【智能体记忆】记忆管理系统:深入了解mem0的记忆管理机制
本文深入讲解了智能体记忆框架Mem0的核心实现,展示了核心记忆内容抽取阶段和更新阶段的2个阶段以及处理的prompt和完整流程,希望对你有所启发。如果你对他的实现有兴趣,推荐去看看论文。
目录
1.前言
当前LLM面临的最大问题是记忆。他们无法理解任何不属于他们学习背景的内容。这里所说的“背景”指的是:
上下文 = 形式字符串 + 形式字符串 + 形式字符串 + 过去数据 + 问题。
暴力点来说,只需要把对话数据粘贴到提示和问题中,然后就完成了,对吗?某种程度上确实如此,但如果聊天内容长达 1M 个 token 怎么办?LLM 的上下文窗口(一次推理中能处理的 token 数量上限)将无法容纳和处理它。
另一种建议是用 RAG(检索增强生成)方案,也就是把过去的信息存到向量数据库里,并根据用户查询进行检索。这样我们可以取出与用户最相关的前 100 或 200 段对话,把它们和当前问题一起作为提示喂给模型。但这依然不高效:
-
它会存非常原始的聊天数据,这些数据对 LLM 是否有用并不确定。很多对话谈的是同一件事,但语境不同。语境信息会丢失,缺乏对过去语境的理解就把聊天记录原样放进提示词。
-
随着每次对话增加,检索质量会随时间变差。数据库变大后,会出现更多相似的向量。旧信息可能被“压住”,相关性降低。
-
没有学习或记忆更新机制。比如我一年前告诉 LLM 我是素食者,6 个月后又说我是荤食者。现在就产生了两条相互矛盾的记忆。
人们时不时地会提出各种各样的解决方案来解决记忆问题。每种方法都有其自身的缺陷和优势。Mem0是对这篇论文的实现:《Mem0:构建具有可扩展长期记忆的生产就绪型 AI 代理》,它以独特性和高效性解决了上述几乎所有问题。
Mem0在 LOCOMO benchmark(一个用于评估“长上下文/多会话对话记忆能力”的公开基准与评测框架)基准上进行了全面评测,系统性地将Mem0的方法与六类基线进行对比:(i)已有的记忆增强系统;(ii)采用不同切块大小与 k 值的检索增强生成(RAG);(iii)处理完整对话历史的全上下文方法;(iv)开源记忆方案;(v)专有模型系统;(vi)专用的记忆管理平台。实证结果显示,我们的方法在四种问题类型(单跳、时间类、多跳、开放域)上始终优于现有的所有记忆系统。值得注意的是,Mem0 在“LLM 作为评审”的指标上相对 OpenAI 实现了 26% 的提升;而带图记忆的 Mem0 (Mem0g)相比基础版 Mem0 的总体得分约高 2%。
除了准确率提升外,与全上下文方法相比,Mem0还显著降低了计算开销。具体而言,Mem0 将 p95 延迟(95 分位延迟)降低了 91%,并节省了超过 90% 的 token 成本,从而在高级推理能力与实际部署约束之间提供了一个颇具吸引力的平衡。我们的研究结果突显了结构化、持久性记忆机制对于长期会话连贯性的关键作用,为更可靠、高效的 LLM 驱动 AI 代理铺平了道路。
论文链接:Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
