中国比欧美更爱开源,集体霸榜大模型开源榜单
中国比欧美更爱开源,集体霸榜大模型开源榜单
多榜认证的中国开源军团
可能有小伙伴和我一样念错过名字,其实业内常说的 "大模型竞技场" 就是 LMArena 排行榜。
最新榜单更让人振奋:月之暗面的 Kimi 、DeepSeek、阿里巴巴Qwen等中国厂商系列霸榜开源列表,Qwen3 系列更是在数学和编程单项里霸榜,活脱脱开源界的 "全能战队"。
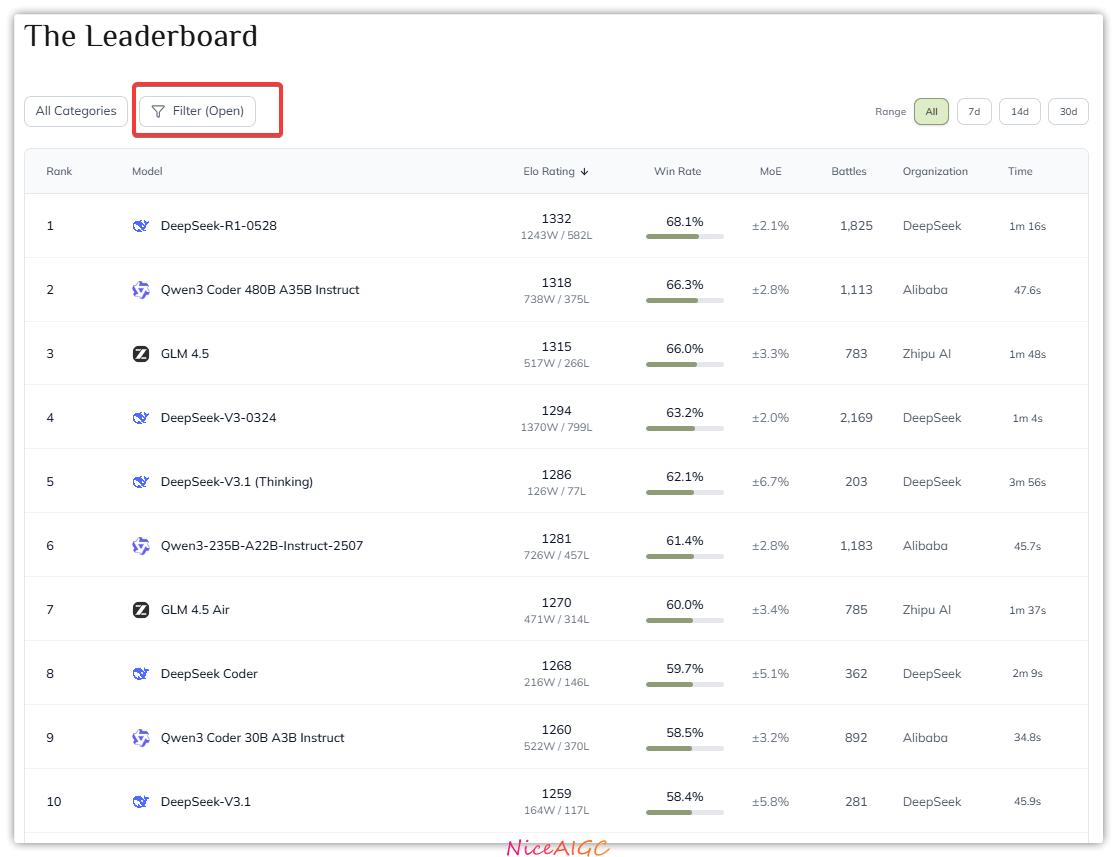
开源界的 "中国力量" 已经藏不住了。
斯坦福报告实锤:差距真的在逐步缩小
斯坦福大学 2025 年 AI 指数报告里有组惊人数据:中美顶级大模型的性能差距从 2023 年的 20% 骤降到 0.3%,DeepSeek 领衔的中国开源模型更是仅以 1.7% 差距逼宫闭源巨头。
报告里 DeepSeek 被提及 45 次,但它在 MMLU 基准测试里的得分已经悄悄超过了 GPT-4 的早期版本。
更夸张的是推理成本,达到 GPT-3.5 水平的模型调用费两年降了 280 倍,现在每百万 token 只要 0.07 美元。
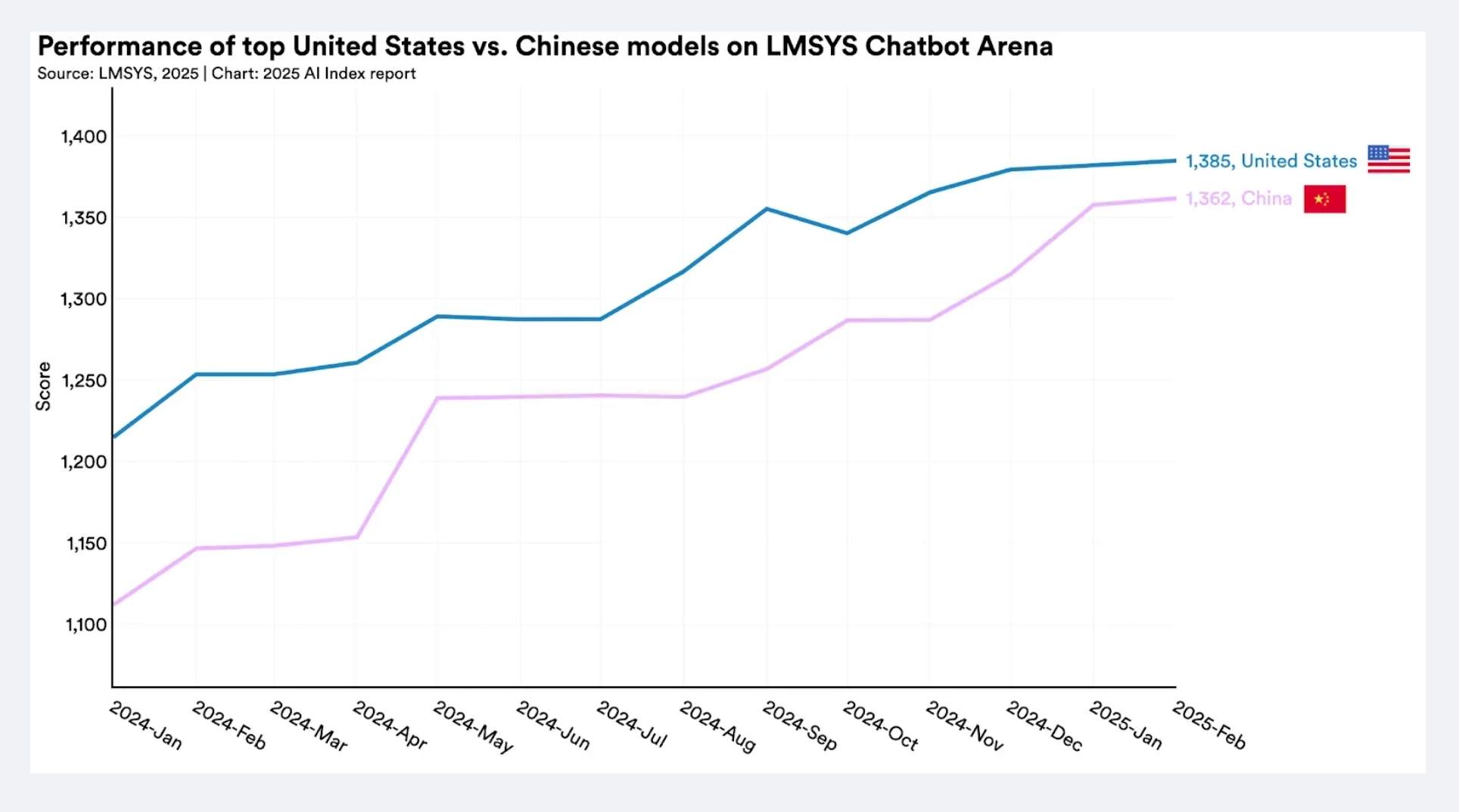
简单说就是中国 AI 不仅跑得更快了,还学会了省油
政策暖风:从国务院到山东的开源红包
7 月 31 日国务院刚通过 "人工智能 +" 行动意见,明确提出要 "构建开源开放生态体系",把魔搭社区这类平台当成重点扶持对象。
地方政府更实在,山东直接发政策红包,要求建设 "开源 + 闭源" 一体化大模型服务体系,真金白银支持模型开源。
这种从中央到地方的政策组合拳,欧美至今还没玩明白,他们还在纠结开源许可证条款时,我们已经把 "开源生态" 写进了发展规划。

此处手动@一位百度的老朋友李XX,看看开源到底有没有前途!
大厂不藏私:700 万下载量的开源底气
