2025年 MoE 架构再次崛起:为什么你看到的每个“超大模型”,都在偷偷用专家网络?
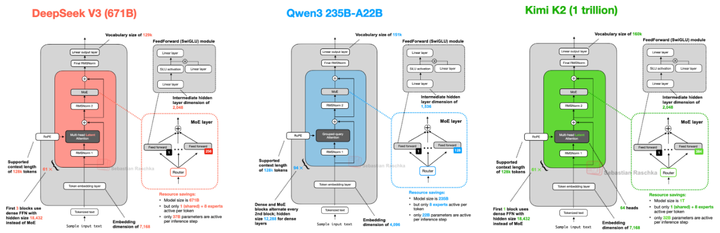
近几年,随着大型语言模型(LLM)朝着更高性能、更大规模扩展,Mixture‑of‑Experts(MoE)架构正从理论验证走向主流部署,成为构筑高效超大模型的重要支撑点(如下图)。MoE。
0. 当主流 LLM中MoE 已成核心力量
近几年,随着大型语言模型(LLM)朝着更高性能、更大规模扩展,Mixture‑of‑Experts(MoE)架构正从理论验证走向主流部署,成为构筑高效超大模型的重要支撑点(如下图)。
MoE
为什么说 MoE 是当前 LLM 架构革新的核心?
-
性能与效率并行。以 DeepSeek‑V3 为例,它采用 MoE 架构实现了 6710 亿参数的惊人规模,却通过每个 token 仅激活 256 个专家(加上一个共享专家),保持了极低的推理与训练成本arXiv。在实际评测中,其综合性能已接近闭源模型如 GPT‑4o 和 Claude 3.5,同时训练时间仅为传统模型的零头,也在性能/成本比上领先维基。
-
逐步成为多方看重的核心架构。无论是在技术社区还是产业链中,MoE 正逐步被多个团队视为突破模型扩展瓶颈的“秘密武器”。
-
主流模型中崛起的重要趋势。尽管像 GPT 和 LLaMA 系列最初使用的是密集 Transformer 架构,但随着硬件成本和性能压力增大,MoE 正被越来越多的开源与闭源团队积极探索。例如开源的 Mixtral 模型基于 Mistral-7B 构建 MoE 系统;Meta 的 LLaMA 4(代号“Scout” 或 “Maverick”)据传亦可能集成多模态专家结构;而 DeepSeek、DBRX 等新一代模型则将 MoE 作为核心设计,从开源到闭源都有接纳该路径的趋势。
1. MoE概念起源与基本原理
Mixture-of-Experts(MoE)的提出。 MoE是一种机遇性组合模型策略,其核心思想是使用多个“专家”模型共同完成学习任务,并由一个门控网络(gating network)根据输入特征选择适当的专家来产生输出giete。这一思想最早可追溯至1991年Jacobs等人提出的“局部专家自适应混合”模型Toronto。他们在论文中展示了一种监督学习方法:由多个独立的网络组成,每个专家网络负责训练数据的一个子集(针对特定子任务)。门控网络根据输入样本的特征决定启用哪一个专家或多个专家共同作用,从而将不同的输入子空间划分给最擅长该区域的专家处理。这种“分而治之”的结构可以减少不同子任务之间的相互干扰,使每个专家专注于其擅长的领域giete.ma。在Jacobs等人的原始设计中,门控网络输出一个softmax权重向量,对所有专家的输出进行加权求和作为最终预测,因此是一种软选择机制(soft routing),并未对专家实施硬性选择限制。这一模型在语音元音辨识等任务上验证了其可行性,通过将复杂任务划分为若干易于学习的子任务,每个子任务由特定专家解决,从而提升整体性能。
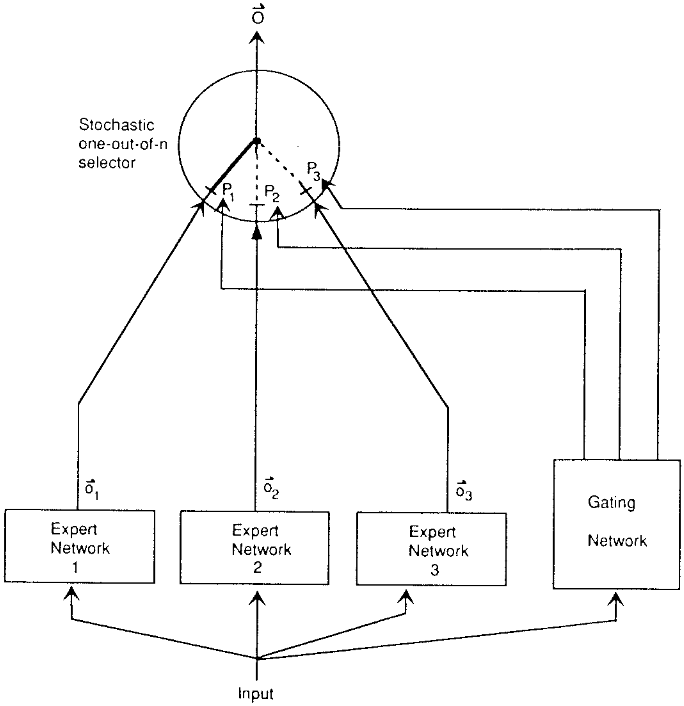
Original MoE
分层MoE与理论基础。 1993年,Jordan和Jacobs进一步扩展了MoE架构,引入了分层混合专家(Hierarchical MoE)的概念Toronto。在分层MoE中,多个专家可以按层次结构组成树状网络,顶层由一个门控网络根据输入先选择某个子树(子任务范围),再由该子树内部的次级门控网络选择具体的专家。这种层次化结构等价于在不同粒度上对输入进行路由,将原本单层门控扩展为多级决策,从而提高模型对复杂任务的表达能力。Jordan等人的工作表明,将门控网络置于树的根节点并允许各子节点拥有各自的门控和专家,可以实现更灵活的专家组合,有效地模拟更加复杂的决策过程。Jacobs和Jordan的两篇开创性论文奠定了MoE架构的基础:即通过门控机制动态选择模型的一部分(专家网络)来对输入做出响应,从而将整个网络划分为若干具有专长的子网络协同工作giete.ma。这一思想在上世纪90年代被提出时,曾被视作集合学习(Ensemble learning)的一种形式wiki,但由于当时计算资源和训练手段的限制,MoE并未得到大规模应用。总体而言,MoE的基本原理在于用一个轻量级的路由函数(门控网络)将输入映射到多个专家中的一个或少数几个,使不同专家各司其职、互不干扰地学习各自的数据子分布,然后将它们的输出按一定权重合并为最终结果。
