【Task05】:向量数据库实践(第三章3、4节)
定义:开源向量数据库,专为大规模向量相似性搜索与分析设计,隶属于 LF AI & Data 基金会顶级项目,由 Zilliz 公司开发。核心优势:区别于 FAISS、ChromaDB 等轻量本地存储,Milvus 采用云原生架构,具备高可用、高性能、易扩展特性,支持十亿 / 百亿级向量数据处理,面向生产环境设计。官方资源:官网()、GitHub(pymilvus(Milvus 客户端)、(多模态嵌
【项目地址】https://github.com/datawhalechina/all-in-rag
第三节 向量数据库
一、向量数据库的核心定位与价值
1. 核心需求:解决海量向量检索难题
当嵌入向量数量增长至数百万、数十亿级时,传统线性相似度计算(暴力匹配)耗时极高,无法满足 RAG 等 AI 应用的实时性需求。向量数据库的核心作用是快速、准确地从海量高维向量中找到与用户查询最相似的结果,是连接嵌入向量与大语言模型(LLM)的关键 “知识库”。
2. 五大核心功能
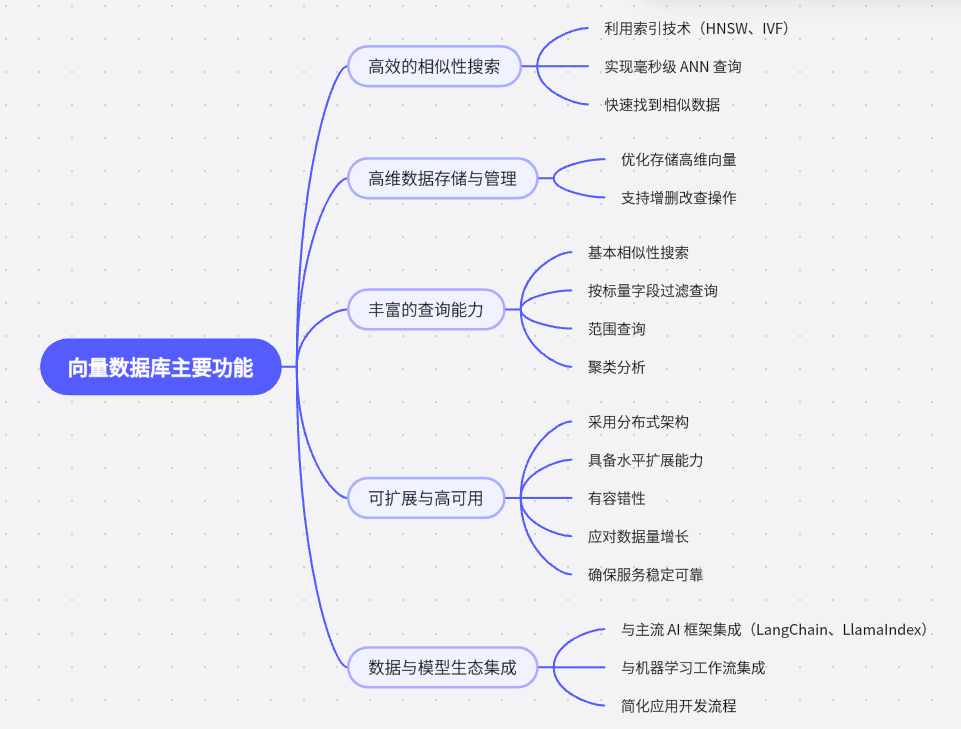
3. 与传统数据库(RDBMS)的核心差异
| 对比维度 | 向量数据库 | 传统数据库(如 MySQL) |
|---|---|---|
| 核心数据类型 | 高维向量(Embeddings) | 结构化数据(文本、数字、日期) |
| 查询方式 | 相似性搜索(ANN) | 精确匹配(如WHERE age=25) |
| 索引机制 | HNSW、IVF、LSH 等 ANN 索引 | B-Tree、Hash Index |
| 应用场景 | AI(RAG)、推荐系统、图像 / 语音识别 | 业务系统(ERP/CRM)、金融交易、报表 |
| 数据规模 | 轻松应对千亿级向量 | 千万 - 亿级行数据,超大规模需分库分表 |
| 性能特点 | 高维检索性能极高(计算密集) | 结构化查询快,高维查询性能指数级下降 |
| 一致性 | 通常为最终一致性 | 强一致性(ACID 事务) |
关系:二者互补而非替代 —— 传统数据库存储业务元数据(如用户 ID、文档创建时间),向量数据库存储 AI 生成的向量,共同支撑现代 AI 应用。
二、向量数据库工作原理
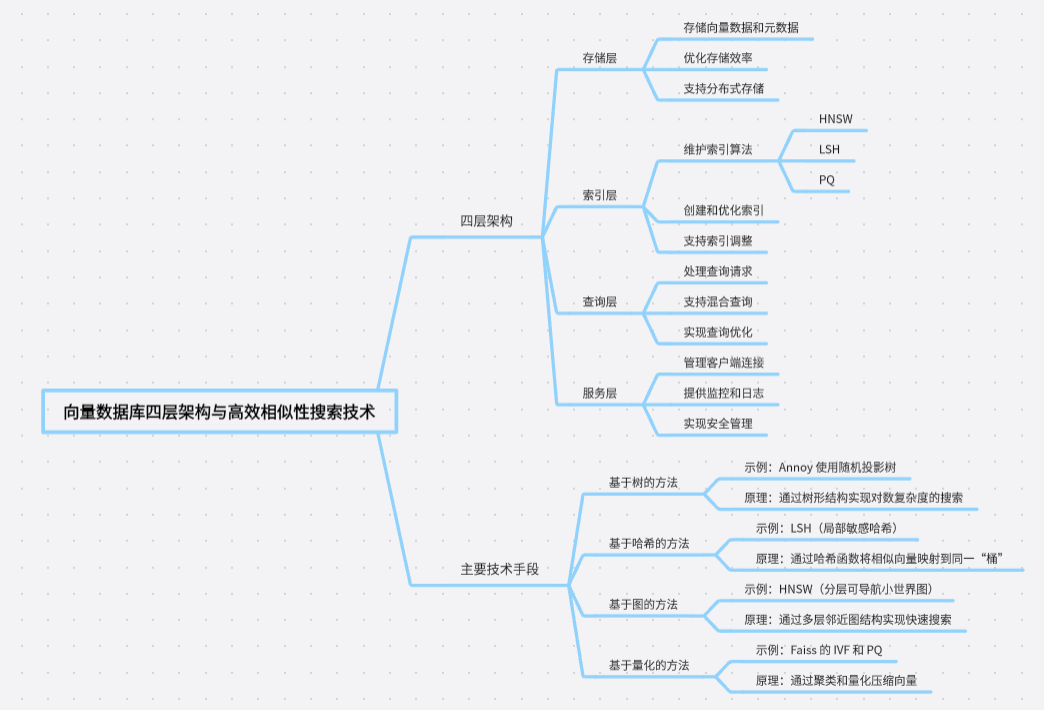
三、主流向量数据库对比与选型
1. 五大主流产品特性
| 产品 | 核心特点 | 适用场景 |
|---|---|---|
| Pinecone | 托管服务(Serverless),存储计算分离,自动扩缩容,99.95% SLA,低延迟(<100ms) | 企业级生产环境、高并发、大规模部署 |
| Milvus | 开源分布式,支持 GPU 加速,多索引算法,亿级向量处理,生态完善 | 大规模部署、高性能需求、开源自定义开发 |
