【工具】DINOv3:Meta AI的突破性自监督视觉模型(模型获取、推理)
DINOv3(Distillation with No Labels v3)是一个最先进的自监督视觉变换器(Vision Transformer,ViT),能够在没有任何人工标注的情况下学习视觉表示。作为Meta AI开发的自监督视觉基础模型,DINOv3显著扩展了早期DINO/DINOv2方法,将模型规模扩大到约67亿参数,训练数据规模扩大到精选的17亿张图像。
1.什么是DINOv3?
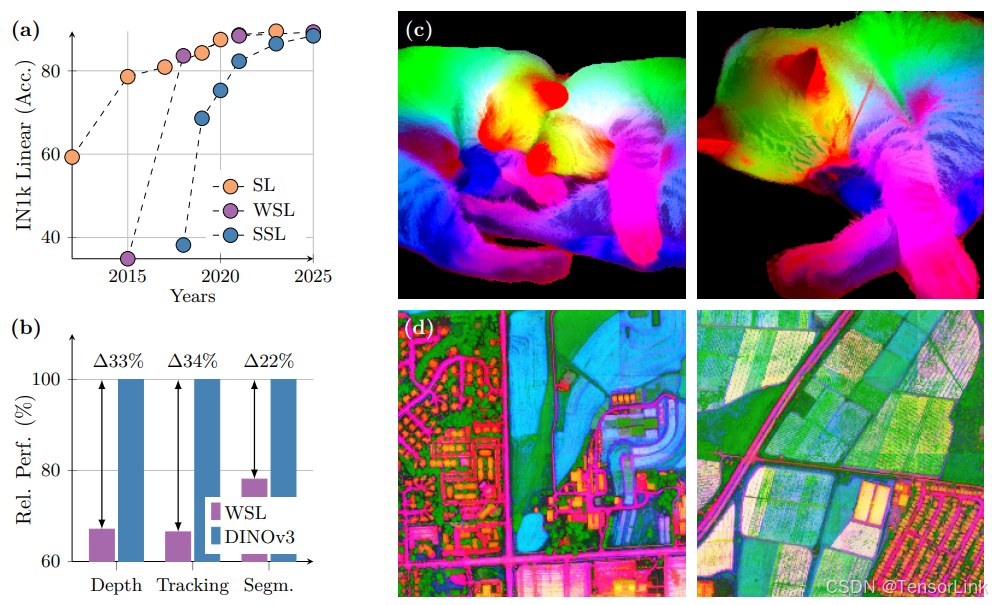
DINOv3(Distillation with No Labels v3)是一个最先进的自监督视觉变换器(Vision Transformer,ViT),能够在没有任何人工标注的情况下学习视觉表示。作为Meta AI开发的自监督视觉基础模型,DINOv3显著扩展了早期DINO/DINOv2方法,将模型规模扩大到约67亿参数,训练数据规模扩大到精选的17亿张图像。
-
Website: https://ai.meta.com/dinov3/
2.模型权重获取和测试
2.1 模型权重
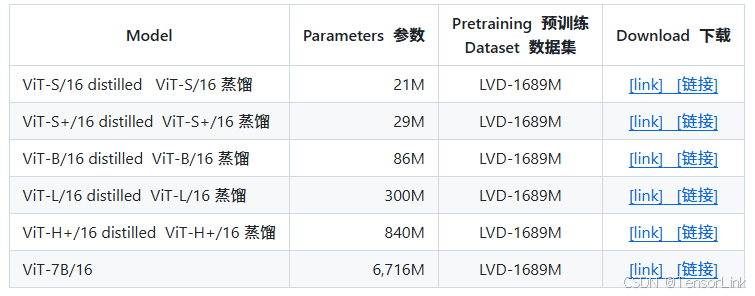
(1). 在 web 数据集上预训练的 ViT 模型(LVD-1689M):
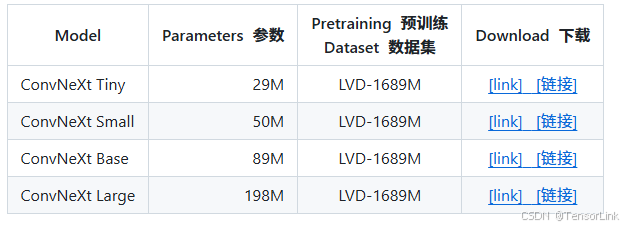
(2). 在 web 数据集(LVD-1689M)上预训练的 ConvNeXt 模型:
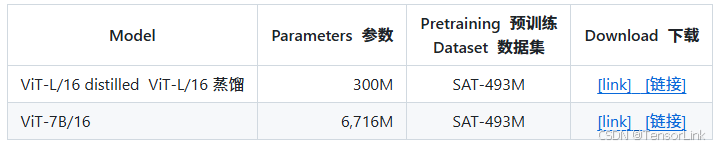
(3). 在卫星数据集(SAT-493M)上预训练的 ViT 模型:
2.2 权重加载
官网提供了两种 Pretrained backbones(via PyTorch Hub 和 Pretrained backbones (via Hugging Face Transformers)),迫于某些局限性,某些模型权重可能无法下载成功,在文章末尾提供了资源包,希望可以帮到共同学习的小伙伴。
2.2.1 PyTorch Hub
- 官网提供了如下代码用于模型的加载:
import torch
REPO_DIR = <PATH/TO/A/LOCAL/DIRECTORY/WHERE/THE/DINOV3/REPO/WAS/CLONED>
# DINOv3 ViT models pretrained on web images
dinov3_vits16 = torch.hub.load(REPO_DIR, 'dinov3_vits16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vits16plus = torch.hub.load(REPO_DIR, 'dinov3_vits16plus', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vitb16 = torch.hub.load(REPO_DIR, 'dinov3_vitb16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vitl16 = torch.hub.load(REPO_DIR, 'dinov3_vitl16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vith16plus = torch.hub.load(REPO_DIR, 'dinov3_vith16plus', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vit7b16 = torch.hub.load(REPO_DIR, 'dinov3_vit7b16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
