《AI Agent压测监控》
传统错误:HTTP 5xx、超时、数据校验失败AI特有错误认知错误:错误理解用户意图生成错误:事实性矛盾/逻辑错误记忆错误:关键信息遗忘或错乱腾讯TMF监控实践在元宝系统中,业务错误码分层定义"5001": "语义理解错误","5002": "知识检索失败","5003": "推理过程异常","5004": "记忆存储冲突"
本文深度解析AI Agent压测监控与传统App压测的核心差异,揭示认知智能系统特有的质量评估维度与技术实现方案
一、本质差异:从执行到认知的能力跃迁
1.1 传统App压测的核心关注点

传统应用压测聚焦请求-响应线性流程,核心监控指标:
- 资源消耗:CPU/MEM/网络带宽
- 事务成功率:HTTP状态码分布
- 响应延迟:P50/P90/P99
- 吞吐量:TPS(每秒事务数)
1.2 AI Agent的认知决策闭环

AI Agent的核心价值在于认知决策能力,这导致压测监控必须新增三个维度:
- 语义理解质量
- 推理决策准确性
- 长期记忆一致性
二、四大专属监控维度解析
2.1 语义理解层监控(传统App无此层)
关键指标矩阵
|
指标 |
监控方法 |
健康阈值 |
问题定位 |
|
意图识别准确率 |
抽样验证API+人工标注 |
>95% |
NLU模型更新失败 |
|
实体抽取完整度 |
F1值计算 |
>0.85 |
领域词典缺失 |
|
多轮对话连贯性 |
上下文关联度分析 |
>0.7 |
对话状态机故障 |
|
拒绝应答率 |
统计“我不明白”类响应占比 |
<15% |
语义泛化能力不足 |
腾讯元宝实践案例:
在10万用户压测中,通过实时意图分析看板发现旅游类意图识别率从98%骤降至82%,定位到新上线的目的地实体库未加载成功,触发自动回滚机制。
2.2 推理决策层监控(AI核心能力)
|
指标 |
采集方式 |
健康范围 |
优化方向 |
|
推理延迟P99 |
Triton监控数据 |
<800ms |
模型量化/动态批处理 |
|
Token生成速率 |
解码器埋点 |
