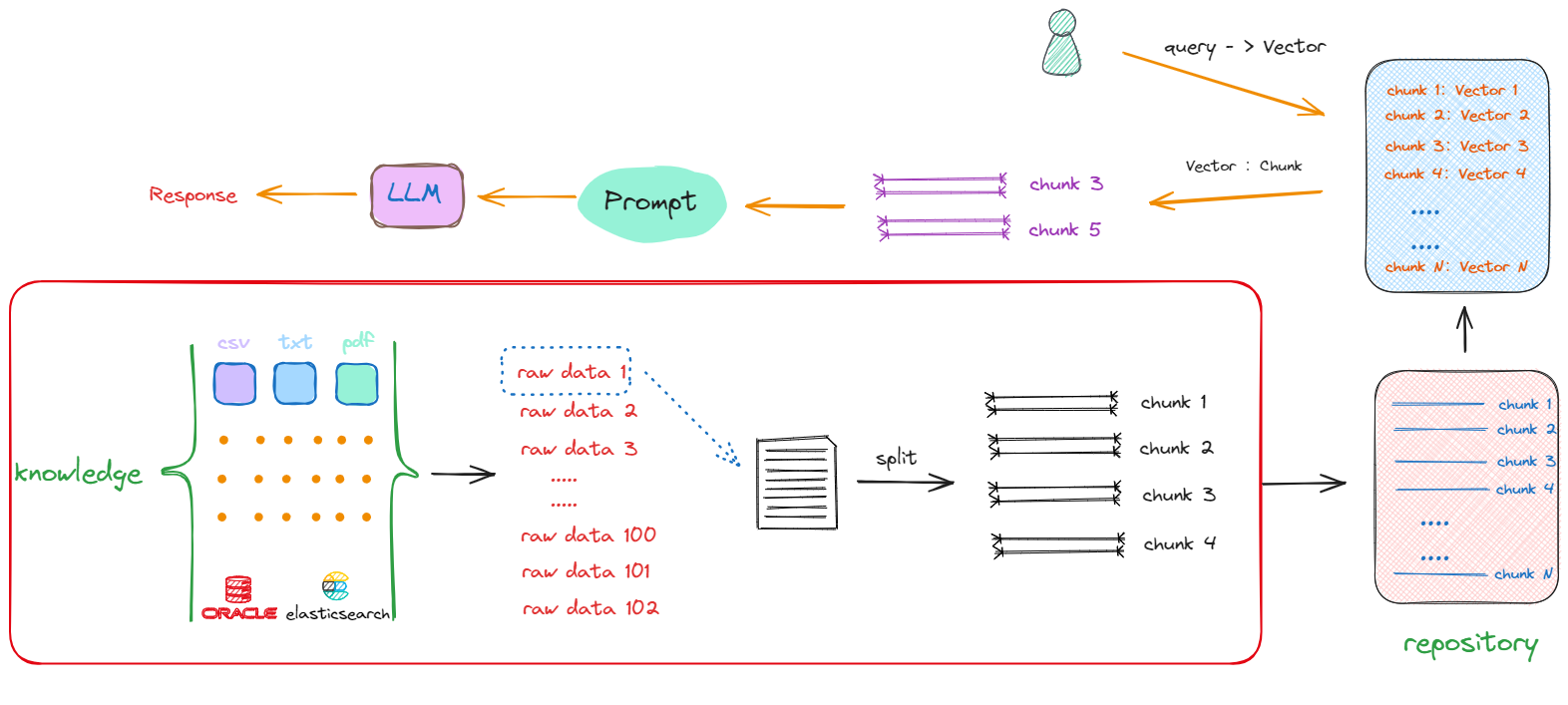
LangChain RAG系统开发基础学习之LangChain 接入向量模型
LangChain RAG系统开发基础学习之LangChain 接入向量模型
文章目录
说明
- 本文学自赋范课堂九天老师公开课,仅用于学习和技术交流使用,不用作任何商业用途,最终著作权归九天老师及其团队所有!
一 Embedding模型
- 从本质上来说,将文本“chunks”(如单词、短语或句子)转换成向量的过程只是一个简单的编码(
Encoding)问题。在这个阶段,没必要去纠结Embedding模型的底层原理,只需要懂得如何对具体的需求,找到最合适的Embedding模型,拿来直接用即可。 - 同样的道理适用于向量数据库。虽然大多数向量数据库的基本功能和使用技巧相似,但每个数据库都有其独特的特性和优点。我们需要的具备的能力是根据自己数据的特点,选择最合适的向量数据库。然后再花时间去学习和掌握该数据库的高级应用技巧,一定要避免将时间浪费在不必要的学习上。
- 在
langchain的原生数据处理流Data connection中,Embedding Models所处的位置如下图红框内。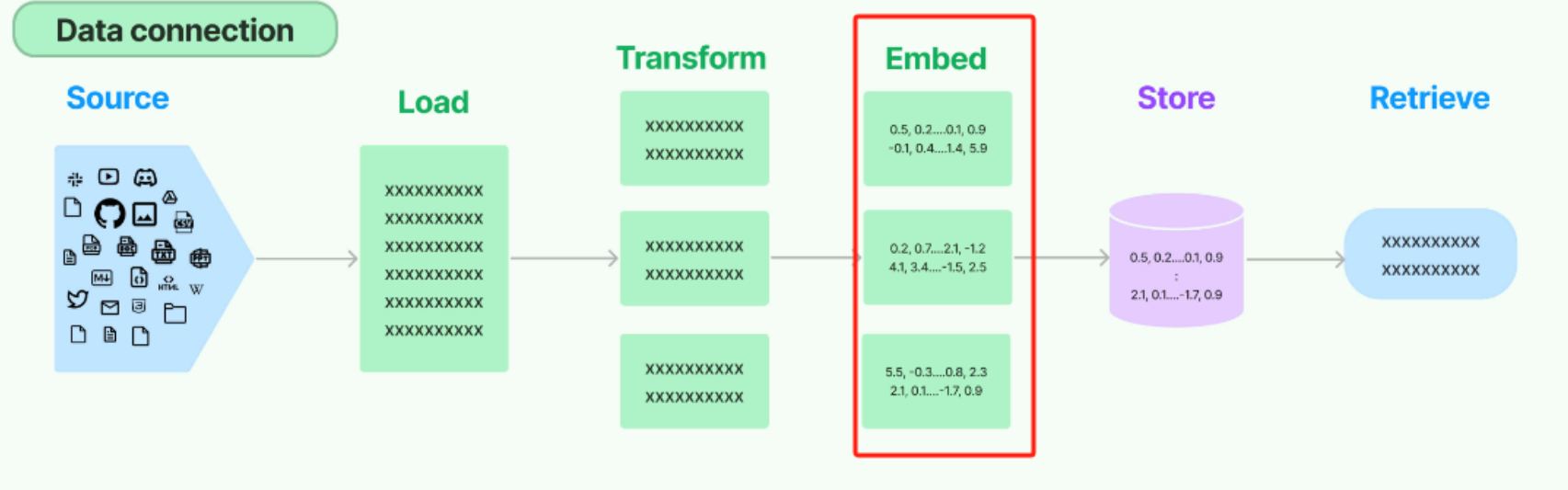
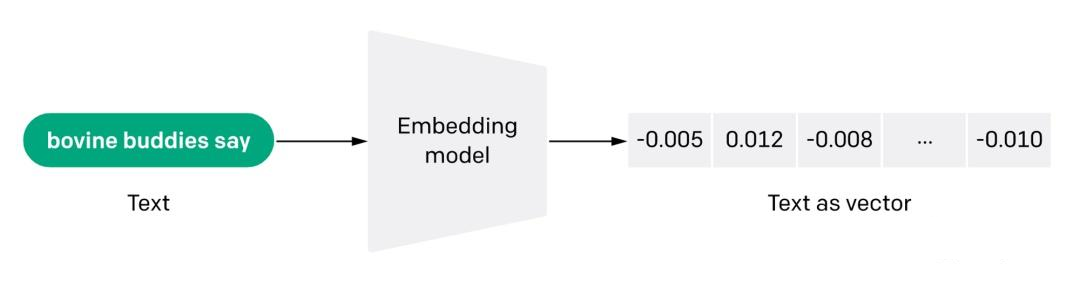
LangChain中的Embeddings基类提供了两种方法:一种用于Embeddings文档对象,另一种用于Embeddings查询(Query)。前者采用多个文本作为输入,而后者采用单个文本。- 在使用形式上把
Embedding Models分为两类:- 在线
Embedding Models:以OpenAI的text-embedding-3为代表,仅提供API服务,需要按照Token付费; - 开源
Embedding Models:以bge-base-zh-v1.5为代表,这类模型托管在Hugging Face或ModelScope平台上,可以下载到本地免费使用,但在运行过程中会消耗GPU资源。
- 在线
1.1 在线Embeddings Model接入
1.1.1 OpenAI Embedding模型接入
OpenAI的Embedding Model目前有三个,均只提供API形式的调用服务,可以在OpenAI官网查看相关的细节:https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
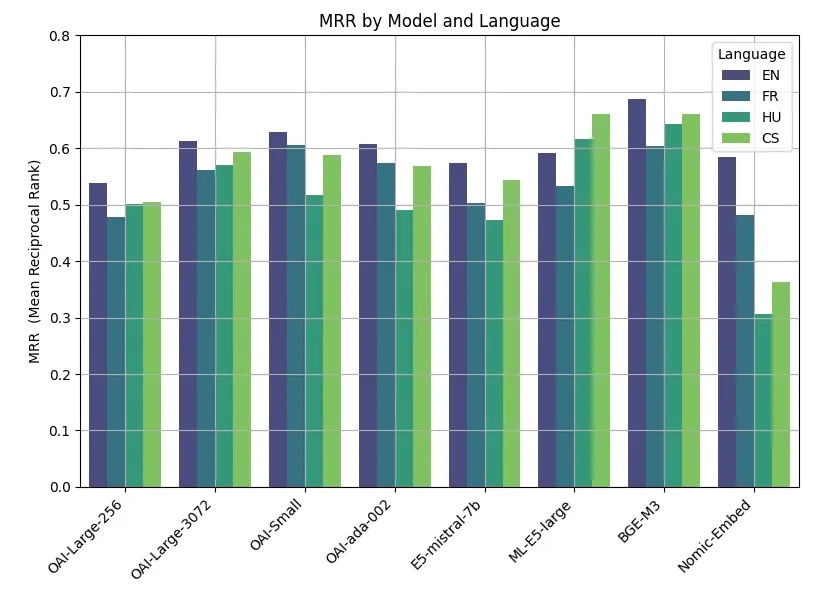
| Model | ~ Pages per dollar | Performance on MTEB eval | Max input |
|---|---|---|---|
| text-embedding-3-small | 62,500 | 62.3% | 8192 |
| text-embedding-3-large | 9,615 | 64.6% | 8192 |
| text-embedding-ada-002 | 12,500 | 61.0% | 8192 |
- 默认情况下,对于
text-embeddings-3-small,Embedding向量的长度为1536,而text-embeddings-3-large生成的向量长度则为3072。也可以通过传入dimensions参数来灵活的调整Embedding的维度,且OpenAI的官方说明,这样的调整并不会影响其生成的词表示的效果。
from openai import OpenAI
OPENAI_API_KEY="hk-xxx"
BASE_URL="https://api.openai-hk.com/v1"
EMBEDDING_MODEL="text-embedding-3-small"
client = OpenAI(api_key=OPENAI_EMBEDDING_API_KEY,
base_url=BASE_URL,
# dimensions=1024
)
text_vector = client.embeddings.create(
input="车到山前必有路",
model=EMBEDDING_MODEL
)
print(len(text_vector.data[0].embedding)) # 1536
- 在
LangChain框架中,使用OpenAI的Embedding,则需要借助到其已经封装好的OpenAIEmbeddings类。源码如下:
class OpenAIEmbeddings(BaseModel, Embeddings):
"""OpenAI embedding models.