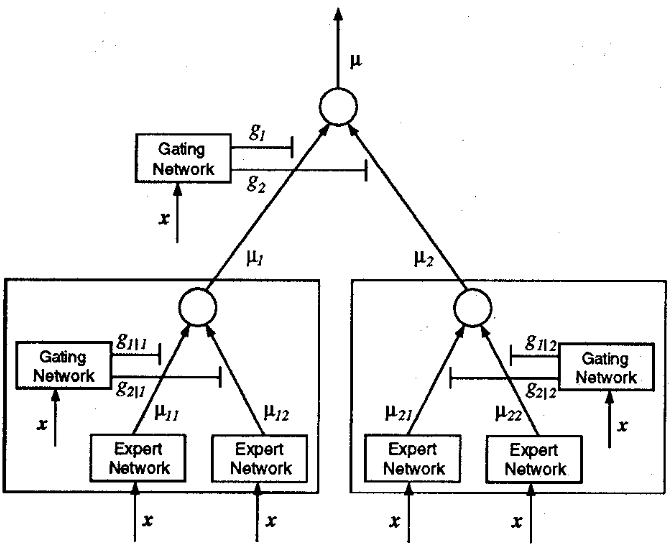
Hierarchical MoE
2. 大型语言模型中MoE的作用与优势
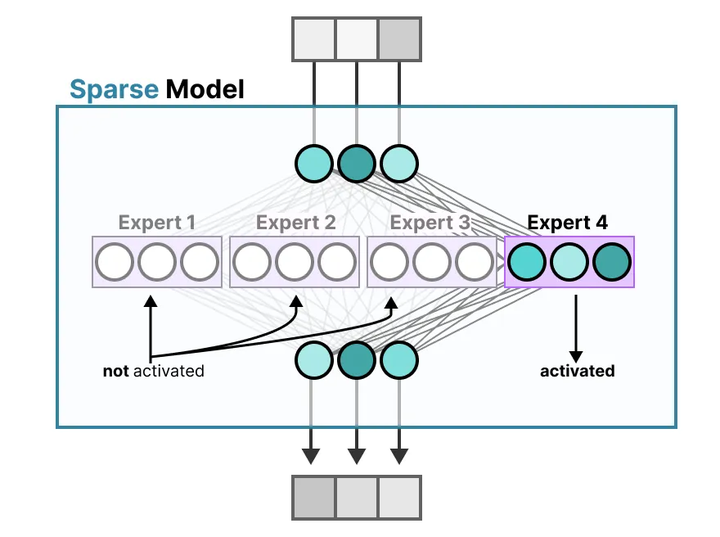
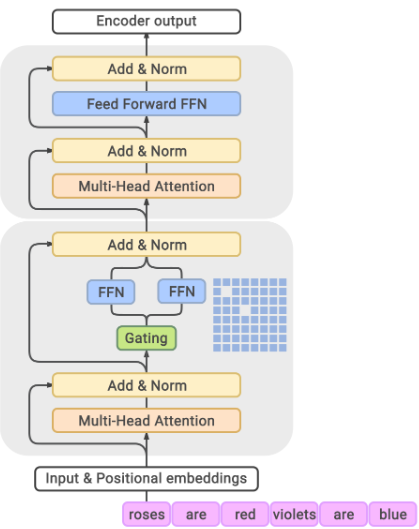
提升参数规模而计算成本可控。 在大型语言模型(LLM)的训练和推理中,MoE机制展现出了独特优势。传统的密集模型(dense model)对每个输入都激活模型中的全部参数,参数规模与计算开销呈线性相关。而MoE采用稀疏激活策略(稀疏模型,Sparse Model):每个输入仅激活模型中一小部分专家参数,由此使模型总参数量可以远大于实际每次计算所用的参数(参考下图)。
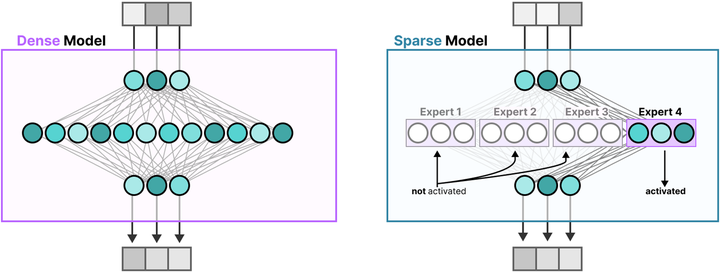
Dense model and Sparse Model
这一特性实现了模型容量与计算成本的解耦——增加专家数量可以大幅提高模型容量和潜在性能,但由于每次仅调用少数专家(如下图),推理和训练的计算开销增长有限arxiv。例如,有文献指出相比同等参数规模的稠密模型,MoE模型在训练和推理时所需的计算量显著降低,因为每个token只会激活少量专家,而非所有参数medium。
MoE
这种参数高效性使得MoE模型能够在保持计算预算接近恒定的情况下扩展至数十亿甚至万亿级参数,从而提升模型性能(如降低困惑度或提高下游任务精度)arxiv。简而言之,MoE允许在不等比例增加计算成本的情况下堆叠更多参数,突破了密集Transformer架构按算力缩放的瓶颈(例如,DeepSpeed-MoE的结果如下,arxiv)。
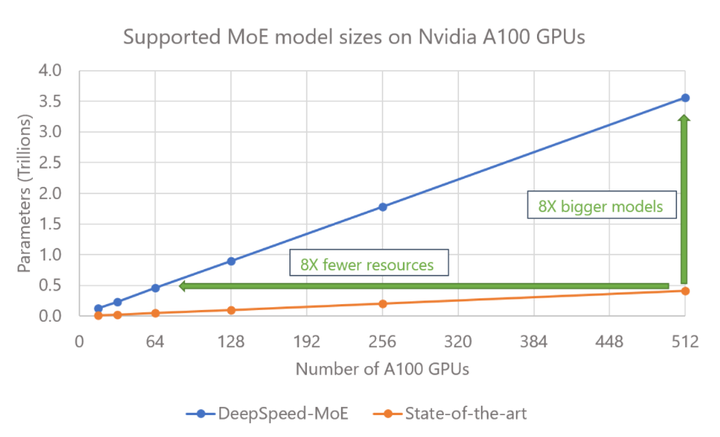
DeepSpeed-MoE
专家特化带来的性能提升。 除了计算效率,MoE通过专家网络的“特化”还能带来模型质量上的提升。由于每个专家只见到某类特定模式的输入,因而学习到更加精细的特征表示medium。大型语言模型往往需要处理多样化的语言现象和任务,MoE通过赋予不同专家各自的“知识领域”,可以让模型同时拥有擅长不同任务或知识领域的模块(如下图,MG)。
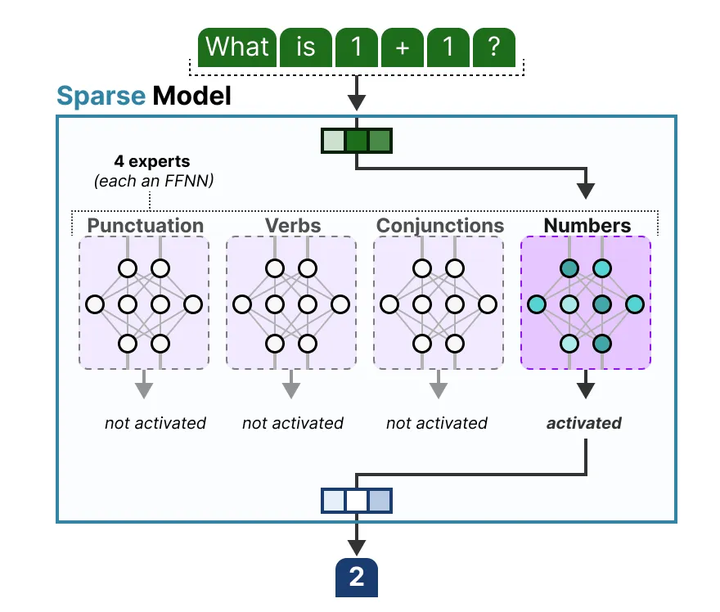
MoE Expert Specialization
这种按需激活的架构提高了模型的泛化性和鲁棒性:当输入改变时,门控网络动态选择最适合的专家来处理,从而使模型能够灵活应对不同类型的问题。研究表明,与将所有知识混杂在单一模型中的方式相比,MoE模型因为专家功能各异,能减少不同任务间的冲突,提升特定任务的表现。例如,有报告总结出MoE的几项关键优势包括:参数效率(例如,下图所示,arxiv)、任务性能提升(在多任务场景下利用专家提高各任务精度)、高效可扩展性(通过增加专家扩展模型能力)等。此外,MoE模型在大规模、多样性数据(如多语言、多模态数据)上表现出处理复杂知识的优势。总的来说,在LLM中引入MoE,可以在保证或提升性能的同时,通过稀疏计算显著降低单次推理计算量,这使得构建超大规模模型成为可能medium。
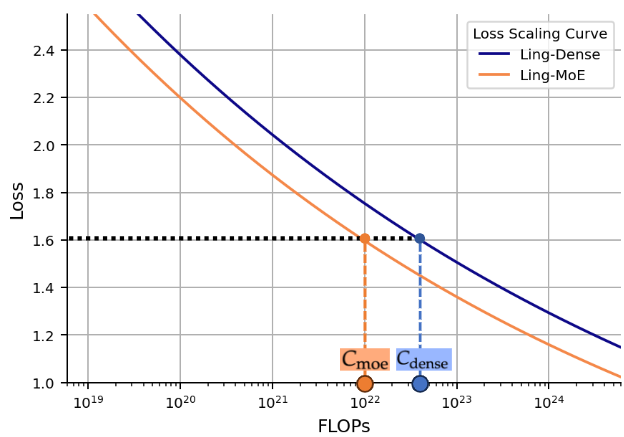
Loss Scaling Curve
稀疏激活对训练的影响。 需要注意的是,MoE的稀疏激活特性也改变了模型的训练动态。每个训练样本只更新所选中的少数专家和门控网络的参数,其余大部分专家在该样本上传递的梯度为零medium。这意味着,训练过程中不同专家将逐渐对不同类型的数据更敏感,形成专家分工。随着训练进行,路由器(门控网络)会学习将相似的token发送给同一专家,促进专家对特定模式的专精。只被选中的专家得到梯度更新,而未选中的专家在该次更新中权重保持不变。
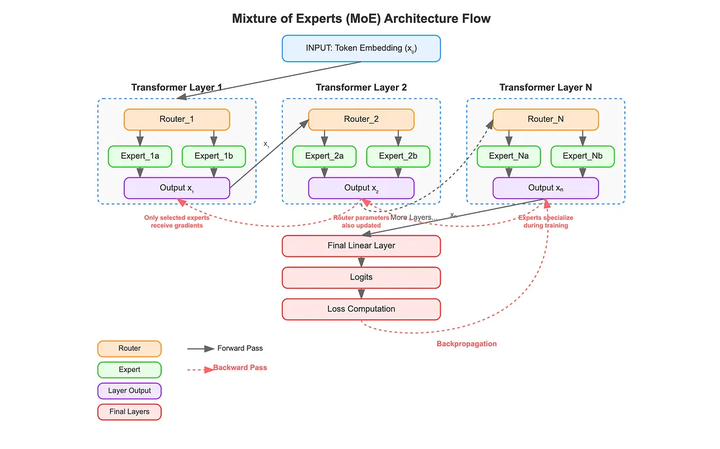
Layer-wise MoE Transformer Architecture: Routing and Gradient Flow