2.Mem0架构和工作原理
2.1 基本概念
首先,我们先理解它的各个组成部分,然后再走一遍整体流程。
摘要(Summary)
这指的是用户完整的过往信息。但它与 RAG 有何不同?在 Mem0 中,这部分被完整地总结成一个段落——可以把它想象成把你的过去写成一段话,但只包含重要信息,不含任何不必要的细节。它简短、精确、直击要点。先不用担心我们如何得到它——稍后会讨论。只需要理解它是一段承载你“karm kundli”的文字。
最近的 M 轮对话(Last M Conversations)
这指的是用户与机器人最近的 M 组消息对(从最新往回数到第 M 轮)。它用于理解当前聊天的上下文、用户在谈什么、以及这段对话到底在讨论什么。
MT-1 和 MT
MT-1是用户提出的问题,MT是机器人给用户的回答。新信息将从这些字符串中被抽取出来。
好了,现在你已经有足够的信息来理解这些阶段了。
2.2 阶段(Phases)
完整的 Mem0 架构分为两个阶段:
-
抽取阶段(Extraction Phase)
-
更新阶段(Update Phase)
2.3 提取阶段
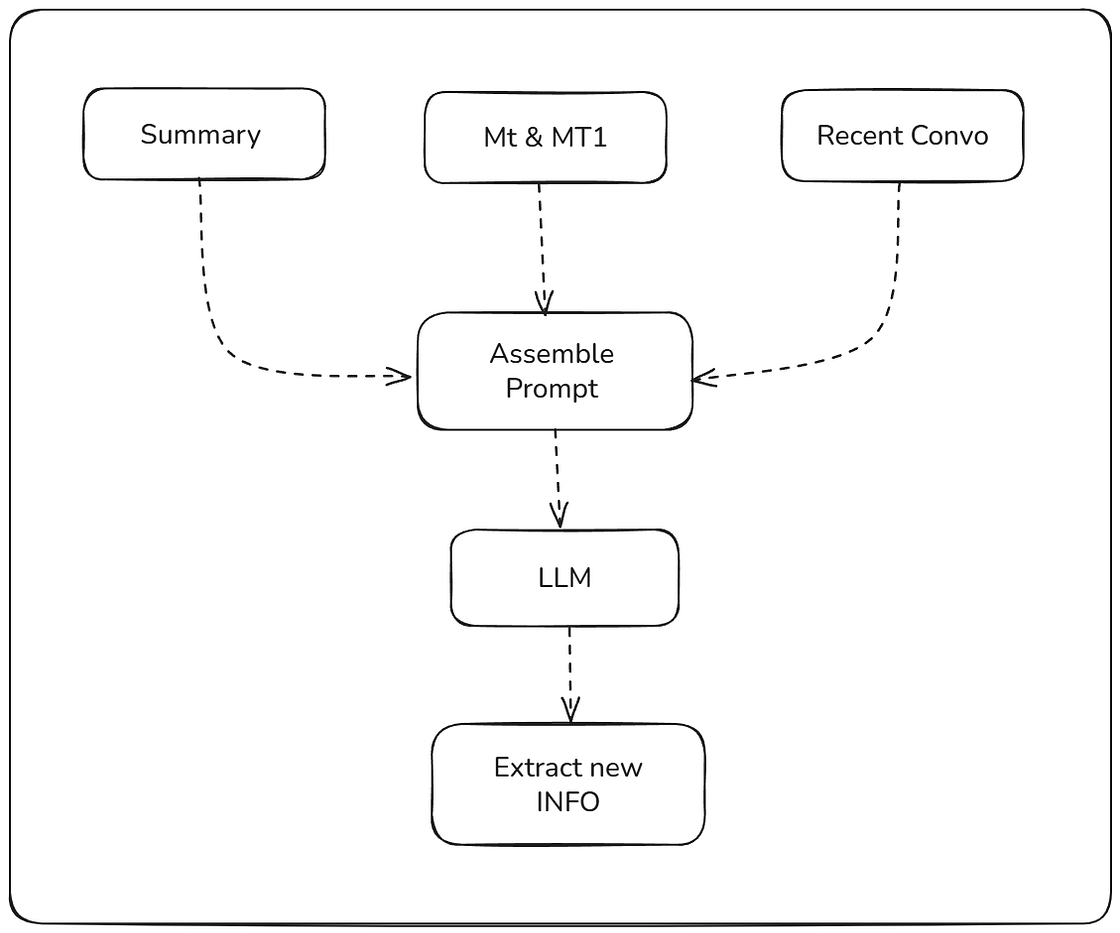
在提取阶段,模型会提取摘要和最后对话以及 (MT-1, MT),并将所有这些组合成一个优化的提示。然后,模型会提取它认为重要且应该考虑的新信息。需要记住的是:新信息只会从 MT和MT--1中提取,摘要和最后对话将用作额外的上下文。
def form_extraction_prompt ( summary, recent_messages, mt_1, mt ):
"""
构建LLM的提示,指示它仅从最新的消息交换中提取新的、突出的、事实性的信息,
简洁地重新表述它们,如果不存在此类信息则返回 <none>。
"""
prompt = (
"您是一个 AI 助手,旨在从对话中提取**关键的、新的、可操作的事实**以供记忆存储。\n"
"您的目标是识别并提取*仅*对未来交互至关重要的事实,重点关注用户特定的详细信息、偏好、说明或重要更新。\n"
"**您的主要指令是精确和有用,捕捉重要细节同时避免噪音。**\n\n"
)
# 将核心数据直接与最严格的指令放在一起
prompt += "### 事实的主要来源(仅分析此部分进行提取):\n"
prompt += f"用户:{mt_1} \n助手:{mt} \n\n"
prompt += "### 结束主要来源\n\n"
# 提供上下文,但要有明确的界限
prompt += "### 上下文信息(仅用于背景 - 请勿从此处提取事实):\n"
prompt += "--- 一般对话摘要(提供历史上下文;请勿提取事实):\n"
prompt += f" {summary} \n\n"
prompt += "--- 最近对话历史记录(提供即时上下文;请勿提取事实):\n"
if not recent_messages:
prompt += "没有最近消息。\n"
else :