# DINOv3 ConvNeXt models pretrained on web images
dinov3_convnext_tiny = torch.hub.load(REPO_DIR, 'dinov3_convnext_tiny', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_small = torch.hub.load(REPO_DIR, 'dinov3_convnext_small', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_base = torch.hub.load(REPO_DIR, 'dinov3_convnext_base', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_convnext_large = torch.hub.load(REPO_DIR, 'dinov3_convnext_large', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
# DINOv3 ViT models pretrained on satellite imagery
dinov3_vitl16 = torch.hub.load(REPO_DIR, 'dinov3_vitl16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
dinov3_vit7b16 = torch.hub.load(REPO_DIR, 'dinov3_vit7b16', source='local', weights=<CHECKPOINT/URL/OR/PATH>)
(1). 通过 git clone克隆项目到本地。
(2). 下载保存权重到对应的目录。
import torch
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_image
REPO_DIR = "project/dinov3"
dinov3_vitb16 = torch.hub.load(REPO_DIR, 'dinov3_vitb16', source='local', weights="dinov3_vitb16_pretrain_lvd1689m-73cec8be.pth")
(3). 执行代码测试,出现下面的进度条说明加载成功:

2.2.2 Hugging Face Transformers
- 与上面的方式类似,不过需要去Hugging Face 上面下载对应的模型信息,同样的,文章末尾也为需要的小伙伴准备了相应的资源 Wink~
import torch
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = load_image(url)
pretrained_model_name = "facebook/dinov3-convnext-tiny-pretrain-lvd1689m"
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(
pretrained_model_name,
device_map="auto",
)
inputs = processor(images=image, return_tensors="pt").to(model.device)
with torch.inference_mode():
outputs = model(**inputs)
pooled_output = outputs.pooler_output
print("Pooled output shape:", pooled_output.shape)
(1). 通过 git clone克隆项目到本地。
(2). 下载保存权重到对应的目录。
