K8S核心组件:Init容器与临时容器详解
Init Container就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行,只有所有的Init Container执行完后,主容器才会被启动。一个Pod里面的所有容器是共享数据卷和网络命名空间的,所以Init Container里面产生的数据可以被主容器使用到的。
目录
1.3、服务质量优先级(Quality of Service Priority)
一、init初始化容器
1、init初始化概述
Init Container就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行,只有所有的Init Container执行完后,主容器才会被启动。一个Pod里面的所有容器是共享数据卷和网络命名空间的,所以Init Container里面产生的数据可以被主容器使用到的。
Init Container和之前的钩子函数有点类似,只是是在容器执行前来做一些工作,从直观的角度看上去的话,初始化容器的确有点像PreStart,但是钩子函数和我们的InitContainer是处在不同的阶段的,我们可以通过下面的图来了解:
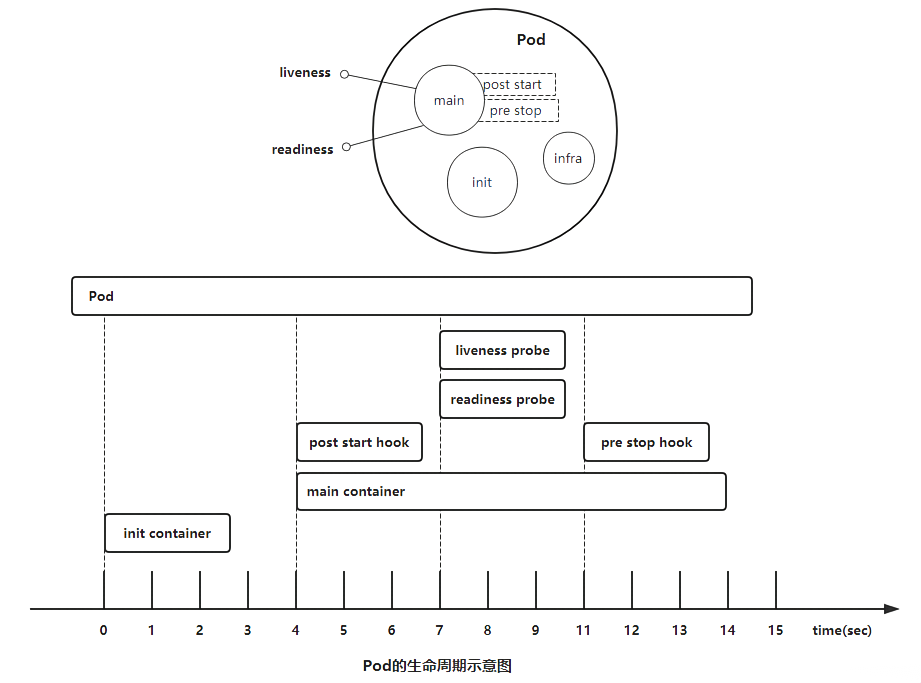
从上面这张图我们可以直观的看到PostStart和PreStop包括liveness和readiness是属于主容器的生命周期范围内的,而Init Container是独立于主容器之外的,当然他们都属于Pod的生命周期范畴之内的。
另外我们可以看到上面我们的Pod右边还有一个infra的容器,我们可以在集群环境中去查看下任意一个Pod对应的运行的Docker容器,可以发现每一个Pod下面都包含了一个pause-amd64的镜像,这个就是我们的infra镜像,我们知道Pod下面的所有容器是共享同一个网络命名空间的,这个镜像就是来做这个事情的,所以每一个Pod当中都会包含一个这个镜像。 很多 Pod 启动不起来就是因为这个 infra 镜像没有被拉下来,所以需要提前拉取到节点上面。
1.1、Init容器与普通容器区别
-
Init容器总是运行到成功为止。
-
每个Init容器都必须在下一个Init容器启动之前成功完成。
如果Pod的Init容器失败,Kubenetes会不断地重启该Pod,直到Init容器成功为止。然而,如果Pod对应的restartPolicy为Never,它不会重新启动
1.2、Init容器的优势
-
可以包含并运行实用工具。出于安全考虑,不建议在应用程序容器镜像中包含这些实用工具的。
-
可以包含实用工具和定制代码来安装,但是不能出现在应用程序容器镜像中。例如:创建镜像没有必要FROM另一个镜像,只需要在安装过程中使用类似sed、awk、python或dig这样的工具。
-
应用程序容器镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像。
-
Init容器使用LinuxNamespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,Init容器能够具有Secret的权限,而应用程序容器则不能。
-
它们必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供一种简单的阻塞或延迟应用程序容器的启动方法,直到满足先决条件。
1.3、Init容器应用场景
-
等待其他模块Ready:可以用来解决服务之间的依赖问题,比如我们有一个 Web服务,该服务又依赖于另外一个数据库服务,但是在我们启动这个 Web服务的时候我们并不能保证依赖的这个数据库服务就已经启动起来了,所以可能会出现一段时间内 Web服务连接数据库异常。要解决这个问题的话我们就可以在 Web 服务的 Pod 中使用一个init Container,在这个初始化容器中去检查数据库是否已经准备好了,准备好了过后初始化容器就结束退出,然后我们的主容器 Web服务被启动起来,这个时候去连接数据库就不会有问题了。
-
做初始化配置:比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。
-
其它场景:如将 pod 注册到一个中央数据库、配置中心等。
2、Init容器使用案例
[root@k8s-master01 ~]# cat init-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: init-demo
labels:
demo: init-demo
spec:
containers:
- name: init-demo
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-demo1
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice;sleep 2; done;']
- name: init-demo2
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'until nslookup mysql; do echo waiting for mysql; sleep 2;done;']
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- port: 5566
targetPort: 6655
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 8899
targetPort: 9988
protocol: TCP
##验证
[root@k8s-master01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-demo 0/1 Init:0/2 0 6s
[root@k8s-master01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-demo 1/1 Running 0 4m24s