这一过程通过梯度的局部化(如上图),实现了专家的自主专精:各专家网络彼此的梯度更新解耦,不会互相干扰,从而在高维参数空间中发展出不同的能力。不过,这种训练方式也带来了专家利用不均衡的问题,需要通过特别的策略(如负载均衡损失、随机路由等)来避免某些专家长期未被训练或过度饱和。总体而言,稀疏激活机制赋予了LLM更高的表示灵活性和计算效率,这是MoE在大型语言模型中受到广泛关注的主要原因之一。
3. MoE机制的发展历程:从简单门控到动态路由
早期探索与停滞。 MoE的基本理念在上世纪90年代初被提出后,曾作为一种新颖的神经网络架构引起关注。然而受限于当时的计算条件和神经网络规模,MoE一度停留在相对小规模的实验阶段。早期的MoE模型多用于较小型的任务(如语音分类、字符识别等),虽然验证了门控+专家的可行性,但在更大规模和更复杂的数据集上尚未显现出显著优势。进入21世纪后,随着神经网络(尤其是深度学习)的蓬勃发展,研究者们逐渐意识到MoE的潜力:通过条件计算(Conditional Computation)可以突破单一模型处理多样数据的瓶颈arxiv。然而直到2010年代中期,MoE的应用仍然局限,主要原因之一是缺乏可扩展的训练机制和高效的路由算法来避免专家的不均衡利用。这一状况在2017年发生了转折(如下图为MoE在2017年后的演变)。
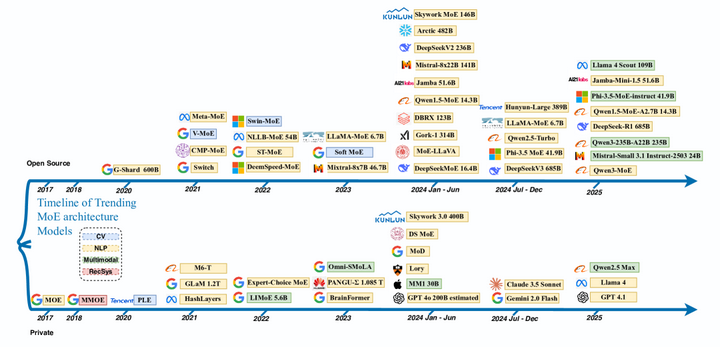
Timeline of mixture of experts (MoE) models development
2017年:大规模稀疏MoE的突破。 2017年,Google Brain团队的Noam Shazeer等人发表了里程碑式的论文“Outrageously Large Neural Networks: The Sparsely-Gated MoE Layer”(arxiv),首次将MoE成功应用于大规模神经网络并取得优异性能。Shazeer等人解决了前述的两个关键问题:(1) 可扩展路由:提出了Top-K门控策略,使每个输入token只激活K个得分最高的专家(通常K=1或2),大幅减少了每次前向计算的专家参与数(如下图);
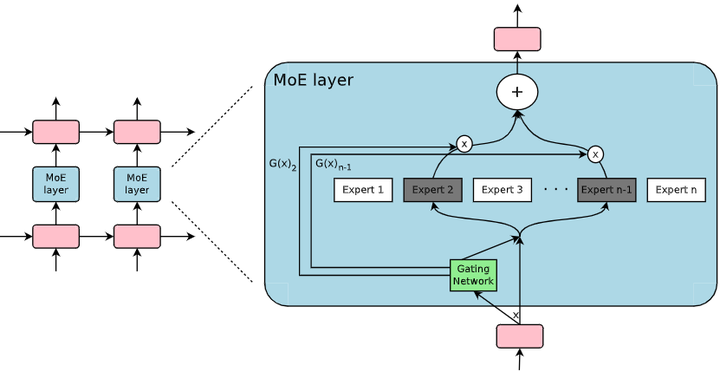
A Mixture of Experts (MoE) layer embedded within a recurrent language mode
(2) 避免专家塌陷:引入Noisy Gating机制(公式如下),在门控网络的得分中加入适度的随机噪声,以打破训练中胜出专家“赢者通吃”的局面,增加不同专家被选中的概率,从而防止模型收敛到只使用少数专家的退化解。

Noisy Top-K Gating
此外,该论文还借鉴了之前Bengio等人在2015年的工作,增加了负载均衡损失(Load Balancing Loss)作为训练的辅助目标(arxiv)。具体做法是衡量每个专家在一个批次中被使用的总权重,让模型最小化各专家使用频率的不均衡程度(通过最小化专家重要性向量的变异系数)。这一额外损失鼓励所有专家的利用率趋于均衡,从而缓解“专家饥饿”问题(即部分专家几乎不被选用)。
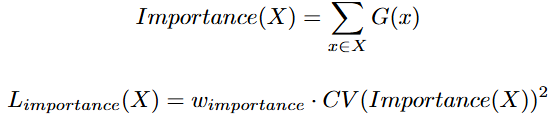
Load Balancing Loss
通过Top-K稀疏激活 + 噪声扰动 + 平衡正则等策略的结合,Shazeer等人为大规模MoE的训练提供了可行方案,使他们在2017年的实验中成功训练了一个1370亿参数的稀疏Transformer模型。这项工作证明:在保持模型性能接近全参数模型的同时,仅激活一小部分专家即可大幅降低计算成本。
2020年前后:迈向万亿参数。 在Shazeer等人的工作引发关注后,业界和学界迅速投入到MoE的扩展研究中。2020年,Google在GShard(arxiv)项目中推出了一个含6000亿参数的多语言模型,其中利用MoE层实现了自动分片(Auto-Sharding)和token粒度的专家路由,证明了稀疏MoE在万亿级参数规模上的可行性。GShard通过在TensorFlow中实现专家并行(Expert Parallelism)和All-to-All通信,首次展示了稀疏专家架构在工业级别大模型训练中的成功应用(如下图)。
