【完整源码+数据集+部署教程】砖块裂缝检测分割系统源码和数据集:改进yolo11-AIFI
【完整源码+数据集+部署教程】砖块裂缝检测分割系统源码和数据集:改进yolo11-AIFI
背景意义
研究背景与意义
随着城市化进程的加快,基础设施的建设和维护变得愈发重要。砖块作为常见的建筑材料,其在道路、墙体等结构中的应用广泛。然而,砖块在长期使用过程中容易出现裂缝,这不仅影响了建筑物的美观,更可能导致结构安全隐患。因此,及时、准确地检测和分割砖块裂缝,对于维护建筑物的安全性和延长其使用寿命具有重要意义。
传统的裂缝检测方法多依赖人工检查,效率低且容易受到主观因素的影响。随着计算机视觉技术的快速发展,基于深度学习的自动化检测方法逐渐成为研究热点。YOLO(You Only Look Once)系列模型因其高效的实时检测能力,广泛应用于目标检测任务中。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更高的检测精度,为裂缝检测提供了新的技术手段。
本研究旨在基于改进的YOLOv11模型,构建一个高效的砖块裂缝检测分割系统。通过使用包含1500张图像的裂缝分割数据集,模型将能够准确识别和分割砖块中的裂缝。该数据集专注于单一类别的裂缝,确保了模型训练的专一性和有效性。通过对数据集的预处理和模型的优化,期望能够显著提高裂缝检测的准确率和实时性。
本项目的研究不仅有助于推动计算机视觉技术在建筑工程领域的应用,还为未来的智能建筑维护提供了理论基础和实践参考。通过实现自动化的裂缝检测与分割,将有效降低人工成本,提高检测效率,最终实现对建筑物的智能化管理。
图片效果
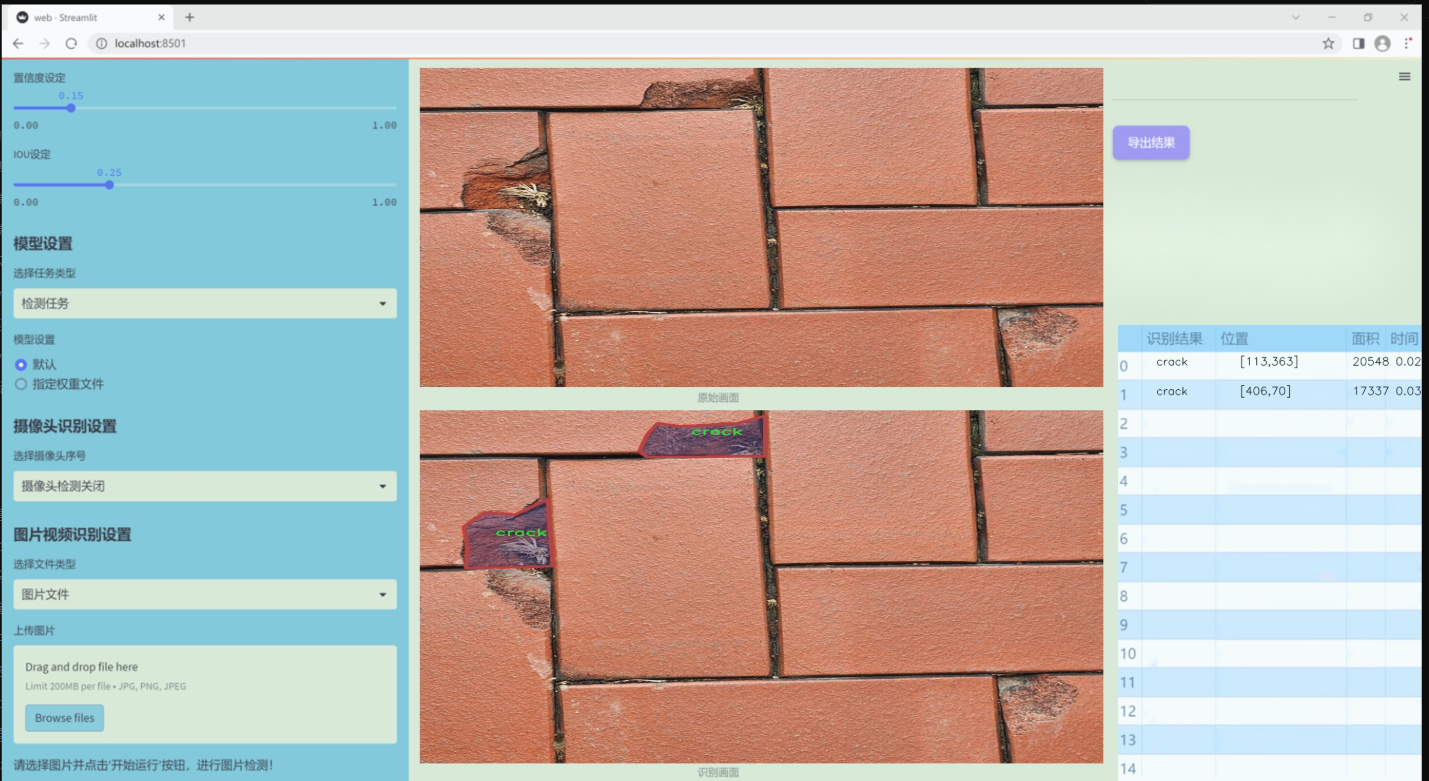
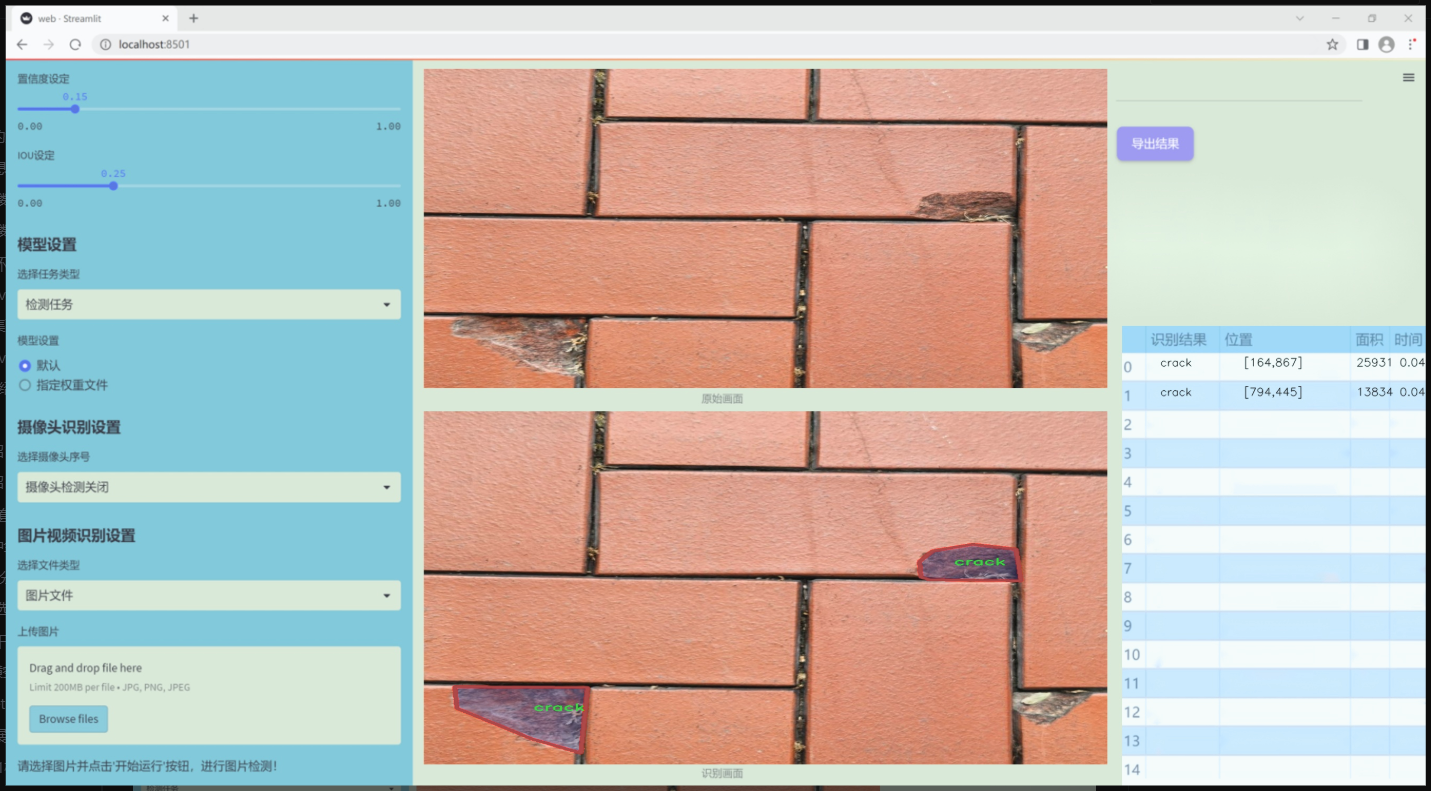
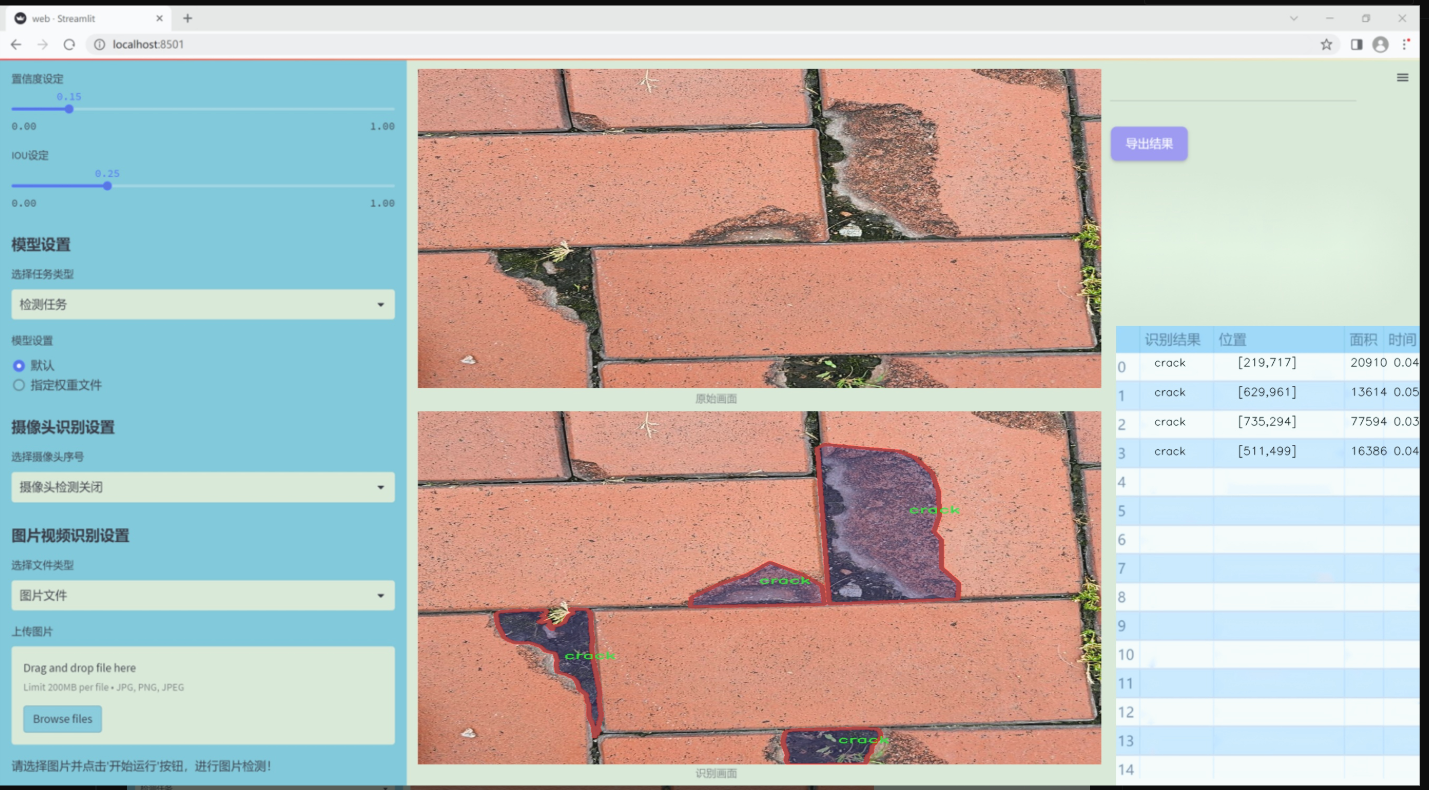
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“crack segmentation_ver2”,专门用于训练和改进YOLOv11模型,以实现高效的砖块裂缝检测与分割。该数据集的设计旨在为裂缝检测提供丰富的样本,以便模型能够准确识别和分割砖块表面的裂缝特征。数据集中包含的类别数量为1,具体类别为“crack”,即裂缝。这一单一类别的选择反映了项目的专注性,旨在深入研究裂缝的特征及其在不同环境和条件下的表现。
数据集中的图像样本涵盖了多种类型的砖块裂缝,确保了训练过程中模型能够接触到多样化的裂缝形态和背景。这些样本不仅包括不同尺寸和形状的裂缝,还涵盖了在不同光照条件、不同材质和不同磨损程度下的砖块表面。通过这种多样化的样本,模型将能够学习到裂缝的多种表现形式,从而提高其在实际应用中的鲁棒性和准确性。
在数据集的标注过程中,采用了精确的分割标注技术,确保每个裂缝的边界都被准确地标识。这种高质量的标注对于训练深度学习模型至关重要,因为它直接影响到模型的学习效果和最终的检测性能。通过使用“crack segmentation_ver2”数据集,项目旨在推动砖块裂缝检测技术的发展,为建筑物的安全监测和维护提供更为有效的解决方案。最终目标是实现一个能够在实际应用中快速、准确地检测和分割裂缝的智能系统,为相关领域的研究和应用提供有力支持。




