【Datawhale之Happy-LLM】编解码器——Github最火大模型原理与实践教程task04精华
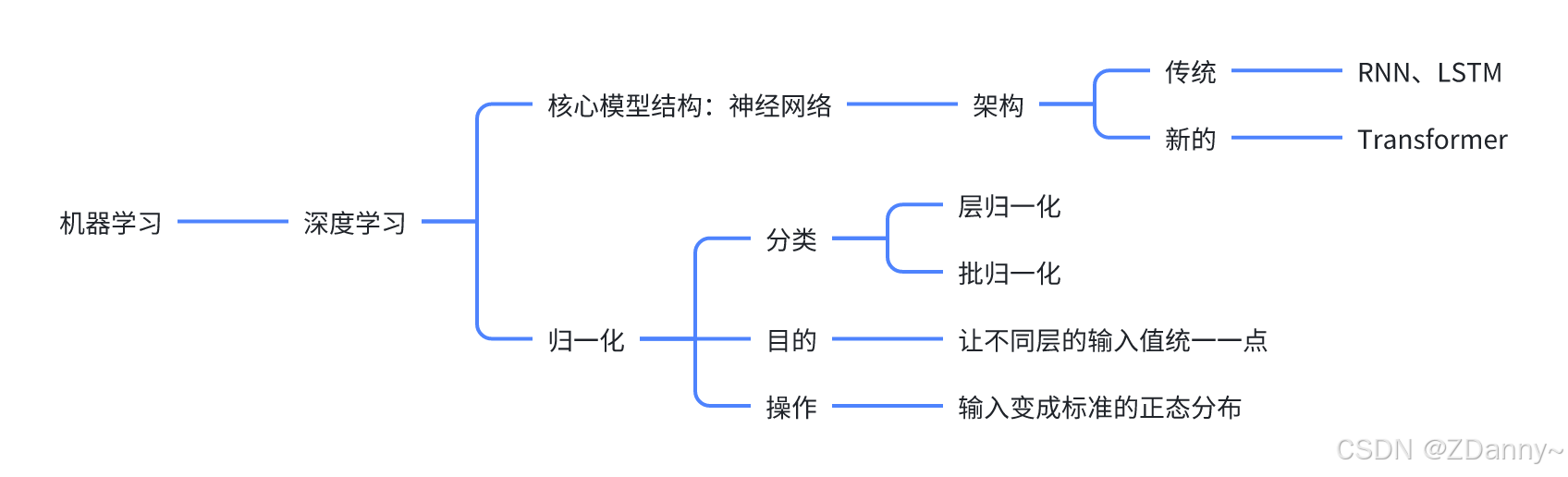
本文介绍了Transformer架构的核心概念与实现。Transformer是一种seq2seq模型,由编码器(Encoder)和解码器(Decoder)组成,核心组件包括注意力机制、层归一化和残差连接。首先通过Tokenizer将文本转换为token序列,再经过Embedding层转换为词向量并添加位置编码。编码器包含6个编码层,每个层有自注意力机制和前馈网络;解码器类似但增加掩码自注意力,并使
Task04:第二章 NLP 基础概念
Task03+04:第二章 Transformer架构
本篇是task04: 2.2 2.3 编解码器、搭建一个Transformer
(这是笔者自己的学习记录,仅供参考,原始学习链接,愿 LLM 越来越好❤)
Transformer架构很重要,需要分几天啃一啃。
Transformer的定位图
Transformer架构图
Transformer论文结构图
接下来,我会按照顺序依次介绍各个部分,这样因果关系会清晰一些
- 顺序:tokenizer、【transformer:(embedding、encoder、decoder、线性层+softmax)】
- transformer的核心:attention、encoder、decoder
- encoder、decoder的核心组件(3个):层归一化(layer norm)、前馈全连接神经网络(FNN)、残差连接(residual connection)
- FNN:如MLP,线性层 + 非线性RELU激活函数 + 线性层
transformer和seq2seq的关系
transformer就是一种seq2seq模型,可以用来完成seq2seq任务
什么是seq2seq?