for msg in recent_messages:
if 'content' in msg and 'role' in msg:
prompt += f"- {msg[ 'role' ].capitalize()} : {msg[ 'content' ]} \n"
elif 'user' in msg and 'assistant' in msg:
prompt += f"- 用户:{msg[ 'user' ]} \n- 助手:{msg[ 'assistant' ]} \n"
elif 'content' in msg:
提示 += f"- {msg[ '内容' ]} \n"
prompt += "### 结束上下文信息\n\n"
# 最终、平衡的任务说明
prompt += (
"## 任务:提取关键、全新、可操作的事实\n"
"1. 你的唯一重点是**专门**分析‘主要事实来源’部分(最新的用户-助理交流)以识别新事实。\n"
"2. **请勿**从‘上下文信息’部分(摘要或最近对话历史记录)提取任何事实或信息。这些内容用于理解正在进行的对话,而不是用于提取新事实。\n"
"3. 仅提取**具体、可验证且重要的细节**,这些细节可确定与用户或任务直接相关的**用户偏好、明确指示或新事实信息**。这包括以下内容:\n"
" - 用户的姓名、年龄、位置或联系信息(如果提供)。\n"
" - 声明的偏好(例如,“我更喜欢咖啡”、“我喜欢黑暗模式”)。\n"
" - 直接指示或要求(例如,‘明天提醒我’,‘我需要周五之前拿到报告’。\n"
" - 与特定正在进行的任务相关的关键信息。\n"
"4. **简洁的改写**:如果提取了一个事实,**请将其改写得尽可能简短、简洁且信息丰富。**删除所有填充词。专注于关键词和直接陈述。简洁比语法更重要。例如,将“用户提到他们的名字是约翰”改为“用户名:约翰”。将相关事实组合成一个简洁的句子。\n"
"5. **何时返回 <none>:**如果“主要事实来源”*仅*包含非关键、新奇且可操作的事实内容,则**必须**输出“<none>”,而不能输出其他任何内容。这适用于以下内容类型:\n"
" - **对话开销**:**问候、闲聊、寒暄或简单的致谢(例如,“嗨”, “你好”、“你好吗?”、‘好的’、‘知道了’、‘谢谢’、‘不客气’)。\n"
" - **常规信息查询**:关于常识、时事或主题的问题,不会透露特定的用户偏好、指示或个人信息(例如,“法国的首都是哪里?”、‘告诉我关于人工智能的信息’、‘天气怎么样?’)。\n"
" - **冗余信息**:已知的信息,不会提供有关用户或任务的新更新或说明。\n"
" - **不可操作的语句**:不需要任何记忆或后续操作的语句。\n"
" 不要解释为什么返回“<none>”。\n\n"
"**提取事实的示例输出格式:**\n"
"- 用户名:John。\n"
"- 偏好:深色主题。\n"
"- 需求:周五前报告。\n"
"- 任务:周一预订飞往德里的航班。\n"
"\n"
"提取的事实(或 <无>):\n"
)