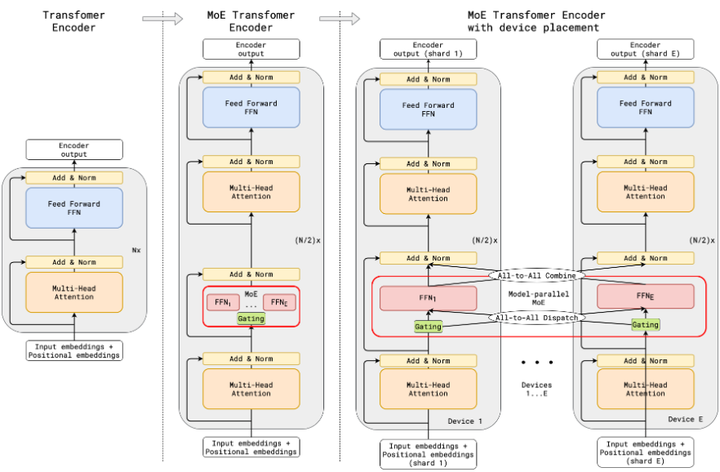
Illustration of scaling of Transformer Encoder with MoE Layers
紧随其后,Google又发布了Switch Transformer和GLaM等模型,将MoE理念应用到自然语言处理的大模型上ar5iv.labs.arxiv.org。Switch Transformer(Fedus et al., 2022,arxiv)采用每层仅激活1个专家(Top-1 gating)的极简路由策略,实现了在参数规模1.6万亿的情况下仍能高效训练和推理(如下图)。
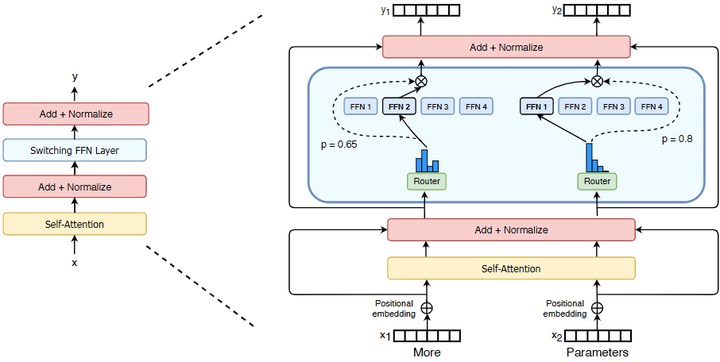
Illustration of a Switch Transformer encoder block
GLaM (Sparse Mixture-of-Experts LM, Du et al., 2022,arxiv) 则使用每层64个专家、激活Top-2专家的设计,模型总参数高达1.2万亿,但每次仅有约8%参数参与计算,以极低的计算成本取得了接近Dense 1.2T模型的性能。这些工作奠定了MoE在LLM中的主流地位:通过稀疏路由,超大参数模型成为可能,而计算代价仍在可控范围内。
GLaM model architecture
2021-2022年:开源实践与多样化应用。 到了2021-2022年,MoE架构从少数实验室的探索逐渐发展为社区广泛尝试的框架。一方面,出现了一系列开源的MoE模型和工具,例如Meta推出的Meta-MoE(在开源框架Fairseq上实现MoE Transformer, github)、微软提出的DeepSpeed-MoE(提供MoE训练与推理的高效并行库, github),以及微软开发的FastMoE/Tutel(一个高性能MoE训练库, github),这些开源项目降低了研究者试验MoE的门槛。另一方面,MoE的思想开始在特定领域的大模型中得到应用:如Facebook AI发布的多语言机器翻译模型NLLB-MoE(将“No Language Left Behind”模型拓展为MoE版本,以支持200种语言的高效翻译,arxiv),计算机视觉领域有谷歌的Vision MoE (V-MoE)模型(在ViT中引入MoE提高图像分类精度,如下图arxiv),以及谷歌的LIMoE(语言-图像混合专家模型,用对比学习训练跨模态专家,arxiv)。
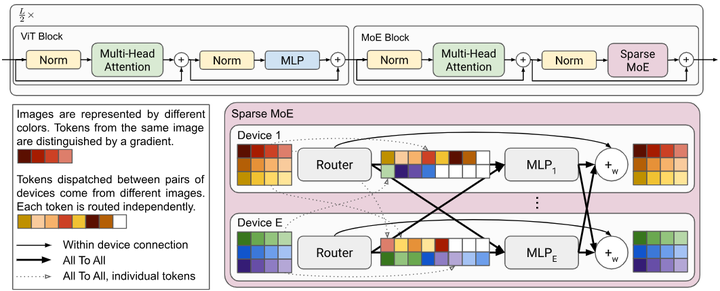
V-MoE
总体来看,2021-2022年标志着MoE从概念验证走向成熟应用:稀疏专家不再局限于NLP单一任务,而是被广泛认为是一种通用的扩展架构,被各大公司和开源社群采用在语言、视觉、多语言、多模态等各类大模型中arxiv。
2023年至今:超大模型和集成趋势。 2023年以后,MoE架构进入了工业界规模部署与架构多样化并行发展的新阶段。例如,发布了DeepSeek系列(DeepSeek-MoE,如下图),迭代推出了DeepSeek-v2 (375亿参数)、DeepSeek-v3 (685亿参数)等具有强化推理能力的MoE模型(arxiv);
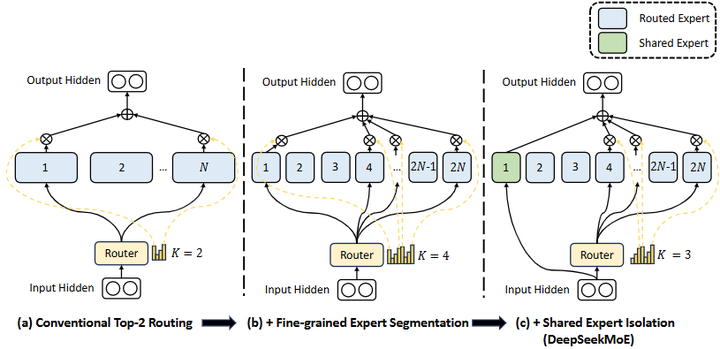
DeepSeek-MoE
阿里巴巴达摩院开源了Qwen系列模型的MoE版本(如Qwen-2-MoE, Qwen-3-MoE等,如下表arxiv),在中文和多语言任务上取得领先性能;

Comparison among Qwen3
Meta公司则在研发LLaMA 4模型时据报道融合了MoE技术,使其成为多模态领域的混合专家模型,被称为“Maverick”架构giete。除了模型规模的突破,MoE正与其它前沿范式相结合来提升模型的综合能力。例如,新一代系统将MoE与检索增强、指令微调和多智能体控制等技术集成在一起,使MoE成为大型AI系统的核心组件之一arxiv。可以预见,在未来的大模型研发中,MoE架构将继续发挥关键作用,不断推动参数规模和模型能力的边界。
4.MoE在LLM中的最新研究进展
近年,关于MoE在大型语言模型中的研究进入了一个百花齐放的局面。2025年及之后公开发布的成果大量涌现,涵盖新模型、新算法和新应用等多个方面。