| Qdrant | Rust 开发,二进制量化,RPS>4000,支持混合搜索,低延迟 | 性能敏感应用、高并发、中小规模部署 |
| Weaviate | 支持 GraphQL,20+AI 模块,多模态适配,RAG 优化,社区活跃 | AI 开发、多模态处理、快速原型迭代 |
| Chroma | 轻量级开源,本地优先,零配置安装,低资源消耗,无依赖 | 新手入门、原型开发、教育培训、小规模应用 |
2. 选型建议
- 新手 / 小型项目:优先选Chroma或FAISS(轻量库),与 LangChain/LlamaIndex 集成简单,几行代码即可运行,满足基础需求。
- 生产 / 大规模应用:数据量超百万级、需高并发 / 实时更新 / 复杂过滤时,选Milvus(开源分布式)、Weaviate(多模态)或Pinecone(托管服务)。
四、本地向量存储实践:以 FAISS 为例
1. FAISS 定位
FAISS(Facebook AI Similarity Search)是高性能向量检索库(非数据库服务),将索引保存为本地文件(.faiss索引文件 + .pkl映射文件),轻量高效,适合原型设计与中小型应用。
2. 核心实践:完整流程(LangChain+FAISS)
(1)环境准备
# 安装依赖(CPU版,GPU版需装faiss-gpu)
pip install faiss-cpu langchain_community huggingface-hub
(2)代码逻辑:创建→保存→加载→查询
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.documents import Document
# 1. 数据与嵌入模型
texts = [
"张三是法外狂徒",
"FAISS是用于高效相似性搜索和密集向量聚类的库",
"LangChain是语言模型驱动应用的开发框架"
]
docs = [Document(page_content=t) for t in texts]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5") # 中文嵌入模型
# 2. 创建并保存索引
vectorstore = FAISS.from_documents(docs, embeddings)
local_path = "./faiss_index_store"
vectorstore.save_local(local_path)
# 3. 加载索引并查询
loaded_store = FAISS.load_local(local_path, embeddings, allow_dangerous_deserialization=True)
query = "FAISS是做什么的?"