return prompt2.4 更新阶段
这里将获取新信息的列表,并对所有信息进行进一步处理,也就是现在的更新阶段。对于更新阶段,你需要了解一些术语。
2.4.1 记忆数据库
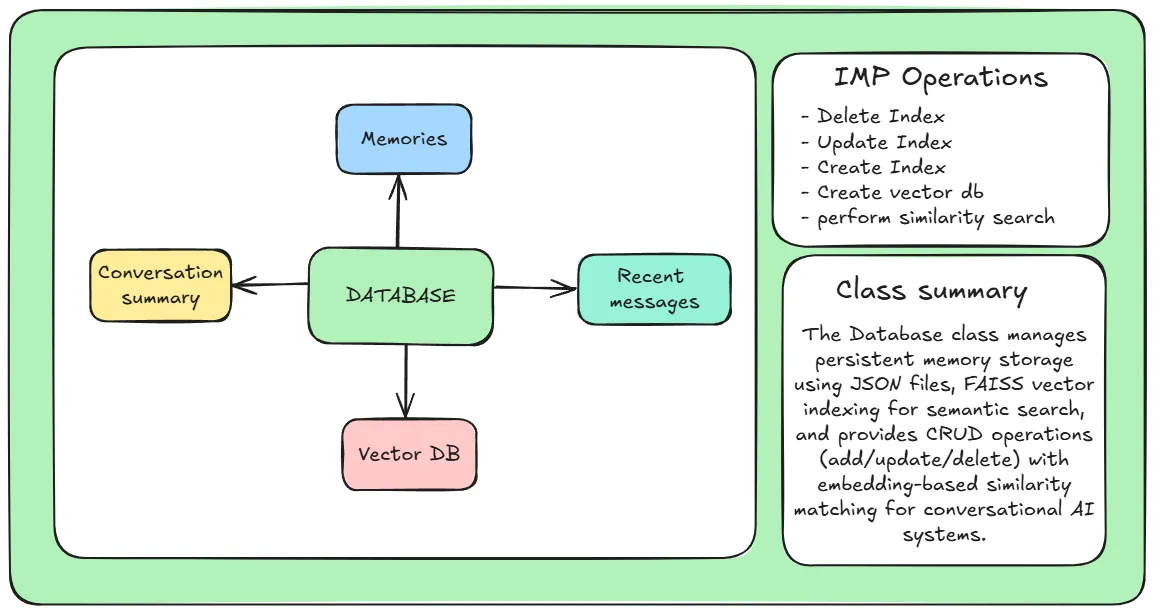
就是我们所说的主记忆。它的作用是存储所有重要且最相关的记忆。Mem0使用了一个 JSON 文件作为记忆数据库。同时还维护了一个记忆向量数据库,以便进行相似性搜索。
Database类,它处理所有 DBMS 操作并保存所有内容。我所说的“所有内容”是指
有一个Database类,它处理所有 DBMS 操作并保存所有内容。我所说的“所有内容”是指:
-
以字符串形式呈现的对话摘要
-
向量数据库
-
最近的 M 消息
-
记忆就像一本字典
它具有以下功能:
-
删除索引:从中删除索引
database.memories。 -
更新索引:更新中的索引
database.memories。 -
添加索引:向中添加新数据
database.memories。 -
创建向量数据库:不完全是 DBMS 操作,而是从中创建向量数据库的基本操作
database.memories。 -
相似性搜索:执行向量相似性搜索(FAISS数据库)
2.4.2 执行更新
在提取阶段,我们将提取的数据作为列表获取吗?现在我们将在这里使用它。我们将从列表中取出一个新信息元素……比如说:
“我只在星期一吃素”并从向量数据库中检索k 个最相似的句子。
然后,将这k 个元素与提取的元素一起输入到模型中,要求模型判断它是什么类型的数据,并在此基础上建议数据库操作:
-
ADD:此操作向数据库添加一个新元素。你猜怎么着?它并不是提取出来的那个元素,而是一个更紧凑、更准确的表示。
-
DELETE:如果模型确定需要删除某些信息,则会触发此操作。LLM 返回要删除的内存的 ID,然后该内存将从数据库中删除。
-
更新:如果 LLM 发现现有记忆需要更新,例如,如果当前记忆说“我是素食主义者”,但新信息添加了“仅在星期一” - 它会使用新信息更新记忆索引。
-
NOOP:这是一个无操作命令。意思是:什么也不做,直接跳过。
以下是更新阶段的提示:
def create_update_prompt ( candidate_fact: str , similar_memories ) -> str :
print ( "similar_memories:" )
print (similar_memories)
prompt = f"""你是一个智能记忆管理系统,旨在将新信息处理成知识库。你的任务是分析一个“候选事实”,并将其与一系列“现有类似记忆”仔细比较,以确定所需的精确操作。
**你的指导原则:
**要极其谨慎地选择。
**避免添加冗余信息。
**只有当“候选事实”引入了真正独特且以前未记录的信息时才添加。如果候选事实改进或替换了现有记忆,即使措辞略有不同,也应优先更新现有记忆。
---
##
待评估的候选事实
**候选事实:** {candidate_fact}
---