[root@k8s-master01 ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.10.0.1 <none> 443/TCP 13m
myservice ClusterIP 10.10.202.229 <none> 5566/TCP 40s
mysql ClusterIP 10.10.222.227 <none> 8899/TCP 39s
[root@k8s-master01 ~]# kubectl logs init-demo -c init-demo13、init初始化容器说明
-
在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出
-
如果由于运行时或失败退出,将导致容器启动失败,它会根据 PodrestartPolicy指定的策略进行重试。然而,如果Pod的restartPolicy设置为Always,Init容器失败时会RestartPolicy策略。
-
在所有的Init容器没有成功之前,Pod将不会变成Ready状态。Init容器的端口将不会在Service中进行聚集。正在初始化中的Pod处于Pending状态,但应该会将Initializing状态设置为true
-
如果Pod重启,所有的Init容器必须重新执行
-
对Init容器spec的修改被限制在容器image字段,修改其他字段都不会生效。更改Init容器的Image字段,等价于重启该Pod。
-
Init容器具有应用容器的所有字段。除了readinessProbe,因为Init容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行。
-
在Pod中的每个app和Init容器名称必须唯一;与任何其他容器共享同一个名称,会在验证时抛出错误。
二、临时容器 Ephemeral Containers
1、概述
临时容器与其他容器的不同之处在于,它们缺少对资源或执行的保证,并且永远不会自动重启,因此不适用于构建应用程序。临时容器使用与常规容器相同的 Container.Spec字段进行描述,但许多字段是不允许使用的。
-
临时容器没有端口配置,因此像 ports,livenessProbe,readinessProbe 这样的字段是不允许的。
-
Pod 资源分配是不可变的,因此 resources 配置是不允许的。
临时容器是使用 API 中的一种特殊的 ephemeralcontainers处理器进行创建的, 而不是直接添加到 pod.spec段,因此无法使用 kubectl edit来添加一个临时容器。
与常规容器一样,将临时容器添加到 Pod 后,将不能更改或删除临时容器。
2、用途
-
当由于容器崩溃或容器镜像不包含调试工具而导致 kubectl exec 无用时, 临时容器对于交互式故障排查很有用。
-
尤其是,Distroless 镜像 允许用户部署最小的容器镜像,从而减少攻击面并减少故障和漏洞的暴露。 由于 distroless镜像不包含 Shell 或任何的调试工具,因此很难单独使用 kubectl exec 命令进行故障排查。
-
使用临时容器时,启用 进程名称空间共享 很有帮助,可以查看其他容器中的进程。
什么是distroless镜像
K8s distroless 是一个 Kubernetes 发行版,它专注于提供轻量级的 Kubernetes 环境,删除了许多默认的工具和组件,以减小 Kubernetes 的存储空间和资源占用。
K8s distroless 使用 Go 语言编写,并使用原生 Kubernetes API 进行集群管理。它删除了许多 Kubernetes 中的默认工具,例如 kubectl、kube-proxy、kubelet 等,并提供了自己的命令行工具来管理集群。
K8s distroless 的主要特点包括:
-
轻量化:K8s distroless 删除了许多默认的工具和组件,以减小 Kubernetes 的存储空间和资源占用。
-
易于部署:K8s distroless 可以轻松地在各种平台上部署,包括云端、本地和容器环境中。
-
高效能:K8s distroless 使用原生 Kubernetes API 进行集群管理,提供了高效的资源利用和管理。
-
安全性:K8s distroless 提供了高度的安全性,包括自动更新、自动补丁和严格的安全策略。
K8s distroless 适合那些想要使用 Kubernetes 进行容器编排,但不想安装大量默认工具和组件的用户。它提供了一种简单、高效和安全的 Kubernetes 解决方案。
3、使用临时容器
创建一个部署nginx的pod
[root@k8s-master01 ~]# cat pod-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
namespace: default
labels:
app: nginx
spec:
containers:
- name: nginx
ports:
- containerPort: 80
image: nginx
imagePullPolicy: IfNotPresent
##提交
[root@k8s-master01 ~]# kubectl apply -f pod-nginx.yaml
##查看
[root@k8s-master01 ~]# kubectl get pod pod-nginx.yaml创建临时容器
[root@k8s-master01 ~]# kubectl debug -it nginx-test --image=busybox:1.28 --target=nginx
Defaulting debug container name to debugger-6m2s8.
If you don't see a command prompt, try pressing enter.
/ #ps -ef | grep nginx查看nginx-test这个pod是否已经有临时容器
[root@k8s-master01 ~]# kubectl describe pods nginx-test一、node节点选择器
我们在创建pod资源的时候,pod会根据schduler进行调度,那么默认会调度到随机的一个工作节点,如果我们想要pod调度到指定节点或者调度到一些具有相同特点的node节点,怎么办呢?
