从混合推理到智能体落地:DeepSeek 3.1如何改写开源大模型竞赛规则
当全球目光仍聚焦于谁能率先把大模型塞进终端设备时,DeepSeek 3.1的发布把焦点重新拉回云端:它用一套同
当全球目光仍聚焦于谁能率先把大模型塞进终端设备时,DeepSeek 3.1的发布把焦点重新拉回云端:它用一套同时容纳“快思考”与“慢思考”的混合推理架构,让单一模型在两种工作范式之间无缝切换。用户摁下界面上的“深度思考”按钮,模型便从闪电式回答转入链式推演,把完整推理过程摊开;关闭按钮,又立刻回到极简输出模式。这种一镜两面式体验不仅降低token消耗20%至50%,还把响应时延压缩到上一代旗舰模型的七成以内,直接回应了商业场景对“成本—速度—质量”三角的苛刻约束。
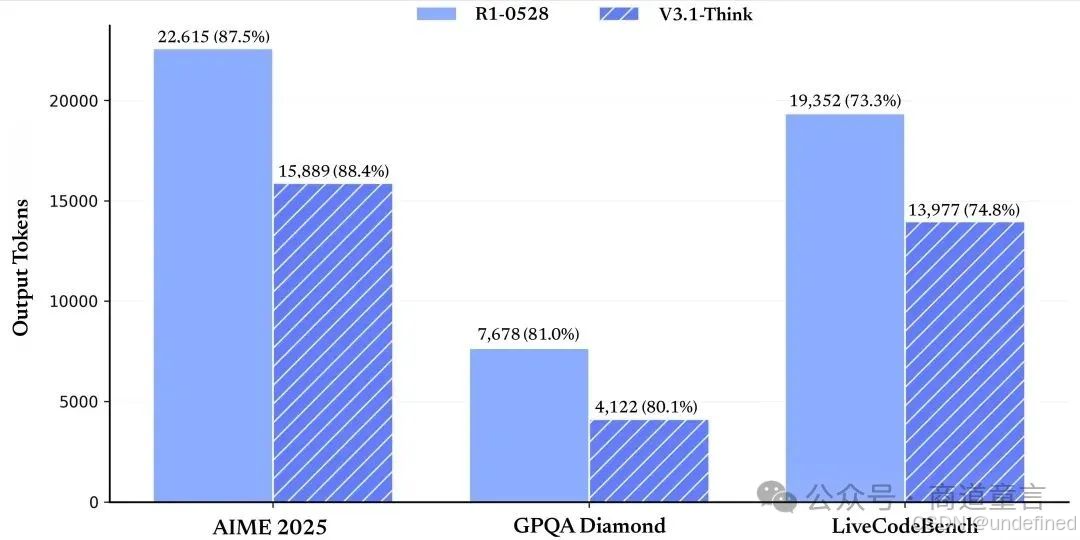
在各项评测指标得分基本持平的情况下(AIME 2025: 87.5/88.4, GPQA: 81/80.1, liveCodeBench: 73.3/74.8),R1-0528 与 V3.1-Think 的 token 消耗量对比图
更长上下文是另一块基石。新版把窗口一口气拉到128 K tokens,相当于一口气吞下十万汉字,一套《红楼梦》的六分之一体量。对金融、法律、科研等长文档密集行业来说,这意味着可以把整份招股书或实验报告一次性喂给模型,而不必再费心切块、拼接、校验。实测显示,在同样硬件条件下,DeepSeek 3.1的吞吐量比同级别的开源对手高出近一倍,显存占用却并未等比例膨胀,工程团队给出的解释是“两阶段长上下文扩展”训练法——先用32 K窗口做10倍数据扩充,再升到128 K做3.3倍精细微调,总计新增8400亿tokens,把长文本的稀疏注意力模式彻底吃透。

代码能力则像一把尖刀,直接把竞争拖进巷战。Aider多语言编程基准上,DeepSeek 3.1以71.6%的通过率力压Claude 4 Opus一个百分点,而单次完整编程任务的成本仅为1美元,相当于专有系统的六十分之一;在SWE-bench代码修复测试中,官方内部代理框架的轮数比开源OpenHands更少,Terminal-Bench命令行任务处理也显著提升。开发者社区把这份成绩单截屏转发时,往往配上一句“开源模型也能打硬仗”——它证明大模型不再需要天价预算才能写出可交付的工程代码。