>80 token/s |
优化采样策略 |
|
思维链断裂率 |
步骤完整性校验 |
<5% |
增加推理约束 |
|
外部工具调用延迟 |
工具调度中间件监控 |
<300ms |
服务降级机制 |
技术突破:
腾讯混元Pro采用动态批处理优化,在GPU利用率90%的高压场景下,Token生成速率仍保持120 tokens/s(行业平均80 tokens/s)

2.3 知识应用层监控
知识系统健康指标
|
指标 |
采集方式 |
异常影响 |
优化方案 |
|
向量检索召回率@5 |
查询结果人工验证 |
知识引用错误↑ |
重建索引+Embedding调优 |
|
知识新鲜度 |
新知识生效时间统计 |
回答过时信息 |
实时流式更新 |
|
知识冲突率 |
多源知识矛盾检测 |
决策矛盾 |
置信度加权融合 |
|
引用溯源准确率 |
生成内容与来源匹配验证 |
虚假引用 |
增强注意力机制 |
2.4 记忆系统专项监控
长期记忆压测三原则:
- 跨会话持久性:30天后记忆保留率>85%
- 冲突解决能力:新旧记忆覆盖准确率>95%
- 关联召回能力:模糊触发记忆召回率>75%
测试方法创新:
# 时间穿越测试框架
def test_memory_consistency():
agent.store_memory("user_birthday", "07-16")
time_travel(days=30) # 加速时间流逝
assert agent.recall("生日") == "07-16" # 跨会话验证三、传统指标在AI场景的质变
|
指标类型 |
典型指标 |
AI场景差异点 |
|
基础设施监控 |
CPU/MEM/网络带宽 |
需增加GPU显存、Token吞吐监控 |
|
服务可用性 |
HTTP错误率 |
需区分业务错误与模型错误 |
|
响应性能 |
API P99延迟 |
增加首Token延迟/生成速率监控 |
|
数据库 |
查询耗时/锁等待 |
需监控向量数据库特有指标 |
|
消息队列 |
堆积消息数 |
增加推理任务队列深度监控 |