核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttentionModule(nn.Module):
def init(self):
super(SpatialAttentionModule, self).init()
# 定义一个卷积层,用于生成空间注意力图
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid() # 使用Sigmoid激活函数将输出归一化到[0, 1]
def forward(self, x):
# 计算输入特征图的平均值和最大值
avgout = torch.mean(x, dim=1, keepdim=True) # 在通道维度上计算平均值
maxout, _ = torch.max(x, dim=1, keepdim=True) # 在通道维度上计算最大值
out = torch.cat([avgout, maxout], dim=1) # 将平均值和最大值拼接在一起
out = self.sigmoid(self.conv2d(out)) # 通过卷积层和Sigmoid激活函数生成注意力图
return out * x # 将注意力图与输入特征图相乘,进行加权
class LocalGlobalAttention(nn.Module):
def init(self, output_dim, patch_size):
super().init()
self.output_dim = output_dim
self.patch_size = patch_size
# 定义两个全连接层和一个卷积层
self.mlp1 = nn.Linear(patch_size * patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
# 定义可学习的参数
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1) # 调整维度顺序,方便处理
B, H, W, C = x.shape # 获取批量大小、高度、宽度和通道数
P = self.patch_size
# 处理局部特征
local_patches = x.unfold(1, P, P).unfold(2, P, P) # 获取局部patches
local_patches = local_patches.reshape(B, -1, P * P, C) # 重新调整形状
local_patches = local_patches.mean(dim=-1) # 计算每个patch的平均值
# 通过MLP处理局部特征
local_patches = self.mlp1(local_patches) # 第一层MLP
local_patches = self.norm(local_patches) # 归一化
local_patches = self.mlp2(local_patches) # 第二层MLP