真正让产业侧心跳加速的是“Agent 能力增强”。DeepSeek 3.1在后训练阶段针对工具调用和多轮代理任务做了定向优化:搜索智能体现在可以调用商业搜索引擎API并叠加网页过滤器,配合128 K上下文完成多跳问答;编程智能体则能在复杂终端环境里执行跨文件调试、依赖安装、回归测试。浏览基准browsecomp和多学科专家级难题HLE的测试曲线显示,新版本把上一代R1-0528远远甩在身后。业内评价认为,这等于把原本“对话即终点”的大模型推向“对话即起点”的Agent时代——模型不再是回答问题的终点,而是调用工具、执行任务、完成交付的起点。
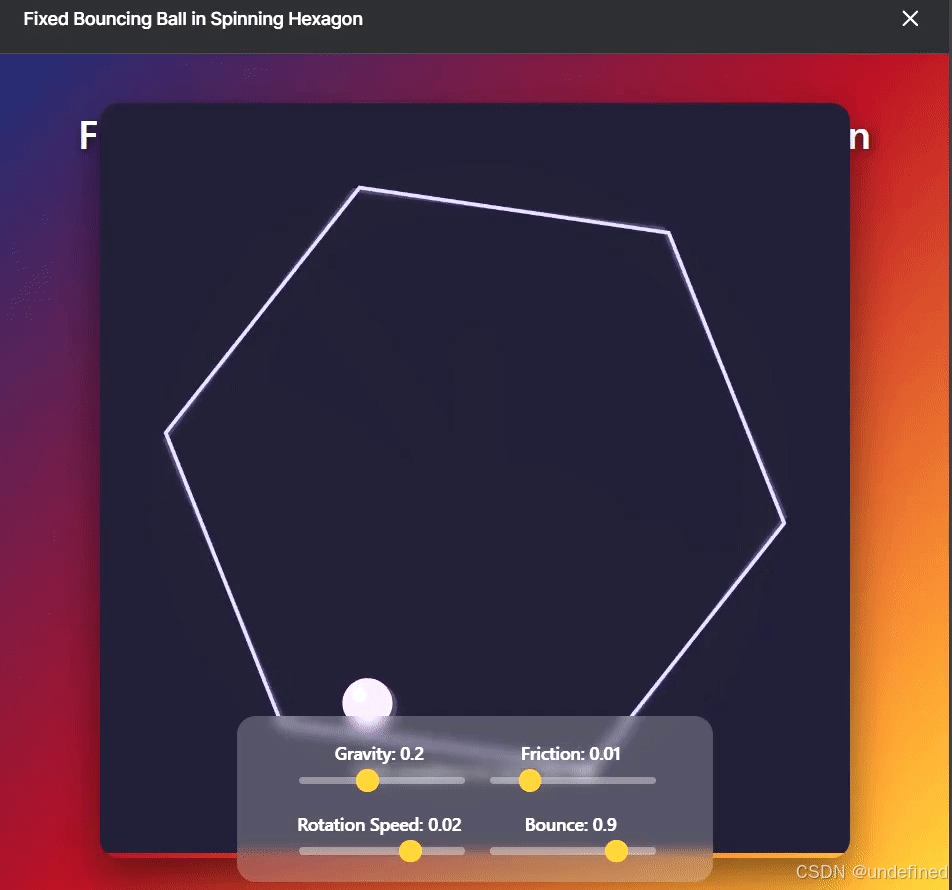
一位网友实测,模拟六边形中小球自由落体的物理测试,DeepSeek V3.1理解力明显提升。
大洋彼岸的观察者迅速给出高规格注脚。VentureBeat罕见地以“目前最强大的开源人工智能”为其定性,并指出多项指标已可与GPT-4o、Llama 3.1等商业旗舰正面抗衡;Reddit开发者板块的置顶帖里,“终于可以把Claude从CI流水线里拔掉”成为高赞回复。资本市场的嗅觉更加敏锐:Benchmark合伙人把DeepSeek 3.1的训练成本——约600万美元——与Meta Llama 3.1 405B的6000万美元并置,得出“以一当十”的性价比结论,暗示开源路线正在击穿闭源护城河。
DeepSeek 3.1所取得的显著成就,不仅有力证明了中国人工智能团队卓越的自主创新实力,更充分展现了开源协作模式下汇聚的集体智慧与强大动能。展望未来,可以预见的是,DeepSeek与Meta、OpenAI等行业巨头之间围绕“开源”与“闭源”战略路径的竞争态势必将愈发激烈。数字经济应用实践专家骆仁童博士表示,在广大多元用户群体及企业的自主选择与积极支持下,人工智能行业的生态格局有望突破传统模式——不再由少数封闭型科技巨头垄断主导,更多兼具实用性、开放性与高性价比的技术解决方案,或将如雨后春笋般在全球各个角落生根发芽、广泛应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)