序列到序列,是一种NLP经典任务,输入是文本序列,输出也是。其实所有nlp任务都可以看成是广义的seq2seq,如机器翻译、文本分类、词性标注等
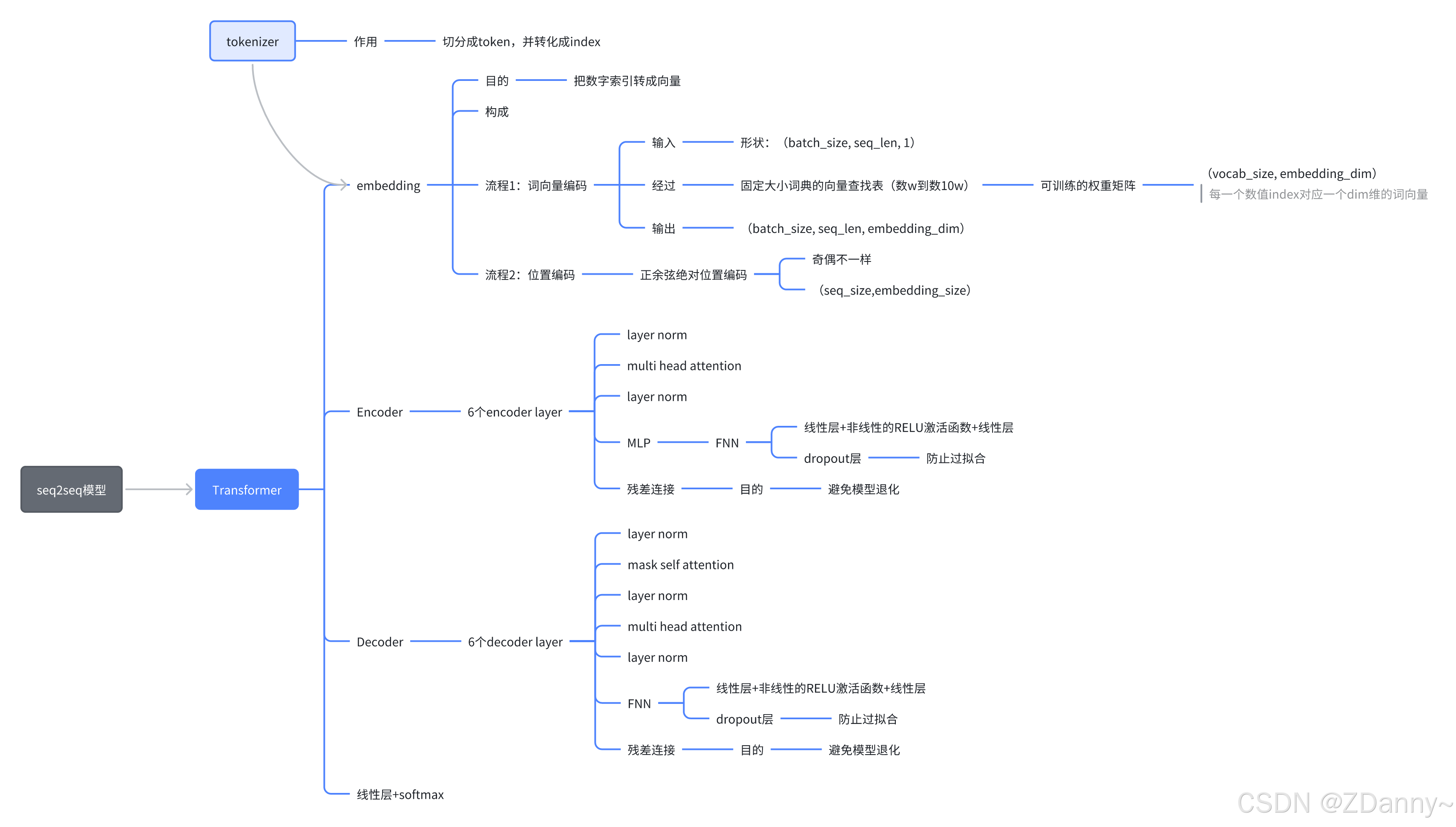
tokenizer 分词器
分词器不在transformer架构中,他是前缀处理模块。
tokenizer作用?
把 文本
–> 切分成很多token=seq_len(有很多策略,词、子词、字符等)
–> index数值,变成(batchsize, seq_len, 1)
embedding
embedding有两个流程:
- 流程1——input embedding :转成词向量。把前面的数值索引 根据
词典向量表变成词向量矩阵 - 流程2——position encoding:位置编码。根据 token在序列中的位置 得到位置编码矩阵
最后,把上面两个矩阵相加,得到这一层的输出。
what 输入输出矩阵形状 of input embedding?
其实就是把一维数值变成了多维的
输入形状:(batch_size, seq_len, 1)
输出形状:(batch_size, seq_len, embedding_dim)
what 词典向量表?
是一个可训练的权重矩阵,(vocab_size,
embedding_dim),每一个数值index对应一个embedding_dim维的词向量。
why position encoding?
因为transformer他是并行计算,和传统的RNN、LSTM这些顺序计算的不太一样,会丢失位置信息。导致模型会认为“我喜欢你”和“你喜欢我”弄成是一样的意思。所以,要在进入编码器之前加上位置信息。
how position encoding?
