全文- ThunderKittens: Simple, Fast, and Adorable AI Kernels
ThunderKittens摘要将AI架构映射到GPU硬件的挑战正成为AI发展的关键瓶颈。尽管付出了巨大努力,手工编写的定制内核仍无法达到其理论性能阈值,即使在线性注意力等成熟操作上也是如此。GPU多样化的硬件能力可能意味着我们需要大量技术来实现高性能。然而,我们的研究探索了是否可以通过少量关键抽象大幅简化这一过程。我们提出了ThunderKittens(TK),一个用于编写高性能AI内核的框架,

摘要
将AI架构映射到GPU硬件的挑战正成为AI发展的关键瓶颈。尽管付出了巨大努力,手工编写的定制内核仍无法达到其理论性能阈值,即使在线性注意力等成熟操作上也是如此。GPU 多样化的硬件能力可能意味着我们需要大量技术来实现高性能。然而,我们的研究探索了是否可以通过少量关键抽象大幅简化这一过程。我们提出了 ThunderKittens(TK),一个用于编写高性能 AI 内核的框架,同时保持易用性和可维护性。我们的抽象映射到 GPU 层次结构的三个级别:
(1)在 warp 级别,我们提供 16x16 矩阵 tile 作为基本数据结构,以及类似 PyTorch 的并行计算操作;
(2)在线程 block 级别,我们提供了一个模板,用于在并行 warp 之间重叠异步操作;
(3)在 grid 级别,我们支持隐藏 block 启动和销毁以及内存成本。
我们通过提供一系列 AI 操作的核函数来展示 TK 的价值,这些核函数匹配或超越了先前的最佳性能。我们在 GEMM 和注意力推理性能上匹配 CuBLAS 和FlashAttention-3,在注意力反向传播上比最强基线提升 10-40%,在状态空间模型上提升 8 倍,在线性注意力上提升 14 倍。
1 引言
AI 发展的瓶颈在于如何高效地将 AI 架构映射到加速GPU硬件上。机器学习架构经历了寒武纪大爆发[25, 21],但这些架构的性能仍远低于其理论潜力,尽管开发核函数(GPU实现)付出了巨大努力。值得注意的是,即使对于行业中广泛使用的 softmax 注意力,核函数支持也严重不足。FlashAttention-2 [12]在移植到 H100 GPU 时性能下降了47%,而从 H100 发布到开发出FlashAttention-3 [37]用了超过两年时间。
我们受到多种支持 AI 内核开发方法的启发。理想情况下,我们希望有一个框架,既能支持广泛原语的高性能,又易于使用、学习和维护。像 NVIDIA CUTLASS/CuTe [29]这样的高性能C ++ 嵌入式库包含大量嵌套模板,而基于编译器的方法(如 Triton [39])为用户提供了更简单的接口,但优化较少。我们探讨了通过选择少量关键抽象能实现多广多快的性能。
加速计算的主要增长点在于专用矩阵乘法单元。在 NVIDIA A100 和 H100 GPU 上,BF16 Tensor Core 的 FLOPs 是通用 BF16/FP32 计算的 16 倍。因此,任何高性能框架都必须优先尽可能保持 Tensor Core 的高利用率。然而,所有内核还包含其他操作(如内存加载或注意力中的 softmax),因此最小化非 Tensor Core 操作的开销至关重要。这一命题是我们方法的核心。
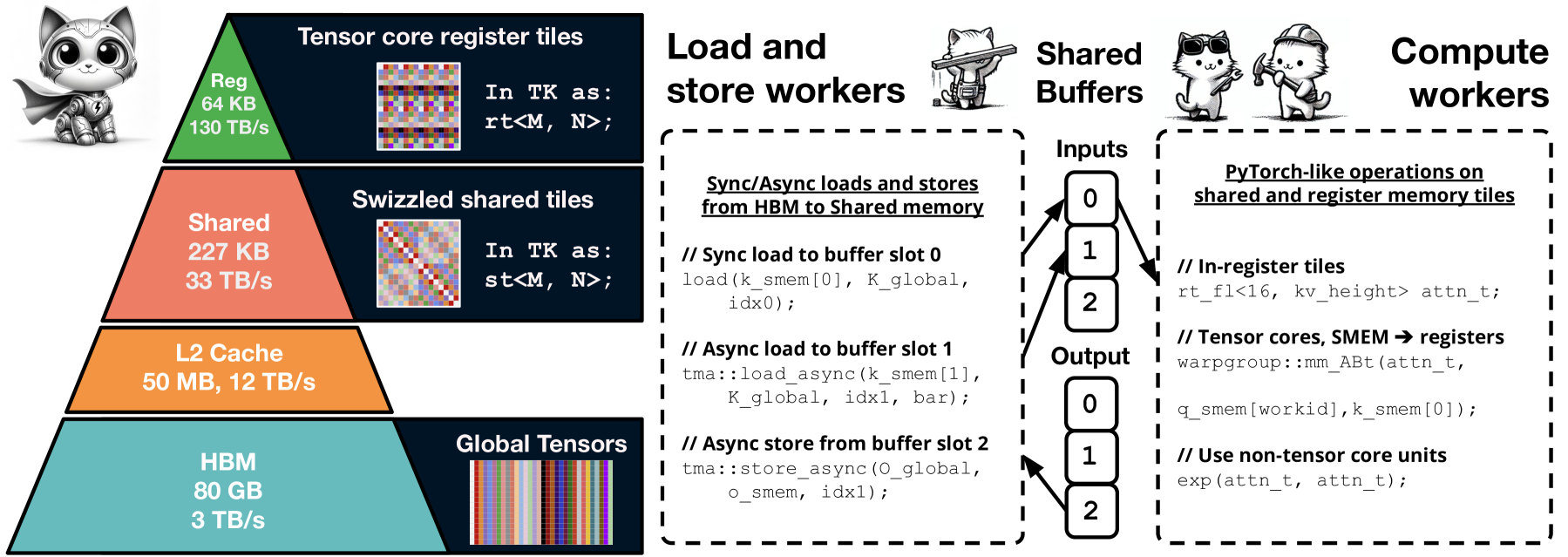
Figure 1: ThunderKittens explores whether a small set of abstractions can support efficient and simple AI kernels. Inspired by PyTorch, our abstractions include tiles with managed layouts and operations over tiles. We provide a general program template for coordinating asynchronous parallel workers – e.g., workers that load from and store data to HBM, while other workers perform computation in fast memory.