To use, you should have the ``openai`` python package installed, and the
environment variable ``OPENAI_API_KEY`` set with your API key or pass it
as a named parameter to the constructor.
Example:
.. code-block:: python
from langchain_community.embeddings import OpenAIEmbeddings
openai = OpenAIEmbeddings(openai_api_key="my-api-key")
"""
def embed_documents(
self, texts: List[str], chunk_size: Optional[int] = 0
) -> List[List[float]]:
"""Call out to OpenAI's embedding endpoint for embedding search docs.
Args:
texts: The list of texts to embed.
chunk_size: The chunk size of embeddings. If None, will use the chunk size
specified by the class.
Returns:
List of embeddings, one for each text.
"""
# NOTE: to keep things simple, we assume the list may contain texts longer
# than the maximum context and use length-safe embedding function.
engine = cast(str, self.deployment)
return self._get_len_safe_embeddings(texts, engine=engine)
def embed_query(self, text: str) -> List[float]:
"""Call out to OpenAI's embedding endpoint for embedding query text.
Args:
text: The text to embed.
Returns:
Embedding for the text.
"""
return self.embed_documents([text])[0]
OpenAIEmbeddings继承自BaseModel和Embeddings,利用OpenAI的Embedding模型获取文本的Embedding向量。只包含两个函数:
embed_documents:将给定的文本列表转换成Embedding向量。它接受两个参数:texts: 需要转换成Embedding向量的文本列表。chunk_size: 指定每次处理的文本块的大小。如果为0或None,那么将使用类中指定的默认大小,默认为0。
embed_query:用于获取单个文本的Embedding向量。它是embed_documents函数的一个特例,专门用于处理单一文本输入。text: 需要转化为Vector的单个文本。- 函数内部通过调用
embed_documents函数实现,将单个文本放入列表中,调用该函数后,取结果列表的第一个元素作为输出。
pip install -qU langchain-openai
from langchain_openai import OpenAIEmbeddings
OPENAI_EMBEDDING_API_KEY="hk-xxx"
OPENAI_EMBEDDING_BASE_URL="https://api.openai-hk.com/v1"
EMBEDDING_MODEL="text-embedding-3-small"
# 默认使用的模型是:text-embedding-ada-002
embeddings_model = OpenAIEmbeddings(
api_key=OPENAI_EMBEDDING_API_KEY,
base_url=OPENAI_EMBEDDING_BASE_URL,
model=EMBEDDING_MODEL
)
# 使用embed_documents方法,生成文档对象的Embedding,其接收的类型为一个列表。
embeddings = embeddings_model.embed_documents(
[
"你好",
"今天的天气好吗",
"我是木羽",
"如果你需要找我,请给我打电话吧",
"明天我们一起去郊游"
]
)
# 每一条文本,都会生成一个单独的Embedding Vector
# print(len(embeddings))
# 每个单独的Embedding Vector的维度都是1536
# print(len(embeddings[0]))
# QA场景:嵌入一段文本,以便与其他嵌入进行比较。
embedded_query = embeddings_model.embed_query("你好,请问你叫什么?")
# 返回的Embedding 维度也是 1536
# print(len(embedded_query))
print(embedded_query[:10])
1.1.2 DashScope Embedding模型接入
- Dashscope是国内最大的API集成平台,其中包含了各类开源模型(如Qwen3系列模型)和国内在线模型(如DeepSeek、BaiChuan)模型API服务,现在已合并入阿里云百炼平台。
- 对于国内开发者来说,若要使用Qwen系列模型API(而非本地部署),那么Dashscope平台提供的API服务肯定是最合适的。
- 阿里百炼平台官网
pip install --upgrade dashscope
from langchain_community.embeddings import DashScopeEmbeddings
dashscope_api_key="sk-xxx"
embedding_model="text-embedding-v4"
qwen3_embedding_model = DashScopeEmbeddings(
model=embedding_model, dashscope_api_key=dashscope_api_key
)
qwen3_embeddings = qwen3_embedding_model.embed_documents(
[
"你好",
"今天的天气好吗",
"我是木羽",
"如果你需要找我,请给我打电话吧",
"明天我们一起去郊游"
]
)
print(len(qwen3_embeddings)) # 5
1.1.3 语义空间可视化展示
- 接下来,通过一个稍加复杂的流程,测试一下关于
Embedding生成的向量,不同语义的文本之间的关系是怎样的,从而验证通过Embedding Models得到的Vector是否具有较强的语义信息。理论上,如果Embedding Vector足够好,那么自然语义相近的原始的文本会更相似。
pip install matplotlib scikit-learn
query = "早睡早起到底是不是保持身体健康的标准?"