(3). 执行代码测试,其中 model 和 pretrained_model_name 可以是以下之一:
facebook/dinov3-vits16-pretrain-lvd1689mfacebook/dinov3-vits16plus-pretrain-lvd1689mfacebook/dinov3-vitb16-pretrain-lvd1689mfacebook/dinov3-vitl16-pretrain-lvd1689mfacebook/dinov3-vith16plus-pretrain-lvd1689mfacebook/dinov3-vit7b16-pretrain-lvd1689mfacebook/dinov3-convnext-base-pretrain-lvd1689mfacebook/dinov3-convnext-large-pretrain-lvd1689mfacebook/dinov3-convnext-small-pretrain-lvd1689mfacebook/dinov3-convnext-tiny-pretrain-lvd1689mfacebook/dinov3-vitl16-pretrain-sat493mfacebook/dinov3-vit7b16-pretrain-sat493m
2.3 图像变换
- 对于使用 LVD-1689M 权重(在网页图像上预训练)的模型,请使用以下转换(标准的 ImageNet 评估转换):
import torchvision
def make_transform(resize_size: int = 224):
to_tensor = transforms.ToTensor()
resize = transforms.Resize((resize_size, resize_size), antialias=True)
normalize = transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
)
return transforms.Compose([to_tensor, resize, normalize])
- 对于使用 SAT-493M 权重(在卫星图像上预训练)的模型,请使用以下转换:
import torchvision
def make_transform(resize_size: int = 224):
to_tensor = transforms.ToTensor()
resize = transforms.Resize((resize_size, resize_size), antialias=True)
normalize = transforms.Normalize(
mean=(0.430, 0.411, 0.296),
std=(0.213, 0.156, 0.143),
)
return transforms.Compose([to_tensor, resize, normalize])
3.下游任务拓展
3.1 图像分类(Image classification)

- 提供全模型(backbone + linear head)权重,分类器模型可以通过 PyTorch Hub 加载:
import torch
# DINOv3
dinov3_vit7b16_lc = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_lc', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
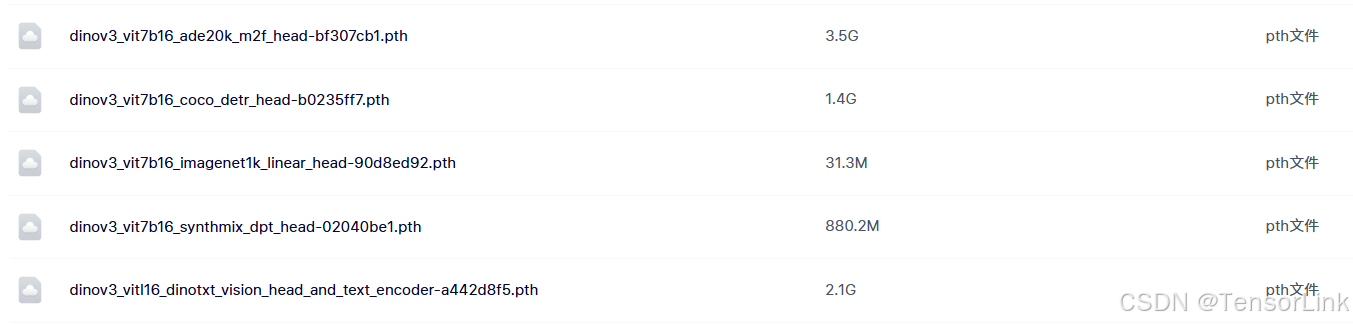
3.2 在 SYNTHMIX 数据集上深度训练

- 提供全模型(backbone + linear head)权重:
depther = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_dd', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