为了理解构建简洁而高性能框架的复杂性和机会,我们研究了 GPU 并行性的简化模型(详见第2.1节):
-
Warp级并行性:现代 GPU 由数万个硬件线程组成,这些线程并行执行。线程被组织成小团体 “warps”,一起执行指令。内存布局决定了逻辑数据元素如何映射到物理线程所有权。如果多个线程尝试访问同一内存区域(“bank”),会导致线程间昂贵的序列化(称为 “bank冲突”)【注,是指共享内存的访问规则】。
-
Block 级并行性:Warps 被分组为线程“block”,可以快速共享数据。warps 在物理执行单元上执行指令,一个块中有更多 warps(称为“占用率”)可以帮助同时运行更多指令,减少运行时间。例如,一个 warp 可以运行 Tensor Core 进行矩阵乘法,而另一个使用 CUDA Core 的 ALU 进行最大值计算。
-
Grid 级并行性:GPU 同时运行许多线程 block,这些 block 通过容量大但访问速度慢的全局内存(HBM)通信。如果线程 block 重用相同数据,片上共享 L2 缓存有助于减少内存延迟并增加带宽。线程 block 还面临设置和销毁的延迟开销,称为 “管道气泡”。
尽管看似需要大量技术来利用所有这些硬件能力,但我们的核心技术发现是,对于许多AI内核,确实存在少量关键抽象可以简化编写高性能内核的过程。我们的探索促使我们开发了ThunderKittens(TK),一个围绕三个关键原则构建的 AI 内核框架:
-
具有托管布局的块数据结构:我们的接口受到 PyTorch 和 NumPy [31] 等熟知的 ML 框架的启发(如 图2 所示)。在 warp 级别,我们使用 16x16 矩阵 tile 作为基本数据结构,最大化与 Tensor Core 的兼容性并鼓励其使用。TK 自动为 tile 选择最佳内存布局,以最小化bank冲突,同时保持与专用硬件指令的兼容性,避免用户费力。我们提供了一组基于 PyTorch 操作的并行计算原语(例如,点乘、mma、exp 和累加和)。
-
异步工作的程序模板:在 block 级别,TK 提供了一个通用内核模板,用于协调线程 block 中 warp 之间的异步执行,基于生产者-消费者范式[16]。开发者的工作简化为在此模型中填充一些样板函数,使用我们类似 PyTorch 的操作数,模板内部通过内存管道和同步原语隐藏延迟(图1)。
-
用于管道化线程 block 的 grid 调度:在网格级别,我们展示 TK 可以帮助开发者减少管道气泡并提高 L2 缓存命中率。我们的模板支持持久网格,其中我们在线程 block 边界重叠内存加载。

我们通过两种方式突出这些抽象对开发者的价值:
-
通过探索,我们确定了实现不同类型并行性之间的基本权衡,包括设置 tile 布局(warp级)、占用率(block 级)和 block 启动顺序(grid 级)。通过消融研究(第3节),我们展示了 TK 中的简化接口如何让用户控制这些权衡。
-
我们通过提供一系列 AI 操作的核函数来验证 TK 抽象,这些核函数匹配或超越了先前的最佳性能。我们匹配 CuBLAS GEMM 和F lashAttention-3 注意力推理,在注意力反向传播上比最强基线提升10-40%,在状态空间模型上提升8倍,在线性注意力上提升14倍。这些内核由小型学术团队编写,包括没有 CUDA 经验的本科生。
我们的贡献是:
(1)展示了 TK 中一小部分关键抽象在编写简洁高性能内核方面出乎意料的有效;
(2)提供了一系列高性能 AI 内核。TK 内核已在 ML 推理提供商和高频交易公司中投入生产。我们希望 TK 及其见解有助于提高 AI 内核的可访问性。
2 GPU基础
GPU 任务被划分为称为内核的小程序。内核从高带宽内存(HBM)加载数据,对其进行处理,然后将输出写回 HBM 后结束。在解释 ThunderKittens 的抽象之前,我们提供 GPU 并行性的背景,包括 warp、block 和 grid 级并行性。我们遵循 NVIDIA 的术语,并专注于 H100 SXM GPU,尽管这些原则适用于所有 GPU 供应商和世代。
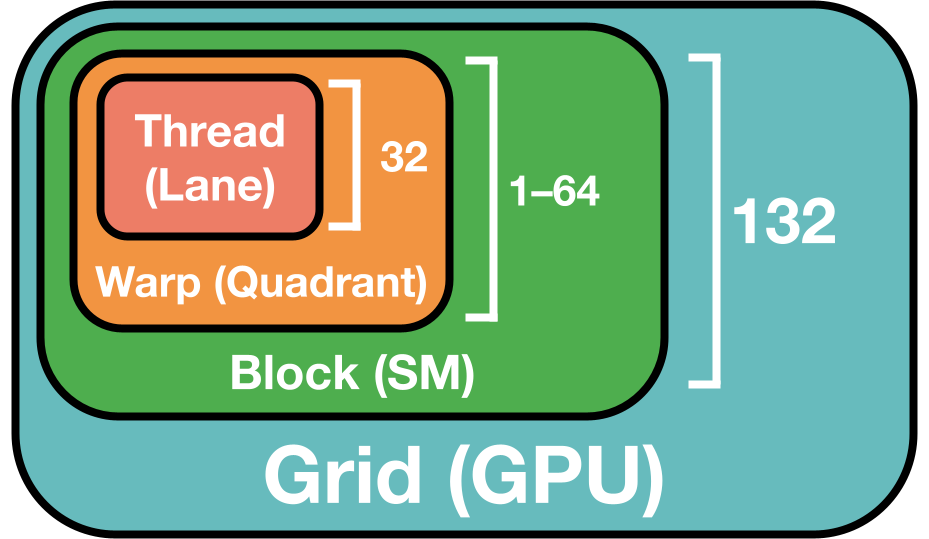
Figure 3: The software (and physical) GPU hierarchy.