可以使用pod中的nodeName或者nodeSelector字段指定要调度到的node节点。
1、nodeName
指定pod节点运行在哪个具体node上
[root@k8s-master ~]# cat pod-node.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod1
namespace: default
labels:
app: myapp
env: dev
spec:
nodeName: k8s-node1
containers:
- name: nginx-nodename
ports:
- containerPort: 80
image: nginx
imagePullPolicy: IfNotPresent
[root@k8s-master ~]# kubectl apply -f pod-node.yaml
#查看pod调度到哪个节点
[root@k8s-master ~]# kubectl get pods -o wide2、nodeSelector
指定pod调度到具有哪些标签的node节点上
#给node节点打标签,打个具有disk=ceph的标签
[root@k8s-master ~]# kubectl label nodes k8s-node1 node=worker01
#查看节点的详细信息
[root@hd1 node]# kubectl describe nodes k8s-node1
#定义pod的时候指定要调度到具有 node=worker01标签的node上
[root@k8s-master ~]# cat pod-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod-1
namespace: default
labels:
app: myapp
env: dev
spec:
nodeSelector:
node: worker01
containers:
- name: nginx-nodename
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
[root@k8s-master ~]# kubectl apply -f pod-1.yaml
#查看pod调度到哪个节点
[root@k8s-master ~]# kubectl get pods -o wide二、Pod亲和性
生产上为了保证应用的高可用性,需要将同一应用的不同pod分散在不同的宿主机上,以防宿主机出现宕机等情况导致pod重建,影响到业务的连续性。要想实现这样的效果,需要用到k8s自带的pod亲和性和反亲和性特性。
Pod 的亲和性与反亲和性有两种类型:
requiredDuringSchedulingIgnoredDuringExecution ##一定满足
preferredDuringSchedulingIgnoredDuringExecution ##尽量满足podAffinity(亲和性):pod和pod更倾向腻在一起,把相近的pod结合到相近的位置,如同一区域,同一机架,这样的话pod和pod之间更好通信,比方说有两个机房,这两个机房部署的集群有1000台主机,那么我们希望把nginx和tomcat都部署同一个地方的node节点上,可以提高通信效率;
podAntiAffinity(反亲和性):pod和pod更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个pod随机选则一个节点,做为评判后续的pod能否到达这个pod所在的节点上的运行方式,这就称为pod亲和性;我们怎么判定哪些节点是相同位置的,哪些节点是不同位置的;我们在定义pod亲和性时需要有一个前提,哪些pod在同一个位置,哪些pod不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
1、 常用字段解析
[root@k8s-master ~]# kubectl explain pods.spec.affinity.podAffinity
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
#硬亲和性
requiredDuringSchedulingIgnoredDuringExecution
#软亲和性
preferredDuringSchedulingIgnoredDuringExecution
[root@k8s-master ~]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution
FIELDS:
labelSelector <Object>
namespaces <[]string>
topologyKey <string> -required-
#位置拓扑的键,这个是必须字段
#topologyKey
#怎么判断是不是同一个位置?
#使用rack的键是同一个位置
#rack=rack1
#使用row的键是同一个位置
#row=row1
#要判断pod跟别的pod亲和,跟哪个pod亲和,需要靠labelSelector,通过labelSelector选则一组能作为亲和对象的pod资源
#labelSelector:
#labelSelector需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过namespace指定,如果不指定namespaces,那么就是当前创建pod的名称空间
#namespace:
[root@k8s-master ~]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector
FIELDS:
matchExpressions <[]Object>
matchLabels <map[string]string>
#匹配表达式
#matchExpressions <[]Object>2、 案例演示
2.1 pod节点亲和性
[root@k8s-master ~]# cat pod-required-affinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app2: myapp2
tier: frontend
spec:
containers:
- name: myapp
image: nginx
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app2, operator: 'In', values: ["myapp2"]}
topologyKey: kubernetes.io/hostname上面表示创建的pod必须与拥有app=myapp2标签的pod在一个节点上
[root@k8s-master ~]# kubectl apply -f pod-required-affinity-demo.yaml
[root@k8s-master ~]# kubectl get pods -o wide2.2 pod节点反亲和性
[root@hd1 node]# kubectl delete -f pod-required-affinity-demo.yaml
[root@k8s-master ~]# cat pod-required-anti-affinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1-first
labels:
app1: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: nginx
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Pod
metadata:
name: pod2-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app1
operator: 'In'
values:
- myapp1
topologyKey: kubernetes.io/hostname
[root@k8s-master ~]# kubectl apply -f pod-required-anti-affinity-demo.yaml
[root@k8s-master ~]# kubectl get pods -o wide 2.3 换一个topologykey
[root@k8s-master ~]# kubectl label nodes k8s-node1 zone=foo
[root@k8s-master ~]# kubectl label node k8s-node2 zone=foo --overwrite
[root@k8s-master ~]# cat pod-first-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod3-first
labels:
app3: myapp3
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
[root@k8s-master ~]# cat pod-second-required-anti-affinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod3-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:1.28
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app3 ,operator: 'In', values: ["myapp3"]}
topologyKey: zone
[root@k8s-master ~]# kubectl apply -f pod-first-required-anti-affinity-demo-1.yaml
[root@k8s-master ~]# kubectl apply -f pod-second-required-anti-affinity-demo-2.yaml
[root@k8s-master ~]# kubectl get pods -o wide
#发现第二个节点是pending,因为两个节点是同一个位置,现在不是同一个位置的了,而且我们要求反亲和性,所以就会处于pending状态,如果在反亲和性这个位置把required改成preferred,那么也会运行。
#podaffinity:pod节点亲和性,pod倾向于哪个pod
#nodeaffinity:node节点亲和性,pod倾向于哪个node三、资源限制
resources四、污点与容忍
前面介绍了节点亲和性调度,它可以使得我们的Pod调度到指定的Node节点上,而污点(Taints)与之相反,它可以让Node拒绝Pod的运行,甚至驱逐已经在该Node上运行的Pod
污点是Node上设置的一个属性,通常设置污点表示该节点有问题,比如磁盘要满了,资源不足,或者该Node正在升级暂时不能提供使用等情况,这时不希望再有新的Pod进来,这个时候就可以给该节点设置一个污点。
但是有的时候其实Node节点并没有故障,只是不想让一些Pod调度进来,比如这台节点磁盘空间比较大,希望是像Elasticsearch、Minio这样需要较大磁盘空间的Pod才调度进来,那么就可以给节点设置一个污点,给Pod设置容忍(Tolerations)对应污点,如果再配合节点亲和性功能还可以达到独占节点的效果
一般时候 Taints 总是与 Tolerations配合使用
1、污点(Taints)
设置污点后,一般Pod将不会调度到该节点上来。每次Pod都不会调度到master节点,那是因为搭建K8s集群的时候,K8s给master自带了一个污点。
1.1、查看污点
查看master上是否有污点,通过describe命令可以看到节点上的所有污点
[root@k8s-master ~]# kubectl describe node k8s-master
...
