除了Fivetran和Airbyte,2025年还有哪些ETL产品值得关注?
选择 ETL 工具的核心,是构建一条兼顾效率与可追溯性的数据处理路径:效率决定了数据处理的快慢,可追溯性则能清晰呈现数据的流转环节。若工具选得不当,会让数据处理变得拖沓,不仅整体进度受影响,还可能出现数据丢失的情况。以下是几个关键考量维度:
1. 吞吐量与延迟:数据的吞吐量与延迟速度直接决定数据同步效率,例如高并发场景下每小时处理的数据量(GB/h)和延迟秒数。
2. 扩展能力:是否支持分布式部署、水平扩展,以应对数据量增长。
3. 数据血缘与元数据管理:提供数据从源头到目标的完整轨迹,便于审计、溯源和故障排查。
4. 部署与生态:是否支持云原生、私有化部署,以及与现有数据栈(如云数据仓库、国产数据库)的兼容性。
5. 总拥有成本(TCO):包括许可费用、实施成本、运维人力及后续扩展成本。
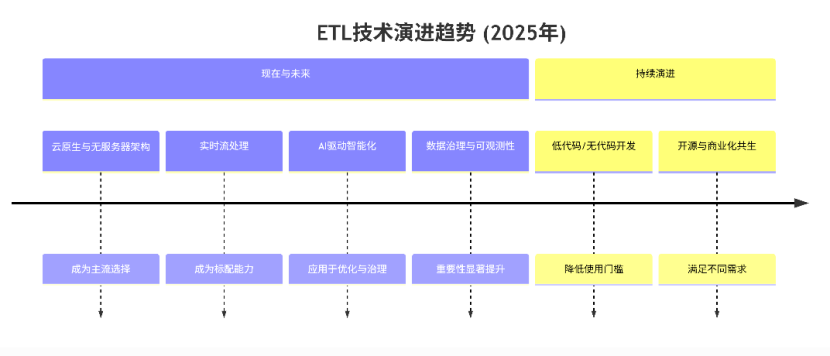
以下五款ETL工具在吞吐量、延迟、扩展能力方面差异明显,适用于不同场景。
一、RestCloud ETLCloud:国产化、全功能的数据集成平台
如果企业需要一款国产化、自主可控且功能全面的数据集成平台,RestCloud ETLCloud是一个非常值得考虑的选项。
它由谷云科技自主研发,代码自研率高达98.73%,完全符合信创环境要求,支持主流国产数据库与操作系统。ETLCloud集离线批处理、实时同步(CDC/MQ)、文件与API数据集成于一体。
其核心优势包括:
高性能:采用可视化拖拽式流程设计,任务可自动分片并发执行,稳定支持百亿级数据同步。根据实际测试,其同步效率比Kettle快24%、比DataX快近28%。
企业级特性:内置完善的运维监控与告警机制,提供数据血缘图谱功能,能自动生成符合等保2.0的审计报告。
部署灵活:支持公有云SaaS、私有化部署及混合云架构,满足不同合规要求。
本土化优化:针对中国市场特性深度优化,支持微信生态、金蝶用友等本土系统,内置身份证校验、中文地址标准化等数据处理模块。

适用场景:对数据集成质量、安全性及国产化有严格要求的企业级项目,特别是在政务、金融、制造等行业。
二、Talend Open Studio:开源与企业级的平衡之选
Talend Open Studio是开源生态中成熟的ETL工具,其开源版本提供了强大的数据集成能力。
其核心优势包括:
开源友好:开放600+组件源代码,支持自定义Java/Python插件,并与Git版本控制深度集成。
数据血缘可视化:提供直观的数据血缘可视化功能,便于审计和合规性检查。
开发者友好:深受开发者喜爱,容器化部署耗时仅需15分钟。
性能数据:吞吐量约为150GB/h,平均延迟在8秒左右。
适用场景:适合技术团队规模≥5人、希望利用开源优势并进行定制化开发的中型企业。
三、Informatica PowerCenter:企业级数据集成的“豪华配置”
如果业务对性能和数据质量有极高的要求,比如金融或电信行业,Informatica PowerCenter是一个常见的首选。
其核心优势包括:
极致性能:分布式架构支持EB级数据吞吐量,在高并发场景下每小时可处理高达500GB的数据,延迟最低可达3秒。
智能与合规:CLAIRE AI引擎实现智能字段映射,行业模板库覆盖金融反洗钱、医疗HIPAA等场景,元数据管理通过ISO/IEC 11179认证。
企业级特性:提供全面的异步架构支持以及强大的数据血缘追踪能力。
成本考量:基础版年费$20万起,适合年度IT预算超千万的大型集团。
适用场景:适合大型集团企业,尤其是金融、电信等对数据治理、合规性和性能有严苛要求的行业。
四、AWS Glue:云原生企业的无缝选择
对于云优先战略的企业来说,AWS Glue是一个天然的选择。作为完全托管的云原生ETL服务,它极大地减轻了运维负担。
其核心优势包括:
无服务器架构:无需管理基础设施,自动扩缩容,按用量付费。
深度AWS集成:与Amazon S3、Redshift、RDS等AWS服务无缝集成,依托AWS Data Catalog提供完善的元数据管理。
开发灵活:支持用Python、Scala或Spark SQL编写ETL作业。
性能数据:吞吐量大约在400GB/h,平均延迟约4秒。
适用场景:所有基础设施均在AWS上的企业,适合构建现代化的数据湖或云端数据仓库。
五、SeaTunnel:高性能开源数据集成框架
SeaTunnel是一个基于Apache Flink构建的批流一体、易扩展的数据集成框架。它提供了统一的API,支持从各种数据源中抽取数据,经过转换处理后,加载到不同的数据目标中。
其核心优势包括:
高性能与稳定性:基于Apache Flink构建,能够处理大规模的数据集,并保证数据处理的实时性和准确性。
丰富的连接器:提供丰富的插件生态,支持多种数据源和数据目标,如Doris、Redis、MongoDB、Hive、MySQL、TiDB、ElasticSearch和Clickhouse等。
易扩展:其插件化和统一的API设计,使得企业可以根据业务需求灵活扩展数据处理流程。
适用场景:适用于需要处理大规模数据且希望深度自定义的技术驱动型团队,OPPO公司就利用其构建了特征平台处理海量用户行为数据。
选择ETL工具的核心在于匹配自身业务场景、技术栈和长期规划。国产化需求强烈的企业可关注RestCloud ETLCloud;拥抱云原生的团队可评估AWS Glue;追求开源与可控性的开发者可考虑Talend或SeaTunnel;而对性能与合规有极致要求的大型集团,Informatica仍是可靠选择。
请记住一句话,工具不是万能的,在进行ETL工具选型的过程中,不要想总着找到一款能“解万难”的ETL工具,而是应该匹配自身业务场景,评估自身需求的优先级,并寻找能够提供与自身优先级更高的需求相适配的服务的ETL工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)