机器学习算法
智能体通过与环境进行交互,根据奖励信号来调整其行为策略,以达到最大化累积奖励的目标。,是一种机器学习的训练方式,它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。,通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。(3)环境根据智能体的动作转换到新的状态,并返回一个奖励信号(reward)。(4)智能体根据奖励信号更新其
按照学习方式分类
|
类别 |
特点 |
训练图 |
类别 |
经典算法 |
应用 |
|
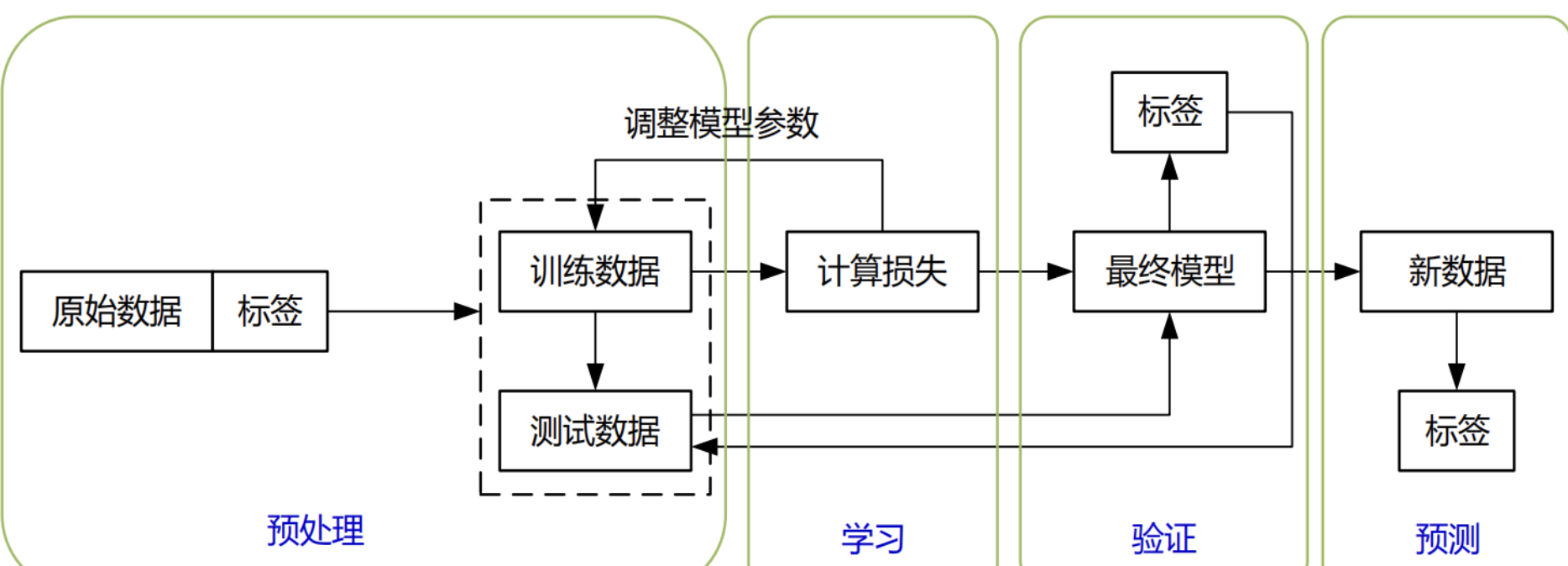
监督学习 |