local_attention = F.softmax(local_patches, dim=-1) # 计算局部注意力
local_out = local_patches * local_attention # 加权局部特征
# 计算与prompt的余弦相似度
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # 计算余弦相似度
mask = cos_sim.clamp(0, 1) # 限制在[0, 1]范围内
local_out = local_out * mask # 应用mask
local_out = local_out @ self.top_down_transform # 应用变换
# 恢复形状并进行上采样
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # 恢复形状
local_out = local_out.permute(0, 3, 1, 2) # 调整维度顺序
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False) # 上采样
output = self.conv(local_out) # 通过卷积层生成输出
return output
class PPA(nn.Module):
def init(self, in_features, filters) -> None:
super().init()
# 定义各个卷积层和注意力模块
self.skip = nn.Conv2d(in_features, filters, kernel_size=1, stride=1) # 跳跃连接
self.c1 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c2 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.c3 = nn.Conv2d(filters, filters, kernel_size=3, padding=1)
self.sa = SpatialAttentionModule() # 空间注意力模块
self.lga2 = LocalGlobalAttention(filters, 2) # 局部全局注意力模块
self.lga4 = LocalGlobalAttention(filters, 4) # 局部全局注意力模块
self.bn1 = nn.BatchNorm2d(filters) # 批归一化
self.silu = nn.SiLU() # SiLU激活函数
def forward(self, x):
# 通过各个层进行前向传播
x_skip = self.skip(x) # 跳跃连接
x_lga2 = self.lga2(x_skip) # 局部全局注意力
x_lga4 = self.lga4(x_skip) # 局部全局注意力
x1 = self.c1(x) # 第一层卷积
x2 = self.c2(x1) # 第二层卷积
x3 = self.c3(x2) # 第三层卷积