2.1 GPU层次结构
GPU 软件层次结构紧密遵循其物理硬件层次结构(图3)。这里,我们说明其几个最重要的组件和方面:
1. Warps:由32个附近线程组成,在小型但快速的寄存器内存中操作数据。这些指令在各种物理执行单元上运行,这些单元专用于不同的计算操作(如下),不同线程可以同时占用不同单元:
(a) 加载和存储单元,用于将数据带入和带出寄存器。先进 GPU 还引入了专用硬件加速用于批量加载和存储【注,load/store,asyncCopy,TMA】。
(b) 通用计算管道,如用于 max、min 的 ALU,用于乘加的 FMA,以及用于复杂操作(如exp)的 XU。不同管道的吞吐量不同。
(c) 加速矩阵乘法硬件(Tensor Core),拥有大部分 GPU 计算能力。
2. 线程block(block):是 warps 的组,在物理核心(称为流多处理器 SM )上一起执行内核。尽管每个 SM 只有四个物理执行单元,但最多 64 个软件 warps 可以同时运行其上(称为“占用率”)。这些并列的 warps 经常竞争硬件资源:寄存器、共享内存、发射槽和计算管道,但它们一起可以帮助在每个执行单元内同时保持许多工作流运行。warps 在屏障处同步,在此期间它们不能发射新工作【注,遇到barrier之后,直到整个block 都到达,这期间,早先到达的thread或warp不能发射指令;】。
重要的是,同一 block 内的 warps 可以通过特殊的共享内存(SMEM,227 KB,33 TB/s)快速通信。为了提高带宽,SMEM 被分组为 32 个物理“bank”,可以同时提供内存。然而,如果不同线程尝试同时访问同一 bank(称为 bank 冲突),它们的访问必须序列化,这既增加了访问延迟又减少了可用带宽。Hopper 每个线程限制 255 个寄存器,尝试请求更多会导致溢出到 L1 缓存【注,local mem 的三种分配情景之一】。SMEM 可以重新分配为 L1 缓存,用于快速访问常用内存(如溢出寄存器)。
3. 网格:启动多个线程 block 来运行内核。H100 SXM GPU 有 132 个物理 SM,可以同时运行线程 block。尽管 SM 能够并列多个线程 block,但大多数 AI 内核可以通过在单个线程 block 中并列更多 warps(增加占用率)来实现高性能。
同一 GPU 上的线程 block 共享公共内存资源【注,指显存】:大但慢的高带宽内存(80 GB,3 TB/s),其延迟最大且带宽最小,以及较小但更快的 L2 缓存(50 MB,12 TB/s)。
调度 block 有开销。首先,block 启动会产生设置成本,尽管初始内核启动至少支付一次成本,但连续启动许多大 block 的内核会产生进一步成本。其次,如果 grid 大小调整不当,会有尾效应成本。如果在有 132 个物理 SM 的 H100 上执行 133 个 block 的内核,内核需要两波执行,第一波全效率,第二波效率<1%。
2.2 成本模型
除了减少总工作量,减少执行时间的另一种关键方法是同时重叠多种工作。总结上述组件,我们提供了一个简化的 GPU 并行性成本模型。我们将总体内核执行时间 分解为:
其中内存成本是延迟和带宽的组合,计算成本是延迟和吞吐量的组合。
该模型代表了内存、计算和 Tensor Core 成本之间完美重叠的理想情况。内核的实际性能将介于这些组件的最大值 与 总和之间【注,总和时间意味着完全没有隐藏延迟】,取决于工作负载属性(即某些操作本质上是顺序的)以及其实现效率。尽管如此,我们的探索将试图(1)减少这些单独成本,以及(2)提高它们共同的重叠。
2.3 GPU编程框架
我们受到许多简化 AI 内核开发的相关努力的启发,如 NVIDIA CUTLASS/CuTe [29] 和 Triton [39]。
CUTLASS 的大量嵌套 CUDA 模板有助于驱动高度优化的 AI 内核 [37, 8, 9],基本上,相同的内核可以在 TK 和 CUTLASS 中表达,因为两者都是嵌入式库,赋予用户 C++ 的全部能力。我们采取互补方法,对抽象有明确主张。我们问:(1)少量模板能走多远?(2)简洁会牺牲性能吗?一个吸引人的结果是对 AI 研究人员的易用性提高,因为充分利用 CUTLASS 的能力可能具有挑战性[9]。我们发现即使是用 CUTLASS 编写的工业流行内核(如 FlashAttention-3)也遭受可防止的问题(如 bank 冲突)的困扰。我们寻求为用户管理此类问题的抽象。大多数最近的 AI 架构改用高级编译器 [13, 44, 20]。
Triton、PyTorch [31]、TVM [10]、TensorFlow XLA [1] 等从编译器角度处理问题。这些框架不是 C++ 嵌入式的,因此使用不支持的专用硬件指令可能具有挑战性【注,是指编译器还没来得及支持的某些新颖的硬件特性】。在高级框架中管理异步执行和寄存器使用也可能很困难。我们在下一节探索保留简洁、类似 PyTorch 感觉并实现高性能的途径。相关工作的扩展讨论在附录 A 中。
3 ThunderKittens
我们提出 ThunderKittens(TK),一个旨在简化高性能 AI 内核开发同时利用现代GPU全部能力的框架。本节(1)介绍我们的关键编程抽象,以及(2)展示它们如何帮助开发者在不同类型并行性之间有效地处理权衡。第3.1节关注 warp 级别,第3.2节关注线程块级别,第3.3节关注网格级别并行性。
作为本节的运行示例,我们展示 TK 如何帮助优化注意力[41]和 GEMM 内核。第4节演示这些原则如何为广泛的 AI 操作(如注意力变体、卷积、SSM、旋转)产生高性能内核。
3.1 使用熟悉数据结构和操作的 warp 并行性
ThunderKittens 的核心建立在两个基本抽象上——内存层次结构每个级别的瓦片数据结构(tile data structures),以及类似 PyTorch 和 NumPy 熟悉操作套件的瓦片上的批量操作数(bulk operands on tiles)。我们首先定义抽象,然后展示它们如何帮助开发者在块大小和效率之间有效地处理权衡。
编程抽象
TK 深受 PyTorch 和 NumPy 的启发,因为它们对 ML 受众很熟悉[31]。我们提供了一组简洁的并行计算操作,基于 PyTorch 中的操作套件(例如图2)。操作由“工作者”抽象执行,或一个warp 或 warpgroup(4个 warps)的线程,它们协作拥有并操作一块数据。TK 使用 16x16 矩阵 tile 作为其基本数据结构,旨在最大化与 Tensor Core 的兼容性。我们为内存层次结构的每个级别提供块:
-
寄存器 tile 和 vector,由类型、形状和布局模板化。在 图2 中,我们初始化一个 bfloat16 类型 tile,具有列优先布局,高度16,宽度64。
-
共享 tile 和 vector,由类型和形状模板化。
-
全局布局描述符:我们将 HBM 加载和存储设置为索引到 4D 张量(类似于 PyTorch 中的{batch, head, length, embed})。维度可以在编译时或运行时已知。编译时维度可以存储在指令缓存中,节省寄存器。
这些基于 tile 的抽象的一个优点是它们使 TK 能够静态检查布局和操作,这很重要,因为 GPU 内核通常难以调试。例如,寄存器内 Tensor Core 乘法 mma_AB 要求 A 处于行优先布局,B 处于列优先布局,如果这些条件不满足,TK 可以引发编译时错误。
Figure 4: Shared memory bank layouts, illustrated for a 16x64 16-bit tile. Top left: A naive, row-major layout. Although loading rows is efficient, loading into a tensor core layout suffers 8-way bank conflicts. Top right: A padded layout, which has no bank conflicts but consumes additional memory and has poor hardware support. Bottom: Two of TK’s three chosen layouts, with compile-time selection based on width. (Bank conflicts are unavoidable for some tile sizes while maintaining good hardware support.) These layouts have 2-way and no bank conflicts, respectively.