sentences = ["早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。",
"早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。",
"关于提高工作效率,确保在日常饮食中包含充足的蛋白质、复合碳水化合物和健康脂肪非常关键。",
"投资可再生能源项目和推广电动汽车可以显著减少温室气体排放,从而缓解气候变化带来的负面影响。",
"多发性硬化症是一种影响中枢神经系统的自身免疫疾病,导致神经传导受损。虽然与阿尔茨海默症类似,多发性硬化症的主要症状包括疲劳、视觉障碍和肌肉控制问题。",
"今天的天气太好了,可以早点起床去爬山",
"如果下班特别晚的话,我建议你还是打车回家吧",
"提升学术研究质量需侧重于多学科融合和国际合作。研究机构应该鼓励学者之间的交流,通过共享数据和研究方法,来推动科学发现和技术创新。",
"如果你认为我说的没用,那你大可以不必理会。",
"衡量一个人是否成功的标准在于他到底能不能让身边的人都变的优秀"
]
from langchain_community.embeddings import DashScopeEmbeddings
dashscope_api_key="sk-xxx"
embedding_model="text-embedding-v4"
qwen3_embedding_model = DashScopeEmbeddings(
model=embedding_model, dashscope_api_key=dashscope_api_key
)
# 使用embed_documents方法,传入sentences列表,得到每条文本的向量表示。
sentence_embeddings = embeddings_model.embed_documents(sentences)
# QA场景:嵌入一段文本,以便与其他Embedding Vector进行比较。
embedded_query = embeddings_model.embed_query(query)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# 设置字体以支持中文显示
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 将查询句子的嵌入添加到句子嵌入数组的首位
all_embeddings = np.vstack([embedded_query, sentence_embeddings])
# 运行 TSNE 降维,固定随机种子以保持结果一致
# n_components (整数): 这个参数指定目标空间的维度。在这里设置为 2,意味着t-SNE将把数据降维到二维空间。
# perplexity (浮点数): 这个参数是t-SNE中非常重要的一个参数,可以看作是考虑周围邻居的数量,它反映了数据局部结构的复杂性。
tsne = TSNE(n_components=2, perplexity=5)
embeddings_2d = tsne.fit_transform(all_embeddings)
# 创建颜色列表,查询句子为红色,其余为绿色
color_list = ['red'] + ['green'] * len(sentence_embeddings)
# 绘制散点图
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1], color=color_list)
# 添加文本标签,包括查询句子
sentences_with_query = [query] + sentences # 加入查询句子到句子列表首位
for i in range(len(embeddings_2d)):
plt.text(embeddings_2d[i, 0], embeddings_2d[i, 1] + 10, # 小幅调整文本位置以防重叠
sentences_with_query[i],
color=color_list[i])
# 显示图表
plt.show()
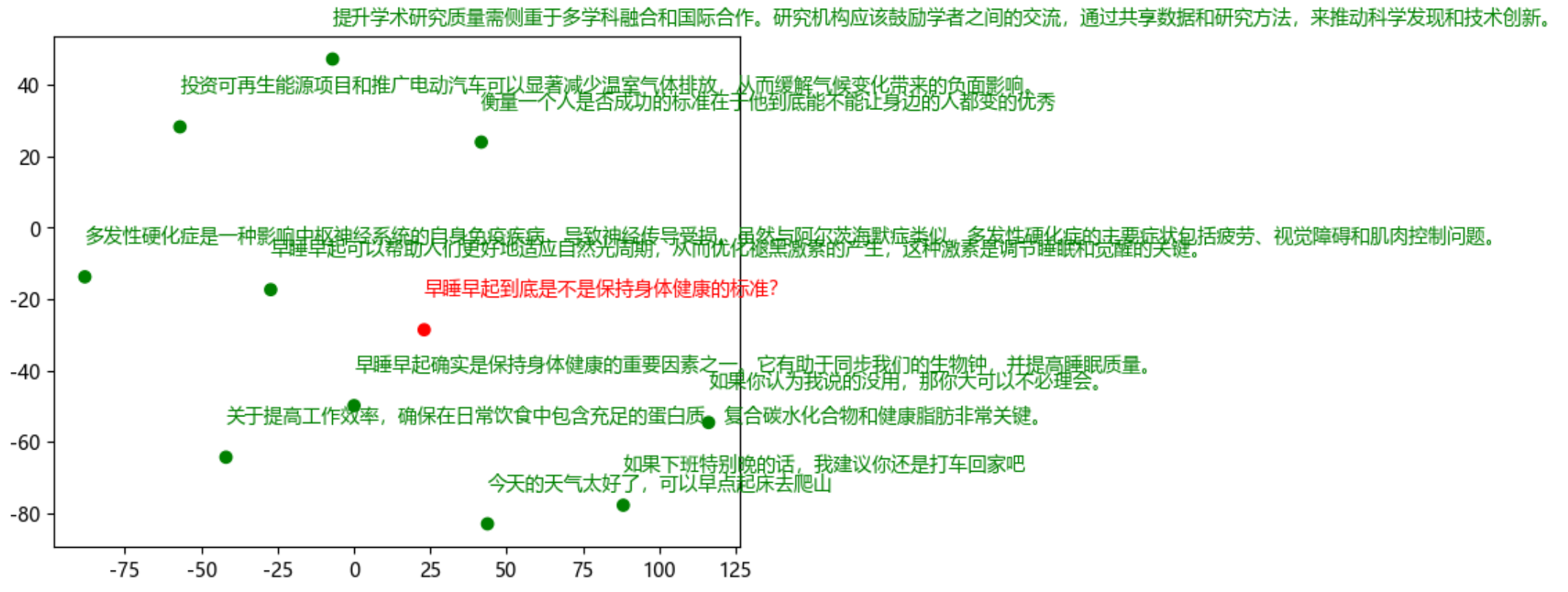
- 从上图中能够非常明显的看出,在分布上红色显示的为Query,不同文本间距离的远近表示着文本间的关联度,关联越大,两个文本的显示距离就越近。对
早睡早起到底是不是保持身体健康的标准?这个问题,在10个绿色字体的答案中,两个最相关的早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。和早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。是距离最近的。同时从自然语义上,也是最能回答该问题的答案。如果这是一个RAG系统,那么被检索出来的内容就会是这两个问题。从而也印证了Embeding后的向量,是具有极强的语义的。
- 在执行时会出现多次执行结果不同的情况,这是正常的,这是由于 t-SNE 算法的特性导致的。它在初始化过程中有一定的随机性。这意味着每次运行算法时,即使是在相同的Embeding向量上,得到的低维表示也可能不同。
1.2 开源Embedding Models接入
-
在
LangChain框架中如果想使用开源Embedding Models,需要先将具体的Embedding Models的全部权重文件下载至本地后才能进行加载,这与本地化部署开源大模型是一样的,其在调用过程中也会消耗一定的GPU资源,而消耗的多少显存则取决于Embedding Models的参数量。 -
LangChain集成的开源Embedding模型托管平台主要有Hugging Face、Ollama、Vllm等,在使用上与OpenAI Embedding Models等API形式差异也并不大,唯一需要做的前置工作是:需要把离线的Embedding Models从指定的托管平台上下载至本地。 -
这里以
BAAI/bge-base-zh-v1.5模型为例,介绍下载及使用方法,并通过Ollama平台进行部署,最后通过LangChain框架进行调用。官方下载地址 -
关于如何选择
Embedding模型,这个问题本质上不存在哪个Embedding最好的说法,同时也并没有比较通用且大家都认可的评测数据、流程等,往往还是需要结合自己的实际数据情况加上构建流程评测出来的效果,来进行综合评估。所以,推荐一个相对完善的Embedidng模型评估开源项目,同时也是一个RAG的解决方案:https://github.com/timescale/pgai?ref=timescale.ghost.io -
pgai项目针对Ollama支持的Embedding模型做了一些基础的评测
| 模型名称 | 优势 | 劣势 |
|---|---|---|
| bge-m3 | 整体检索准确率最高 | 在不清楚和含糊不清的问题上表现较差,最低准确率 |
| 在长问题上表现出色 | ||
| mxbai-embed-large | 尺寸小 | 在简短和直接的问题上表现不如其他模型 |
| 在上下文较重的问题上表现良好 | ||
| 长问题表现良好 | ||
| nomic-embed-text | 在简短和直接的问题上表现优异 | 整体表现排名最后 |
| 在长问题上也取得了较好性能 |
1.2.1 bge-m3向量模型接入
-
bge(**BAAI General Embeddin最受欢迎备受关注的开源Embedding模型,由北京智源人工智能研究院(BAAI)推出,旨在在多样化的下游任务中提供通用而高效的语义表示。bge系列模型特别强调对中文和英文文本的双语支持,具备较强的跨语言检索能力,这一特性在实际场景中尤为重要,比如中英文混合的搜索、问答与推荐系统。
-
bge模型的设计理念是通过大规模对比学习(Contrastive Learning),让模型能够识别和区分不同语义表达之间的细微差别。它在训练阶段利用了丰富的语料库,涵盖新闻、百科、问答、社交媒体等多种领域,从而具备良好的通用性。用户在使用bge时,可以直接将句子或文档输入模型,获得稠密的向量表示,这些向量可以被用作向量检索、相似性匹配或特。
-
目前,bge系列已经推出了多个主流的Embedding模型,主要包括bge-small、bge-base、bge-large以及针对多语言和指令微调优化的变体,每个版本都在参数规模、性能和使用场景上有所侧重。
-
最小版本bge-small体积轻量,推理速度快,非常适合对资源有限或对延迟敏感的应用场景,例如在边缘设备或移动端部署。尽管模型规模较小,但在中英文检索任务中依然具备不错的鲁棒性,对于一些基础的语义匹配和快速召回需求,bge-small往往已经足够应对。
-
中等规模的bge-base则是bge系列中应用最为广泛的版本之一,它在准确率和推理效率之间做到了良好平衡。bge-base在多项公开基准上都取得了领先的性能,尤其在中文检索、问答对齐以及多轮对话场景下表现出较强的泛化能力。许多开发者将bge-base作为向量数据库(如FAISS、Milvus)的默认Embedding模型,用于构建高质量的语义检索系统。
-
性能最强的bge-large版本在模型容量和表达能力方面进一步提升,适合对精度要求极高的场景,比如法律、金融等领域的大规模语义搜索或复杂问答。bge-large在向量表示上更为细腻,可以捕捉文本间更微妙的语义差异,但同时需要更多的显存和算力资源。
-
除了这些通用版本,bge还提供了bge-m3等多语言模型和bge-reranker这样的重排序模型。bge-m3在多语种环境下具备出色的跨语言检索能力,支持中英文及其他语种的混合对比学习,非常适合构建国际化的检索服务。而bge-reranker则是一种专用于对召回结果进行精细排序的模型,它可以与Embedding模型搭配使用,将粗排后的候选文本再进行一轮打分,显著提升最终的检索相关性。
-
-
选择bge-m3模型进行下载使用。
ollama pull bge-m3 -
启动Ollama服务后,通过如下命令下载并启动bge-m3模型
ollama start
bge-m3模型不支持在类似对话模型启动后可以在命令行进行问答,需要通过Ollama的REST API进行使用。
- ollama成功启动后,
Ollama提供给Embedding模型使用的REST API接口为:/api/embed。其可以支持单个输入和多个输入的请求。
| 参数名 | 类型 | 描述 |
|---|---|---|
| model | 字符串 | 用于生成嵌入的模型名称 |
| input | 字符串或字符串列表 | 要生成嵌入的文本或文本列表 |
| truncate | 布尔值 | 是否截断每个输入的末尾以适应上下文长度。若为 false 且超出上下文长度则返回错误。默认值为 true |
| options | 对象 | 额外的模型参数,例如温度等 |
| keep_alive | 字符串 | 控制模型在请求后保持加载到内存中的时间(默认:5分钟) |
import requests
import json
# 定义 API 端点
url = "http://localhost:11434/api/embed" # 根据实际情况进行修改
# 单个输入的请求示例
single_input_payload = {
"model": "bge-m3", # 模型名称
"input": "世上无难事,只要肯放弃"
}
# 发送 POST 请求
response_single = requests.post(url, json=single_input_payload)
# 检查响应
if response_single.status_code == 200:
print("Single Input Response:")
response_data_single = response_single.json()
print(len(response_data_single["embeddings"][0])) # 向量维度为1024
print(json.dumps(response_data_single, indent=2))
else:
print(f"Error: {response_single.status_code} - {response_single.text}")
- 经过
bge-m3模型处理后的结果, 就是将输入的文本转换为一个包含1024个浮点数的列表,并且用这个列表来表示输入文本的语义。 - 同时,
bge-m3模型还支持多个输入的请求,即可以一次性输入多个文本,然后返回每个文本的嵌入结果。
import requests
import json
# 定义 API 端点
url = "http://localhost:11434/api/embed" # 这里需要根据实际情况进行修改
# 多个输入的请求示例
multiple_input_payload = {
"model": "bge-m3",
"input": ["天为什么是蓝色的?",
"草为什么是绿色的?"]