阿里云的周靖人在 AI 峰会上说 "开源是战略" 时,手里握着实打实的成绩单:通义系列开源模型下载量超 700 万,从 5 亿到 1100 亿参数的 8 款模型全面开放。中兴更狠,一次性开源 6 个大模型和 5 个数据集,连电信领域的核心技术都拿出来共享。这些操作在欧美大厂看来简直不可理喻 ——Meta 的 Llama 2 虽然开源,但月活超 7 亿用户就得单独申请许可,谷歌的 Gemini 至今捂着核心代码不放。

中国大厂玩开源是真・裸奔级,别人藏着掖着的技术,我们直接打包放在 GitHub 上供全球下载
24.4% 的 LLM 开发者来自中国
GitHub 的统计数据藏着更震撼的真相:中国开发者占全球 LLM 开源项目贡献者的 24.4%,远超美国的 15.7%。深夜刷 GitHub 时,你会发现中文 issue 的回复速度比英文还快,中国开发者在模型微调、部署工具等领域的贡献,就像奶茶店的珍珠,密密麻麻无处不在。
这种社区活跃度形成了良性循环,阿里通义衍生出 14 万个模型变体,相当于给开源生态播撒了 14 万颗种子。
欧美大厂的开源态度始终像拧不开的瓶盖:OpenAI 坚持闭源路线,把 GPT-4o 当成独门秘方;
Meta 虽然开源 Llama 2,但加了一堆限制条款,活像给免费奶茶加了 "限喝三杯" 的规矩。
中国厂商则选择了截然不同的路 —— 阿里云把 1100 亿参数模型开源,相当于把顶级餐厅的菜谱公之于众;
DeepSeek 更绝,连推理成本降低 280 倍的技术都共享出来。
开源能让中国 AI 弯道超车吗?
当中国开源模型在榜单上霸屏,当推理成本持续暴跌,当全球开发者都在用中国模型二次创作时,一个更值得思考的问题浮出水面:这种开源优势能持续多久?斯坦福报告说中美差距只剩 0.3%,但基础算法和芯片领域的短板仍在。或许就像网友说的:"开源让我们在应用层领先,但核心技术的攻坚战才刚刚开始。"
革命尚未完成,同志仍需努力,中国 AI 厂商们加油吧!
关注 NiceAIGC 公众号,实时获取更多AI资讯!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)