新型开源MoE大模型。 众多研究团队发布了开源的MoE大型语言模型,为社区提供了宝贵的资源和经验。例如,DeepSeek系列利用MoE提升模型的推理和工具使用能力,其最新版本DeepSeek-v3(包括3.1)参数规模达685亿,并通过MoE实现了较高的性价比(如下表为DeepSeek-v3.1的使用价格,deepseek)。
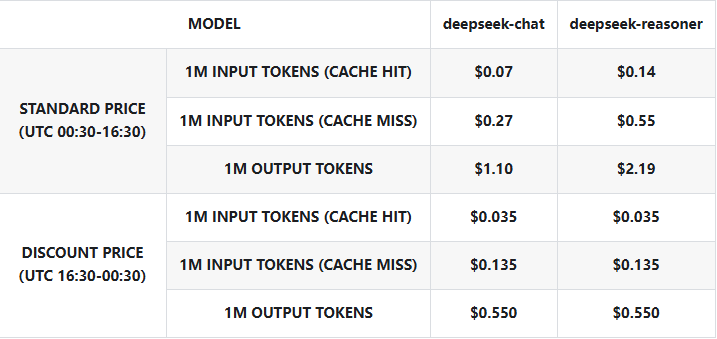
Pricing Details for DeepSeek-v3.1
DeepSeek模型引入了强化学习等机制训练专家,使其在数学推理等任务上表现突出。阿里巴巴达摩院发布了Qwen-MoE系列模型,Qwen团队针对MoE模型提出了量化和专家Dropout等实用优化,使得在不损失精度的情况下大幅降低了推理成本。Meta公司方面,虽然LLaMA系列早期版本未采用MoE,但据2025年的技术报告,“LLaMA 4”代号Maverick的模型将融合多模态能力与MoE机制,实现跨语言和视觉的统一专家路由giete。此外,MLCommons基于开源模型Mistral开发了Mixtral 8×7B模型,它由8个Mistral-7B专家组成,每层对每个token启用2个专家,有效参数约为467亿,但每次推理仅需激活约130亿参数,相当于在13B计算开销下获得近45B规模模型的性能medium。Mixtral的出现证明,将较小的开源模型组合为MoE可以快速扩充模型容量且推理高效。其它如华为诺亚等发布的PanGu-MoE(如下图,arxiv)、清华等的GLM-MoE版本也相继在2024年问世,为中文和多语种任务提供了强大的开源MoE模型(bigmodel)。这些新模型的出现,标志着MoE技术正迅速从实验室走向开源社区,推动大模型生态的繁荣。
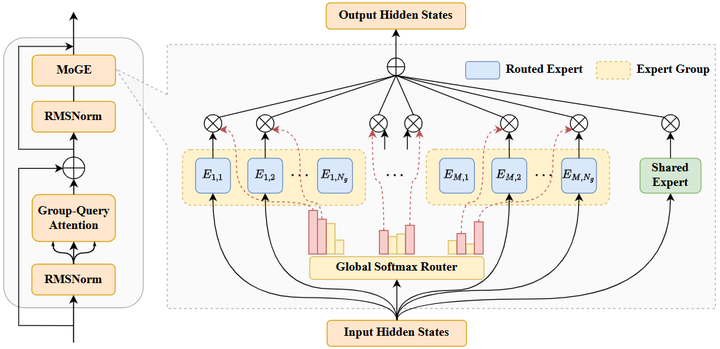
PANGU PRO MOE
MoE模型压缩与优化方法。 随着MoE模型参数量激增,如何压缩和加速MoE模型成为研究热点。多项工作致力于专家级别的模型压缩,以降低存储和计算开销。例如,Huang等人提出“Mixture Compressor”方法(arxiv),针对MoE模型设计专用的压缩策略,在不显著损伤精度的前提下进一步缩减模型尺寸(如下图);
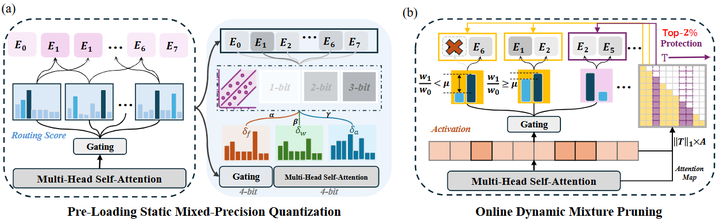
MC( Mixture-Compressor for MoE-LLMs)
Su等人提出一种统一压缩框架(arxiv),将 MoE 模型的冗余参数通过专家瘦身(Expert Slimming,如剪枝或量化)与结构精简(Expert Trimming,如删除不重要专家或整层/整块),显著提升推理速度同时保持性能。(如下图所示,每一层中都有许多专家(Experts),但只有一个被高亮显示(例如第 1 层的 Expert 68、第 2 层的 Expert 92、第 3 层的 Expert 82),它们被识别为所谓的“Super Experts(超级专家)”;本图以直观方式说明了一种关键机制:尽管在模型中激活的是许多专家,但只有少数特定专家(即 Super Experts)在某些层中触发了极端激活,从而在网络内部形成显著信号,并对整体模型性能产生重要影响。 arxiv)。

Super Experts mechanism in Qwen3-30B-A3B
Yang等人提出MoE-I2(Inter-Expert Pruning & Intra-Expert Low-Rank Decomposition),分两步压缩MoE模型:先剪除影响较小的整个专家,然后对每个剩余专家的权重矩阵做低秩近似分解,以进一步压缩内存占用arxiv.。实验表明,这种组合剪枝-低秩的方法在大幅降低模型参数量时仅带来极小的性能下降(如下图)。
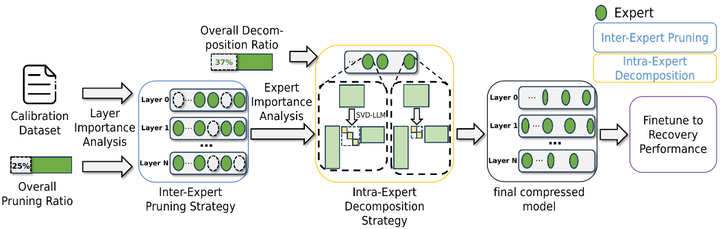
MoE-I2
在模型量化方面,Duanmu等人提出了MxMoE(Mixed-Precision MoE)框架,通过混合精度量化技术专门针对MoE进行优化,协同设计精度与性能,使量化后的模型在保持精度的同时获得更高的执行效率arxiv。