results = loaded_store.similarity_search(query, k=1) # 取Top-1相似结果
# 4. 输出结果
print(f"查询:{query}\n最相似文档:{results[0].page_content}")
(3)运行结果
FAISS index has been saved to ./faiss_index_store
查询:FAISS是做什么的?
最相似文档: FAISS是用于高效相似性搜索和密集向量聚类的库
(4)索引创建底层逻辑(LangChain 源码)
from_documents(封装层):提取文档的page_content和元数据,调用from_texts。from_texts(向量化入口):批量生成向量,传递给__from。__from(框架搭建):初始化 FAISS 空索引,准备文档存储与映射关系。__add(数据填充):添加向量到索引,存储文档,建立索引 - 文档映射。
3. 练习
- 新建代码,用 LlamaIndex 的
VectorStoreIndex类实现向量数据的加载与相似性搜索。
from llama_index.core import VectorStoreIndex, Document, Settings, StorageContext, load_index_from_storage
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 1. 配置全局嵌入模型
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")
# 索引存储路径
persist_path = "./llamaindex_index_store"
# 加载已保存的索引
storage_context = StorageContext.from_defaults(persist_dir=persist_path)
index = load_index_from_storage(storage_context)
# 创建查询引擎并执行相似性搜索
query_engine = index.as_query_engine(similarity_top_k=2) # 返回最相似的2个结果
# 示例查询
queries = [
"谁是法外狂徒?",
"LlamaIndex有什么功能?"
]
# 执行查询并输出结果
for query in queries:
print(f"\n查询: {query}")
response = query_engine.query(query)
print(f"回答: {response}")
# 显示相似文档信息
print("相似文档:")
for i, node in enumerate(response.source_nodes, 1):
print(f" {i}. 相似度: {node.score:.4f}, 内容: {node.text}")
查询: 谁是法外狂徒?
相似文档:
1. 相似度: 0.6592, 内容: 张三是法外狂徒
2. 相似度: 0.2969, 内容: LlamaIndex是一个用于构建和查询私有或领域特定数据的框架。查询: LlamaIndex有什么功能?
相似文档:
1. 相似度: 0.6753, 内容: LlamaIndex是一个用于构建和查询私有或领域特定数据的框架。
2. 相似度: 0.4149, 内容: 它提供了数据连接、索引和查询接口等工具。
Milvus介绍及多模态检索实践
一、Milvus 核心简介
1. 定位与特性
- 定义:开源向量数据库,专为大规模向量相似性搜索与分析设计,隶属于 LF AI & Data 基金会顶级项目,由 Zilliz 公司开发。
- 核心优势:区别于 FAISS、ChromaDB 等轻量本地存储,Milvus 采用云原生架构,具备高可用、高性能、易扩展特性,支持十亿 / 百亿级向量数据处理,面向生产环境设计。
