突破Agent记忆瓶颈!三层架构深度解析:如何让AI拥有“人类级“记忆?
当前,AI智能体(Agent)持续受到广泛关注,然而许多智能体系统普遍存在一个显著短板——“健忘”问题,尤其在上下文较长时更为突出。这种缺乏持续、连贯记忆能力的缺陷,严重限制了AI智能体的发展潜力与实际用户体验。由于难以真正理解用户意图并维持深层次的上下文关联,提供高度个性化的服务也变得更加困难。
当前,AI智能体(Agent)持续受到广泛关注,然而许多智能体系统普遍存在一个显著短板——“健忘”问题,尤其在上下文较长时更为突出。这种缺乏持续、连贯记忆能力的缺陷,严重限制了AI智能体的发展潜力与实际用户体验。由于难以真正理解用户意图并维持深层次的上下文关联,提供高度个性化的服务也变得更加困难。
Memory是Agent系统中重要的组成部分,因此如何为AI智能体构建一个类人记忆系统,从而设计出类人智能体(Human-like Memory for Agents)使Agent具备长期且清晰的记忆,是当前Agent研究的一个热门方向。
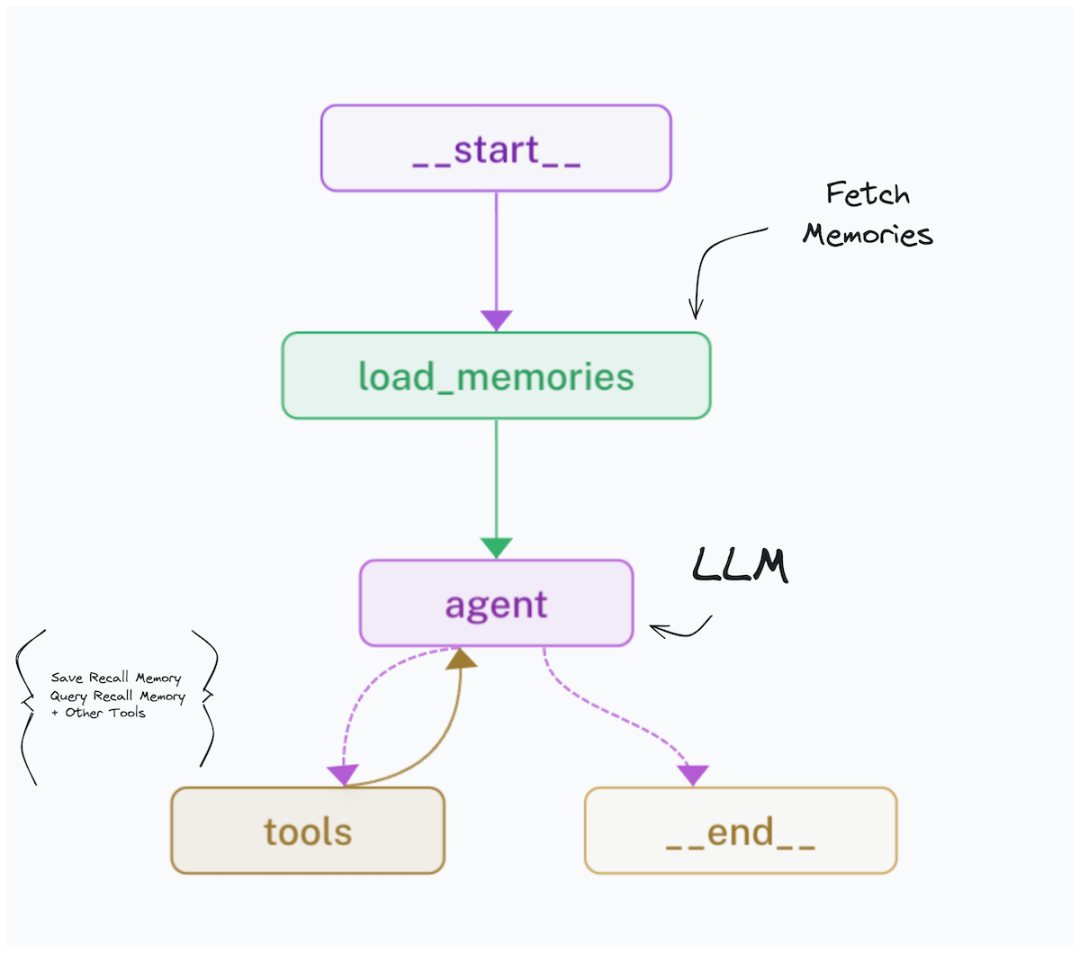
— 1 核心工作流程 —
让Agent的每一次回答都不是一次性的、孤立的计算
本文介绍的便是一个类人记忆系统的架构设计,共分为三个层次,首先通过架构图了解整个系统的核心工作流程:
**1. 用户查询 (User Query):**一切始于用户的输入。用户向AI智能体提出一个问题或指令。这可以是任何形式的交互,比如“上次我们讨论的项目进展如何了?”
**2. 调用记忆 (Access Memory):**这是整个架构的魔法所在。Agent的核心由一个强大的大语言模型驱动。但它并非孤立地处理问题,而是首先连接到Memory记忆系统。它会检索与当前查询相关的历史对话、文档、实体关系等一切信息。
**3. 生成响应 (Generate Final response):**在“回忆”起所有相关上下文之后,AI智能体将这些记忆与当前的用户查询结合起来,进行深度理解和推理,最终生成一个高度相关、充满上下文感知、且更加智能的最终响应。
这个流程确保了AI的每一次回答都不是一次性的、孤立的计算,而是基于不断积累和学习的知识库。而这个架构最精妙的设计,在于它模仿了人类记忆的加工方式,将原始信息层层递进,抽丝剥茧,最终形成结构化的知识和高度抽象的总结。
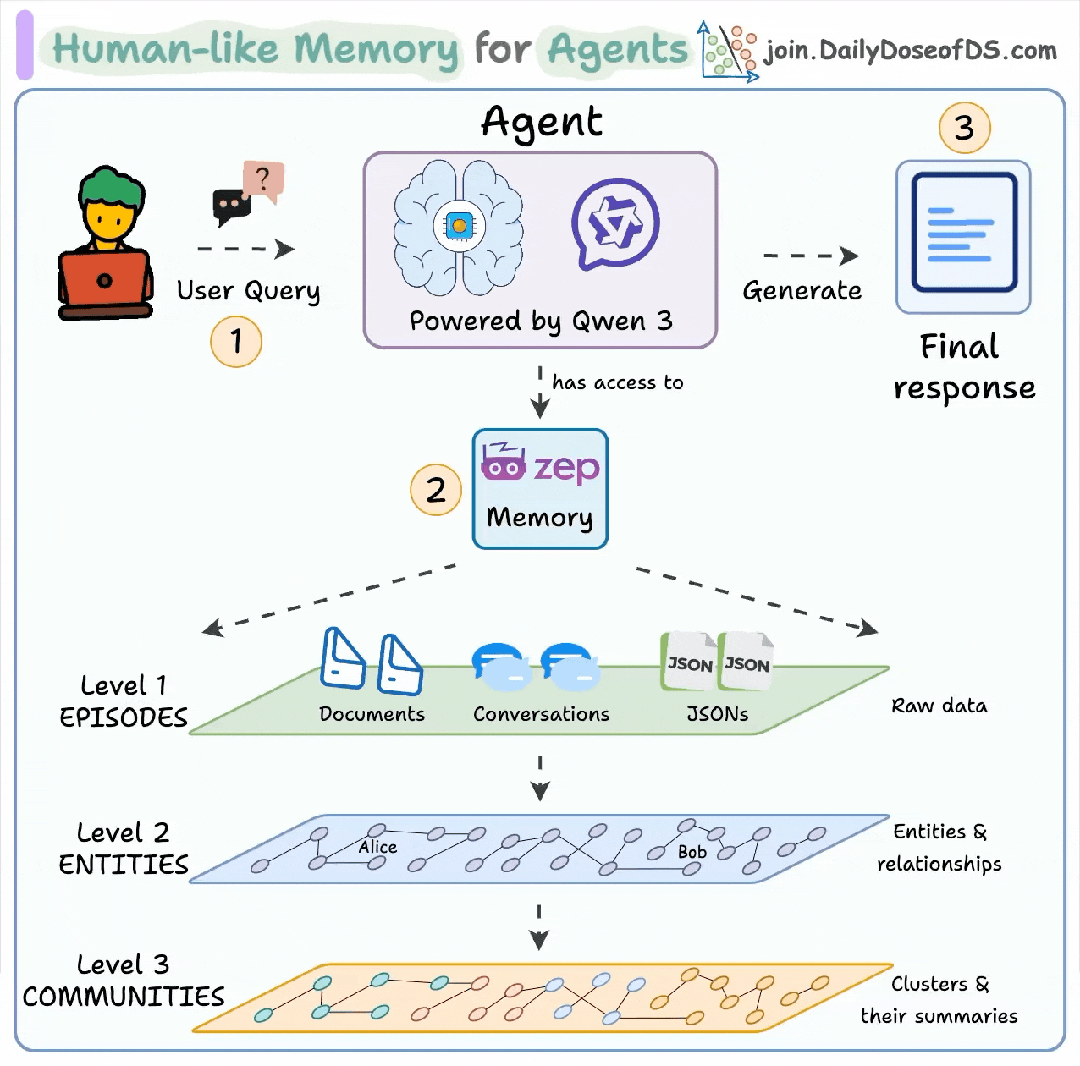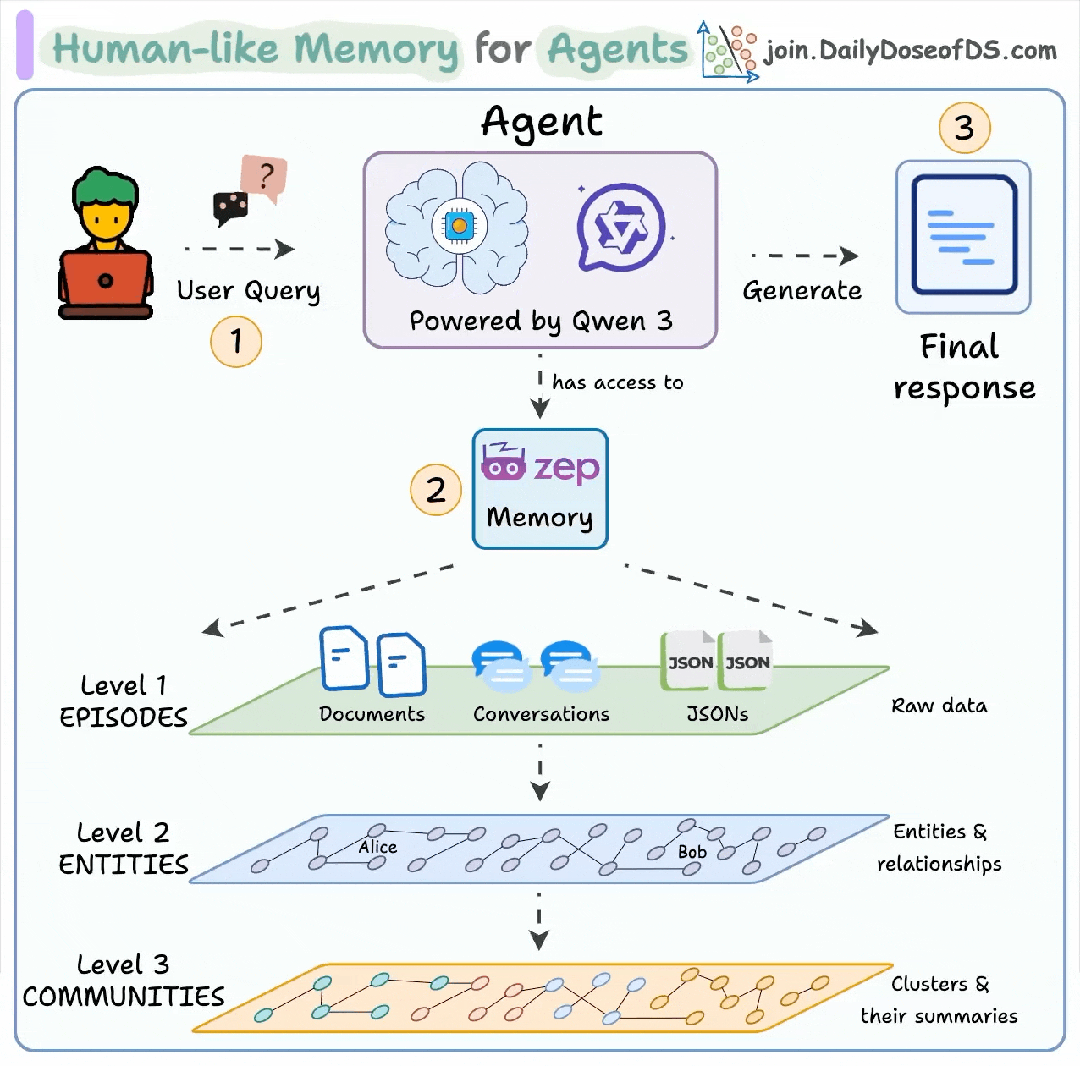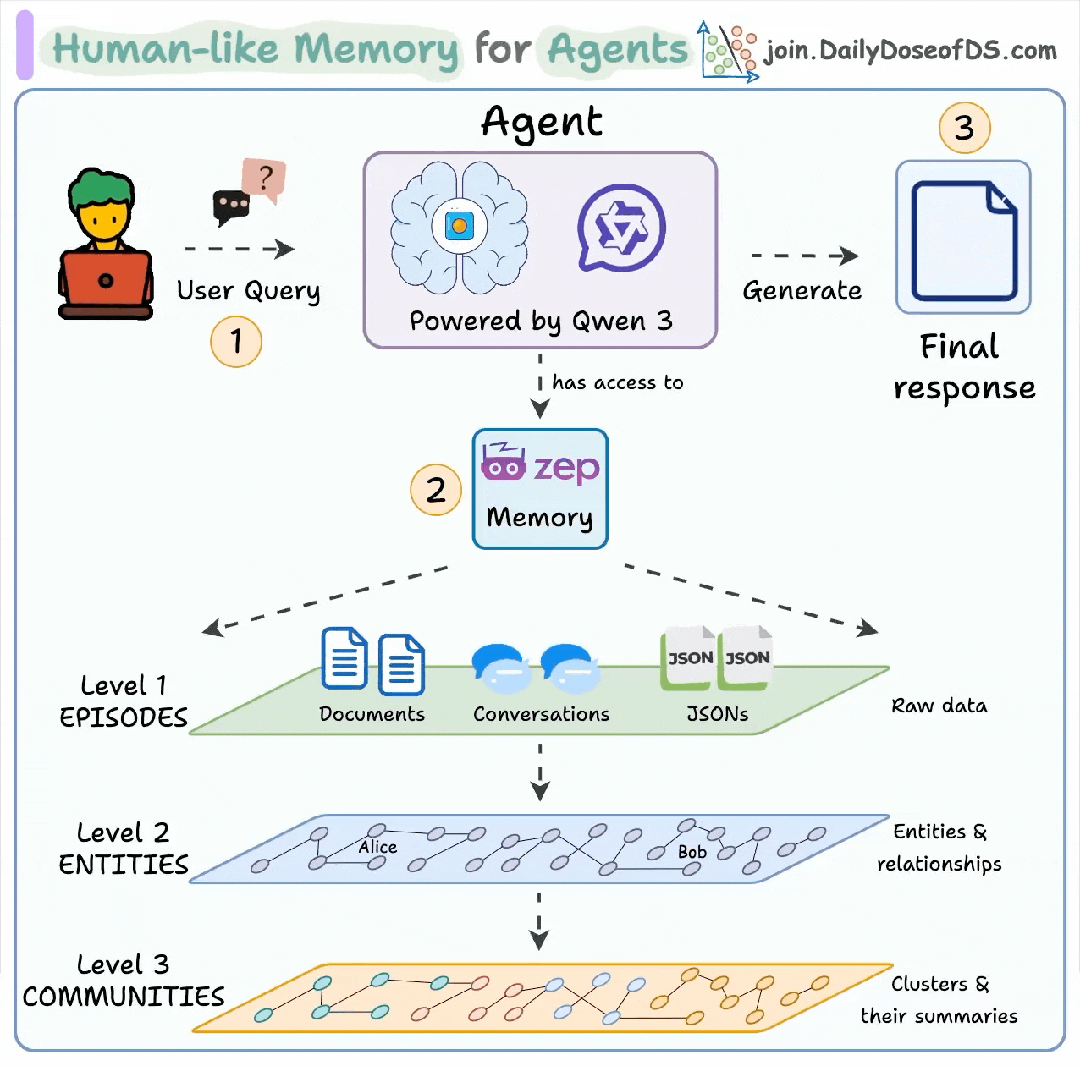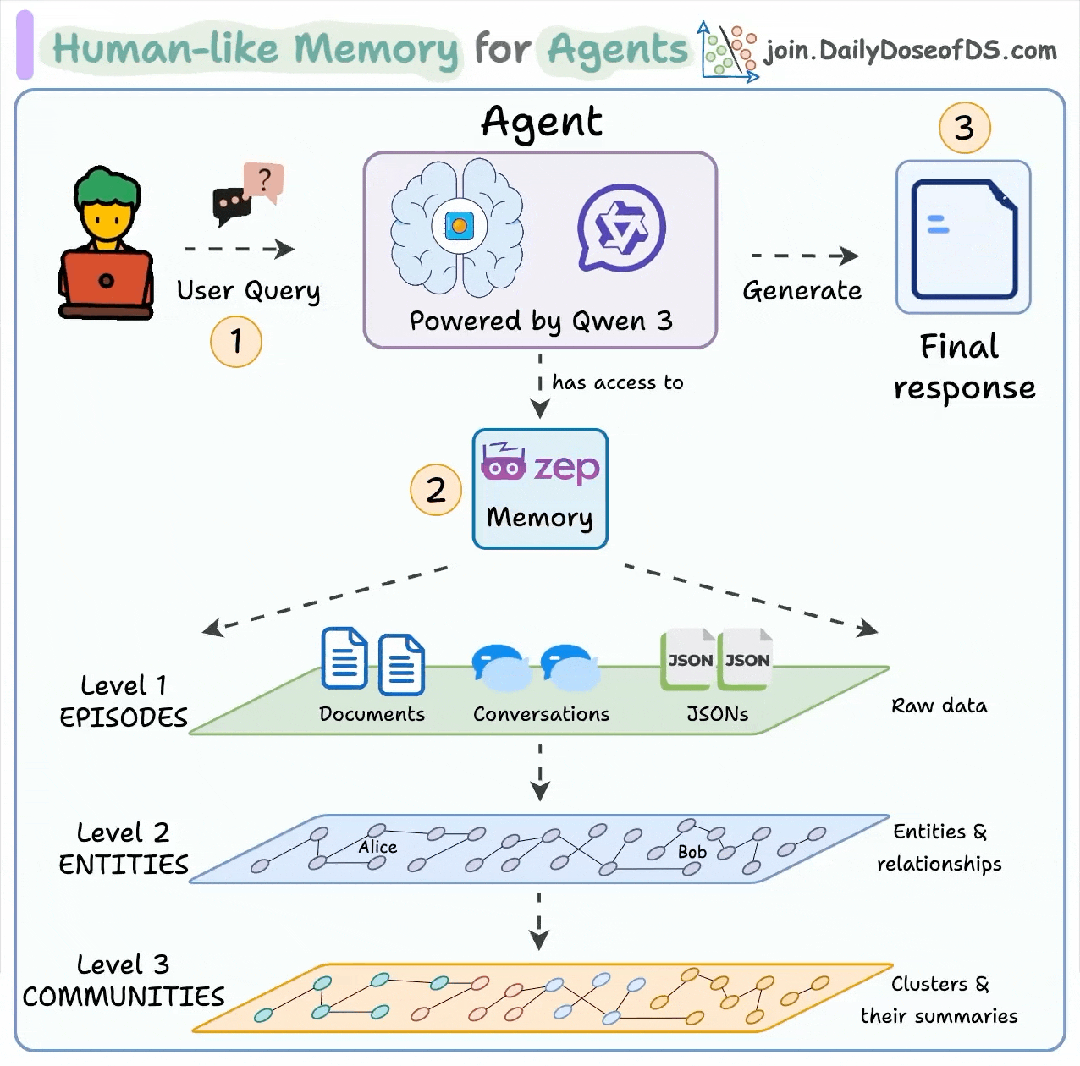
— 2.1 Level 1: EPISODES —
情节记忆层 - 原始数据
这一层是记忆金字塔的基石,负责记录所有未经处理的原始交互数据。它就像我们大脑中的“海马体”,负责短期存储我们经历的每一个具体情节。
**文档 (Documents):**智能体读取过的所有外部文件,如PDF报告、网页、知识库文章等。
**对话 (Conversations):**与用户之间的完整聊天记录,保留了最原始的交互上下文。
**JSONs:**结构化数据,可能来源于API调用结果或其他外部系统的数据。
作用:这一层保证了信息的完整性和可追溯性。所有的高级记忆都源于此,当需要核对事实或查找原始出处时,可以随时回溯到这一层。
— 2.2 Level 2: ENTITIES**—**
实体关系层 - 结构化知识
如果记忆只停留在原始数据,那就像拥有一座图书馆却不知道书在哪里、讲了什么。Level 2的作用就是对这些原始数据进行第一次提炼,构建一个结构化的知识图谱。