}
# 发送 POST 请求
response_multiple = requests.post(url, json=multiple_input_payload)
# 检查响应
if response_multiple.status_code == 200:
print("\nMultiple Input Response:")
response_data_multiple = response_multiple.json()
# print(json.dumps(response_data_multiple, indent=2))
# 提取嵌入结果
multiple_embeddings = response_data_multiple.get("embeddings", [])
else:
print(f"Error: {response_multiple.status_code} - {response_multiple.text}")
print("Total embeddings:", len(multiple_embeddings))
# 只查看前10个位置的向量
print("First embedding:", len(multiple_embeddings[0]), multiple_embeddings[0][:10]) # 表示天为什么是蓝色的?
print("Second embedding:", len(multiple_embeddings[1]), multiple_embeddings[1][:10]) # 表示草为什么是绿色的?
Multiple Input Response:
Total embeddings: 2
First embedding: 1024 [-0.04207424, 0.005275975, -0.03769521, -0.06222176, -0.030408813, -0.007812904, -0.04390911, 0.0022407186, 0.016319353, -0.011895019]
Second embedding: 1024 [-0.039750945, 0.018036807, -0.027083319, -0.03382646, -0.010967627, -0.08791342, -0.048105538, 0.031287055, 0.03213445, -0.0045457482]
Ollama启动的Embedding REST API同样是兼容了OpenAI的接口规范。
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key ="ollama") # 需要根据自己的实际情况调整
response = client.embeddings.create(
model="bge-m3",
input="世上无难事,只要肯放弃",
)
print(response)
print(len(response.data[0].embedding)) # 1024
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key ="ollama") # 需要根据自己的实际情况调整
batch_input = ["天为什么是蓝色的?", "草为什么是绿色的?"]
response = client.embeddings.create(
model="bge-m3",
input=batch_input
)
# print(response)
print(len(response.data)) # 2
print(len(response.data[0].embedding)) # 1024
print(len(response.data[1].embedding)) # 1024
1.2.3 Embedding模型评测榜单
-
在
Huggging Face的mteb/leaderboard有一个较为优质的评测榜单:https://huggingface.co/spaces/mteb/leaderboard ,该榜单中包含了很多Embedding模型,并且每个模型都给出了在不同任务上的得分。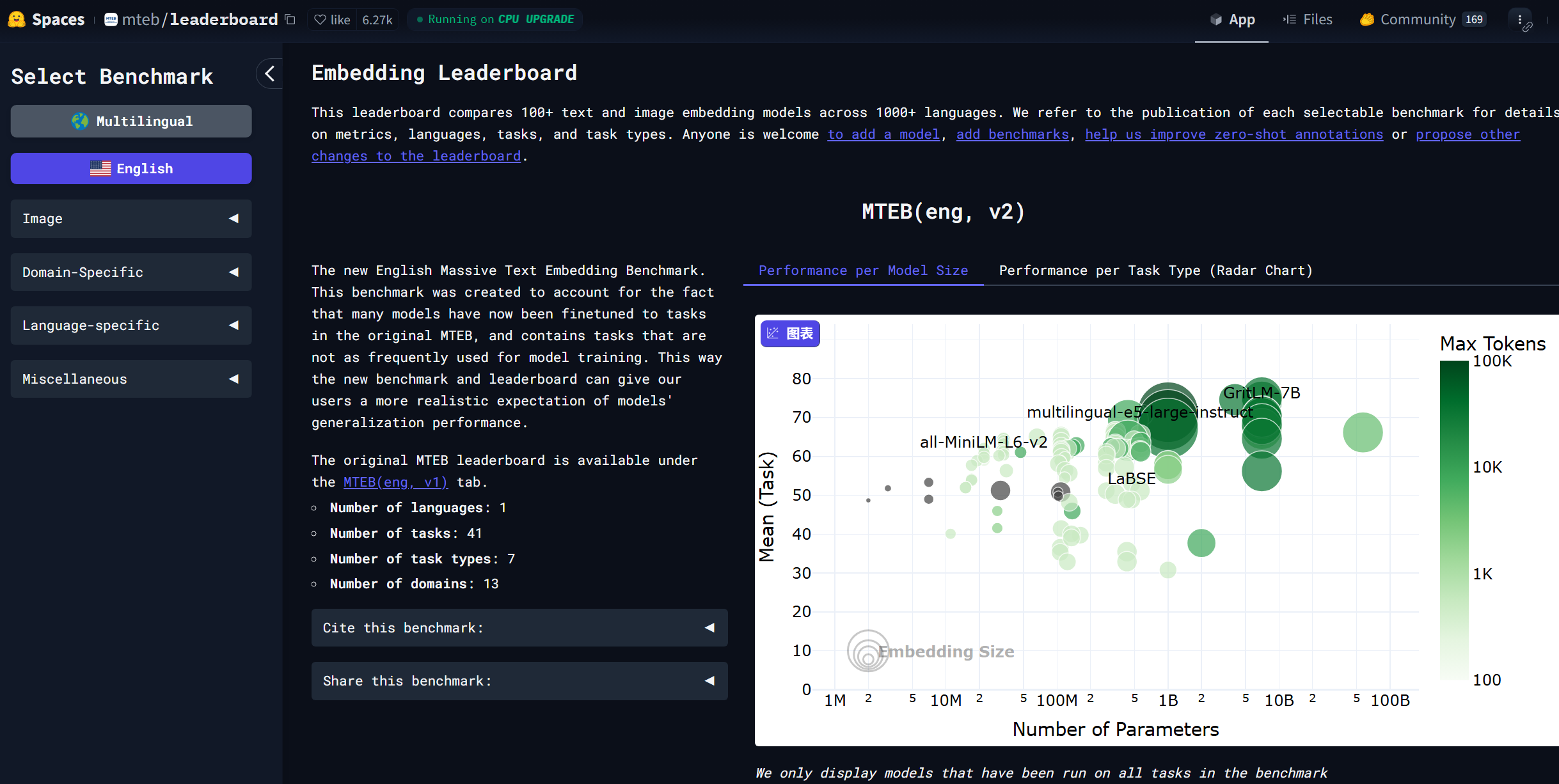
-
在选择
Embedding模型时,考虑以下四个关键因素来确保能选取到最适合当前需求的模型:
-
文本长度和块大小(Chunk Size 和 Sequence Length):模型选择应基于文本块的大小和序列长度,这通常取决于预期回答的长度。选择能够有效处理特定文本长度的模型。
-
Embedding维度:维度大小并非总是越大越好。如果文本语义丰富,较高的维度可能更有利于捕捉复杂信息。然而,对于语义较简单和直接的文本,较小的维度可能更为有效。
-
模型大小和硬件资源:根据可用的硬件资源(如显存大小),选择合适的模型。如果硬件资源充足,可以选择较大的模型,一般来说模型越大,性能越好,但是这并不绝对。
-
实际测试和验证:使用一个简单的