# 将各个特征图相加
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.sa(x) # 应用空间注意力
x = self.bn1(x) # 批归一化
x = self.silu(x) # 激活
return x # 返回最终输出
以上代码包含了空间注意力模块、局部全局注意力模块和PPA模块的核心实现。每个模块的功能和结构都有详细的中文注释,便于理解其工作原理。
这个程序文件 hcfnet.py 定义了一些用于深度学习的神经网络模块,主要包括空间注意力模块、局部全局注意力模块、ECA(有效通道注意力)、PPA(部分特征提取模块)和 DASI(双重注意力模块)。以下是对各个部分的详细说明。
首先,SpatialAttentionModule 类实现了一个空间注意力机制。它通过对输入特征图进行平均池化和最大池化操作,生成两个特征图,然后将这两个特征图拼接在一起,经过一个卷积层和 Sigmoid 激活函数,最终生成一个注意力权重图。这个权重图与输入特征图相乘,从而强调了重要的空间区域。
接下来,LocalGlobalAttention 类实现了局部和全局注意力机制。它首先将输入特征图进行分块处理,提取局部特征。然后通过两个全连接层和层归一化对局部特征进行处理,生成局部注意力。局部特征经过归一化后与一个可学习的提示向量进行余弦相似度计算,生成一个掩码。最后,局部特征与掩码相乘,并通过一个变换矩阵进行处理,恢复特征图的形状,并使用双线性插值上采样到原始尺寸。
ECA 类实现了一种有效的通道注意力机制。它通过自适应平均池化将输入特征图压缩为一个通道向量,然后使用一维卷积生成通道注意力权重。该权重与输入特征图相乘,以增强重要通道的特征。
PPA 类是一个特征提取模块,包含多个卷积层和注意力机制。它首先通过跳跃连接提取特征,然后将这些特征通过局部全局注意力模块和卷积层进行处理,最后通过空间注意力模块进一步调整特征图。模块的输出经过批归一化和激活函数处理,以增强特征的表达能力。
Bag 类实现了一种简单的加权机制,用于结合不同特征图的输出。它通过计算边缘注意力来决定如何加权输入特征图和部分特征图的组合。
最后,DASI 类是一个双重注意力模块,结合了低级特征和高级特征。它通过跳跃连接提取不同层次的特征,并通过 Bag 类结合这些特征。该模块还包含卷积层和批归一化层,最终输出经过激活函数处理的特征图。
整体来看,这个文件实现了一些复杂的注意力机制和特征提取模块,旨在提高深度学习模型在图像处理任务中的性能。
10.4 attention.py
以下是经过简化和注释的核心代码部分,主要保留了 EMA、SimAM、SpatialGroupEnhance、TopkRouting、KVGather、QKVLinear 和 BiLevelRoutingAttention 类。这些类实现了不同的注意力机制和特征增强模块,适用于深度学习模型中的特征处理。
import torch
from torch import nn
class EMA(nn.Module):
“”"
Exponential Moving Average (EMA) module for feature enhancement.
“”"