- 图像深度上的完整示例代码:
from PIL import Image
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from matplotlib import colormaps
def get_img():
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
return image
def make_transform(resize_size: int | list[int] = 768):
to_tensor = transforms.ToTensor()
resize = transforms.Resize((resize_size, resize_size), antialias=True)
normalize = transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
)
return transforms.Compose([to_tensor, resize, normalize])
depther = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_dd', source="local", weights=<DEPTHER/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
img_size = 1024
img = get_img()
transform = make_transform(img_size)
with torch.inference_mode():
with torch.autocast('cuda', dtype=torch.bfloat16):
batch_img = transform(img)[None]
batch_img = batch_img
depths = depther(batch_img)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.axis("off")
plt.subplot(122)
plt.imshow(depths[0,0].cpu(), cmap=colormaps["Spectral"])
plt.axis("off")
3.3 在 COCO2017 数据集上训练的检测器

detector = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_de', source="local", weights=<DETECTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
3.4 在 ADE20K 数据集上训练的分割器

segmentor = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_ms', source="local", weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
- 图像上分割的完整示例代码:
import sys
sys.path.append(REPO_DIR)
from PIL import Image
import torch
from torchvision import transforms
import matplotlib.pyplot as plt
from matplotlib import colormaps
from functools import partial
from dinov3.eval.segmentation.inference import make_inference
def get_img():