Taints: node-role.kubernetes.io/control-plane:NoSchedule
...还可以通过如下命令查看
[root@k8s-master ~]# kubectl get nodes k8s-master -o go-template={{.spec.taints}}
[map[effect:NoSchedule key:node-role.kubernetes.io/control-plane]]发现master上自带了一个没有value的污点 node-role.kubernetes.io/control-plane ,effect 为 NoSchedule,由于我们的Pod都没有容忍这个污点,所以一直都不会调度到master
1.2、污点类别
上面我们看到了污点有一个effect 属性为NoSchedule,其实还有其它两种类别分别是 PreferNoSchedule与 NoExecute
-
NoSchedule: 如果没有容忍该污点就不能调度进来。
-
PreferNoSchedule: 相当于NoExecute的一个软限制,如果没有容忍该污点,尽量不要把Pod调度进来,但也不是强制的。
-
NoExecute: 如果没有设置容忍该污点,新的Pod肯定不会调度进来, 并且已经在运行的Pod没有容忍该污点也会被驱逐。
1.3、设置污点
污点分别由key、value(可以为空)、effect 组成,设置命令如下
# 设置污点并不允许Pod调度到该节点
$ kubectl taint node k8s-node1 key=value:NoSchedule
# 设置污点尽量不要让Pod调度到该节点
$ kubectl taint node k8s-node1 key=value:PreferNoSchedule
# 设置污点,不允许Pod调度到该节点,并且且将该节点上没有容忍该污点的Pod将进行驱逐
$ kubectl taint node k8s-node1 key=value:NoExecute1.4、删除污点
# 删除该key的所有污点
$ kubectl taint node k8s-node1 key-
# 删除该key的某一个污点
$ kubectl taint node k8s-node1 key=value:NoSchedule-
# 删除该key的某一个污点可以不写value
$ kubectl taint node k8s-node1 key:NoSchedule-1.5、污点测试
给k8s-node1节点设置一个污点,表示只有前台web应用才能调度,后端app应用不能调度
[root@k8s-master ~]# kubectl taint node k8s-node1 web=true:NoSchedule
node/k8s-node1 tainted编写 web-taint.yaml 内容如下,有三个Pod均没有容忍该污点
apiVersion: v1
kind: Pod
metadata:
name: web-taint1
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent # 本地有不拉取镜像
---
apiVersion: v1
kind: Pod
metadata:
name: web-taint2
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent # 本地有不拉取镜像
---
apiVersion: v1
kind: Pod
metadata:
name: web-taint3
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent # 本地有不拉取镜像启动Pod,观察Pod是否都被调度到k8s-node2节点
# 启动三个Pod
[root@k8s-master taint]# kubectl apply -f web-taint.yaml
pod/web-taint1 applyd
pod/web-taint2 applyd
pod/web-taint3 applyd
# 查看pod详情发现均被调度到k8s-node2节点
[root@k8s-master taint]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-taint1 1/1 Running 0 13s 10.244.2.35 k8s-node2 <none> <none>
web-taint2 1/1 Running 0 13s 10.244.2.34 k8s-node2 <none> <none>
web-taint3 1/1 Running 0 13s 10.244.2.36 k8s-node2 <none> <none>给k8s-node2节点添加污点 app=true:NoExecute,表示只有后端服务才能调度进来,并且已经在k8s-node2节点上运行的不是后端服务的节点将被驱逐
# 设置污点
[root@k8s-master taint]# kubectl taint node k8s-node2 app=true:NoExecute
node/k8s-node2 tainted
# 查看Pod详情,发现三个Pod已经被驱逐
[root@k8s-master taint]# kubectl get pod -o wide
No resources found in default namespace.从上面可以知道我们虽然设置了污点,但是我们的节点其实很正常,既然是正常节点,那么就可以有服务运行,这就需要用到容忍机制来运行这些Pod
2、容忍(Toletations)
如果需要Pod忽略Node上的污点,就需要给Pod设置容忍,并且是需要容忍该Pod上的所有污点。
通过 kubectl explain pod.spec.tolerations 可以查看容忍的配置项
2.1、配置项
tolerations: # 数组类型,可以设置多个容忍
- key: # 污点key
operator: # 操作符,有两个选项 Exists and Equal 默认是Equal
value: # 污点value,如果使用Equal需要设置,如果是Exists就不需要设置
effect: # 可以设置为NoSchedule、PreferNoSchedule、NoExecute,如果为空表示匹配该key下所有污点,
tolerationSeconds: # 如果污点类型为NoExecute,还可以设置一个时间,表示这一个时间段内Pod不会被驱逐,过了这个时间段会立刻驱逐,0或者负数会被立刻驱逐2.2、设置容忍
给Pod设置容忍k8s-node1节点的污点web=true:NoSchedule
编写 web-tolerations.yaml 内容如下,容忍污点web=true:NoSchedule
apiVersion: v1
kind: Pod
metadata:
name: web-tolerations
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent # 本地有不拉取镜像
tolerations:
- key: web
operator: Equal
value: "true"
effect: NoSchedule启动web-tolerations,观察Pod是否正常运行
# 启动web-tolerations
[root@k8s-master taint]# kubectl apply -f web-tolerations.yaml
pod/web-tolerations applyd
# Pod正常运行,且运行在k8s-node1节点
[root@k8s-master taint]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-tolerations 1/1 Running 0 8s 10.244.1.92 k8s-node1 <none> <none>查看该Pod上的容忍
[root@k8s-master taint]# kubectl describe pod web-tolerations
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
web=true:NoSchedule可以看到我们设置的Tolerations在里边,除了我们自己的,K8s还会给每个Pod设置两个默认Tolerations,并且Tolerations时间为五分钟,表示某些节点发生一些临时性问题,Pod能够继续在该节点上运行五分钟等待节点恢复,并不是立刻被驱逐,从而避免系统的异常波动。
编写 app-tolerations.yaml 内容如下,容忍污点app=true:NoExecute,并且只容忍60s
apiVersion: v1
kind: Pod
metadata:
name: app-tolerations
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: app
operator: Exists
effect: NoExecute
tolerationSeconds: 60启动app-tolerations,查看Pod是否能够正常运行,且运行在k8s-node2节点,等待60秒,查看Pod是否已被驱逐
# 启动app-tolerations
[root@k8s-master taint]# kubectl apply -f app-tolerations.yaml
pod/app-tolerations applyd
# 查看详情,已经运行成功并且调度到了k8s-node2节点,此时运行59秒
[root@k8s-master taint]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
app-tolerations 1/1 Running 0 59s 10.244.2.37 k8s-node2 <none> <none>
# 运行60秒查看,状态已经变为Terminating
[root@k8s-master taint]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
app-tolerations 1/1 Terminating 0 60s 10.244.2.37 k8s-node2 <none> <none>
# 立刻再次查看,已经被驱逐
[root@k8s-master taint]# kubectl get pod -o wide
No resources found in default namespace.如果一个节点没有任何污点,另一个节点有污点,并且Pod容忍了该污点,那么最终会调度到哪个节点呢?