def init(self, channels, factor=8):
super(EMA, self).init()
self.groups = factor # 分组数
assert channels // self.groups > 0 # 确保每组至少有一个通道
self.softmax = nn.Softmax(-1) # Softmax激活函数
self.agp = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化
self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # 自适应池化,保持高度
self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # 自适应池化,保持宽度
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 分组归一化
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1) # 1x1卷积
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, padding=1) # 3x3卷积
def forward(self, x):
b, c, h, w = x.size() # 获取输入的尺寸
group_x = x.reshape(b * self.groups, -1, h, w) # 重新调整为分组形式
x_h = self.pool_h(group_x) # 对每组进行高度池化
x_w = self.pool_w(group_x).permute(0, 1, 3, 2) # 对每组进行宽度池化并转置
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2)) # 1x1卷积处理
x_h, x_w = torch.split(hw, [h, w], dim=2) # 分割为高度和宽度部分
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid()) # 归一化处理
x2 = self.conv3x3(group_x) # 3x3卷积处理
# 计算权重
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # 重新调整形状
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # 重新调整形状
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w) # 计算权重
return (group_x * weights.sigmoid()).reshape(b, c, h, w) # 返回加权后的特征
class SimAM(nn.Module):
“”"
Similarity Attention Module (SimAM) for enhancing feature representation.