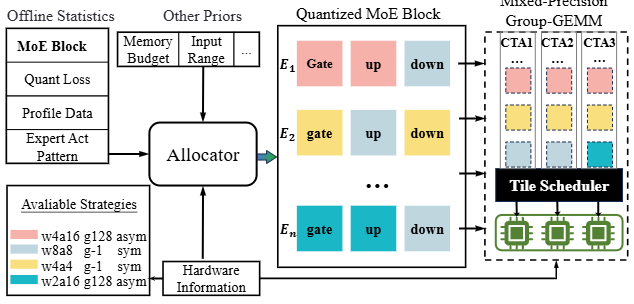
MxMoE
Hu等人则开发了MoE-Quant方法,使用专家均衡采样和亲和力引导等策略改进MoE量化效果,显著降低了MoE LLM的量化误差arxiv.org。总的来说,这些工作从剪枝、量化、低秩分解、合并等多角度出发,使超大MoE模型更加轻量、高效,为MoE在实际部署中落地奠定了基础。
MoE-Quant
训练稳定性与专家利用研究。 MoE特有的专家选择机制带来了一些训练稳定性问题,研究者亦提出解决方案并进行了理论分析。Jaiswal等人在2025年的工作中系统研究了“专家丢弃”策略(Expert Dropping),即在训练中有选择地临时停用一些专家以平衡梯度更新,发现此举有助于缓解专家利用失衡并提升模型鲁棒性arxiv。他们统一了多种专家压缩方法(如下图所示),并通过实验观察到:适度的专家丢弃能让长期未被选中的专家重新参与学习,从而避免部分专家的“饥饿”现象。
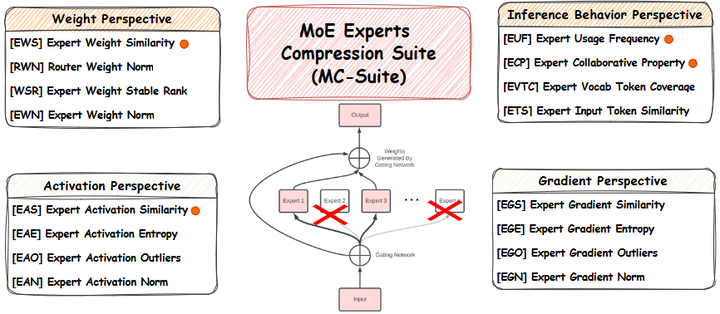
MoE Experts Compression Suite (MC-Suite)
Hwang等人提出预门控MoE(Pre-gated MoE)架构,在馈送给路由器之前对输入进行预处理,使路由决策对输入分布的变化更加平滑,从而增强专家选择的稳定性和专家的功能专一化arxiv。另外,为了从理论上理解MoE的训练行为,Chi等人(2022,arxiv)分析了稀疏MoE的表示塌陷问题,探讨了何种条件下MoE会退化为等价于小容量模型的情况,并提出通过正则化避免表示能力受损。这些研究虽然发表于2025年之前,但为后续工作提供了理论支撑。2025年,Su等人首次报道了“超级专家”(Super Experts)现象(arxiv):他们发现在训练好的MoE LLM中,有极少数专家在模型推理过程中扮演了至关重要的角色。即使总专家数很多,但删除其中几位“超级专家”会导致模型性能大幅崩溃。这一发现表明专家在模型中的重要性分布是高度不均的,并警示后续在剪枝或压缩专家时应特别关注这些关键专家。上述工作深化了我们对MoE内部工作机理的认识,并为改进训练策略提供了依据。
MoE在垂直领域和新场景的应用。 除了一般的语言模型外,近年的研究将MoE机制引入到许多特殊领域的LLM中,取得了显著效果。例如,Pieri等人(arxiv)发布了BiMedix,这是一种面向医疗领域的双语大型语言模型,它在Transformer的每层引入生物医学专用专家和通用语言专家,由门控网络根据输入医学文本的性质在二者之间动态切换。又如,Zhang等人(2025,arxiv)提出了TableMoE,针对表格问答和结构化数据理解任务设计MoE模型:他们引入了“输入感知的专家分配”策略,根据问题涉及的表格内容类型来路由到不同类型的专家,并采用预路由校准提升专家选择准确性。实验显示,相较于传统Transformer,TableMoE在处理表格和文本混合信息时表现出更好的适应性和准确率。

TableMoE
此外,多模态领域也出现了MoE的扩展应用:Wu等人(arxiv)提出DeepSeek-VL2(如下图),将MoE应用于视觉-语言理解模型,提供图像专家和文本专家的混合架构,在复杂多模态推理上取得了领先结果。这些应用导向的研究表明,MoE并非只能服务于通用语言模型,它在专业领域和特定任务中同样具有价值。通过引入量身定制的专家,模型可以融合领域知识、提升专业任务表现,展现出MoE架构的强大灵活性。
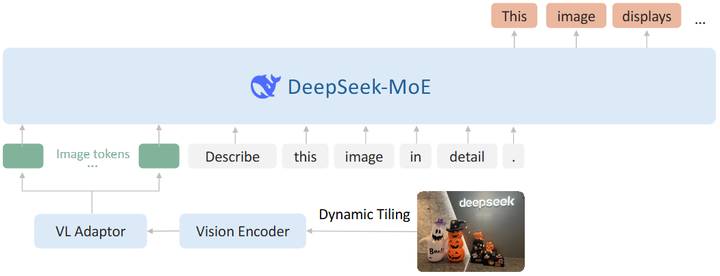
DeepSeek-VL2
工具和基准的推出。 最后值得一提的是,为了更好地评估和使用MoE模型,社区也开发了相应的工具和基准。Nguyen等人发布了LibMoE库(arxiv),这是一个综合测评MoE在LLM中性能的开源框架,提供了从数据并行、专家并行到通信优化等多种实现,方便研究者比较不同MoE算法在统一环境下的效果(参考下图)。
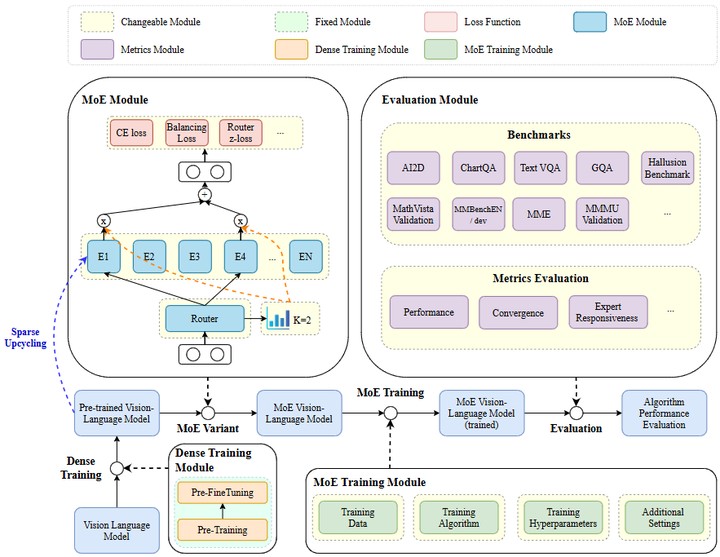
LibMoE