位置编码有很多方式,transformer论文中用的是正余弦绝对位置编码,和输入文本的内容无关,是和序列的token数有关,以及他是奇偶位置有关,具体的计算可以参考原文。得到的位置编码矩阵的形状就是(seq_size,
embedding_dim),要和词向量矩阵的维度一样才可以相加。
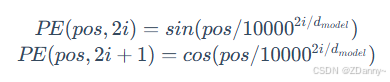
encoder 编码器
encoder的整体组成
- encoder:里有N个encoder layer(论文里是6个层)
- encoder layer:里有2个layer norm、1个attention、1个fnn
总结:先归一化,再给attention,输出后归一化,再进fnn。然后6个layer组装,再归一化。
2个细节?
层归一化收敛快一点
残差连接不让模型走偏,下一层input = 上一层output + 上一层 input
代码实现
先写encoder layer类,再组装出encoder
class EncoderLayer(nn.Module):
'''Encoder层'''
def __init__(self, args):
super().__init__()
# 一个 Layer 中有两个 LayerNorm,分别在 Attention 之前和 MLP 之前
self.attention_norm = LayerNorm(args.n_embd)
# Encoder 不需要掩码,传入 is_causal=False
self.attention = MultiHeadAttention(args, is_causal=False)
self.fnn_norm = LayerNorm(args.n_embd)
self.feed_forward = MLP(args.dim, args.dim, args.dropout)
def forward(self, x):
# Layer Norm
norm_x = self.attention_norm(x)
# 自注意力
h = x + self.attention.forward(norm_x, norm_x, norm_x)
# 经过前馈神经网络
out = h + self.feed_forward.forward(self.fnn_norm(h))
return out
class Encoder(nn.Module):
'''Encoder 块'''
def __init__(self, args):
super(Encoder, self).__init__()
# 一个 Encoder 由 N 个 Encoder Layer 组成
self.layers = nn.ModuleList([EncoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd)
def forward(self, x):
"分别通过 N 层 Encoder Layer"
for layer in self.layers:
x = layer(x)
return self.norm(x)
拓:深度神经网络中的归一化?
有两种:
- 批归一化(batch norm)
- 层归一化(layer norm):transformer里用的是这个
都涉及均值和方差,具体的公式先不管
decoder 解码器
decoder的整体组成
decoder和encoder很像,就是单层里的结构有点差异
- decoder:里有N个decoder layer(论文里也是6个层)
- decoder layer:里有3个layer norm、2个attention(mask self attention、multi head attention)、1个fnn
总结:先归一化,经过掩码自注意,再归一化,经过多头注意力,再归一化,经过fnn。再把6个层组装,再归一化
decoder的两个注意力层
第一个注意力层是一个掩码自注意力层,即使用
Mask 的注意力计算,保证每一个 token 只能使用该 token之前的注意力分数;
第二个注意力层是一个多头注意力层,该层将使用第一个注意力层的输出作为 query,使用Encoder 的输出作为 key和 value,来计算注意力分数。
代码实现
class DecoderLayer(nn.Module):
'''解码层'''
def __init__(self, args):
super().__init__()
# 一个 Layer 中有三个 LayerNorm,分别在 Mask Attention 之前、Self Attention 之前和 MLP 之前
self.attention_norm_1 = LayerNorm(args.n_embd)
# Decoder 的第一个部分是 Mask Attention,传入 is_causal=True
self.mask_attention = MultiHeadAttention(args, is_causal=True)
self.attention_norm_2 = LayerNorm(args.n_embd)
# Decoder 的第二个部分是 类似于 Encoder 的 Attention,传入 is_causal=False
self.attention = MultiHeadAttention(args, is_causal=False)
self.ffn_norm = LayerNorm(args.n_embd)
# 第三个部分是 MLP
self.feed_forward = MLP(args.dim, args.dim, args.dropout)
def forward(self, x, enc_out):
# Layer Norm
norm_x = self.attention_norm_1(x)
# 掩码自注意力
x = x + self.mask_attention.forward(norm_x, norm_x, norm_x)
# 多头注意力
norm_x = self.attention_norm_2(x)
h = x + self.attention.forward(norm_x, enc_out, enc_out)
# 经过前馈神经网络
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Decoder(nn.Module):
'''解码器'''
def __init__(self, args):
super(Decoder, self).__init__()