“”"
def init(self, e_lambda=1e-4):
super(SimAM, self).init()
self.activaton = nn.Sigmoid() # Sigmoid激活函数
self.e_lambda = e_lambda # 正则化参数
def forward(self, x):
b, c, h, w = x.size() # 获取输入的尺寸
n = w * h - 1 # 计算总的像素点数
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2) # 计算方差
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5 # 计算注意力
return x * self.activaton(y) # 返回加权后的特征
class SpatialGroupEnhance(nn.Module):
“”"
Spatial Group Enhancement module for enhancing spatial features.
“”"
def init(self, groups=8):
super().init()
self.groups = groups # 分组数
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
self.weight = nn.Parameter(torch.zeros(1, groups, 1, 1)) # 权重参数
self.bias = nn.Parameter(torch.zeros(1, groups, 1, 1)) # 偏置参数
self.sig = nn.Sigmoid() # Sigmoid激活函数
self.init_weights() # 初始化权重
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out') # Kaiming初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置初始化为0
def forward(self, x):
b, c, h, w = x.shape # 获取输入的尺寸
x = x.view(b * self.groups, -1, h, w) # 重新调整为分组形式
xn = x * self.avg_pool(x) # 计算增强特征
xn = xn.sum(dim=1, keepdim=True) # 求和
t = xn.view(b * self.groups, -1) # 重新调整形状
t = t - t.mean(dim=1, keepdim=True) # 去均值
std = t.std(dim=1, keepdim=True) + 1e-5 # 计算标准差
t = t / std # 归一化
t = t.view(b, self.groups, h, w) # 重新调整形状
t = t * self.weight + self.bias # 加权
t = t.view(b * self.groups, 1, h, w) # 重新调整形状
x = x * self.sig(t) # 加权输入特征
return x.view(b, c, h, w) # 返回增强后的特征
class TopkRouting(nn.Module):
“”"
Differentiable Top-k Routing module for attention mechanism.
“”"
def init(self, qk_dim, topk=4):
super().init()
self.topk = topk # Top-k参数
self.qk_dim = qk_dim # 查询和键的维度
self.scale = qk_dim ** -0.5 # 缩放因子
self.routing_act = nn.Softmax(dim=-1) # Softmax激活函数
def forward(self, query: Tensor, key: Tensor):
"""
Args:
query: (n, p^2, c) tensor
key: (n, p^2, c) tensor
Return:
r_weight, topk_index: (n, p^2, topk) tensor
"""
query_hat, key_hat = query, key # 直接使用输入
attn_logit = (query_hat * self.scale) @ key_hat.transpose(-2, -1) # 计算注意力日志
topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1) # 获取Top-k
r_weight = self.routing_act(topk_attn_logit) # 计算路由权重
return r_weight, topk_index # 返回权重和索引
class KVGather(nn.Module):
“”"
Key-Value Gather module for attention mechanism.
“”"
def init(self, mul_weight=‘none’):
super().init()
assert mul_weight in [‘none’, ‘soft’, ‘hard’] # 确保权重类型有效
self.mul_weight = mul_weight # 权重类型
def forward(self, r_idx: Tensor, r_weight: Tensor, kv: Tensor):
"""
r_idx: (n, p^2, topk) tensor
r_weight: (n, p^2, topk) tensor
kv: (n, p^2, w^2, c_kq+c_v)
Return:
(n, p^2, topk, w^2, c_kq+c_v) tensor
"""
n, p2, w2, c_kv = kv.size() # 获取kv的尺寸
topk = r_idx.size(-1) # 获取Top-k数量
topk_kv = torch.gather(kv.view(n, 1, p2, w2, c_kv).expand(-1, p2, -1, -1, -1), # 根据索引选择kv
dim=2,
index=r_idx.view(n, p2, topk, 1, 1).expand(-1, -1, -1, w2, c_kv)) # 扩展索引
if self.mul_weight == 'soft':
topk_kv = r_weight.view(n, p2, topk, 1, 1) * topk_kv # 软加权
return topk_kv # 返回选择的kv
class QKVLinear(nn.Module):
“”"
QKV Linear mapping for attention mechanism.