训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。 |
|
分类 回归 |
支持向量机(SVM) 决策树 逻辑回归 随机森林 |
图像识别 语音识别 自然语言处理 |
|
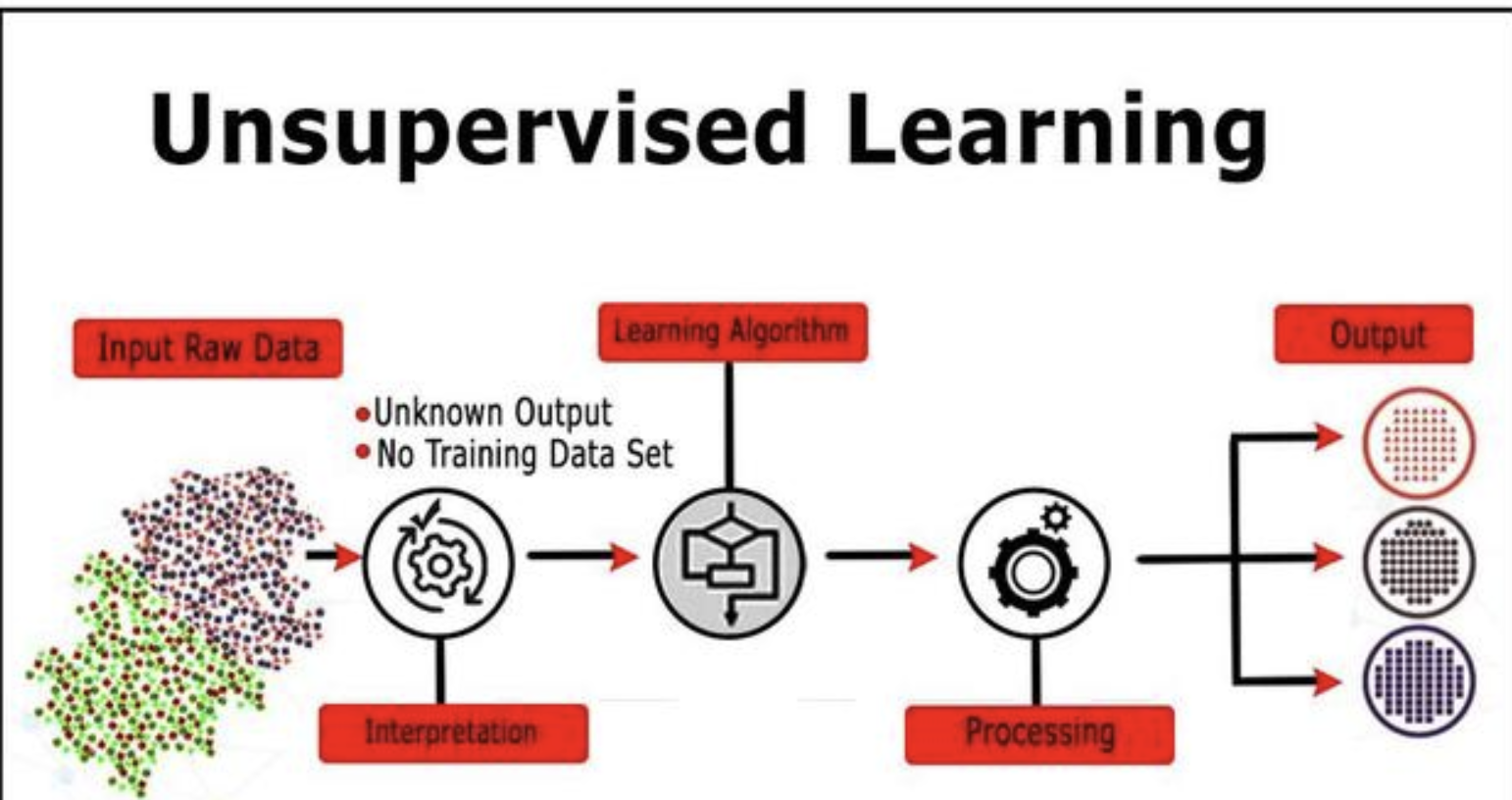
无监督学习 |
数据只有特征(feature)无标签(label),是一种机器学习的训练方式,它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。 |
|
聚类 降维 关联规则挖掘 异常检测 |
k均值聚类 主成分分析 关联规则挖掘 异常检测 |
聚类与分组 特征学习与降维 异常检测 |