- 官方资源:官网(Milvus | High-Performance Vector Database Built for Scale)、GitHub(https://github.com/milvus-io/milvus)。
二、Milvus 部署安装(单机版为例)
1. 核心依赖
- 环境要求:安装并运行 Docker + Docker Compose(Codespace 环境自带,无需额外安装)。
2. 部署步骤
| 步骤 | 操作内容 | 关键命令 / 说明 |
|---|---|---|
| 1. 下载配置文件 | 下载官方docker-compose.yml,含 Milvus 核心服务(standalone)及依赖(etcd 存储元数据、MinIO 存储对象) |
macOS/Linux:wget https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml -O docker-compose.ymlWindows: Invoke-WebRequest -Uri "xxx" -OutFile "docker-compose.yml" |
| 2. 启动服务 | 后台启动 Milvus 相关容器 | docker compose up -d(需在配置文件目录执行,拉取镜像约几分钟) |
| 3. 验证安装 | 确认容器状态与端口 | 1. 查看容器:docker ps,确保milvus-standalone/milvus-minio/milvus-etcd均为running;2. 端口检查:默认服务端口 19530(后续代码连接需用) |
3. 常用管理命令
- 停止服务(保留数据):
docker compose down - 彻底清理(删除数据):
docker compose down -v
三、Milvus 核心组件
1. Collection(数据容器)
类比 “图书馆”,是 Milvus 中数据组织的顶层单位(类似传统数据库的 “表”),所有数据操作(增删改查)围绕其展开。
(1)核心子概念
| 概念 | 类比 | 说明 |
|---|---|---|
| Partition(分区) | 图书馆分区(小说区 / 科技区) | 逻辑划分数据,默认分区为_default;可按类别 / 日期划分,减少检索扫描范围,提升性能,支持批量数据操作(加载 / 删除) |
| Schema(模式) | 图书卡片规则 | 定义数据结构,含 3 类字段: 1. 主键字段(唯一标识实体,如 INT64 / 字符串); 2. 向量字段(存储核心向量,支持 1 个或多个,适配多模态); 3. 标量字段(存储元数据,如文本 / 数字,用于过滤查询) |
| Entity(实体) | 单本书 | 具体数据单元,含主键、向量、标量字段的完整数据 |
| Alias(别名) | 推荐书单(“本周精选”) | 为 Collection 设置动态昵称,支持数据无缝更新(如切换collection_v1→collection_v2,无需修改上层代码) |
(2)Schema 设计示例(多模态场景)
以新闻文章为例,Schema 含:主键(Article ID)、标量字段(Title/Author/Image URL)、向量字段(Image Embedding/Text Embedding/Sparse Embedding),适配图文多模态数据。
2. Index(检索加速引擎)
核心是通过特殊数据结构提升向量检索速度,需在向量字段上创建,是 Milvus 高性能检索的关键。
(1)主要向量索引类型对比
| 索引类型 | 原理 | 优缺点 | 适用场景 |
|---|---|---|---|
| FLAT(精确查找) | 暴力搜索,计算查询与所有向量的真实距离 | 优点:100% 召回率; 缺点:速度慢、内存占用大 |
数据规模小(百万级内)、需精确结果 |