“”"
def init(self, dim, qk_dim, bias=True):
super().init()
self.qkv = nn.Linear(dim, qk_dim + qk_dim + dim, bias=bias) # 线性映射
def forward(self, x):
q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim + x.size(1)], dim=-1) # 分割为q和kv
return q, kv # 返回q和kv
class BiLevelRoutingAttention(nn.Module):
“”"
Bi-Level Routing Attention module for enhanced attention mechanism.
“”"
def init(self, dim, num_heads=8, n_win=7, qk_dim=None, topk=4):
super().init()
self.dim = dim # 输入维度
self.n_win = n_win # 窗口数量
self.num_heads = num_heads # 注意力头数量
self.qk_dim = qk_dim or dim # 查询和键的维度
self.router = TopkRouting(qk_dim=self.qk_dim, topk=topk) # 初始化路由模块
self.kv_gather = KVGather(mul_weight=‘soft’) # 初始化kv收集模块
self.qkv = QKVLinear(self.dim, self.qk_dim) # 初始化QKV线性映射
def forward(self, x):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
b, c, h, w = x.size() # 获取输入的尺寸
q, kv = self.qkv(x) # 进行QKV映射
# 进行注意力计算...
return x # 返回处理后的特征
代码说明
EMA: 实现了指数移动平均的特征增强模块,通过对输入特征进行分组处理和加权来增强特征表示。
SimAM: 实现了相似性注意力模块,通过计算特征的方差来生成注意力权重,增强特征的表示能力。
SpatialGroupEnhance: 实现了空间分组增强模块,通过自适应池化和分组归一化来增强空间特征。
TopkRouting: 实现了可微分的Top-k路由机制,用于注意力计算。
KVGather: 实现了键值收集模块,根据路由索引选择相应的键值对。
QKVLinear: 实现了QKV线性映射,将输入特征映射到查询、键和值。
BiLevelRoutingAttention: 实现了双层路由注意力机制,结合了上述模块以增强注意力计算。
这些模块可以用于构建复杂的深度学习模型,特别是在计算机视觉任务中。
这个程序文件 attention.py 实现了一系列的注意力机制模块,主要用于深度学习中的视觉任务。以下是对代码的详细说明:
首先,文件导入了必要的库,包括 PyTorch 和一些用于深度学习的模块。然后定义了一些注意力机制的类,这些类实现了不同类型的注意力机制,例如 EMA(Exponential Moving Average)、SimAM(Similarity Attention Module)、SpatialGroupEnhance、TopkRouting、KVGather、QKVLinear、BiLevelRoutingAttention 等。
每个类都继承自 nn.Module,并实现了 init 和 forward 方法。init 方法用于初始化模型的参数和结构,而 forward 方法则定义了数据的前向传播过程。
例如,EMA 类实现了一种基于通道的注意力机制,通过对输入特征图进行分组、池化和卷积操作,生成加权的输出特征图。SimAM 类则实现了一种基于相似度的注意力机制,通过计算输入特征的均值和方差来生成注意力权重。
BiLevelRoutingAttention 类实现了一种双层路由注意力机制,允许在多个窗口之间进行信息传递。它通过对查询、键和值进行线性变换,并计算注意力权重来实现这一点。
此外,文件中还实现了一些其他的注意力机制模块,如 CoordAtt、TripletAttention、BAMBlock、EfficientAttention、LSKBlock、SEAttention、CPCA、MPCA 等。这些模块在视觉任务中各有其独特的作用,能够有效地增强模型的表达能力。
例如,CoordAtt 类实现了坐标注意力机制,通过对输入特征图的水平和垂直方向进行池化,生成通道注意力权重。TripletAttention 类则结合了通道、空间和组合注意力,增强了特征图的表达能力。
在 forward 方法中,输入特征图经过不同的操作后,输出加权后的特征图。这些注意力机制可以被集成到更大的神经网络中,以提高模型在图像分类、目标检测和语义分割等任务中的性能。
总的来说,这个文件实现了多种注意力机制模块,提供了灵活的接口,可以在深度学习模型中进行组合和使用,以增强模型的性能和表达能力。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)