删除k8s-node2节点的污点app=true:NoExecute,保留k8s-node1节点的web=true:NoSchedule,再次启动之前的web-tolerations.yaml 观察Pod所在节点
# 删除k8s-node2上的污点
[root@k8s-master taint]# kubectl taint node k8s-node2 app:NoExecute-
node/k8s-node2 untainted
# 启动Pod web-tolerations
[root@k8s-master taint]# kubectl apply -f web-tolerations.yaml
pod/web-tolerations applyd
# Pod正常运行,并且运行在k8s-node2节点
[root@k8s-master taint]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-tolerations 1/1 Running 0 2s 10.244.2.38 k8s-node2 <none> <none>上面表明,即使是容忍了该污点,如果有其它节点不需要容忍就可以调度的话,那还是会优先选择没有污点的机器,但是生产上往往设置污点就是为了给你这个Pod使用的,不能调度到其它节点,这个时候需要配合节点亲和性调度一起使用。
2.3、Equal 与 Exists
Exists 表示key是否存在所以无需设置value,Equal 则必须设置value需要完全匹配,默认为Equal
空的key配合Exists 可以匹配所有的key-value,也就是容忍所有的污点,生产上非常不建议使用
一、Pod优先级
-
优先级是什么?
-
优先级代表一个Pod相对其他Pod的重要性
-
-
优先级有什么用
-
优先级可以保证重要的Pod被调用运行
-
-
如何使用优先级和抢占
-
配置优先级类PriorityClass
-
创建Pod是为其设置对应的优先级
-
-
PriorityClass
-
PriorityClass是一个全局资源对象,它定义了从优先级类名称到优先级整数值的映射。优先级在values字段中指定,可以设置小于10亿的整数值,值越大,优先级越高
-
-
PriorityClass还有两个可选字段:
-
globalDefault:用于设置默认优先级状态,如果没有任何优先级设置,Pod的优先级为零
-
description:用来配置描述性信息,告诉用户优先级的用途
-
-
优先级策略
-
非抢占优先:指的是在调度阶段优先进行调度分配,一旦容器调度完成就不可以抢占,资源不足时,只能等待,对应
preemptionPolicy: Never -
抢占优先:强制调度一个Pod,如果资源不足无法被调度,调度程序会抢占(删除)较低优先级的Pod的资源,来保证高优先级Pod的运行,对应
preemptionPolicy: PreemptLowerPriority
-
1、非抢占优先级
# 定义优先级(队列优先)
[root@k8s-master ~]# vim mypriority.yaml
---
kind: PriorityClass # 资源对象类型
apiVersion: scheduling.k8s.io/v1 # 资源对象版本
metadata:
name: high-non # 优先级名称,可在Pod中引用
globalDefault: false # 是否定义默认优先级(唯一)
preemptionPolicy: Never # 抢占策略
value: 1000 # 优先级
description: non-preemptive # 描述信息
---
kind: PriorityClass
apiVersion: scheduling.k8s.io/v1
metadata:
name: low-non
globalDefault: false
preemptionPolicy: Never
value: 500
description: non-preemptive
[root@k8s-master ~]# kubectl apply -f mypriority.yaml
priorityclass.scheduling.k8s.io/high-non created
priorityclass.scheduling.k8s.io/low-non created
[root@k8s-master ~]# kubectl get priorityclasses.scheduling.k8s.io
NAME VALUE GLOBAL-DEFAULT AGE
high-non 1000 false 12s
low-non 500 false 12s
system-cluster-critical 2000000000 false 45h
system-node-critical 2000001000 false 45hPod资源文件
# 无优先级的 Pod
[root@k8s-master ~]# cat nginx1.yaml
---
kind: Pod
apiVersion: v1
metadata:
name: nginx1
spec:
nodeName: k8s-node2
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "1500m"
# 低优先级 Pod
[root@k8s-master ~]# cat nginx2.yaml
---
kind: Pod
apiVersion: v1
metadata:
name: nginx2
spec:
nodeName: k8s-node2
priorityClassName: low-non # 指定优先级的名称
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "1500m"
# 高优先级 Pod
[root@k8s-master ~]# cat nginx3.yaml
---
kind: Pod
apiVersion: v1
metadata:
name: nginx3
spec:
nodeName: k8s-node2
priorityClassName: high-non # 指定优先级的名称
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "1500m"2、验证非抢占优先
[root@master ~]# kubectl apply -f nginx1.yaml
pod/nginx1 created
[root@master ~]# kubectl apply -f nginx2.yaml