选择内存布局
布局指定逻辑数据元素如何映射到物理线程所有权。不同的执行单元、tile 大小和类型以及硬件加速指令受益于不同布局。布局选择不当会导致 bank 冲突( ,第2节)。我们的目标是:
-
我们希望我们的寄存器 tiles (最快的GPU内存)默认将内存保持在 Tensor Core 单元(最快的GPU计算单元)所需的布局中。如图1(左)所示,其中每种颜色代表不同线程对数据元素的所有权,张量格式相当难以使用和推理,我们在图4中对朴素布局的讨论中强调了这一点。
-
我们希望支持使用硬件加速指令(例如异步矩阵乘法和批量复制指令),这些指令也需要特定的共享内存布局。
在 TK 中,我们将搜索空间简化为3种布局——跨步为32、64和128字节——并自动为 tile 大小支持的最大布局提供共享 tiles,以最小化 bank 冲突。第4.2节强调,即使使用 CUTLASS 和 CuTe 模板编写的优化 FlashAttention-3 内核也遭受 bank 冲突,损害性能。我们的方法有助于最小化冲突。
3.2 使用通用异步模板实现块级并行
ThunderKittens 通过协调线程块内工作者(workers)如何异步重叠执行来帮助开发者减少开销。尽管 GPU 层次结构可能暗示我们需要多种技术,但我们提出了一个单一简洁的模板,我们发现它能在惊人广泛的 AI 工作负载上实现高性能。我们首先定义这个模板,它有四个步骤——加载-计算-存储-完成(简称 LCSF)——并建立在经典的生产者-消费者范式[16, 7]之上。然后我们展示 LCSF 模板如何帮助开发者在占用率(occupancy)和效率之间进行权衡。

编程抽象
如第2节所述,AI 内核的通用模式是将大张量的块(tiles)从 HBM 加载到 SRAM(共享内存),在快速内存(如寄存器和SRAM)中执行计算,将结果块存储回 HBM,并为下一个块重复此过程。要使用 LCSF 模板,开发者需要编写四个函数:
-
加载函数 (Load function):加载函数指定加载工作者应将哪些数据从 HBM 加载到共享内存,以及何时向计算工作者发出信号表明该内存已准备就绪可使用。
-
计算函数 (Compute function):此函数指定计算工作者应执行的内核指令,使用第3.1节中的 tile 数据结构和操作原语。
-
存储函数 (Store function):存储函数指定存储工作者需要将哪些数据存储到 HBM。
-
完成函数 (Finish function):在内核结束时,工作者们存储任何最终状态并退出。
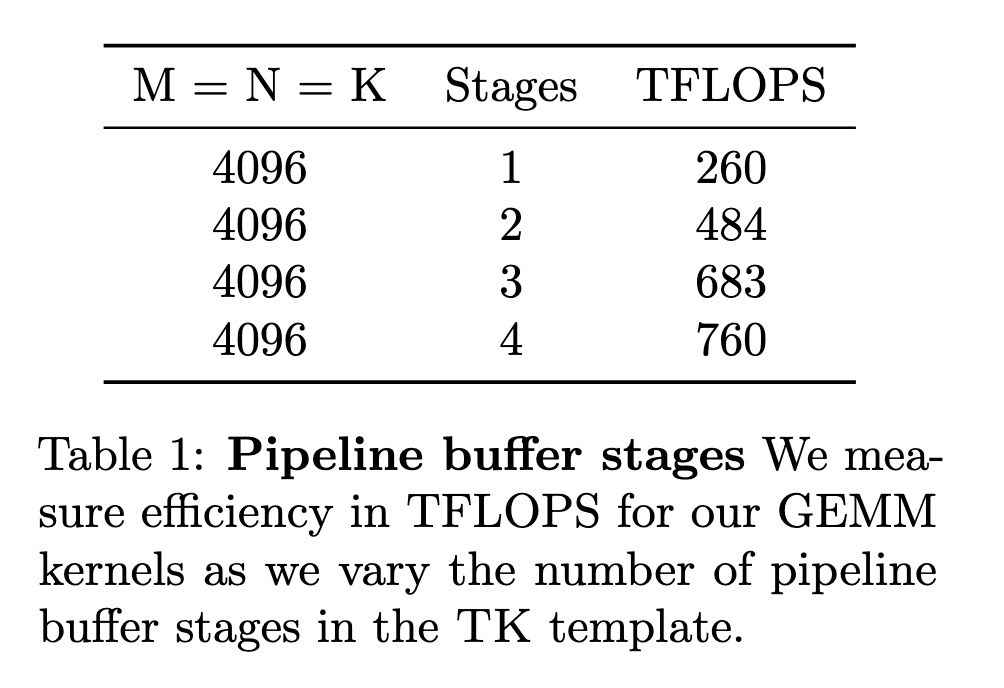
Table 1: Pipeline buffer stages We measure efficiency in TFLOPS for our GEMM kernels as we vary the number of pipeline buffer stages in the TK template.