## 现有类似记忆(用于比较)
"""
if similar_memories:
for i, memory in enumerate (similar_memories, 1 ):
prompt += f"记忆 ID: {memory.get( 'memory_id' , 'N/A' )} \n" \
f"内容: {memory.get( 'content' , '' )} \n" \
f"相似度得分: {memory.get( 'score' , 0 ): .3 f} \n" \
f"---\n" # 记忆之间的分隔符
else :
prompt += "未找到相似的记忆。这很可能是一个新的事实。继续添加。\n---\n" # 加强“新事实”
prompt += """
---
## 定义的操作
* **添加**:**仅当**“候选事实”引入了真正的**全新概念或一条信息**,且该信息未被任何“现有类似记忆”提及、暗示或与之相矛盾。此信息应谨慎使用,作为排除 UPDATE、DELETE 和 NOOP 之后的最后手段。
* **条件**:候选事实代表一条独特的、从未被记录过的可操作情报。
* **示例**:**现有信息:“用户喜欢咖啡。”候选信息:“用户想要一部新手机。”-> ADD。
* **ADD 的输出**:{"operation":“添加”,“target_memory_id”:“”,“updated_content”:null}
* **更新:**如果“候选事实”提供了关于现有高度相似的记忆的**额外、改进或略有不同的细节**,则**优先考虑**此操作。这包括措辞不同但核心含义或主题相同的情况。它增强、澄清或巧妙地修改了现有记录,而不会完全与之相矛盾。
* **条件:**候选事实为现有记忆添加了具体、补充或略微改写的信息,使现有记忆更加完整或准确。
* **示例 1(改进):**现有内容:“用户住在纽约。”候选内容:“用户住在纽约,具体来说是布鲁克林。”-> 更新。新内容:“用户住在纽约布鲁克林。”
* **示例 2(改写/完成):**现有内容:“用户 30 岁。”候选内容:“我的年龄是 30 岁。”-> 更新。新内容:“用户 30 岁。”(即使语义相同,也请重新表述为标准表述)。
* **示例 3(添加小细节):**现有内容:“用户想要披萨。”候选内容:“我想要一个大号意大利辣香肠披萨。”-> 更新。新内容:“用户想要一个大号意大利辣香肠披萨。”
* **更新输出:** {"operation": "UPDATE", "target_memory_id": "ID_OF_MEMORY_TO_UPDATE", "updated_content": "修订后的合并简洁内容"}
* **删除:**仅当**“候选事实”*直接且明确地与*现有的高度相似的记忆*相矛盾或使其无效时,才选择此操作。新信息使旧记忆在事实上不正确或完全不相关。
* **条件:**候选事实使现有记忆明确错误或过时。
* **示例:**现有:“用户的名字是 John。” 候选:“我的名字实际上是 Mike,不是 John。” -> 删除“用户的名字是 John”。