# 一个 Decoder 由 N 个 Decoder Layer 组成
self.layers = nn.ModuleList([DecoderLayer(args) for _ in range(args.n_layer)])
self.norm = LayerNorm(args.n_embd)
def forward(self, x, enc_out):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, enc_out)
return self.norm(x)
末尾步骤
经过一个线性层,再经过softmax。softmax就是只取正,否则就是0
手搓Transformer代码
论文中写的归一化是post-norm,但是发出来的代码中用的是pre-norm,鉴于pre-norm可以让loss更稳定,便默认用pre-norm(就是在输入每个attention或者fnn前归一化)
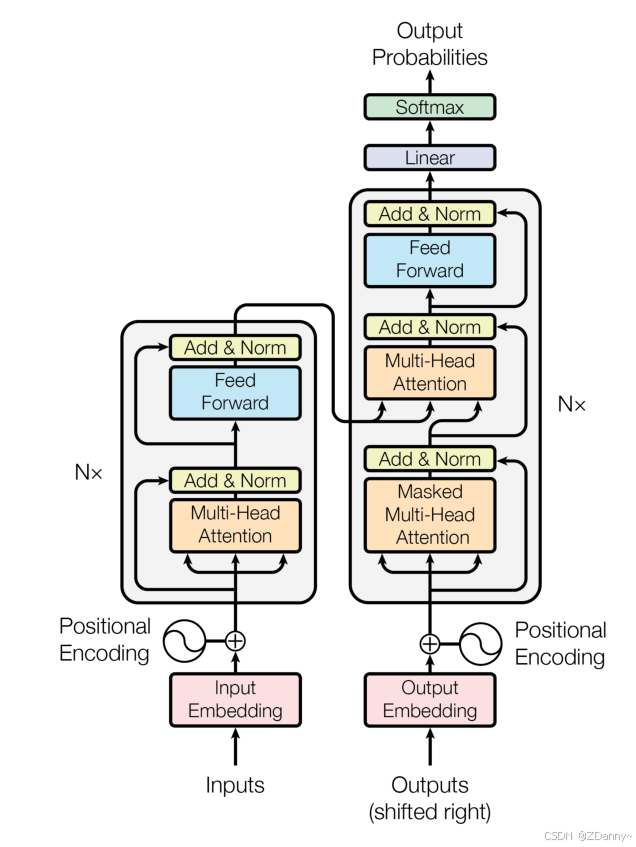
经过 tokenizer 映射后的输出先经过 Embedding 层和 Positional Embedding层编码,然后进入 N 个 Encoder 和 N 个 Decoder(在 Transformer 原模型中,N取为6),最后经过一个线性层和一个 Softmax 层就得到了最终输出。
class Transformer(nn.Module):
'''整体模型'''
def __init__(self, args):
super().__init__()
# 必须输入词表大小和 block size
assert args.vocab_size is not None
assert args.block_size is not None
self.args = args
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(args.vocab_size, args.n_embd),
wpe = PositionalEncoding(args),
drop = nn.Dropout(args.dropout),
encoder = Encoder(args),
decoder = Decoder(args),
))
# 最后的线性层,输入是 n_embd,输出是词表大小
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias=False)
# 初始化所有的权重
self.apply(self._init_weights)
# 查看所有参数的数量
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
'''统计所有参数的数量'''
def get_num_params(self, non_embedding=False):
# non_embedding: 是否统计 embedding 的参数
n_params = sum(p.numel() for p in self.parameters())
# 如果不统计 embedding 的参数,就减去
if non_embedding:
n_params -= self.transformer.wte.weight.numel()
return n_params
'''初始化权重'''
def _init_weights(self, module):
# 线性层和 Embedding 层初始化为正则分布
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
'''前向计算函数'''
def forward(self, idx, targets=None):
# 输入为 idx,维度为 (batch size, sequence length, 1);targets 为目标序列,用于计算 loss
device = idx.device
b, t = idx.size()
assert t <= self.args.block_size, f"不能计算该序列,该序列长度为 {t}, 最大序列长度只有 {self.args.block_size}"
# 通过 self.transformer
# 首先将输入 idx 通过 Embedding 层,得到维度为 (batch size, sequence length, n_embd)
print("idx",idx.size())
# 通过 Embedding 层
tok_emb = self.transformer.wte(idx)
print("tok_emb",tok_emb.size())
# 然后通过位置编码
pos_emb = self.transformer.wpe(tok_emb)
# 再进行 Dropout
x = self.transformer.drop(pos_emb)
# 然后通过 Encoder
print("x after wpe:",x.size())
enc_out = self.transformer.encoder(x)
print("enc_out:",enc_out.size())
# 再通过 Decoder
x = self.transformer.decoder(x, enc_out)
print("x after decoder:",x.size())
if targets is not None:
# 训练阶段,如果我们给了 targets,就计算 loss
# 先通过最后的 Linear 层,得到维度为 (batch size, sequence length, vocab size)
logits = self.lm_head(x)
# 再跟 targets 计算交叉熵
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# 推理阶段,我们只需要 logits,loss 为 None
# 取 -1 是只取序列中的最后一个作为输出
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss
注意,上述代码除去搭建了整个 Transformer 结构外,还额外实现了三个函数:
- get_num_params:用于统计模型的参数量
- _init_weights:用于对模型所有参数进行随机初始化
- forward:前向计算函数
强调:本篇中所有代码都是原文链接中提供的,不是主包自己贡献的!!感谢开源大佬

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)