3.1 延迟指标的维度扩展
|
延迟类型 |
AI场景意义 |
监控方法 |
传统App对比 |
|
首Token延迟 |
用户感知响应速度 |
首个生成Token时间戳 |
无对应概念 |
|
生成延迟 |
内容生产速度 |
输出Token间隔统计 |
整体响应时间 |
|
思考延迟 |
决策推理耗时 |
推理引擎埋点 |
业务逻辑处理时间 |
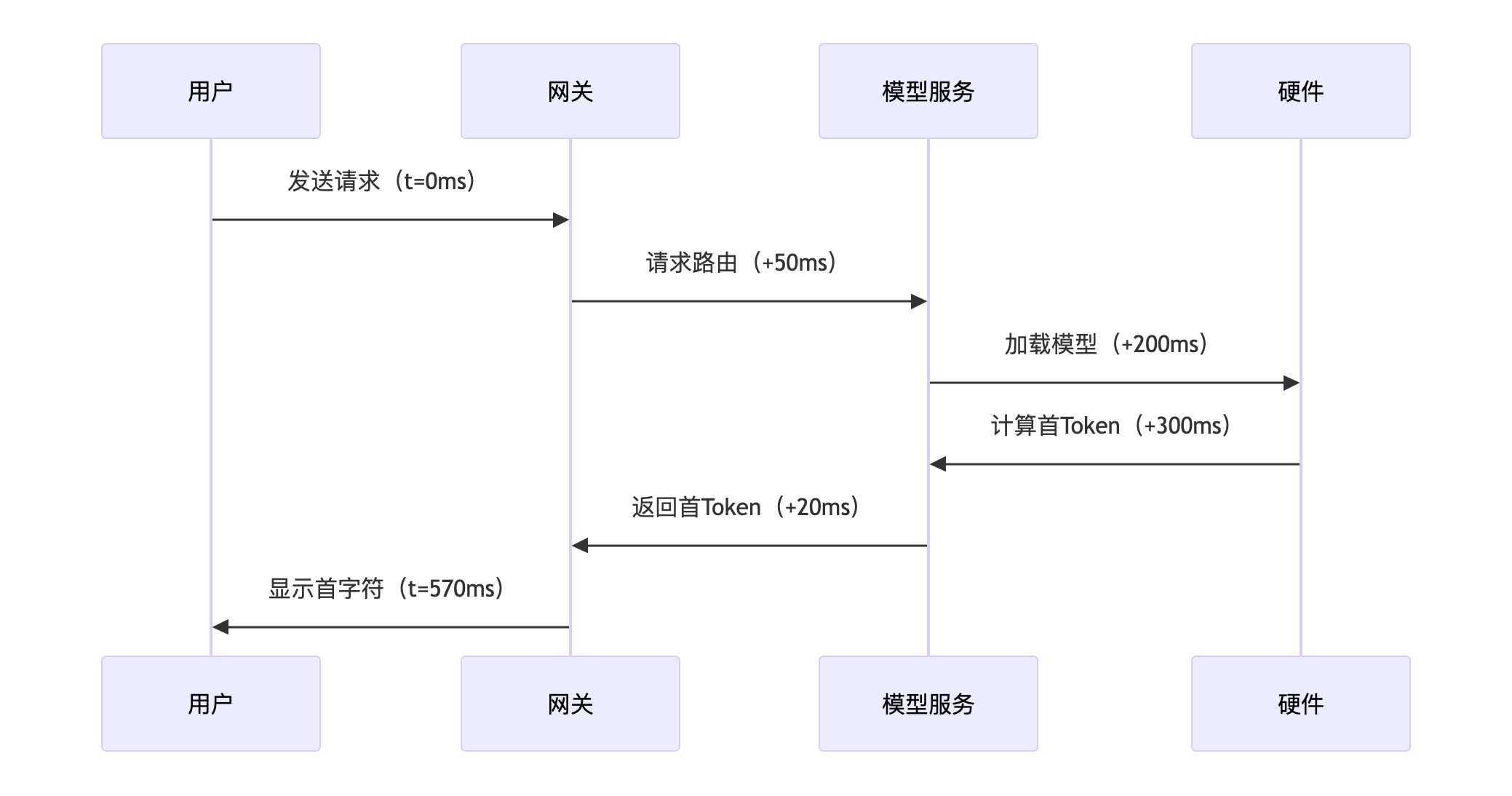
关键耗时环节
|
阶段 |
耗时占比 |
优化手段 |
|
网络传输 |
10-15% |
QUIC协议/边缘计算 |
|
模型加载 |
30-40% |
模型预热/常驻内存 |
|
计算首Token |
40-60% |
连续批处理/KV缓存复用 |
|
结果回传 |
5-10% |
流式传输优化 |
生成式AI vs 传统API
|
特性 |
传统API响应 |
AI首Token延迟 |
|
响应内容 |
完整结果 |
首个字符 |
|
耗时敏感点 |
全流程结束 |
首个有效输出 |
|
用户体验 |
等待后完整显示 |
逐字出现 |
|
技术瓶颈 |
数据库查询 |
自回归生成计算 |
3.2 错误率的重新定义
传统错误:HTTP 5xx、超时、数据校验失败
AI特有错误:
- 认知错误:错误理解用户意图
- 生成错误:事实性矛盾/逻辑错误
- 记忆错误:关键信息遗忘或错乱
腾讯TMF监控实践:
在元宝系统中,业务错误码分层定义:
{
"5001": "语义理解错误",
"5002": "知识检索失败",
"5003": "推理过程异常",
"5004": "记忆存储冲突"
}四、AI压测的混沌工程挑战
4.1 传统故障注入 vs AI认知干扰
|
注入类型 |
传统方案 |
AI增强方案 |
|
网络抖动 |
随机丢包/延迟 |
语义理解中间件注入噪声 |
|
服务宕机 |
Kill进程 |
模拟知识库连接中断 |
|
数据污染 |
数据库脏数据 |
向量检索返回对抗样本 |
|
资源过载 |
CPU满载 |
GPU显存耗尽+推理队列溢出 |