| IVF 系列(倒排文件) | 先聚类分 “桶”(nlist),查询时仅搜索相似桶 | 优点:平衡性能与召回率,吞吐量高; 缺点:召回率 < 100% |
通用场景,大规模数据集(亿级) |
| HNSW(基于图) | 构建多层邻近图,顶层快速导航、下层精确匹配 | 优点:检索速度极快、召回率高; 缺点:内存占用大、索引构建久 |
低延迟需求(实时推荐 / 在线搜索) |
| DiskANN(基于磁盘) | 优化 SSD 存储的图索引 | 优点:支持超海量数据(十亿级 +),内存占用低; 缺点:延迟略高于纯内存索引 |
数据无法全载入内存的超大规模场景 |
(2)索引选择依据
- 内存足够 + 低延迟:选 HNSW
- 内存足够 + 高吞吐:选 IVF_FLAT/IVF_SQ8
- 超大规模数据:选 DiskANN
- 需 100% 精确:选 FLAT(小规模数据)
3. 检索功能(核心应用)
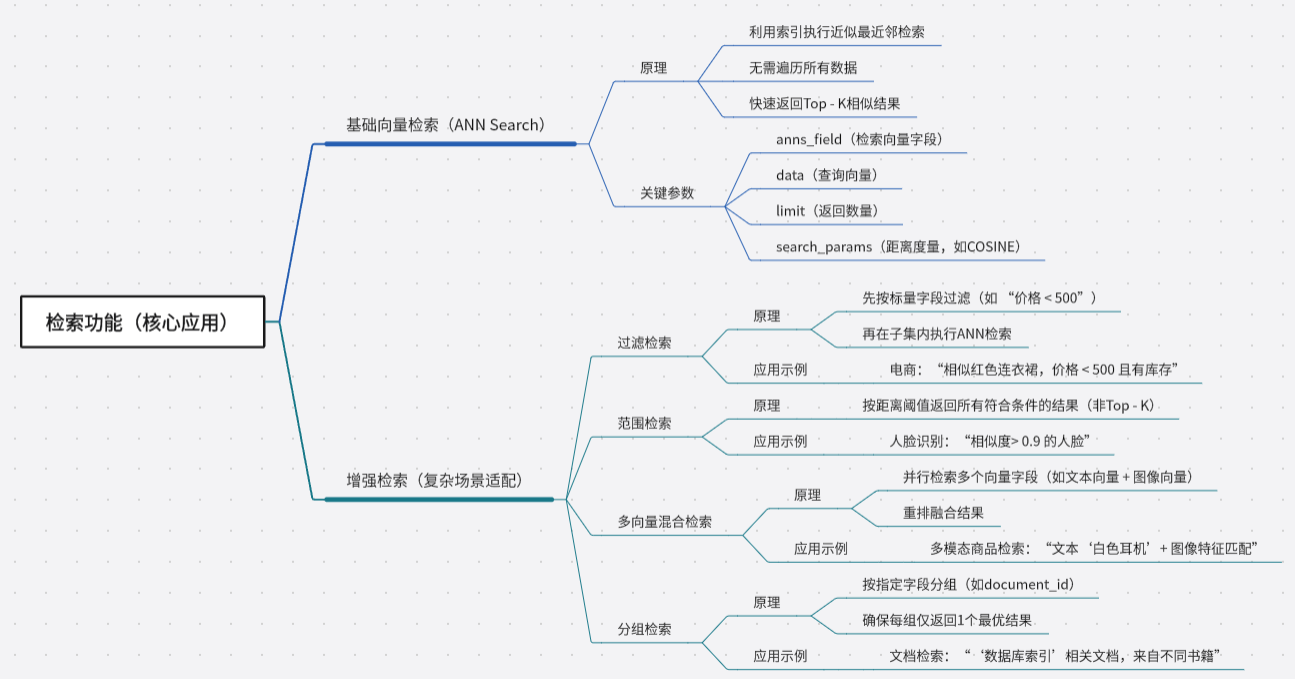
四、Milvus 多模态检索实践(图文示例)
1. 核心目标
用 Milvus+Visualized-BGE 模型,构建端到端图文多模态检索引擎(输入 “图像 + 文本”,返回相似图像)。
2. 关键步骤与代码逻辑
(1)初始化与工具定义
- 导入依赖:
pymilvus(Milvus 客户端)、Visualized_BGE(多模态嵌入模型)、cv2/PIL(图像处理)。 - 封装工具:
Encoder类:加载 Visualized-BGE,实现 “图像编码”“图文联合编码”。visualize_results函数:生成查询图像与检索结果的全景对比图。
(2)创建 Collection
- 初始化 Milvus 客户端:
MilvusClient(uri="http://localhost:19530")。 - 定义 Schema:含 3 个字段 —— 主键
id(自增 INT64)、向量vector(FLOAT_VECTOR,维度由模型输出决定,如 768)、标量image_path(存储图片路径)。 - 创建 Collection:若已存在则删除,重新创建并描述结构。
(3)插入数据
- 遍历图像目录(如
../../data/C3/dragon),用Encoder将每张图编码为向量,组织成{"vector": 向量, "image_path": 路径}格式,批量插入 Milvus。
(4)创建索引与加载
- 选择 HNSW 索引(适配低延迟需求),参数:
metric_type="COSINE"(余弦相似度)、M=16(节点最大连接数)、efConstruction=256(索引构建搜索范围)。 - 加载 Collection 到内存:
milvus_client.load_collection(COLLECTION_NAME)(检索前必需)。
(5)执行多模态检索
- 构造查询:输入 “查询图像(dragon01.png)+ 文本(‘一条龙’)”,用
Encoder.encode_query生成联合向量。 - 执行搜索:调用
milvus_client.search,返回 Top-5 相似结果,含id(主键)、distance(相似度,越近 1 越相似)、image_path(图片路径)。
(6)可视化与清理
- 生成全景图:用
visualize_results将查询图与检索结果拼接,保存并展示。 - 资源清理:释放内存(
release_collection)、删除 Collection(drop_collection)。
3. 关键结果
- 检索有效性:Top-1 结果为查询图像本身(相似度 0.9411),其余结果按相似度降序排列(均为 “龙” 相关图像)。
- 常见问题:若报
libgl.so.1缺失,执行sudo apt-get install python3-opencv安装依赖。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)