TK 提供抽象来帮助开发者管理工作者的重叠和同步。
-
多级缓冲区 (Multi-stage buffer):模板在共享内存中维护 N 级流水线缓冲区,用于 HBM 的加载和存储。加载/存储工作者根据计算工作者的状态向缓冲区添加/移除数据块。如果只有单级,加载工作者需要等待所有计算工作者执行完毕才能替换输入块。2级缓冲区可以隐藏 HBM 加载(存储)延迟,因为下一个 tile 可以异步加载,而计算工作者在当前 tile 上执行。更深的缓冲区可以减少计算工作者之间所需的同步量,允许它们同时在不同的块上操作。
TK 让用户设置一个数字来指定级数,并为用户管理这些缓冲区的设置和使用。我们在 表1 中演示了这一点,其中我们为 GEMM 内核改变了级数。
-
同步屏障 (Synchronization barriers):当新内存写入输入缓冲区时,加载/存储工作者需要通知计算工作者。当 tile 写入输出缓冲区,或输入 tile 可以从输入缓冲区逐出时,计算工作者需要通知加载/存储工作者。在 TK 模板内,我们提供了一个
arrive函数,供工作者发出信号表明它们已完成其阶段。 -
异步I/O (Asynchronous I/O):我们将同步和异步的加载及存储指令(包括
cp.async和TMA)封装在同一接口中。我们为全局布局描述符(gl)自动创建 TMA 硬件加速地址生成所需的张量映射描述符。
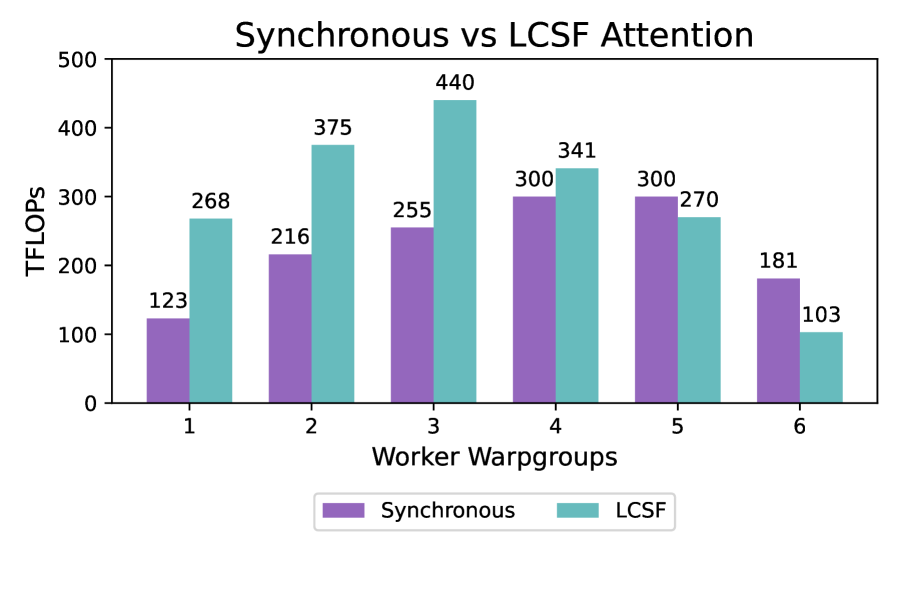
Figure 6: Occupancy tradeoff: (Left) Attention TFLOPs as a function of occupancy, benchmarked with head dimension 64 and a sequence length of 4096. We compare a basic synchronous and LCSF kernel.
占用率与效率之间的权衡
TK 参数化了加载/存储和计算工作者的数量(或称占用率),为开发者调整其内核提供了一种简单的方法。如第2节所讨论,更高的占用率增加了重叠性,但也会对有限的硬件资源(例如寄存器)产生争用。寄存器较少时,工作者需要在更小的数据块上操作,导致更多的指令发射、SRAM到寄存器的I/O,以及由于跨工作者数据分区增加而可能产生的更高同步成本。
图6 显示了注意力内核的占用率权衡。我们考虑了(1)仅使用 warp 级并行性的简单内核(列表2)和(2)使用 LCSF 模板编写的内核(列表5)。对于这两个内核,性能都会提高,直到资源争用占主导地位。其次,我们观察到,随着我们改变占用率,LCSF 将帕累托边界(Pareto frontier)扩展到了 warp 级并行内核之外。
我们发现通用的 LCSF 模板在一系列 AI 工作负载上都是有效的。我们通过做出明确的设计选择来保持模板的轻量级和简单性。但是,我们不希望 TK 妨碍实现峰值 GPU 性能——与 Triton 等框架不同,TK 是嵌入式的,这意味着开发者可以使用 C++ 的全部功能来按需扩展库。
3.3 使用 block 启动调度实现 grid 级并行
接下来,在网格级别,我们探索如何协调线程块启动。TK的模板不会为用户明确选择网格结构,但是我们提供了两个关键机会的权衡研究:减少每个线程块的设置和销毁成本(𝐂Setup),以及鼓励线程块之间的内存重用以避免缓慢的HBM访问(𝐂HBM)。
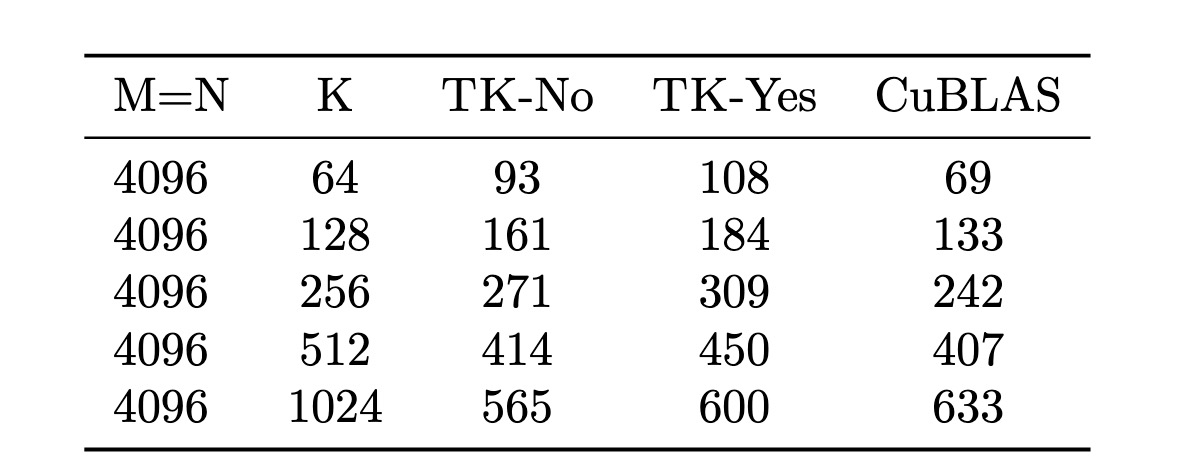
Table 2: Persistent block launch TFLOPS for TK GEMM kernels with (yes) persistent and without (no) persistent launch as we vary matrix dimension K.