4.2 腾讯元宝的混沌测试案例
五、三维监控体系构建实践
5.1 腾讯元宝监控架构
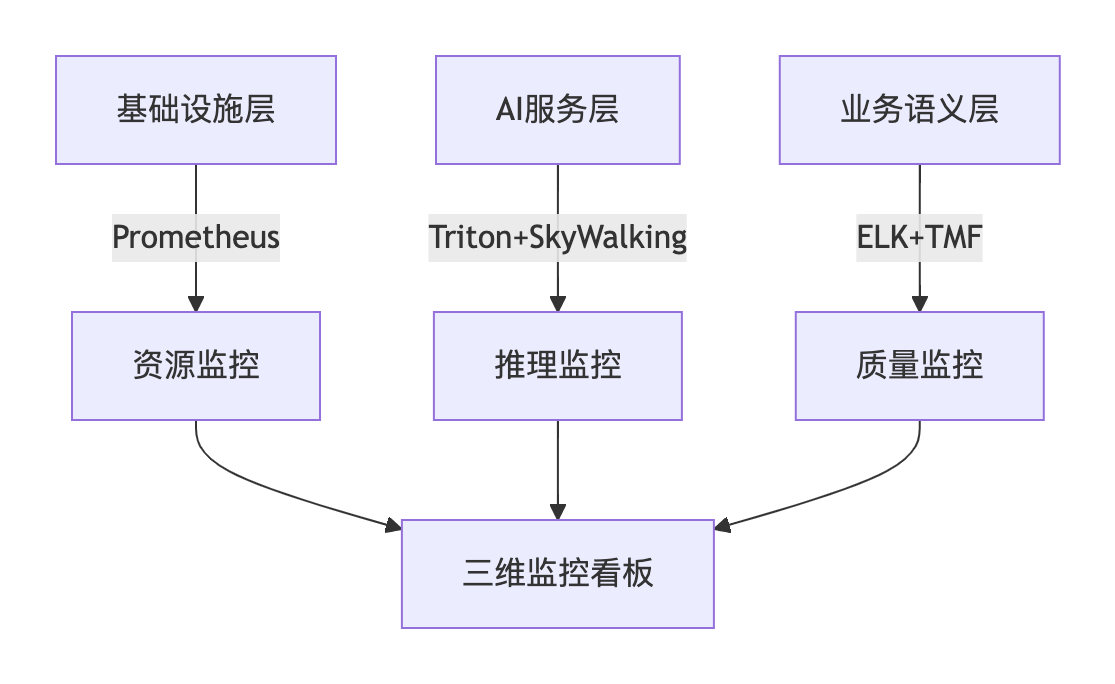
5.2 智能告警联动机制
def adaptive_alert_system():
# 语义质量与资源告警联动
if semantic_quality < 0.8 and gpu_usage > 0.9:
trigger_alert("模型过热导致质量下降")
auto_switch_model("lightweight")
# 错误率突增与记忆异常关联
if error_rate > 0.1 and memory_recall < 0.6:
trigger_alert("记忆系统故障引发决策错误")
restart_memory_service()5.3 典型问题定位路径
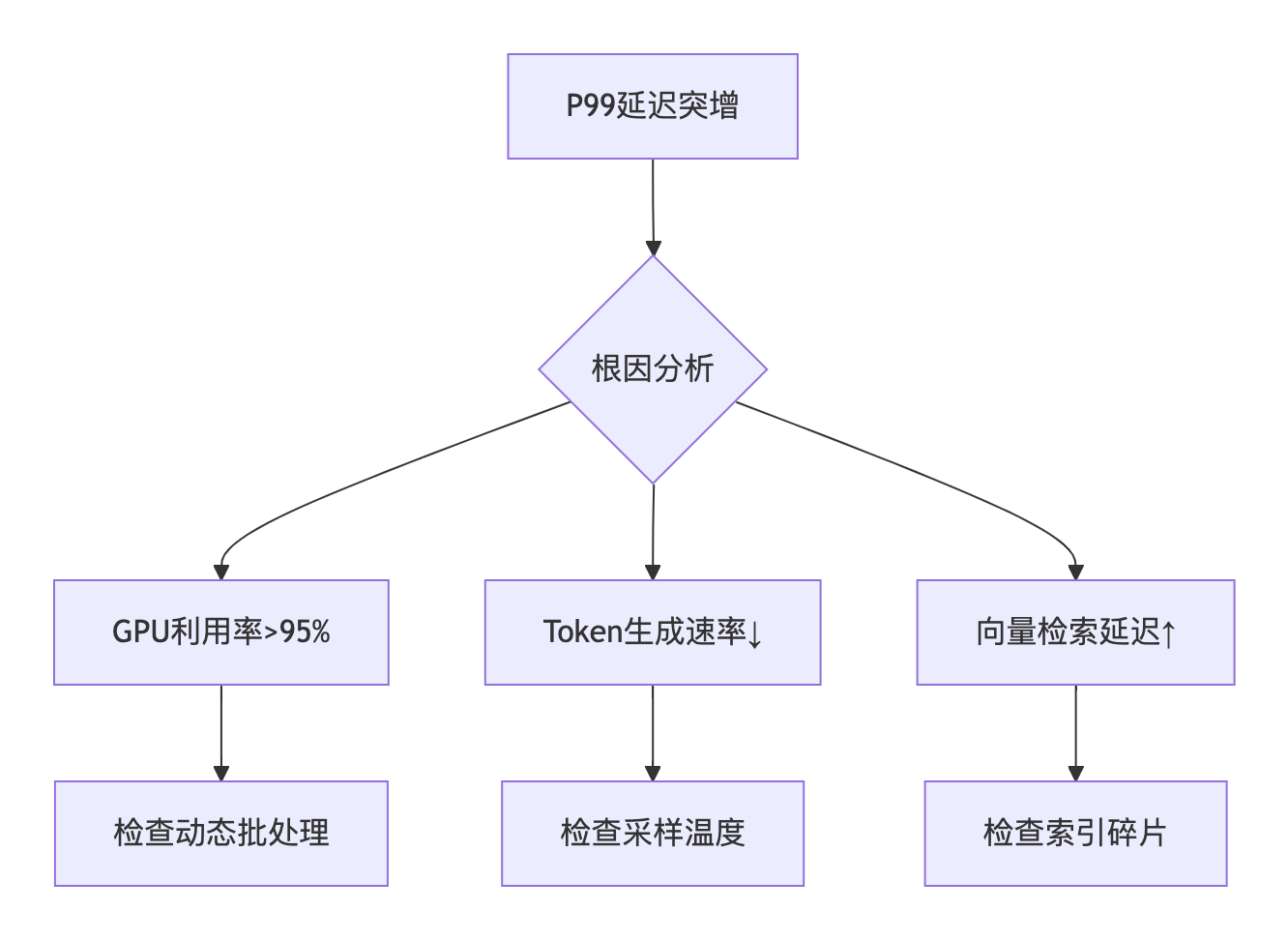
5.4. 关键优化效果
|
优化项 |
监控指标变化 |
收益 |
|
注意力缓存优化 |
首Token延迟↓35% |
用户体验提升 |
|
向量索引重构 |
检索召回率@5↑22% |
幻觉减少40% |
|
流式响应改造 |
可感知延迟↓60% |
用户流失率降低 |
|
模型量化部署 |
GPU显存占用↓50% |
承载量翻倍 |
六、未来挑战与展望
6.1 新兴挑战
- 多模态监控:图文音交叉验证的复杂性
- 伦理安全监控:偏见/隐私/合规的量化评估
- 自我演进跟踪:在线学习系统的版本控制
6.2 技术演进方向
- 可解释性监控:决策过程可视化追溯
- 预测性监控:基于LLM的异常根因分析
- 联邦监控:跨Agent系统的协同观测
结论:AI Agent压测已进入“认知监控”新时代,传统App的二维监控(性能+资源)必须升级为性能-资源-质量三维体系。腾讯元宝的实践表明,完善的AI专项监控可使线上问题定位效率提升300%,同时降低30%的运维成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)