Demo来测试模型的实际效果。如果初步的可视化测试结果不理想,那么有可能是不适合的。但这并不绝对,比如上面的例子,因为是降维之后的可视化,所以有可能在高维下,其表现是很好的,所以要综合衡量。
二 计算向量之间的相似度
- 向量之间的相似度往往是通过一些具体的算法来计算的,向量和标量最大的区别在于向量是有方向的,而标量没有方向,只有大小。那么对于向量,一些常用的计算方法比如:
-
点积(内积): 两个向量的点积是一种衡量它们在同一方向上投影的大小的方法。如果两个向量是单位向量(长度为1),它们的点积等于它们之间夹角的余弦值。因此,点积经常被用来计算两个向量的相似度。
-
余弦相似度: 这是一种通过测量两个向量之间的角度来确定它们相似度的方法。余弦相似度是两个向量点积和它们各自长度乘积的商。这个值的范围从-1到1,其中1表示完全相同的方向,-1表示完全相反,0表示正交。
-
欧氏距离: 这种方法测量的是两个向量在n维空间中的实际距离。虽然它通常用于计算不相似度(即距离越大,不相似度越高),但可以通过某些转换(如取反数或用最大距离归一化)将其用于相似度计算。
-
- 余弦相似度代码实现
import numpy as np
def cosine_similarity(A, B):
# 使用numpy的dot函数计算两个数组的点积
# 点积是向量A和向量B在相同维度上对应元素乘积的和
dot_product = np.dot(A, B)
# 计算向量A的欧几里得范数(长度)
# linalg.norm默认计算2-范数,即向量的长度
norm_A = np.linalg.norm(A)
# 计算向量B的欧几里得范数(长度)
norm_B = np.linalg.norm(B)
# 计算余弦相似度
# 余弦相似度定义为向量点积与向量范数乘积的比值
# 这个比值表示了两个向量在n维空间中的夹角的余弦值
return dot_product / (norm_A * norm_B)
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key ="ollama") # 需要实际情况调整
def get_embedding(text, model="bge-m3"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
embedding1 = get_embedding("我正在学习大模型技术应用实战课")
embedding2 = get_embedding("如果你想找到大模型岗位的工作,一定要来学习大模型技术实战课")
embedding3 = get_embedding("我喜欢打篮球")
embedding4 = get_embedding("我也在学习大模型技术应用实战课")
# 计算不同向量之间的余弦相似度
print(cosine_similarity(embedding1, embedding2)) # 0.8056793561318286
print(cosine_similarity(embedding1, embedding3)) # 0.509560442146839
print(cosine_similarity(embedding2, embedding3)) # 0.3749113653081741
print(cosine_similarity(embedding1, embedding4)) # 0.9543285830094022
- 当两段文本的语义越相近,通过余弦相似度计算出来的分数就越高。这也是衡量文本相似度最为常用的方法。
- 将余弦相似度流程应用在
LangChain的数据处理流中。from langchain.document_loaders import TextLoader # 文档中的文本内容覆盖了多个主题,用来增强测试的复杂性 docs = TextLoader('./Multitheme_Test_Document_Chinese.txt', encoding="utf-8").load()print(docs[0].page_content)科技创新: 随着技术的快速发展,人工智能和机器学习已经成为当下最热门的话题之一。从智能助手到自动驾驶汽车,AI的应用正在改变我们的生活方式。同时,关于数据隐私和机器伦理的讨论也日益增加,呼吁制定更明确的规范和法律。 环境保护: 全球气候变化对自然和人类社会构成了巨大的挑战。在这种情况下,推广绿色能源、减少塑料使用并保护生态多样性显得尤为重要。多国政府和非政府组织正在努力寻找解决方案,以减轻环境退化的影响。 经济趋势: 在全球化的大背景下,中国经济持续其增长势头,同时全球经济格局也在经历重大的转变。数字货币和区块链技术被视为金融领域的革命性创新,预计将对世界经济产生深远的影响。 文化艺术: 中国传统文化如书法和京剧在现代社会中依然占有重要地位。同时,现代艺术家也在尝试将传统艺术形式与现代技术结合,创造出新的艺术表现形式。艺术节和展览为这些创新提供了展示的平台。 健康生活: 现代生活节奏加快,健康问题也越来越受到人们的关注。健康饮食、规律运动是维持健康的重要因素。此外,心理健康和压力管理也开始被更多人重视,相关的研究和讨论日益增多。 旅游探险: 旅游已成为现代人生活的一部分,不仅是放松心情,更是一种文化和自我探索的方式。从遥远的北极圈到热带雨林,人们越来越愿意探索未知的领域,体验不同的文化和自然环境。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(docs)