Block 启动成本 (Block launch costs)
我们首先探索使用持久化网格(persistent grid),即我们预先在全部132个 SM 上启动线程块,并简单地在现有块内为内核加载下一块工作,而不是启动一个新块。我们还探索了让线程块在运行前一块工作的完成阶段的同时,将共享内存加载到模板内存缓冲区的输入阶段以为下一块工作做准备的想法。表2 显示了这些优化对我们的 GEMM 内核的好处。
L2重用与块启动顺序 (L2 reuse and block launch order)
回顾一下,线程块需要通过HBM进行通信。如第2节介绍,当线程块重用内存时,数据通常可在L2缓存中获得,这比 HBM 快得多。然而,缓存驱逐意味着这些重用特性取决于块启动的顺序。对于我们的注意力和 GEMM 内核,我们测量了改变块顺序时的效率,总结在 表3 中。块顺序显著影响L2重用(通过HBM带宽测量),这反过来又可以控制内核性能。

Table 3: L2 reuse We vary the block orders and measure both consumed bandwidth from HBM (GB/s) and efficiency (TFLOPs). For attention, we consider an optimized kernel, with an internal tiling of 8 rows of blocks, versus a naive kernel that schedules blocks in row-major order. For attention, we compare block order (1) sequence length N, heads H, and outermost batch B vs. (2) innermost B, H, then outermost N. Different block orders have significant performance implications.
4 实验
在实验中,我们验证了 ThunderKittens 能够加速广泛的ML原语。我们与先前工作中使用其他框架(如 CutLass、CuBLAS、通用 CUDA 和 Triton )编写的优化良好的内核进行了比较。我们比较了我们的内核在 AI "主力"操作(GEMM 和注意力)以及新兴AI架构(如线性注意力和状态空间模型)上的性能(第4.1节)。我们在第4.2节中对内核进行分析,以了解 TK 在实现高性能中的作用。TK模板中的内核列表见附录B。
Figure 7: GEMM kernel from CuBLAS and TK.
4.1 TK实现了简洁且高性能的AI内核
本节展示了我们在TK框架中开发的一套内核。我们在 NVIDIA H100 80GB SXM GPU 上使用 CUDA 12.6 对内核进行基准测试,并报告平均 TFLOPS(每秒万亿次浮点运算)。
AI的主力内核
工业界团队和研究人员在过去几年中为优化 GEMM 和注意力投入了大量资源,这两个主力操作支撑了Transformer架构。尽管有这些投入,完全使用TK抽象和LCSF模板编写的TK内核可以匹配或超越最强的基线:
-
GEMM:我们与最强的可用基线进行比较:用于 GEMM 的 CuBLAS。我们展示了一个仅用40行设备代码的单一矩阵乘法内核,即可与 CuBLAS 竞争
-
注意力:我们支持多种注意力变体:头维度为 64 和 128 的因果、非因果以及分组查询注意力。我们与最强的可用基线(与我们工作并发)进行比较:FlashAttention-3(FA3)。TK在非因果前向传播上在不同序列长度下与FA3竞争,并在因果和非因果反向传播上超越 FA3,在短序列上超过40%,在较长序列上超过10%
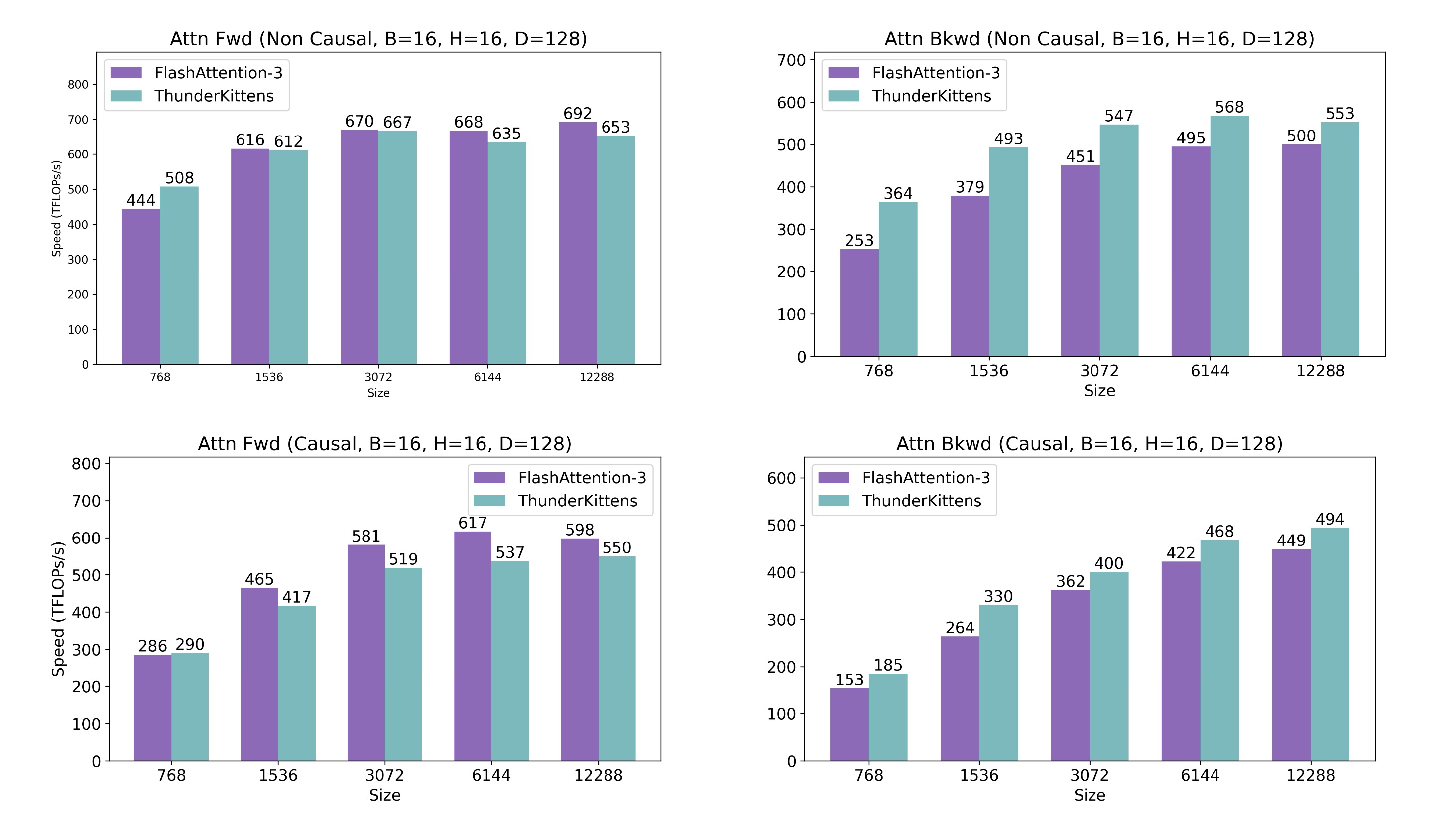
Figure 8: Attention causal and non causal inference and backwards pass efficiency.