MLCommons组织也在2024年引入了MoE推理基准(如Mixtral 8x7B已被用作MLPerf推理中的一个测试模型),推动建立评测MoE模型效率和性能的行业标准(ml)。此外,一些研究关注MoE的可伸缩定律:Ludziejewski等人(2025,arxiv)分析了MoE的参数-性能缩放关系以及显存占用,提出Joint MoE Scaling Law,指出在合理的专家划分下,MoE可以实现更高的记忆体效率扩展。这些工具化和理论性的工作,将帮助社区更深入地了解MoE模型的行为,并指导未来的模型设计和优化。
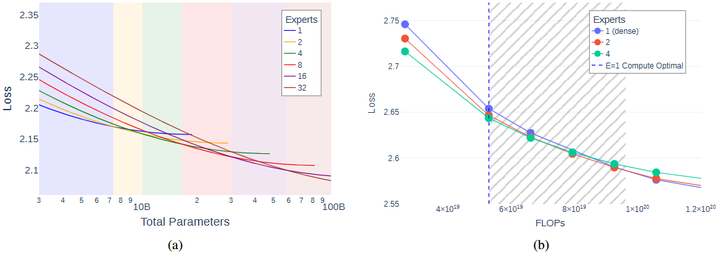
Joint MoE Scaling Laws
综上,2025年及之后,大量开放的研究成果从模型、算法、应用各方面推进了MoE在大型语言模型中的发展。从上述概览可以看到,MoE架构正变得更加成熟和多样,相关研究不仅提升了模型性能,也在积极解决MoE带来的新问题。这些进展为MoE技术在工业界大模型中的广泛落地奠定了基础。
5. MoE在部署中的挑战与优化
尽管MoE为大模型带来了种种益处,但在实际训练部署中也面临若干挑战。研究者和工程团队针对这些问题提出了相应的优化方法。
通信开销与系统瓶颈。 MoE模型的一个显著挑战在于分布式通信。在大型MoE模型训练或推理时,不同专家通常分布在不同的设备(GPU/TPU)上,因此门控网络需要将每个token的数据发送到选中的专家所在设备,再收集计算结果。这种All-to-All通信模式会带来不小的开销:每个设备需要与许多其他设备交换数据,导致网络带宽成为瓶颈。尤其当专家数量和设备数量都很大时,通信延迟和同步等待会降低GPU利用率,抵消MoE节省的部分计算时间。为了解决这一问题,研究者提出了多种优化策略。例如,Li等人(2024)提出系统Aurora,通过通信调度优化和模型部署调整来减少MoE推理时的通信时间arxiv。Aurora的核心思路包括:智能排序各设备间的token发送顺序,尽量避免同时大规模通信;并将来自不同模型或不同层的专家巧妙地同置在同一设备,以减少跨设备传输。实验显示,这种方法可将MoE推理延迟降低2-3倍,提高GPU利用率约1.5倍。
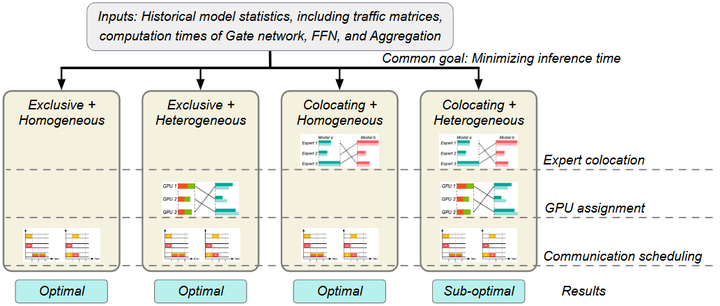
Aurora
另一方面,工程实现上也有针对通信的优化,例如DeepSpeed-MoE采用了分组All-to-All(如下图)和Overlap通信与计算等技巧,使得通信开销大幅下降mlr。
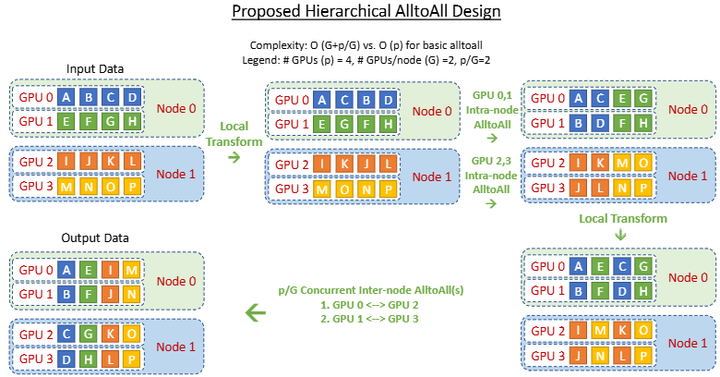
All-to-All
还有研究提出使用局部敏感哈希(LSH)等方法(如下图),将经常一起被访问的token和专家映射到相邻设备,减少远程通信次数neurips。总之,通信开销虽然是MoE扩展中的难点,但通过架构和系统层面的创新,可以在较大程度上缓解这一瓶颈,从而充分发挥MoE的计算优势。
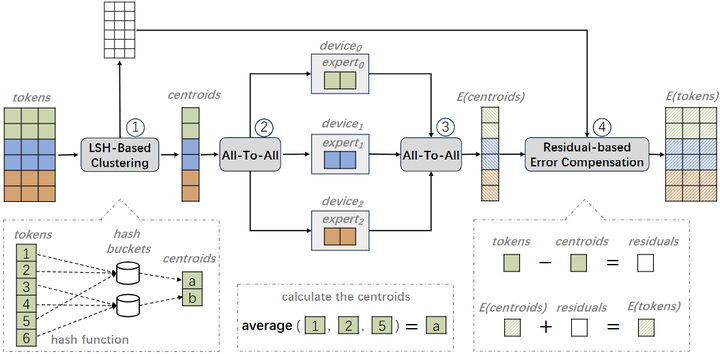
Schematic of MoE training with Locality-Sensitive Hashing (LSH-MoE)
模型大小与内存占用。 MoE模型的另一挑战在于模型参数量虽稀疏使用但总体庞大。例如,一个含数百专家的MoE模型总参数可能数倍于等价性能的稠密模型。这带来了显存和存储上的压力:推理时虽然只激活部分专家,但所有专家参数都需加载在内存中以备选择medium。因此,在部署MoE模型时,设备需要足够大的内存容纳模型,即使很多参数在一次推理中不会被用到。这与常规密集模型(每次用到所有参数)有所不同,但内存瓶颈依然存在。解决这一问题的一种途径是模型压缩(正如前述各种专家剪枝、量化等方法),将MoE整体参数量削减。另一种方案是在系统层面按需加载专家参数,例如通过分布式存储+高速互连,在需要用某个专家时再将其权重临时调入显存。不过由于推理实时性要求高,按需加载较具挑战。此外,有研究探索专家参数共享的方法:让多个专家共享一部分权重(如底层表示),或者在多个MoE层之间共享相同的一组候选专家,以减少总参数存储(例如,如下图所示的MoLAE方法 ,arxiv)。
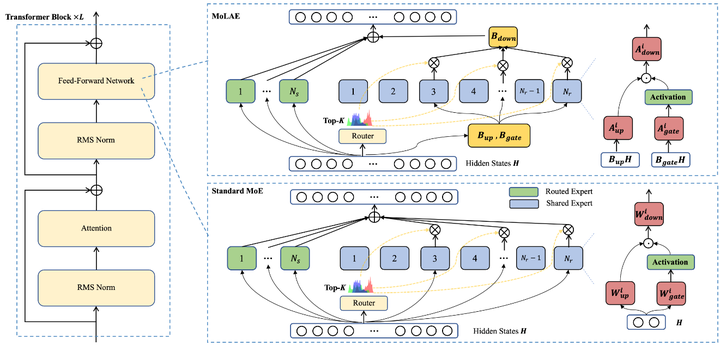
MoLAE