for index, doc in enumerate(docs):
print(f"Chunk {index + 1}: {doc.page_content}\n")
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key ="ollama") # 需要实际情况调整
def get_embedding(text, model="bge-m3"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
embeddings = [get_embedding(doc.page_content) for doc in docs]
# 获取到query的表示
response = client.embeddings.create(
input="现在科技创新方面有什么进展?",
model="bge-m3"
)
query_embedding = response.data[0].embedding
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
The most similar chunk is Chunk 1 with similarity 0.666865955434427:
科技创新:
随着技术的快速发展,人工智能和机器学习已经成为当下最热门的话题之一。从智能助手到自动驾驶汽车,AI的应用正在改变我们的生活方式。同时,关于数据隐私和机器伦理的讨论也日益增加,呼吁制定更明确的规范和法律。
response = client.embeddings.create(
input="现在的经济趋势怎么样?",
model="bge-m3"
)
query_embedding = response.data[0].embedding
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
The most similar chunk is Chunk 3 with similarity 0.6743476591005652:
经济趋势:
在全球化的大背景下,中国经济持续其增长势头,同时全球经济格局也在经历重大的转变。数字货币和区块链技术被视为金融领域的革命性创新,预计将对世界经济产生深远的影响。
三 向量数据库
- 一个应用级的
RAG系统仅知识库存储的内容很多甚至是海量的,chunks更多,当一个用户的query进入到这个RAG系统,query作为一个向量,要去偌大的知识库中(可能有几万、上千万个chunks)中找到与其最接近、内容最相关的问题,这就变成了一个搜索问题。 - 接下来了解了解一下向量数据库的应用方法和使用技巧。
3.1 向量数据库功能特性
- 向量数据库解决的就问题是更高效的实现搜索(
Search)过程。传统数据库是先存储数据表,然后用查询语句(SQL)进行数据搜索,本质还是基于文本的精确匹配,这种方法对于关键字的搜索非常合适,但对于语义的搜索就非常弱。但是,在向量数据库的应用场景:给定一个查询向量,然后在众多向量中找到最为相似的一些向量返回。具有一定的模糊性,这就是所谓的最近邻(Nearest Neighbors)问题,而能实现这一点的则称之为【最近邻(搜索)算法】。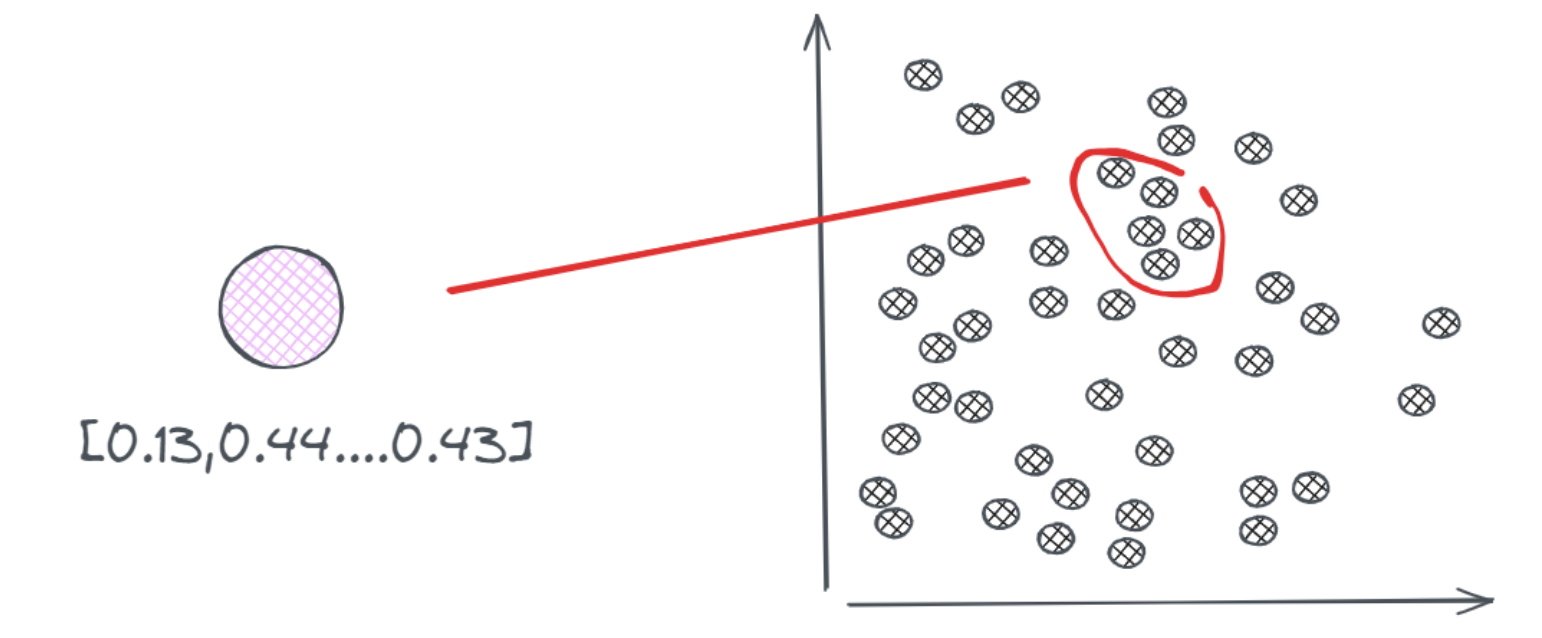
- 一种直观的方法是暴力搜索,即逐一计算查询向量与所有向量的相似度,并返回相似度最高的结果。相似度计算可采用余弦相似度(衡量向量夹角)或欧氏距离(衡量向量间距)等方法。然而,当向量规模较大时,暴力搜索的时间复杂度会显著增加,难以满足实时性需求。
- 为此,常见的优化思路是:先通过聚类等方法缩小搜索范围,再在有限范围内进行精确搜索。例如,使用K-Means等聚类算法对向量分簇后,数据库中的向量会以聚类结构存储,从而大幅提升检索效率。
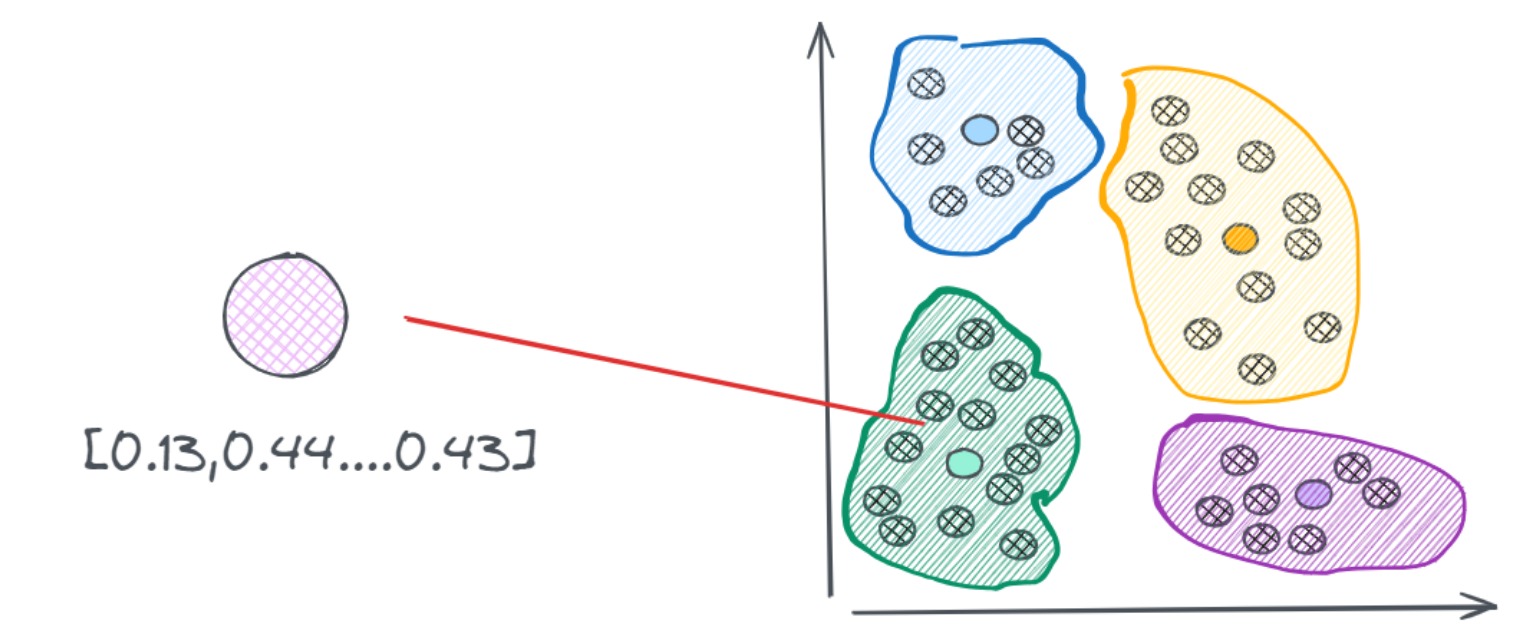
- 通过聚类算法先进行一轮训练,把相似向量划分到一个个不同的簇中,在实际执行搜索的时候,只需要找到和聚类向量中心点最近的那个向量,然后在这个簇中的执行搜索过程即可。但也会出现一些问题,如:红色的点是查询向量落到的位置,它距离蓝色簇质心的距离最近,所以按照规则,它会去蓝色的簇中搜索向量,但实际上,与它最相近的向量是在黄色的簇中的红色点。
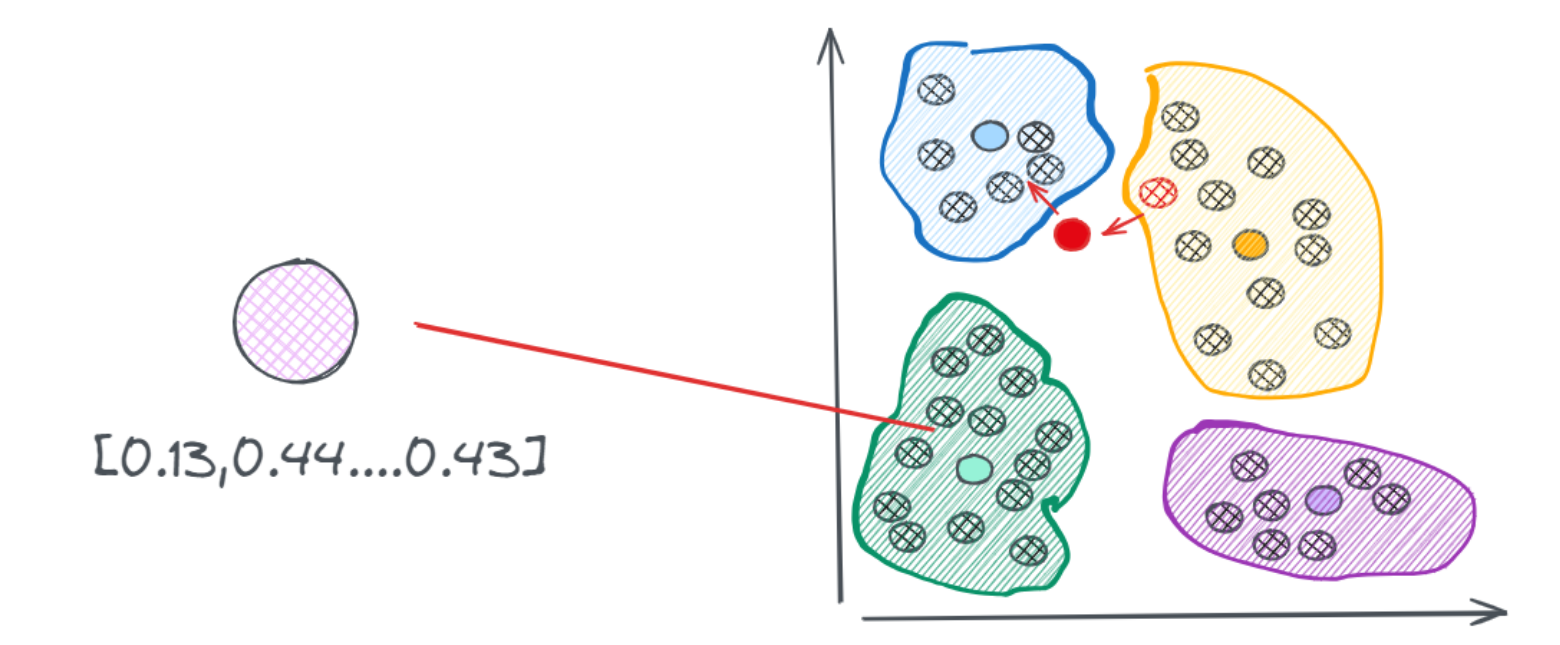