|
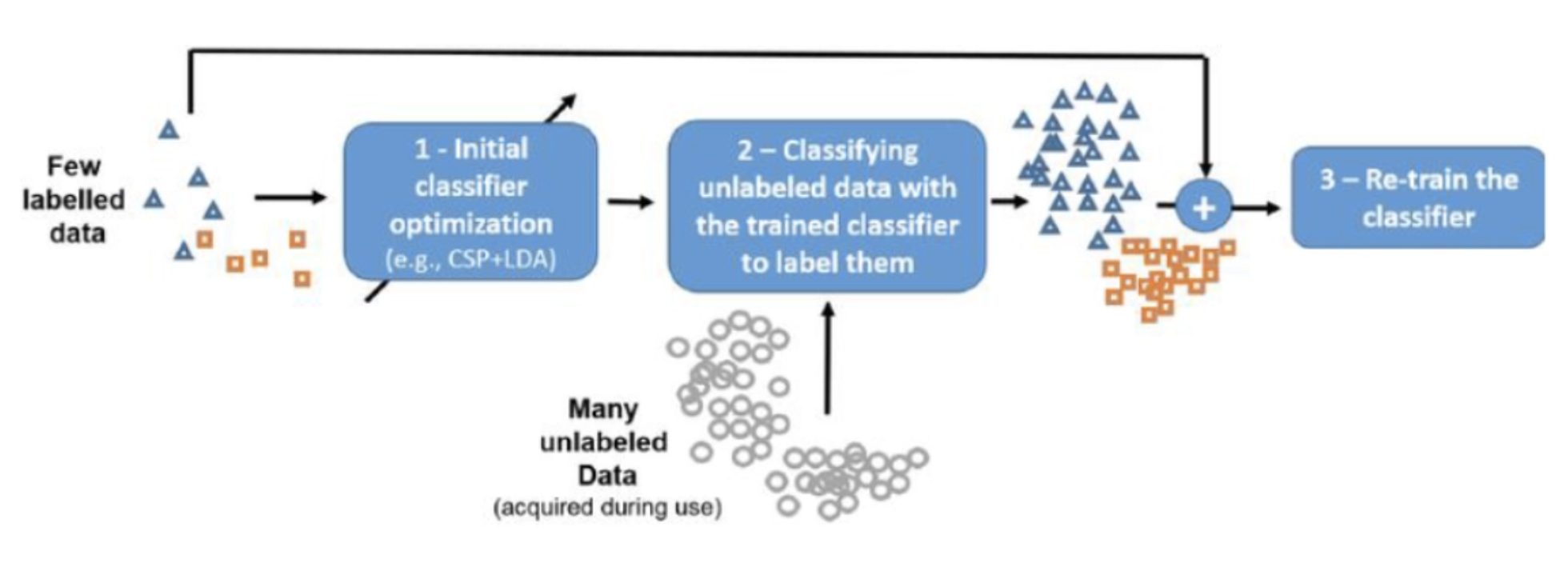
半监督学习 |
训练数据中只有一小部分样本是带有标签的,而大部分样本是没有标签的。 |
|
半监督分类 半监督回归 半监督聚类 半监督异常检测 对抗网络的半监督 |
自训练 协作训练 半监督支持向量机 生成式半监督 半监督深度学习 图半监督学习 |
自然语言处理 图像识别 数据聚类 机器人控制 |
|
强化学习 |
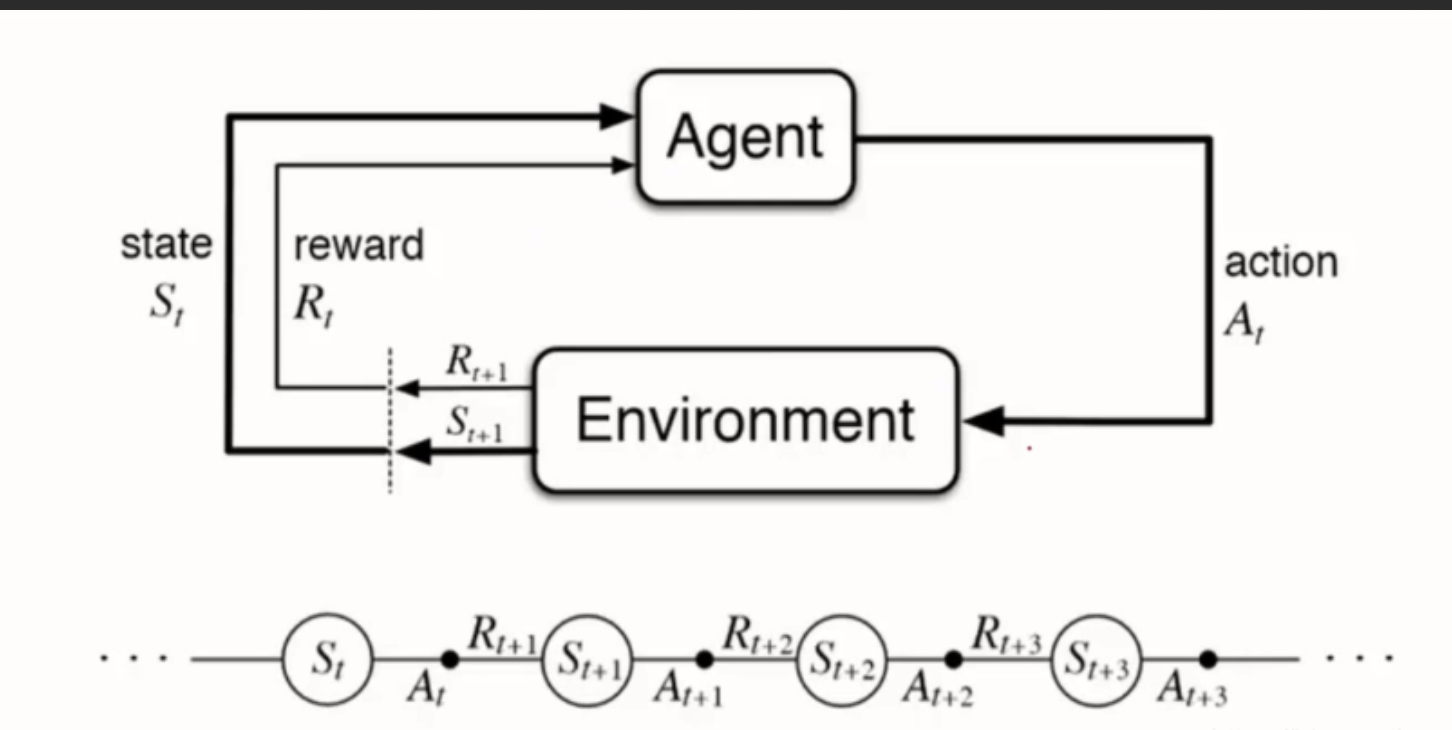
强化学习是让一个智能体(agent)在环境中通过尝试和错误来学习行为策略。智能体通过与环境进行交互,根据奖励信号来调整其行为策略,以达到最大化累积奖励的目标。 (1)智能体观察当前环境状态(state)。 (2)基于当前状态,智能体选择一个动作(action)。 (3)环境根据智能体的动作转换到新的状态,并返回一个奖励信号(reward)。 (4)智能体根据奖励信号更新其策略,以便在将来的决策中获得更好的奖励。 (5)重复以上步骤,直到智能体学习到一个使其获得最大累积奖励的策略。 |
|
基于值的强化学习 基于策略的强化学习 基于模型的强化学习 深度强化学习 多智能体强化学习 |
q-learing sarsa dqn A3c PPO MAPPO TRAPO |
自动驾驶 车联网 游戏 机器人控制 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)