**实体 (Entities):**系统自动从Level 1的数据中识别出关键的概念,如图中提到的“Alice”、“Bob”,也可能是项目名称、公司、地点等。
关系 (Relationships):更进一步,它会分析并建立这些实体之间的联系。例如,系统能理解“Alice 管理 Bob”、“项目A 属于 团队B”这类关系。
作用:这一层将杂乱无章的信息转化为结构化的知识。智能体不再需要每次都全文检索海量文本,而是可以直接查询这个“关系网络”,快速找到关键信息点及其联系,极大地提升了信息检索的效率和准确性。
— 2.3 Level 3 COMMUNITIES —
社群摘要层 - 抽象概念
这是记忆金字塔的顶端,也是最高级的认知层。它在实体关系网络的基础上,进行更深度的聚类分析和模式识别,形成高度浓缩的摘要和见解。
**簇 (Clusters):**系统会自动将关联紧密的实体和关系归纳成“簇”或“社群”。例如,所有与“Q3季度营销活动”相关的任务、人员、文档和讨论,会被自动聚合在一起,形成一个主题社区。
**摘要 (Summaries):**对于每一个“簇”,系统能生成一个高层次的摘要。智能体只需读取这个摘要,就能迅速了解这个复杂主题的核心内容,而无需重新阅读所有底层细节。
作用:这一层赋予了智能体宏观洞察和快速理解复杂问题的能力。当用户问及一个跨越长时间、涉及多方的复杂项目时,智能体可以直接调用Level 3的摘要,迅速把握全局,并给出有洞见的回答。这好比我们人类能够对一段长期的经历(如“我的大学生活”)形成一个高度概括的印象。
— 3 为什么类人记忆系统架构如此重要?****—
AI智能体从“有用的工具”向“可靠的伙伴”转变
这种分层记忆架构不仅仅是一个技术概念,它为构建下一代AI智能体带来了四大核心优势:
**1. 深度上下文感知:**智能体能够记住长期的对话历史和用户偏好,让交流像和老朋友聊天一样自然流畅。
**2. 高度个性化:**通过不断学习和构建关于用户的“实体-关系-社群”模型,智能体可以提供真正量身定制的服务和建议。
**3. 强大的推理能力:**面对需要整合多方面信息才能回答的复杂问题,智能体可以通过其结构化的记忆网络进行推理,找到答案。
**4. 较高的检索效率:**从原始数据到抽象摘要的逐级提炼,使得信息检索过程从“大海捞针”变成了“按图索骥”,响应速度和资源消耗都得到了巨大优化。
结论
我们正处在AI智能体从“有用的工具”向“可靠的伙伴”转变的关键节点。而一个强大、持久、且能够不断演进的记忆系统,正是实现这一飞跃的核心。图中所展示的这种类人记忆架构,通过模仿人类从具体情节到抽象概念的认知过程,为我们提供了一个值得探索的思路。
学习大模型 AI 如何助力提升市场竞争优势?
随着新技术的不断涌现,特别是在人工智能领域,大模型的应用正逐渐成为提高社会生产效率的关键因素。这些先进的技术工具不仅优化了工作流程,还极大地提升了工作效率。然而,对于个人而言,掌握这些新技术的时间差异将直接影响到他们的竞争优势。正如在计算机、互联网和移动互联网的早期阶段所展现的那样,那些最先掌握新技术的人往往能够在职场中占据先机。
掌握 AI 大模型技能,不仅能够提高个人工作效率,还能增强在求职市场上的竞争力。在当今快速发展的技术时代,大模型 AI 已成为推动市场竞争力的重要力量。个人和企业必须迅速适应这一变化,以便在市场中保持领先地位。
如何学习大模型 AI ?