这类似于参数因子化的思想,可降低存储冗余。但需要权衡共享对模型性能的影响。当前来看,更可行的是模型量化,即用低比特表示存储专家权重。例如通过8-bit甚至4-bit量化专家,可以在几乎无损精度下将模型内存占用减少一半以上。例如Mixture of Quantized Experts (MoQE,arxiv)的量化效果如下:
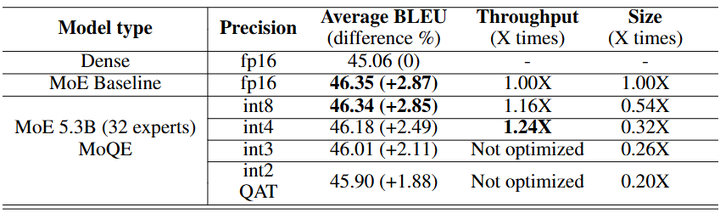
Mixture of Quantized Experts (MoQE)
实际部署中,许多MoE模型也结合使用了如NVIDIA TensorRT等支持低精度的推理库,将显存占用降到可接受范围。简言之,MoE模型部署面临“大模型装载”的问题,需要综合采用模型压缩和系统优化手段,使超大参数模型能够适配现有硬件环境。
训练和推理的实现复杂度。 最后,MoE的引入无可避免地增加了模型实现的复杂性,包括软件和硬件上的挑战。相较于标准Transformer,MoE需要维护门控网络、进行动态路由决策,以及处理跨设备的数据交换。这对训练框架和推理引擎都提出了更高要求。例如,BigMac(DCCA 结构,arxiv):将细粒度 MoE 的通信顺序改为“降维→通信→通信→升维(DCCA)”,把 All-to-All 发生在低维上,显著降低通信体量与时延(如下图,A2A就是All-to-All );
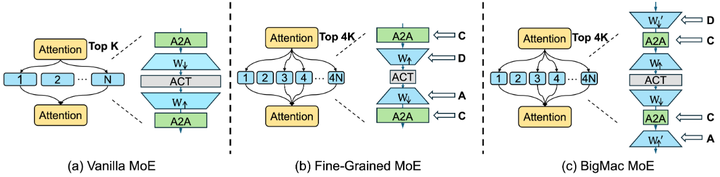
BigMac MoE
在推理部署时,要在实时性要求下完成token到专家的动态映射也有一定难度。为此,工作例如Speculative MoE(arxiv)提出“推测式 token 重排 + 专家分组”,预判路由并预排程,无精度损失地裁剪 EP 通信量(如下图);已在 DeepSpeed-MoE 与 SGLang 推理引擎中实现。
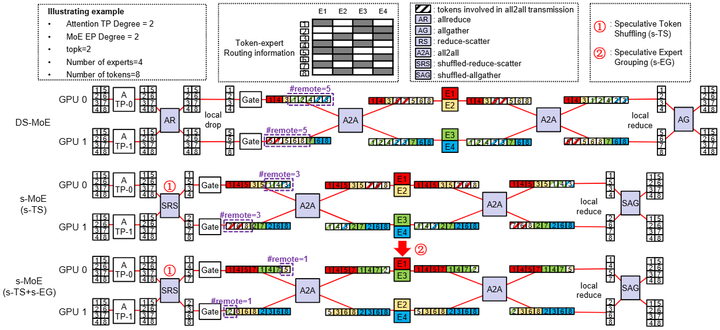
Example of Speculative-MoE.(s-MoE)
此外,MoE模型在微调(fine-tuning)阶段也需特别考虑:如果微调数据覆盖范围有限,可能只有部分专家相关,因此需要策略来避免不相关专家在微调中漂移甚至退化。为此,例如SEE (Sequential Ensemble of Experts)(arxiv)通过顺序专家集合实现的大模型持续微调框架(如下图)。它避免了传统方法中所有专家都被更新的问题,而是为每个新任务只训练新增专家,其余专家保持冻结。这样可以防止不相关专家被微调过程中扰动或遗忘,显著提升微调模型的泛化与抗灾性。
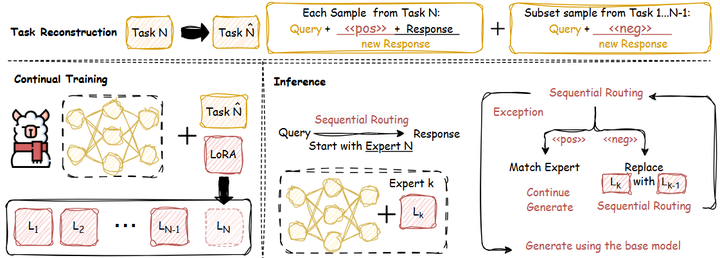
SEE Framework
针对实现复杂度,业界的思路主要是工具化:即通过通用库封装MoE的复杂操作,使研究者和工程师无需每次从零实现。例如前述的Tutel、FastMoE库(github)就极大简化了MoE分布式训练过程。NVIDIA的Megatron-LM(github)和FasterTransformer(github)等框架也内置了MoE支持,可自动处理专家通信和负载均衡。硬件方面,新一代AI加速芯片(如Google TPU v4等)提供了快速互连和更大内存,对MoE这种通信密集型、参数海量型模型更为友好。有报告指出,借助专门优化的软硬件方案,MoE模型的推理效率完全可以达到与等效小模型相近的水平arxiv。因此,尽管MoE增加了实现难度,但随着生态系统的成熟,这一障碍正逐步降低。未来的研究应继续完善MoE的标准化实现、提高工具易用性,并探索硬件级支持(如智能网络调度、混合精度计算),以进一步减少复杂度带来的性能开销。
结论
综上所述,Mixture-of-Experts在大型语言模型中的未来前景十分令人期待。从算法到应用、从软件到硬件,各方面的发展都将进一步释放MoE的潜力。这些模型将能够在有限的算力预算下,处理前所未有复杂和多样的任务,朝着通用人工智能迈出重要一步。在可以预见的未来,MoE将继续站在高效扩展AI模型的前沿,引领大型语言模型的演进方向。我们有理由相信,随着研究的深入和技术的成熟,MoE机制将在下一个十年为AI领域带来更多突破和惊喜。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 37
37 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)