自适应RAG:用本地 LLM 构建更聪明的检索增强生成系统,大模型从入门到精通,收藏这篇就够了
本文我们将用 LangGraph + 本地 LLM(Ollama + Mistral) 搭建一个 Adaptive RAG 系统,能在 Web 搜索 和 向量库检索 之间灵活切换,还能自我纠错。
大模型越来越强大,但它们依旧有一个致命短板:知识更新慢。如果直接问 ChatGPT 之类的模型一个近期事件的问题,它很可能答不上来。这就是为什么 RAG(检索增强生成) 变得重要 —— 在回答问题之前,先去找相关资料,再让模型结合这些资料生成答案。
不过,RAG 并不是“一刀切”的方案:有些问题根本不需要检索(比如定义类问题),有些问题需要一次检索就能解决,而另一些则需要多次尝试(比如先改写问题,再检索)。这就是 自适应RAG 的核心:根据问题的不同,动态选择最合适的策略。
本文我们将用 LangGraph + 本地 LLM(Ollama + Mistral) 搭建一个 Adaptive RAG 系统,能在 Web 搜索 和 向量库检索 之间灵活切换,还能自我纠错。
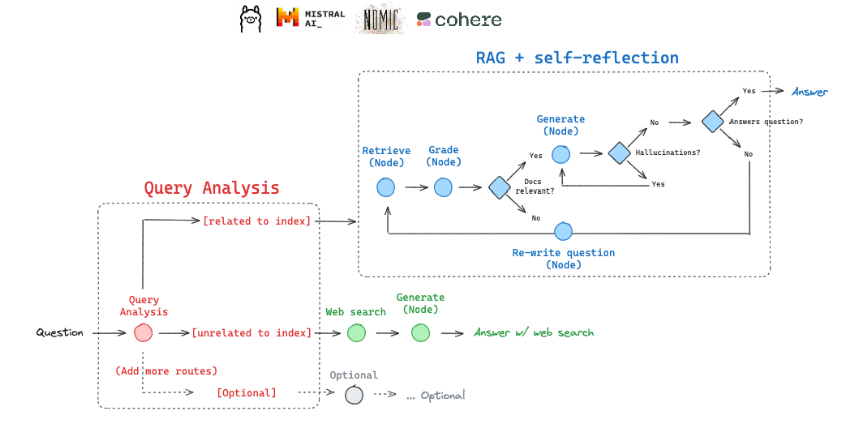
注意:我们的 Adaptive RAG 系统有两个主要分支:
Web Search:处理最近事件相关的问题(因为向量库的数据是历史快照,不会包含最新信息)。借助 Tavily 搜索 API 获取网页结果,再交给 LLM 组织答案。
Self-Corrective RAG:针对我们自己构建的知识库(这里我们抓取了 Lilian Weng 的几篇经典博客:Agent、Prompt Engineering、Adversarial Attack)。向量库用****Chroma 搭建,文本向量用 Nomic 本地 Embedding 生成。如果第一次检索结果不相关,会尝试改写问题,再次检索。同时会过滤掉“答非所问”的文档,避免垃圾结果。
- 环境准备
%capture --no-stderr
%pip install -U langchain-nomic langchain_community tiktoken langchainhub chromadb langchain langgraph tavily-python nomic[local]
设置 API Key(Tavily 搜索 + Nomic embedding)。
import getpass, os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("TAVILY_API_KEY")
_set_env("NOMIC_API_KEY")
- 本地模型和向量库
我们将要构建了一个 向量数据库,内容是 Lilian Weng 的三篇博客。以后凡是涉及 Agent/Prompt Engineering/Adversarial Attack 的问题,就走这里。
# Ollama 模型
local_llm = "mistral"
# 文本切分 & 向量化
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_nomic.embeddings import NomicEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=NomicEmbeddings(model="nomic-embed-text-v1.5", inference_mode="local"),
)
retriever = vectorstore.as_retriever()
- 问题路由器(Router)
假如这个问题和 Agent 相关,所以走向量库。
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
llm = ChatOllama(model=local_llm, format="json", temperature=0)
prompt = PromptTemplate(
template="""You are an expert at routing a user question to a vectorstore or web search...
Question to route: {question}""",
input_variables=["question"],
)
question_router = prompt | llm | JsonOutputParser()
question = "llm agent memory"
print(question_router.invoke({"question": question}))
执行结果
{'datasource': 'vectorstore'}
- 检索质量评估(Retrieval Grader)
如果检索到的文档与问题相关。
retrieval_grader = prompt | llm | JsonOutputParser()
question = "agent memory"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
执行结果
{'score': 'yes'}
- 答案生成(RAG Generate)
成了一段关于 “Agent Memory” 的解释。
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOllama(model=local_llm, temperature=0)
rag_chain = prompt | llm | StrOutputParser()
question = "agent memory"
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
执行结果
In an LLM-powered autonomous agent system, the Large Language Model (LLM) functions as the agent's brain...
- 幻觉检测(Hallucination Grader)
如果答案确实是基于文档生成的,没有瞎编。如果答案不靠谱,就让系统重新检索或改写问题。
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
执行结果
{'score': 'yes'}
- 答案有用性评估(Answer Grader)
如果这个答案对用户有用。
answer_grader.invoke({"question": question, "generation": generation})
执行结果
{'score': 'yes'}
- 问题重写器(Question Rewriter)
改成了更适合检索的问法。
question_rewriter.invoke({"question": question})
执行结果
'What is agent memory and how can it be effectively utilized in vector database retrieval?'
- Web 搜索工具
当问题和近期事件有关时,就会走 Tavily 搜索,而不是本地库。
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)
执行结果日志
---ROUTE QUESTION---
What is the AlphaCodium paper about?
{'datasource': 'web_search'}
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'---'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'---'
('The AlphaCodium paper introduces a new approach for code generation...')
10.工作流(LangGraph 具体实现)
我们用 LangGraph 把这些步骤连起来,形成一个有条件分支的工作流:
- 开始 → 判断走 Web Search 还是 Vectorstore
- 如果走 Vectorstore:检索 → 文档过滤 →
-
如果靠谱 → 返回结果
-
如果不靠谱 → 改写问题 → 再检索
-
如果没文档:改写问题 → 再检索
-
如果有文档:生成答案 → 检查是否靠谱
- 如果走 Web Search:直接搜 → 生成答案 → 检查 → 返回结果
最终,系统能在不同类型的问题上灵活切换,而不是死板地“一问一搜”。
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]
### Nodes
from langchain.schema import Document
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score["score"]
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}
### Edges ###
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
print(question)
source = question_router.invoke({"question": question})
print(source)
print(source["datasource"])
if source["datasource"] == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif source["datasource"] == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score["score"]
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
inputs = {"question": "What is the AlphaCodium paper about?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
pprint(value["generation"])
执行结果
---ROUTE QUESTION---
What is the AlphaCodium paper about?
{'datasource': 'web_search'}
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'---'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'---'
('The AlphaCodium paper introduces a new approach for code generation...')
我们写的这套 自适应 RAG 系统展示了几个关键点:
灵活路由:不同问题走不同管道(Web / Vectorstore)。
自我纠错:检索结果不相关时,自动改写问题再试。
质量把控:通过“幻觉检测 + 答案有用性判断”,尽量避免胡编乱造。
本地化:Embedding 和 LLM 都可以跑在本地(隐私友好,节省成本)。
未来可以扩展的方向包括:增加“多步推理”路线(先子问题分解,再检索)。更细的路由分类(比如结构化查询 vs 自然语言查询)。融合图数据库或知识图谱,增强事实性。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础第二不要求准备高配置的电脑第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)