我们发现TK通过简化内存布局的选择、探索L2重用的网格模式以及选择占用率和流水线深度,使得有效使用GPU变得容易。基线内核成功使用了专用的H100指令并管理了内存。然而,现有的内核相对复杂:FlashAttention-3为工作者提出了一个"乒乓调度器",而 CuBLAS 库在 CUDA 12.6 中大于 600MB,包含许多调优的 GEMM 变体和在运行时选择最佳选项的逻辑。使用TK,我们移除了乒乓调度并保持了 FA3 级别的效率,并且我们使用单一 GEMM 内核在所示矩阵大小上与 CuBLAS 竞争。
新兴AI架构的内核
除了在流行操作(如 GEMM 和注意力)上支持峰值性能外,TK 还设计为可扩展到新兴的 AI 工作负载。我们发布了一系列跨越新型机器学习原语的内核,包括线性注意力、FFT 卷积和状态空间模型。
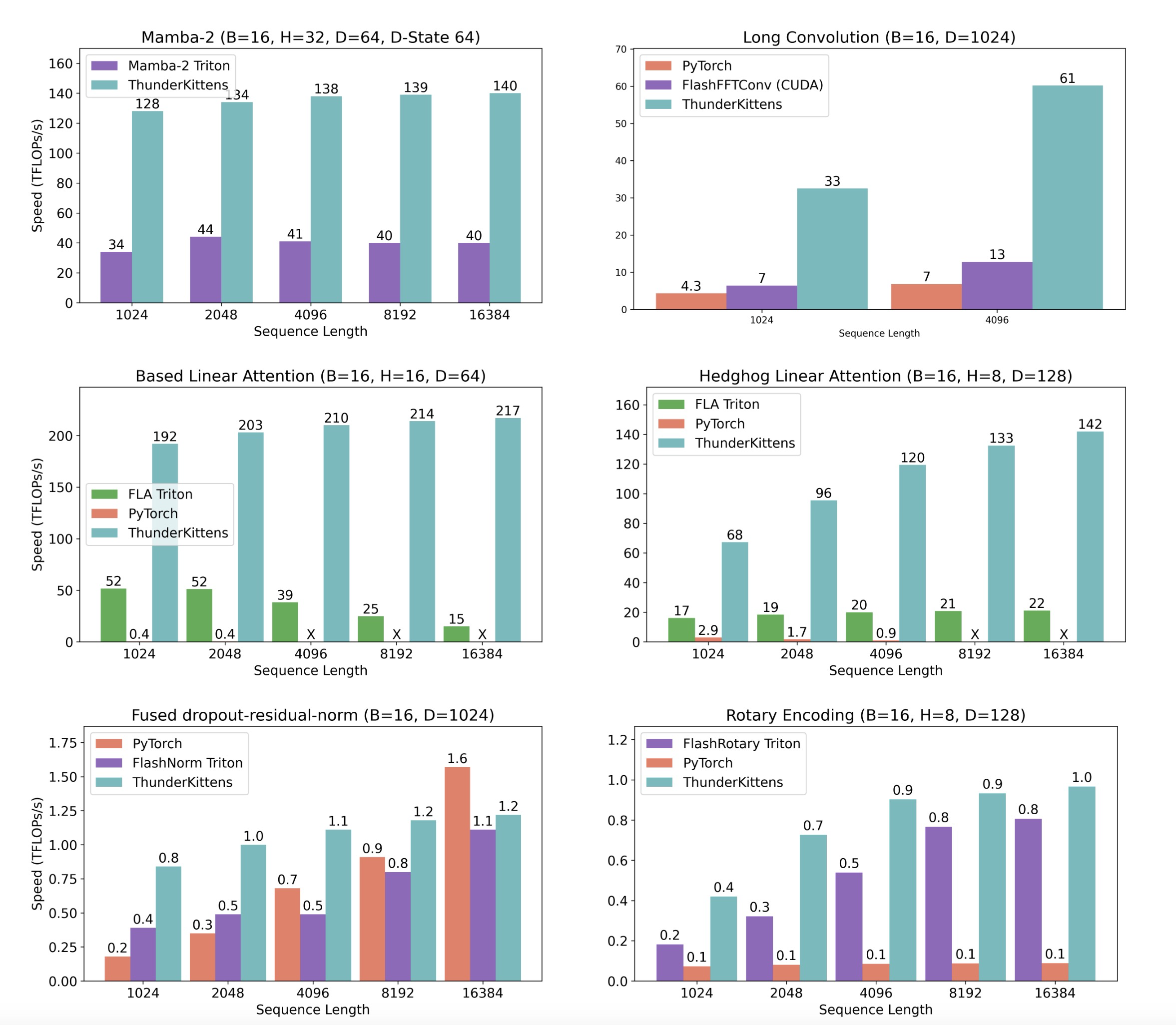
Figure 9: ThunderKittens kernels are performant across a wide range of kernels. We benchmark the kernels on an 80GB NVIDIA H100 GPU and report TFLOPs.