pod/nginx2 created
[root@master ~]# kubectl apply -f nginx3.yaml
pod/nginx3 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 9s
nginx2 0/1 Pending 0 6s
nginx3 0/1 Pending 0 4s
[root@master ~]# kubectl delete pod nginx1
pod "nginx1" deleted
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx2 0/1 Pending 0 20s
nginx3 1/1 Running 0 18s
# 清理实验 Pod
[root@master ~]# kubectl delete pod nginx2 nginx3
pod "nginx2" deleted
pod "nginx3" deleted3、抢占策略(有问题)
K8S在发生调度失败后,会基于优先级进行抢占,抢占并不是简单的将Node上的低优先级的pod”挤走“,抢占的设计还是相对比较有意思的。
K8S内部在调度过程中,会维护2个队列,分别是activeQ和unschedulableQ。
activeQ
当K8S里新创建一个Pod的时候,调度器会将这个Pod入队到activeQ里面,然后调度器从这个队列里取出一个pod进行调度。
unschedulableQ
专门用来存放调度失败的pod,当一个unschedulableQ里的Pod被更新之后,调度器会自动把这个Pod移动到activeQ里。
3.1、抢占的基本流程:
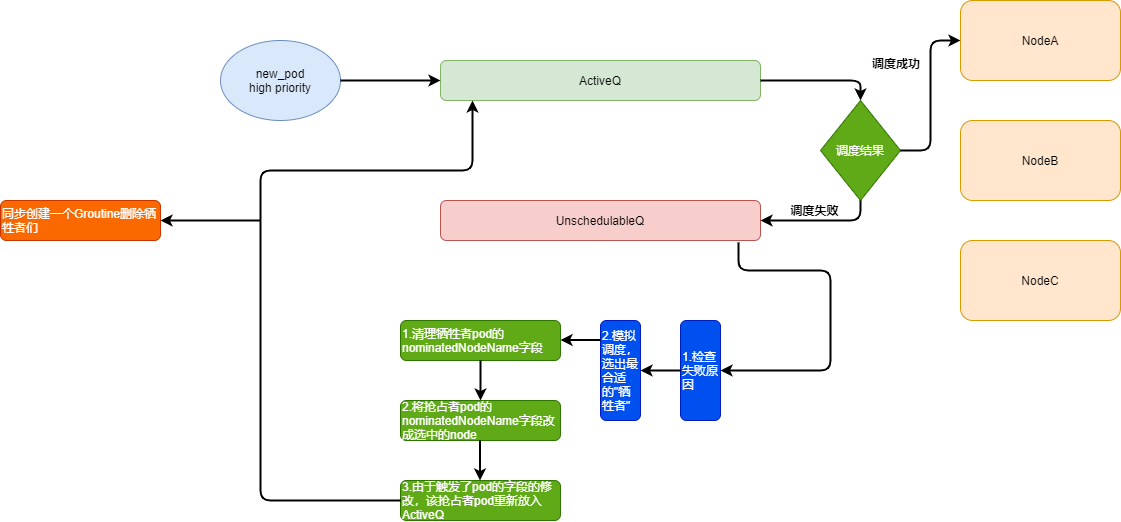
-
正常调度的pod会先放入activeQ, activeQ会经过正常的调度策略进行调度。
-
调度失败后,将这个pod放入unreachableQ里,随后出发寻找牺牲者流程。
-
在寻找牺牲者之前,先对失败原因检查下,看下是不是因为一些无法恢复的原因导致失败的,比如node-selector失败之类的。
-
确认可以触发抢占后,scheduler 会拉取所有node的缓存信息,进行一次模拟抢占流程,基于影响集群稳定性最小原则,选出了哪些node上的哪些pod,可以成为”牺牲者”。
-
对于选出的牺牲者pod,schedueler 会先清楚他们pod里的nominatedNodeName字段。
-
然后更新抢占者pod,将nominatedNodeName改成第4步选出的node名字。
-
由于抢占者pod已发生了更新,所以给他“重新做人”的机会,重新放入activeQ里。
-
同时,开启一个新的协程,清理牺牲者node上对应的牺牲者pod。
3.2、抢占的异常流程
抢占者和牺牲者其实是相对的,或者说,优先级是相对的,抢占者在第一次流程后,一般会创建在之前模拟出来的那个牺牲者node上,但是,假设同样队列里有另外一个pod也正好要调度在那个node上,K8S会对这种情况做一些特殊处理,即对该node进行2次预选操作。
-
第一次预选,假设抢占者已经在对应node上了,以这个前提进行一次预选算法。
-
第二次预选,假设抢占者不在对应node上,以这个前提进行一次预选算法。
只有这两次预选都通过了,调度器才认为这个node和pod可以绑定,再进入后续的优选算法。第二预选比较奇怪,为什么需要假设抢占者不在node上呢,这是因为删除牺牲者操作,实际是调用了标准的DELETE API进行操作的,这是一个"优雅关闭"的操作,所以存在默认30S的退出时间,而30S内,可能会有很多变故,比如再重新调度的时候,Node服务器挂了或者有更加高优先级的pod需要抢占这个node,这些都导致了重新调度的失败,所以说,抢占者不一定会调度到对应的node上。
另外还有一种情况,假设整个K8S集群有了一个比较大的变化,比如新扩容了node节点等,scheduler会执行MoveAllToActiveQueue的操作,把所调度失败的Pod从unscheduelableQ移动到activeQ里面。
另外由于亲和性的存在,当一个已经调度成功的Pod被更新时,调度器则会将unschedulableQ里所有跟这个Pod有 Affinity/Anti-affinity关系的Pod,移动到 activeQ 里面,开始调度。
[root@master ~]# vim mypriority.yaml
---
kind: PriorityClass
apiVersion: scheduling.k8s.io/v1
metadata:
name: high
globalDefault: false
preemptionPolicy: PreemptLowerPriority
value: 1000
description: non-preemptive
---
kind: PriorityClass
apiVersion: scheduling.k8s.io/v1
metadata:
name: low
globalDefault: false
preemptionPolicy: PreemptLowerPriority
value: 500
description: non-preemptive
[root@master ~]# kubectl apply -f mypriority.yaml
priorityclass.scheduling.k8s.io/high created
priorityclass.scheduling.k8s.io/low created
[root@master ~]# kubectl get priorityclasses.scheduling.k8s.io
NAME VALUE GLOBAL-DEFAULT AGE
high 1000 false 12s
low 500 false 12s
system-cluster-critical 2000000000 false 45h
system-node-critical 2000001000 false 45h4、验证抢占优先级
# 默认优先级 Pod
[root@master ~]# kubectl apply -f nginx1.yaml
pod/nginx1 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 6s
# 高优先级 Pod
[root@master ~]# sed 's,-non,,' nginx3.yaml |kubectl apply -f-