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
return image
def make_transform(resize_size: int | list[int] = 768):
to_tensor = transforms.ToTensor()
resize = transforms.Resize((resize_size, resize_size), antialias=True)
normalize = transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
)
return transforms.Compose([to_tensor, resize, normalize])
segmentor = torch.hub.load(REPO_DIR, 'dinov3_vit7b16_ms', source="local", weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
img_size = 896
img = get_img()
transform = make_transform(img_size)
with torch.inference_mode():
with torch.autocast('cuda', dtype=torch.bfloat16):
batch_img = transform(img)[None]
pred_vit7b = segmentor(batch_img) # raw predictions
# actual segmentation map
segmentation_map_vit7b = make_inference(
batch_img,
segmentor,
inference_mode="slide",
decoder_head_type="m2f",
rescale_to=(img.size[-1], img.size[-2]),
n_output_channels=150,
crop_size=(img_size, img_size),
stride=(img_size, img_size),
output_activation=partial(torch.nn.functional.softmax, dim=1),
).argmax(dim=1, keepdim=True)
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.axis("off")
plt.subplot(122)
plt.imshow(segmentation_map_vit7b[0,0].cpu(), cmap=colormaps["Spectral"])
plt.axis("off")
3.5 dino.txt 零样本任务

import torch
# DINOv3
dinov3_vitl16_dinotxt_tet1280d20h24l, tokenizer = torch.hub.load(REPO_DIR, 'dinov3_vitl16_dinotxt_tet1280d20h24l', weights=<SEGMENTOR/CHECKPOINT/URL/OR/PATH>, backbone_weights=<BACKBONE/CHECKPOINT/URL/OR/PATH>)
4.线上运行
官网也提供了几种 jupyter 的方式,不过也是需要下载对应的模型权重进行执行,可以在本地搭建好环境之后修改路径进行测试。

5.权重资源

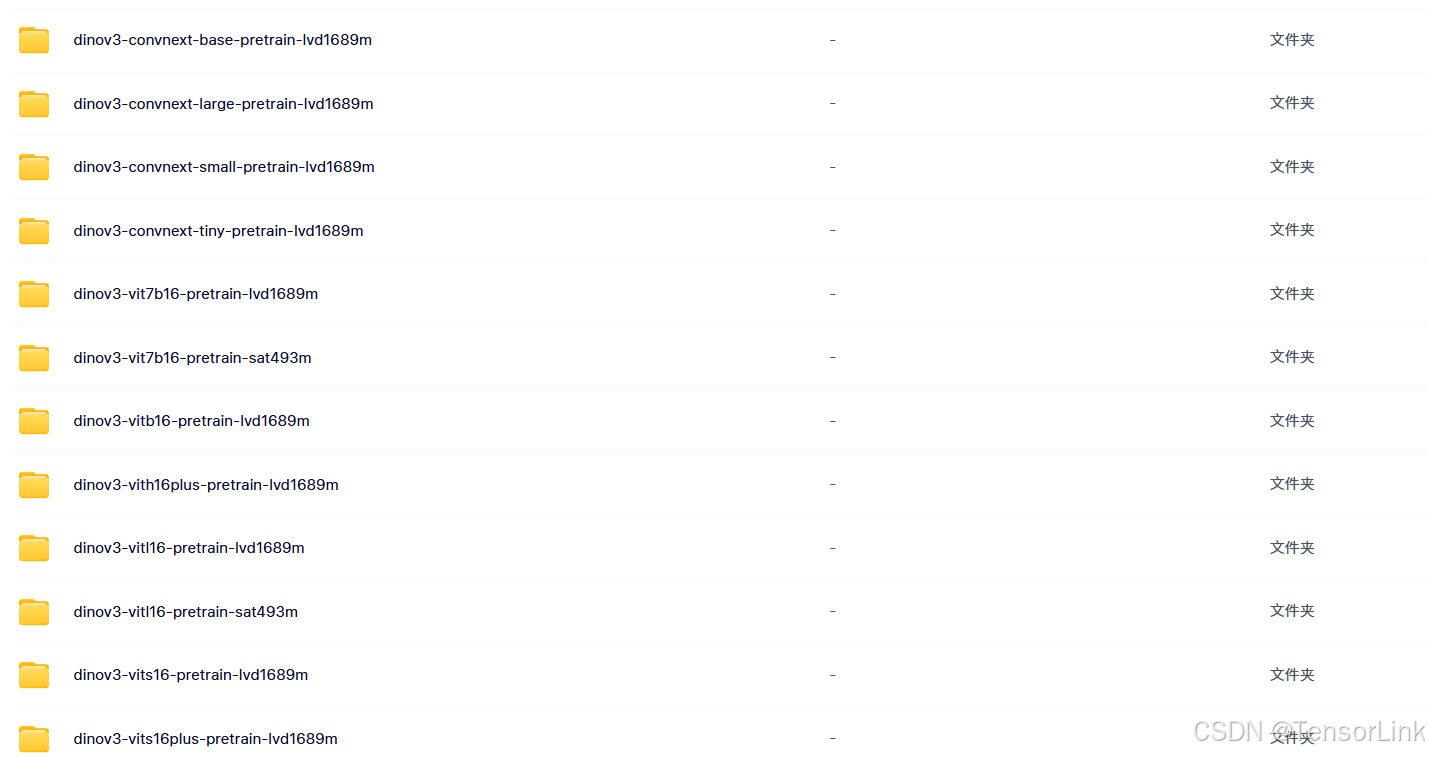
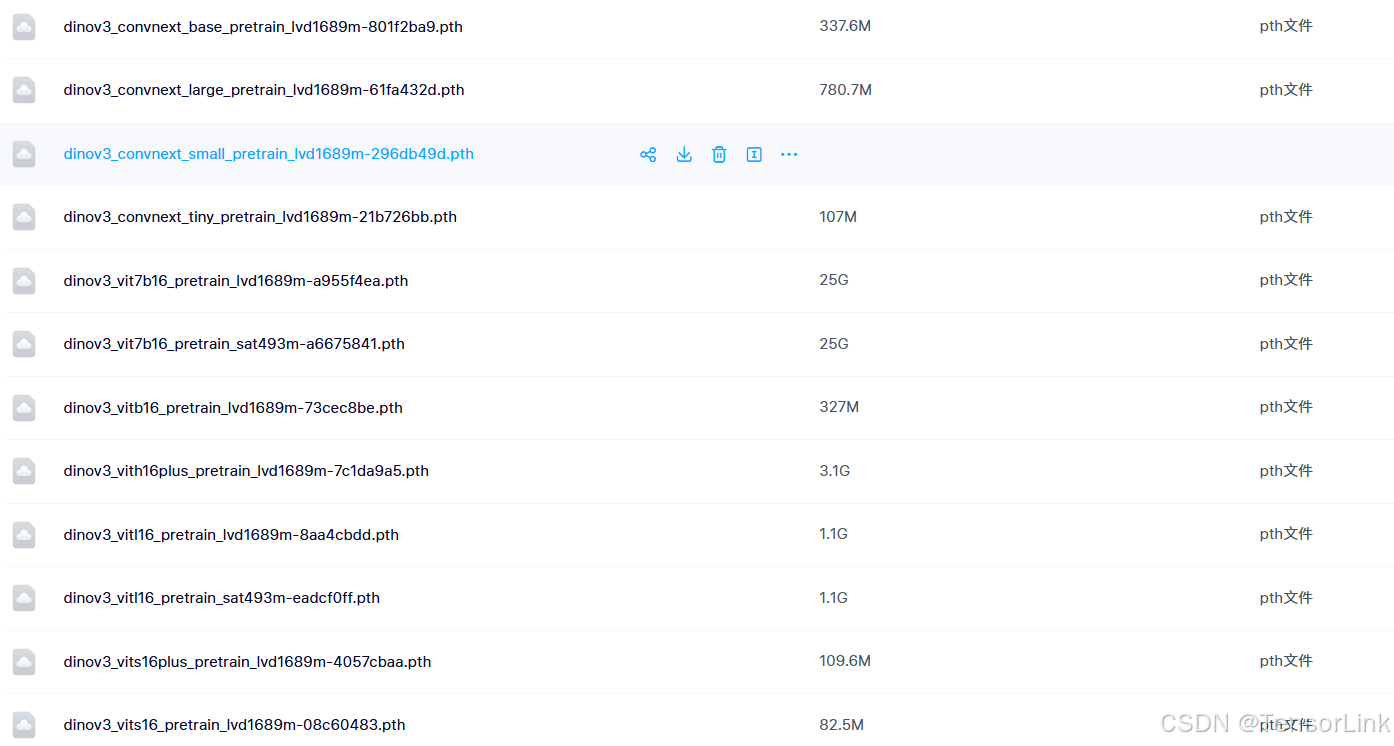
关注公众号【TensorLink】回复 DINOv3 即可获取所有权重信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)