-
线性注意力:我们优化了两类不同的线性注意力架构:基于多项式的特征映射和学习的特征映射。我们与最强的可用基线进行比较:流行的用Triton编写的Flash Linear Attention(FLA)CUDA内核。我们显示TK在基于多项式的线性注意力上性能超过 FLA 14倍。TK在学习的映射线性注意力上性能超过FLA 6.5倍
-
状态空间模型:使用卷积定理通过傅里叶变换实现的长卷积是流行状态空间建模架构(如S4、H3 和 Hyena)中的关键原语。我们与最强的可用基线进行比较:Fu 等人中的FlashFFTConv CUDA内核,并显示TK在序列长度4096时性能超过先前工作 4.7 倍,在 1024 时超过 7.9 倍。TK 性能超过 PyTorch 的 FFT 操作最多8.7倍
我们还优化了最近的 Mamba-2 状态空间模型。我们提供了一个TK内核,其性能超过先前工作中 Dao & Gu 的 Triton 内核 3 倍以上。这种差距主要源于在TK中融合复杂操作的便利性。
TK 中的抽象——包括专用指令(如 TMA 和 WGMMA)以及用于有效管理寄存器内存的寄存器块——促成了这些巨大的改进。基线内核没有使用这些 GPU 特性。
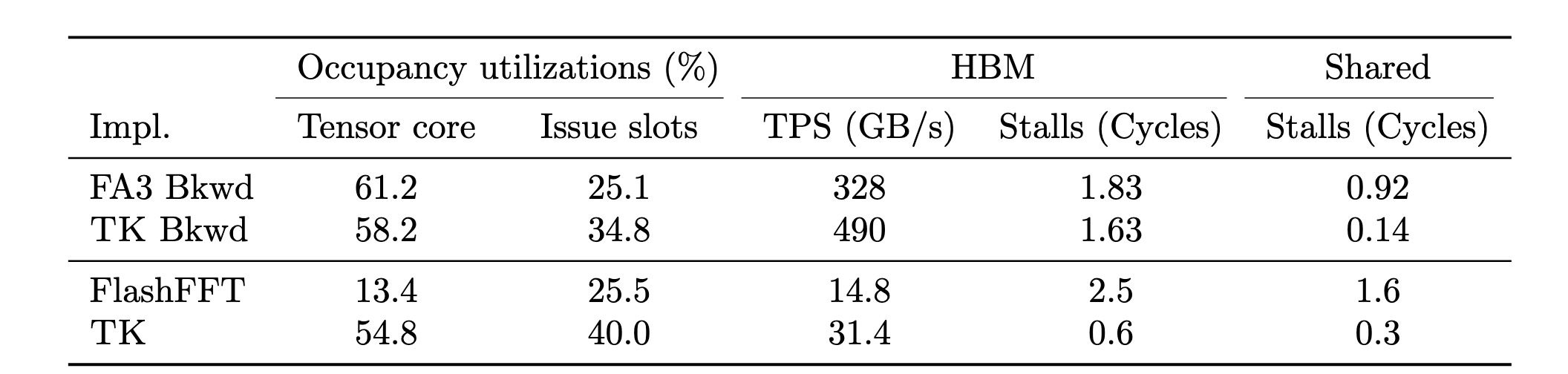
Table 4: Profiles for 1) attention backwards pass kernels from FlashAttention-3 [37] vs. TK and 2) long convolution kernels from FlashFFTConv [20] vs. TK, obtained using NVIDIA NSight Compute.
TK的编程模型是可扩展的
我们为常见的AI内存操作——融合 dropout-residual-layernorm 和 rotary ——开发了内核,并表明 TK 是有效的。我们与这些操作的流行 Triton 内核进行了比较。
4.2 比较内核实现
为了进一步比较TK和基线内核,我们使用 NVIDIA 的 NSight Compute(NCU)工具对内核进行了分析。在表4中,我们提供了新兴的长卷积原语和经过良好优化的注意力反向传播的NCU分析结果,并与各自最强的基线进行了比较。
-
长卷积:我们在NCU中分析了FlashFFTConv(FC)和TK长卷积内核。我们发现TK有助于重叠工作者(表现为更高的发射槽利用率和更少的内存停滞)和提高张量核心利用率(增加4.1倍)。这是通过我们的TK模板以及使用TK warpgroup操作实现的
-
注意力反向传播:我们考虑了 FA3 和 TK。两种方法的张量核心利用率匹配,但 TK 提供了更高的发射槽利用率,表明占用率可能得到了更好的调优。在 HBM 成本方面,TK 提供了更高的内存吞吐量,相应地因等待 HBM 而导致的停滞周期减少了10%。对于共享内存,TK的停滞周期减少了85%——我们发现 TK 没有 bank 冲突,但 NVIDIA 的 NCU 分析器报告 FA-3 中存在高达 9.6 路的bank冲突
内核分析结果凸显了同时管理每种类型 GPU 并行性的难度,我们希望 TK 可以帮助减少这方面的努力。我们在附录B中提供了示例 TK 内核列表。
5 结论
鉴于将AI架构映射到 GPU 硬件的挑战,我们的工作探讨了使用少量易于使用的GPU编程抽象能走多远。在 ThunderKittens 中,我们为 GPU 层次结构的每个级别提供了一个抽象:工作者级别的具有托管布局的块,以及线程块级别的异步执行 LCSF 模板。我们重点介绍了网格级别持久化块启动和 L2 重用的选项和权衡。一个自然的问题是,当我们用如此少的抽象编写内核时,是否会在性能上有所牺牲。我们在 TK 中实现了广泛的 AI 内核,并令人兴奋地发现我们的抽象既通用又始终达到或超过了最先进的水平。我们对简单易用的AI硬件编程方式的潜力持乐观态度。
为支持未来的开发,我们的框架和内核已在以下地址开源:https://github.com/HazyResearch/ThunderKittens。
6 致谢
我们感谢Together.ai使这项工作成为可能。我们感谢Arjun Parthasarthy在开发复杂块支持和FlashFFT内核方面提供的帮助。我们感谢Mayee Chen、Tri Dao、Kawin Ethyarajh、Sabri Eyuboglu、Neel Guha、David Hou、Jordan Juravsky、Hermann Kumbong、Jerry Liu、Avner May、Quinn McIntyre、Jon Saad-Falcon、Vijay Thakkar、Albert Tseng、Michael Zhang在本工作期间提供的宝贵反馈和讨论。我们衷心感谢NIH、NSF、美国DEVCOM ARL、ONR、Stanford HAI以及众多工业界合作伙伴的支持。BFS获得Hertz Fellowship支持,SA获得SGF Fellowship支持。美国政府有权复制和分发用于政府目的的再版,尽管其上可能有版权标记。本材料中表达的任何意见、发现、结论或建议均为作者的观点,不一定反映NIH、ONR或美国政府的观点、政策或认可。
参考文献:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)