在我超过十年的互联网企业工作经验中,我有幸指导了许多同行和后辈,并帮助他们实现个人成长和学习进步。我深刻认识到,分享经验和知识对于推动整个行业的发展至关重要。因此,尽管工作繁忙,我仍然致力于整理和分享各种有价值的AI大模型资料,包括AI大模型入门学习思维导图、精选学习书籍手册、视频教程以及实战学习等内容。通过这些免费的资源,我希望能够帮助更多的互联网行业朋友获取正确的学习资料,进而提升大家的技能和竞争力。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、初阶应用:建立AI基础认知
在第一阶段(10天),重点是对大模型 AI 的基本概念和功能进行深入了解。这将帮助您在相关讨论中发表高级、独特的见解,而不仅仅是跟随他人。您将学习如何调教 AI,以及如何将大模型与业务相结合。
主要学习内容:
- 大模型AI的功能与应用场景:探索AI在各个领域的实际应用
- AI智能的起源与进化:深入了解AI如何获得并提升其智能水平
- AI的核心原理与心法:掌握AI技术的核心概念和关键原理
- 大模型应用的业务与技术架构:学习如何将大模型AI应用于业务场景和技术架构中
- 代码实践:向GPT-3.5注入新知识的示例代码
- 提示工程的重要性与核心思想:理解提示工程在AI应用中的关键作用
- Prompt的构建与指令调优方法:学习如何构建有效的Prompt和进行指令调优
- 思维链与思维树的应用:掌握思维链和思维树在AI推理和决策中的作用
- Prompt攻击与防范策略:了解Prompt攻击的类型和如何进行有效的防范


、、、
二、中阶应用:深入AI实战开发
在第二阶段(30天),您将进入大模型 AI 的进阶实战学习。这将帮助您构建私有知识库,扩展 AI 的能力,并快速开发基于 agent 的对话机器人。适合 Python 和 JavaScript 程序员。
主要学习内容:
- RAG的重要性:理解RAG在AI应用中的关键作用
- 构建基础ChatPDF:动手搭建一个简单的ChatPDF应用
- 检索基础:掌握信息检索的基本概念和原理
- 理解向量表示:深入探讨Embeddings的原理和应用
- 向量数据库与检索技术:学习如何使用向量数据库进行高效检索
- 基于 vector 的 RAG 实现:掌握基于向量的RAG构建方法
- RAG系统的高级扩展:探索RAG系统的进阶知识和技巧
- 混合检索与RAG-Fusion:了解混合检索和RAG-Fusion的概念和应用
- 向量模型的本地部署策略:学习如何在本地环境中部署向量模型

三、高阶应用:模型训练
在这个阶段,你将掌握模型训练的核心技术,能够独立训练和优化大模型AI。你将了解模型训练的基本概念、技术和方法,并能够进行实际操作。
- 模型训练的意义:理解为什么需要进行模型训练。
- 模型训练的基本概念:学习模型训练的基本术语和概念。
- 求解器与损失函数:了解求解器和损失函数在模型训练中的作用。
- 神经网络训练实践:通过实验学习如何手写一个简单的神经网络并进行训练。
- 训练与微调:掌握训练、预训练、微调和轻量化微调的概念和应用。
- Transformer结构:了解Transformer的结构和原理。
- 轻量化微调:学习如何进行轻量化微调以优化模型性能。
- 实验数据集构建:掌握如何构建和准备实验数据集。

四、专家应用:AI商业应用与创业
在这个阶段,你将了解全球大模型的性能、吞吐量和成本等方面的知识,能够在云端和本地等多种环境下部署大模型。你将找到适合自己的项目或创业方向,成为一名被AI武装的产品经理。
- 硬件选型:学习如何选择合适的硬件来部署和运行大模型AI。
- 全球大模型概览:了解全球大模型的发展趋势和主要玩家。
- 国产大模型服务:探索国产大模型服务的优势和特点。
- OpenAI代理搭建:学习如何搭建OpenAI代理以扩展AI的功能和应用范围。
- 热身练习:在阿里云 PAI 上部署 Stable Diffusion
- 本地化部署:在个人计算机上运行大型模型
- 私有化部署策略:大型模型的内部部署方法
- 利用 vLLM 进行模型部署:高效部署大型模型的技术
- 案例分析:如何在阿里云上优雅地私有部署开源大型模型
- 开源 LLM 项目的全面部署:从零开始部署开源大型语言模型
- 内容安全与合规:确保AI应用的内容安全和合规性
- 算法备案流程:互联网信息服务算法的备案指南
通过这些学习内容,您不仅能够掌握大模型 AI 的基本技能,还能够深入理解其高级应用,从而在市场竞争中占据优势。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你无疑是AI领域的佼佼者。然而,即使你只能完成60-70%的内容,你也已经展现出了成为一名大模型AI大师的潜力。
最后,本文提供的完整版大模型 AI 学习资料已上传至 CSDN,您可以通过微信扫描下方的 CSDN 官方认证二维码免费领取【保证100%免费】。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 41
41 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)