- 可以通过划分多个簇来尽可能的减少这种遗漏的情况,但需要说明的是,一旦提高搜索质量通常会降低处理速度,这两者之间往往存在难以调和的矛盾。在实际应用中,几乎所有的算法都是在这两个指标之间寻求平衡。因此,除了暴力搜索之外,任何算法得到的都是一些近似的结果。这类算法也被称为“近似最近邻”(Approximate Nearest Neighbors,简称ANN)。
- 除了聚类以外,减少搜索范围的方法还有很多,比如哈希算法。哈希算法就是任何数据经过哈希函数计算后,都会输出一个固定的哈希值,那就会存在一个问题:将无限可能的输入映射到有限的输出范围内,就一定会出现不同的输入数据产生相同的哈希值的这种情况,这种现象被称为“碰撞”。一个理想的哈希算法是尽可能的减少碰撞,但向量数据库的哈希函数设计却反其道而行,它会倾向于增大碰撞发生的可能性,因为当哈希值一样,那它就会认为这两个向量是相似的,然后把这些向量划分到一起,组成的向量集合叫做桶:Bucket。
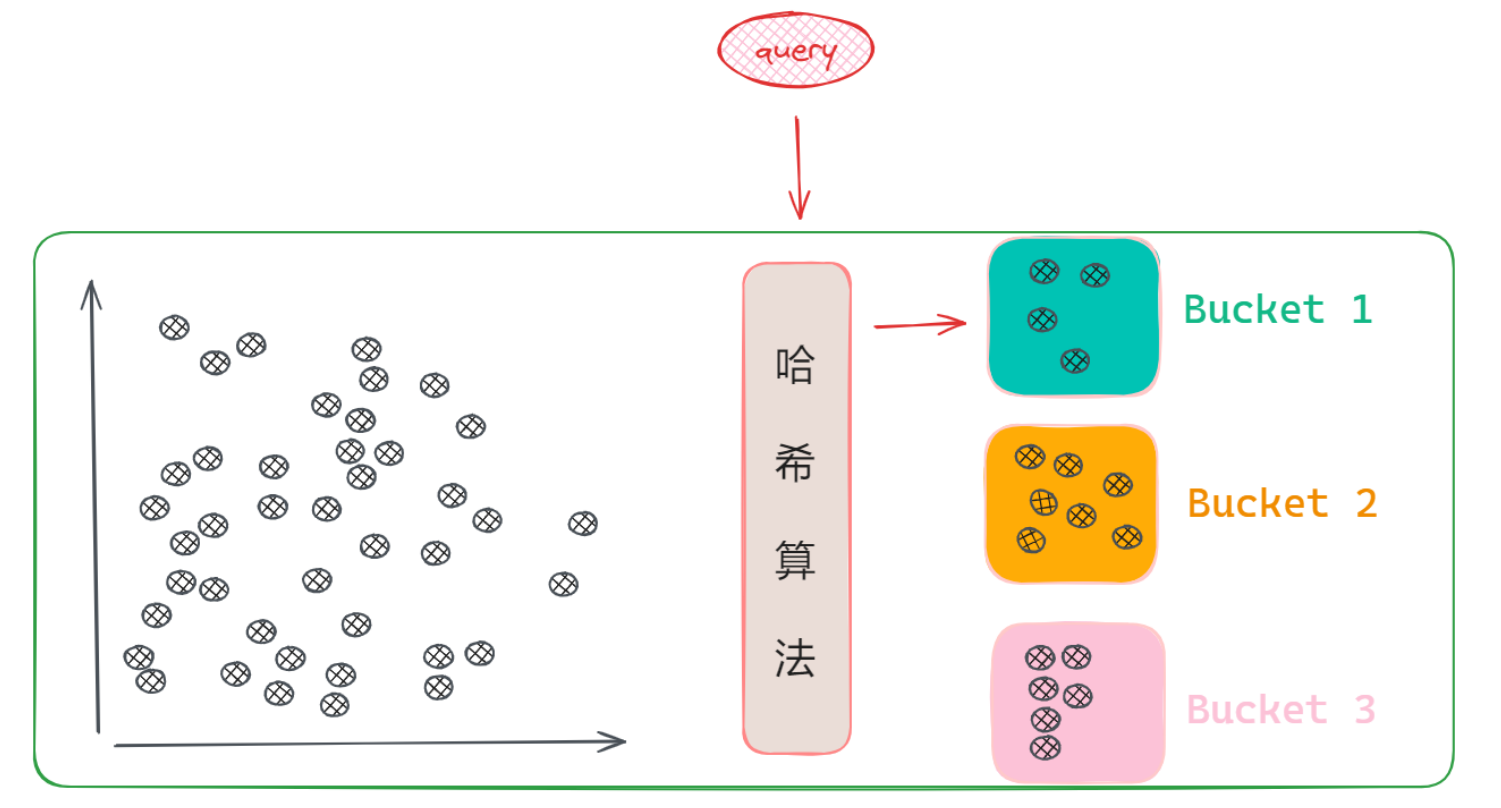
在向量数据库中,哈希函数的设计使得相似向量更可能发生碰撞,从而被分到同一个桶(Bucket)中。这种策略称为位置敏感哈希(Locality-Sensitive Hashing, LSH),它能在查询时快速定位相似向量的候选集,大幅缩小搜索范围。
此外,还有其他优化算法可降低计算或内存开销,例如: - PQ(Product Quantization):通过有损压缩减少存储需求
- HNSW(Hierarchical Navigable Small World):基于图结构的高效近邻搜索
3.2 向量数据库小结
- 不同的向量数据库,底层实现的只是不同的逻辑,但核心都会搭建类似流程。而在应用层面上,其展现出来将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时,将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。
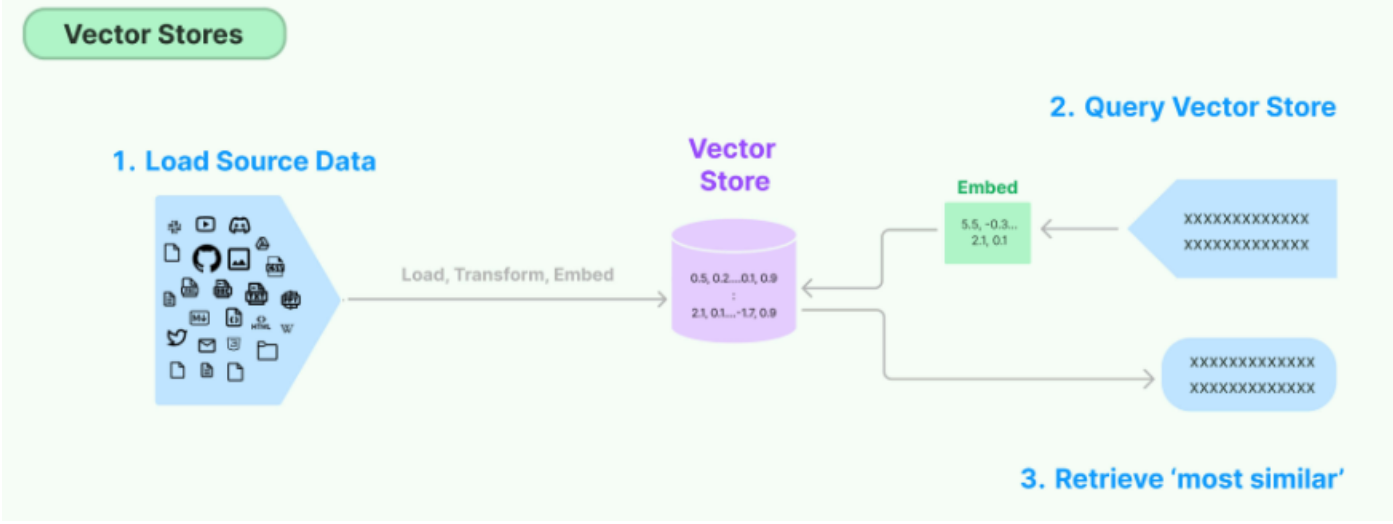
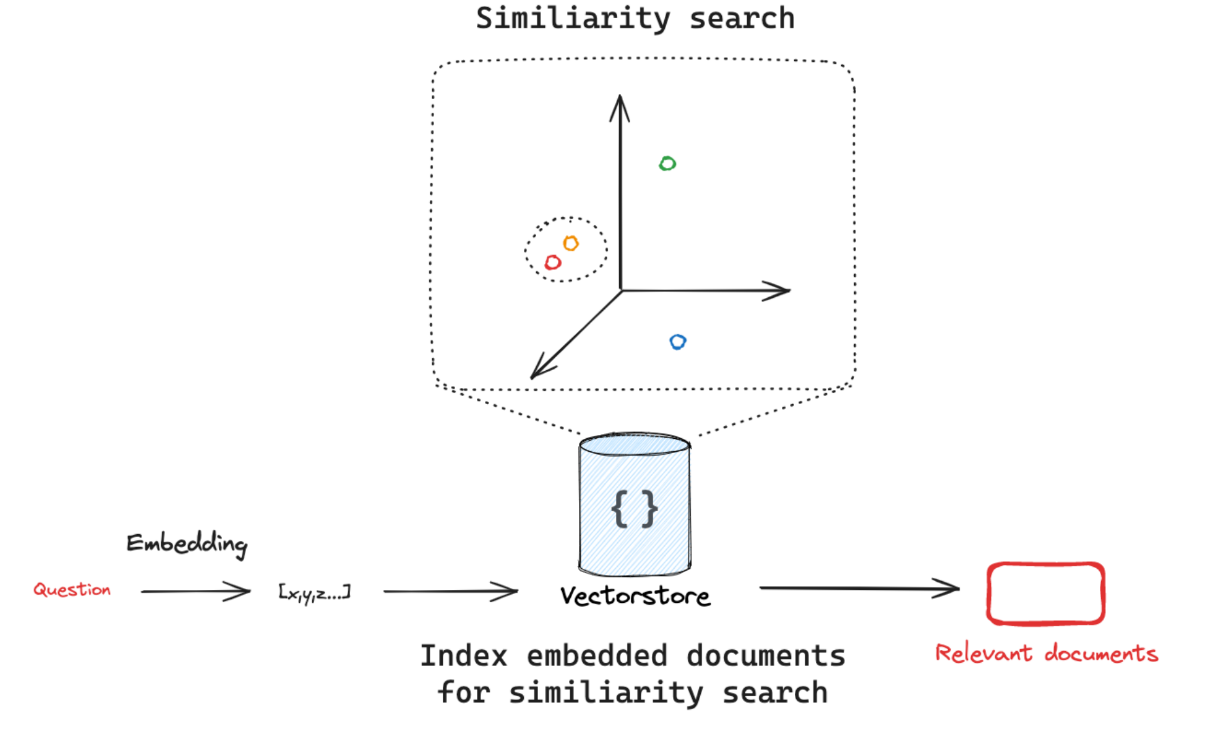
3.3 主流词向量数据库
- 主流的向量数据库主要分为开源和闭源两种类型。常用的向量数据库如下:

Pinecone为闭源的向量数据库,Chroma,Faiss和Qdrant为开源的向量数据库。Chroma为LangChain官方主推的向量数据库,同时Faiss和Qdrant也非常受欢迎。而像Postgres、Neo4j和Redis等原本较为传统的数据库,为适应当前大模型技术的发展趋势也添加了向量功能。
3.4 langchain集成Chroma向量数据库
Chroma是一家构建开源项目(也称为Chroma)的公司,其官网:https://www.trychroma.com/- 它支持用于搜索、过滤等的丰富功能,并能与多种平台和工具(如
LangChain,LlamaIndex,OpenAI等)集成。Chroma的核心API包括四个命令,分别用于创建集合、添加文档、更新和删除,以及执行查询。Chroma向量数据库官方原生支持Python和JavaScript,也有其他语言的社区版本支持。所以可以直接通过Python或JS操作,具体的操作文档可查阅其官方文档:https://docs.trychroma.com/
pip install langchain-chroma
pip install -U langchain-ollama
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain.vectorstores import Chroma # 向量数据库
# 加载文档
raw_documents = TextLoader('./sora.txt', encoding="utf-8").load()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""],
chunk_size=500,
chunk_overlap=20,
add_start_index=True
)
documents = text_splitter.split_documents(raw_documents)
# 初始化嵌入模型(使用 Ollama 的 bge-m3 模型)
embeddings_model = OllamaEmbeddings(model="bge-m3", base_url="http://localhost:11434")
# 创建向量数据库并持久化
db = Chroma.from_documents(
documents,
embeddings_model,
persist_directory="./chroma_langchain_db"
)
# 查询相似内容
query = "什么是Sora"
docs = db.similarity_search(query)
print(f"question: {query}")
print(f"result: {docs[0].page_content}")
print("---")
query = "Sora在训练时消耗了多少算力?"