* **删除操作的输出:** {"operation": "DELETE", "target_memory_id": "ID_OF_MEMORY_TO_DELETE", "updated_content": null}
* **NOOP:**仅当**“候选事实”与现有记忆**完全相同(或语义上几乎完全相同)**、**未提供任何新信息**、或相对于现有记忆而言**不重要/冗余**时,才选择此操作。这意味着无需采取任何行动,因为该记忆已经以充分的形式存在。
* **条件:**候选事实对现有记忆没有任何有意义的补充或更改。它是真正的重复或无关细节。
* **示例 1**:现有语句:“用户喜欢咖啡。” 候选语句:“我真的很喜欢咖啡。” -> NOOP。
* **示例 2**:现有语句:“用户住在柏林。” 候选语句:“用户的住所是柏林。” -> NOOP。(相同的事实,不同的措辞,没有新的信息)。
* **NOOP 的输出:** {"operation": "NOOP", "target_memory_id": "", "updated_content": null}
---
## 决策指令
1.**按顺序排列操作优先级:NOOP > DELETE > UPDATE > ADD。**如果“候选事实”符合 NOOP 的标准,请选择 NOOP。如果不符合,请勾选 DELETE。如果还不符合,请勾选 UPDATE。仅当以上都不适用时,才选择 ADD。
2.**严格比较**:仔细将“候选事实”与*每个*“现有类似记忆”进行比较。考虑语义,而不仅仅是确切的措辞。3.**合并和压缩更新**:**对于**更新**,您*必须*生成一个新的 `updated_content` 字符串,该字符串精心组合了来自 `候选事实` 和 `target_memory` 的信息。此 `updated_content` 应**尽可能简洁且信息丰富**,消除冗余,类似于事实提取过程。 (例如,将“用户住在纽约”和“用户住在布鲁克林”合并为“用户住在纽约布鲁克林”)。
4.**更新/删除的目标 ID:**如果执行**更新**或**删除**操作,您*必须*识别要执行操作的特定内存的 `target_memory_id`。
5.**输出格式遵循:**仅以 JSON 对象的形式提供您的响应。请勿在 JSON 之外包含任何其他文本、解释或对话填充内容。
---
提取的 JSON 操作:
“””
return prompt这些操作将针对从提取阶段提取的每个元素同时调用。
更新记忆有什么用?更新后的记忆用在哪儿?
- 第一个用途是相似性搜索,我们已经在更新阶段使用过它。
- 第二个也是最重要的用途是 生成摘要。
现在,让我们转到摘要生成。我们在这里所做的是从数据库中获取更新后的记忆,并要求模型基于它们生成一个全新的摘要。
2.4.3 生成摘要
def create_summary_prompt ( memories_list ):
# 这个初始指令很好,它设定了角色
memories_section = "你是一位专注于极其简洁和关键事实的摘要作者。\n"