pod/nginx3 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx3 1/1 Running 0 9s
# 低优先级 Pod
[root@master ~]# sed 's,-non,,' nginx2.yaml |kubectl apply -f-
pod/nginx2 created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx2 0/1 Pending 0 3s
nginx3 1/1 Running 0 9s
# 清理实验 Pod
[root@master ~]# kubectl delete pod nginx2 nginx3
pod "nginx2" deleted
pod "nginx3" deleted
[root@master ~]# kubectl delete -f mypriority.yaml
priorityclass.scheduling.k8s.io "high-non" deleted
priorityclass.scheduling.k8s.io "low-non" deleted
priorityclass.scheduling.k8s.io "high" deleted
priorityclass.scheduling.k8s.io "low" deleted二、节点优先级
在 Kubernetes 中,节点优先级(Node Priority)是用于指定节点的调度权重的设置。节点优先级主要用于调度器在选择节点时进行权衡和做出选择。
1、优先级类型
1.1、静态优先级(Static Priority)
可以手动为每个节点设置一个固定的优先级值。在节点对象的注解(Annotations)中使用 scheduler.alpha.kubernetes.io/priority 注解来定义节点的优先级。较高的优先级值表示节点的优先级较高。
1.2、亲和性优先级(Affinity Priority)
可以通过节点的亲和性(Affinity)设置来隐式地设置节点的优先级。优先级是根据亲和性规则和节点的亲和性权重(weight)来计算的。
1.3、服务质量优先级(Quality of Service Priority)
可以通过指定 Pod 的服务质量等级(Quality of Service Class)来设置节点的优先级。服务质量等级包括 Guaranteed、Burstable、BestEffort。较高的服务质量等级对应较高的优先级。
1.3.1、QoS(服务质量)
Requests 和 limits 的配置除了表明资源情况和限制资源使用之外,还有一个隐藏的作用:它决定了 pod 的 QoS 等级。
如果 pod 没有配置 limits ,那么它可以使用节点上任意多的可用资源。这类 pod 能灵活使用资源,但这也导致它不稳定且危险,对于这类 pod 我们一定要在它占用过多资源导致节点资源紧张时处理掉。优先处理这类 pod,而不是资源使用处于自己请求范围内的 pod 是非常合理的想法,而这就是 pod QoS 的含义:根据 pod 的资源请求把 pod 分成不同的重要性等级。
kubernetes 把 pod 分成了三个 QoS 等级:
-
Guaranteed:优先级最高,可以考虑数据库应用或者一些重要的业务应用。除非 pods 使用超过了它们的 limits,或者节点的内存压力很大而且没有 QoS 更低的 pod,否则不会被杀死
-
Burstable:这种类型的 pod 可以多于自己请求的资源(上限有 limit 指定,如果 limit没有配置,则可以使用主机的任意可用资源),但是重要性认为比较低,可以是一般性的应用或者批处理任务
-
Best Effort:优先级最低,集群不知道 pod的资源请求情况,调度不考虑资源,可以运行到任意节点上(从资源角度来说),可以是一些临时性的不重要应用。pod可以使用节点上任何可用资源,但在资源不足时也会被优先杀死
1.3.2、根据QoS进行资源回收
策略
Kubernetes 通过cgroup给pod设置QoS级别,当资源不足时先kill优先级低的 pod,在实际使用过程中,通过OOM分数值来实现,OOM分数值范围为0-1000。OOM 分数值根据OOM_ADJ参数计算得出。
对于Guaranteed级别的 Pod,OOM_ADJ参数设置成了-998,对于Best-Effort级别的 Pod,OOM_ADJ参数设置成了1000,对于Burstable级别的 Pod,OOM_ADJ参数取值从2到999。
对于 kuberntes 保留资源,比如kubelet,docker,OOM_ADJ参数设置成了-999,表示不会被OOM kill掉。OOM_ADJ参数设置的越大,计算出来的OOM分数越高,表明该pod优先级就越低,当出现资源竞争时会越早被kill掉,对于OOM_ADJ参数是-999的表示kubernetes永远不会因为OOM将其kill掉。
1.3.3、QoS pods被kill掉场景与顺序
-
Best-Effort pods:系统用完了全部内存时,该类型 pods 会最先被kill掉。
-
Burstable pods:系统用完了全部内存,且没有 Best-Effort 类型的容器可以被 kill 时,该类型的 pods 会被kill 掉。
-
Guaranteed pods:系统用完了全部内存,且没有 Burstable 与 Best-Effort 类型的容器可以被 kill时,该类型的 pods 会被 kill 掉。
1.4、插件优先级(Plugin Priority)
可以编写插件来扩展调度器的功能,并为节点设置一些额外的优先级规则。
调度器在进行节点选择时,会根据节点的优先级进行权衡,优先选择具有较高优先级的节点。如果存在多个节点具有相同的优先级,则会根据其它因素(例如节点资源、亲和性规则等)进一步进行选择。
2、实战案例
2.1、静态优先级案例
场景描述
假设有一个混合了新旧硬件的Kubernetes集群。新硬件性能更优,希望调度器优先将资源密集型的应用部署到新硬件节点上。
设置步骤与示例
首先,给新硬件节点设置较高的静态优先级。假设集群中有三个节点,node-new-1和node-new-2是新硬件节点,node-old是旧硬件节点。
通过以下命令(假设可以直接修改节点注解)为新硬件节点设置优先级:
kubectl annotate node node-new-1 scheduler.alpha.kubernetes.io/priority=100
kubectl annotate node node-new-2 scheduler.alpha.kubernetes.io/priority=100