docs = db.similarity_search(query)
print(f"question: {query}")
print(f"result: {docs[0].page_content}")
question: 什么是Sora
result: 一、Sora是什么?为什么说Sora是人工智能划时代的突破?
2024年2月16日凌晨,OpenAI在官网发布了最新的文生视频模型Sora。Sora不仅突破了现有文生视频模型10秒左右的连贯性局限,而且展示出了更精细的画质、多角度多镜头切换中保持一致性等能力。最重要的是,Sora较好地表现出了现实世界中的逻辑,比如在模型生成的两艘海盗船在咖啡杯内航行的视频中,咖啡的流动完全符合现实世界中的流体力学;比如一则宠物猫等待主人起床的视频中,宠物猫踩奶的动作、对主人鼻头的轻触都符合现实世界中动物的习性。
---
question: Sora在训练时消耗了多少算力?
result: 对于算力而言,由于OpenAI并未公布模型架构的细节,很难推测训练Sora具体消耗了多少算力,但既然ScalingLaw,或者说“大力出奇迹”依然是当前AI模型实现“涌现”的黄金法则,就意味着对算力的需求仍然没有看到“拐点”。如果Sora的训练确实使用了合成数据,意味着可供训练的数据远未耗尽,人类对AI模型参数和训练数据的提升还远远没有达到瓶颈。甚至随着AI模型合成数据能力的增强,模型推理结果本身就可以作为训练的一部分,从而实现AI的自我迭代。此外,视频生成推理需要更大的VRAM或带宽,如果Sora开放使用后如期推动各类视频创作的繁荣,当前电信和数通网络的带宽都需要大幅升级。作为广义算力的一部分,网络设备的需求也将爆发式增长。
对于投资而言,Sora最大的意义在于证明了AI产业的创新浪潮还远未停歇。Sora的“前辈”ChatGPT发布以来,芯片龙头英伟达、博通股价分别上涨超300%、130%,软件应用龙头微软上涨超60%。Sora作为多模态大模型,向公众开放后预计对算力需求更大、对软件应用成长空间提升更显著,有望进一步提升相关产业投资价值。
- 还可以使用
similarity_search_by_vector搜索与给定Embedding向量类似的文档,它接受Embedding向量作为参数而不是字符串。query = "Sora在训练时消耗了多少算力?" embedding_vector = embeddings_model.embed_query(query) # 通过k参数指定返回的文档数量 docs = db.similarity_search/similarity_search_by_vector(query, k=2) docs = db.similarity_search_by_vector(embedding_vector) print(docs[0].page_content) - 计算相似度:Chroma默认用的通常是点积相似性(dot product),所以它返回的分数并不限定在1以内。换句话说:这个数值不是“标准化的余弦相似度”,它只是一个相对大小的指标,越大表示越接近,越小表示越不相关
results = db.similarity_search_with_score("Sora是什么?", k=1) print(results)[(Document(metadata={'start_index': 0, 'source': './sora.txt'}, page_content='一、Sora是什么?为什么说Sora是人工智能划时代的突破?\n\n2024年2月16日凌晨,OpenAI在官网发布了最新的文生视频模型Sora。Sora不仅突破了现有文生视频模型10秒左右的连贯性局限,而且展示出了更精细的画质、多角度多镜头切换中保持一致性等能力。最重要的是,Sora较好地表现出了现实世界中的逻辑,比如在模型生成的两艘海盗船在咖啡杯内航行的视频中,咖啡的流动完全符合现实世界中的流体力学;比如一则宠物猫等待主人起床的视频中,宠物猫踩奶的动作、对主人鼻头的轻触都符合现实世界中动物的习性。'), 0.8639981746673584)]
3.5 chroma文档操作
- 在构建实际应用程序时,除了添加和检索,非常多的情况下还需要更新和删除数据,需要使用
Chroma类定义的ids参数,它可以传入文件名或任意的标识。需要先根据分成Chunks构建起唯一的对应id。
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain.vectorstores import Chroma # 向量数据库
# 加载文档
raw_documents = TextLoader('./sora.txt', encoding="utf-8").load()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""],
chunk_size=500,
chunk_overlap=20,
add_start_index=True
)
documents = text_splitter.split_documents(raw_documents)
# 创建一个简单的文档ids
ids = [str(i) for i in range(1, len(documents) + 1)]
print(ids)
# 初始化嵌入模型(使用 Ollama 的 bge-m3 模型)
embeddings_model = OllamaEmbeddings(model="bge-m3", base_url="http://localhost:11434")
# # 重新构造Chroma实例并持久化
db = Chroma.from_documents(
documents,
embeddings_model,
ids=ids,
persist_directory="./chroma_langchain_db"
)
# 输入查询的问题
query = "Sora是什么?"
docs = new_db.similarity_search(query, k=1)
print(docs)
print(docs[0].metadata)
print(docs[0].page_content)
# 直接修改metadata 执行update_document方法进行更新
docs[0].metadata = {
"source": "./sora.txt",
"new_value": "这是我主动更新的",
}
new_db.update_document(ids[0], docs[0])
# 查询
print(new_db._collection.get(ids=[ids[0]]))
['1', '2', '3', '4', '5', '6']
[Document(metadata={'start_index': 0, 'source': './sora.txt'},
page_content='一、Sora是什么?为什么说Sora是人工智能划时代的突破?\n\n2024年2月16日凌晨,OpenAI在官网发布了最新的文生视频模型Sora。Sora不仅突破了现有文生视频模型10秒左右的连贯性局限,而且展示出了更精细的画质、多角度多镜头切换中保持一致性等能力。最重要的是,Sora较好地表现出了现实世界中的逻辑,比如在模型生成的两艘海盗船在咖啡杯内航行的视频中,咖啡的流动完全符合现实世界中的流体力学;比如一则宠物猫等待主人起床的视频中,宠物猫踩奶的动作、对主人鼻头的轻触都符合现实世界中动物的习性。')]
{'start_index': 0, 'source': './sora.txt'}
一、Sora是什么?为什么说Sora是人工智能划时代的突破?
2024年2月16日凌晨,OpenAI在官网发布了最新的文生视频模型Sora。Sora不仅突破了现有文生视频模型10秒左右的连贯性局限,而且展示出了更精细的画质、多角度多镜头切换中保持一致性等能力。最重要的是,Sora较好地表现出了现实世界中的逻辑,比如在模型生成的两艘海盗船在咖啡杯内航行的视频中,咖啡的流动完全符合现实世界中的流体力学;比如一则宠物猫等待主人起床的视频中,宠物猫踩奶的动作、对主人鼻头的轻触都符合现实世界中动物的习性。
{'ids': ['1'], 'embeddings': None,
'documents': ['一、Sora是什么?为什么说Sora是人工智能划时代的突破?\n\n2024年2月16日凌晨,OpenAI在官网发布了最新的文生视频模型Sora。Sora不仅突破了现有文生视频模型10秒左右的连贯性局限,而且展示出了更精细的画质、多角度多镜头切换中保持一致性等能力。最重要的是,Sora较好地表现出了现实世界中的逻辑,比如在模型生成的两艘海盗船在咖啡杯内航行的视频中,咖啡的流动完全符合现实世界中的流体力学;比如一则宠物猫等待主人起床的视频中,宠物猫踩奶的动作、对主人鼻头的轻触都符合现实世界中动物的习性。'],
'uris': None, 'included': ['metadatas', 'documents'],
'data': None,
'metadatas': [{'new_value': '这是我主动更新的', 'source': './sora.txt', 'start_index': 0}]}
update_documents方法用于更新向量库中的一组文档,具体来看:它从传入的文档列表中,提取出所有文档的页面内容(page_content)和元数据(metadata),然后执行更新过程。- 与任何其他数据库一样,在向量数据库中,也可以使用
.add、.get、.update.delete等方法,但如果想直接访问,需要执行._collection.method()。# 删除 删除最后一个chunk new_db._collection.delete(ids=[ids[-1]])

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)