memories_section += "从以下记忆中仅提取关键的、可操作的信息:\n"
memories_section += "\n--- 记忆开始 ---\n"
for memory in memories_list:
memories_section += f"- {memory[ 'content' ].strip()} \n" # 添加连字符表示项目符号,添加条形码表示清晰的线条
memories_section += "--- 记忆结束 ---\n\n"
prompt = (
f" {memories_section} "
"摘要规则:\n"
"1. **仅包含关键事实**:仅包含绝对*必须*记住的事实,以便将来的交互(例如,用户偏好、明确说明、名称、重要决定)。\n"
"2. **极简主义**:消除所有填充词、问候语、闲聊和对话流畅。直奔主题。\n"
"3. **短语/关键词**:使用短语、关键词或项目符号(如果自然)代替完整的句子。简洁优先,语法次于语法。\n"
"4. **无引言/结论**:直接从事实开始。不要写“这是一个摘要”或类似的东西。\n"
"5. **段落格式**:尽管简短,但输出为单个密集的段落。\n"
"6. **所需样式示例:“用户名:John。喜欢黑暗模式。需要在周五之前提交报告。”**\n\n"
"根据这些规则生成极其简洁的摘要。如果不存在关键事实,则输出“尚无关键信息。”\n"
"摘要:"
)
return prompt注:这是一个极简操作。有很多方法可以解决这个问题,例如,你可以将旧的摘要与新的记忆一起使用,或者将更新和删除的记忆结合起来修改摘要。这也可能是一种有效的方法。
3.完整的工作流程
现在,让我们缩小范围,再次回顾一下实际流程。根据你的限制和需求,设计工作流程的方法有很多种。以下是Mem0实现的:
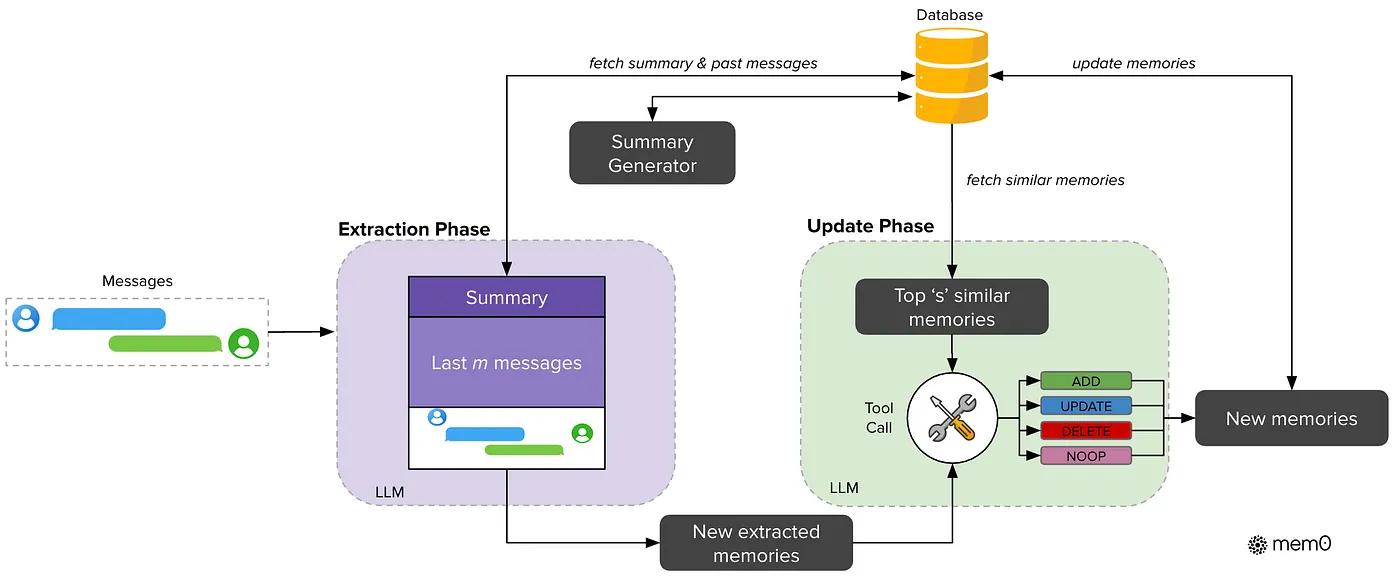
初始启动时,会根据记忆数据库生成概要。概要生成后,您就可以开始聊天了。
当用户发送消息时,提示(用户输入)会与摘要和最近的对话一起传递,以便生成正确且相关的答案。答案生成后,将触发提取阶段。
提取阶段结束后,更新阶段开始更新数据库。然后,聊天循环继续。
您可以将摘要生成配置为在每第 K 次迭代时运行,甚至可以异步运行,这样您就不必每次都等待摘要生成。
这就是实现Mem0的基本方法。你可以在我的 GitHub 上找到它,并在你的本地系统上运行它。你甚至可以进一步改进它,或者用你自己的方式优化它。论文也值得读一读,官方实现还包含一种基于图的方法,其结果比传统的基于向量数据库的方法有所改进。
4.总结
本文深入讲解了智能体记忆框架Mem0的核心实现,展示了核心记忆内容抽取阶段和更新阶段的2个阶段以及处理的prompt和完整流程,希望对你有所启发。如果你对他的实现有兴趣,推荐去看看论文。
智能体记忆系列往期推荐:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)