kubectl annotate node node-old scheduler.alpha.kubernetes.io/priority=50现在有一个大数据处理的Pod,需要大量的CPU和内存资源。当调度器调度这个Pod时,会首先考虑node-new-1和node-new-2这两个优先级为100的节点,因为它们的优先级高于node-old(优先级为50)。只有当新硬件节点资源不足或者不符合其他调度规则(如亲和性规则)时,调度器才会考虑node-old。
删除注解
kubectl annotate node node-old scheduler.alpha.kubernetes.io/priority-2.2、亲和性优先级案例
场景描述
考虑一个具有多个区域(zone)的多节点集群,应用需要根据区域亲和性进行部署,并且希望在满足区域亲和性的基础上,根据某种权重来优先选择节点。例如,有一个应用,它的数据存储在特定区域的存储服务中,为了减少网络延迟,希望将应用的Pod优先调度到靠近存储服务的区域的节点上,并且在这个区域内,有些节点与存储服务的网络连接质量更好,希望给这些节点更高的优先级。
设置步骤与示例
首先,为节点添加区域标签。假设存储服务在zone-a区域,节点node-1、node-2在zone-a,节点node-3在zone-b。
bash
kubectl label node node-1 zone=zone-a
kubectl label node node-2 zone=zone-a
kubectl label node node-3 zone=zone-b然后,在Pod的配置文件中设置节点亲和性和权重。假设node-1与存储服务的网络连接质量更好,希望给它更高的优先级。
apiVersion: v1
kind: Pod
metadata:
name: data-app-pod
spec:
containers:
- name: data-app-container
image: data-app-image
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- zone-a
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: node-name
operator: In
values:
- node-1
- weight: 40
preference:
matchExpressions:
- key: node-name
operator: In
values:
- node-2当调度data-app-pod时,调度器首先会过滤出zone-a的节点(node-1和node-2),因为有硬亲和性要求。然后,根据亲和性优先级的权重计算,node-1因为权重为80,会比node-2(权重为40)更有可能被选中。
2.3、服务质量优先级案例
场景描述
有一个在线交易系统,包括一个保证服务质量(Guaranteed)的核心交易处理服务,一个可突发(Burstable)的订单查询服务,以及一个尽力而为(BestEffort)的日志收集服务。希望核心交易处理服务的Pod能够优先调度到资源充足且稳定的节点上。
设置步骤与示例
对于核心交易处理服务的Pod,在配置文件中设置服务质量等级为Guaranteed:
limit与request的资源设置一致。
apiVersion: v1
kind: Pod
metadata:
name: trade-processing-pod
spec:
containers:
- name: trade-container
image: trade-processing-image
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "1"
memory: "1Gi"
### qosClass: Guaranteed-
对于订单查询服务的Pod,设置为Burstable:
limit的资源设置小于request的资源设置
apiVersion: v1
kind: Pod
metadata:
name: order-query-pod
spec:
containers:
- name: order-container
image: order-query-image
resources:
requests:
cpu: "0.5"
memory: "512Mi"
limits:
cpu: "1"
memory: "1Gi"
### qosClass: Burstable-
对于日志收集服务的Pod,设置为BestEffort:
不进行资源限制
apiVersion: v1
kind: Pod
metadata:
name: log-collection-pod
spec:
containers:
- name: log-container
image: log-collection-image
### qosClass: BestEffort调度器在调度这些Pod时,会优先考虑将trade-processing-pod(Guaranteed)调度到资源充足且稳定的节点。因为它的服务质量等级最高,其次是order-query-pod(Burstable),最后是log-collection-pod(BestEffort)。
2.4、插件优先级案例
场景描述
假设在一个企业级的Kubernetes集群中,安全团队要求对于运行敏感数据处理应用的Pod,必须优先调度到经过特定安全加固的节点上。这些节点有额外的安全防护软件和硬件模块,并且希望通过插件来实现这种特殊的优先级设置。
设置步骤与示例
首先,开发一个自定义的调度插件。这个插件可以检查节点是否具有“security-hardened”标签(表示经过安全加固的节点),并为这些节点设置较高的优先级。
安装和配置插件后,给经过安全加固的节点添加标签:
kubectl label node node-sec-1 security-hardened=true
kubectl label node node-sec-2 security-hardened=true对于敏感数据处理应用的Pod,正常创建配置文件。当调度器运行时,由于插件的作用,会优先将这些Pod调度到带有“security-hardened”标签的节点(node-sec-1和node-sec-2)上,因为插件为这些节点设置了更高的优先级。具体的插件实现可能涉及到Go语言编程,并且需要遵循Kubernetes调度器插件的开发规范来与调度器集成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)