上下文感知性(得益于自回归机制):文本以逐token方式生成,每个新token依赖于所有先前生成的token
- 多样性(通过top-p采样实现)
- 自然流畅性(具备重复控制机制)
- 遵循ChatML对话格式,确保交互应用中的一致性
在生成过程的每个步骤中,模型为词汇表中的每个token(Qwen包含超过15万个token)分配概率值,然后从该分布中采样,基于可能性选择下一个token。这一方法为几乎所有现代LLM所采用。
Qwen2.5-Omni中Talker的高质量语音生成
Talker作为语音生成模块,将语义意图转换为富有表现力的流畅语音。当Thinker生成内部思考并选择词汇(token)后,会向Talker传递两类信息:
- Thinker生成的高级语义表征,包含丰富的语义含义、情感和意图
- Thinker生成的离散token,用于确保语音的语音清晰度,明确精确发音和结构
在流式模式下,Talker在完整句子生成前即可开始语音输出。然而,为保证自然度,仍需预测语气。Thinker提供的高级嵌入向量携带情感和风格信息,使Talker能够实时调整音调、节奏和语气。
Talker采用qwen-tts-tokenizer——一种自定义编解码器,其生成的音频token通过因果解码器转换为音频波形。传统TTS系统通常需要精确的时序控制:如"该词始于0.6秒,止于1.2秒"等。而Qwen2.5-Omni无需此类控制,Talker通过仅使用文本和音频数据进行端到端训练,无需强制对齐。
Qwen2.5-Omni的流式输出设计
流式交互中的初始延迟存在若干主要来源。Qwen2.5-Omni论文探讨了多种优化策略,包括:
- 算法层面——如流式编码器、滑动窗口注意力、Thinker-Talker并行机制
- 架构层面——如轻量级视觉/音频编码器和快速解码器
这些优化的目标是最小化启动延迟,使实际系统能够快速接收视听信息、完成理解并立即响应。
以下详细介绍这些优化措施:
Qwen2.5-Omni的预填充支持
预填充指在模型开始生成输出之前,用部分输入数据对模型进行初始化,这对流动模型尤为有用。
- 音频编码器以2秒块为单位处理数据,采用时间块级注意力而非一次性处理全部数据。这使系统能够提前启动推理,无需等待完整输入到达。
视觉编码器的两项优化:
- Flash Attention:一种优化算法,可加速自注意力计算并减少内存占用
- 2×2token合并——轻量级MLP将每个2×2网格的视觉token合并为一个,减少token总数,实现视觉输入的有效下采样
视觉编码器将图像分割为补丁(与ViT工作方式类似),14×14的补丁大小使可变尺寸图像能够高效分词。
Qwen2.5-Omni的流式编解码器生成
流式语音生成采用:
-
Flow-Matching DiT模型:将音频token生成梅尔频谱图。流匹配(Flow-Matching)是一种学习分布间映射的生成方法,可将离散语音token(代码)转换为梅尔频谱图(音频的时频表示)。

图4. Flow-Matching DiT中使用的块级注意力机制 -
改进的BigVGAN声码器:将频谱图转换为波形。梅尔频谱图生成后,输入声码器以产生原始音频。基于GAN的BigVGAN神经声码器以生成逼真高质量波形著称。
解码过程采用基于块的滑动窗口注意力,通过4块感受野(2块回溯,1块前瞻)确保低延迟场景下的上下文连贯性。
Qwen2.5-Omni的预训练
该模型的预训练分为三个精心设计的阶段,每个阶段具有特定目标:
阶段1:编码器对齐
语言模型(LLM)保持冻结状态(不参与训练),仅训练视觉和音频编码器。此阶段目标是使编码器输出与LLM的语义空间对齐,帮助LLM后续处理多模态输入时不受未对齐嵌入的干扰。
阶段2:跨模态整合
此时整个模型均可训练:包括LLM、音频编码器和视觉编码器。训练数据更加多样化,涵盖图像-文本、视频-文本、音频-文本、视频-音频等组合。该阶段促进跨模态深度整合与任务协同。
在本阶段,Qwen2.5-Omni多模态模型的训练数据规模为:
- 8000亿图像/视频tokens
- 3000亿音频tokens
- 1000亿视频-音频tokens
本阶段中,层级标签已替换为自然语言提示以提升泛化能力。
阶段3:长序列支持
- 最大序列长度从8192增加至32,768 tokens
- 纳入长音频和视频数据
- 支持长对话、长音频和长视频片段的理解
基于现有骨干模型的初始化
为加速和稳定训练,Qwen2.5-Omni采用以下模型初始化策略:
- LLM → 基于Qwen2.5
- 视觉编码器 → 基于Qwen2.5-VL
- 音频编码器 → 基于Whisper-large-v3(一款优秀的开源语音模型)
这一策略提供了坚实基础,避免从零开始训练。
两个编码器在固定LLM上分别训练,初始阶段均专注于训练各自的适配器,之后再训练编码器主体。这有助于多模态特征与LLM的渐进式安全对齐。
Qwen2.5-Omni的后训练
预训练完成后,Qwen2.5-Omni使用ChatML格式进行指令遵循微调:

图5. 用于Qwen2.5-Omni后训练的多模态指令数据ChatML格式示例
- 结构:<|system|>、<|user|>、<|assistant|>
- 支持多轮对话
- 支持纯文本、基于音频、视觉及混合模态对话
采用该格式有助于Thinker学习结构化对话,保持跨模态和跨轮次的一致性。
Qwen2.5-Omni中Talker的后训练策略
负责流式语音输出的Talker组件通过三个精心设计的阶段进行训练:
阶段1:语音延续
类似标准的下一个token预测,但针对音频token。Talker训练目标是生成自然流畅的语音输出,保持前序token的上下文、语调和节奏。这可理解为学习如何像人类说话者一样连贯地持续表达。
阶段2:基于DPO的稳定性优化
DPO(直接偏好优化) 是一种强化学习技术。与仅优化可能性不同,它直接教会模型偏好高质量输出而非低质量输出。模型通过对比语音响应对(优质vs.劣质)进行学习,基于较低词错误率(WER) 和较少标点错误识别并偏好"更优语音"。
阶段3:多说话人指令调优
本阶段训练Talker模拟不同说话人的声音,基于指令或上下文调整语气、情感、韵律和风格。这使用户或下游任务能够控制语音的呈现方式。
训练中还采用音色解耦技术,将声音与语义内容分离。音色代表语音的独特品质,解耦有助于将这一品质与文本含义分离,确保语音特性独立于内容,实现任意说话人声音与任意内容的组合使用。
强化学习技术通过词错误率(WER)和标点反馈过滤低质量输出。
基础Talker训练完成后,通过最终微调步骤使其能够模拟特定人的语音,提升语音的流畅度和真实感。
以上即为Qwen2.5-Omni的完整介绍。
结论
Qwen2.5-Omni代表了通用型实时多模态AI助手发展的重要一步。随着世界向多模态计算迈进,Qwen2.5-Omni展现了未来趋势:一款能够同时看、听、理解和表达的AI。通过整合强大的架构(Thinker-Talker)、深度集成的训练流程以及TMRoPE和分块流式处理等智能推理设计,该模型能够在广泛的实际场景中高效运行。
Qwen2.5-Omni不仅是另一款多模态模型,更是一款精心设计的流式优先AI助手,能够实时跨文本、语音、视觉和视频进行理解与响应,具备自然语音、长序列推理和多说话人表达能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)